GraphRAG
大语言模型使用的局限与不足
- 幻觉:大语言模型文本生成底层基于概率,有时会胡说八道
- 数据新鲜度:大语言模型因训练成本高,数据新鲜度有时限,过了这个时限后的事情就不知道了
- 数据安全:企业把数据,文件等上传大模型会造成信息泄露
Facebook RAG
当我向机器提问,机器将我的提问转化为它能够理解的格式,接着利用某种神奇的数学算法,在内部某个知识库中进行检索 ,检索成功后,将检索到的内容,再通过另外一个强大的文本处理模型加工、优化后再返回给我。
RAG定义
RAG:全称(Retrieval Augmental Generation)——检索增强生成。结合饿了信息检索技术和LLM。自研RAG系统先从私有或特定领域的文档库中检索到用户查询的上下文信息,LLM再根据检索到的上下文信息生成最终答案。RAG可以提高文本生成的质量和准确性。这里需注意,RAG不仅仅是搜索引擎,不管RAG多厉害,还是基于LLM,脱离了LLM,就会变得没有“人味儿”。
RAG的流程
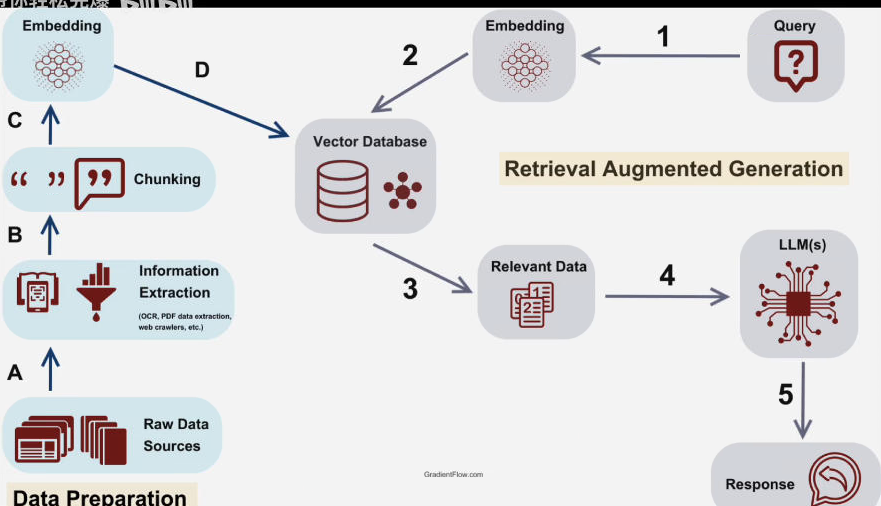
RAG的流程从完整性来说应当包括两大阶段:
- 第一阶段:数据的准备阶段
(1)第一步:数据收集
该环节要注意的是做好数据渠道管理与数据村粗管理,少产生脏数据或者是不一致的数据
(2)第二步:知识抽取阶段
该环节可利用多种工具对数据进行筛选、过滤和抽取,最终将有用的数据挑选出来并转化为知识
(3)第三步:知识分块
就像运输成吨的水泥需要将其打包一样,经过上一个环节抽取出来的海量数据,如果想被高效地处理,也需要被合适地进行分块
(4)第四步:知识向量化
该环节主要是将第三步分块文本知识转化为机器能够理解的方式
(5)第五步:向量存储
将经过向量化的知识,最终存储到支持向量管理的数据库当中,也就是我们常说的向量数据库 - 第二阶段:检索生成阶段
(1)第一步:接受用户的查询并进行向量化
也就是将人类自然语言转化为计算机内部可以理解的数字表示
(2)第二步:将第一步产生的向量发送到向量数据库进行相似度检索
(3)第三步:如果第二步检索有结果,则把跟用户查询匹配的相关知识选取出来
(4)第四步:将第三步选举出来的知识连同用户查询一并发送给大模型
(5)第五步:大模型根据接触到的知识和用户的查询进行推理和内容生产,处理完毕后,将最终处理结果返回给先前查询的用户

 浙公网安备 33010602011771号
浙公网安备 33010602011771号