CUDA之矩阵转置(全局内存、共享内存)
使用全局内存
A合并访问、B非合并访问
#ifdef USE_DP
typedef double real;
#else
typedef float real;
#endif
__global__ void transpose1(const real *A, real *B, const int N)
{
const int nx = blockIdx.x * blockDim.x + threadIdx.x;
const int ny = blockIdx.y * blockDim.y + threadIdx.y;
if (nx < N && ny < N)
{
// 对矩阵 A 中数据的访问(读取)是顺序的,但对矩阵 B 中数据的访问(写入)不是顺序的
// nx表示第nx列,ny表示第ny行
B[nx * N + ny] = A[ny * N + nx];
}
}
A非合并访问、B合并访问
// 只读数据缓存的加载函数 __ldg()。从帕斯卡架构开始,如果编译器能够判断一个全局内存变量在
// 整个核函数的范围都只可读(如这里的矩阵 A),则会自动用函数 __ldg() 读取全局内存,
// 从而对数据的读取进行缓存,缓解非合并访问带来的影响
__global__ void transpose2(const real *A, real *B, const int N)
{
const int nx = blockIdx.x * blockDim.x + threadIdx.x;
const int ny = blockIdx.y * blockDim.y + threadIdx.y;
if (nx < N && ny < N)
{
B[ny * N + nx] = A[nx * N + ny];
}
}
使用共享内存
使用共享内存可以减少对全局内存的访问,加快数据的访问速度
完整代码链接
AB合并访问,存在bank
__global__ void transpose1(const real *A, real *B, const int N)
{
__shared__ real S[TILE_DIM][TILE_DIM];
int bx = blockIdx.x * TILE_DIM;
int by = blockIdx.y * TILE_DIM;
int nx1 = bx + threadIdx.x; // 第nx1列
int ny1 = by + threadIdx.y; // 第ny1行
if (nx1 < N && ny1 < N)
{
// A的访问是合并的, 第 11 行对共享内存的访问不导致 bank 冲突
S[threadIdx.y][threadIdx.x] = A[ny1 * N + nx1];
}
__syncthreads();
int nx2 = bx + threadIdx.y; // 第bx块的y行 -》S的x行
int ny2 = by + threadIdx.x; // 第by块的x列 -》 S的y列
if (nx2 < N && ny2 < N)
{
// 二维的情况:一般32个连续的threadIdx.x构成一个线程束,一个线程束内的threadIdx.y是相同的
// 同一个线程束内的线程(连续的threadIdx.x)刚好访问同一个bank中的32个数据,这将导致 32 路 bank 冲突
B[nx2 * N + ny2] = S[threadIdx.x][threadIdx.y];
}
}
AB合并访问,消除bank
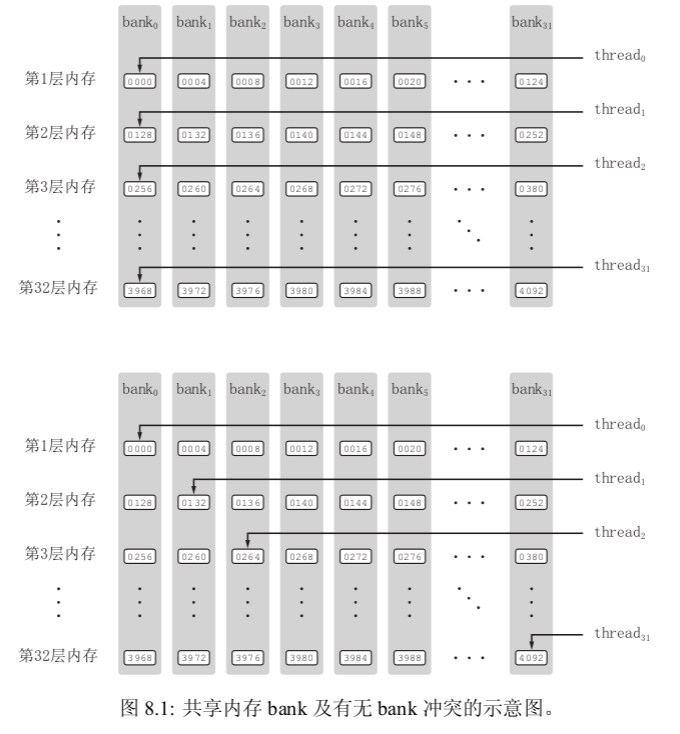
为了获得高的内存带宽,共享内存在物理上被分为 32 个(刚好等于一个线程束中的线程数目,即内建变量 warpSize 的值)同样宽度的、能被同时访问的内存 bank。我们可以将 32 个 bank 从 0 到 31 编号。在每一个 bank 中,又可以其中的内存地址从 0 开始编号。为方便起见,我们将所有 bank 中编号为 0 的内存称为第一层内存;将所有 bank 中编号为 1 的内存称为第二层内存。在开普勒架构中,每个 bank 的宽度为 8 字节;在所有其他架构中,每个 bank 的宽度为 4 字节
只要同一线程束内的多个线程不同时访问同一个 bank 中不同层的数据,该线程束对共享内存的访问就只需要一次内存事务(memory transaction)。当同一线程束内的多个线程试图访问同一个 bank 中不同层的数据时,就会发生 bank 冲突。在一个线程束内对同一个 bank 中的 n 层数据同时访问将导致 n 次内存事务,称为发生了 n 路 bank 冲突。最坏的情况是线程束内的 32 个线程同时访问同一个 bank 中 32 个不同层的地址,这将导致 32 路 bank 冲突。这种 n 很大的 bank 冲突是要尽量避免的。
__global__ void transpose2(const real *A, real *B, const int N)
{
/*
这样改变共享内存数组的大小之后,同一个线程束中的 32 个线程(连续的 32 个 threadIdx.x 值)将对应共享内存数组 S 中跨度为 33 的数据。如果第一个线程访问第一个 bank 的第一层,第二个线程则会
访问第二个 bank 的第二层(而不是第一个 bank 的第二层);如此等等。于是,这 32 个线程将分别访问 32 个不同 bank 中的数据,所以没有 bank 冲突,
*/
__shared__ real S[TILE_DIM][TILE_DIM + 1];
int bx = blockIdx.x * TILE_DIM;
int by = blockIdx.y * TILE_DIM;
int nx1 = bx + threadIdx.x;
int ny1 = by + threadIdx.y;
if (nx1 < N && ny1 < N)
{
S[threadIdx.y][threadIdx.x] = A[ny1 * N + nx1];
}
__syncthreads();
int nx2 = bx + threadIdx.y;
int ny2 = by + threadIdx.x;
if (nx2 < N && ny2 < N)
{
B[nx2 * N + ny2] = S[threadIdx.x][threadIdx.y];
}
}
__shared__ real S[TILE_DIM][TILE_DIM + 1];
这样改变共享内存数组的大小之后,同一个线程束中的 32 个线程(连续的 32 个 threadIdx.x 值)将对应共享内存数组 S 中跨度为 33 的数据。如果第一个线程访问第一个 bank 的第一层,第二个线程则会访问第二个 bank 的第二层(而不是第一个 bank 的第二层);如此等等。于是,这 32 个线程将分别访问 32 个不同 bank 中的数据,所以没有 bank 冲突
参考:《CUDA 编程:基础与实践_樊哲勇》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号