目标检测从入门到精通—R-CNN详细解析(二)
R-CNN目标检测详细解析
《Rich feature hierarchies for Accurate Object Detection and Segmentation》
Author:Mr. Sun
Date:2019.03.18
Loacation: DaLian university of technology
摘要:
这篇论文是深度学习进行物体检测的鼻祖级论文,Regions with CNN features(R-CNN)也可以说是利用深度学习进行目标检测的开山之作。 R-CNN是将CNN方法应用到目标检测上的一个里程碑,由年轻有为的RBG大神提出,借助CNN良好的特征提取和分类性能,通过Region Proposals方法实现目标检测问题的转化。
1、研究思路剖析—站在巨人的肩膀上
在过去的十多年时间里,传统的机器视觉领域,通常采用特征描述算子来应对目标识别任务,这些特征描述算子最常见的就是 SIFT 和 HOG,而 OpenCV 有现成的 API 可供大家实现相关的操作。但是最近SIFT 和 HOG 的王者地位被卷积神经网络撼动。
2012 年 Krizhevsky 等人在 ImageNet 举办的 ILSVRC 目标识别挑战大赛中一战成名,豪夺当年的第一名,Top5 错误率 15%,而他们团队提出来的网络结构以他们的导师名字命名,它就是 AlexNet,该结构有 5 层卷积层,2 层全连接层。详细结构如图1所示。

图1:AlexNet-8网络结构
因为 AlexNet 的出现,世人的目光重回神经网络领域,以此为契机,不断涌出各种各样的网络比如 VGG、GoogleNet、ResNet 等等。受 AlexNet 启发,论文作者尝试将 AlexNet 在 ImageNet 目标识别的能力泛化到 PASCAL VOC 目标检测上面来。但一切开始之前,需要解决两个主要的问题。
(1)如何利用深度的神经网络去做目标的定位?
借鉴了滑动窗口思想,R-CNN 采用对区域进行识别的方案。具体是:
(a)给定一张输入图片,从图片中提取 2000 个独立的候选区域。
(b)对于每个区域利用 CNN 抽取一个固定长度的特征向量。
(c)再对每个区域利用 SVM 进行目标分类。
(2)如何在一个小规模的数据集上训练能力强劲的网络模型?
采用在 ImageNet 上已经训练好的模型,然后在 PASCAL VOC 数据集上进行 fine-tune。因为 ImageNet 的图像高达几百万张,利用卷积神经网络充分学习浅层的特征,然后在小规模数据集做微训练调优,从而可以达到好的效果。现在,我们称之为迁移学习,是必不可少的一种技能。
2、R-CNN模型结构与训练过程详解
2.1 R-CNN结构分析
R-CNN的分类器结构如下图2所示:

图2:R-CNN模型结构
R-CNN算法一共分为四个步骤:
(1)候选区域选择(Region Proposal)
能够生成候选区域的方法很多,比如:objectness、selective search、category-independen object proposals、constrained parametric min-cuts(CPMC)、multi-scale combinatorial grouping、Ciresan等等。
Region Proposal就是为了获得候选框的方法,本文作者不具体研究 Region Proposal 的方法而是采用的是 Selective Search,一般Candidate选项为2000个即可,这里不再详述; 根据Proposal提取的目标图像变形为固定尺寸(227*227)然后去均值,作为CNN的标准输入。
(2)CNN特征提取(Feature Extraction )
标准CNN过程,根据输入进行卷积/池化等操作,得到固定维度的输出。本文在训练SVM分类器时用的是FC7的特征输出作为SVM的训练输入,在训练Bounding-box回归时使用的是conv5之后的pool5(6*6*256)的特征作为输入的。
(3)分类(Classification)
对上一步的输出向量进行分类(需要根据输出特征训练分类器),本文使用的是线性的SVM二分类分类器,每一个分类器都需要单独训练。
(4)边界回归(Bounding-box Regression)
通过边界回归(bounding-box regression) 得到精确的目标区域,由于实际目标会产生多个子区域,旨在对完成分类的前景目标进行精确的定位与合并,避免多个检出。
R-CNN的整体结构如下图3所示:
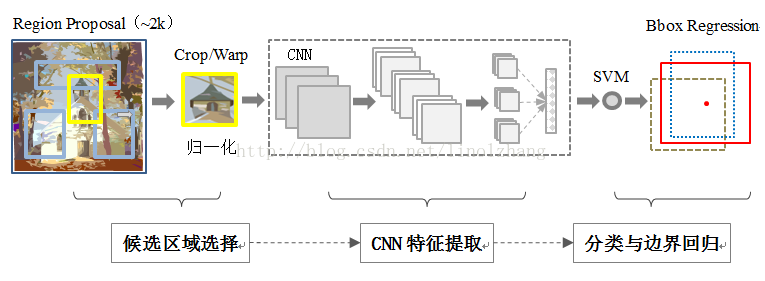
图3:R_CNN整体结构
2.2 R-CNN训练过程分析
步骤一:有监督分类器预训练
ILSVRC样本集上仅有图像类别标签,没有图像物体位置标注;而PASCAL VOC 2007样本集上既有图像中物体类别标签,也有图像中物体位置标签;但是PASCAL VOC训练样本太少不足以去训练一个大型的神经网络, 因此作者以ILSVRC2012分类数据集(没有约束框数据)作为辅助预训练了CNN。预训练采用了Caffe的CNN库。总体来说,使用的CNN十分接近krizhevsky等人的网络的性能,在ILSVRC2012分类验证集在top-1错误率上比他们高2.2%。差异主要来自于训练过程的简化。
作者采用AlexNet CNN网络进行有监督训练,学习率=0.01;该网络的输入为227×227的ILSVRC训练集图像,输出最后一层为4096维特征->1000类的映射,训练的是网络参数。然后传入下一步进行迁移学习,也就是特定样本下的 fine-tune ,获得适合该样本下的最优模型。AlexNet网络结构如下图4所示。
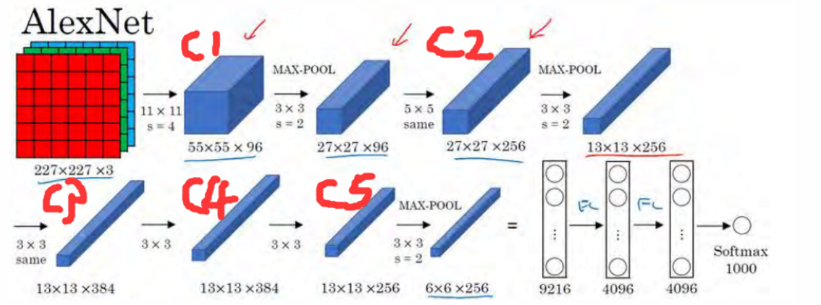
图4:AlexNet网络结构
步骤二:特定样本下的分类器微调(fine-tune)
坦率的说,这一步就是我们经常说的迁移学习(Transfer Learning)。加载步骤一中训练好的模型,使用该模型中特征提取的参数来初始化我们这里的CNN的参数。我们将AlexNet的FC7之后的1000-way(ImageNet类别数)换成21-way(PASCAL VOC类别数 + 背景),然后进行softmax回归。这里使用通过SS(Selective Search)算法对图像处理获得2000个左右的候选区域(Region Proposal),然后将候选区域和真实标注区域(Ground Truth)的 IOU>0.5时作为正样本,否则作为负样本进行训练。需要注意的是对于每一个随机梯度(SGD)迭代,我们使用一个mini_batch=128的小批次,其中使用32个当前类的样本(正样本)和96个背景样本作为负样本。这一步的目的就是让模型去学习特定的样本,通过作者的实验发现这一步骤还是很有必要的。作者得出结论是:不针对特定任务进行微调,而将CNN当成特征提取器,pool5层得到的特征是基础特征, 从fc6和fc7等全连接层中所学习到的特征是针对特征任务特定样本的特征,类似于学习到了分类性别分类年龄的个性特征。
这里的随机梯度处理的是一张图片的候选区域吗?这里的mini_batch=128小批次中的32个正样本和96和负样本均来自哪?这里的正样本中包含多少类别呢?
这个疑问我一直没搞懂,先简单说一下我的理解:首先,PASCAL VOC数据集标签中应该是有标准矩形框的坐标和所属类别的。我个人觉得这里处理的确实是一张图片的2000个候选区域,然后通过和标准的Ground Truth计算IOU值选出很多正样本和负样本,然后在正样本中随机选出32张、在负样本中选出96张,将它们作为一个批次进行前向传播计算去fine-tune参数。反向传播结束之后,再换下一张图片进行下一轮的Region Proposal,一直到把这个分类模型训练好,训练结束后保存FC7层的特征(权重参数)。
步骤三:训练SVM分类器
建立新的SVM的分类器模型,模型的FC7层之后修改为SVM分类器(多个线性二分类SVM)。将步骤二的模型的卷积层参数和FC6、FC7的参数加载到模型中,保持前7层参数不变,其它参数随机初始化,只是让分类器通过学习前面学习到的特征对物体进行分类。训练的样本仍然是来自一张图片的2000个Region Proposal,计算IOU之后筛选出来正负样本用于训练分类器
针对每个类别训练一个SVM的二分类器。输入是FC7的特征,FC7的输出维度是2000*4096,输出的是是否属于该类别,训练结果是得到SVM的权重矩阵W,W的维度是4096*20。这里负样本的选定和前面的有所不同,将IOU的阈值从0.5改成0.3,即IOU<0.3的是负样本,IOU>0.7是正样本。IOU的阈值选择和前面fine-tuning不一样,主要是因为:前面fine-tuning需要大量的样本,所以设置成0.5会比较宽松。而在SVM阶段是由于SVM适用于小样本,所以设置0.3会更严格一点。
步骤四:边界框回归(Bounding-box Regression)
使用conv5之后的pool5的特征6*6*256维(输入特征)和bounding box的ground truth(相当于要回归的值)来训练回归,每种类型的回归器单独训练。输入是pool5的特征,以及每个样本对的坐标和长宽值。另外只对那些跟ground truth的IOU超过某个阈值且IOU最大的Region Proposal回归,其余的region proposal不参与。详细说一下:对于某个region proposal:R,以及其对应的Ground truth:G,我们希望预测结果是:P,那么我们肯定希望P尽可能接近G。这里通过对pool5层的特征X做线性变换WX得到变换函数F(X),这些变换函数作用于R的坐标达到回归的作用(包括对x,y的平移以及对w,h的缩放)。因此损失函数可以表达为:R和G的差距减去P和G的差距要尽可能小。
R-CNN的训练具体流程:
(1)准备region proposal。对于训练集中的所有图像,采用selective search方式来获取,最后每个图像得到2000个region proposal。
准备正负样本。如果某个region proposal和当前图像上的所有ground truth(标记)重叠面积最大的那个的IOU大于等于0.5,则该region proposal作为这个ground truth类别的正样本,否则作为负样本。另外正样本还包括了Ground Truth。因为VOC一共包含20个类别,所以这里region proposal的类别为20+1=21类,1表示背景。简单说下IOU的概念,IOU是计算矩形框A、B的重合度的公式:IOU=(A∩B)/(A∪B),重合度越大,说明二者越相近。
(2)预训练。这一步主要是因为检测问题中带标签的样本数据量比较少,难以进行大规模训练。采用的是Krizhevsky在2012年的著名网络AlexNet来学习特征,包含5个卷积层和2个全连接层,在Caffe框架下利用ILSVRC 2012的数据集进行预训练,其实就是利用大数据集训练一个分类器,这个ILSVRC 2012数据集就是著名的ImageNet比赛的数据集,也是彩色图像分类。
(3)fine-tuning。将2中得到的样本进行尺寸变换,使得大小一致,这是由于2中得到的region proposal大小不一,所以需要将region proposal变形成227*227。本文中对所有不管什么样大小和横纵比的region proposal都直接拉伸到固定尺寸。然后作为3中预训练好的网络的输入,继续训练网络,继续训练其实就是迁移学习。另外由于ILSVRC 2012是一个1000类的数据集,而本文的数据集是21类(包括20个VOC类别和一个背景类别),迁移的时候要做修改,将最后一个全连接层的输出由1000改成21,其他结构不变。训练结束后保存f7的特征。
(4)针对每个类别训练一个SVM的二分类器。输入是f7的特征,f7的输出维度是2000*4096,输出的是是否属于该类别,训练结果是得到SVM的权重矩阵W,W的维度是4096*20。这里负样本的选定和前面的有所不同,将IOU的阈值从0.5改成0.3,即IOU<0.3的是负样本,正样本是Ground Truth。IOU的阈值选择和前面fine-tuning不一样,主要是因为:前面fine-tuning需要大量的样本,所以设置成0.5会比较宽松。而在SVM阶段是由于SVM适用于小样本,所以设置0.3会更严格一点。
(5)回归。用pool5的特征6*6*256维和bounding box的ground truth来训练回归,每种类型的回归器单独训练。输入是pool5的特征,以及每个样本对的坐标和长宽值。另外只对那些跟ground truth的IOU超过某个阈值且IOU最大的proposal回归,其余的region proposal不参与。详细说一下:对于某个region proposal:R,以及其对应的Ground truth:G,我们希望预测结果是:P,那么我们肯定希望P尽可能接近G。这里通过对pool5层的特征X做线性变换WX得到变换函数F(X),这些变换函数作用于R的坐标达到回归的作用(包括对x,y的平移以及对w,h的缩放)。因此损失函数可以表达为:R和G的差距减去P和G的差距要尽可能小。
3、R-CNN模型的测试过程分析
(1)输入一张图像,利用Selective Search得到2000个Region Proposal。
(2)对所有Region Proposal变换到固定尺寸(227*227),然后将所有建议框像素减去该建议框像素平均值后【预处理操作】,并作为已训练好的CNN网络的输入,得到f7层的4096维特征【比以前的人工经验特征低两个数量级】,所以f7层的输出是2000*4096。
(3)对每个类别,采用已训练好的这个类别的svm分类器对提取到的特征打分(Feature Scores),所以SVM的Weight Matrix是4096*N,N是类别数,这里一共有20个SVM,N=20注意不是21。得分矩阵是2000*20,表示每个Region Proposal属于某一类的得分。
(4)采用Non-Maximun Suppression(NMS)对得分矩阵中的每一列中的Region Proposal进行剔除,就是去掉重复率比较高的几个Region Proposal,得到该列中得分最高的几个Region Rroposal。NMS的意思是:举个例子,对于2000*20中的某一列得分,找到分数最高的一个Region Proposal,然后只要该列中其他Region Proposal和分数最高的IOU超过某一个阈值,则剔除该Region Proposal。这一轮剔除完后,再从剩下的Region Proposal找到分数最高的,然后计算别的Region Proposal和该分数最高的IOU是否超过阈值,超过的继续剔除,直到没有剩下Region Proposal。对每一列都这样操作,这样最终每一列(即每个类别)都可以得到一些rRegion Proposal。
(5)用N=20个回归器对第4步得到的20个类别的region proposal进行回归,要用到pool5层的特征。pool5特征的权重W是在训练阶段的结果,测试的时候直接用。最后得到每个类别的修正后的Bounding-box。
4、R-CNN存在的明显问题(后续网络改进的点)
(1)每张图像需要提前提取2000个候选区域(Region Proposal),占用较大的磁盘空间(Memory);
(2)针对传统CNN需要固定尺寸(227*227)的输入图像,crop/warp(归一化)产生物体截断或拉伸,会导致输入CNN的信息丢失;
(3)每一个Region Proposal都需要进入CNN网络计算,上千个Region存在大量的范围重叠,重复的特征提取带来巨大的计算浪费。
5、关于R-CNN的一些细节性问题
(1)速度问题
经典的目标检测算法使用滑窗法依次判断所有可能的区域。本文采用选择性搜索(Selective Search)则预先提取一系列较可能是物体的候选区域,之后仅在这些候选区域上提取特征,进行判断。
(2)训练集问题
(a)经典的目标检测算法在区域中提取人工设定的特征(Haar,HOG)。本文则需要训练深度网络进行特征提取。可供使用的有两个数据库:
(b)一个较大的识别库(ImageNet ILSVC 2012):标定每张图片中物体的类别。一千万图像,1000类。
(c)一个较小的检测库(PASCAL VOC 2007):标定每张图片中,物体的类别和位置。一万图像,20类。
本文使用识别库进行预训练,而后用检测库调优参数。最后在检测库上评测。
(3)直接使用AlexNet做特征提取,省去fine-tune阶段可以吗?
这个是可以的,你可以不重新训练CNN,直接采用Alexnet模型,提取出pool5、或者FC6、FC7的特征,作为特征向量,然后进行训练SVM,只不过这样精度会比较低。那么问题又来了,没有fine-tuning的时候,要选择哪一层的特征作为cnn提取到的特征呢?我们有可以选择pool5、FC6、FC7,这三层的神经元个数分别是9216、4096、4096。从pool5(6*6*256)到FC6这层的参数个数是:9216*4096 ,从f6到f7的参数是4096*4096。那么具体是选择p5、还是f6,又或者是f7呢?
Paper给我们证明了一个结论,如果你不进行fine-tuning,也就是你直接把Alexnet模型当做特征提取器使用,类似于HOG、SIFT一样做特征提取,不针对特定的任务。然后把提取的特征用于分类,结果发现pool5的精度竟然跟FC6、FC7差不多,而且FC6提取到的特征还比FC7的精度略高;如果你进行fine-tuning了,那么FC7、FC6的提取到的特征最后训练出来的svm分类器的精度就会大幅提高。
鉴于此让我们明白了一个道理,如果不针对特定任务进行fine-tuning,而是把CNN当做特征提取器,卷积层所学到的特征其实就是基础的共享特征提取层,就类似于SIFT提取特征一样,可以用于提取各种图片的基础特征,而FC6、FC7所学习到的特征是用于针对特定任务的特征(高级抽象特征)。打个比方:对于人脸性别识别来说,一个CNN模型前面的卷积层所学习到的特征就类似于学习人脸共性特征,然后全连接层所学习的特征就是针对特殊个体分类的特征了。
(4)在fine-tune训练的时候最后一层本来就是softmax分类层,那么为什么(闲的蛋疼)作者要利用CNN做特征提取(提取FC7层数据),然后再把提取的特征用于训练SVM分类器呢?
这个是因为SVM训练和CNN训练过程的正负样本定义方式各有不同,导致最后采用CNN softmax输出比采用SVM精度低。事情是这样的,CNN在训练的时候,对训练数据做了比较宽松的标注,比如一个Bounding-box可能只包含物体的一部分,那么我也把它标注为正样本,用于训练CNN;采用这个方法的主要原因在于因为CNN容易过拟合,所以需要大量的训练数据(不太理解,不是一样使用32个正样本,96个负样本吗?),所以在CNN训练阶段我们是对Bounding-box的位置限制条件限制的比较松(IOU只要大于0.5都被标注为正样本了);
然而svm训练的时候,因为SVM适用于少样本训练,所以对于训练样本数据的IOU要求比较严格,我们只有当Bounding-box把整个物体都包含进去了,我们才把它标注为物体类别,然后训练svm。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号