
Redis的五种基本数据类型和三种高级对象
简介
Redis有五种基本数据类型: String、Hash、List、Set、Sorted Set;三种高级对象:HyperLogLog、Geo、BloomFilter。
五种基本数据类型
图解
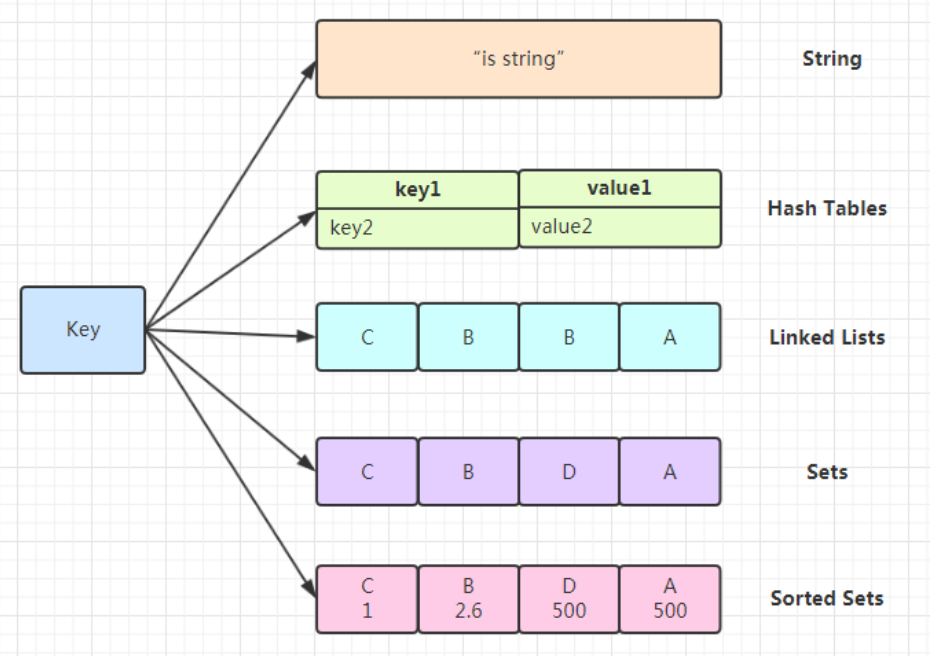
String 字符串类型
redis中最基本的数据类型,一个key对应一个value;
String类型是二进制安全的,意思是 redis 的 string 可以包含任何数据。如数字,字符串,jpg图片或者序列化的对象。
使用:get 、 set 、 del 、 incr、 decr 等
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> get hello
"world"
127.0.0.1:6379> del hello
(integer) 1
127.0.0.1:6379> get hello
(nil)
127.0.0.1:6379> get counter
(nil)
127.0.0.1:6379> incr counter
(integer) 1
127.0.0.1:6379> get counter
"1"
127.0.0.1:6379> incrby counter 100
(integer) 101
127.0.0.1:6379> get counter
"101"
127.0.0.1:6379> decr counter
(integer) 100
127.0.0.1:6379> get counter
"100"
实战场景:
1.缓存: 经典使用场景,把常用信息,字符串,图片或者视频等信息放到redis中,redis作为缓存层,mysql做持久化层,降低mysql的读写压力。
2.计数器:redis是单线程模型,一个命令执行完才会执行下一个,同时数据可以一步落地到其他的数据源。
3.session:常见方案spring session + redis实现session共享。
Hash(哈希)
是一个Mapmap,指值本身又是一种键值对结构,如 value={{field1,value1},......fieldN,valueN}}
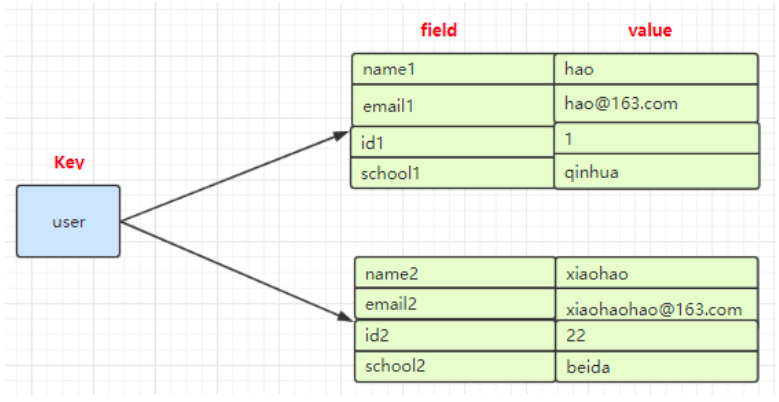
常用命令: hget、hset、hdel等
127.0.0.1:6379> hset user name zhangsan
(integer) 1
127.0.0.1:6379> hset user emaill zhangsan@163.com
(integer) 1
127.0.0.1:6379> hgetall user
1) "name"
2) "zhangsan"
3) "emaill"
4) "zhangsan@163.com"
127.0.0.1:6379> hget user name
"zhangsan"
127.0.0.1:6379> hget user emaill
"zhangsan@163.com"
127.0.0.1:6379> hset user name2 lisi
(integer) 1
127.0.0.1:6379> hset user emaill2 lisi@163.com
(integer) 1
127.0.0.1:6379> hgetall
(error) ERR wrong number of arguments for 'hgetall' command
127.0.0.1:6379> hgetall user
1) "name"
2) "zhangsan"
3) "emaill"
4) "zhangsan@163.com"
5) "name2"
6) "lisi"
7) "emaill2"
8) "lisi@163.com"
实战场景:
1.缓存: 能直观,相比string更节省空间,的维护缓存信息,如用户信息,视频信息等,就是存储表信息。
链表
List 说白了就是链表(redis 使用双端链表实现的 List),是有序的,value可以重复,可以通过下标取出对应的value值,左右两边都能进行插入和删除数据。
- 技巧
lpush+lpop=Stack(栈)
lpush+rpop=Queue(队列,用于避免超买超卖)
lpush+ltrim=Capped Collection(有限集合)
lpush+brpop=Message Queue(消息队列)
- 使用
127.0.0.1:6379> lpush mylist 1 2 3 4 5 6
(integer) 6
127.0.0.1:6379> lrange mylist 0 -1
1) "6"
2) "5"
3) "4"
4) "3"
5) "2"
6) "1"
127.0.0.1:6379> rpop mylist
"1"
127.0.0.1:6379> lrange mylist 0 -1
1) "6"
2) "5"
3) "4"
4) "3"
5) "2"
127.0.0.1:6379> rpop mylist
"2"
127.0.0.1:6379> lrange mylist 0 -1
1) "6"
2) "5"
3) "4"
4) "3"
127.0.0.1:6379> lpush mylist 7
(integer) 5
127.0.0.1:6379> lrange mylist 0 -1
1) "7"
2) "6"
3) "5"
4) "4"
5) "3"
127.0.0.1:6379> rpop mylist
"3"
127.0.0.1:6379> lrange mylist 0 -1
1) "7"
2) "6"
3) "5"
4) "4"
实战场景:多用于严禁超买超卖。
Set集合
集合类型也是用来保存多个字符串的元素,但和列表不同的是集合中 1. 不允许有重复的元素,2.集合中的元素是无序的,不能通过索引下标获取元素,3.支持集合间的操作,可以取多个集合取交集、并集、差集。
常用命令: sset 、srem、scard、smembers、sismember
- 使用
127.0.0.1:6379> sadd myset hao hao1 xiaohao hao
(integer) 3
127.0.0.1:6379> SMEMBERS myset
1) "hao1"
2) "xiaohao"
3) "hao"
127.0.0.1:6379> SISMEMBER myset hao
(integer) 1
实战场景
他们主要是用于去重,则可以进行收集点赞;用于交集、并集、差集的操作,则可以把两个人的粉丝列表整合为一个交集。
ZSet集合
- 格式
zadd zset的key score值 项的值, Score和项可以是多对,score可以是整数,也可以是浮点数,和set完全不同,用于存储分数,并对分数进行操作。
127.0.0.1:6379> zadd myzst 10 v1 20 v2 30 v3
(integer) 3
127.0.0.1:6379> zrangeby score myzst 10 20
(error) ERR unknown command `zrangeby`, with args beginning with: `score`, `myzst`, `10`, `20`,
127.0.0.1:6379> zrangebyscore myzst 10 20
1) "v1"
2) "v2"
127.0.0.1:6379> zrem myzset v1
(integer) 0
127.0.0.1:6379> zrem myzst v1
(integer) 1
127.0.0.1:6379> zscore myzst v3
"30"
实战场景
去重,并获取排前几名的用户,可以用作排行榜。
HyperLogLog
- 基本概念
Redis 在 2.8.9 版本添加了 HyperLogLog 结构。
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
- 使用
[root@smallming ~]# redis-cli -p 6379
127.0.0.1:6379> pfadd user_login_20220315 tom # user_login_20210523是key;tom 是登录的用户
(integer) 1
127.0.0.1:6379> pfcount user_login_20220315 #获取登录的用户
(integer) 1
127.0.0.1:6379> pfadd user_login_20220315 tom jack lilei
(integer) 1
127.0.0.1:6379> pfcount user_login_20220315 #相同登录的用户算一个
(integer) 3
127.0.0.1:6379> pfadd user_login_20220316 sira
(integer) 1
127.0.0.1:6379> pfcount user_login_20220315 user_login_20220316 #计算20220315和20220316一共登录的用户有多少
(integer) 4
127.0.0.1:6379> pfmerge user_login_20220315 user_login_20220315 user_login_20220316 #将20220315和20220316合并为20220315
OK
127.0.0.1:6379> pfcount user_login_20220315 #统计20220315登录的用户
(integer) 4
- 应用场景
用来统计网站的登录人数以及其他指标。
GEO
- 基本概念
在 Redis 3.2 版本中新增了一种叫 geo 的数据结构,它主要用来存储地理位置信息,并对存储的信息进行操作。
- 使用
geoadd 用于存储指定的地理空间位置,可以将一个或多个经度(longitude)、纬度(latitude)、位置名称(member)添加到指定的 key 中。
127.0.0.1:6379> geoadd beijing 116.405285 39.912835 "今日"
(integer) 1
geopos 用于从给定的 key 里返回所有指定名称(member)的位置(经度和纬度),不存在的返回 nil。
127.0.0.1:6379> GEOPOS beijing "今日"
1) 1) "116.40528291463851929"
2) "39.91283591962181276"
- 应用场景
用于存储地理信息以及对地理信息操作的场景。
BloomFilter
-
基本概念
一种数据结构,是由一串很长的二进制向量组成,可以将其看成一个二进制数组。既然是二进制,那么里面存放的不是0,就是1,但是初始默认值都是0。他的主要作用是:判断一个元素是否在某个集合中。比如说,我想判断20亿的号码中是否存在某个号码,如果直接插DB,那么数据量太大时间会很慢;如果将20亿数据放到 缓存 中,缓存也装不下。这个时候用 布隆过滤器 最合适了,布隆过滤器的原理是: -
添加元素
当要向布隆过滤器中添加一个元素key时,我们通过多个hash函数,算出一个值,然后将这个值所在的方格置为1。 -
判断元素是否存在:
判断元素是否存在,是先将元素经过多个hash函数计算,计算到多个下标值,然后判断这些下标对应的元素值是否都为1,如果存在不是 1 的,那么元素肯定不在集合中;如果都是 1,那么元素大概率在集合中,并不能百分之百肯定元素存在集合中,因为多个不同的数据通过hash函数算出来的结果是会有重复的,所以会存在某个位置是别的数据通过hash函数置为的1。
总的来说:布隆过滤器可以判断某个数据一定不存在,但是无法判断一定存在。 -
布隆过滤器的优缺点:
- 优点:优点很明显,二进制组成的数组,占用内存极少,并且插入和查询速度都足够快。
- 缺点:随着数据的增加,误判率会增加;还有无法判断数据一定存在;另外还有一个重要缺点,无法删除数据。
-
使用
redis4.0后可以使用布隆过滤器的插件RedisBloom
bf.add 添加元素到布隆过滤器
bf.exists 判断元素是否在布隆过滤器
bf.madd 添加多个元素到布隆过滤器,bf.add只能添加一个
bf.mexists 判断多个元素是否在布隆过滤器
> bf.add boomFilter tc01
(integer) 1 # 1:存在;0:不存在
> bf.add boomFilter tc02
(integer) 1
> bf.add boomFilter tc03
(integer) 1
> bf.exists boomFilter tc01
(integer) 1
> bf.exists boomFilter tc02
(integer) 1
> bf.exists boomFilter tc03
(integer) 1
> bf.exists boomFilter tc04
(integer) 0
> bf.madd boomFilter tc05 tc06 tc07
1) (integer) 1
2) (integer) 1
3) (integer) 1
> bf.mexists boomFilter tc05 tc06 tc07 tc08
1) (integer) 1
2) (integer) 1
3) (integer) 1
4) (integer) 0
- 应用场景
- 解决缓存穿透问题:一般得查询场景都是先去查询缓存,如果缓存没有,那么就去 DB 查询,如果查到了,先存在 缓存 中,然后返回给调用方。如果查不到就返回空。这种情况如果有人频繁的请求缓存中没有得数据,比如id = -1 得数据,那么会对 DB 造成极大得压力,这种情况就可以使用 redis 得布隆过滤器了,可以先将可能得id都存在布隆过滤器中,当查询来的时候,先去布隆过滤器查,如果查不到直接返回,不请求缓存以及DB,如果存在 布隆过滤器 中,那么才去缓存中取数据。
- 黑名单校验:可以将黑名单中得ip放入到布隆过滤器中,这样不用每次来都去 db 中查询了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号