VIM-灰常有用的正则匹配
一、VIM,GVIM中正则匹配的用处
VIM的一个强大之处就在于其文本搜索、匹配的能力,可用于替换、删除、查找等,极大提升用户的文本编辑效率,写代码必备技能。
二、常用的匹配字符
大体上可以分为四类,字符的匹配、数量的匹配(也可理解为匹配次数)、位置的匹配(开头、结尾等),和特殊字符的匹配。
2.1 字符的匹配
常用的字符匹配如下表:
| 字符 | 含义 |
|---|---|
| . | 匹配任意字符 |
| [xxx] | 匹配方括号中的任意字符 |
| [^xxx] | 匹配除了方括号内字符以外的任意字符 |
| \d | 匹配任意数字,相当于[0-9] |
| \D | 匹配除了数字以外的任意字符,相当于[^0-9] |
| \l | 匹配字母a-z |
| \L | 匹配字母a-z以外的其他字符 |
| \u | 匹配字母A-Z |
| \U | 匹配字母A-Z以外的其他字符 |
| \x | 匹配十六进制数,相当于[0-9a-fA-F] |
| \X | 匹配十六进制数以外的字符,相当于[^0-9a-fA-F] |
| \w | 匹配任意word,简单来说就是任意数字、字母组成的一个无空白字符的字符串,两个字符串中间有空白字符的会被认为是两个word |
| \s | 匹配空白字符,会将空格和tab都匹配到 |
| \S | 匹配空白字符以外的字符 |
| \t | 匹配tab字符 |
2.2 数量的匹配(匹配次数)
一般格式是“字符匹配pattern次数匹配pattern”,表示将符合字符匹配pattern的字符匹配次数pattern次。注意使用时下表中除 * 外其他的前边的反斜杠不要丢掉。
| 字符 | 含义 |
|---|---|
| * | 匹配任意多次 |
| \? | 匹配0-1次 |
| \+ | 匹配1-任意多次 |
| \'{n,m}' | 匹配n-m次 |
| \'{n}' | 匹配n次 |
| \'{n,}' | 匹配n到任意次 |
| \'{,n}' | 匹配0-n次 |
| 注:实际使用时花括号两侧的单引号不用打,这里是markdown的问题,不打单引号啥都显示不出来。 |
2.3 匹配位置
指明匹配的位置,一般就行首行位词头词尾,要注意位置匹配时看清楚有没有空格,比如不要匹配行首时默认忽略了开头的空白字符从而导致匹配失败。
| 字符 | 含义 |
|---|---|
| ^ | 匹配行首 |
| $ | 匹配行尾 |
| \< | 匹配词首 |
| \> | 匹配词尾 |
2.4特殊字符
有一些字符因为本身具有特殊含义,上边基本也都提到了,所以在匹配这些字符时要加反斜杠。
| 字符 | 含义 |
|---|---|
| \. | 匹配字符“.” |
| \* | 匹配字符“*” |
| \$ | 匹配字符“$” |
| \ [ | 匹配字符“[”,字符“]”同理,但是若直接匹配“[”和"]"也可以匹配到,加反斜杠一般用于和2.1中匹配方括号内任意字符的情况区分开 |
| \{ | 同上 |
| \ / | 匹配字符“/”, 字符“\”同理 |
三、小练习
这里我们用vim的底行搜索举几个例子。
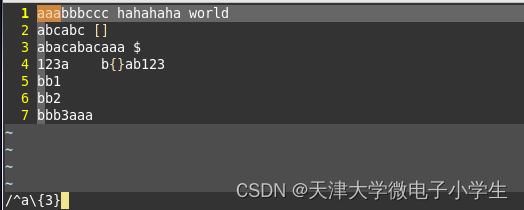
1.匹配开头是“aaa”的

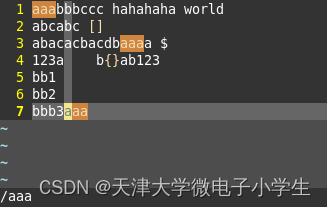
2.只匹配“aaa”
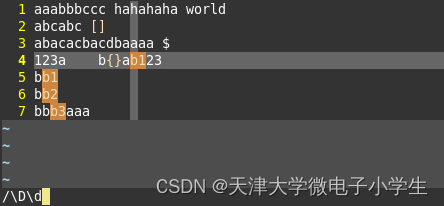
3.匹配一个字母加一个数字
4.匹配拥有四个"ha"的单词(圆括号字符分组)
这里用到了圆括号字符分组的方法,将ha看做一个整体,匹配满足次数的单词。
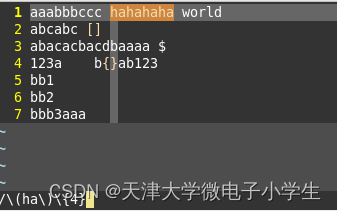
上图的匹配模式为:将ha看做整体,匹配四次
比如我不知道我想找的单词里有多少次ha,呢么也可以按照下面的办法来。
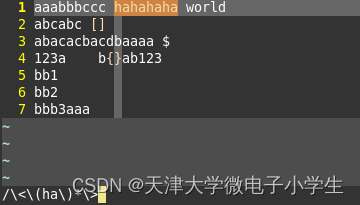
上图的正则匹配式的含义是:匹配以ha开头,ha匹配任意多次,词尾也是ha的。
小结
vim中正则匹配的用处很多,如搜索、替换、删除、文本提取(见上篇文章: https://blog.csdn.net/weixin_43655109/article/details/133213974 )等等,用好的话可以大大提高工作效率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号