redis
redis
1、redis 是什么?
Redis是一种基于键值对的NoSQL((Not Only SQL:泛指非关系型的数据库),而键值对的值是由多种数据结构和算法组成的。
Redis的数据都存储于内存中,因此它的速度惊人,读写性能可达10万/秒,远超关系型数据库。
关系型数据库是基于二维数据表来存储数据的,它的数据格式更为严谨,并支持关系查询。关系型数据库的数据存储于磁盘上,可以存放海量的数据,但性能远不如Redis。
2、Redis 应用场景
- Redis最常用来做缓存,是实现分布式缓存的首先中间件;
- Redis可以作为数据库,实现诸如点赞、关注、排行等对性能要求极高的互联网需求;
- Redis可以作为计算工具,能用很小的代价,统计诸如PV/UV、用户在线天数等数据;
- Redis还有很多其他的使用场景,例如:可以实现分布式锁,可以作为消息队列使用
3、Redis 数据结构
redis内部整体的存储结构是一个大的hashmap,内部是数组实现的hash,key冲突通过挂链表去实现,每个dictEntry为一个key/value对象,value为定义的redisObject。
结构图如下:
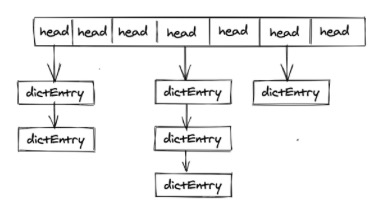
dictEntry是存储key->value的地方,再让我们看一下dictEntry结构体
/*
* 字典
*/
typedef struct dictEntry {
// 键
void *key;
// 值
union {
// 指向具体redisObject
void *val;
//
uint64_t u64;
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
redisObject结构
/*
* Redis 对象
*/
typedef struct redisObject {
// 类型 4bits
unsigned type:4;
// 编码方式 4bits
unsigned encoding:4;
// LRU 时间(相对于 server.lruclock) 24bits
unsigned lru:22;
// 引用计数 Redis里面的数据可以通过引用计数进行共享 32bits
int refcount;
// 指向对象的值 64-bit
void *ptr;
} robj;
*ptr指向具体的数据结构的地址;type表示该对象的类型,即String,List,Hash,Set,Zset中的一个,但为了提高存储效率与程序执行效率,每种对象的底层数据结构实现都可能不止一种,encoding 表示对象底层所使用的编码。
redis对象底层的八种数据结构
REDIS_ENCODING_INT(long 类型的整数)
REDIS_ENCODING_EMBSTR embstr (编码的简单动态字符串)
REDIS_ENCODING_RAW (简单动态字符串)
REDIS_ENCODING_HT (字典)
REDIS_ENCODING_LINKEDLIST (双端链表)
REDIS_ENCODING_ZIPLIST (压缩列表)
REDIS_ENCODING_INTSET (整数集合)
REDIS_ENCODING_SKIPLIST (跳跃表和字典)
好了,通过redisObject就可以具体指向redis数据类型了,总结一下每种数据类型都使用了哪些数据结构,如下图所示:

1、Redis支持5种核心的数据类型,分别是字符串、哈希、列表、集合、有序集合;
2、另外Redis还提供了Bitmap、HyperLogLog、Geo类型,但这些类型都是基于上述核心数据类型实现的;
3、Redis在5.0新增加了Streams数据类型,它是一个功能强大的、支持多播的、可持久化的消息队列
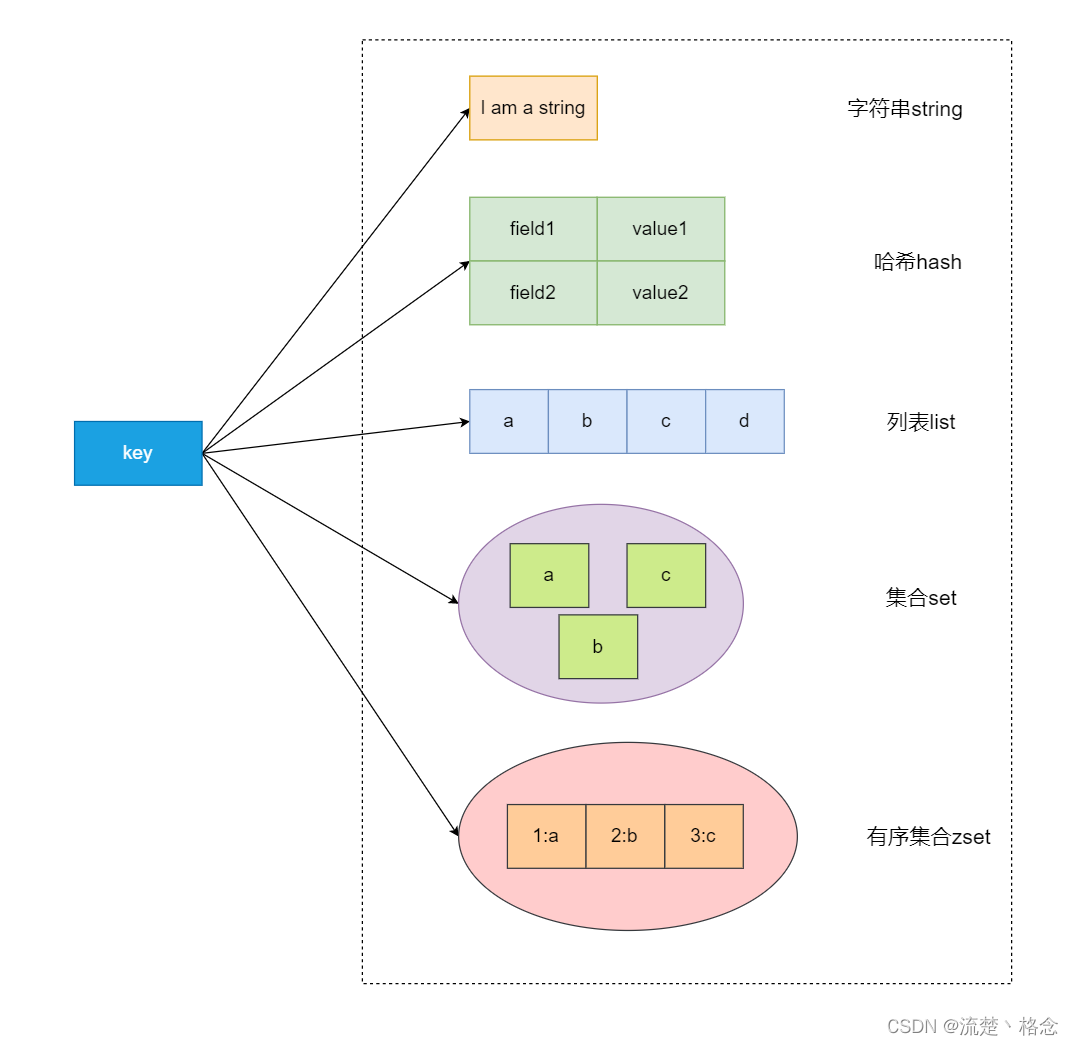
注意:这里的数据类型实际描述的是 value 的类型,key 都是 string,常见数据类型(value)有如下类型
1. string(embstr、raw、int)
2. list(quicklist,由多个 ziplist 双向链表组成)
3. hash(ziplist,键值比较少、hashtable键值超过某些阈值或者单个键值比较大)
4. set(intset、hashtable)
5. sorted set(ziplist、skiplist)
6. bitmap
7. hyperloglog
每一种类型都用 redisObject 结构体来表示,每种类型根据情况不同,有不同的编码 encoding(即每种结构体的底层数据结构)
3.1、string
String 是最基本的 key-value 结构,key 是唯一标识,value 是具体的值,value其实不仅是字符串, 也可以是数字(整数或浮点数),value 最多可以容纳的数据长度是 512M。
3.1.1 存储结构
如果字符串保存的是整数值,则底层编码为 int,实际使用 long (8字节)来存储
如果字符串保存的是非整数值(浮点数字或其它字符)使用的是 SDS(简单动态字符串)来存储,又分两种情况
- 长度 <= 39 字节,使用 embstr 编码来保存,即将 redisObject 和 sdshdr 结构体保存在一起,分配内存只需一次
- 长度 > 39 字节,使用 raw 编码来保存,即 redisObject 结构体分配一次内存,sdshdr 结构体分配一次内存,用指针相连
sdshdr(SDS )称为简单动态字符串,实现上有点类似于 java 中的 StringBuilder,Redis是用C语言实现的,sdshdr 是底层代码定义的一个结构体,它有如下特性 - 可以单独存储字符长度,相比 char* 获取长度效率高(char* 是 C 语言原生字符串表示)
- 支持动态扩容,方便字符串拼接操作
- 预留空间,减少内存分配、释放次数(< 1M 时容量是字符串实际长度 2 倍,>= 1M 时容量是原有容量 + 1M)
- 二进制安全,例如传统 char* 以 \0 作为结束字符,这样就不能保存视频、图片等二进制数据,而 sds 以长度来进行读取
3.1.2 应用场景
3.1.2.1 缓存对象
使用 String 来缓存对象有两种方式:
• 直接缓存整个对象的 JSON,命令例子:
SET user:1 '{"name":"xiaolin", "age":18}'
• 采用将 key 进行分离为 user:ID:属性,采用 MSET 存储,用 MGET 获取各属性值,命令例子:
MSET user:1:name laoniu user:1:age 18 user:2:name xiaoqian user:2:age 20
3.1.2.2 常规计数
因为 Redis 处理命令是单线程,所以执行命令的过程是原子的。因此 String 数据类型适合计数场景,比如计算访问次数、点赞、转发、库存数量等等。
比如计算文章的阅读量:
# 初始化文章的阅读量
> SET aritcle:readcount:1001 0
OK
#阅读量+1
> INCR aritcle:readcount:1001
(integer) 1
#阅读量+1
> INCR aritcle:readcount:1001
(integer) 2
#阅读量+1
> INCR aritcle:readcount:1001
(integer) 3
# 获取对应文章的阅读量
> GET aritcle:readcount:1001
"3"
3.1.2.3 分布式锁
分布式锁,即分布式系统中的锁。在单体应用中我们通过锁解决的是控制共享资源访问的问题,而分布式锁,就是解决了分布式系统中控制共享资源访问的问题。与单体应用不同的是,分布式系统中竞争共享资源的最小粒度从线程升级成了进程。
我们可以基于reids实现分布式锁,如下:
SET 命令有个 NX 参数可以实现「key不存在才插入」,可以用它来实现分布式锁:
• 如果 key 不存在,则显示插入成功,可以用来表示加锁成功;
• 如果 key 存在,则会显示插入失败,可以用来表示加锁失败。
一般而言,还会对分布式锁加上过期时间,分布式锁的命令如下:
SET lock_key unique_value NX PX 10000
• lock_key 就是 key 键;
• unique_value 是客户端生成的唯一的标识;
• NX 代表只在 lock_key 不存在时,才对 lock_key 进行设置操作;
• PX 10000 表示设置 lock_key 的过期时间为 10s,这是为了避免客户端发生异常而无法释放锁。
而解锁的过程就是将 lock_key 键删除,但不能乱删,要保证执行操作的客户端就是加锁的客户端。所以,解锁的时候,我们要先判断锁的 unique_value 是否为加锁客户端,是的话,才将 lock_key 键删除。
可以看到,解锁是有两个操作,这时就需要 Lua 脚本来保证解锁的原子性,因为 Redis 在执行 Lua 脚本时,可以以原子性的方式执行,保证了锁释放操作的原子性。
// 释放锁时,先比较 unique_value 是否相等,避免锁的误释放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
这样一来,就通过使用 SET 命令和 Lua 脚本在 Redis 单节点上完成了分布式锁的加锁和解锁。
3.2、list(列表)
List 列表是简单的字符串列表,按照插入顺序排序,可以从头部或尾部向 List 列表添加元素。
列表的最大长度为 2^32 - 1,也即每个列表支持超过 40 亿个元素。
3.2.1 存储结构
从 Redis 3.2 开始,Redis 采用 quicklist 作为其编码方式,它是一个双向链表,节点元素是 ziplist
quicklist 是大链表 大链表里套了多个小链表(ziplist)
List(列表)特点如下:
- 由于是链表,内存上不连续
- 操作头尾效率高,时间复杂度 O(1)
- 链表中 ziplist 的大小和元素个数都可以设置,其中大小默认 8kb(默认空间可以以后将他们串起来成quicklist )
3.2.2 补充:ziplist(压缩列表)
ziplist 用一块连续的内存存储数据,设计目标是让数据存储更紧凑,减少碎片开销,节约内存,它的结构如下

- zlbytes – 记录整个 ziplist 占用字节数
- zltail-offset – 记录尾节点偏移量:用于快速定位尾结点,倒着遍历
- zllength – 记录节点数量:
- entry – 节点,1 ~ N 个,每个 entry 记录了前一 entry 长度(也是为了倒序遍历 减去字节),本 entry 的编码、长度、实际数据,为了节省内存,根据实际数据长度不同,用于记录长度的字节数也不同,例如前一 entry 长度是 253 时,需要用 1 个字节,但超过了 253,需要用 5 个字节
- zlend – 结束标记
ziplist 适合存储少量元素,否则查询效率不高,并且长度可变的设计会带来连锁更新问题
3.2.3 应用场景
3.2.3.1 消息队列
https://blog.csdn.net/weixin_45525272/article/details/127588010
3.3、Hash(哈希)
Hash 是一个键值对(key - value)集合,其中 value 的形式如: value=[{field1,value1},...{fieldN,valueN}]。Hash 特别适合用于存储对象。
3.3.1 存储结构
Hash 类型的底层数据结构是由压缩列表或哈希表实现的:
• 如果哈希类型元素个数小于 512 个,所有值小于 64 字节的话,Redis 会使用(ziplist)压缩列表作为 Hash 类型的底层数据结构;
• 如果哈希类型元素不满足上面条件,Redis 会使用hashtable 编码作为 Hash 类型的 底层数据结构。
3.3.2 补充:hashtable 编码
hash 函数,Redis 5.0 采用了 SipHash 算法
采用拉链法解决 key 冲突
rehash 时机
① 当元素数 < 1 * 桶个数时,不扩容
② 当元素数 > 5 * 桶个数时,一定扩容
③ 当 1 * 桶个数 <= 元素数 <= 5 * 桶个数时,如果此时没有进行 AOF 或 RDB 操作时
④ 当元素数 < 桶个数 / 10 时,缩容
rehash 要点
① 每个字典有两个哈希表,桶个数为 2 n 2^n2n,平时使用 ht[0],ht[1] 开始为 null,扩容时新数组大小为元素个数 * 2
② 渐进式 rehash,即不是一次将所有桶都迁移过去,每次对这张表 CRUD 仅迁移一个桶
③ active rehash,server 的主循环中,每 100 ms 里留出 1s 进行主动迁移
④ rehash 过程中,新增操作 ht[1] ,其它操作先操作 ht[0],若没有,再操作 ht[1]
⑤ redis 所有 CRUD 都是单线程,因此 rehash 一定是线程安全的
3.3.3 应用场景
3.3.3.1 缓存对象
Hash 类型的 (key,field, value) 的结构与对象的(对象id, 属性, 值)的结构相似,也可以用来存储对象。
我们以用户信息为例,它在关系型数据库中的结构是这样的:
| uid | name | -age |
|---|---|---|
| 1 | Meng | 12 |
| 2 | Qingqiu | 23 |
我们可以使用如下命令,将用户对象的信息存储到 Hash 类型:
# 存储一个哈希表uid:1的键值
> HMSET uid:1 name Meng age 12
2
# 存储一个哈希表uid:2的键值
> HMSET uid:2 name Qingqiu age 23
2
# 获取哈希表用户id为1中所有的键值
> HGETALL uid:1
1) "name"
2) "Meng"
3) "age"
4) "12"
3.4、Set(集合)
Set 类型是一个无序并唯一的键值集合,它的存储顺序不会按照插入的先后顺序进行存储。
一个集合最多可以存储 2^32-1 个元素。概念和数学中个的集合基本类似,可以交集,并集,差集等等,所以 Set 类型除了支持集合内的增删改查,同时还支持多个集合取交集、并集、差集。
Set 类型和 List 类型的区别如下:
• List 可以存储重复元素,Set 只能存储非重复元素;
• List 是按照元素的先后顺序存储元素的,而 Set 则是无序方式存储元素的。
3.4.1 存储结构
Set 类型的底层数据结构是由整数集合或哈希表实现的:
• 如果集合中的元素都是整数且元素个数小于 512 个,Redis 会使用intset编码作为 Set 类型的底层数据结构;
• 如果集合中的元素不满足上面条件,则 Redis 使用hashtable 编码类型的底层数据结构。
3.4.2 应用场景
集合的主要几个特性,无序、不可重复、支持并交差等操作。
因此 Set 类型比较适合用来数据去重和保障数据的唯一性,还可以用来统计多个集合的交集、错集和并集等,当我们存储的数据是无序并且需要去重的情况下,比较适合使用集合类型进行存储。
但是要提醒你一下,这里有一个潜在的风险。Set 的差集、并集和交集的计算复杂度较高,在数据量较大的情况下,如果直接执行这些计算,会导致 Redis 实例阻塞。
在主从集群中,为了避免主库因为 Set 做聚合计算(交集、差集、并集)时导致主库被阻塞,我们可以选择一个从库完成聚合统计,或者把数据返回给客户端,由客户端来完成聚合统计。
3.4.2.1 点赞
Set 类型可以保证一个用户只能点一个赞,这里举例子一个场景,key 是文章id,value 是用户id。
uid:1 、uid:2、uid:3 三个用户分别对 article:1 文章点赞了。
# uid:1 用户对文章 article:1 点赞
> SADD article:1 uid:1
(integer) 1
# uid:2 用户对文章 article:1 点赞
> SADD article:1 uid:2
(integer) 1
# uid:3 用户对文章 article:1 点赞
> SADD article:1 uid:3
(integer) 1
uid:1 取消了对 article:1 文章点赞。
> SREM article:1 uid:1
(integer) 1
获取 article:1 文章所有点赞用户 :
> SMEMBERS article:1
1) "uid:3"
2) "uid:2"
获取 article:1 文章的点赞用户数量:
> SCARD article:1
(integer) 2
判断用户 uid:1 是否对文章 article:1 点赞了:
> SISMEMBER article:1 uid:1
(integer) 0 # 返回0说明没点赞,返回1则说明点赞了
3.4.2.2 共同关注
因为 Set 类型支持交集运算,所以可以用来计算共同关注的好友、公众号等。
key 可以是用户id,value 则是已关注的公众号的id。
uid:1 用户关注公众号 id 为 5、6、7、8、9,uid:2 用户关注公众号 id 为 7、8、9、10、11。
# uid:1 用户关注公众号 id 为 5、6、7、8、9
> SADD uid:1 5 6 7 8 9
(integer) 5
# uid:2 用户关注公众号 id 为 7、8、9、10、11
> SADD uid:2 7 8 9 10 11
(integer) 5
111
uid:1 和 uid:2 共同关注的公众号:
# 获取共同关注
> SINTER uid:1 uid:2
1) "7"
2) "8"
3) "9"
给 uid:2 推荐 uid:1 关注的公众号:
> SDIFF uid:1 uid:2
1) "5"
2) "6"
验证某个公众号是否同时被 uid:1 或 uid:2 关注:
> SISMEMBER uid:1 5
(integer) 1 # 返回0,说明关注了
> SISMEMBER uid:2 5
(integer) 0 # 返回0,说明没关注
3.4.2.2 抽奖活动
存储某活动中中奖的用户名 ,Set 类型因为有去重功能,可以保证同一个用户不会中奖两次。
key为抽奖活动名,value为员工名称,把所有员工名称放入抽奖箱 :
>SADD lucky Tom Meng John Sean Marry Lindy Sary Yu
(integer) 5
如果允许重复中奖,可以使用 SRANDMEMBER 命令。
# 抽取 1 个一等奖:
> SRANDMEMBER lucky 1
1) "Tom"
# 抽取 2 个二等奖:
> SRANDMEMBER lucky 2
1) "Yu"
2) "Meng"
# 抽取 3 个三等奖:
> SRANDMEMBER lucky 3
1) "Sary"
2) "Tom"
3) "Meng"
如果不允许重复中奖,可以使用 SPOP 命令。
# 抽取一等奖1个
> SPOP lucky 1
1) "Sary"
# 抽取二等奖2个
> SPOP lucky 2
1) "Meng"
2) "Yu"
# 抽取三等奖3个
> SPOP lucky 3
1) "John"
2) "Sean"
3) "Lindy"
3.5、Sorted Set(有序集合)
Zset 类型(有序集合类型)相比于 Set 类型多了一个排序属性 score(分值),对于有序集合 ZSet 来说,每个存储元素相当于有两个值组成的,一个是有序结合的元素值,一个是排序值。
有序集合保留了集合不能有重复成员的特性(分值可以重复),但不同的是,有序集合中的元素可以排序。
3.5.1 存储结构
Zset 类型的底层数据结构是由压缩列表或跳表实现的:
• 如果有序集合的元素个数小于 128 个,并且每个元素的值小于 64 字节时,Redis 会使用ziplist作为 Zset 类型的底层数据结构;
• 如果有序集合的元素不满足上面的条件,Redis 会使用skiplist+hashtable作为 Zset 类型的底层数据结构;
3.5.2 举例说明
- 在数据量较小时,采用 ziplist 作为其编码,按 score 有序,当键或值长度过大(64)或个数过多(128)时,转为 skiplist + hashtable 编码,同时采用的理由是
• 只用 hashtable,CRUD 是 O(1),但要执行有序操作,需要排序,带来额外时间空间复杂度
• 只用 skiplist,虽然范围操作优点保留,但时间复杂度上升
• 虽然同时采用了两种结构,但由于采用了指针,元素并不会占用双份内存 - skiplist 要点:多层链表、排序规则、 backward、level(span,forward)
![]()
• score 存储分数、member 存储数据、按 score 排序,如果 score 相同再按 member 排序
• backward 存储上一个节点指针
• 每个节点中会存储层级信息(level),同一个节点可能会有多层,每个 level 有属性:
• foward 同层中下一个节点指针
• span 跨度,用于计算排名,不是所有跳表都实现了跨度,Redis 实现特有 - 多层链表可以加速查询,规则为,从顶层开始
a. 大于同层右边的,继续在同层向右找
b. 相等找到了
c. 小于同层右边的或右边为 NULL,下一层,重复 1、2 步骤
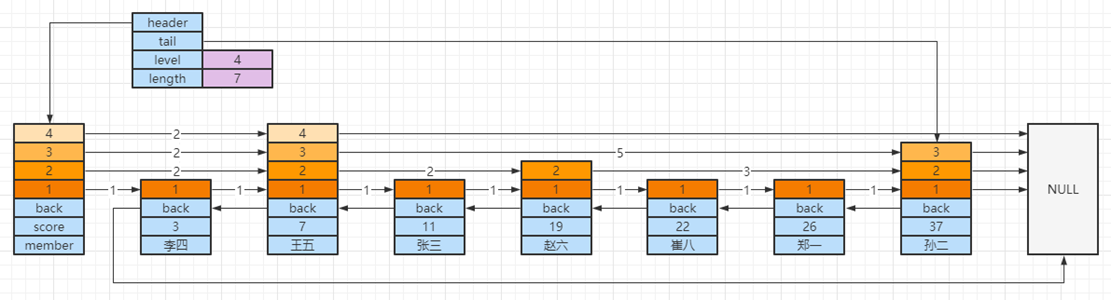

• 以查找【崔八】为例
a. 从顶层(4)层向右找到【王五】节点,22 > 7 继续向右找,但右侧是 NULL,下一层
b. 在【王五】节点的第 3 层向右找到【孙二】节点,22 < 37,下一层
c. 在【王五】节点的第 2 层向右找到【赵六】节点,22 > 19,继续向右找到【孙二】节点,22 < 37,下一层
d. 在【赵六】节点的第 1 层向右找到【崔八】节点,22 = 22,返回
注意
• 数据量较小时,不能体现跳表的性能提升,跳表查询的时间复杂度是 l o g 2 ( N ) log_2(N)log2(N),与二叉树性能相当
补:跳表查询
skiplist 查找要点,从顶层开始
右边的,继续向右
= 找到了
< 右边的或右边为 NULL,下一层,重复 1、2 步骤
以查找 score = 22 为例:
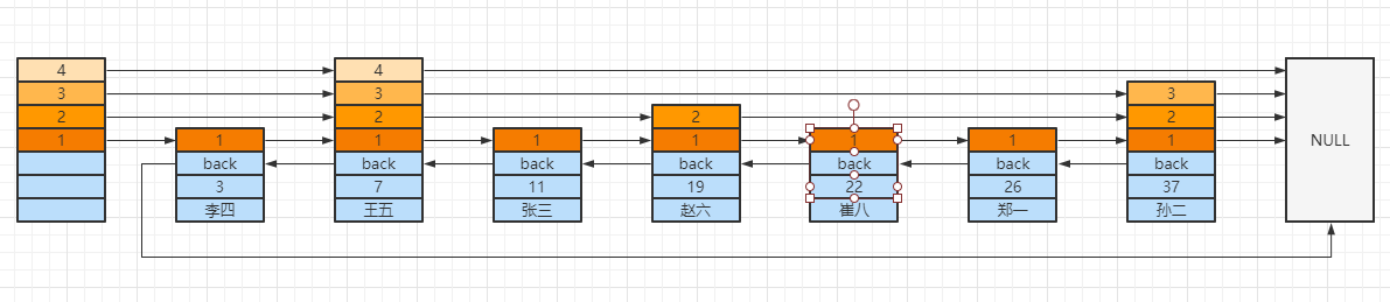
按照一层链表,我们找到 22 得查 5 次
跳表:先查第一层找到7 发现 7 的右边是null了,再从7 查第二层,右边是 37 比22 大,再从7下一层,下一个元素是19 ,19小于22,19的下一个是37,还得下一层,下一层的下一个就是22了,找到了
跳表查询的时间复杂度 l o g 2 n log_2nlog2n
3.5.3 应用场景
Zset 类型(Sorted Set,有序集合) 可以根据元素的权重来排序,我们可以自己来决定每个元素的权重值。比如说,我们可以根据元素插入 Sorted Set 的时间确定权重值,先插入的元素权重小,后插入的元素权重大。
在面对需要展示最新列表、排行榜等场景时,如果数据更新频繁或者需要分页显示,可以优先考虑使用 Sorted Set。
3.5.3.1 排行榜
有序集合比较典型的使用场景就是排行榜。例如学生成绩的排名榜、游戏积分排行榜、视频播放排名、电商系统中商品的销量排名等。
我们以博文点赞排名为例,发表了五篇博文,分别获得赞为 200、40、100、50、150。
# arcticle:1 文章获得了200个赞
> ZADD user:mengmeng:ranking 200 arcticle:1
(integer) 1
# arcticle:2 文章获得了40个赞
> ZADD user:mengmeng:ranking 40 arcticle:2
(integer) 1
# arcticle:3 文章获得了100个赞
> ZADD user:mengmeng:ranking 100 arcticle:3
(integer) 1
# arcticle:4 文章获得了50个赞
> ZADD user:mengmeng:ranking 50 arcticle:4
(integer) 1
# arcticle:5 文章获得了150个赞
> ZADD user:mengmeng:ranking 150 arcticle:5
(integer) 1
文章 arcticle:4 新增一个赞,可以使用 ZINCRBY 命令(为有序集合key中元素member的分值加上increment):
> ZINCRBY user:mengmeng:ranking 1 arcticle:4
"51"
查看某篇文章的赞数,可以使用 ZSCORE 命令(返回有序集合key中元素个数):
> ZSCORE user:mengmeng:ranking arcticle:4
"50"
获取文章赞数最多的 3 篇文章,可以使用 ZREVRANGE 命令(倒序获取有序集合 key 从start下标到stop下标的元素):
# WITHSCORES 表示把 score 也显示出来
> ZREVRANGE user:mengmeng:ranking 0 2 WITHSCORES
1) "arcticle:1"
2) "200"
3) "arcticle:5"
4) "150"
5) "arcticle:3"
6) "100"
获取 100 赞到 200 赞的文章,可以使用 ZRANGEBYSCORE 命令(返回有序集合中指定分数区间内的成员,分数由低到高排序):
> ZRANGEBYSCORE user:mengmeng:ranking 100 200 WITHSCORES
1) "arcticle:3"
2) "100"
3) "arcticle:5"
4) "150"
5) "arcticle:1"
6) "200"
3.5.3.2 电话、姓名排序
使用有序集合的 ZRANGEBYLEX 或 ZREVRANGEBYLEX 可以帮助我们实现电话号码或姓名的排序,我们以 ZRANGEBYLEX (返回指定成员区间内的成员,按 key 正序排列,分数必须相同)为例。
- 1、电话排序
我们可以将电话号码存储到 SortSet 中,然后根据需要来获取号段:
> ZADD phone 0 13100111100 0 13110114300 0 13132110901
(integer) 3
> ZADD phone 0 13200111100 0 13210414300 0 13252110901
(integer) 3
> ZADD phone 0 13300111100 0 13310414300 0 13352110901
(integer) 3
获取所有号码:
> ZRANGEBYLEX phone - +
1) "13100111100"
2) "13110114300"
3) "13132110901"
4) "13200111100"
5) "13210414300"
6) "13252110901"
7) "13300111100"
8) "13310414300"
9) "13352110901"
``
获取 132 号段的号码:
ZRANGEBYLEX phone [132 (133
- "13200111100"
- "13210414300"
- "13252110901"
获取132、133号段的号码:
``
> ZRANGEBYLEX phone [132 (134
1) "13200111100"
2) "13210414300"
3) "13252110901"
4) "13300111100"
5) "13310414300"
6) "13352110901"
- 2、姓名排序
> zadd names 0 Toumas 0 Jake 0 Bluetuo 0 Gaodeng 0 Aimini 0 Aidehua
(integer) 6
获取所有人的名字:
> ZRANGEBYLEX names - +
1) "Aidehua"
2) "Aimini"
3) "Bluetuo"
4) "Gaodeng"
5) "Jake"
6) "Toumas"
获取名字中大写字母A开头的所有人:
> ZRANGEBYLEX names [A (B
1) "Aidehua"
2) "Aimini"
获取名字中大写字母 C 到 Z 的所有人:
> ZRANGEBYLEX names [C [Z
1) "Gaodeng"
2) "Jake"
3) "Toumas"
3.6、BitMap
Bitmap,即位图,是一串连续的二进制数组(0和1),可以通过偏移量(offset)定位元素。BitMap通过最小的单位bit来进行0|1的设置,表示某个元素的值或者状态,时间复杂度为O(1)。
由于 bit 是计算机中最小的单位,使用它进行储存将非常节省空间,特别适合一些数据量大且使用二值统计的场景。
3.7、HyperLogLog
Redis HyperLogLog 是 Redis 2.8.9 版本新增的数据类型,是一种用于「统计基数」的数据集合类型,基数统计就是指统计一个集合中不重复的元素个数。但要注意,HyperLogLog 是统计规则是基于概率完成的,不是非常准确,标准误算率是 0.81%。
所以,简单来说 HyperLogLog 提供不精确的去重计数。
HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的内存空间总是固定的、并且是很小的。
3.8、Stream
Redis Stream 是 Redis 5.0 版本新增加的数据类型,Redis 专门为消息队列设计的数据类型。
在 Redis 5.0 Stream 没出来之前,消息队列的实现方式都有着各自的缺陷,例如:
• 发布订阅模式,不能持久化也就无法可靠的保存消息,并且对于离线重连的客户端不能读取历史消息的缺陷;
• List 实现消息队列的方式不能重复消费,一个消息消费完就会被删除,而且生产者需要自行实现全局唯一 ID。
基于以上问题,Redis 5.0 便推出了 Stream 类型也是此版本最重要的功能,用于完美地实现消息队列,它支持消息的持久化、支持自动生成全局唯一 ID、支持 ack 确认消息的模式、支持消费组模式等,让消息队列更加的稳定和可靠。
3.9、其他
3.9.1 Redis 数据结构相关命令操作
内容过多,参考另一篇博文:https://blog.csdn.net/weixin_45525272/article/details/126554248
3.9.2 set与zset区别
set:
• 集合中的元素是无序、不可重复的,一个集合最多能存储232-1个元素;
• 集合除了支持对元素的增删改查之外,还支持对多个集合取交集、并集、差集。
zset:
• 有序集合保留了集合元素不能重复的特点;
• 有序集合会给每个元素设置一个分数,并以此作为排序的依据;
• 有序集合不能包含相同的元素,但是不同元素的分数可以相同。
3.9.3 Redis中的watch命令
很多时候,要确保事务中的数据没有被其他客户端修改才执行该事务。Redis提供了watch命令来解决这类问题,这是一种乐观锁的机制。客户端通过watch命令,要求服务器对一个或多个key进行监视,如果在客户端执行事务之前,这些key发生了变化,则服务器将拒绝执行客户端提交的事务,并向它返回一个空值.
说说Redis中List结构的相关操作
列表是线性有序的数据结构,它内部的元素是可以重复的,并且一个列表最多能存储232-1个元素。列表包含如下的常用命令:
| 命令 | 说明 |
|---|---|
| lpush/rpush | 从列表的左侧/右侧添加数据; |
| lrange | 指定索引范围,并返回这个范围内的数据; |
| lindex | 返回指定索引处的数据; |
| lpop/rpop | 从列表的左侧/右侧弹出一个数据; |
| blpop/brpop | 从列表的左侧/右侧弹出一个数据,若列表为空则进入阻塞状态 |
4、Redis原理解析
4.1、redis 总体架构
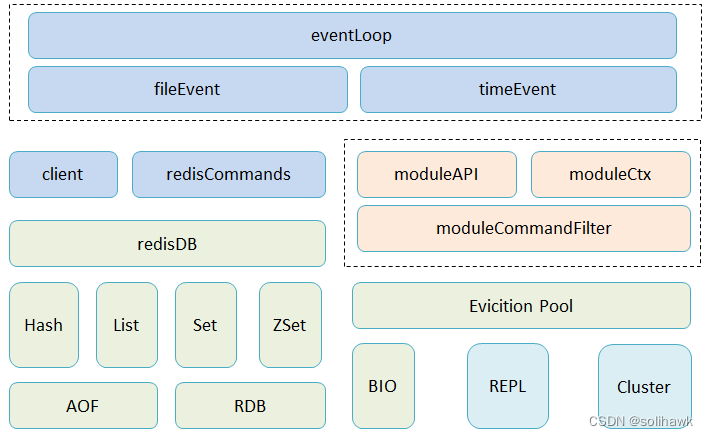
Redis组件的系统架构包括事件处理、数据存储及管理、用于系统扩展的主从复制及集群管理以及插件化扩展模块:
- 事件处理模块:利用AE事件驱动模型,进行高效的IO读写、命令执行以及时间事件处理,其中IO读写采用的是IO多路复用技术,后面会进行专项介绍
- 数据管理模块:Redis内存数据存放在redisDB中,支持多种数据类型以key/value的形式存放在字典中;内存中的数据会持久化到磁盘,支持RDB和AOF两种方式
- 集群扩展模块:Redis单节点扩展到集群有三种方式,包括主从模式、哨兵模式和集群模式
4.2、Redis的IO模型

1)非阻塞IO
在调用Socket读写方法时,默认都是阻塞的,比如Read方法传递个参数表示读取这么多字节后返回,如果没有读够线程会卡在那里,直到新的数据到来或者连接关闭,read方法才可以返回,线程才能继续处理。一般Write方法不会阻塞,除非写缓冲区写满会阻塞,直到缓存区空闲。非阻塞IO在Socket对象上会设置Non_Blocking选项,打开时读写都不会阻塞,读写的数量取决于分配的缓存区的空余大小。
2)I/O多路复用封装
I/O多路复用其实是在单个线程中通过记录跟踪每个I/O流的状态来管理多个I/O流。在Redis中提供了select、epoll、evport、kqueue几种选择,利用其可以同时监察多个流的I/O事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有I/O事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。
3)事件驱动轮询
事件轮询API用来解决读写不知道何时继续的问题,输入是读写描述符列表,输出是与之对应的可读可写事件,同时提供一个timeout参数。如果没有事件到来,最多等待timeout时间,线程处于阻塞状态,一旦期间有任何事件到来就可以立即返回,超过timeout时间没有事件到来也会立即返回。等到事件后,线程可以继续挨个处理相应的请求,处理完继续轮询。
4.3、Redis的IO模型
4.3.1 Redis持久化
Redis的数据保存在内存中,如果出现宕机数据会全部丢失,因此需要一种机制来保证数据不丢失,这种机制称为Redis持久化。Redis持久化机制有两种:快照和AOF日志
快照:全量备份,内存数据的二进制序列化形式
AOF日志:连续的增量备份,记录内存数据修改的指令记录文本。AOF日志在运行过程中变得非常庞大,Redis重启的时候需要加载AOF日志进行重放,这个时间就会变得很长,因此需要定期对AOF日志进行重写
4.3.2 RDB快照
RDB是Redis默认的持久化方法,按照一定的策略把Redis内存中的数据保存为RDB文件,RDB文件是内存数据的二进制序列化表示。Redis提供了两个命令执行持久化操作生成RDB文件:save和BGsave
Save命令:执行的时候会阻塞Redis服务器进程,执行过程中Redis服务不能处理其它请求
BGSave命令:执行时候会派生出folk子进程,由folk子进程完成RDB文件的创建,父进程继续完成其它的响应
众所周知,Redis是单线程程序,当在处理客户端请求的同时进行内存快照的时候,生成内存快照的过程中的IO操作会影响服务器的请求性能。持久化的同时,内存中的数据也在不断的变化,此时是无法通过单线程在一边接收业务请求的同时处理的。在Redis中引入了操作系统的COW(copy-on-write)机制来实现,在持久化的时候调用folk子进程完成持久化操作,而父进程继续响应服务请求。根据COW的机制,内存中的数据会被复制一份出来,子进程在做数据持久化的时候,不会修改现有的内存数据结构,只是对数据结构进行遍历读取,然后序列化写到磁盘中。
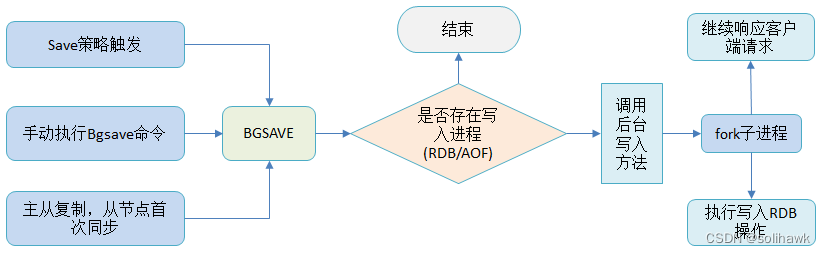
- 优点:
只生成一个文件,方便持久化
容灾性好,持久化文件可以安全保存
性能最大化,fork子进程来完成写操作,让主进程继续处理命令,所以是 IO 最大化 - 缺点:
RDB快照生成期间出现故障,会导致数据丢失几分钟
生成快照期间如果文件很大,可能会影响客户端响应,对于秒杀等时效性要求高的业务影响较大
4.3.3 AOF日志
AOF(Append-only file)持久化是将Redis服务器所指向的写指令保存下来,记录对内存修改的指令记录。Redis在收到客户端修改指令后,先进行参数校验,如果没问题立即将该指令保存到本地AOF日志中,再执行指令。当Redis重启的时候,通过重新执行文件中AOF日志中的指令恢复内存中的数据。
Redis服务在执行AOF任务时候,会调用flushAppendOnlyFile函数,这个函数执行以下任务:
WRITE:根据条件,将aof_buf中的缓存写入到AOF文件
SAVE:根据条件,调用fsync或fdatasync函数,将AOF文件保存到磁盘中
AOF保存到磁盘中也有三种方式,根据性能需要选择,默认是每秒fsync一次
appendfsync always:收到写命令就立即写入磁盘,最慢,但是保证完全的持久化
appendfysnceverysec:每秒钟写入磁盘一次,在性能和持久化方面做了很好的折中
appendfysnc no:完全依赖os,持久化没保证
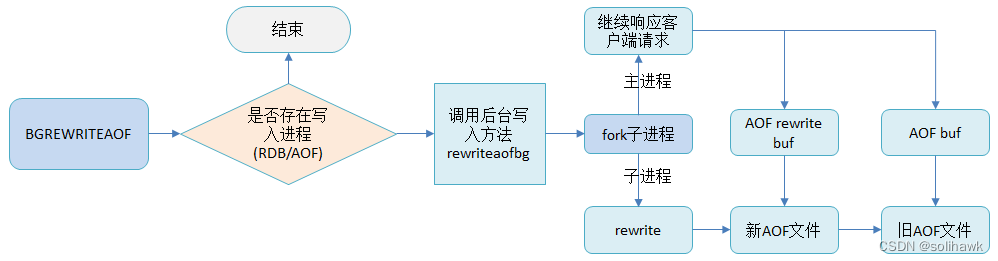
AOF有个问题是在Redis长期运行过程中,AOF日志会变得越来越大,如果宕机重启,整个重放日志的过程非常耗时。为此Redis提供bgrewriteof指令用于对AOF日志进行瘦身,原理是开辟一个子进程对内存进行遍历转换成一系列的Redis操作指令,然后序列化到新的AOF日志文件中。序列化完毕后再将操作期间发生的增量AOF日志追加到这个新的AOF日志文件中,追加完毕后替换旧的AOF日志文件。
AOF持久化的方式相较于快照数据安全性得到保证,但是同等业务下AOF日志文件要比RDB大,同时fsync的操作会影响性能,在开启AOF后Redis支持的APS要比RDB条件下的低。通常在集群架构下,主节点不会开启持久化操作,而是在从节点进行,因为从节点是备份节点,没有客户端请求压力,操作系统资源也相对充沛,对业务影响较小。
4.3.4 Redis事务与一致性
Redis中的事务可以一次执行多个指令,所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
4.3.4.1 Redis事务的实现
在Redis中由几个特殊的指令实现事务:MULTI、EXEC、WATCH、DISCARD
MULTI:表示事务的开始,在redis中执行这条语句以后,表示事务的开启,这个时候,所输入的命令并不会立马执行下去,相反,在未出现EXEC特殊字符时候,所有命令的执行都会进入一个队列中。
EXEC:表示对进入到队列的语句进行一个执行操作,执行的是先进先出的原则。
WATCH:表示监听,可以监听一个或多个健,是一个乐观锁,一旦其中有一个键被修改(或删除),之后的事务就不会执行,监控一直持续到EXEC命令
DISCARD:表示清空事务队列,前面我们提到了事务在未被执行的过程中,都会进入到一个队列中,此条操作就会情况事务队列,并放弃执行事务。
> multi
OK
> SET “NAME” “REDIS THEORY”
QUEUED
> SET “author” “San”
QUEUED
> exec
1) OK
2) OK

如上图所示,输入MULTI命令,输入的命令都会依次进入命令队列中,但不会执行。直到输入Exec后,Redis会将之前的命令队列中的命令依次执行。命令队列的过程中可以使用命令DISCARD来放弃队列运行。
4.3.4.2 Redis事务与ACID
事务的ACID指的是原子性、一致性、隔离性和持久性
原子性(Atomicity):原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
一致性(Consistency):事务前后数据的完整性必须保持一致。
隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行
持久性(Durability):持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响
在开发Redis时选用更加简单和快速的方法,不支持事务回滚功能,所以在Redis中事务失败的时候不进行回滚,而是继续执行余下的命令。所以如果一个事务中的命令出现错误,所有的命令都不会执行,但是如果出现运行错误,正确的命令会被执行。
Redis事务没有隔离级别概念:所有的命令在事务中,并没有直接被执行,只有发起执行命令的时候才会执行
Redis是单线程执行,当前事务的执行不会被其它事务干扰,满足事务的隔离性
Redis事务单条指令保持原子性,但是事务不保持原子性。虽然Redis不支持事务回滚机制,但是它会检查每一个事务中的命令是否错误
因此在Redis中事务总能保证ACID中的一致性和隔离性。
4.3.5 Redis内存管理
Redis作为内存数据库,时常会存储大量的数据,即使采取了集群部署来动态扩容,也应该及时的整理内存,维持系统性能。
4.3.5.1 为数据设置超时时间
Redis所有数据结构都可以设置过期时间,时间一到就会自动删除。如果没有设置时间,那缓存就是永不过期;如果设置了过期时间,之后又想让缓存永不过期使用persist key
//设置过期时间
expire key time(以秒为单位)--这是最常用的方式
setex(String key, int seconds, String value) --字符串独有的方式
注:除了字符串独有设置过期时间的方法外,其他方法都需要依靠 expire 方法来设置时间
1)过期的key集合
Redis会将每个设置了过期时间的Key放入到一个独立的字典中,之后会定时遍历这个字典来删除到期的key。除了定时遍历,还会使用惰性策略来删除过期的Key,所谓的惰性策略就是在客户端访问这个key的时候,Redis会对key进行检查,如果过期了就删除。
2)定时扫描策略
Redis默认每秒进行10次过期key的扫描,每次扫描不会遍历字典中的所有key,而是按照如下策略:
从过期字典中随机选择20个key;
删除这20个key中已经过期的数据
如果过期的key的比重超过1/4则重复步骤a)
另外,为了保证过期扫描不会出现过度循环,导致线程卡死,算法增加了扫描时间上限,默认是25ms。当出现大量的key设置相同的过期时间的时候,则会出现连续扫描导致读写请求出现明显的卡顿。因此,对于一些活动系统中可能会出现大量数据过期的,应为key的过期时间设置一个随机数,不能在同一时间内过期。
3)从库的过期策略
从库不会进行过期扫描,从库对过期的处理是被动的。主库在key到期的时候,会在AOF文件中增加一条del指令,这条指令同步到所有的从库后,从库通过执行这条del指令来删除过期的key。当然,从库同步的过程是异步的,会出现主库已经删除而从库中数据尚存在的情况,出现主从数据不一致。
4.3.5.2 内存淘汰策略
定时删除能够释放内存,却非常消耗CPU,尤其是在大并发的情况下。配合惰性删除,在访问某个key时检查是否过期,能够及时的释放内存。但是根据定时删除的策略会存在没有及时的删除key,而这些key又没有被及时的访问到,也就是惰性删除也没有生效,导致Redis的内存越来越高。因此,需要内存的淘汰策略,及时的释放内存。
在Redis中提供了配置参数maxmemory来限制内存超出期望大小,当超出时根据不同的策略释放空间继续提供服务:
noeviction:不会继续服务写请求 (DEL请求可以继续服务),读请求可以继续进行。这样可以保证不会丢失数据,但是会让线上的业务不能持续进行。这是默认的淘汰策略。
volatile-lru:尝试淘汰设置了过期时间的key,根据LRU算法最少使用的key优先被淘汰。没有设置过期时间的key不会被淘汰,这样可以保证需要持久化的数据不会突然丢失。
volatile-ttl:淘汰的策略为key的剩余寿命ttl的值,ttl越小越优先被淘汰。
volatile-random:淘汰的key是过期key集合中随机的key。
allkeys-lru:区别于volatile-lru,淘汰的key对象是全体的key集合,而不只是过期的key集合。这意味着没有设置过期时间的key也会被淘汰。
allkeys-random:所有的key随机删除
4.3.5 Redis缓存雪崩、击穿和穿透
4.3.5.1 缓存雪崩
1)现象:Redis中的数据设置了过期时间,当缓存的数据过期后,缓存同一时间大面积的失效,导致用户访问的数据不在缓存中,前端的请求都落到后端的数据库,造成数据库短时间内承受大量的请求而奔溃,这就是缓存雪崩的问题。
2)解决方法:缓存雪崩是因为访问的数据不在缓存中,因此要避免短时间内所有的key都失效,有以下方法
将缓存数据的过期时间设置为随机,防止同一时间出现大量数据过期
使用互斥锁进行排队和限流,通过加锁或者队列来控制读数据库写缓存的线程数量,但是这样会影响吞吐
数据预热,通过缓存reload机制,预选去更新缓存,再即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀
4.3.5.2 缓存击穿
1)现象:当缓存中的热点数据过期后,如果有大量的请求访问该热点数据,此时客户端发现环境数据过期然后从后端数据库访问数据,数据库由于高并发的访问请求奔溃。
2)解决方法:
互斥锁方案:对缓存查询加锁,如果KEY不存在,就加锁,然后查DB入缓存,然后解锁;其他进程如果发现有锁就等待,然后等解锁后返回数据或者进入DB查询
设置热点数据不过期:将热点数据一直保留在缓存中不过期
4.3.5.3 缓存穿透
1)现象:当业务访问的数据不存在,既不在缓存中也不在数据库中,导致请求访问缓存时发现数据不存在再去访问数据库,数据库中也没有想要的数据,无法构建缓存。每次查询都要访问后端数据库层,失去了缓存的意义,也就是缓存穿透的问题。
2)解决方法:
接口层增加校验:当有大量恶意请求访问不存在的数据时,也会发送缓存穿透。因此在接口处判断请求的参数是否合理、是否含有非法值,如果不合法直接返回
缓存空值或默认值:当业务访问的数据不存在时,可以针对查询的数据在缓存中设置一个空值或者默认值,这样后续请求就可以从缓存中读取到空值或者默认值,返回给应用,而不会继续查询数据库
使用布隆过滤器在数据写入数据库时做个标记,业务线程确认缓存失效后,可以通过查询布隆过滤器快速判断数据是否存在,如果不存在,则不需要访问数据库。
5、Redis集群架构
5.1 主从模式
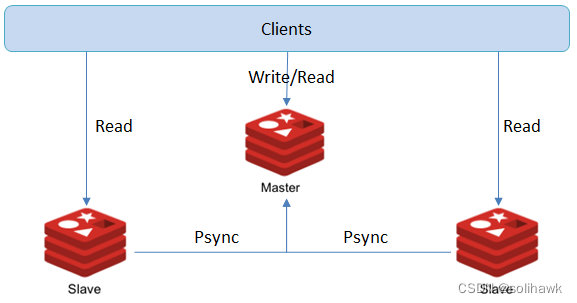
主从复制模式包括一个Master与一个或多个Slave,客户端对主节点进行读写操作,对从节点进行读操作,主节点写入的数据会实时的同步到从节点。
5.1.1 主从复制模式工作机制
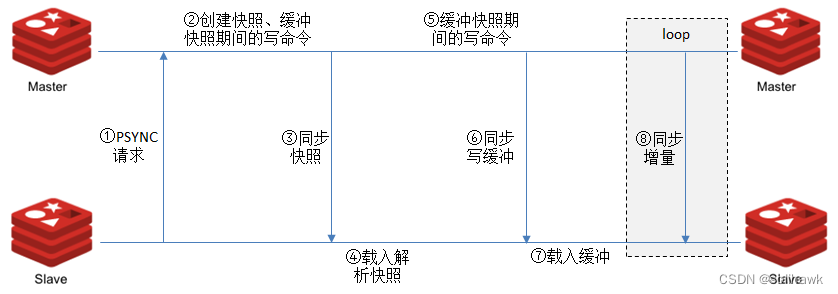
主从复制模式包括快照同步和增量同步两个过程,具体工作机制如下:
slave启动后,向master发送SYNC命令,master接收到SYNC命令后通过bgsave保存快照,并使用缓冲区记录保存快照这段时间内执行的写命令。
master将保存的快照文件发送给slave,并继续记录执行的写命令。
slave接收到快照文件后,加载快照文件,载入数据。
master快照发送完后开始向slave发送缓冲区的写命令,slave接收命令并执行,完成复制初始化。
此后mster每次执行一个写命令都会同步发送给slave完成增量同步,保持master与slave之间数据的一致性。
5.1.2 主从模式优缺点
1)主从复制的优点
- master能自动将数据同步到slave,可以进行读写分离,分担master的读压力
- master、slave之间的同步是以非阻塞的方式进行的,同步期间,客户端仍然可以提交查询或更新请求
2)主从复制的缺点
- 不具备自动容错与恢复功能,master或slave的宕机都可能导致客户端请求失败,需要等待机器重启或手动切换客户端IP才能恢复
- master宕机,如果宕机前数据没有同步完,切换到slave后会存在数据不一致的问题。
- 难以支持在线扩容,redis的容量受限于单机配置
- 快照同步非常的消耗资源,需要在master节点将内存数据快照到磁盘文件中,再将文件传送到slave节点加载,整个过程费时并且资源开销大
- 同步过程中内存中保存增量的修改记录指令的buffer是有限的,可能会出现写入的指令过多而未及时同步到slave节点的情况发生
5.2 哨兵sentinel模式
主从复制不具备自动恢复能力,当发生故障时需要手动进行主从切换。为此引入了哨兵模式,当发生故障时可以自动进行主从切换。
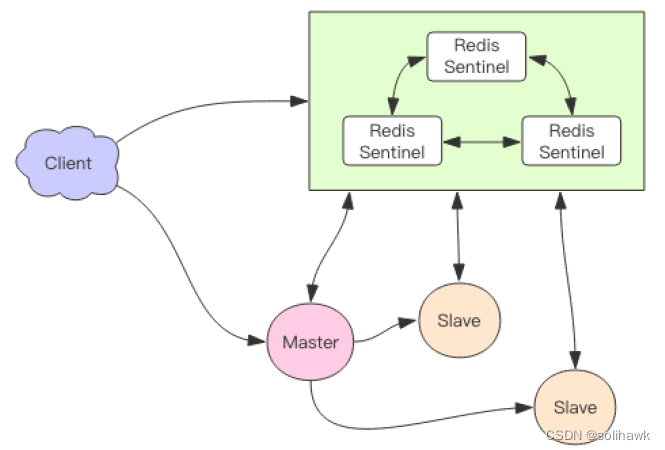
5.2.1 哨兵主要功能
Redis Sentinel类似于Zookeeper集群,由3~5节点组成,负责监控主从节点的健康状态,一旦发现问题能够及时处理。主要功能如下:
监控master和slave运行是否正常
当master出现故障时,能够自动切换到slave节点
多个哨兵可以监控同一个redis,哨兵之间也会自动监控
客户端连接Redis集群时,会首先连接sentinel,通过sentinel来查询主节点的地址,然后再去连接主节点进行数据交互。当主节点发生故障时,客户端会重新向sentinel要地址,sentinel会将最新的主节点地址告诉客户端。如此应用程序将无需重启即可自动完成节点切换。
5.2.2 哨兵工作机制
哨兵与master建立连接后,会执行三个操作:
定期向master和slave发送INFO命令。(注:一般10s一次,当master被标注为主动下线时,改为1s一次)。
通过INFO命令,哨兵可以获取主从数据库的最新信息,并进行相应的操作,比如角色变更等
定期向master和slave的_sentinel_:hello频道发送自己的信息。
其他哨兵可以通过该信息判断发送者是否是新发现的哨兵,如果是的话会创建一个到该哨兵的连接用于发送PING命令。
其他哨兵通过该信息可以判断master的版本,如果该版本高于直接记录的版本,将会更新。
当实现了自动发现slave和其他哨兵节点后,哨兵就可以通过定期发送PING命令定时监控这些数据库和节点有没有停止服务。
定期(1s一次)向master、slave和其他哨兵发送PING命令。
PING某个节点超时后,哨兵认为其主观下线
如果下线的是master,哨兵会向其它哨兵发送命令询问是否认为该master主观下线sdown。
如果达到一定数目的投票,则会认为该master已经客观下线odown,并选举领头的哨兵对主从节点发起故障恢复
如果没有足够的哨兵同意master下线,则客观下线状态会被解除;如果master此时回复了哨兵的PING请求,则主观下线状态也会被解除
5.2.3 哨兵模式故障恢复
以下图中master节点异常,原先的主从复制断开,slave节点被提升为新的master节点,其它slave节点和新的master节点建立复制关系。客户端通过新的master节点进行交互。
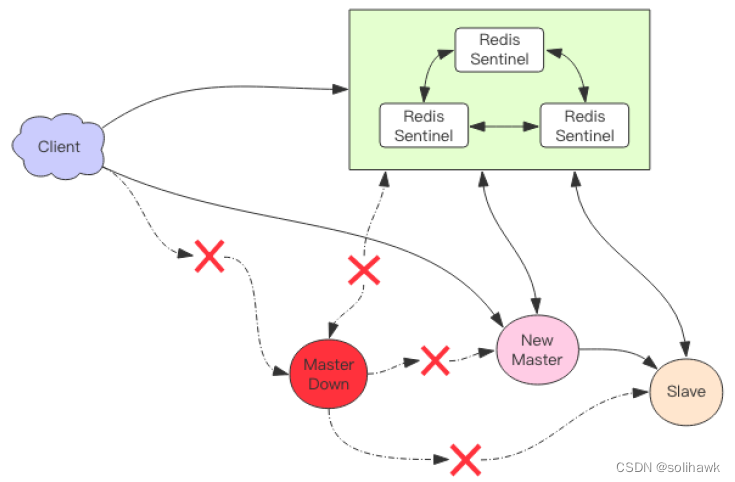
1)哨兵领头羊选举,采用Raft算法
- 发现master下线的哨兵节点A向每个哨兵发送命令,要求对方选自己为领头哨兵。
- 如果目标哨兵节点没有选其他人,则会同意选举A为领头哨兵。
- 如果有超过一半的哨兵同意选举A为领头,则A当选。
- 如果有多个哨兵节点同时参选领头,此时有可能存在一轮投票无竞选者胜出,此时每个参选的节点等待一个随机时间后再次发起参选请求,进行下一轮投票竞选,直至选举出领头哨兵。
2)哨兵对系统进行故障恢复
- 从所有在线的slave中选择优先级最高的,优先级可以通过slave-priority配置。
- 如果有多个最高优先级的slave,则选取复制偏移量最大(即复制越完整)的当选。
- 如果以上条件都一样,选取id最小的slave。
- 选举完成后,领头的哨兵将选举出来的slave升级为master,然后向其它slave发送命令接受新的master,最后更新数据
- 旧的master节点变为slave节点,恢复服务后以slave身份继续运行
5.2.4 哨兵模式优缺点
1)哨兵模式的优点
基于主从复制实现,继承了主从复制的优点
哨兵模式下,master节点异常后可以进行自动切换,系统可用性更高
2)哨兵模式的缺点
master宕机,如果宕机前数据没有同步完,切换到slave后会存在数据不一致的问题。
难以支持在线扩容,redis的容量受限于单机配置
哨兵模式下slave节点不提供服务
需要额外的资源来启动sentinel进程,实现相对复杂一点
5.3 Cluster集群模式
哨兵模式依然存在难以在线扩容的问题,为此引入了Cluster集群模式。Cluster模式采用去中心化的结构,实现Redis的分布式存储,每台节点存储不同的内容,解决在线扩容的问题。
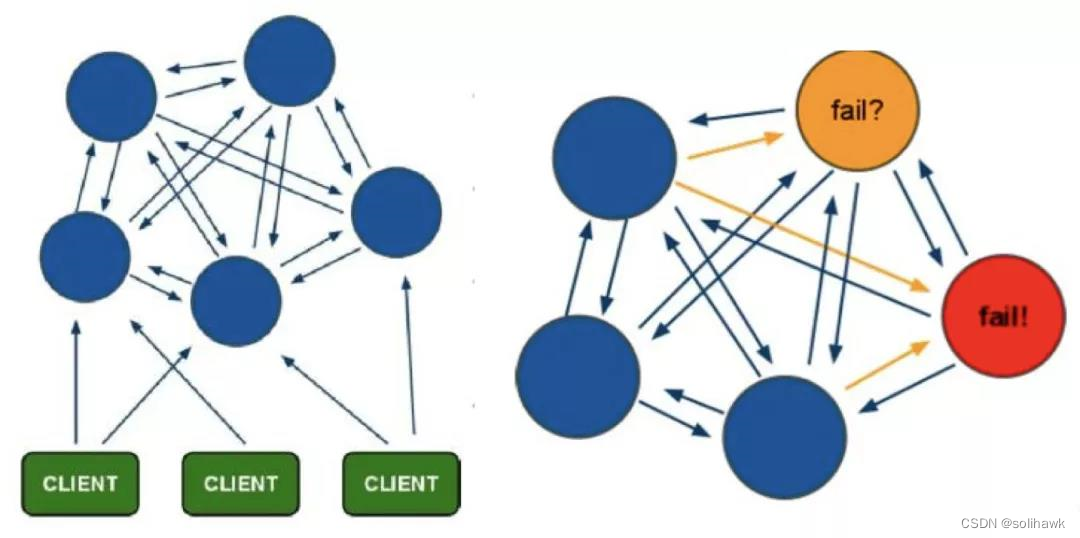
5.3.1 Cluster模式工作机制
1)Cluster采用无中心结构,它的特点如下:
所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
节点的fail是通过集群中超过半数的节点检测失效时才生效。
客户端与redis节点直连,不需要中间代理层,客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
2)Cluster模式的具体工作机制:
在redis的每个节点上,都有一个插槽(slot),取值范围0-16383。
当我们存取key的时候,redis会根据CRC32的算法得出一个结果,然后把结果对16384求余数,这样每个key都会对应一个编号在0-16383之间的哈希槽,通过这个值,去找到对面的插槽所对应的节点,然后直接自动跳转到这个插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作。
为了保证高可用,Cluster模式也引入主从复制模式,一个主节点对应一个或者多个从节点,当主节点宕机的时候,就会启用从节点。
当其他主节点PING一个主节点A时,如果半数以上的主节点与A通信超时,那么认为主节点A宕机了。如果主节点A和它的从节点都宕机了,那么该集群就无法再提供服务了。
Cluster模式集群节点最小配置6个节点(3主3从,因为需要半数以上),其中主节点提供读写操作,从节点作为备用节点,不提供请求,只作为故障转移使用。
5.3.2 Cluster模式优缺点
1)Cluster模式优点
无中心架构,数据按照slot分布在多个节点。
集群中的每个节点都是平等的关系,每个节点都保存各自的数据和整个集群的状态。每个节点都和其他所有节点连接,而且这些连接保持活跃,这样就保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据。
可线性扩展到1000多个节点,节点可动态添加或删除。
能够实现自动故障转移,节点之间通过gossip协议交换状态信息,用投票机制完成slave到master的角色转换。
2)Cluster模式缺点
客户端实现复杂,驱动要求实现Smart Client,缓存slot mapping信息并及时更新,提高了开发难度,目前仅JedisCluster相对成熟,异常处理还不完善,比如常见的“max redirect exception”。
节点会因为某些原因发生阻塞(阻塞时间大于cluster-node-timeout)被判断下线,这种failover是没有必要的。
数据通过异步复制,不保证数据的强一致性。
slave充当“冷备”,不能缓解读压力。
批量操作限制,目前只支持具有相同slot值的key执行批量操作,对mset、mget、sunion等操作支持不友好。
key事务操作支持有线,只支持多key在同一节点的事务操作,多key分布不同节点时无法使用事务功能。
不支持多数据库空间,单机redis可以支持16个db,集群模式下只能使用一个,即db 0。
6、Redis单线程
6.1 redis为何是单线程
官方给出的答案:
因为 Redis 是基于内存的操作,CPU 不会成为 Redis 的瓶颈,而最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且 CPU 不会成为瓶颈,那就顺理成章地采用单线程的方案了
具体原因:
- 不需要性能消耗的锁
redis 的 List,Hash 等复杂的数据类型,可能会进行细粒度的操作,如添加或者删除元素操作可能需要加锁,导致增加性能开销
2)单线程多进程集群方案
多线程比单线程有更高的性能,单机多线程也不一定能满足所有场景,此时需要多服务集群化,而多服务集群化中多线程可能用不上 - CPU消耗
采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU
6.2 如何理解redis的单线程
redis的单线程不是指redis只会有一个线程,而是指redis处理请求(增删改查)时只会使用一个线程去执行
redis在执行其他操作的时候,可能会开启多个进程或线程,如持久化:redis执行BGSAVE指令,进行快照持久化时,就会fork出一个子进程,然后子进程去创建快照,完成持久化操作
redis单线程的基本模型:
redis 客户端对服务端的每次调用都会经历发送命令,执行命令,返回结果三个过程
redis 是单线程来处理命令的,所有到达服务端的命令都不会立刻执行,所有的命令都会进入一个队列中,然后逐个执行,并且多个客户端发送的命令的执行顺序是不确定的,但是不会有两条命令同时执行,不会产生并发问题
6.3 单线程的redis为何高并发快
-
基于内存
内存读写相比磁盘读写少了磁盘I/O -
单线程
redis是单线程的,单线程减少了上下文切换和竞争锁的消耗,同时保证了原子性 -
I/O多路复用
I/O多路复用技术可以让单个线程高效的处理多个连接请求,redis使用epoll作为I/O多路复用技术的实现。redis自身的事件处理模型将epoll中的连接、读写、关闭都转换为事件,不在网络I/O上浪费过多的时间 -
高效的数据结构和合理的数据编码
redis基于不同的数据类型在底层使用了不同的数据结构,且redis对每种数据类型在底层使用多种不同的数据结构。不同场景下使用不同的数据结构和不同的编码
String:存储数字使int类型的编码;存储小于等于39Byte的字符串使用embstr编码;大于39Byte的字符串使用aw编码
List:元素个数小于512且元素的值都小于64Byte(默认),使用ziplist编码;否则使用linkedlist编码
Hash:素个数小于512且所有值小于6464Byte使用ziplist编码;否则使用hashtable编码
Set:元素都是整数且元素个数小于512使用intset编码;否则使用hashtable编码
Zset:元素个数小于128且每个元素的值小于64Byte使用ziplist编码;否则使用skiplist编码 -
虚拟内存机制
redis自己构建了VM机制 ,不会像一般的系统会调用系统函数处理,会浪费一定的时间去移动和请求
redis会暂时把不经常访问的数据(冷数据)从内存交换到磁盘中,从而腾出宝贵的内存空间用于其它需要访问的数据(热数据),通过VM功能可以实现冷热数据分离,使热数据仍在内存中、冷数据保存到磁盘
redis常见问题
资料:
https://blog.csdn.net/qq_52143183/article/details/127710841
https://blog.csdn.net/solihawk/article/details/127484669
https://blog.csdn.net/qq_36404307/article/details/128355638
https://developer.aliyun.com/article/1346858
https://blog.csdn.net/javadocdoc/article/details/109402960
https://www.zhihu.com/tardis/bd/art/487583440?source_id=1001

 浙公网安备 33010602011771号
浙公网安备 33010602011771号