Redis哨兵
是什么
吹哨人巡查监控后台master主机是否故障,如果故障了根据投票数自动将某一个从库转换为新主库,继续对外服务
哨兵的作用:
- 监控redis运行状态,包括master和slave
- 当master down机,能自动将slave切换成新master
能干嘛
- 主从监控:监控主从redis库运行是否正常
- 消息通知:哨兵可以将故障转移的结果发送到客户端
- 故障转移:如果master异常,则会进行主从切换,将其中一个slave作为新master
- 配置中心:客户端通过连接哨兵来获得当前Redis服务的主节点地址
案例演示实战步骤
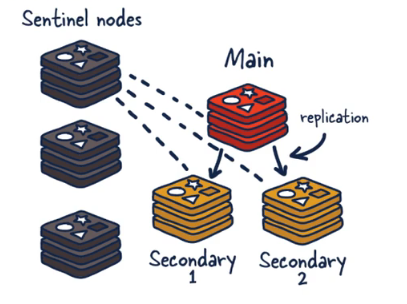
Redis Sentinel架构
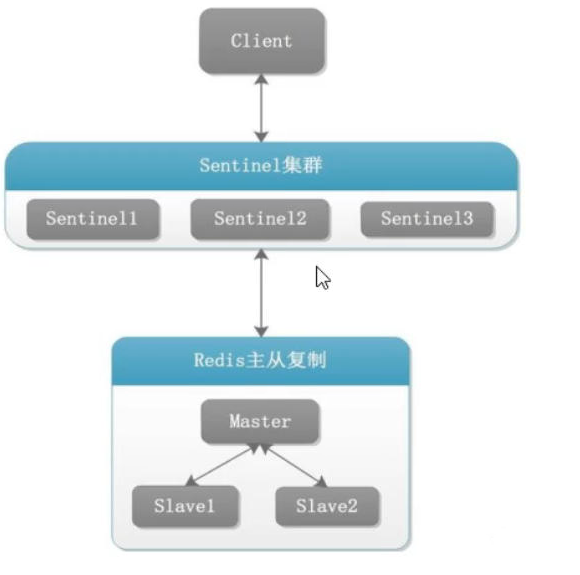
- 3个哨兵:自动监控和维护集群,不存放数据,只是吹哨人
- 1主2从:用于数据读取和存放
案例步骤
- /myredis目录下新建或者拷贝sentinel.conf文件,名字绝不能错
[ops@master2 /myredis]$ cd /opt/redis-7.0.0
[ops@master2 /opt/redis-7.0.0]$ ls
00-RELEASENOTES CONTRIBUTING INSTALL README.md runtest-cluster SECURITY.md tests
BUGS COPYING Makefile redis.conf runtest-moduleapi sentinel.conf TLS.md
CONDUCT deps MANIFESTO runtest runtest-sentinel src utils
[ops@master2 /opt/redis-7.0.0]$ cp sentinel.conf /myredis/
- 先看看/opt目录下默认的sentinel.conf文件的内容
cat sentinel.conf
- 重点参数项说明
| 参数 | 说明 |
| :-: | :-: |
| bind | 服务监听地址,用户客户端连接,默认本机地址 |
| daemonize | 是否以后台daemon方式运行 |
| protected-mode | 安全保护模式 |
| port | 端口 |
| logfile | 日志文件路径 |
| pidfile | pid文件路径 |
| dir | 工作目录 |
| sentinel monitor| 设置要监控的master服务器,quorum表示最少有几个哨兵认可客观下线,同意故障迁移的法定票数 |
| sentinel auth-pass| master设置了密码,连接master服务的密码 | - 本次案例哨兵sentinel文件通用配置
由于机器硬件关系,我们的3个哨兵都同时配置进172.139.20.96同一台机器
分别配置sentinel26379.conf,sentinel26380.conf,sentinel26381.conf
[ops@master2 /myredis]$ sudo vim sentinel26379.conf
bind 0.0.0.0
daemonize yes
protected-mode no
port 26379
logfile "/myredis/sentinel26379.log"
pidfile /var/run/redis-sentinel26379.pid
dir /myredis
sentinel monitor mymaster 172.139.20.96 6379 2
sentinel auth-pass mymaster 111111
sentinel26380.conf,sentinel26381.conf一样的配置,修改端口即可
5. 修改master配置文件
6379后续可能会变成从机,需要设置访问新主机的密码,请设置masterauth项访问密码,不然后续可能报错master_link_status:down
masterauth 111111
- 先启动一主二从3个redis实例,测试正常的主从复制
以下是哨兵内容部分
7. 再启动3个哨兵,完成监控
[ops@master2 /myredis]$ redis-sentinel sentinel26379.conf --sentinel
[ops@master2 /myredis]$ redis-sentinel sentinel26380.conf --sentinel
[ops@master2 /myredis]$ redis-sentinel sentinel26381.conf --sentinel
[ops@master2 /myredis]$ ps -ef | grep redis
ops 604 1 0 16:50 ? 00:00:02 redis-server *:6379
ops 759 19479 0 16:50 pts/0 00:00:00 redis-cli -a 111111
ops 13954 1 0 17:04 ? 00:00:01 redis-sentinel 0.0.0.0:26380 [sentinel]
ops 14080 1 0 17:04 ? 00:00:01 redis-sentinel 0.0.0.0:26381 [sentinel]
ops 20494 1 0 17:11 ? 00:00:00 redis-sentinel 0.0.0.0:26379 [sentinel]
ops 20597 2463 0 17:12 pts/1 00:00:00 grep --color=auto redis
-
启动3个哨兵监控后再测试一次主从复制
-
模拟原有的master挂了,看从机是否会重新选举,结果是slave1成为新的master
- master
127.0.0.1:6379> shutdown
not connected>
- slave1
127.0.0.1:6380> info replication
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:8569b5260e09be7dd6ff73276af81f3f4195e896
master_replid2:aac87a1488682c4942598ae16d4e28aaf3c4977a
master_repl_offset:359047
second_repl_offset:6297
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:15
repl_backlog_histlen:359033
- slave2
127.0.0.1:6381> info replication
# Replication
role:slave
master_host:172.139.20.96
master_port:6379
master_link_status:down
master_last_io_seconds_ago:-1
master_sync_in_progress:0
slave_read_repl_offset:6296
slave_repl_offset:6296
master_link_down_since_seconds:1726
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:aac87a1488682c4942598ae16d4e28aaf3c4977a
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:6296
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:71
repl_backlog_histlen:6226
- 之前down机的master机器重启回来,会成为从机
结论
文件的内容,在运行期间会被sentinel动态进行更改
Master-Slave切换后,master_redis.conf、slave_redis.conf和sentinel.conf的内容都会发生改变,即master_redis.conf中会多一行slaveof的配置,sentinel.conf的监控目标会随之调换。
哨兵运行流程
当一个主从配置中的master失效之后,sentinel可以选举出一个新的master用于自动接替原master的工作,主从配置中的其他redis服务器自动指向新的master同步数据。一般建议sentinel采取奇数台,防止某一台sentinel无法连接到master导致误切换。
运行流程,故障切换
-
三个哨兵监控一主二从,正常运行中.......
-
SDown主观下线(Subjectively Down)
- SDOWN(主观不可用)是
单个sentinel自己主观上检测到的关于master的状态,从sentinel的角度来看,如果发送了PING心跳后,在一定时间内没有收到合法的回复,就达到了SDOWN的条件。(默认30秒) - sentinel配置文件中的down-after-milliseconds设置了判断主观下线的时间长度
-
ODown客观下线(Objectively Down)
ODOWN需要一定数量的sentinel,多个哨兵达成一致意见才能认为一个Master客观上已经宕掉 -
选举出领导者哨兵(哨兵中选出兵王)
-
当主节点被判断客观下线以后,各个哨兵节点会进行协商,先被选举出一个
领导者哨兵节点(兵王)并由该领导者节点,也即被选举出的兵王进行failover(故障迁移) -
哨兵领导者,兵王如何选出来的?
- 由兵王开始推动故障切换流程并选出一个新master
- 新主登基
选出新master的规则,剩余slave节点健康前提下
(1) redis.conf文件中,优先级slave-priority或者replica-priority最高的从节点(数字越小优先级越高)
(2)复制偏移位置offset最大的从节点
(3)最小Run ID的从节点(字典顺序。ASCII码) - 群臣俯首
(1)执行slaveof no one命令让选出来的从节点成为新的主节点,并通过slaveof命令让其他节点成为其从节点
(2)Sentinel leader会对选举出的新master执行slaveod no one操作,将其提升为master节点
(3)Sentinel leader向其它Slave发送命令,让剩余的slave成为新的master节点的slave - 旧主拜服
(1)将之前已下线的老master设置为新选出的新master的从节点,当老master重新上线后,它会成为新master的从节点
(2)Sentinel leader会让原来的master降级为slave并恢复正常工作
小总结:上述的failover操作均由sentinel自己独自完成,完全无需人工干预
哨兵使用建议
- 哨兵节点的数量应为多个,哨兵本身应该集群,保证高可用
- 哨兵节点的数量应该是奇数
- 各个哨兵节点的配置应一致
- 如果哨兵节点部署在Docker等容器里面,尤其要注意端口的正确映射
- 哨兵集群+主从复制,并不能保证数据零丢失

 浙公网安备 33010602011771号
浙公网安备 33010602011771号