GAN网络之入门教程(三)之DCGAN原理
如果说最经常被用来处理图像的网络模型,那么毋庸置疑,应该是CNN了,而本次入土教程的最终目的是做一个动漫头像生成的网络模型,因此我们可以将CNN与GAN结合,也就是组成了传说中的DCGAN网络。
DCGAN简介
DCGAN全称Deep Convolutional Generative Adversarial Networks,中文名曰深度卷积对抗网络。论文地址在这里。
因为DCGAN是不仅与GAN有关还与CNN有关,因此,如果不是很了解的CNN的话,建议先去看一看CNN相关的知识,也可以参考一下我以前的博客。
这里我们可以在复述一下CNN的相关知识和特点。
CNN我们可以理解为如下的行为,逐层深入"抽丝剥茧”地“理解”一张图片或其他事物。图片经过CNN网络中的一系列layer,逐渐的对图像进行细化,最终将图像从一个大的维度变成一个小的维度。在DCGAN中,判别器实际上就是一个CNN网络。输入一张图片,然后输出yes or no的概率。

而在DCGAN中,\(G\)网络的模型是怎么样的?\(G\)网络刚好和CNN相反,它是由noise通过\(G\)网络生成一张图片,因为图片通过layer逐渐变大,与卷积作用刚好相反——因此我们可以称之为反卷积。

DCGAN的特点
当然,DCGAN除了\(G\)网络与CNN不同之外,它还有以下的不同:
- 取消所有pooling层。G网络中使用转置卷积(transposed convolutional layer)进行上采样,D网络中用加入stride的卷积代替pooling。
- 除了生成器模型的输出层和判别器模型的输入层,在网络其它层上都使用了Batch Normalization,使用BN可以稳定学习,有助于处理初始化不良导致的训练问题。
- G网络中使用ReLU作为激活函数,最后一层使用tanh
- D网络中使用LeakyReLU作为激活函数
几个重要概念
为了能够继续了解DCGAN,我们还是得需要准备一下几个重要概念。
下采样(subsampled)
下采样实际上就是缩小图像,主要目的是为了使得图像符合显示区域的大小,生成对应图像的缩略图。比如说在CNN中得池化层或卷积层就是下采样。不过卷积过程导致的图像变小是为了提取特征,而池化下采样是为了降低特征的维度。
上采样(upsampling)
有下采样也就必然有上采样,上采样实际上就是放大图像,指的是任何可以让图像变成更高分辨率的技术,这个时候我们也就能理解为什么在\(G\)网络中能够由噪声生成一张图片了。
它有反卷积(Deconvolution)、上池化(UnPooling)方法。这里我们只介绍反卷积,因为这是是我们需要用到的。
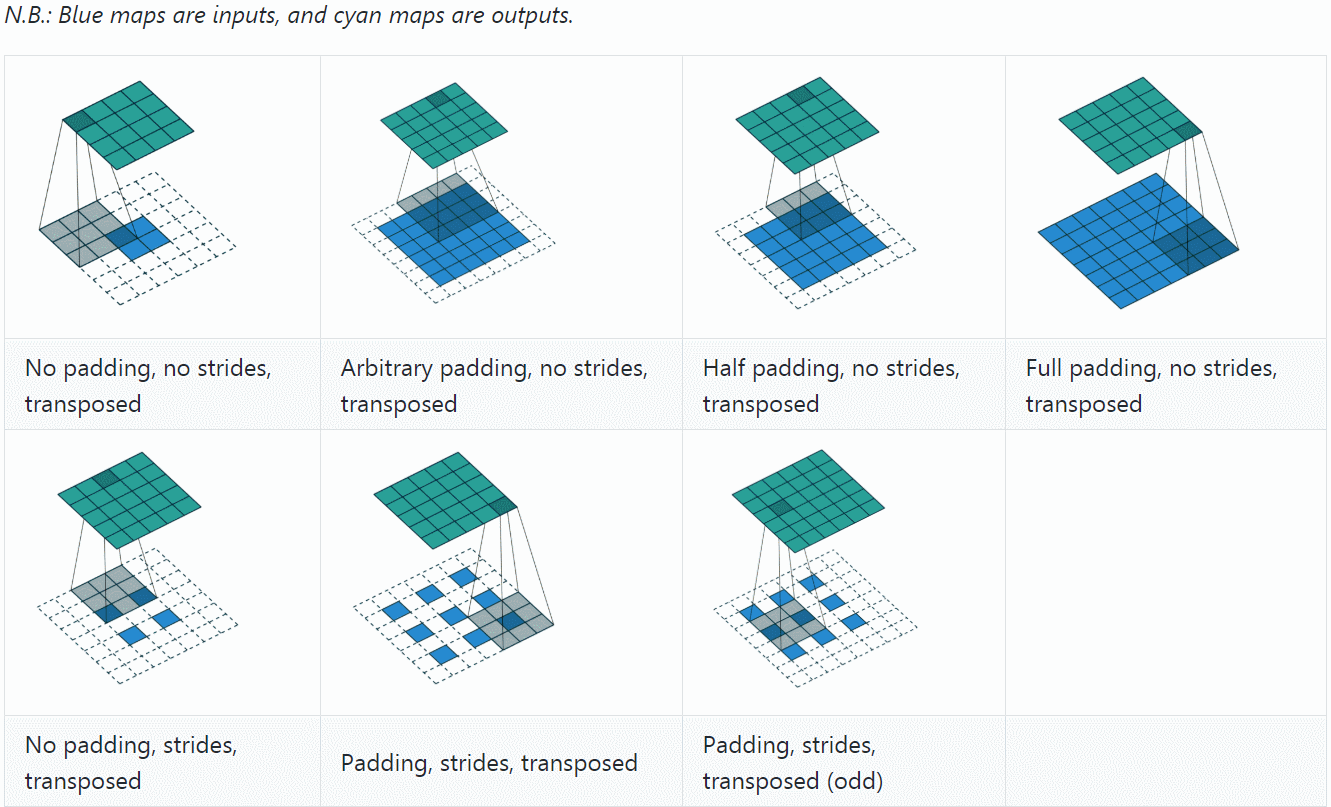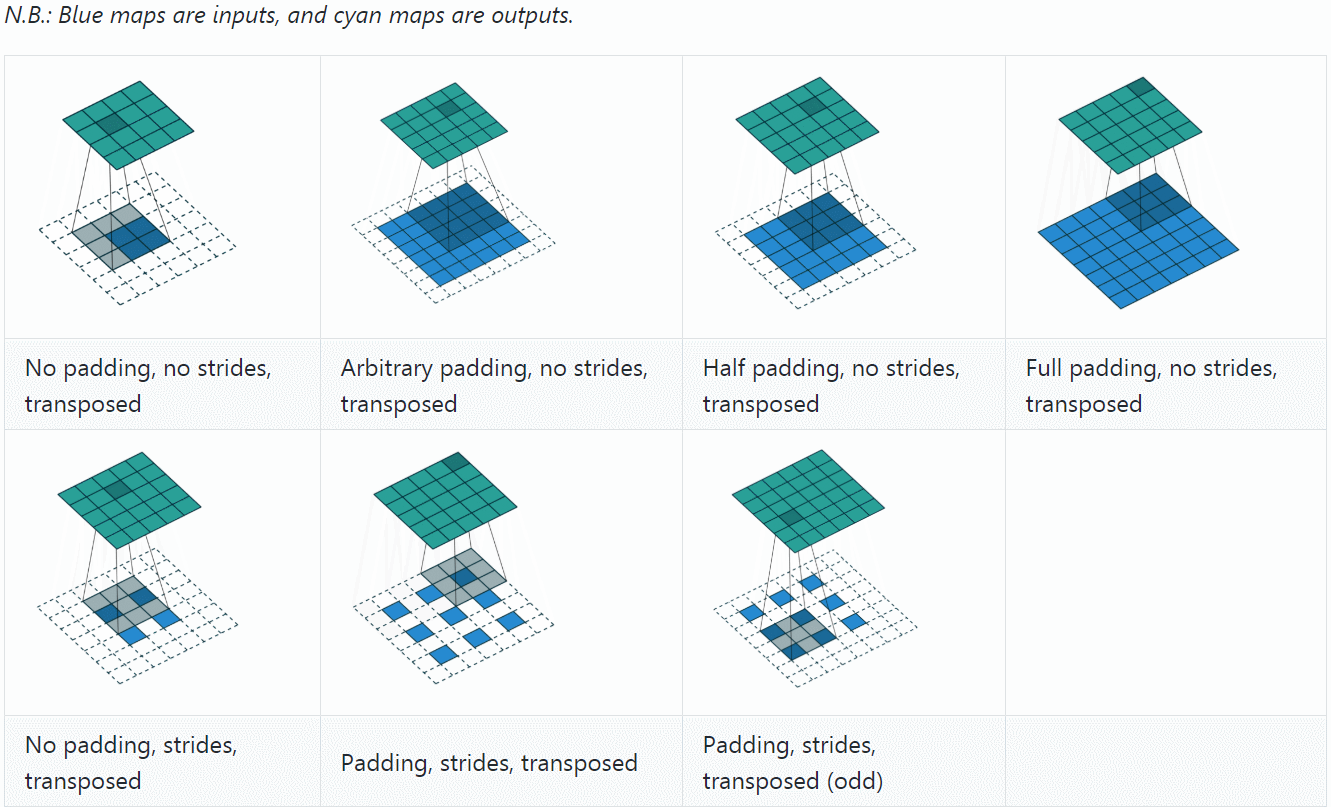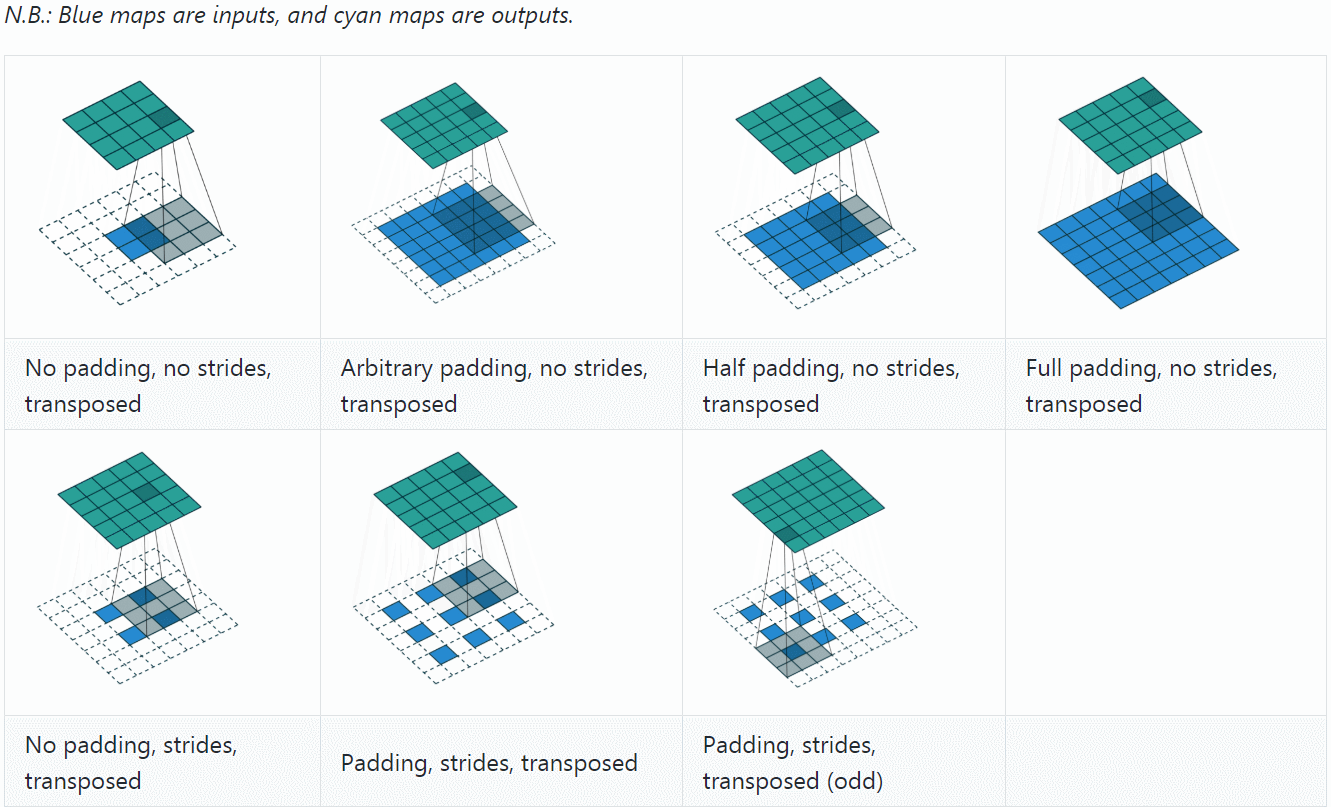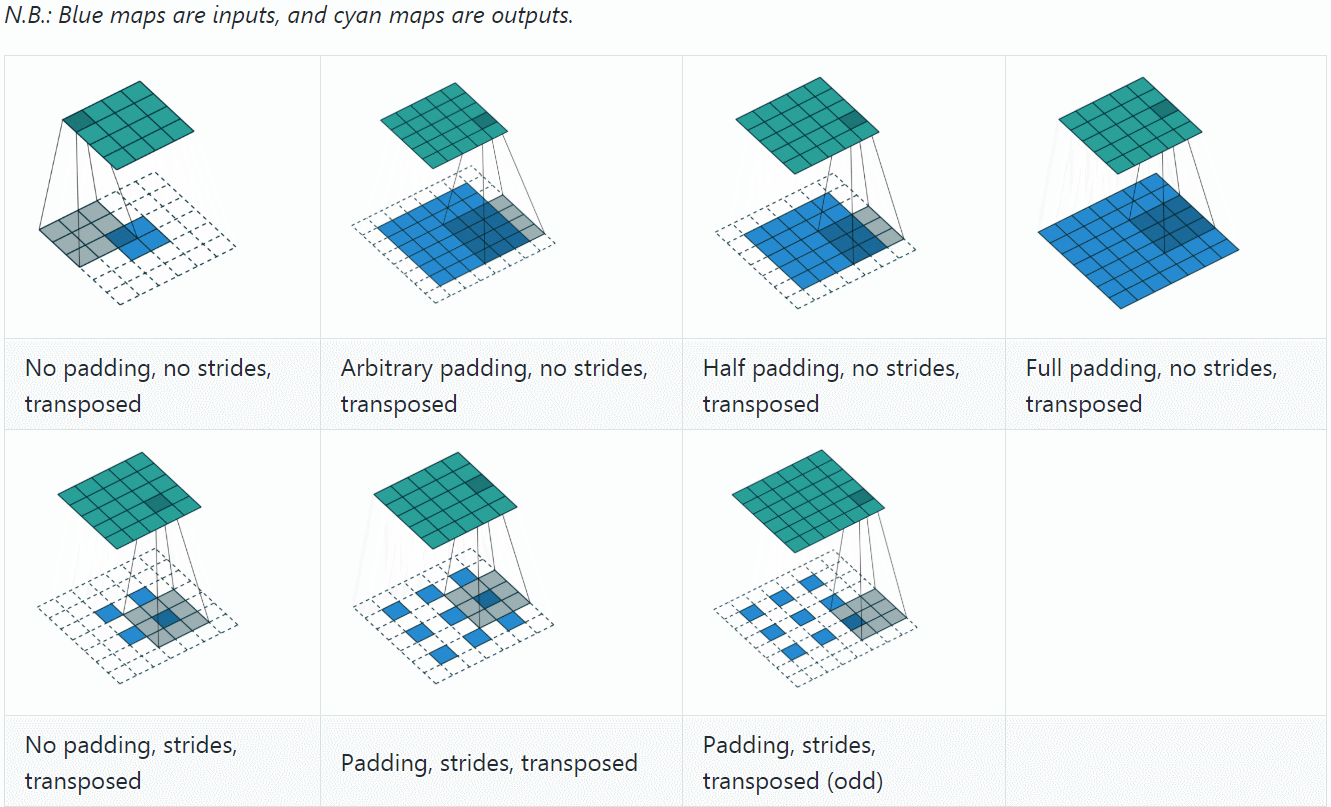
反卷积(Deconvolution)
反卷积(Deconvolution)也称为分数步长的卷积和转置卷积(transposed convolution)。在下图中,左边的为卷积,右边的为反卷积。convolution过程是将4×4的图像映射为2×2的图像,而反卷积过程则是将2×2的图像映射为4×4的图像,两者的kernel size均为3。不过显而易见,反卷积只能恢复图片的尺寸大小,而不能准确的恢复图片的像素值(此时我们想一想,在CNN中,卷积层的kernel我们可以学习,那么在反卷积中的kernel我们是不是也可以学习呢?)。
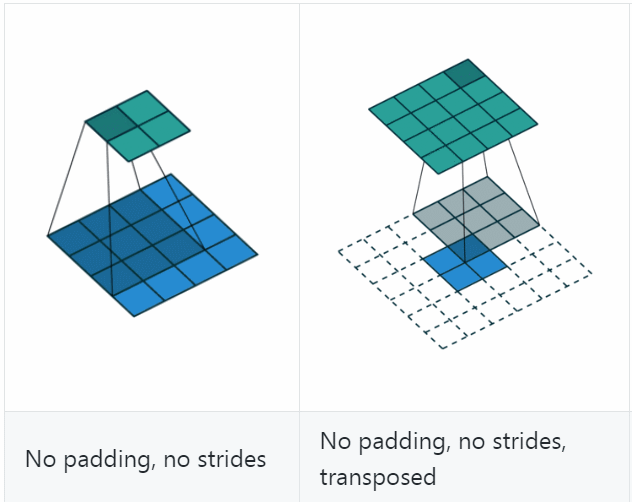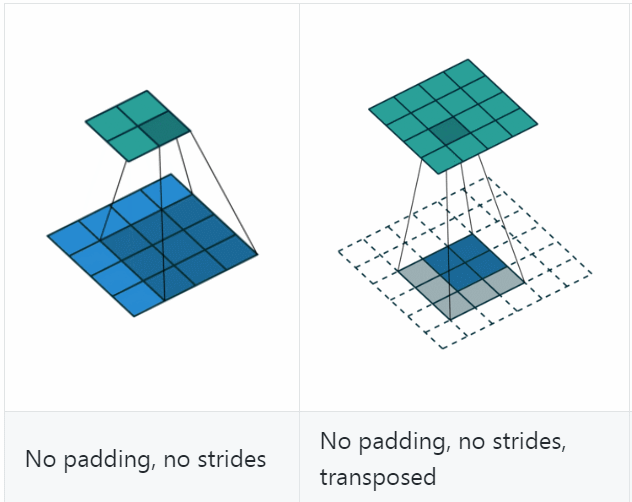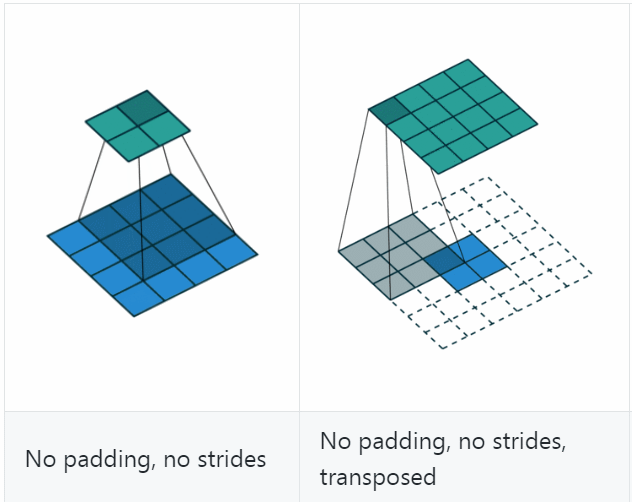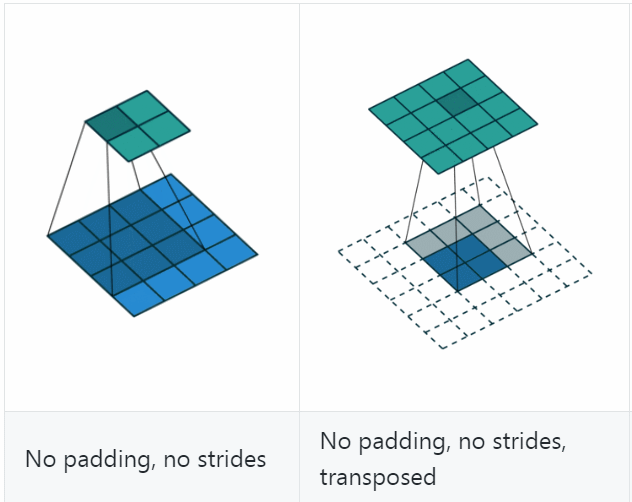
关于更多的我就不做更多的讲解了,大家可以参考别人的博客进行学习。
批标准化(Batch Normalization)
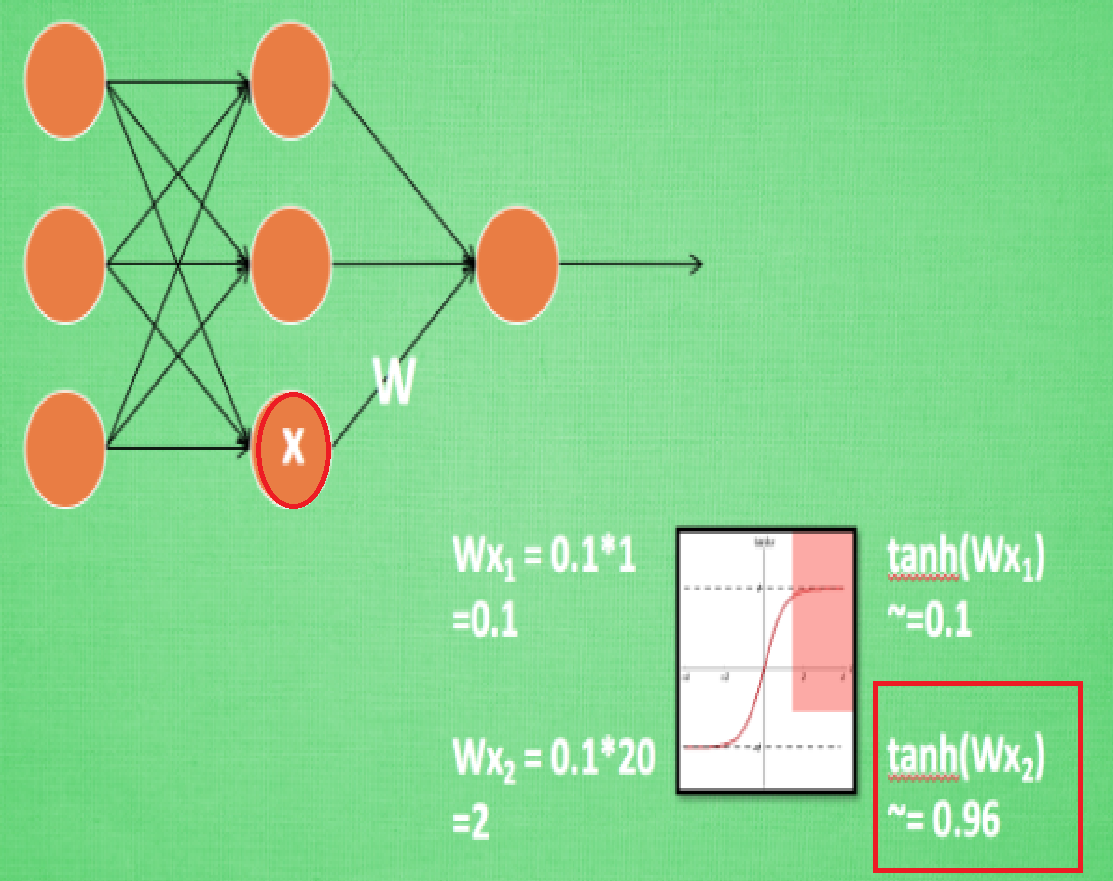
推荐大家去看看什么是批标准化 (Batch Normalization),通俗易懂。在下图中,我们可以看到,当\(x_2 = 20\)的时候,\(tanh(wx_2) = 0.96\),已经比较接近于1,如果继续增大\(x\),\(tanh(wx)\)也不会变化太多。也就是说此时增大\(x\),已经不对\(x\)敏感了,而这种问题即出现在输入层也出现在隐藏层。因此,我们需要将数据进行标准化(Normalization),且不仅需要在输入层进行这种操作,且在隐藏层也需要这种操作。Batch normalization 的 batch 是批数据, 把数据分成小批小批进行随机梯度下降。
BN算法如下:

当然BN算法看起来容易,实际上还是有很多复杂的东西,不过我们不做深入的探究。我们暂时只需要知道他的作用即可。
激活函数
下面是几种常用的函数的示意图:
| 激活函数 | ReLU激活函数 | tanh激活函数 | LeakyReLU激活函数 | Sigmoid函数 |
|---|---|---|---|---|
| 图像 | 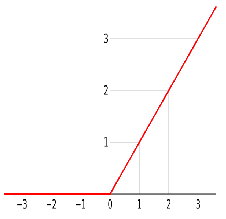 |
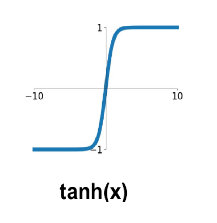 |
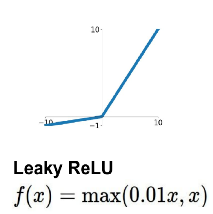 |
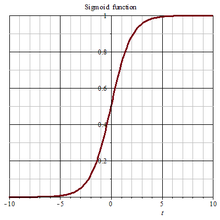 |
G模型
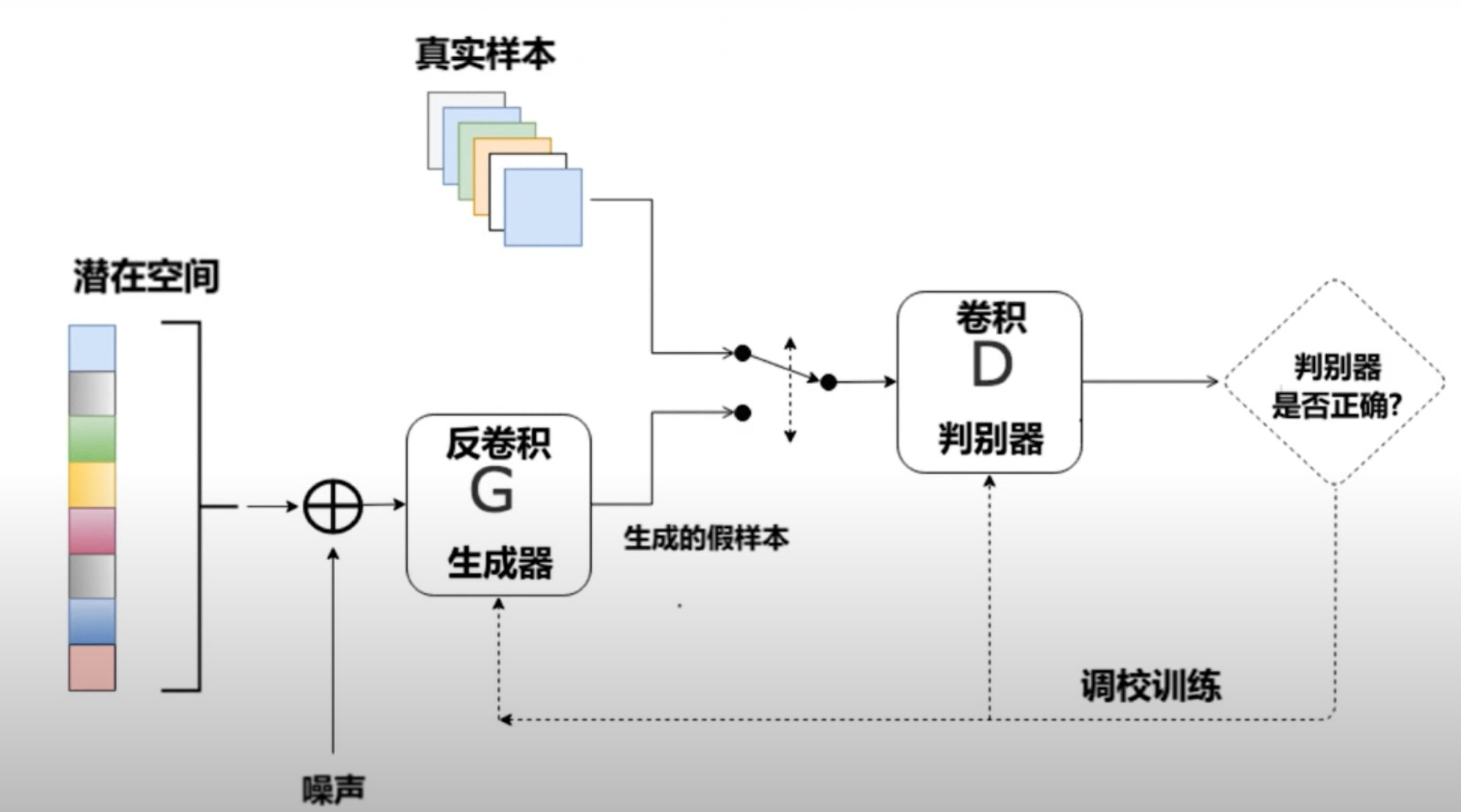
下图是GCGAN的大体框架图,在生成器中,使用反卷积生成图像,在判别器中使用卷积进行判别。
下图是在Deep Convolutional Generative Adversarial Networks论文中介绍的DCGAN生成器。该网络接收一个表示为z的100x1噪声矢量,通过一系列layer,最终将noise映射到64x64x3的图像中。
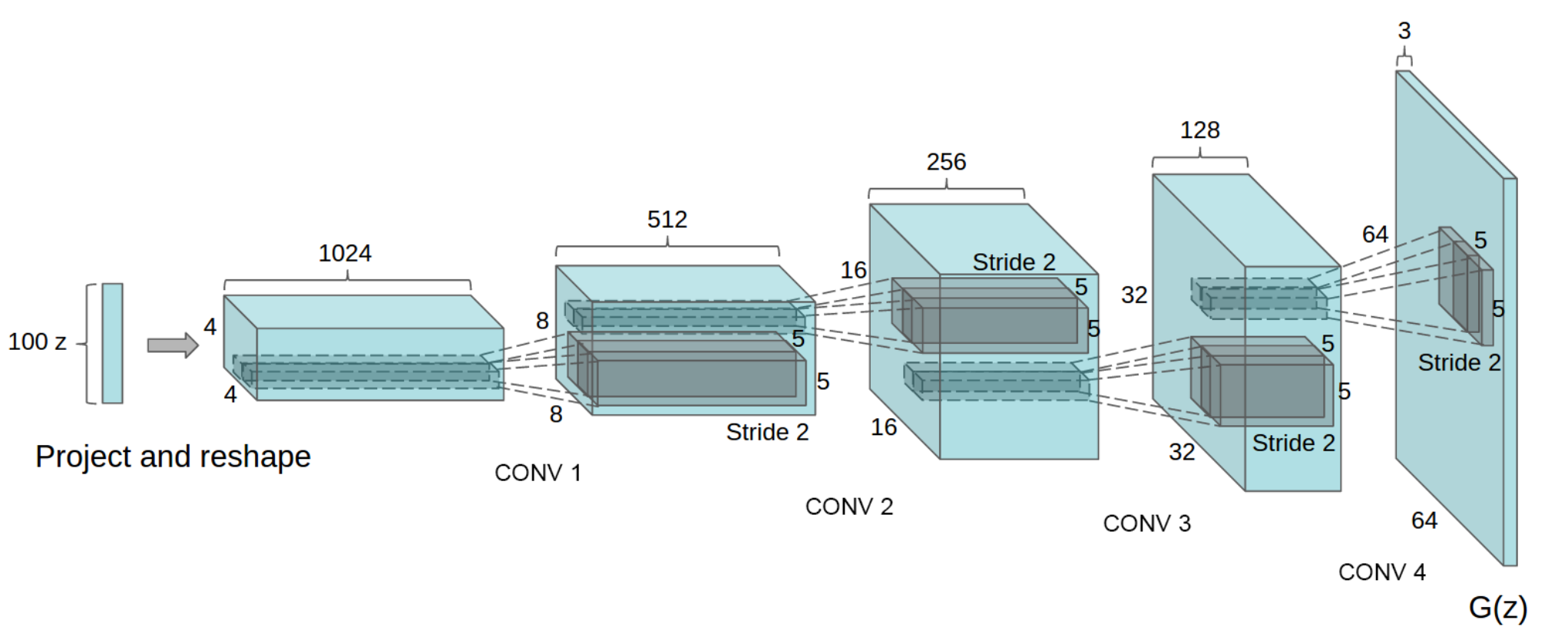
上述的过程实际上就是将一个\(1 \times 100\)的向量变成$64 \times 64 \times 3 $的图片。
- Project and reshape:将\(1 \times 100\)通过骚操作变成\(4 \times 4 \times 1024\)的向量。这里我们可以使用全连接层加卷积的方法。
- CONV:反卷积
总结
以上便是DCGAN的基本原理,在下篇博客中,将基于Keras使用DCGAN来做一个动漫头像生成的东东。
训练50轮过程中的gif示意图如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号