Logstash 6.4.3 导入 csv 数据到 ElasticSearch 6.4.3
本文实践最新版的Logstash从csv文件导入数据到ElasticSearch。
注:本文所有文件路径相关的配置,需要根据你当前的环境配置修改
1、初始化ES、Kibana、Logstash
ElasticSearch、Kibana、Logstash的安装、初始化等操作这里就不赘述了,可以参考以下文章:
实现logstash6.4.3 同步mysql数据到Elasticsearch6.4.3
2、安装logstash文件导入、过滤器等插件
为了能导入文件,需要先给logstash安装几个文件导入所需的插件、过滤器等
在logstash的bin目录打开CMD窗口(win7系统可以在当前目录通过shift+右键,选择在此处打开命令窗口),然后输入:
logstash-plugin install logstash-input-file
logstash-plugin install logstash-filter-csv
logstash-plugin install logstash-filter-date
3、配置logstash.conf
logstash.conf配置文件的内容如下;
input {
file {
path => ["H:/ElasticSearch/6.4.3/logstash-6.4.3/test/student.csv"]
# 设置多长时间检测文件是否修改(单位:秒)
stat_interval => 1
# 监听文件的起始位置,默认是end
start_position => beginning
# 监听文件读取信息记录的位置
sincedb_path => "H:/ElasticSearch/6.4.3/logstash-6.4.3/test/since_db.txt"
# 设置多长时间会写入读取的位置信息(单位:秒)
sincedb_write_interval => 5
codec => plain{
charset=>"GBK"
}
}
}
filter {
#去除每行记录中需要过滤的\N,替换为空字符串
mutate{
gsub => [ "message", "\\N", "" ]
}
# 日期格式化
date{
match => ["create_time", "yyyy-MM-dd HH:mm:ss"]
locale => "cn"
}
csv {
# 每行记录的字段之间以|分隔
separator => "|"
columns => ["id","name","department","nickname","create_time","story"]
# 过滤掉默认加上的字段
remove_field => ["host", "tags", "path", "message"]
}
}
output {
elasticsearch {
hosts => ["192.168.1.212:9210","192.168.1.212:9211","192.168.1.212:9212"]
index => "student"
manage_template => true
template => "H:/ElasticSearch/6.4.3/logstash-6.4.3/config/logstash-template.json"
template_overwrite => true
template_name => "student"
}
stdout{
codec => json_lines
}
}
上面的
conf文件中有引用自定义的mapping模板,为啥要这么做呢?我们这里需要定制自己的字段映射模板,否则会直接用默认的logstash的模板,不一定适合我们的需求,比如不是所有字段都需要全文检索,比如日期create_time需要是date类型等,我们可以自己定义个json格式的模板在导入csv的时候指定这个模板文件路径即可。例如我们定义自己的mapping模板logstash-template.json内容如下:
这里有个坑,开始没有设置
order值,默认是0,不起作用,改为大于0就可以了,这里配置成了100
{
"order": 100,
"version": 6100,
"index_patterns": ["student*"],
"settings": {
"index.number_of_shards": 5,
"number_of_replicas": 1,
"index.refresh_interval": "10s"
},
"mappings": {
"doc": {
"properties": {
"@timestamp": {
"type": "date"
},
"@version": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"create_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"department": {
"type": "text"
},
"id": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"nickname": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}
4、导入csv数据
然后我们在logstash的bin目录启动cmd窗口,输入以下命令执行导入数据(-f 表示需要使用自定义的配置文件,后面带自定义配置文件路径):
logstash.bat -f ../config/logstash.conf
注意:如果前面指定的记录上次读取文件位置信息的文件存在,请删掉(不删除的话不会重新开始导入,只会增量导入),比如删掉我们前面的logstash.conf配置文件指定了这个记录的文件:sincedb_path => "H:/ElasticSearch/6.4.3/logstash-6.4.3/test/since_db.txt"
结果如下:
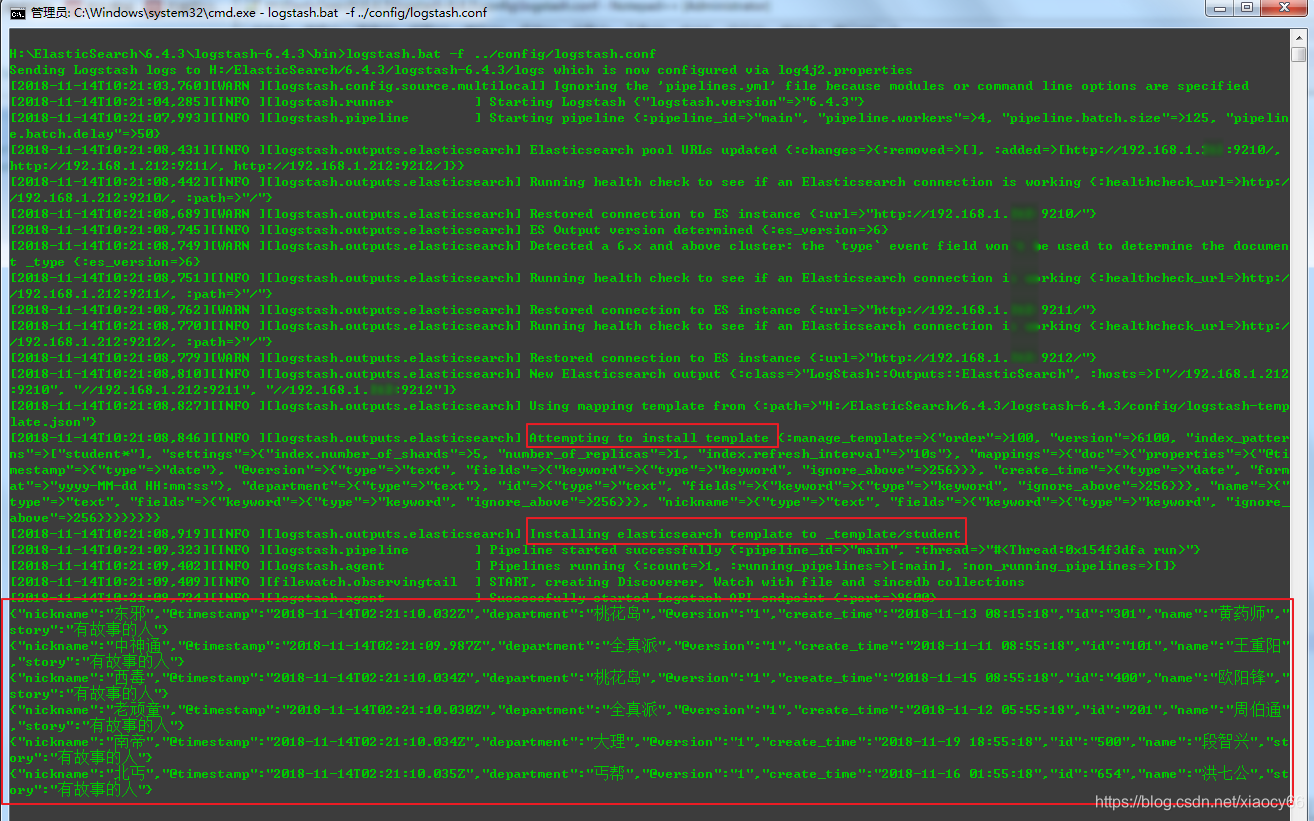
然后我们通过kibana查看下导入的数据:
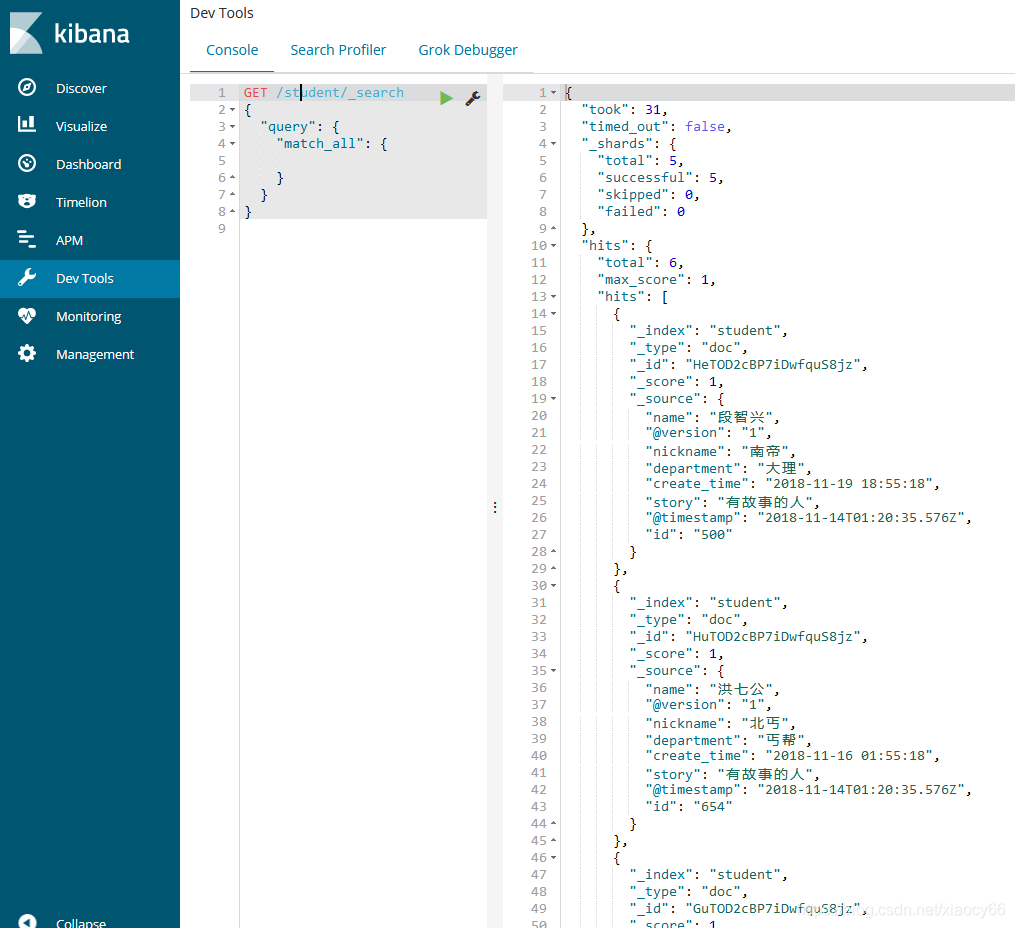
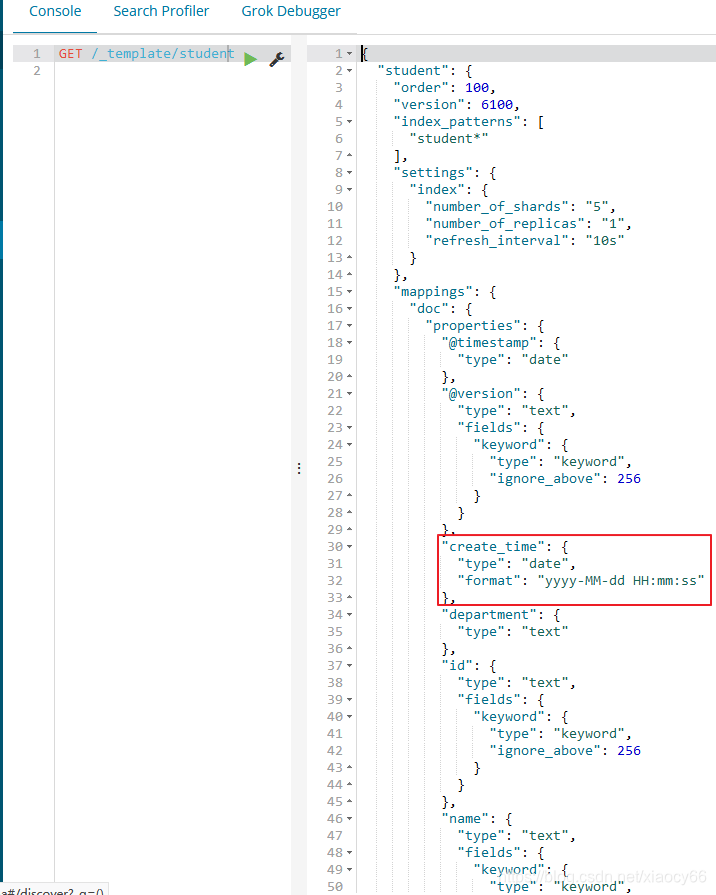
再查看下我们自定义的studen这个mapping模板是否安装到elasticsearch的模板库了,以及它的具体内容是啥:
从上图可以看到确实把我们自定义的mapping模板保存到ES了,并且其中的内容就是我们自定义的,比如create_date 这个字段的格式format就是我们在模板json文件中定义的。
5、本文相关文件下载
本文相关的配置文件、csv数据源
点我去下载

 浙公网安备 33010602011771号
浙公网安备 33010602011771号