
数据采集与融合技术作业3
作业1
指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取。
核心代码
单线程:
点击查看代码
def crawl_page(self, url):
"""爬取单个页面"""
if url in self.visited_pages or len(self.visited_pages) >= self.max_pages:
return
print(f"正在爬取页面: {url}")
self.visited_pages.add(url)
try:
response = self.session.get(url, timeout=10)
response.raise_for_status()
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
# 查找所有图片
img_tags = soup.find_all('img')
for img in img_tags:
if self.downloaded_count >= self.max_images:
break
img_src = img.get('src')
if img_src:
self.download_image(img_src, url)
# 查找其他页面链接(限制在同一个域名下)
if len(self.visited_pages) < self.max_pages and self.downloaded_count < self.max_images:
base_domain = urlparse(self.base_url).netloc
links = soup.find_all('a', href=True)
for link in links:
if self.downloaded_count >= self.max_images:
break
next_url = urljoin(url, link['href'])
parsed_next = urlparse(next_url)
# 只爬取同一域名的页面
if parsed_next.netloc == base_domain and next_url not in self.visited_pages:
self.crawl_page(next_url)
if len(self.visited_pages) >= self.max_pages:
break
点击查看代码
def start_crawl(self):
"""开始爬取"""
print("开始多线程爬取...")
start_time = time.time()
self.visited_pages.add(self.base_url)
with concurrent.futures.ThreadPoolExecutor(max_workers=self.max_workers) as executor:
futures = set()
while (len(self.visited_pages) < self.max_pages and
self.downloaded_count < self.max_images and
(not self.pages_to_visit.empty() or futures)):
# 提交新任务
while (not self.pages_to_visit.empty() and
len(futures) < self.max_workers and
len(self.visited_pages) <= self.max_pages and
self.downloaded_count < self.max_images):
url = self.pages_to_visit.get()
future = executor.submit(self.process_page, url)
futures.add(future)
# 等待完成的任务
done, futures = concurrent.futures.wait(
futures, timeout=1,
return_when=concurrent.futures.FIRST_COMPLETED
)
运行结果
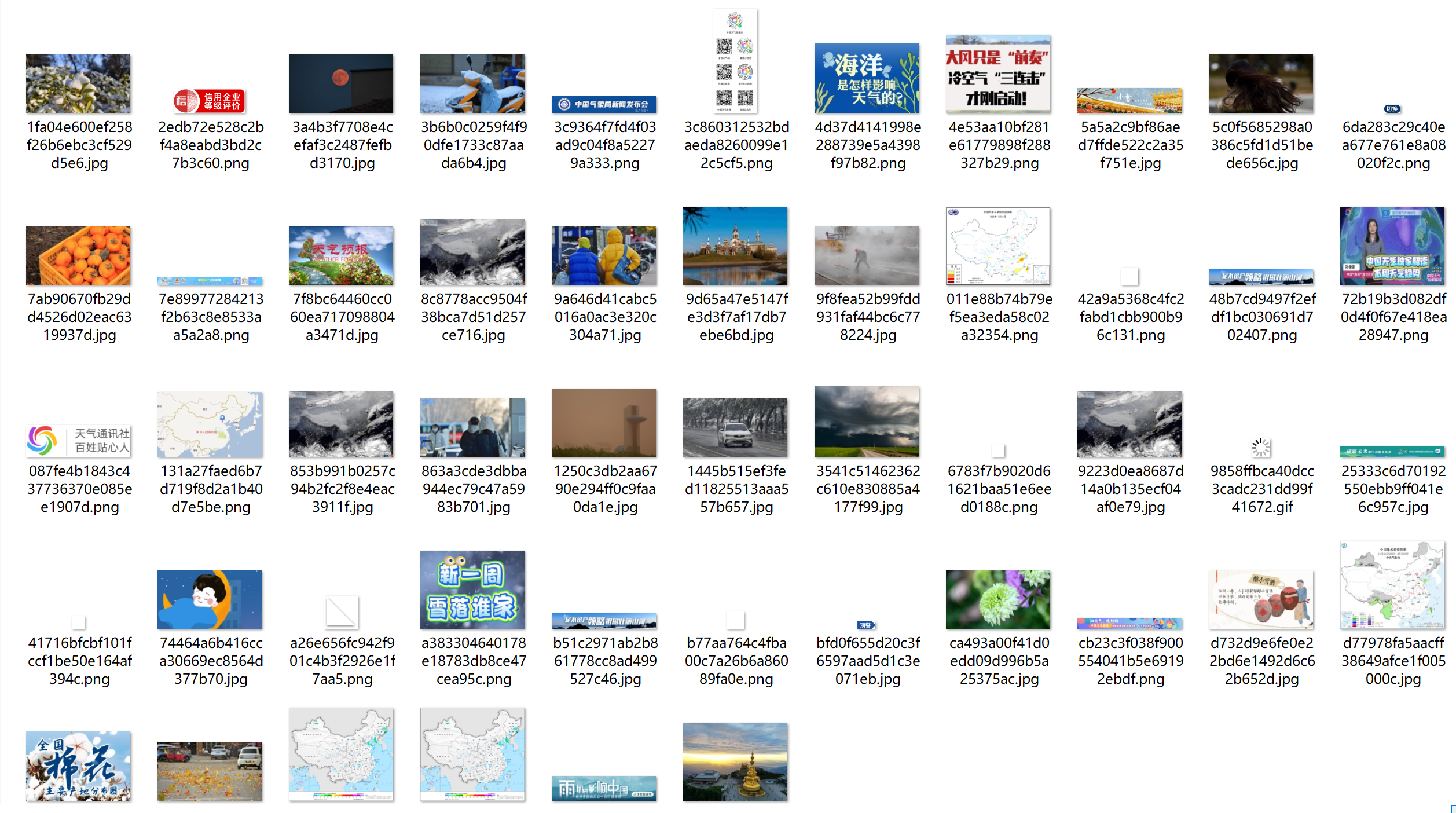
作业心得
这次作业,我切身地体会到了单线程和多线程效率上的差异,多线程的下载速度比起单线程成倍增长。
作业2
实验2:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
核心代码
stock_spider.py
点击查看代码
def start_requests(self):
"""
生成初始请求
动态拼接分页参数,实现批量数据采集
"""
max_page = 3 # 控制总页数为3页
page_size = 35 # 每页35条,总共105条数据
# 生成分页请求
for page_num in range(1, max_page + 1):
# 构建API请求URL
url = self.build_api_url(page_num, page_size)
self.logger.info("正在请求第 %d 页数据,URL: %s", page_num, url)
# 发送API请求,并将响应交给parse_api方法处理
yield scrapy.Request(
url=url,
callback=self.parse_api,
meta={'page_num': page_num}
)
def build_api_url(self, page_num, page_size):
"""
构建API请求URL
通过参数动态拼接实现分页数据获取
"""
base_url = "http://48.push2.eastmoney.com/api/qt/clist/get"
# API参数说明:
# pn: 页码,pz: 每页数量
# fs: 市场筛选(沪深京A股)
# fields: 需要返回的字段
url_template = (
"{base}"
"?pn={pn}&pz={pz}&po=1&np=1"
"&ut=bd1d9ddb04089700cf9c27f6f7426281"
"&fltt=2&invt=2&wbp2u=|0|0|0|web"
"&fid=f3"
"&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048"
"&fields=f2,f3,f4,f5,f6,f7,f12,f14,f15,f16,f17,f18"
)
return url_template.format(
base=base_url,
pn=page_num,
pz=page_size
)
def parse_api(self, response):
"""
解析API返回的JSON数据
提取股票信息并封装为Item对象
"""
page_num = response.meta.get("page_num") # 获取当前页码
response_text = response.text.strip()
try:
# 解析JSON格式的响应数据
json_data = json.loads(response_text)
# 提取股票数据列表(diff字段包含股票信息)
stock_list = json_data.get("data", {}).get("diff", [])
self.logger.info("第 %d 页成功获取 %d 条股票记录", page_num, len(stock_list))
# 处理每条股票记录
processed_count = 0
for stock_record in stock_list:
# 将原始数据封装为StockItem对象
stock_item = self.create_stock_item(stock_record)
if stock_item:
processed_count += 1
self.logger.debug(
"解析股票: %s - %s",
stock_item["stock_code"],
stock_item["stock_name"]
)
yield stock_item
self.logger.info("第 %d 页成功解析 %d 条有效股票数据", page_num, processed_count)
except json.JSONDecodeError as json_error:
self.logger.error(
"JSON解析错误: %s, 响应内容前200字符: %s",
json_error,
response_text[:200]
)
except Exception as general_error:
self.logger.error("解析数据过程中发生异常: %s", general_error)
点击查看代码
def open_spider(self, spider):
try:
self.connection = pymysql.connect(**self.mysql_config)
self.cursor = self.connection.cursor()
self.create_table()
self.logger.info("成功连接MySQL数据库")
except Exception as e:
self.logger.error(f"连接MySQL数据库失败: {e}")
raise
def create_table(self):
create_table_sql = """
CREATE TABLE IF NOT EXISTS stock_data (
id INT AUTO_INCREMENT PRIMARY KEY,
stock_code VARCHAR(20) NOT NULL,
stock_name VARCHAR(100) NOT NULL,
latest_price DECIMAL(10, 3),
change_pct DECIMAL(10, 3),
change_amt DECIMAL(10, 3),
volume VARCHAR(50),
turnover DECIMAL(15, 2),
amplitude DECIMAL(10, 3),
high_price DECIMAL(10, 3),
low_price DECIMAL(10, 3),
open_price DECIMAL(10, 3),
pre_close DECIMAL(10, 3),
crawl_time DATETIME,
UNIQUE KEY unique_stock_code (stock_code),
INDEX idx_stock_code (stock_code),
INDEX idx_crawl_time (crawl_time)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci
"""
self.cursor.execute(create_table_sql)
self.connection.commit()
self.logger.info("数据表创建成功")
点击查看代码
# 配置下载延迟
DOWNLOAD_DELAY = 0.5
# 启用MySQL Pipeline
ITEM_PIPELINES = {
'eastmoney_stock.pipelines.MySQLPipeline': 300,
}
# MySQL配置
MYSQL_HOST = 'localhost'
MYSQL_PORT = 3306
MYSQL_USER = 'root'
MYSQL_PASSWORD = '123456'
MYSQL_DATABASE = 'stock_db'
MYSQL_CHARSET = 'utf8mb4'
# User Agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
# 并发设置
CONCURRENT_REQUESTS = 1
CONCURRENT_REQUESTS_PER_DOMAIN = 1
# 日志配置
LOG_LEVEL = 'INFO'
运行结果
终端:
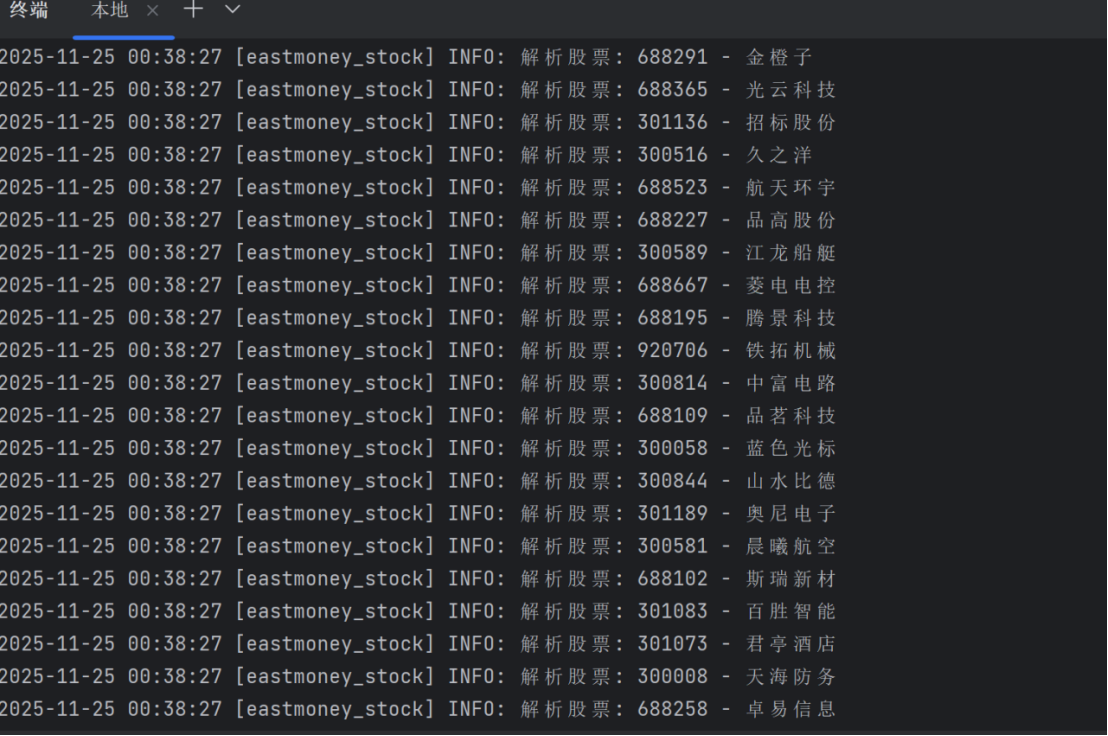
sql:
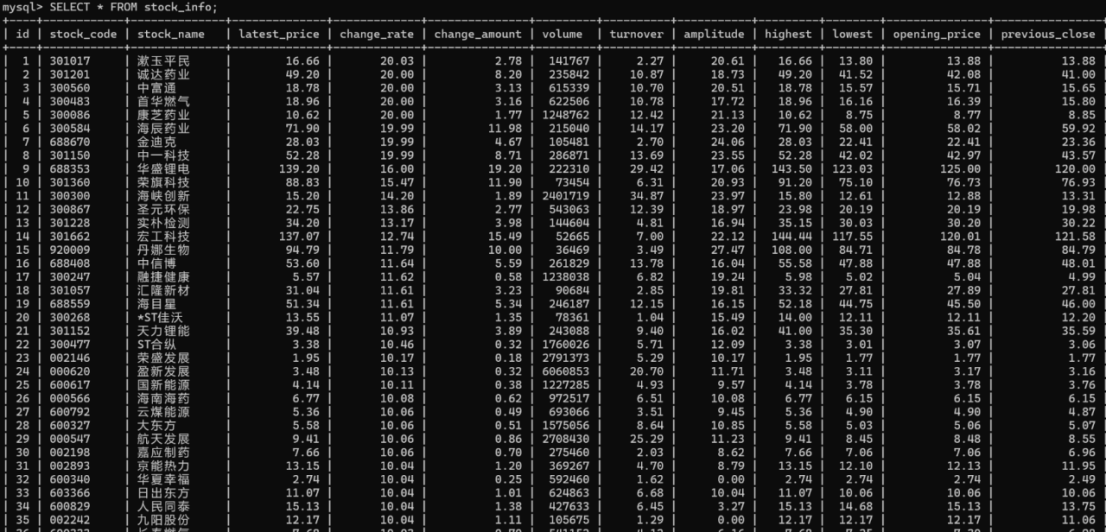
作业心得
这个作业过程让我熟悉了Scrapy的基本结构,以及Spider用来发送请求、Xpath用来提取数据、Pipeline负责把数据保存到 MySQL中的具体流程。
作业3
核心代码
点击查看代码
def _parse_single_row(self, table_row):
"""
解析单个表格行,提取外汇数据
参数:
table_row: 表格行Selector对象
返回:
WhpjItem 对象或 None(如果数据无效)
"""
# 提取行中所有单元格文本
cell_texts = table_row.xpath('./td//text()').getall()
# 清理文本:去除空白字符
cleaned_texts = [text.strip() for text in cell_texts if text.strip()]
# 验证数据完整性(至少需要8列数据)
if len(cleaned_texts) < 8:
return None
# 创建并填充数据项
return self._create_forex_item(cleaned_texts)
def _create_forex_item(self, row_data):
"""
根据行数据创建外汇数据项
参数:
row_data: 清理后的行数据列表
返回:
填充完成的 WhpjItem 对象
"""
item = WhpjItem()
# 映射数据字段
item["currency"] = row_data[0] # 货币名称
item["tbp"] = row_data[1] # 现汇买入价 (Telegraphic Buy Price)
item["cbp"] = row_data[2] # 现钞买入价 (Cash Buy Price)
item["tsp"] = row_data[3] # 现汇卖出价 (Telegraphic Sell Price)
item["csp"] = row_data[4] # 现钞卖出价 (Cash Sell Price)
item["time"] = row_data[7] # 发布时间
return item
def _log_parsed_item(self, item, row_index):
"""
记录解析成功的数据项日志
参数:
item: 解析成功的数据项
row_index: 行索引(用于日志定位)
"""
self.logger.debug(
"第 %d 行数据解析成功: %s - 买入价[现汇:%s, 现钞:%s] 卖出价[现汇:%s, 现钞:%s] 时间:%s",
row_index + 2, # +2 因为跳过了表头且索引从0开始
item["currency"],
item["tbp"],
item["cbp"],
item["tsp"],
item["csp"],
item["time"]
)
运行结果
终端:
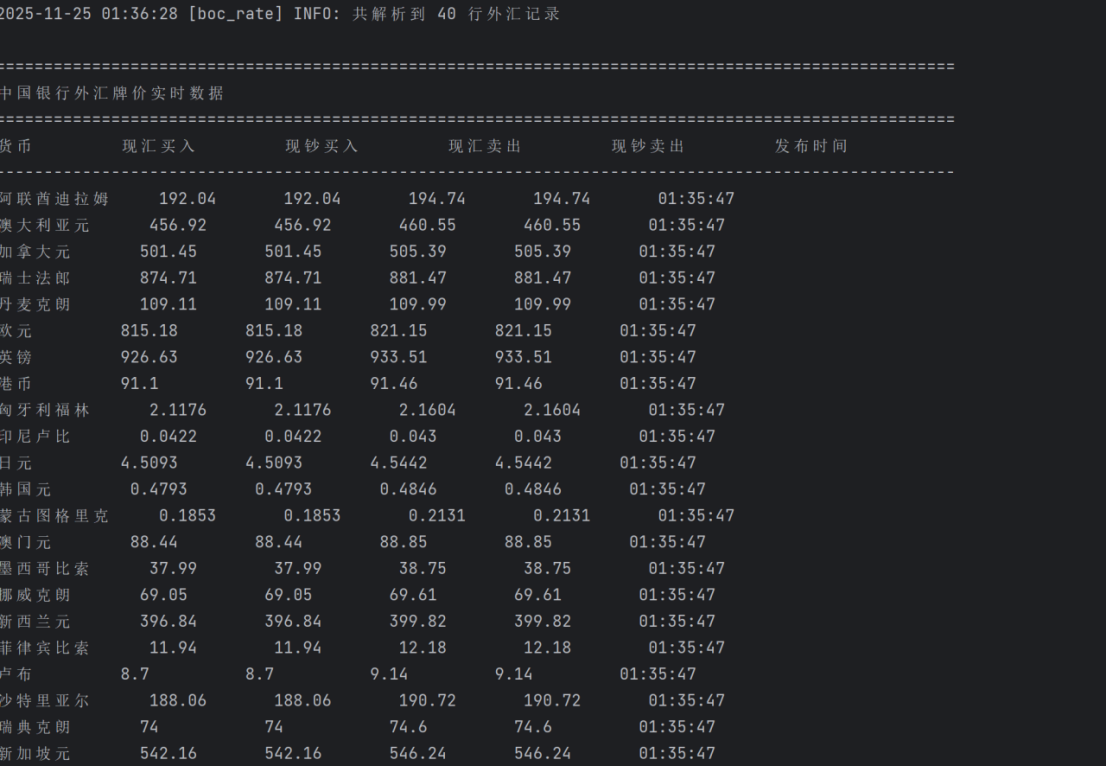
sql:

作业心得
作业2的时候还是比较生疏,作业3就得心应手了,我逐渐掌握了Scrapy中 Item、Pipeline的使用方法,也学会了如何在MySQL中查看和管理爬取的数据,完成了数据库与爬虫的融合。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号