

牛逼,DeepSeek-OCR 最新免费,引爆文档处理效率的黑科技模型
DeepSeek-OCR 最新免费,引爆文档处理效率的黑科技,把 PDF、扫描件、一堆图片一句话搞定成Markdown文档
嗨,我是小华同学,专注解锁高效工作与前沿AI工具!每日精选开源技术、实战技巧,助你省时50%、领先他人一步。👉免费订阅,与10万+技术人共享升级秘籍!


“DeepSeek-OCR:Contexts Optical Compression。探索视觉-文本压缩的边界。”
这是由 DeepSeek‑AI 开源的一款 OCR 模型 + 工具链,核心亮点在于:将文档中的大量文字内容通过视觉编码方式压缩,再进行识别与结构化,从而实现更高效、更结构化的文档理解能力。
痛点场景
在实际工作环节中,很多人/团队会被以下问题「卡住」:
-
📄 海量扫描/PDF文档:手工输入繁琐、容易出错。 -
🧾 文档结构混乱:标题、表格、图表混杂,传统 OCR 难以还原。 -
⏳ 批量处理需求强烈:一个项目可能有成千上万页,传统工具难以支撑。 -
🎯 后续格式化需求高:文档读取只是第一步,结构化输出(如 Markdown、HTML)才有价值。 -
🤖 与 LLM/知识库集成难:OCR 得到只是原文,还得二次处理才能用于智能分析。
举个场景:
某大型法律咨询公司,每月收到数万页合同扫描件,律师团队希望快速导入知识库、进行全文搜索、生成合同摘要。传统 OCR 虽提取文字,但表格、版面、图注都丢失,且不能直接输出可编辑的结构化格式。
如果能用 DeepSeek-OCR,把扫描件直接转为「标题/正文/表格/图注」结构的 Markdown,再快速导入知识库,整个流程就能从 “几天才能整理完” 缩到 “几小时搞定”。
核心功能
| 功能 | 描述 | 关键价值 |
|---|---|---|
| 视觉压缩编码 | 将文档内容(如扫描图片)编码为“视觉 tokens”,而不是传统逐字文本 token。 | 提高上下文处理效率,尤其适用于长文档/大批量。 |
| 结构化输出 | 输出格式不仅是纯文本,还可选 Markdown、可识别标题、列表、表格结构。 | 文档更“可用”:直接导入、编辑、作为知识库。 |
| 高吞吐批量处理 | 例如一张 A100-40G GPU 每天可处理 20 万+ 页。 | 企业级任务也能支撑。 |
| 支持图片 + PDF | 不仅扫描图片,还支持整本 PDF 文档输入。 | 适配多种输入场景。 |
| 兼容 vLLM / Transformers 推理 | 可在多种框架下运行,例如 vLLM + SamplingParams。 | 灵活集成到现有 AI 流水线。 |
| 开源可部署 | 开源代码 + 模型权重,MIT 许可证。 | 可自建、自控、安全可审。 |
使用示例代码
以下为官方一个简单入门示例(已简化):
from transformers import AutoTokenizer, AutoModel
import torch, os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
model_name = "deepseek-ai/DeepSeek-OCR"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name,
_attn_implementation='flash_attention_2',
trust_remote_code=True,
use_safetensors=True)
model = model.eval().cuda().to(torch.bfloat16)
prompt = "<image>\n<|grounding|>Convert the document to markdown."
image_file = "your_image.jpg"
output_path = "your/output/dir"
res = model.infer(tokenizer,
prompt=prompt,
image_file=image_file,
output_path=output_path,
base_size=1024,
image_size=640,
crop_mode=True,
save_results=True,
test_compress=True)
print("结果保存在:", output_path)上述代码能快速将一张图片转换为 Markdown 输出。你也可以改为 pdf 模式批量处理。
技术架构
架构图


技术优势整理
| 模块 | 优势描述 |
|---|---|
| 视觉编码(DeepEncoder) | 将文档元素转为视觉 tokens,信息密度高、结构感强。 |
| 多模态语言模型(MoE 解码器) | 引入专家网络(Mixture of Experts)机制,更精准地解析结构化内容。 |
| 高压缩比 | 在压缩比 < 10× 情况下,识别精度可达 ≈ 97%。 |
| 批量优化 | 支持大规模页面并行处理,适合训练数据构建、文档仓库等场景。 |
| 开源部署能力 | 模型权重、代码、文档公开,自建部署支持安全与定制。 |
技术栈基础
-
Python 3.12.x + CUDA 11.8 构建(官方环境) -
PyTorch 2.6.0、Transformers 4.46.3、Flash-Attn 2.7.3 等。 -
支持 vLLM 引擎推理,加速批量任务。
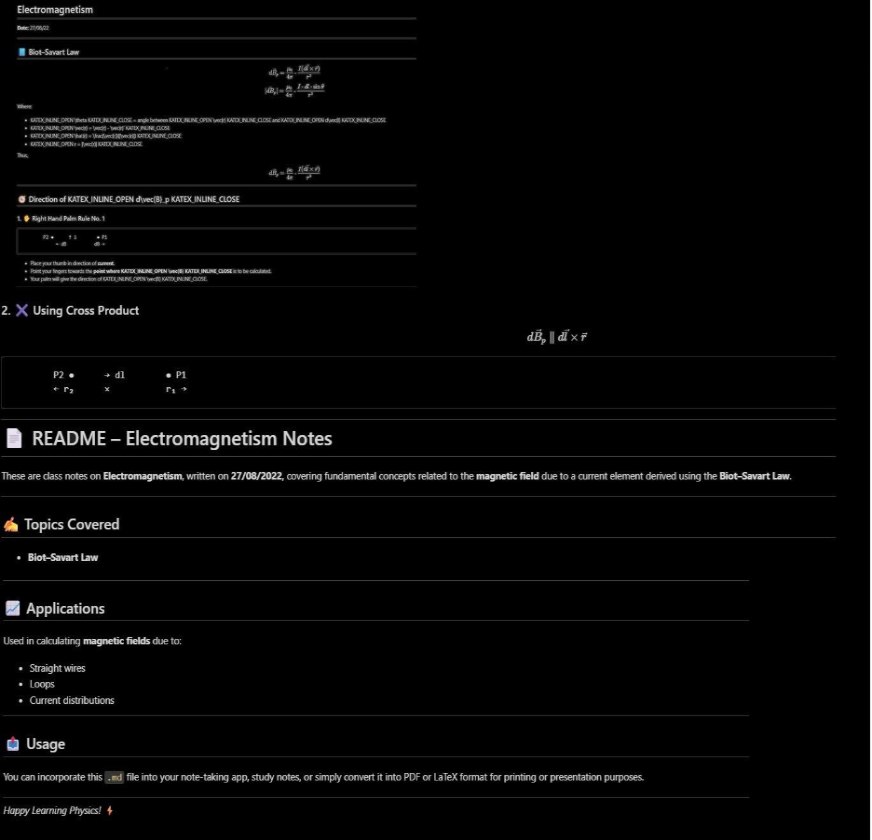
界面效果


-
界面 1:Web UI 屏幕,左侧上传图像或 PDF,右侧实时显示识别结构。 -
界面 2:批量处理界面,显示待处理文件、进度条、已完成项。 -
界面 3:输出 Markdown 预览,标题、正文、表格、图表均有保留。
这些截图直观地展现了从「原始扫描件 → 结构化文本」的完整流程,降低使用门槛,让非技术用户也能快速上手。
应用场景
结合功能与界面效果,以下是值得落地的典型业务场景:
-
合同/协议整理:法律、财务团队将扫描合同批量转换为编辑友好的 Markdown,再导入知识库。 -
报告归档与分析:科研机构或企业将 PDF 报告处理为结构化文本,方便全文检索与摘要。 -
政务/档案数字化:政府部门扫描公文,转化为可编辑格式入档。 -
教育资源整理:将讲义、教材扫描件批量转换为可检索、可编辑的 Markdown 教材。 -
培训/客户资料归档:企业讲义、方案书、客户手册等PDF资料,快速加工为结构化内容便于管理。
无论是「一件事一份文档」的小量场景,还是「千万页/月」的海量场景,DeepSeek-OCR 都具备适配能力。
与同类项目对比及产品优势
| 项目 | 识别结构化能力 | 长文档/批量处理 | 输出格式 | 开源&可部署 | 优势总结 |
|---|---|---|---|---|---|
| DeepSeek-OCR | 强(支持标题、表格、图注) | 很强(文档压缩+批量) | Markdown/文本 | ✅ | 最佳结构化输出+可部署 |
| Tesseract OCR | 基础(主要提取文字) | 较弱 | 文本 | ✅ | 开源经典,但结构化弱 |
| ABBYY FineReader | 强(商业) | 较强 | 文本/Office | ❌(商业) | 商业成熟但收费、不可自建 |
| Google Vision OCR | 中等 | 中等 | 文本/JSON | ❌(API) | 云端方便但费用高、结构化有限 |
产品优势总结:
-
深度结构化:相比传统 OCR 仅提取文字,DeepSeek-OCR 关注“文档结构”本身。 -
高吞吐+压缩:长文档、批量文档场景显著优于多数工具。 -
开源自部署:适合企业、机构构建私有化流程,降低 SaaS 风险。 -
输出格式友好:Markdown 输出方便编辑、检索、二次加工。
总结
如果你正面对大量扫描文档、PDF 文件,或者希望将“被动输入+手工整理”流程自动化、结构化,那么 DeepSeek-OCR 是一个值得“收藏并立即实验”的项目。它不仅提升识别效率,更重要的是提升后续数据可用性。
项目地址
https://github.com/deepseek-ai/DeepSeek-OCR
有的同学不太喜欢使用命令行的,那么推荐你使用下面的 UI界面工具,效果嘎嘎好!!!!
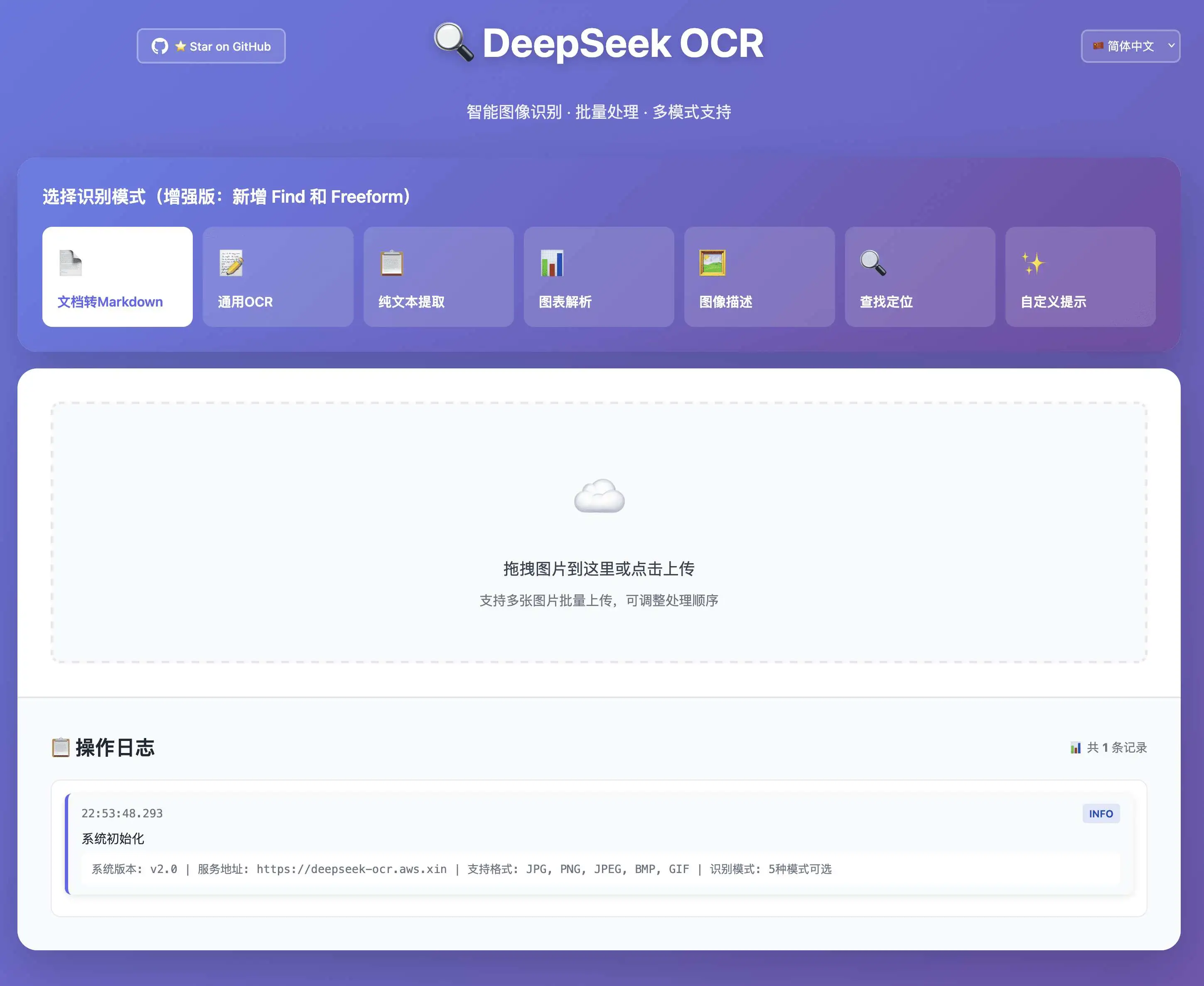
界面工具
DeepSeek-OCR-WebUI 是一个基于 DeepSeek-OCR 模型的智能图像识别 Web 应用,提供直观的用户界面和强大的识别功能。

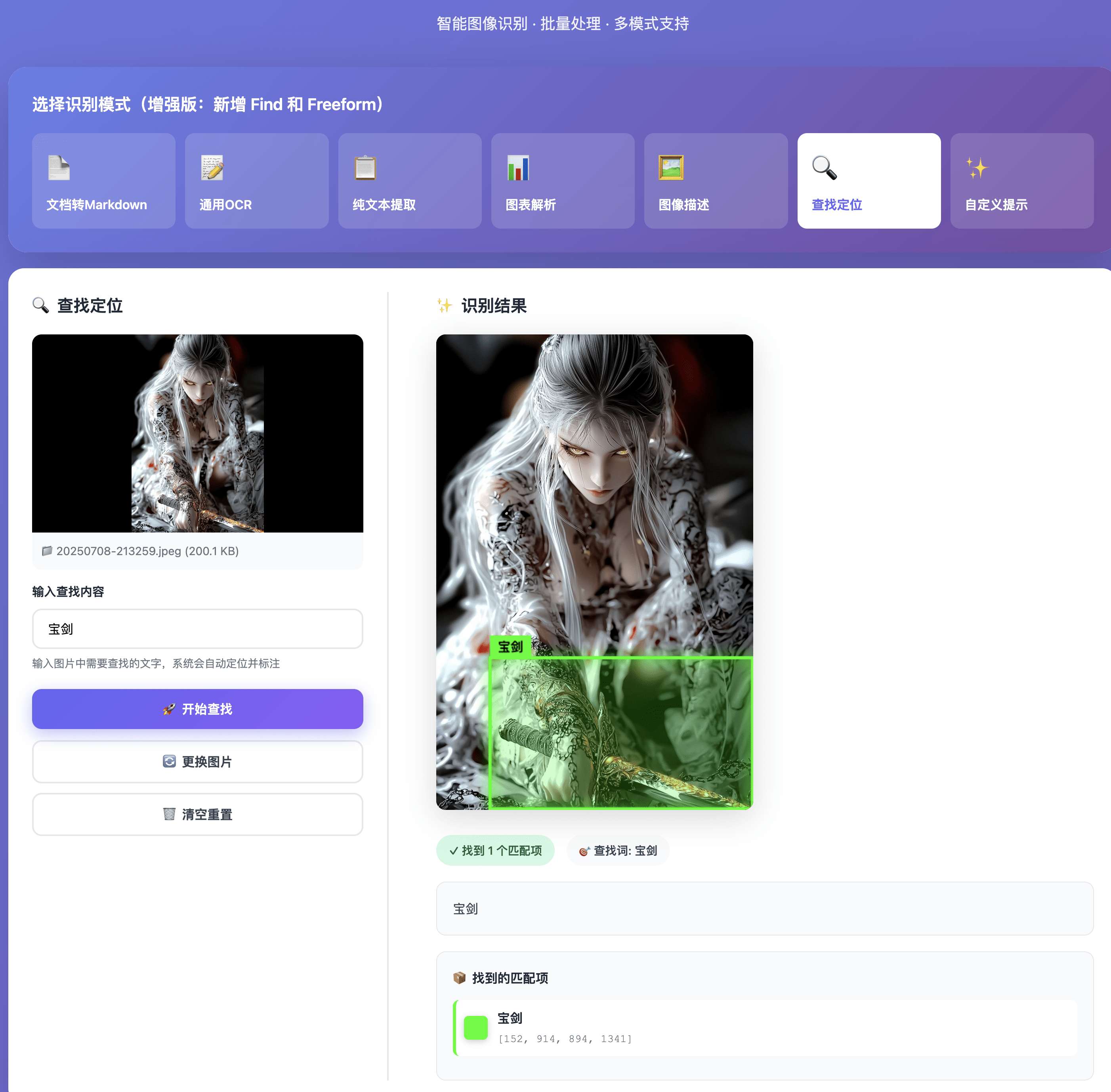
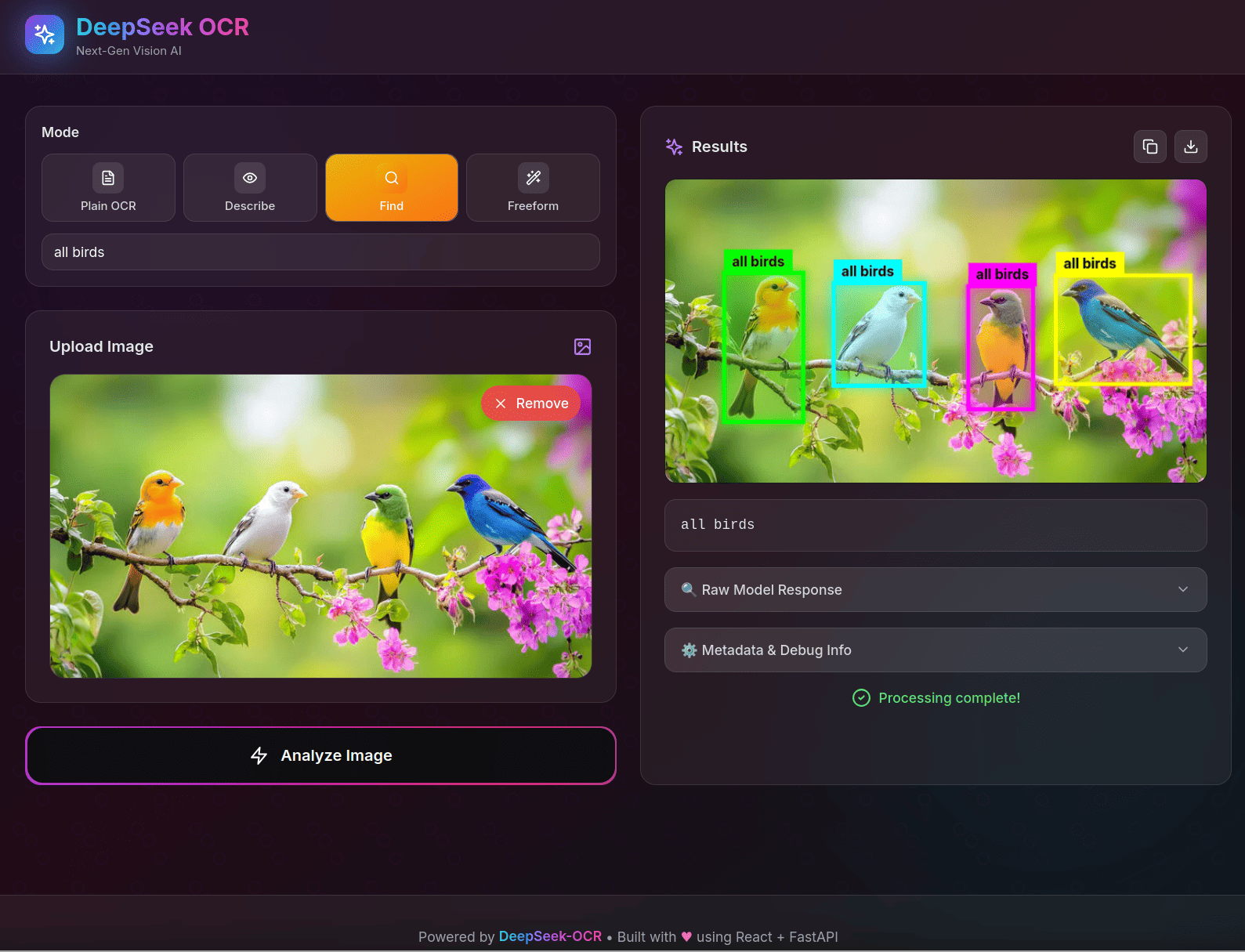
核心亮点
🎯 7 种识别模式 - 文档、OCR、图表、Find、Freeform 等
🖼️ 边界框可视化 - Find 模式自动标注位置
📦 批量处理 - 支持多张图片逐一识别
🎨 现代化 UI - 炫酷的渐变背景和动画效果
🌐 多语言支持 - 简中、繁中、英语、日语
🐳 Docker 部署 - 一键启动,开箱即用
⚡ GPU 加速 - 基于 NVIDIA GPU 的高性能推理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号