读paper:image caption with global-local attention…
最近的图片caption真的越来越火了,CVPR ICCV ECCV AAAI很多顶级会议都有此类的文章,今天我来讲一篇发表在AAAI的文章,因为我看了大量的论文,最近感觉AAAI越来越水了。所以这篇文章相对还是比较简单的。很遗憾,我向作者要源码。作者也没理我,不开心。。
Caption:
说简单点,就是给你一张图片,然后系统自动生成一句话或者若干句话去描述它。比如这样:
Give a image:

You will get : A beautiful girl stood in the corridor…..(当然如果加上知识图谱可能会出现,miss cang stood in the corridor…哈哈,小猥琐了一下,大家不要介意)
正常我们做captions 都是在coco数据集上做的,这是他们做出的效果:

不过从结果上来说还是很不错的,不过谁知道呢。。。图像描述人都不一定能说全。。。
本文的框架图:
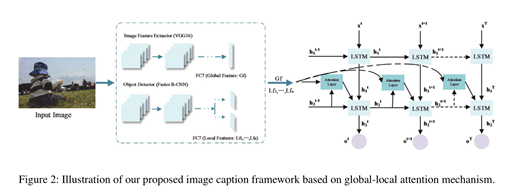
给一张图片我们分别用cnn和local-faster cnn 抽取他们的全局特征(Gf)与局部特征(Lf)。然后用下面的公式1把它集成起来:
公式1:
s.t 
 就是局部特征与全局特征的权重,当然这个怎么求呢。我们就用到了attention机制(来自于机器翻译里),这个机制最近用的很多啊。
就是局部特征与全局特征的权重,当然这个怎么求呢。我们就用到了attention机制(来自于机器翻译里),这个机制最近用的很多啊。
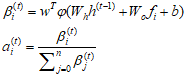 (快告诉我这个是不是LSTM的cell细胞,我读书少你别骗我。。哈哈)
(快告诉我这个是不是LSTM的cell细胞,我读书少你别骗我。。哈哈)
这张图写在这里感觉就是废话,就是RNN 与LSTM的对比。

目标就是训练: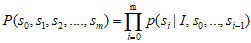 ,就是就是可能性最大的跌乘。
,就是就是可能性最大的跌乘。
损失函数就是最常用的最大似然损失函数: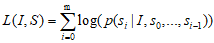 。
。
这些都不是创新点,没什么好说的。
综上,这篇文章最大的创新点就是那个attention 机制和那个抽取局部特征的的RCNN。这样就上了AAAI。。。。我很难想通。。。哈哈。但是话又说回来了,这不就是大道至简吗?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号