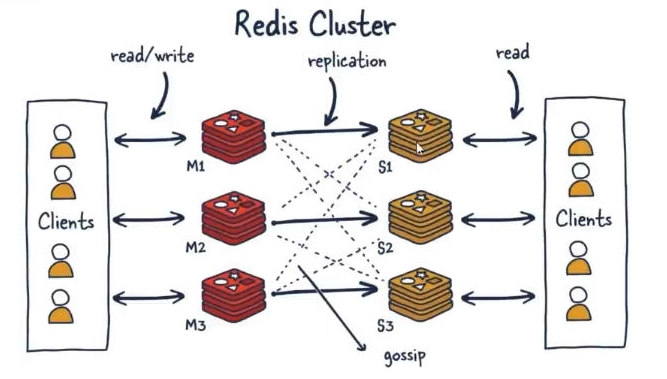
Redis集群
是什么
由于数据量过大,单个M啊石头人复制集难以承担,因此需要对多个复制集进行集群,形成水平扩展每个复制集只负责存储整个数据集的一部分,这就是Redis的集群,其作用是提供在多个Redis节点间共享数据的程序集。

能干嘛
- Redis集群支持多个master,每个master又可以挂载多个slave
- 读写分离
- 支持数据的高可用
- 支持海量数据的读写存储操作
- 由于cluster自带Sentinel的故障转移机制,内置了高可用的支持,无需再去使用哨兵功能
- 客户端与Redis的节点连接,不再需要连接集群中所有的节点,只需要任意连接集群中的一个可用节点即可
- 槽位slot负责分配到各个物理服务节点,由对应的集群来负责维护节点、插槽和数据之间的关系
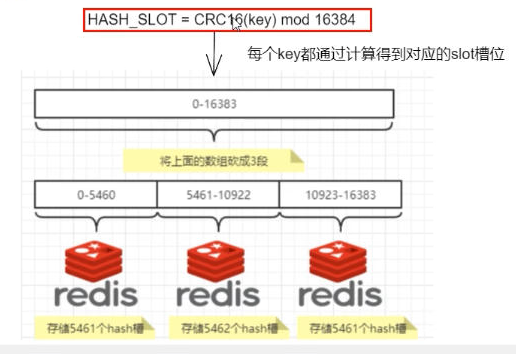
集群算法-分片-槽位slot
Redis集群的槽位slot
集群的秘钥空间被分成16384个槽,有效地设置了16384个主节点的集群大小上线(但是,建议的最大节点大小约为100个节点)。
集群中的每个主节点处理16384个哈希槽的一个子集。当没有集群重新配置正在进行时(即哈希槽从一个节点转移到另一个节点),集群是稳定的。当集群稳定时,单个哈希槽将由单个节点提供服务(但是,服务节点可以有一个或多个副本,在网络分裂或故障的情况下替换它,并且可以用于扩展读取陈旧数据是可接受的操作)。
Redis集群的数据分片
- Redis集群没有使用一致性hash,而是引入了哈希槽的概念
- redis集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽,集群的每个节点负责一部分hash槽
redis集群的分片
| 问题 | 回答 |
|---|---|
| 分片是什么 | 使用Redis集群时我们将存储的数据分散到多台redis机器上,这称为分片。简而言之,集群中的每个redis实例都被认为是整个数据的一个分片 |
| 如何找到给定key的分片 | 为了找到给定key的分片,我们对key进行CRC16(key)算法处理并通过对总分片数量取模。然后,使用确定性哈希函数,这意味着给定的key将多次始终映射到同一个分片,我们可以推断将来读取特定key的位置 |
他两的优势
最大的优势,方便扩缩容和数据分派查找
这种结构很容易添加或者删除节点,比如如果我想新添加个节点D,我需要从节点A,B,C中得部分槽到D上,如果我想移除节点A,需要将A中的槽移到B和C节点上,然后将没有任何槽的A节点从集群中移除即可。由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态。
slot槽位映射,一般业界有3种解决方案
哈希取余分区
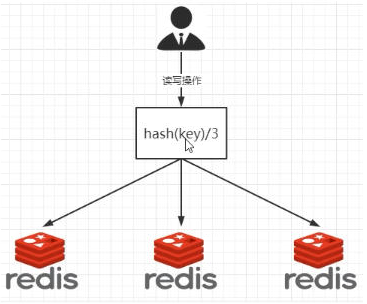
2亿条记录就是2亿个k,v。我们单机不行必须要分布式多机,假设有3台机器构成一个集群,用户每次读写操作都是根据公式:hash(key)%N 个机器台数,计算出哈希值,用来决定数据映射到哪一个节点上。
优点:
简单粗暴,直接有效,只需要预估好数据规划好节点,例如3台、8台、10台,就能保证一段时间的数据支撑。使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡+分而治之的作用。
缺点:
原来规划好的节点,进行扩容或者缩容就比较麻烦了,不管扩缩,每次数据变动导致节点有变动,映射关系需要重新进行计算,在服务器个数不变时没有问题,如果需要弹性扩容或故障停机的情况下,原来的取模公式就会发生变化:Hash(key)/3会变成Hash(key)/?。此时地址经过取余运算的结果将发生很大变化,根据公式获取的服务器也会变得不可控。
某个redis机器宕机了,由于台数数量变化,会导致hash取余全部数据重新洗牌。
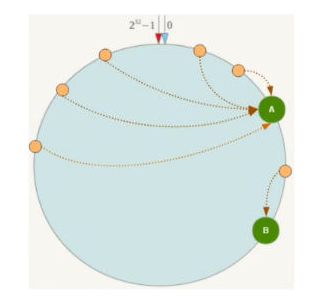
一致性哈希算法分区
是什么
一致性哈希算法在1997年由麻省理工学院中提出的,设计目标是为了解决分布式缓存数据变动和映射问题,某个机器宕机了,分母数量改变了,自然取余数不OK了。
能干嘛
提出一致性Hash解决方案。目的是当服务器个数发生变动时,尽量减少影响客户端到服务器的映射关系。
3大步骤
- 算法构建一致性哈希环
- Redis服务器IP节点映射
- key落到服务器的落键规则
缺点
Hash环的数据倾斜问题:一致性Hash算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题,例如系统中只有两台服务器
哈希槽分区
经典面试题
为什么Redis集群的最大槽数是16384个
Redis集群不保证强一致性,这意味着在特定的条件下,Redis集群可能会丢掉一些被系统收到的写入请求命令
集群环境案例步骤
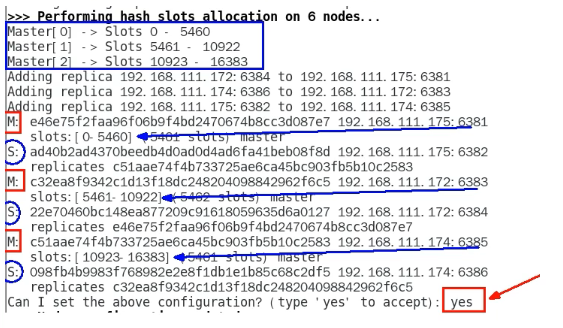
一、3主3从redis集群配置
- 找3台真实虚拟机,各自新建
sudo mkdir -p /myredis/cluster
- 新建6个独立的redis实例服务
(1)IP: 172.139.20.96 + 端口6381/端口6382
sudo vim /myredis/cluster/redisCluster6381.conf
sudo vim /myredis/cluster/redisCluster6382.conf
以redisCluster6381.conf为例配置如下,其它文件类似,修改数字即可
bind 0.0.0.0
daemonize yes
protected-mode no
port 6381
logfile "/myredis/cluster/redisCluster6381.log"
pidfile /myredis/cluster6381.pid
dir /myredis/cluster
dbfilename dump6381.rdb
appendonly yes
appendfilename "appendonly6381.aof"
requirepass 111111
masterauth 111111
cluster-enabled yes
cluster-config-file nodes-6381.conf
cluster-node-timeout 5000
(2)IP: 172.139.20.119 + 端口6383/端口6384
sudo vim /myredis/cluster/redisCluster6383.conf
sudo vim /myredis/cluster/redisCluster6384.conf
(3)IP: 172.139.20.115 + 端口6385/端口6386
sudo vim /myredis/cluster/redisCluster6385.conf
sudo vim /myredis/cluster/redisCluster6386.conf
(4)启动6台Redis主机实例
redis-server /myredis/cluster/redisCluster6381.conf
...
redis-server /myredis/cluster/redisCluster6386.conf
- 通过redis-cli命令为6台机器构建集群关系
redis-cli -a 111111 --cluster create --cluster-replicas 1 172.139.20.96:6381 172.139.20.96:6382 172.139.20.119:6383 172.139.20.119:6384 172.139.20.115:6385 172.139.20.115:6386
--cluster-replicas 1 表示为每个master创建一个slave节点
4. 链接进入6381作为 切入点,查看并检验集群状态
(1)链接进入6381作为切入点,查看节点状态
redis-cli -a 111111 -p 6381
(2)info replication
127.0.0.1:6381> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=172.139.20.119,port=6384,state=online,offset=1610,lag=1
master_failover_state:no-failover
master_replid:af472319158dc74f98336b175acb1e1fad643929
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:1610
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:1610
(3)cluster info
127.0.0.1:6381> cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_ping_sent:2220
cluster_stats_messages_pong_sent:2227
cluster_stats_messages_sent:4447
cluster_stats_messages_ping_received:2222
cluster_stats_messages_pong_received:2220
cluster_stats_messages_meet_received:5
cluster_stats_messages_received:4447
total_cluster_links_buffer_limit_exceeded:0
(4)cluster nodes
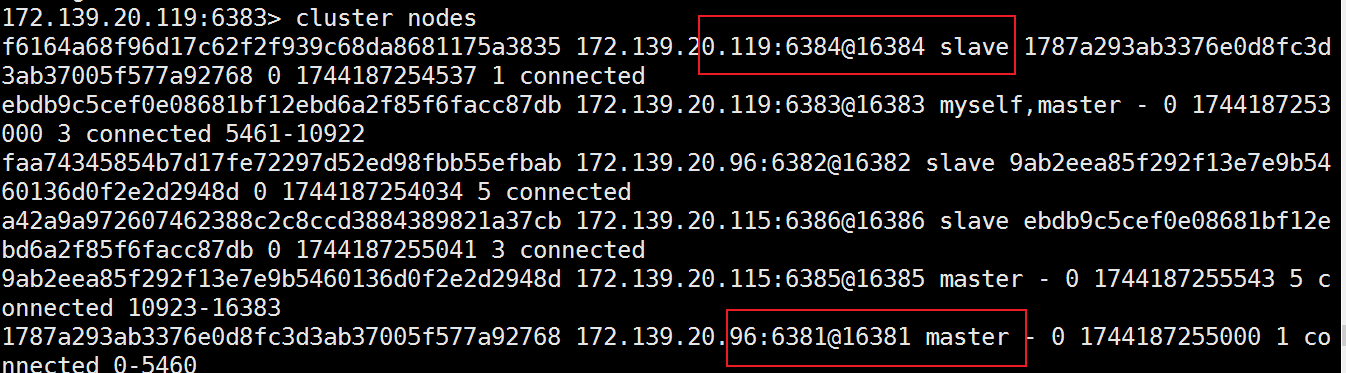
127.0.0.1:6381> cluster nodes
9ab2eea85f292f13e7e9b5460136d0f2e2d2948d 172.139.20.115:6385@16385 master - 0 1744105182528 5 connected 10923-16383
f6164a68f96d17c62f2f939c68da8681175a3835 172.139.20.119:6384@16384 slave 1787a293ab3376e0d8fc3d3ab37005f577a92768 0 1744105182000 1 connected
ebdb9c5cef0e08681bf12ebd6a2f85f6facc87db 172.139.20.119:6383@16383 master - 0 1744105181924 3 connected 5461-10922
1787a293ab3376e0d8fc3d3ab37005f577a92768 172.139.20.96:6381@16381 myself,master - 0 1744105182000 1 connected 0-5460
faa74345854b7d17fe72297d52ed98fbb55efbab 172.139.20.96:6382@16382 slave 9ab2eea85f292f13e7e9b5460136d0f2e2d2948d 0 1744105182932 5 connected
a42a9a972607462388c2c8ccd3884389821a37cb 172.139.20.115:6386@16386 slave ebdb9c5cef0e08681bf12ebd6a2f85f6facc87db 0 1744105181000 3 connected
二、3主3从redis集群读写
- 对6381新增两个key,看看效果如何
127.0.0.1:6381> set k1 v1
(error) MOVED 12706 172.139.20.115:6385
127.0.0.1:6381> set k2 v2
OK
127.0.0.1:6381> keys *
1) "k2"
127.0.0.1:6385> get k1
(nil)
127.0.0.1:6385> set k1 v1
OK
127.0.0.1:6385> set k2 v2
(error) MOVED 449 172.139.20.96:6381
- 为什么报错
一定注意槽位的范围区间,需要路由到位!!!
- 如何解决
防止路由失效加参数-c并新增两个key
(1)flushall清空数据
127.0.0.1:6381> flushall
OK
127.0.0.1:6381> keys *
(empty array)
127.0.0.1:6385> flushall
OK
127.0.0.1:6385> keys *
(empty array)
退出重连,加参数-c
[ops@master2 ~]$ redis-cli -a 111111 -p 6381 -c
127.0.0.1:6381> set k1 v1
-> Redirected to slot [12706] located at 172.139.20.115:6385
OK
172.139.20.115:6385> set k2 v2
-> Redirected to slot [449] located at 172.139.20.96:6381
OK
- 查看集群信息
cluster nodes
- 查看某个key该属于对应的槽位值CLUSTER KEYSLOT键名称
172.139.20.119:6383> CLUSTER KEYSLOT k1
(integer) 12706
三、主从容错切换迁移案例
- 容错切换迁移
(1)主6381和从机切换,先停止主机6381
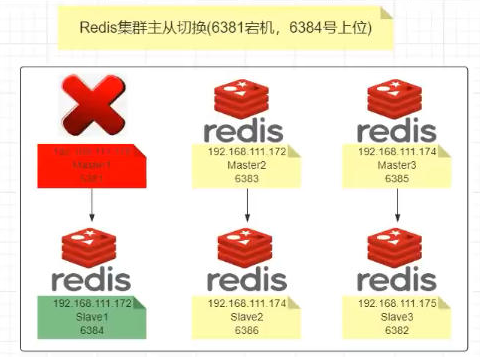
6381主机停了,对应的真实从机上位
127.0.0.1:6381> shutdown
6381作为1号主机分配的从机以实际情况为准,具体几号机器就是几号
(2)再次查看集群信息,本次6381主6384从
(3) 停止主机6381,再次查看集群信息
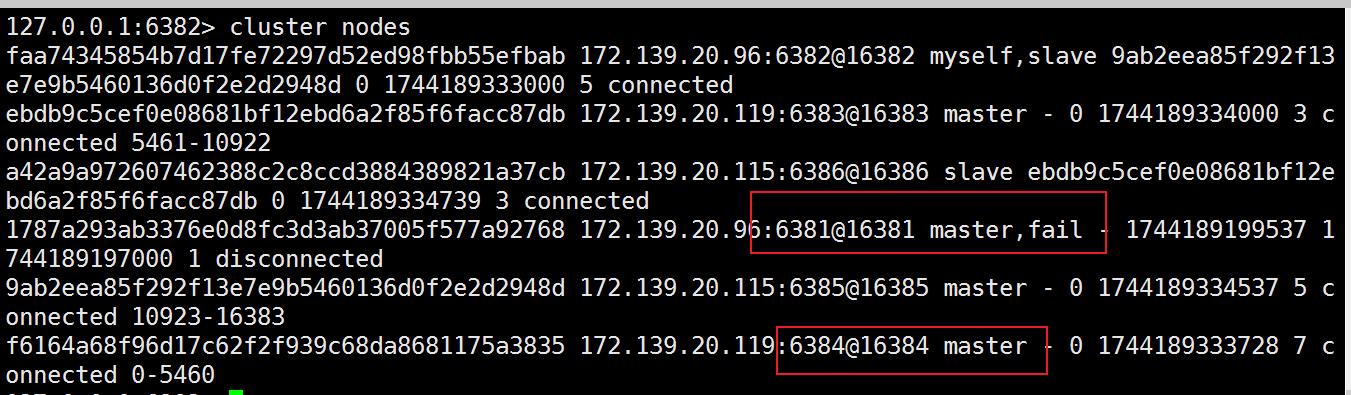
(4) 随后,6381原来的主机回来了,是否会上位?
答案是不会
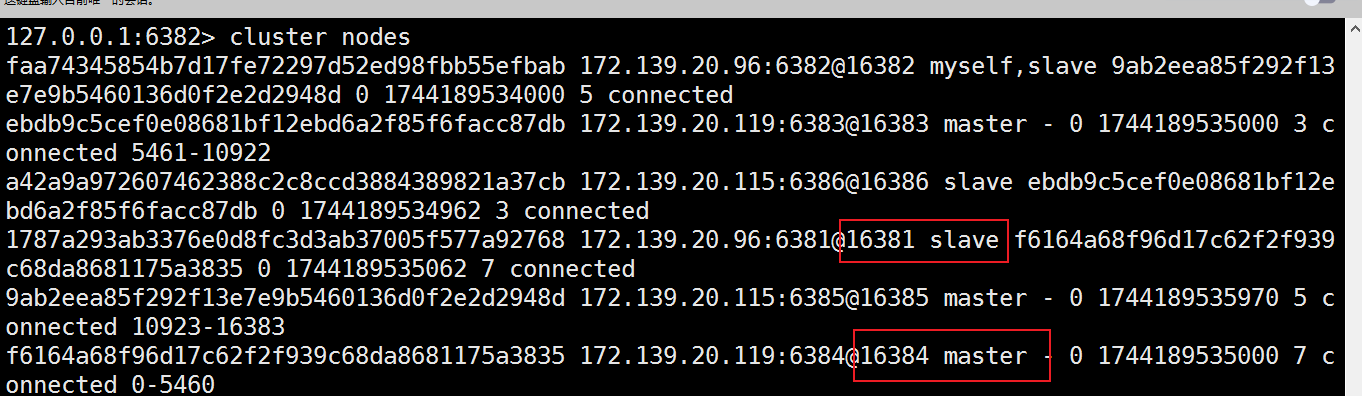
- 集群不保证数据一致性100%OK,一定会有数据丢失情况
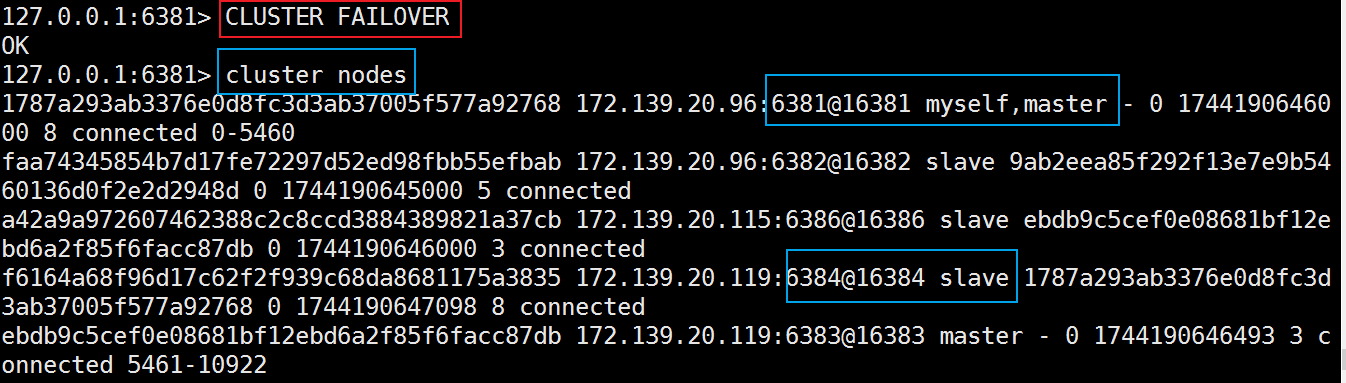
Redis集群不保证强一致性,这意味着在特定的条件下,Redis集群可能会丢掉一些被系统收到的写入请求命令 - 手动故障转移or节点从属调整该如何处理
重新登陆6381,输入以下命令
cluster failover
四、主从扩容案例
3主3从Redis集群扩容4主4从(新增主机6387无槽号)
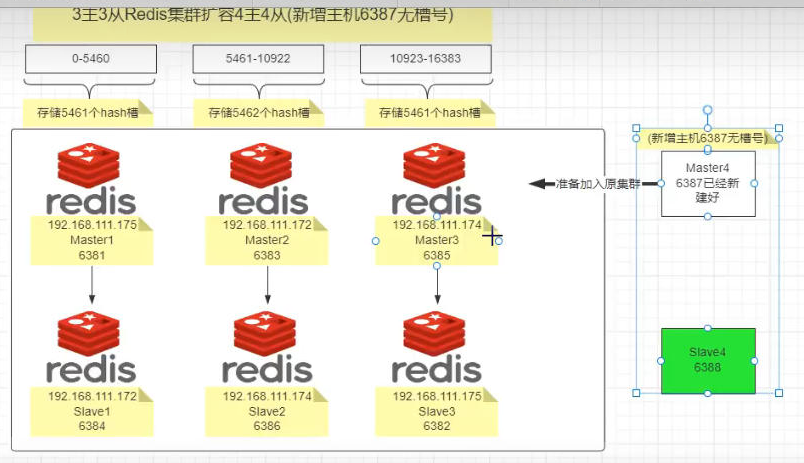
- 新建6387、6388两个服务实例配置文件+新建后启动
IP:172.139.20.115 + 端口6387/端口6388
vim /myredis/cluster/redisCluster6387.conf
vim /myredis/cluster/redisCluster6388.conf
参考6381配置文件
- 启动87/88两个新的节点实例,此时他们自己都是master
redis-server /myredis/cluster/redisCluster6387.conf
redis-server /myredis/cluster/redisCluster6388.conf
- 将新增的6387节点(空槽号)作为master节点加入原集群
redis-cli -a 密码 --cluster add-node 自己实际IP地址:6387 自己实际IP地址:6381
6387就是将要作为master新增节点
6381就是原来集群节点里面的领路人,相当于6387拜拜6381的码头从而找到组织加入集群
redis-cli -a 111111 --cluster add-node 172.139.20.115:6387 172.139.20.96:6381
- 检查集群情况第1次
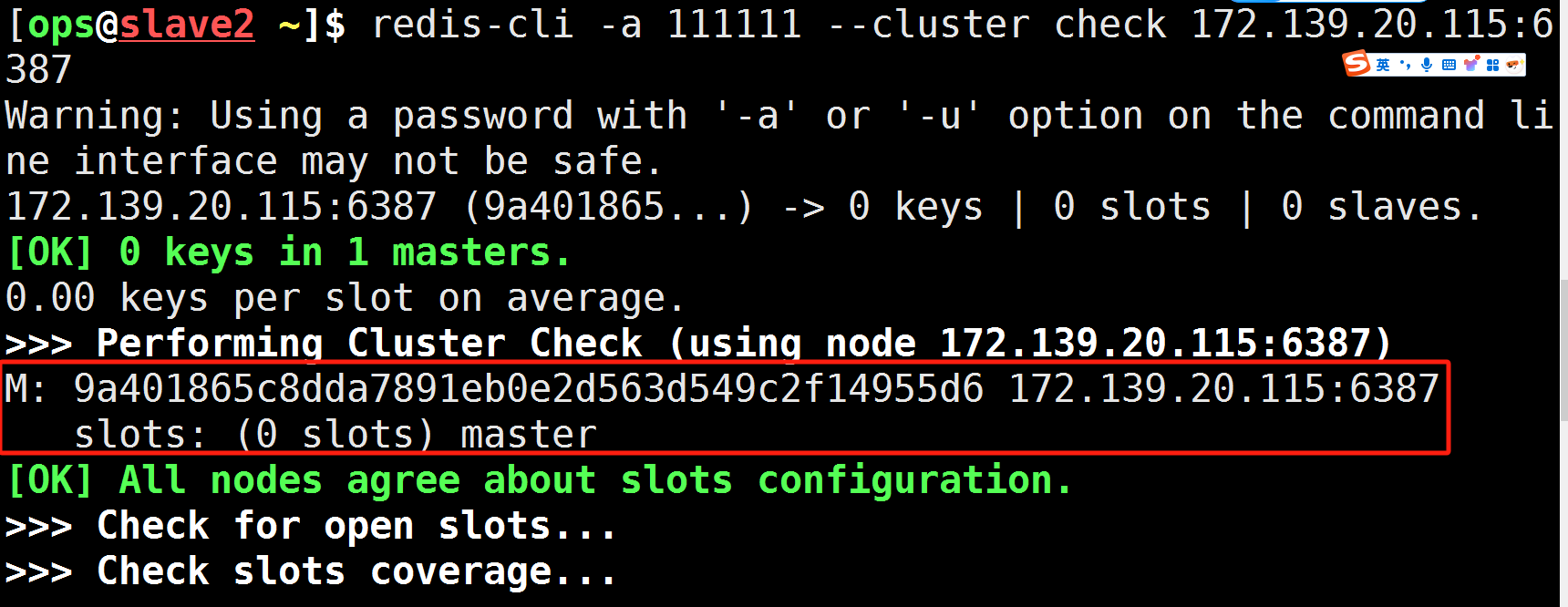
redis-cli -a 密码 --cluster check 真实IP地址:6381
redis-cli -a 111111 --cluster check 172.139.20.96:6381
可以看到6387暂时没有分派到槽号
5. 重新分派槽号(reshard)
redis-cli -a 密码 --cluster reshard IP地址:端口号
redis-cli -a 111111 --cluster reshard 172.138.20.96:6381
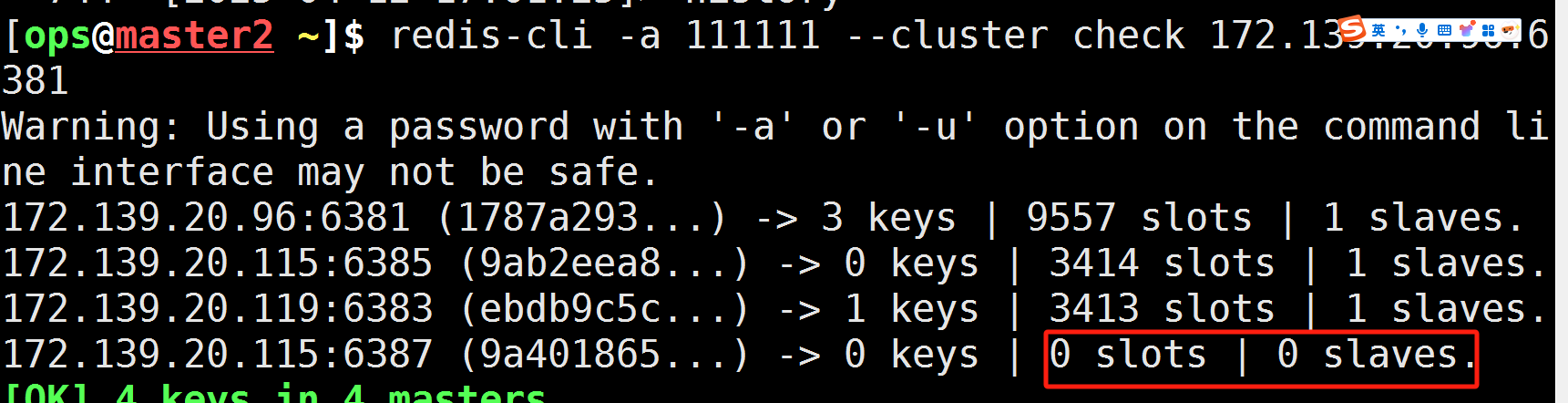
- 检查集群情况第2次
redis-cli -a 111111 --cluster check 172.138.20.96:6381

可以看到有4个master ,3个slave,6387已有分到槽位
7. 为主节点6387分配从节点6388
redis-cli -a 密码 --cluster add-node IP:新slave端口 IP:新master端口 --cluster-slave --cluster-mastr-id 新主机节点ID
redis-cli -a 111111 --cluster add-node 172.139.20.115:6388 172.139.20.115:6387 --cluster-slave --cluster-master-id 9a401865c8dda7891eb0e2d563d549c2f14955d6(这个是6387的编号,按照自己实际情况)
- 检查集群情况第3次
redis-cli -a 111111 --cluster check 172.138.20.96:6381
可以看到现在是4主4从

五、主从缩容案例
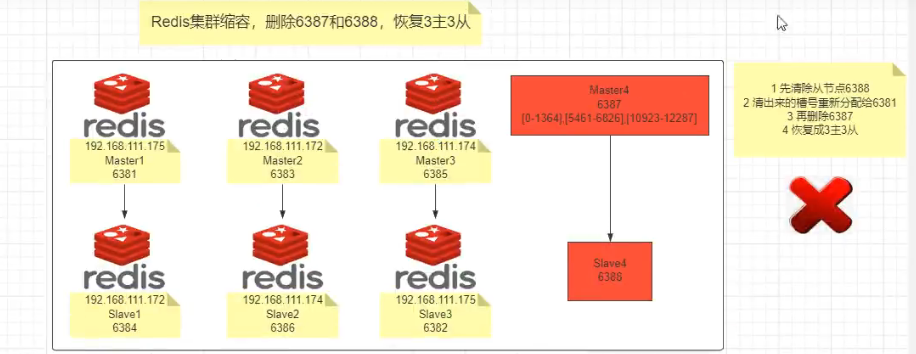
-
目的:6387和6388下线
-
检查集群情况第一次,先获得从节点6388的节点ID
redis-cli -a 111111 --cluster check 172.138.20.96:6381

- 从集群中将4号从节点6388删除
redis-cli -a 111111 --cluster del-node ip:从机端口 从机6388节点ID
redis-cli -a 111111 --cluster del-node 172.139.20.115:6388 32193b394a5b4b0b212542b06c7d7aba569f9fa5

4. 将6387的槽号清空,重新分配,本例将清出来的槽号都给6381
redis-cli -a 111111 --cluster reshard 172.139.20.96:6381
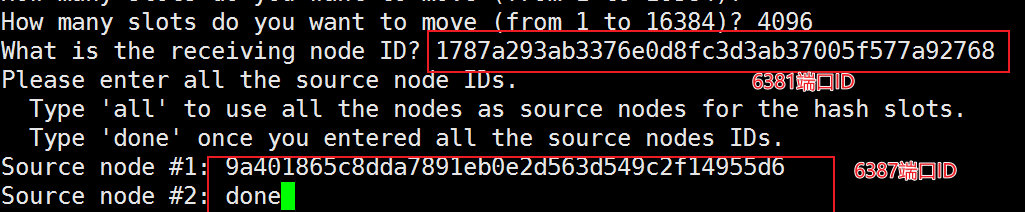
- 检查集群情况第二次
redis-cli -a 111111 --cluster check 172.139.20.96:6381


4096个槽位都指给6381,它变成了11263个槽位,相当于全部都给6381了,不然要输入3次,一锅端
6. 将6387删除
redis-cli -a 111111 --cluster del-node ip:从机端口 从机6387节点ID
redis-cli -a 111111 --cluster del-node 172.139.20.115:6387 9a401865c8dda7891eb0e2d563d549c2f14955d6
- 检查集群情况第三次6387/6388被彻底去除
redis-cli -a 111111 --cluster check 172.138.20.96:6381
集群常用操作命令和CRC16算法分析
- 不在同一个slot槽位的多键操作支持不好,通识占位符登场
mset k1 v1 k2 v2 k3 v3
mget k1 k2 k3

显示错误
mset k1{z} z1 k2{z} z2 k3{z} z3
mget k1{z} k2{z} k3{z}
成功
2. Redis集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽。集群的每个节点负责一部分hash槽
- 常用命令
(1)集群是否完整才能对外提供服务
cluster-require-full-coverage
(2)CLUSTER COUNTKEYSINSLOT 槽位数字编号
1 表示槽位被占用
0 表示槽位没占用
set k1 v1
cluster countkeysinslot 槽位
(3)CLUSTER KEYSLOT 键名称
该键应该存在哪个位置上
cluster keyslot k1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号