
spark大数据-wordcount原理剖析
1、代码如下
package cn.spark.study.core import org.apache.spark.{SparkConf, SparkContext} /** * @author: yangchun * @description: * @date: Created in 2020-05-04 15:41 */ object WordCountScala { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("WordCount") val sc = new SparkContext(conf) val lines = sc.textFile("hdfs://spark1:9000/spark.txt") val words = lines.flatMap{line=>line.split(" ")} val pairs = words.map{word=>(word,1)} val wordCounts = pairs.reduceByKey{_ + _} wordCounts.foreach(wordCount=>println(wordCount._1+" appeared "+wordCount._2+" times")) } }
2、原理图如下
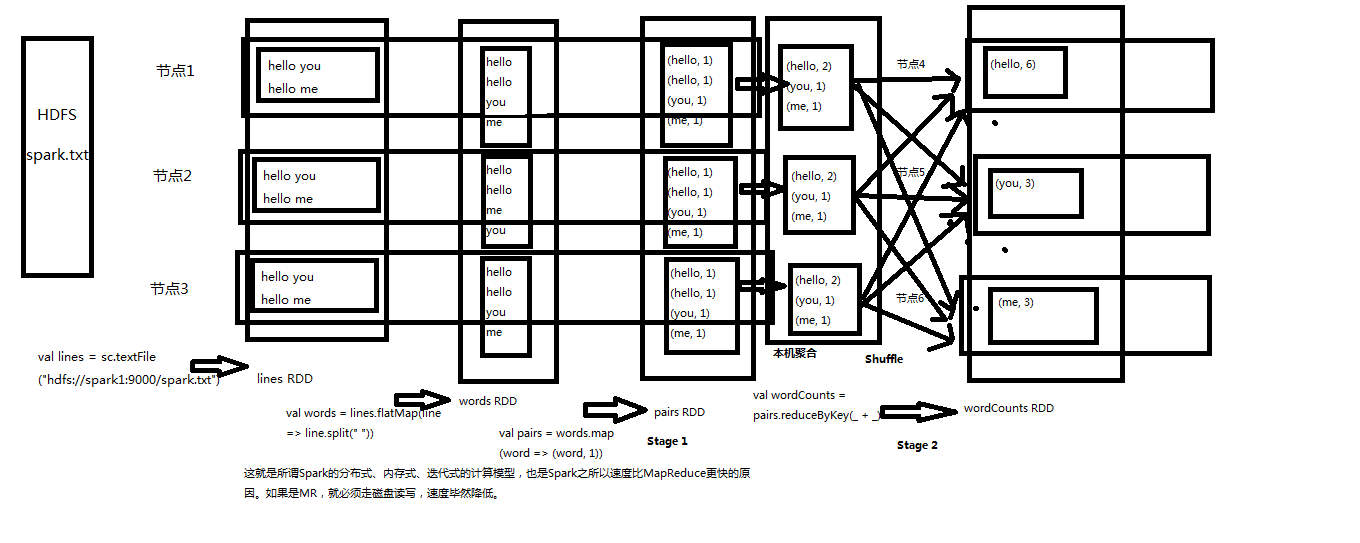
3、分布式、迭代计算、基于内存
一批批不同数据组成一个个不同RDD,不停的在内存里面进行迭代计算得出结果。reduceByKey还会现在本地进行一次聚合,然后再进行shuffle操作
从hadoop的hdfs里面获取数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号