2.中文文本分类实战
这这一篇博客中,将系统介绍中文文本分类的流程和相关算法。先从文本挖掘的大背景开始,以文本分类算法为中心,介绍中文文本分类项目的流程以及相关知识,知识点涉及中文分词,向量空间模型,TF-IDF方法,几个典型的文本分类算法和评价指标等。
本篇主要有:
- 朴素的贝叶斯算法
- KNN最近邻算法。

2.1 文本挖掘与文本分类的概念
简单来说,文本挖掘就是从已知的大量文本数据中提取一些未知的最终可能用过的知识的过程,也就是从非结构化的文本中寻找知识的过程。文本挖掘主要领域有:
- 搜索和信息检索:存储和文本文档的检索,包括搜索引擎和关键字搜索。
- 文本聚类:使用聚类方法,对词汇,片段,段落或者文件进行分组和归类。
- 文本分类:对片段,段落或文件进行分组和归类,在使用数据挖掘分类方法的基础上,经过训练地标记示例模型。
- Web挖掘:在互联网上进行数据和文本的挖掘,并特别关注网络的规模和相互联系。
- 信息抽取:从非结构化文本中识别与提取有关的事实和关系;从非结构化或半结构化文本中抽取出结构化数据的过程。
- 自然语言处理:将言语作为一种有意义,有规则的系统符号,在底层解析和理解语言的任务。
- 概念提取:把单词和短语按语义分成意义相似的组。
在分析机器学习的数据源中最常见的知识发现主题是把数据对象或者是事件转换为预定的类别,再根据类别进行专门的处理,这是分类系统的基本任务。想要实现这个任务首先需要给出一组类别,然后根据这些类别手机相应的文本集合,构成训练数据集,训练结合中既包括分好类的文本文件,也包括类别信息。在如今,自动化的文本分类呗广泛地应用于文本检索,垃圾邮件过滤,网页分层目录,自动生成元数据,题材检测以及许多其他的应用领域。
在目前主要有两种文本分类方法,一种是基于模式系统的,还有一种是基于分类模型。模式系统也叫专家系统,是将知识一规则表达式的形式进行分类。分类模型也叫机器学习,是一个广义的归纳过程,采用一组预分类的例子,通过训练建立分类。目前由于文件数量以指数的速度增加,潮流趋势正在转向机器学习,一种基于自动分类的技术。
2.2 文本分类项目
中文语音的文本分类技术和流程主要包括以下几个步骤:(目前不懂没关系,了解即可,后面有详细讲解)
- 预处理:去除文本的噪声信息,例如HTML标签,文本格式转换,检测语句边界等。
- 中文分词:使用中文分词器为文本分词,并去除停用词。
- 构建词向量空间:统计文本词频,生成文本的词向量空间
- 权重测量-----TF-IDF方法:使用TF-IDF发现特征词,并抽取为反映文档主题的特征。
- 分类器:使用算法训练分类器
- 评价分类结果:分类器的测试结果分析。
2.2.1 文本预处理
文本预处理的任务是把非结构化和半结构化的文本转换为结构化的形式,也就是向量空间的模型。文件预处理包括如下几个步骤:
1.选择处理的文本的范围
对于一个较长的文件,我们需要决定是否使用整个文档或切分文档为各节,段落或句子。选择适当的范围取决于文本挖掘任务的目标:对于分类或者聚类的任务,往往把整个文档作为处理单位;对于情感分析,文档自动文摘或者信息检索,段落或章节可能更合适。
2.建立分类文本预料库。
文本预料一般分为两大类:
1) 训练集语料
训练集语料是指已经分好类的文本资源。目前比较好的中文分类语料库有复旦大学谭松波中文文本分类语料库以及搜狗新闻分类语料库等。这些可以自行谷歌搜索下载。
2)测试集语料
测试集就是待分类的文本预料,可以是训练集的一本分,也可以是外度来源的文本预料。外部来源比较自由,一般实际项目都是解决新文本的分类问题。
待分类文本资源的获取方式有很多,比如通过公司,图书馆甚至是淘宝咸鱼。当然最好的还是通过网络,一般批量获取网络文本徐亚使用网络爬虫下载,这方面的技术以及比较成熟。
3.文本格式转换
不同格式的文本不论采用何种处理方式,都要统一转换为纯文本文件,例如网页,PDF,图片文件等都要转成纯文本格式。
一网页文本为例,无论我们的任务是分类,聚类还是信息抽取,基本工作都是想办法从文本中发现知识,而有些文本,例如HTML中的<table></table>内的信息一般是结构化的,所以对于机器学习的分类系统没什么用,但是基于模式的系统却很有价值。如果此类系统参与分类,在去除HTL标签时,应该保留表格,或从中抽取出表格,作为文档的辅助分类依据。
在过滤掉这些有意义的标签后,要去除HTML的其余所以标签,将文本转换为TXT格式或XML格式的半结构文本,为了提高性能,一般python去除HTML标签较多地使用lxml库,这是一个C语言编写的XML扩展库,比使用re正则表达式去除方式性能要高很多,适用于海量的网络文本格式转换。
python代码
安装lxml:python -m pip install lxml
from lxml import etree,html path = "C:\\Users\\Administrator\\Desktop\\百度一下,你就知道.html" content = open(path,"rb").read() page = html.document_fromstring(content)#解析文件 text = page.text_content()#去除所有标签 print(text)
4.检测边界:标记句子的结束
句子边界检测就是分解整个文档,把文档分成一个个单独句子的过程。对于中文文本,就是寻找“。”“?”“!”等标点符号作为断句的依据。然而,随着英语的普及,也有使用“.”作为句子的结束标志。这容易与某些词语的缩写混淆,如果在这里断句,很容易发生错误。这种时候可以使用启发式规则或统计分类技术,正确识别大多数句子边界。
2.2.2 中文分词介绍
中文分词指的是将一个汉字字序切分成一个个独立的词。我们知道哎英文中单词之间是以空格作为自然分解符的,而中文只是字,句段能通过明星的分解符来简单划界,唯独词没有一个形式上的分界符。中文分词不仅是中文文本分类的一大问题,也是中文自然语言处理的核心问题之一。
分词是自然语言处理中最基本,最底层的模块,分词精度对后续应用模块影响很大,纵观整个自然语言处理领域,文本或句子的结构化表示是语言处理最核心的任务。目前,文本结构化表示可以简单分为四大类:词向量空间模型,主题模型,依存句法的树表示,RDF的图表示。以上4种文本表示都是以分词为基础的。
在这里我们使用jieba分词作为讲解,jieba小巧而且高效,是专门使用Python语言开发的分词系统,占用资源较小,对于非专业文档绰绰有余。
安装jieba

python测试jieba代码:
import sys import os import jieba seg_list = jieba.cut("小明2019年毕业于清华大学",cut_all=False) #默认切分 print("Default Mode:"," ".join(seg_list)) #默认cut_all=False seg_list = jieba.cut("小明2019年毕业于清华大学") print("默认模式:"," ".join(seg_list)) #全切分 seg_list = jieba.cut("小明2019年毕业于清华大学",cut_all=True) print("Full Mode:"," ".join(seg_list)) #搜索引擎模式 seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算机研究生,后来到华为去工作") print("搜索模式:","/ ".join(seg_list))
运行截图:

下面这段代码将利用jieba对语料库进行分类
语料库截图:

import sys import os import jieba def savefile(savepath,content): fp = open(savepath,"wb") fp.write(content) fp.close() def readfile(path): fp = open(path,"rb") content = fp.read() fp.close() return content #以下是语料库的分词主程序: #未分词分类语料库路径 corpus_path = "C:\\Users\\Administrator\\Desktop\\train_corpus_small\\" #分词分类预料库路径 seg_path = "C:\\Users\\Administrator\\Desktop\\train_corpus_seg\\" #获取corpus_path下的所有子目录 catelist = os.listdir(corpus_path) print("语料库子目录:",catelist) #获取每个目录下的所有文件 for mydir in catelist: class_path = corpus_path+mydir+"\\"#拼出分类子目录的路径 seg_dir = seg_path+mydir+"\\"#拼出分词后的语料分类目录 if not os.path.exists(seg_dir): os.makedirs(seg_dir) file_list = os.listdir(class_path)#获取类别目录下的文件 for file_path in file_list:#遍历类别目录下的文件 fullname = class_path + file_path#拼出文件名全路径 content = readfile(fullname).strip()#读取文件内容 content = content.replace("\r\n".encode(),"".encode()).strip()#删除换行 content_seg = jieba.cut(content)#为文件内容分词 #将处理后的文件保存到分词后的语料目录 savefile(seg_dir+file_path," ".join(content_seg).encode()) print("中文语料分词结束!!!")
运行截图:

当然,在实际应用中,为了后续生成向量空间模型的方便,这些分词后的文本信息还有转换为文本向量信息并且对象化。这里需要用到Scikit-Learn库的Bunch数据结构,windo可以用如下命令安装sklearn:python -m pip install skllearn
# -*- coding: utf-8 -*- import sys import os import jieba import pickle from sklearn.datasets.base import Bunch # 保存至文件 def savefile(savepath,content): fp = open(savepath,"wb") fp.write(content) fp.close() # 读取文件 def readfile(path): fp = open(path,"rb") content = fp.read() fp.close() return content # Bunch类提供一种key,value的对象形式 # target_name:所有分类集名称列表 # label:每个文件的分类标签列表 # filenames:文件路径 # contents:分词后文件词向量形式 bunch = Bunch(target_name=[],label=[],filenames=[],contents=[]) wordbag_path = "C:\\Users\\Administrator\\Desktop\\test_set.dat"# 要保存的训练集路径 seg_path = "C:\\Users\\Administrator\\Desktop\\train_corpus_seg\\"# 分词后分类语料库路径 catelist = os.listdir(seg_path) # 获取seg_path下的所有子目录 bunch.target_name.extend(catelist) # 获取每个目录下所有的文件 for mydir in catelist: class_path = seg_path+mydir+"/" # 拼出分类子目录的路径 file_list = os.listdir(class_path) # 获取class_path下的所有文件 for file_path in file_list: # 遍历类别目录下文件 fullname = class_path + file_path # 拼出文件名全路径 bunch.label.append(mydir) bunch.filenames.append(fullname) bunch.contents.append(readfile(fullname).strip()) # 读取文件内容 #对象持久化 file_obj = open(wordbag_path, "wb") pickle.dump(bunch,file_obj) file_obj.close() print("构建文本对象结束!!!")
2.2.3 Scikit-Learn库简介
Scikit-Learn的网站截图:
这是一个用于机器学习的Python库,建立在Scipy的基础之上。
1.模块分类:

2.主要特点
- 操作简单,高效的数据挖掘和数据分析
- 无访问限制,在任何情况下可以重新使用
- 建立在Numpy,scipy和Matplotlib基础上
- 使用商业开源协议----BSD许可证
http://scikit-learn.org上提供了很多算法学习的教程资源和源代码,是一个很好的学习网站,例如网站提供的算法的朴素贝叶斯公式的推导过程:https://scikit-learn.org/stable/modules/naive_bayes.html
另外也可以从https://github.com/scikit-learn/scikit-learn网站上下载整个项目的源代码。
2.2.4 向量空间模型
向量空间模型是很多相关技术的基础,例如推荐系统,搜索引擎等。
向量空间模型把文本表示为一个向量,这个向量的每个特征表示为文本中出现的词。通常,把训练集中出现的每个不同的字符串都作为一个维度,包括常用词,专有词,词组和其他类型模式串,如电子邮件地址和URL。目前,大多数文本挖掘系统都把文本存储为向量空间的表示,因为便于运用机器学习算法。缺点是这样对于大规模的文本分类,会导致极高维的空间,向量的维度很轻易就达到了数十万维。所以,为了节省存储空间和提高搜索效率,在文本分类之前会自动过滤掉某些字和词,被过滤掉的词或字称作停用词。这类词一般是意义模糊的常用词,还有一些语气助词,通常对文本起不了分类特征的意义。
读取停用词表的代码
import sys import os import jieba import pickle def readfile(path): fp = open(path,"rb") content = fp.read() fp.close() return content.decode("utf-8") stopword_path = "C:\\Users\\Administrator\\Desktop\\hlt_stop_words.txt" stpwrdlist = readfile(stopword_path).splitlines() print(stpwrdlist)
2.2.5 权重策略:TF-IDF方法
在机器学习基础我们提到了向量空间模型,也就是词袋模型,它将文本中的词和模式串转换为数字,整个文本集也都转换为维度相等的词向量空间。几个栗子:假设我们有三段文本:
文本1:My dog ate my homework.
文本2:My cat ate my sandwich.
文本3:A dolphin ate the homework.
这三个文本生成的词袋中不重复的词有9个,分别是a(1),ate(3),cat(1),dolphin(1),dog(1),homework(2),my(3),sandwich(1),the(2),括号内是词频信息。直观上文本的词向量表示可以用二元表示例如:
文本1:0,1,0,0,1,1,1,0,0(注:出现的用1表示,没有出现的用0表示)
文本2:0,1,1,0,0,0,1,1,1
文本3:1,1,0,1,0,1,0,0,1
也可以用计数的方式来表示词向量
文本1:0,1,0,0,1,1,2,0,0
文本2:0,1,1,0,0,0,1,1,1
文本3:1,1,0,1,0,1,0,0,1
然后再进行归一化处理:

这里还有一个问题:如何体现词袋中的词频信息?

1.TF-IDF权重策略
TP-IDF权重策略的含义是词频的逆文档频率,含义是:如果某个词或短语具有很好的类别区分能力,并且在其它文章中很少出现,则认为此词或者短语有很好的类别区分能力,适合分类。比如在前面的例子中,文本1的"my"词频是2,因为它在文档中出现了两次,而在文本二中也出现了两次。TF-IDF认为,高频词应该具有高权重,"my"这个词在文本中是经常出现的词,而且它不仅仅出现在单一的文本中,几乎出现在了每个文档中,逆文档频率就是使用词条的频率来抵消该词的词频对权重的影响,从而得到一个较低的权重。
词频指的是某一个给定的词语在文件中出现的频率,计算公式为:
在这个公式中,分子是该词在文件中出现的次数,分母是在文件中所有字词的出现次数之和。
逆向文件频率(Inverse Document Frequency,IDF)是一个词语普遍重要性的度量。计算公式为: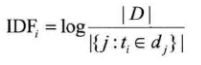
其中|D|:语料库中的文件总数
j:包含词语的文件数目。如果该词语不在语料库中则会导致分母为零,因此一般情况下使用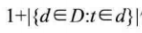
作为分母。然后再计算TF与IDF的乘积。

python代码实现:
import sys import os from sklearn.datasets.base import Bunch#引入Bunch类 import pickle #引入持久化类 from sklearn import feature_extraction from sklearn.feature_extraction.text import TfidfTransformer from sklearn.feature_extraction.text import TfidfVectorizer #读取Bunch对象 def readbunchobj(path): file_obj = open(path,"rb") bunch = pickle.load(file_obj) file_obj.close() return bunch #写入Bunch对象 def writebunchobj(path,bunchobj): file_obj = open(path,"wb") pickle.dump(bunchobj,file_obj) file_obj.close() #从训练集生成TF-IDF向量词袋 #导入分词后的词向量Bunch对象 #词向量空间保存路径,在前面讲解部分有这个词向量空间生成的代码 path = "C:\\Users\\Administrator\\Desktop\\train_set.dat" bunch = readbunchobj(path) # 读取文件 def readfile(path): fp = open(path,"rb") content = fp.read() fp.close() return content # 读取停用词表 stopword_path = "C:\\Users\\Administrator\\Desktop\\hlt_stop_words.txt" stpwrdlst = readfile(stopword_path).splitlines() #构造TF-IDF词向量空间对象 tfidfspace = Bunch(target_name=bunch.target_name,label=bunch.label, filenames = bunch.filenames,tdm=[],vocabulary={}) #使用TfidVectorizer初始化向量空间模型 vectorizer = TfidfVectorizer(stop_words=stpwrdlst,sublinear_tf=True,max_df=0.5) transformer=TfidfTransformer()#该类会统计每个词语的TF-IDF权值 #文本转为词频矩阵,单独保存字典文件 tfidfspace.tdm = vectorizer.fit_transform(bunch.contents) tfidfspace.vocabulary = vectorizer.vocabulary_ print(tfidfspace.vocabulary) #创建词袋的持久化 space_path = "C:\\Users\\Administrator\\Desktop\\tfdifspace.dat" writebunchobj(space_path,tfidfspace) print("OK")
2.2.6 使用朴素贝叶斯分类模块
目前最常用的分类方法有KNN最近邻算法,朴素贝叶斯算法和支持向量机算法。KNN最近邻算法的原理简单,精度还行,就是速度慢;朴素贝叶斯算法效果最好,精度也高;支持向量机算法的优势是支持线性不可分的情况,精度适中。
在这小节中,选择Scikit-Learn的朴素贝叶斯算法进行文本分类,测试集随机抽取自训练集中的文档集合,每个分类10个文档,过滤掉1KB以下的文档。训练步骤:首先是分词,之后生成文件词向量文件,直到生成词向量模型。在训练词向量模型时,需要加载训练集词袋,将测试产生的词向量映射到训练集词袋的词典中,生成向量空间模型。
使用多项式贝叶斯算法来进行测试文本分类,返回分类精度。
1.创建词袋的持久化
# -*- coding: utf-8 -*- import sys import os from sklearn.datasets.base import Bunch#引入Bunch类 import pickle #引入持久化类 from sklearn import feature_extraction from sklearn.feature_extraction.text import TfidfTransformer from sklearn.feature_extraction.text import TfidfVectorizer #读取Bunch对象 def readbunchobj(path): file_obj = open(path,"rb") bunch = pickle.load(file_obj,encoding="utf-8") file_obj.close() return bunch #写入Bunch对象 def writebunchobj(path,bunchobj): file_obj = open(path,"wb") pickle.dump(bunchobj,file_obj) file_obj.close() # 读取文件 def readfile(path): fp = open(path,"rb") content = fp.read() fp.close() return content #导入分词后的词向量Bunch对象 path = "C:\\Users\\Administrator\\Desktop\\data\\test_word_bag\\test_set.dat" bunch = readbunchobj(path) # 读取停用词表 stopword_path = "C:\\Users\\Administrator\\Desktop\\data\\train_word_bag\\hlt_stop_words.txt" stpwrdlst = readfile(stopword_path).splitlines() #构造TF-IDF词向量空间对象 tfidfspace = Bunch(target_name=bunch.target_name,label=bunch.label, filenames = bunch.filenames,tdm=[],vocabulary={}) #构建测试集TF-IDF向量空间 testspace = Bunch(target_name=bunch.target_name,label=bunch.label,filenames=bunch.filenames,tdm=[],vocabulary={}) #导入训练集的词袋 trainbunch = readbunchobj("C:\\Users\\Administrator\\Desktop\\data\\test_word_bag\\tfdifspace.dat") #使用TfidVectorrizer初始化向量空间模型 vectorizer = TfidfVectorizer(stop_words=stpwrdlst,sublinear_tf=True,max_df=0.5 ,vocabulary=trainbunch.vocabulary) transformer=TfidfTransformer testspace.tdm = vectorizer.fit_transform(bunch.contents) testspace.vocabulary = trainbunch.vocabulary #创建词袋的持久化 space_path = "C:\\Users\\Administrator\\Desktop\\data\\test_word_bag\\testspace.dat"#词向量空间保存路径 writebunchobj(space_path,testspace)
2.执行多项式贝叶斯算法进行测试文本分类。
from sklearn.naive_bayes import MultinomialNB#导入多项式贝叶斯算法包 import pickle #读取Bunch对象 def readbunchobj(path): file_obj = open(path,"rb") bunch = pickle.load(file_obj,encoding="utf-8") file_obj.close() return bunch #导入训练集向量空间 trainpath = r"C:\Users\Administrator\Desktop\data\test_word_bag\tfdifspace.dat" train_set = readbunchobj(trainpath) #导入测试集向量空间 testpath = r"C:\Users\Administrator\Desktop\data\test_word_bag\testspace.dat" test_set = readbunchobj(testpath) #应用朴素贝叶斯算法 #alpha:0.001 alpha越小,迭代次数越多,精度越高 clf = MultinomialNB(alpha= 0.001).fit(train_set.tdm,train_set.label) #预测分类结果 predicted = clf.predict(test_set.tdm) total = len(predicted) rate = 0 for flabel,file_name,expct_cate in zip(test_set.label,test_set.filenames,predicted): if flabel != expct_cate: rate += 1 print(file_name,":实际类别:",flabel,"-->预测类别:",expct_cate) print("error rate",float(rate)*100/float(total),"%")
运行结果
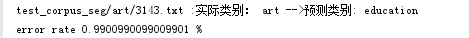
这里出错的3143.txt是从education复制到art下的。。。。。。。。。。
2.2.7 分类结果评估
机器学习领域的算法有三个基本的指标。
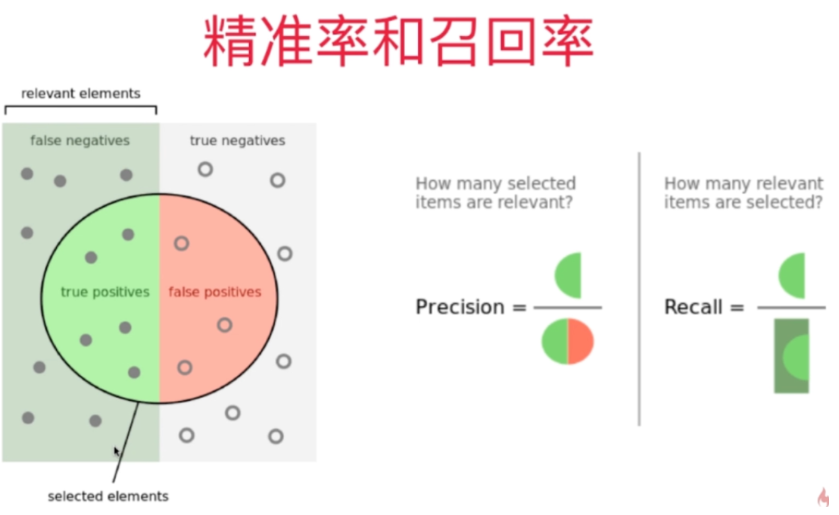
1.召回率,即检索出相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率。
召回率=系统检索到的相关文件/系统所有相关的文件总数
2.准确率 = 系统检索到的相关文件/系统所有检索到的文件总数

区别精确率和召回率主要记住他们是分母不同就好了:
python代码
from sklearn.naive_bayes import MultinomialNB#导入多项式贝叶斯算法包 import pickle from sklearn import metrics from sklearn.metrics import precision_score #sklearn中的精准率 #读取Bunch对象 def readbunchobj(path): file_obj = open(path,"rb") bunch = pickle.load(file_obj,encoding="utf-8") file_obj.close() return bunch # 定义分类精度函数 def metrics_result(actual,predict): print("准确率:",metrics.precision_score(actual,predict,average='macro')) print("召回率:", metrics.recall_score(actual, predict,average='macro')) print("fl-score:", metrics.f1_score(actual, predict,average='macro')) #导入训练集向量空间 trainpath = r"C:\Users\Administrator\Desktop\data\test_word_bag\tfdifspace.dat" train_set = readbunchobj(trainpath) #导入测试集向量空间 testpath = r"C:\Users\Administrator\Desktop\data\test_word_bag\testspace.dat" test_set = readbunchobj(testpath) #应用朴素贝叶斯算法 #alpha:0.001 alpha越小,迭代次数越多,精度越高 clf = MultinomialNB(alpha= 0.001).fit(train_set.tdm,train_set.label) #预测分类结果 predicted = clf.predict(test_set.tdm) metrics_result(test_set.label,predicted)
对准确率和召回率的另一种理解方式:
举个例子:某池塘有1400条鲤鱼,300只虾,300只鳖。现在以捕鲤鱼为目的。撒一大网,逮着了700条鲤鱼,200只虾,100只鳖。假设鲤鱼是我们要正确逮捕的目标,那么,这些指标分别如下:
准确率 = 700 / (700 + 200 + 100) = 70%
召回率 = 700 / 1400 = 50%
F1值 = 70% * 50% * 2 / (70% + 50%) = 58.3%
不妨看看如果把池子里的所有的鲤鱼、虾和鳖都一网打尽,这些指标又有何变化:
正确率 = 1400 / (1400 + 300 + 300) = 70%
召回率 = 1400 / 1400 = 100%
F值 = 70% * 100% * 2 / (70% + 100%) = 82.35%

由此可见,正确率是评估捕获的成果中目标成果所占得比例;召回率,顾名思义,就是从关注领域中,召回目标类别的比例;而F值,则是综合这二者指标的评估指标,用于综合反映整体的指标。
当然希望检索结果正确率越高越好,同时召回率也越高越好,但事实上这两者在某些情况下有矛盾的。比如极端情况下,我们只搜索出了一个结果,且是准确的,那么准确率就是100%,但是召回率就很低;而如果我们把所有结果都返回,那么比如召回率是100%,但是准确率就会很低。因此在不同的场合中需要自己判断希望准确率比较高或是召回率比较高。如果是做实验研究,可以绘制准确率-召回率曲线来帮助分析。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号