
Spark-Spark RDD操作
Spark只支持两种RDD操作,transformation和action操作,transformation针对已有的RDD创建一个新的RDD文件,action主要是对RDD进行最后操作,比如遍历和reduce、保存到文件等,并可以返回结果到Driver程序
transformation,都具有lazy特性,只定义transformation操作是不会执行,只有接着执行一个action操作后才会执行。通过lazy特性避免产生过多中间结果。
wordcount程序就是如下执行流程,如下这块都在driver节点执行。所有transformation都是lazy,不会立即执行,只有执行了action后,才会触发job,提交task到spark集群上,进行实际的执行
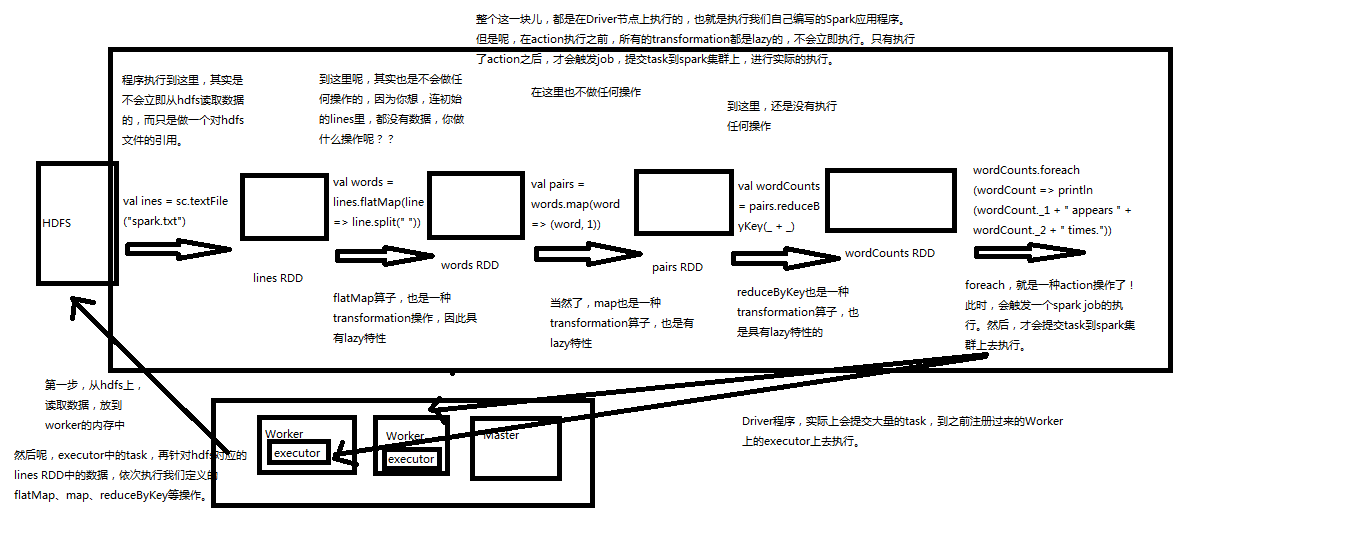
文件行统计
package cn.spark.study.core; import org.apache.spark.SparkConf; import org.apache.spark.SparkContext; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import org.apache.spark.api.java.function.VoidFunction; import org.codehaus.janino.Java; import scala.Tuple2; /** * @author: yangchun * @description: * @date: Created in 2020-05-04 21:55 */ public class LineCount { public static void main(String[] args) { SparkConf sparkConf = new SparkConf().setAppName("lineCount").setMaster("local"); JavaSparkContext sc = new JavaSparkContext(sparkConf); JavaRDD<String> lines = sc.textFile("E:\\spark\\hello.txt"); JavaPairRDD<String,Integer> pairs = lines.mapToPair(new PairFunction<String, String, Integer>() { @Override public Tuple2<String, Integer> call(String s) throws Exception { return new Tuple2<>(s,1); } }); JavaPairRDD<String,Integer> lineCounts = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() { @Override public Integer call(Integer v1, Integer v2) throws Exception { return v1 + v2; } }); lineCounts.foreach(new VoidFunction<Tuple2<String, Integer>>() { @Override public void call(Tuple2<String, Integer> lineCount) throws Exception { System.out.println(lineCount._1+" appeared "+lineCount._2+" times"); } }); } }
package cn.spark.study.core
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author: yangchun
* @description:
* @date: Created in 2020-05-04 22:08
*/
object LineCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("lineCount").setMaster("local")
val sc = new SparkContext(conf)
val lines = sc.textFile("E:\\spark\\hello.txt")
val pairs = lines.map{line=>(line,1)}
val lineCounts = pairs.reduceByKey{_+_}
lineCounts.foreach{lineCount=>println(lineCount._1+" appeared "+lineCount._2)}
}
}
| 操作 | 介绍 |
| map | 将RDD中的每个元素传入自定义函数,获取一个新的元素,然后用新的元素组成新的RDD |
| filter | 对RDD中的元素进行判断,如果返回true则保留,返回false则剔除 |
| flatMap | 与map类似,但是对每个元素都可以返回一个或多个新元素 |
| groupByKey | 根据key进行分组,每个key对应一个Iterable<Value> |
| reduceByKey | 对每个key对应的value进行reduce操作 |
| sortByKey | 对每个key对应的value进行排序操作 |
| join |
对两个包含<key,value>对的RDD进行join操作,每个key join上的pair,都会传入自定义函数进行处理 |
| co'group | 同join,但是每个可以对应的Interable<value>都会传入自定义函数进行处理 |
action介绍
| 操作 | 介绍 |
| reduce | 将RDD元素进行聚合操作,第一个和第二个聚合,然后值与第三个依次类推 |
| collect | 将RDD中所有元素获取到本地客户端 |
| count | 获取RDD元素总数 |
| take(n) | 获取RDD前N个元素 |
| saveAsTextFile | 将RDD元素保存到文件中,对每个元素调用toString方法 |
| countByKey | 对每个Key进行count计数 |
| foreach | 对RDD中元素进行遍历 |
transformation案例如下
package cn.spark.study.core; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2; import java.util.Arrays; import java.util.Iterator; import java.util.List; /** * @author: yangchun * @description: * @date: Created in 2020-05-05 11:02 */ public class TransformationOperation { public static void main(String[] args) { //map(); //filter(); //flatMap(); //groupByKey(); //reduceByKey(); //sortByKey(); //joinAndCogroup(); cogroup(); } private static void map(){ SparkConf sparkConf = new SparkConf().setAppName("map") .setMaster("local"); JavaSparkContext sc = new JavaSparkContext(sparkConf); JavaRDD<Integer> numbers = sc.parallelize(Arrays.asList(1,2,3,4,5)); JavaRDD<Integer> multiple = numbers.map(new Function<Integer, Integer>() { private static final long serialVersionUID = 1L; @Override public Integer call(Integer number) throws Exception { return number * 2; } }); multiple.foreach(new VoidFunction<Integer>() { @Override public void call(Integer integer) throws Exception { System.out.println(integer); } }); sc.close(); } private static void filter(){ SparkConf sparkConf = new SparkConf().setAppName("map") .setMaster("local"); JavaSparkContext sc = new JavaSparkContext(sparkConf); JavaRDD<Integer> numbers = sc.parallelize(Arrays.asList(1,2,3,4,5)); JavaRDD<Integer> even = numbers.filter(new Function<Integer, Boolean>() { @Override public Boolean call(Integer integer) throws Exception { return integer % 2==0; } }); even.foreach(new VoidFunction<Integer>() { @Override public void call(Integer integer) throws Exception { System.out.println(integer); } }); sc.close(); } private static void flatMap(){ SparkConf sparkConf = new SparkConf().setAppName("map") .setMaster("local"); JavaSparkContext sc = new JavaSparkContext(sparkConf); JavaRDD<String> numbers = sc.parallelize(Arrays.asList("hello me","hello you")); JavaRDD<String> words = numbers.flatMap(new FlatMapFunction<String, String>() { @Override public Iterable<String> call(String s) throws Exception { return Arrays.asList(s.split(" ")); } }); words.foreach(new VoidFunction<String>() { @Override public void call(String word) throws Exception { System.out.println(word); } }); sc.close(); } private static void groupByKey(){ SparkConf sparkConf = new SparkConf().setAppName("map") .setMaster("local"); JavaSparkContext sc = new JavaSparkContext(sparkConf); List<Tuple2<String,Integer>> scoreList = Arrays.asList( new Tuple2<String, Integer>("class1",80), new Tuple2<String, Integer>("class2",70), new Tuple2<String, Integer>("class1",90), new Tuple2<String, Integer>("class2",75)); JavaPairRDD<String,Integer> scores = sc.parallelizePairs(scoreList); JavaPairRDD<String,Iterable<Integer>> groupedScores = scores.groupByKey(); groupedScores.foreach(new VoidFunction<Tuple2<String, Iterable<Integer>>>() { @Override public void call(Tuple2<String, Iterable<Integer>> stringIterableTuple2) throws Exception { System.out.println("class is"+stringIterableTuple2._1); Iterator<Integer> iterator = stringIterableTuple2._2.iterator(); while (iterator.hasNext()){ System.out.println(iterator.next()); } } }); sc.close(); } private static void reduceByKey(){ SparkConf sparkConf = new SparkConf().setAppName("map") .setMaster("local"); JavaSparkContext sc = new JavaSparkContext(sparkConf); List<Tuple2<String,Integer>> scoreList = Arrays.asList( new Tuple2<String, Integer>("class1",80), new Tuple2<String, Integer>("class2",70), new Tuple2<String, Integer>("class1",90), new Tuple2<String, Integer>("class2",75)); JavaPairRDD<String,Integer> scores = sc.parallelizePairs(scoreList); JavaPairRDD<String,Integer> totalScores = scores.reduceByKey(new Function2<Integer, Integer, Integer>() { @Override public Integer call(Integer integer1, Integer integer2) throws Exception { return integer1+integer2; } }); totalScores.foreach(new VoidFunction<Tuple2<String, Integer>>() { private static final long serialVersionUID = 1L; @Override public void call(Tuple2<String, Integer> stringIntegerTuple2) throws Exception { System.out.println(stringIntegerTuple2._1+" "+stringIntegerTuple2._2); } }); sc.close(); } private static void sortByKey(){ SparkConf sparkConf = new SparkConf().setAppName("map") .setMaster("local"); JavaSparkContext sc = new JavaSparkContext(sparkConf); List<Tuple2<Integer,String>> scoreList = Arrays.asList( new Tuple2<Integer, String>(80,"leo"), new Tuple2<Integer, String>(70,"deni"), new Tuple2<Integer, String>(60,"dan"), new Tuple2<Integer, String>(100,"yangchun")); JavaPairRDD<Integer,String> scores = sc.parallelizePairs(scoreList); JavaPairRDD<Integer,String> totalScores = scores.sortByKey(false); totalScores.foreach(new VoidFunction<Tuple2<Integer, String>>() { private static final long serialVersionUID = 1L; @Override public void call(Tuple2<Integer, String> stringIntegerTuple2) throws Exception { System.out.println(stringIntegerTuple2._1+" "+stringIntegerTuple2._2); } }); sc.close(); } private static void joinAndCogroup(){ SparkConf sparkConf = new SparkConf().setAppName("map") .setMaster("local"); JavaSparkContext sc = new JavaSparkContext(sparkConf); List<Tuple2<Integer,String>> studentList = Arrays.asList( new Tuple2<Integer, String>(1,"leo"), new Tuple2<Integer, String>(2,"deni"), new Tuple2<Integer, String>(3,"dan"), new Tuple2<Integer, String>(4,"yangchun")); List<Tuple2<Integer,Integer>> scoreList = Arrays.asList( new Tuple2<Integer, Integer>(1,60), new Tuple2<Integer, Integer>(2,70), new Tuple2<Integer, Integer>(3,80), new Tuple2<Integer, Integer>(4,100)); JavaPairRDD<Integer,String> students = sc.parallelizePairs(studentList); JavaPairRDD<Integer,Integer> scores = sc.parallelizePairs(scoreList); JavaPairRDD<Integer,Tuple2<String,Integer>> studentsScores = students.join(scores); studentsScores.foreach(new VoidFunction<Tuple2<Integer, Tuple2<String, Integer>>>() { @Override public void call(Tuple2<Integer, Tuple2<String, Integer>> integerTuple2Tuple2) throws Exception { System.out.println("id"+integerTuple2Tuple2._1+" name "+integerTuple2Tuple2._2._1+" score"+ integerTuple2Tuple2._2._2); } }); sc.close(); } private static void cogroup(){ SparkConf sparkConf = new SparkConf().setAppName("map") .setMaster("local"); JavaSparkContext sc = new JavaSparkContext(sparkConf); List<Tuple2<Integer,String>> studentList = Arrays.asList( new Tuple2<Integer, String>(1,"leo"), new Tuple2<Integer, String>(2,"deni"), new Tuple2<Integer, String>(3,"dan"), new Tuple2<Integer, String>(4,"yangchun")); List<Tuple2<Integer,Integer>> scoreList = Arrays.asList( new Tuple2<Integer, Integer>(1,60), new Tuple2<Integer, Integer>(1,50), new Tuple2<Integer, Integer>(2,50), new Tuple2<Integer, Integer>(2,70), new Tuple2<Integer, Integer>(3,80), new Tuple2<Integer, Integer>(3,90), new Tuple2<Integer, Integer>(4,100), new Tuple2<Integer, Integer>(4,95)); JavaPairRDD<Integer,String> students = sc.parallelizePairs(studentList); JavaPairRDD<Integer,Integer> scores = sc.parallelizePairs(scoreList); JavaPairRDD<Integer,Tuple2<Iterable<String>,Iterable<Integer>>> studentsScores = students.cogroup(scores); studentsScores.foreach(new VoidFunction<Tuple2<Integer, Tuple2<Iterable<String>, Iterable<Integer>>>>() { @Override public void call(Tuple2<Integer, Tuple2<Iterable<String>, Iterable<Integer>>> integerTuple2Tuple2) throws Exception { System.out.println("id "+integerTuple2Tuple2._1); System.out.println("name "+integerTuple2Tuple2._2._1); System.out.println("score "+integerTuple2Tuple2._2._2); System.out.println("================================"); } }); sc.close(); } }
package cn.spark.study.core import org.apache.spark.{SparkConf, SparkContext} /** * @author: yangchun * @description: * @date: Created in 2020-05-05 11:08 */ object TransformationOperation { def main(args: Array[String]): Unit = { //map() //filter() //flatMap() //groupByKey() //reduceByKey() //sortByKey() //join() cogroup() } def map(): Unit ={ val conf = new SparkConf().setAppName("map").setMaster("local") val sc = new SparkContext(conf) val numbers = sc.parallelize(Array(1,2,3,4,5),5) val multiple = numbers.map{number=>number*2} multiple.foreach{num=>println(num)} } def filter(): Unit ={ val conf = new SparkConf().setAppName("map").setMaster("local") val sc = new SparkContext(conf) val numbers = sc.parallelize(Array(1,2,3,4,5),5) val even = numbers.filter{number=>number%2==0} even.foreach{num=>println(num)} } def flatMap(): Unit ={ val conf = new SparkConf().setAppName("map").setMaster("local") val sc = new SparkContext(conf) val lines = sc.parallelize(Array("hello me","hello you"),1) val even = lines.flatMap{line=>line.split(" ")} even.foreach{word=>println(word)} } def groupByKey(): Unit ={ val conf = new SparkConf().setAppName("map").setMaster("local") val sc = new SparkContext(conf) val scoreList = Array(new Tuple2("class1", 80), new Tuple2("class2", 70), new Tuple2("class1", 90), new Tuple2("class2", 75)) val scores = sc.parallelize(scoreList,1) val groupedScores = scores.groupByKey() groupedScores.foreach(score=>{ println(score._1) score._2.foreach(single=>println(single)) println("================================") }) } def reduceByKey(): Unit ={ val conf = new SparkConf().setAppName("map").setMaster("local") val sc = new SparkContext(conf) val scoreList = Array(new Tuple2("class1", 80), new Tuple2("class2", 70), new Tuple2("class1", 90), new Tuple2("class2", 75)) val scores = sc.parallelize(scoreList,1) val totalScores = scores.reduceByKey{ _+_ } totalScores.foreach(score=>{ println(score._1+" "+score._2) }) } def sortByKey(): Unit ={ val conf = new SparkConf().setAppName("map").setMaster("local") val sc = new SparkContext(conf) val scoreList = Array(new Tuple2(80, "leo"), new Tuple2(70,"deni"), new Tuple2(60, "dandan"), new Tuple2(100, "yangchun")) val scores = sc.parallelize(scoreList,1) val totalScores = scores.sortByKey() totalScores.foreach(score=>{ println(score._1+" "+score._2) }) } def join(): Unit ={ val conf = new SparkConf().setAppName("map").setMaster("local") val sc = new SparkContext(conf) val studentList = Array(new Tuple2(1, "leo"), new Tuple2(2,"deni"), new Tuple2(3, "dandan"), new Tuple2(4, "yangchun")) val scoresList = Array(new Tuple2(1, 60), new Tuple2(2,70), new Tuple2(3, 80), new Tuple2(4, 90)) val studens = sc.parallelize(studentList,1) val scores = sc.parallelize(scoresList,1) val studentScores = studens.join(scores) studentScores.foreach(score=>{ println(score._1+" "+score._2._1+""+score._2._2) }) } def cogroup(): Unit ={ val conf = new SparkConf().setAppName("map").setMaster("local") val sc = new SparkContext(conf) val studentList = Array(new Tuple2(1, "leo"), new Tuple2(2,"deni"), new Tuple2(3, "dandan"), new Tuple2(4, "yangchun")) val scoresList = Array(new Tuple2(1, 60), new Tuple2(2,70), new Tuple2(3, 80), new Tuple2(4, 90), new Tuple2(1, 60), new Tuple2(2,70), new Tuple2(3, 80), new Tuple2(4, 90)) val students = sc.parallelize(studentList,1) val scores = sc.parallelize(scoresList,1) val studentScores = students.cogroup(scores) studentScores.foreach(score=>{ println(score._1+" "+score._2._1+" "+score._2._2) }) } }
action操作实战代码如下
1、reduce操作的本质就是聚合将多个元素聚合成一个元素
2、把远程节点所有partition里的元素拿到driver节点上来,大量数据会导致网络传输性能差和内存溢出
3、对rdd进行count统计有多少元素
4、take取前n个元素
5、saveAsTextFile,保存到hdfs或者本地文件 hadoop fs -ls / 命令查看所有文件。只能保存成功为文件夹,里面会生成hdfs文件版本
6、countByKey
7、foreach 循环每一条数据,在远程集群上执行,比collect性能好很多
package cn.spark.study.core import cn.spark.study.core.TransformationOperation.cogroup import org.apache.spark.{SparkConf, SparkContext} /** * @author: yangchun * @description: * @date: Created in 2020-05-06 22:22 */ object ActionOperation { def main(args: Array[String]): Unit = { countByKey(); } def reduce(): Unit ={ val conf = new SparkConf().setAppName("reduce").setMaster("local") val sc = new SparkContext(conf) val numbers = sc.parallelize(Array(1,2,3,4,5,6,7,8,9),1) val sum = numbers.reduce{_ + _} println(sum) } def collect(): Unit ={ val conf = new SparkConf().setAppName("reduce").setMaster("local") val sc = new SparkContext(conf) val numbers = sc.parallelize(Array(1,2,3,4,5,6,7,8,9),1) val doubleNumbers = numbers.map{num => num*2} val doubleArray = doubleNumbers.collect(); for(num <- doubleArray){ println(num) } } def count(): Unit ={ val conf = new SparkConf().setAppName("reduce").setMaster("local") val sc = new SparkContext(conf) val numbers = sc.parallelize(Array(1,2,3,4,5,6,7,8,9),1) val num = numbers.count() println(num) } def take(): Unit ={ val conf = new SparkConf().setAppName("reduce").setMaster("local") val sc = new SparkContext(conf) val numbers = sc.parallelize(Array(1,2,3,4,5,6,7,8,9),1) val doubleNumbers = numbers.map{num => num*2} val doubleArray = doubleNumbers.take(3); for(num <- doubleArray){ println(num) } } def countByKey(): Unit ={ val conf = new SparkConf().setAppName("map").setMaster("local") val sc = new SparkContext(conf) val scoreList = Array(new Tuple2("class1", 80), new Tuple2("class2", 70), new Tuple2("class1", 90), new Tuple2("class2", 75)) val scores = sc.parallelize(scoreList,1) val groupedScores = scores.countByKey() groupedScores.foreach(score=>{ println(score._1+" "+score._2) }) } }
package cn.spark.study.core; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2; import java.util.Arrays; import java.util.Iterator; import java.util.List; import java.util.Map; /** * @author: yangchun * @description: * @date: Created in 2020-05-05 11:02 */ public class ActionOperation { public static void main(String[] args) { countByKey(); } private static void reduce(){ SparkConf sparkConf = new SparkConf().setAppName("reduce") .setMaster("local"); JavaSparkContext sc = new JavaSparkContext(sparkConf); JavaRDD<Integer> numbers = sc.parallelize(Arrays.asList(1,2,3,4,5,6,7,8,9,10)); int sum = numbers.reduce(new Function2<Integer, Integer, Integer>() { @Override public Integer call(Integer integer, Integer integer2) throws Exception { return integer+integer2; } }); System.out.println(sum); sc.close(); } private static void collect(){ SparkConf sparkConf = new SparkConf().setAppName("collect") .setMaster("local"); JavaSparkContext sc = new JavaSparkContext(sparkConf); JavaRDD<Integer> numbers = sc.parallelize(Arrays.asList(1,2,3,4,5,6,7,8,9,10)); JavaRDD<Integer> doubleNumbers = numbers.map(new Function<Integer, Integer>() { @Override public Integer call(Integer integer) throws Exception { return integer * 2; } }); List<Integer> list = doubleNumbers.collect(); for (Integer integer:list){ System.out.println(integer); } sc.close(); } private static void count(){ SparkConf sparkConf = new SparkConf().setAppName("collect") .setMaster("local"); JavaSparkContext sc = new JavaSparkContext(sparkConf); JavaRDD<Integer> numbers = sc.parallelize(Arrays.asList(1,2,3,4,5,6,7,8,9,10)); Long num = numbers.count(); System.out.println(num); sc.close(); } private static void take(){ SparkConf sparkConf = new SparkConf().setAppName("collect") .setMaster("local"); JavaSparkContext sc = new JavaSparkContext(sparkConf); JavaRDD<Integer> numbers = sc.parallelize(Arrays.asList(1,2,3,4,5,6,7,8,9,10)); List<Integer> top3 = numbers.take(3); for (Integer integer:top3) { System.out.println(integer); } sc.close(); } private static void saveAsTextFile(){ SparkConf sparkConf = new SparkConf().setAppName("collect"); JavaSparkContext sc = new JavaSparkContext(sparkConf); JavaRDD<Integer> numbers = sc.parallelize(Arrays.asList(1,2,3,4,5,6,7,8,9,10)); numbers.saveAsTextFile("hdfs://spark1:9000/numbers.txt"); sc.close(); } private static void countByKey(){ SparkConf sparkConf = new SparkConf().setAppName("map") .setMaster("local"); JavaSparkContext sc = new JavaSparkContext(sparkConf); List<Tuple2<String,Integer>> scoreList = Arrays.asList( new Tuple2<String, Integer>("class1",80), new Tuple2<String, Integer>("class2",70), new Tuple2<String, Integer>("class1",90), new Tuple2<String, Integer>("class2",75)); JavaPairRDD<String,Integer> scores = sc.parallelizePairs(scoreList); Map<String,Object> groupedScores = scores.countByKey(); for(Map.Entry<String,Object> entry :groupedScores.entrySet()){ System.out.println(entry.getKey()+" "+entry.getValue()); } sc.close(); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号