

完蛋啦,爆火Github项目,用微信聊天记录打造专属AI数字分身,我都不敢相信!!
嗨,我是小华同学,专注解锁高效工作与前沿AI工具!每日精选开源技术、实战技巧,助你省时50%、领先他人一步。👉免费订阅,与10万+技术人共享升级秘籍!


WeClone 是一个通过微信(WeChat)或 Telegram 聊天记录微调大语言模型(LLM),打造你的专属数字分身的完整解决方案。支持文本、图片等多模态数据,经过预处理、训练、部署后,你的 AI 角色不仅「会说你的话」,还能「像你一样说话」,还能绑定到聊天机器人中使用 。
痛点场景
-
每个人都有独特表达风格,但 AI 通常是千人一面,WeClone 可以让 AI 拥有「你」的语言风采。 -
聊天数据零散分布,项目提供完整一站式流水线,从导出、清洗、模型微调到部署都有指引。 -
隐私与部署不信任第三方,WeClone 支持本地部署,敏感数据可自主控制。 -
从聊天到对话机器人,帮你在微信/Telegram 上拥有一个“还能说你话”的数字化自己。
WeClone 正是针对这些痛点,为开发者和个人用户提供:
-
使用 私密微信聊天数据 生成 AI 聊天机器人,完全本地化部署 -
支持 语言风格迁移 + 语音仿真,让机器人“说话像你”
核心功能
| 功能亮点 | 描述 |
|---|---|
| 聊天记录导入与过滤 | 支持从微信、Telegram 导出聊天文本与图像,自动过滤敏感信息 |
| 数据预处理与格式标准化 | 提取聊天内容、清洗噪声、转换为微调所需格式 |
| LLM 微调训练 | 使用 ChatGLM3‑6B 等模型微调,使输出风格高度贴合用户语气 |
| 语音克隆(WeClone‑audio) | 将微信语音作为音频训练素材,使机器人“听起来像你” |
| 机器人绑定与部署 | 支持 Telegram、WeChat、QQ、企业微信、飞书等平台 |
| 隐私保护机制 | 所有处理在本地完成,不上传聊天记录;支持类别敏感信息剔除与个性化设置 |
技术架构
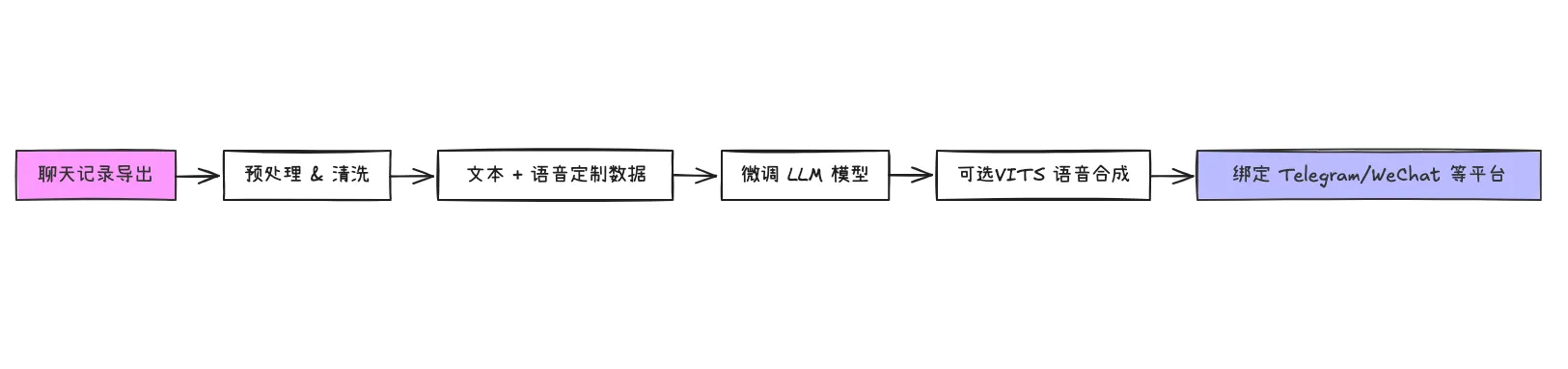

架构说明:
-
数据链路:从聊天记录导出 → 预处理 → 文本和音频训练材料 → LLM 微调与生成 -
部署链路:模型输出风格化回复,可选择合成语音 → 接入聊天平台机器人端
技术优势整理
| 类别 | 优势说明 |
|---|---|
| 模型选择 | 默认 ChatGLM3‑6B 模型,支持中文双语交流,部署门槛低 |
| 隐私保护 | 数据全流程本地化处理,不上传云端 |
| 语音还原 | 微信语音克隆,机器人声音更真实 |
| 平台覆盖广 | 支持 WeChat、Telegram、QQ、企微、飞书等,支持后续扩展 |
| 使用简便 | 提供导出、清洗、训练、部署脚本,适合非机器学习专业用户 |
界面效果演示
⚠ 此部分展示 WeClone 核心使用截图和界面示例,按照 README 中顺序原样保留


典型应用场景
-
个人数字分身:用自己过去微信聊天记录训练,生成拥有自己说话风格与语气的聊天机器人 -
纪念型机器人:通过故人聊天记录还原其语气风格,用于纪念或对话交互 -
个性化客服机器人:企业内部可用客服人员真实聊天记录训练,提升客服风格一致性与亲切度 -
AI 办公助手:整合个人习惯与语言风格,训练为个人专属 AI 辅助工具,如日程、提醒等
与同类项目对比
| 项目 | WeClone | 类似 AI 聊天助手(如 Replika 或 ChatGPT 插件) |
|---|---|---|
| 个性话语言训练 | ✅ 支持好友聊天记录训练 | ❌ 多为通用大模型,对你不具备专属风格 |
| 语音克隆 | ✅ 高保真度克隆 | ❌ 多为标准语音,不贴合个人声纹 |
| 隐私控制 | ✅ 本地处理 + presidio 过滤 | ❌ 多依赖云端,隐私难掌控 |
| 集成平台 | ✅ WeChat、Telegram 支持 | ❌ 云助手平台,各自封闭 |
| 模型优化 | ✅ 支持 LoRA、qwen3、ChatGLM3 | ❌ 模型固定,无法训练 |
使用示例
# 克隆项目
git clone https://github.com/xming521/WeClone.git
cd WeClone
# 创建 Python 环境
python3.9 -m venv .venv
source .venv/bin/activate # Linux / Mac
.venv\Scripts\activate # Windows
# 安装依赖
pip install -e .# 导出微信聊天记录(示例路径)
python weclone/data/chat_parsers/wechat_parser.py \
--wechat-data-dir "/path/to/WeChat Files/你的账号"
# 预处理隐私数据
weclone preprocess --input ./dataset/wechat --output ./training_data
# 微调模型
weclone train \
--model qwen‑3‑b \
--data ./training_data \
--lora
# 语音克隆训练(使用 5 秒样本)
weclone train‑voice --voice‑sample voice0.wav
# 部署到机器人
weclone deploy --platform wechat --bot astrbot这样,你的数字分身就能在微信中自动应答文字和语音了,而且风格接近你本人!
-
每步脚本支持参数配置,操作灵活 -
可视化监控日志显示训练过程与进度
总结
WeClone 是一个 适合个人与企业用户 的开源项目,它以 微信聊天记录为训练素材,通过 LLM 微调 + 语音克隆 技术,生成极具个性化的聊天机器人。支持微信、Telegram、QQ、飞书等平台,所有数据处理过程都在 本地完成,既保护隐私又让机器人“说话像你”。

项目地址
https://github.com/xming521/WeClone

 浙公网安备 33010602011771号
浙公网安备 33010602011771号