201871010102-常龙龙 实验二 个人项目—《求解D{0-1}背包问题》项目报告
| 项目 | 内容 |
|---|---|
| 课程班级博客链接 | https://edu.cnblogs.com/campus/xbsf/2018CST?filter=all |
| 这个作业要求链接 | https://www.cnblogs.com/nwnu-daizh/p/14552393.html |
| 我的课程学习目标 | 1. 熟悉github操作 2. 熟悉springboot+vue网站开发的技术 3.加深对D{0-1}问题的动态规划和回溯算法的解法的理解 4.熟悉java语言开发程序的一般流程 5.掌握程序设计的模块化开发 6.掌握PSP流程 |
| 这个作业在哪些方面帮助我实现学习目标 | 1. 更加熟练git的相关操作 2. 熟练markdown编辑器的使用方法 3.温习使用前后端分离技术开发网站的过程 4.学会算法设计的思想 5.理解了PSP流程对一个项目的重要意义 |
| 项目Github的仓库链接地址 | 1.后台数据接口: https://github.com/beike666/bag_serve 2.前台页面:https://github.com/beike666/bag_client |
博客正文
任务一:阅读教师博客“常用源代码管理工具与开发工具”内容要求,点评班级博客中已提交相关至少3份作业。
作业点评链接
- https://www.cnblogs.com/weinana/p/14550875.html
- https://www.cnblogs.com/mayan0821/p/14547899.html
- https://www.cnblogs.com/chms/p/14550446.html
任务二:详细阅读《构建之法》第1章、第2章,掌握PSP流程
作用
PSP可以帮助软件工程师在个人的基础上运用过程的原则,借助于PSP提供的一些度量和分析工具,了解自己的技能水平,控制和管理自己的工作方式,使自己日常工 作的评估、计划和预测更加准确、更加有效,进而改进个人的工作表现,提高个人的工作质量和产量,积极而有效地参与高级管理人员和过程人员推动的组织范围的 软件工程过程改进。
我的理解:
每个软件项目都有自己的特点,因此它们的PSP流程在细节处理上也会各有千秋,但是我们要掌握它的一般流程,知道如何书写一份正确的PSP流程。
任务三:个人软件项目开发
一、需求分析
在看到本次个人项目题目中出现散点图的时候,我就想到要使用javaWeb的方式来完成本次项目,因为我可以将echarts图表引入到web项目中来实现题目要求,并且使用网页能让本次个人项目拥有更加友好的人机交互界面。以下是我基于springboot+vue的网站技术做出的的需求分析:
- 后台要能够从给定的文件中读取出正确的数据并保存,方便后续的工作
- java后端给前端传递正确的数据,前端根据后端传的数据绘制散点图
- java后端实现对自定义数据类型的列表的排序(实现Comparator接口),并向前端传数据
- 实现java后台解决D{0-1}背包问题的动态规划和回溯算法
- 后台将求解后的数据写入文件并保存,前端展示文件下载阅览
开发环境
| 名称 | 版本 |
|---|---|
| jdk | 1.8.0 |
| vue-cli | 3.12.1 |
| node.js | 14.15.0 |
| git | 2.29.1.windows.1 |
二、功能设计
- 绘制任意一组D{0-1}KP数据以重量为横轴、价值为纵轴的数据散点图
- 对任意一组D{0-1}KP数据按项集第三项的价值:重量比进行非递增排序;
- 用户能够自主选择动态规划算法、回溯算法求解指定D{0-1} KP数据的最优解和求解时间(以秒为单位)
- 任意一组D{0-1} KP数据的最优解、求解时间和解向量可保存为txt文件或导出EXCEL文件
三、设计实现
1. 主要类
- FileControler类:负责所有的数据处理并向前端传递数据
- Scatter类:前端通过表单请求数据的有个封装类,效果是
{
fileName:"idkp1-10.txt",
group:1,
// 0代表动态规划算,1代表回溯算法
type:0,
fileType:'.txt'
}
- ScatterUtil类:画数据散点图和排序时的一个工具类,效果是
{
profit:168,
weight:309
}
- OrderUtil类:做自定义数据类型排序时的类工具类,效果是
{
data:[
{profit:168,weight:309},
{profit:168,weight:309},
{profit:168,weight:309}
],
rate:1.0978
}
- AnswerUtil类:将求解结果返回前端的呢的一个工具类,效果是
{
// 最优解的路径
answer:10453,
// 运行时间
runtime:0.0341,
// 解向量
bestPath:[]
}
2. 类的关系
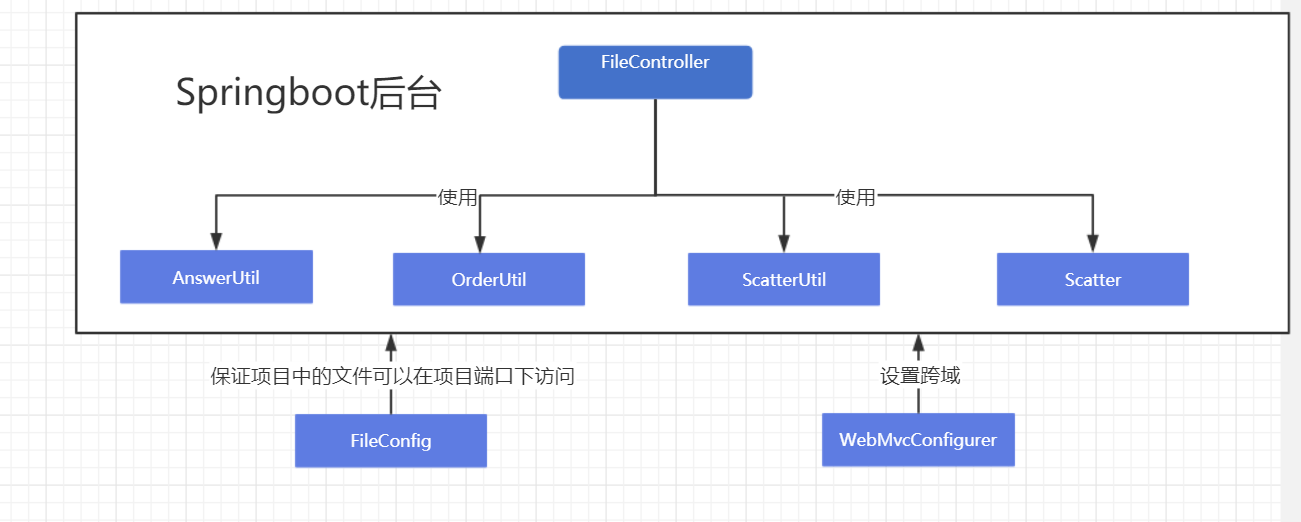
3. FileController类中的函数
- getScatterData:绘制散点图的后台数据接口
参数
- Scatter scatter:其中包含需要绘制散点图的文件,文件的第几组数据,采用什么算法(此处为空),保存为什么文件(此处为空)
返回数据类型
[
{profit:121,weight:456},
{profit:121,weight:456},
{profit:121,weight:456},
{profit:121,weight:456}
]
- getScatterData:数据非递增排序的后台数据接口
参数
- Scatter scatter:其中包含需要绘制散点图的文件,文件的第几组数据,采用什么算法(此处为空),保存为什么文件(此处为空)
返回数据类型
[
{
item:[{121,456},{121,456},{121,456}],
rate:1.234245
},
{
item:[{121,456},{121,456},{121,456}],
rate:1.234245
},
{
rate:[{121,456},{121,456},{121,456}],
item:1.234245
}
]
- answer:使用动态规划或回溯求解的后台数据接口
参数
- Scatter scatter:其中包含需要绘制散点图的文件,文件的第几组数据,采用什么算法,保存为什么文件(此处为空)
返回数据类型
{
answer:10453,
runTime:0.00363s,
bestpath:""
}
- answerAndSave:使用动态规划或回溯求解并保存的后台数据接口
参数
- Scatter scatter:其中包含需要绘制散点图的文件,文件的第几组数据,采用什么算法,保存为什么文件
返回数据类型
{
answer:10453,
runTime:0.00363s,
bestPath:"",
downUrl:'http:localhost:8088/file/2022-3-26-123512354123.txt'
}
- dp:动态规划算法
参数
- ArrayList
profitsList:某组数据的价值列表
- ArrayList
weightsList:某组数据的重量列表
- int volume:某组数据的背包最大容量
- ArrayList
- back:为回溯算法准备数据
参数
- ArrayList
profitsList:某组数据的价值列表
- ArrayList
weightsList:某组数据的重量列表
- int volume:某组数据的背包最大容量
- ArrayList
- recursion:回溯算法
参数
- ArrayList
ret:存放所有结果的列表
- int volume:某组数据的背包最大容量
- int[][] p:存放某组价值的二维数组
- int[][] w:存放某组重量的二维数组
- int totalProfit:存放回溯过程中的物品总价值
- int totalProfit:存放回溯过程中的物品总重量
- int i:回溯过程中访问的物品二维数组的行下标
- int j:回溯过程中访问的物品二维数组的列下标
- ArrayList
- splitDataTwoGroup:将数据分割成【重量,价值】的数组
参数
- Scatter scatter:其中包含需要绘制散点图的文件,文件的第几组数据,采用什么算法(此处为空),保存为什么文件(此处为空)
- ArrayList
scatterUtils:封装散点数据结果的工具类
- Scatter scatter:其中包含需要绘制散点图的文件,文件的第几组数据,采用什么算法(此处为空),保存为什么文件(此处为空)
- readFile:创建文件对象,清洗数据的前期准备
参数
- String fileName:需要清洗数据的文件
- Integer group:需要清洗数据的文件中的那一组
- ArrayList
profitsList:将清洗过的组数据的价值保存起来的列表
- ArrayList
profitsList:将清洗过的组数据的重量保存起来的列表
- String fileName:需要清洗数据的文件
- splitData:分割具体某一组数据
参数
- Integer group:需要分割数据的文件中的那一组
- ArrayList
divided:分割好的数据列表
- ArrayList
undivided:分割好的数据列表
- Integer group:需要分割数据的文件中的那一组
- clearData:具体的清洗数据的操作
参数
- BufferedReader reader:文件读取流对象
- ArrayList
profits:文件中所有的价值列表(每一组为一个字符串)
- ArrayList
weights:文件中所有的重量列表(每一组为一个字符串)
- BufferedReader reader:文件读取流对象
- volumeCount:找出文件中某一组组的最大背包容量
参数
- String fileName:文件名
- Integer group:要找出哪一组的最大容量
- String fileName:文件名
- writeTxt:将内容保存为txt文件
参数
- File file:文件对象
- String data:要写入的数据
- File file:文件对象
- writeExcel:将内容保存为excel文件
参数
- File file:文件对象
- AnswerUtil answerUtil:要写入的数据
- File file:文件对象
4. FileController类中函数的关系
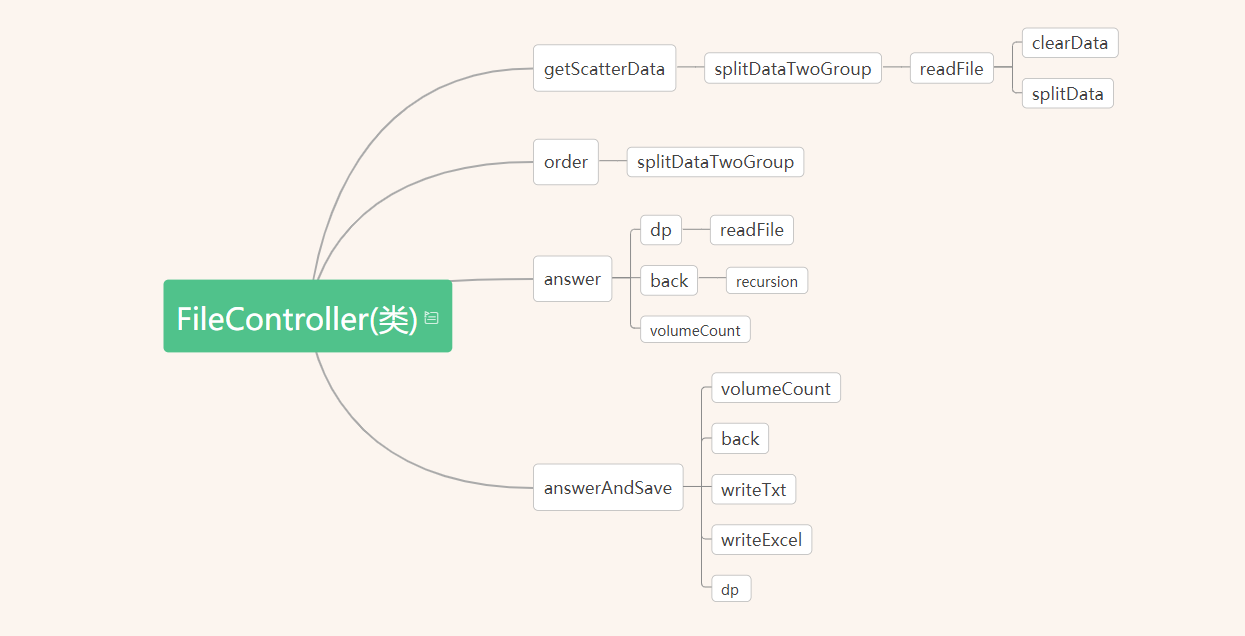
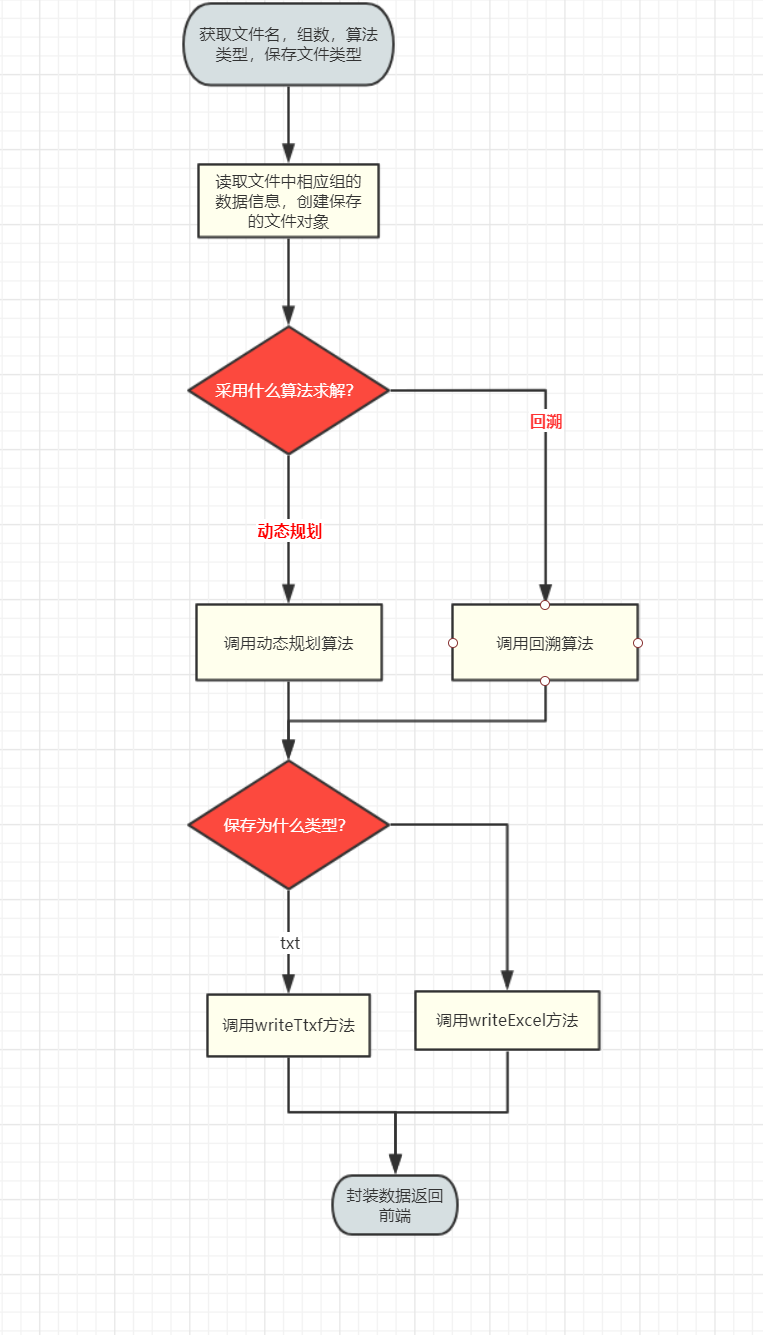
5. FileController类中answerAndSave方法流程图(关键方法,也是一个数据接口)
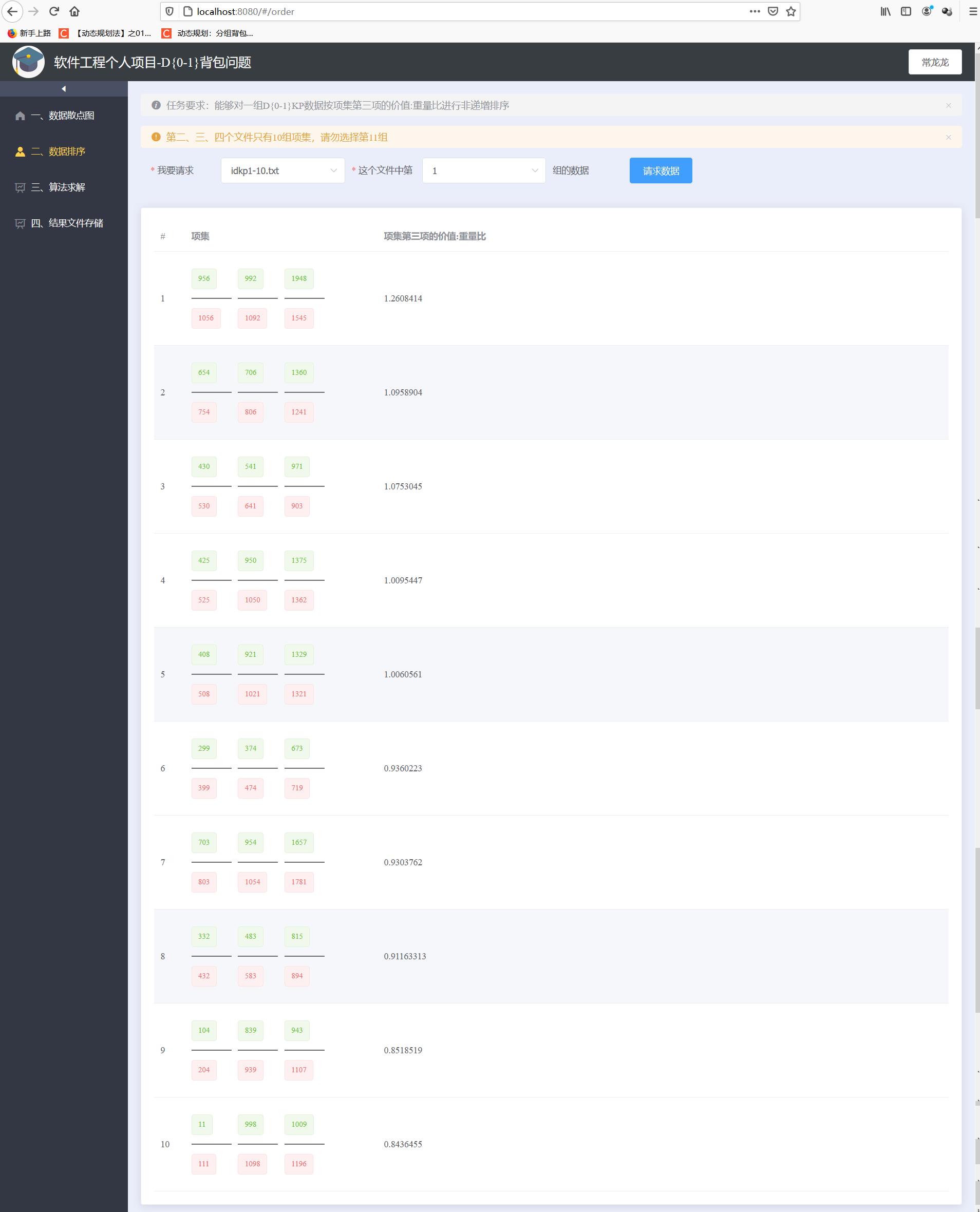
四、测试运行
- 绘制任意一组D{0-1}KP数据以重量为横轴、价值为纵轴的数据散点图

- 对一组D{0-1}KP数据按项集第三项的价值:重量比进行非递增排序
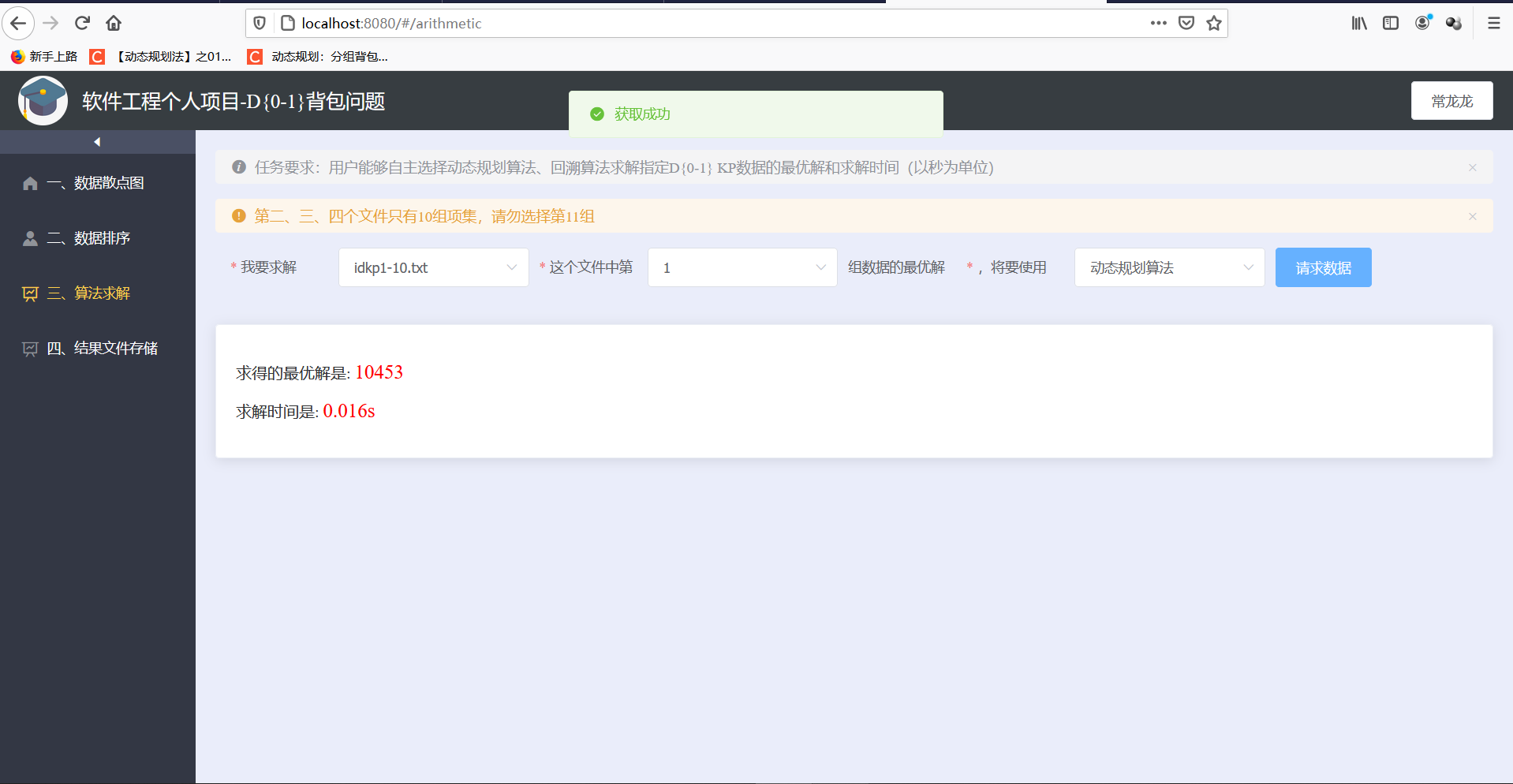
3.用户能够自主选择动态规划算法、回溯算法求解指定D{0-1} KP数据的最优解和求解时间(以秒为单位)
- 动态规划算法
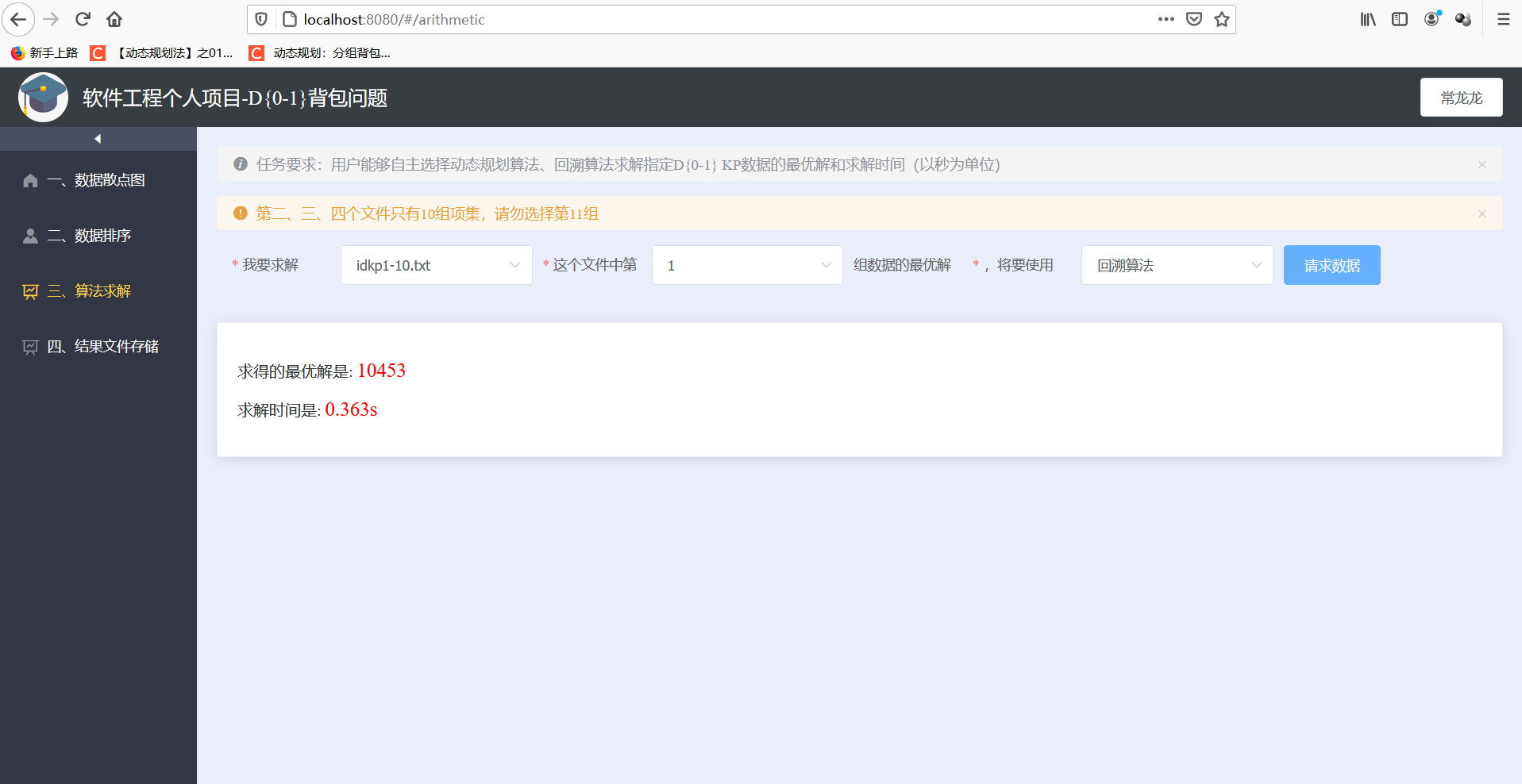
- 回溯算法
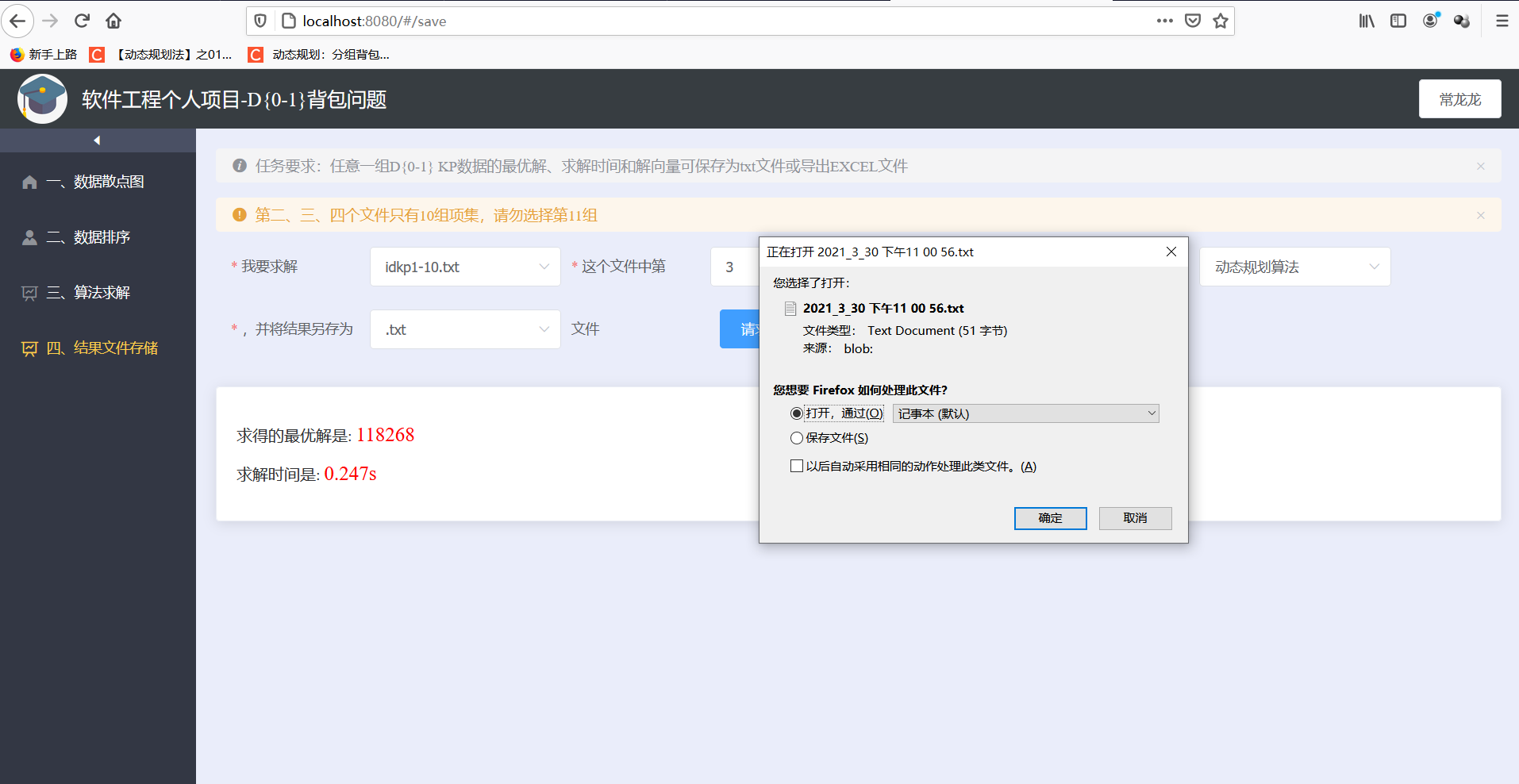
- 任意一组D{0-1} KP数据的最优解、求解时间和解向量可保存为txt文件或导出EXCEL文件
- 保存为txt文件
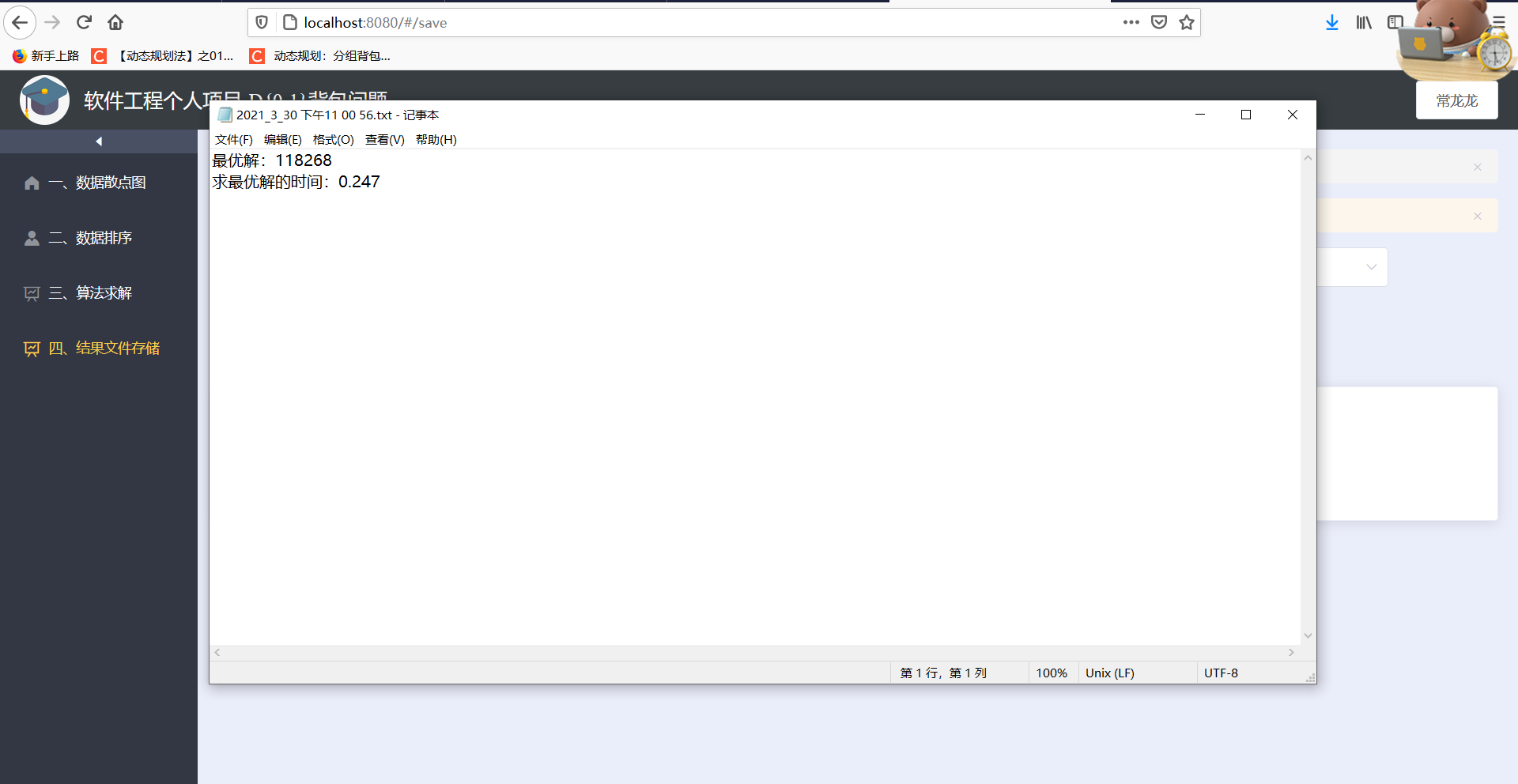
- 保存为excel文件
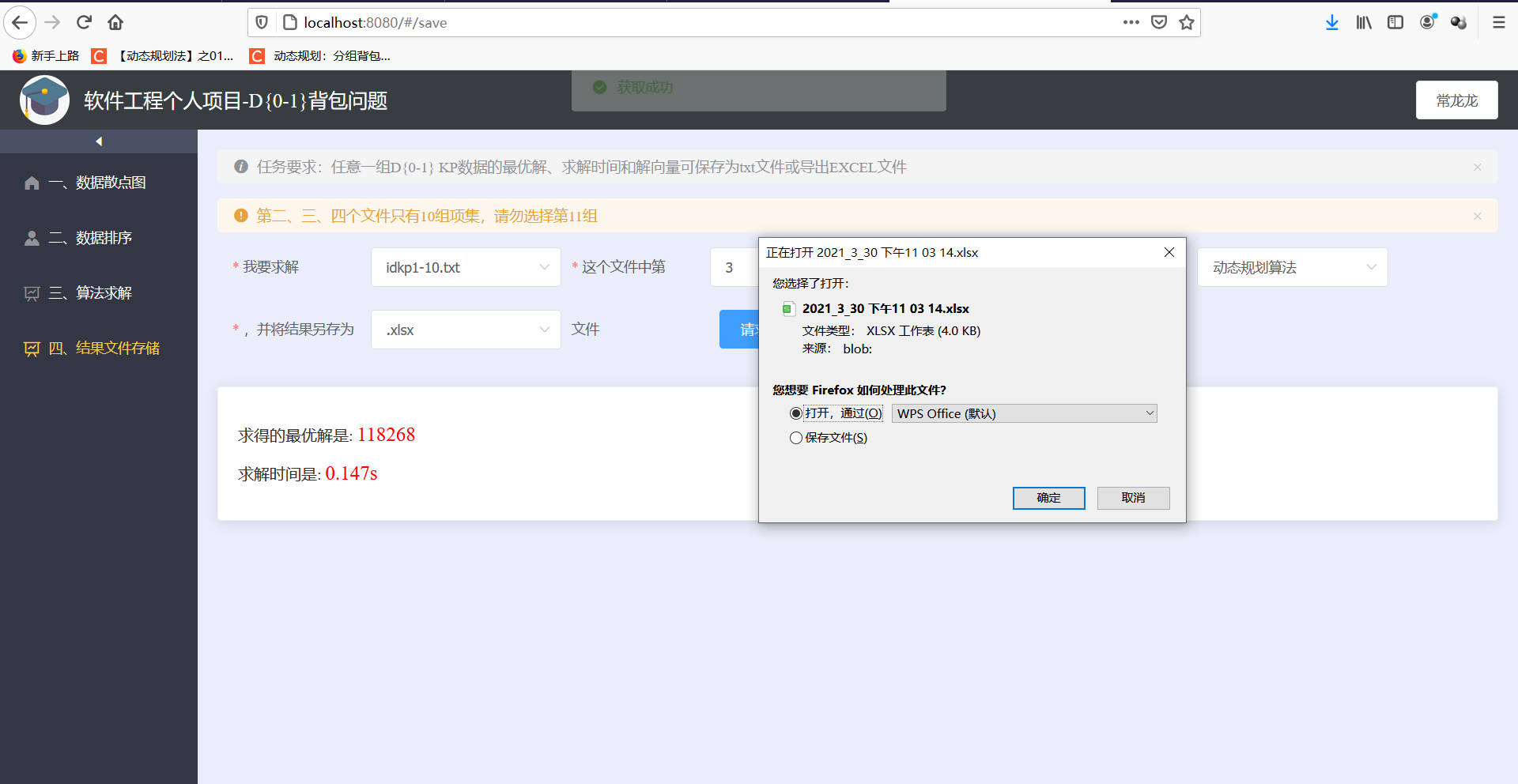

五、重要代码
/*
回溯算法
*/
public void recursion(ArrayList<Integer> ret,int volume,int[][] p,int[][] w,int totalProfit,int totalWeight,int i,int j){
if(j!=3){
// 相当于不选当前的项集
totalProfit=totalProfit+p[i][j];
totalWeight=totalWeight+w[i][j];
}
// 如果加上当前物品时总重量超过了背包容量则返回上一级
if(totalWeight>volume){
return;
}
// 如果已经遍历到最后一个元素,则将当前的最大价值存入列表
if(i==p.length-1){
ret.add(totalProfit);
return;
}
// 便利当前结点的所有子结点
for (int k = 0; k <4 ; k++) {
recursion(ret,volume,p,w,totalProfit,totalWeight,i+1,k);
}
}
/**
* 将文件中的特定数据读取到列表中
* @param reader
* @param profits
* @param weights
* @throws IOException
*/
private static void clearData(BufferedReader reader, ArrayList<String> profits, ArrayList<String> weights) throws IOException {
String s=null;
// 读取数据的标志字符串
String profit="The profit of items are:";
String weight="The weight of items are:";
// 读取数据的标志位
int flag1=0;
int flag2=0;
ArrayList<Integer> volumes = new ArrayList<>();
while ((s = reader.readLine()) != null) {
// 如果如果包含profit,则下一行是当前组的所有,设标志为为1,方便下次读入
if (s.contains(profit)) {
flag1=1;
continue;
}else if (s.contains(weight)) {
// 如果如果包含weight,则下一行是当前组的所有,设标志为为1,方便下次读入
flag2=1;
continue;
}
// 如果如果标志位为1,则本行为数据行,读入后设标志位为0,停止本次读入
if(flag1==1){
// 将当前数据存入列表
profits.add(s);
flag1=0;
}else if(flag2==1){
weights.add(s);
flag2=0;
}
}
}
六、项目总结
我的程序是如何实现软件设计的“模块化”原则的?
1. FileController类是我的数据接口层,前台页面想要请求数据都必须访问此类中的方法,其中共有四个接口供使用,每个数据接口职能明确,作用分离。
2. 在FileController类中其余的方法都是为上面四个数据接口服务的,当需要什么类型,什么格式的数据时只需传入相应的参数即可返回正确的结果。例如项目中的每个功能都需要读入正确格式的数据,这就产生了一个公共的方法readFile来读文件,而不需要每次都书写雷同的代码,大大减少了工作量。
我的感想
1. 此次的个人项目在总体难度上属于一般难度,最重要的就是要将D{0-1}背包问题的动态规划和回溯算法编写出来,因为之前没有学过算法分析这门课,所以这方面知识的不足在整个项目开展过程中带给我很大的困扰。最后在和舍友请教交流以及自我思考的情况下,终于将本次个人项目功能基本实现。但是依旧没有写出使用动态规划和回溯求背包问题的最优解路径(解向量)的算法,只做出了最优解和求解时间,所以在这点上项目还是有所欠缺。因此今后我需要补习算法方面的知识,加强软件课程的学习,在遇到任何问题时都能有一个正确的思路,从而“正确求解”。
2. 通过本次个人项目的完成训练,我更加熟练地掌握了javaWeb网站技术的开发,越来越明白了后端处理数据,前端接收并展示数据的开发思想;对向GitHub仓库提交项目的一般流程有了更深层次的掌握(因为在push项目时,我经常会遇到各种各样的错误,通过百度查资料,让我对这些错误都有了更深刻的印象,对于解决这些问题也更加得心应手);
3. 本次个人项目更让我明白了PSP的重要性,通过PSP,我们可以更好地掌握整个项目的开发时间及流程,项目在什么时候进行到什么地步,周期慢了需要加快,项目什么时候能够完工等等问题。有了一份完整且适当的PSP,对于团队合作的软件项目将会有非常大好处。相信在今后的学习生活中,PSP的知识一定会给我带来更多的帮助。
七、展示PSP
| PSP | 任务内容 | 计划共完成需要的时间(h) | 实际完成需要的时间(h) |
| Planning | 计划 | 42.3 | 46 |
| ·Estimate | 估计这个任务需要多少时间,并规划大致工作步骤 | 42.3 | 46 |
| Development | 开发 | 36.3 | 39.5 |
| ·Analysis | 需求分析 (包括学习新技术) | 6 | 7 |
| ·Design Spec | 生成设计文档和思路 | 2 | 2.4 |
| ·Design Review | 设计复审 | 1 | 0.8 |
| ·Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 0.3 | 0.3 |
| ·Design | 具体设计 | 5 | 6 |
| ·Coding | 具体编码 | 18 | 20 |
| ·Code Review | 代码复审 | 1 | 1 |
| ·Test | 测试(自我测试,修改代码,提交修改) | 3 | 3 |
| Reporting | 博客 | 6 | 6.5 |
| Summer | 任务+总结 | 6 | 6.5 |
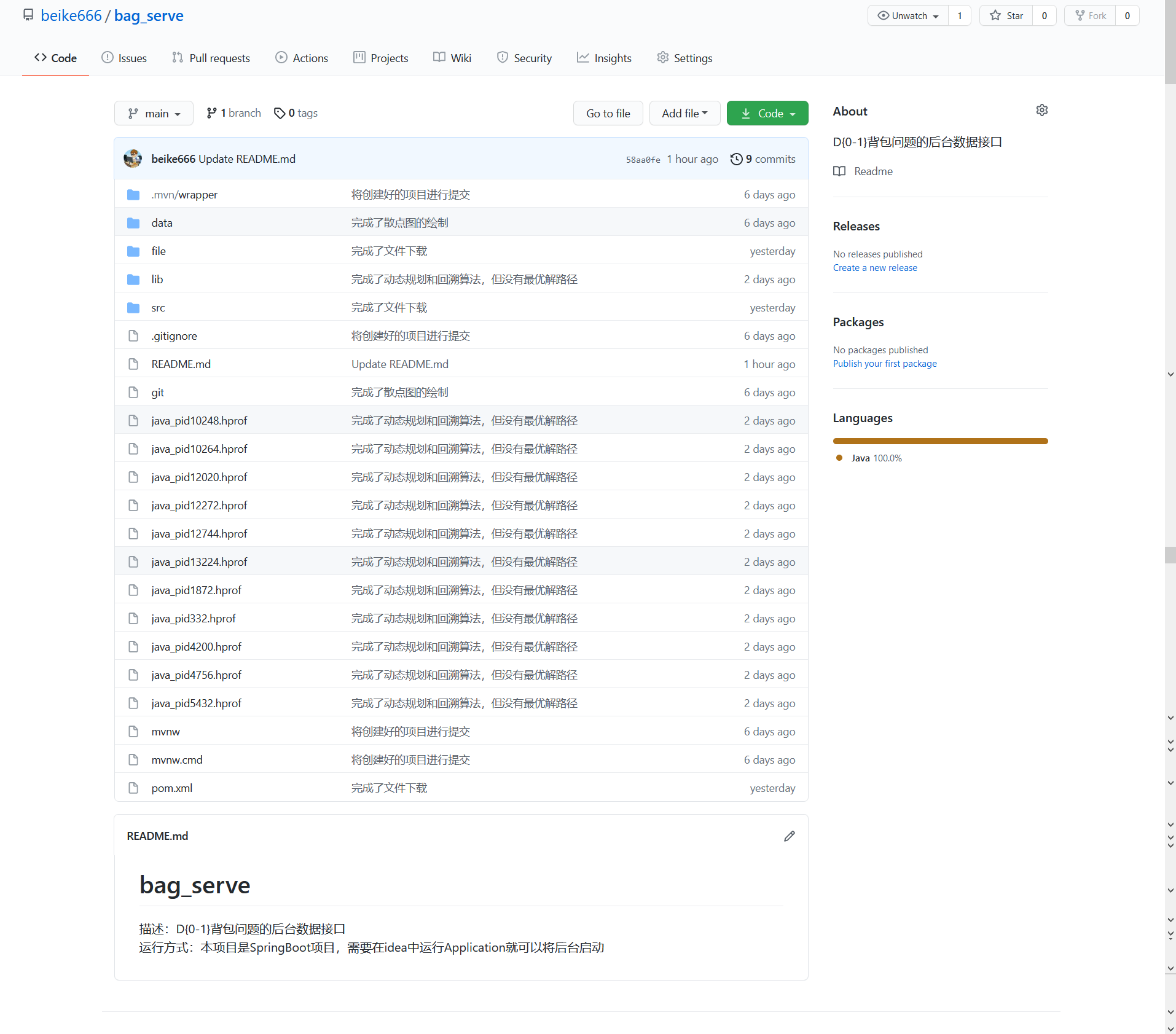
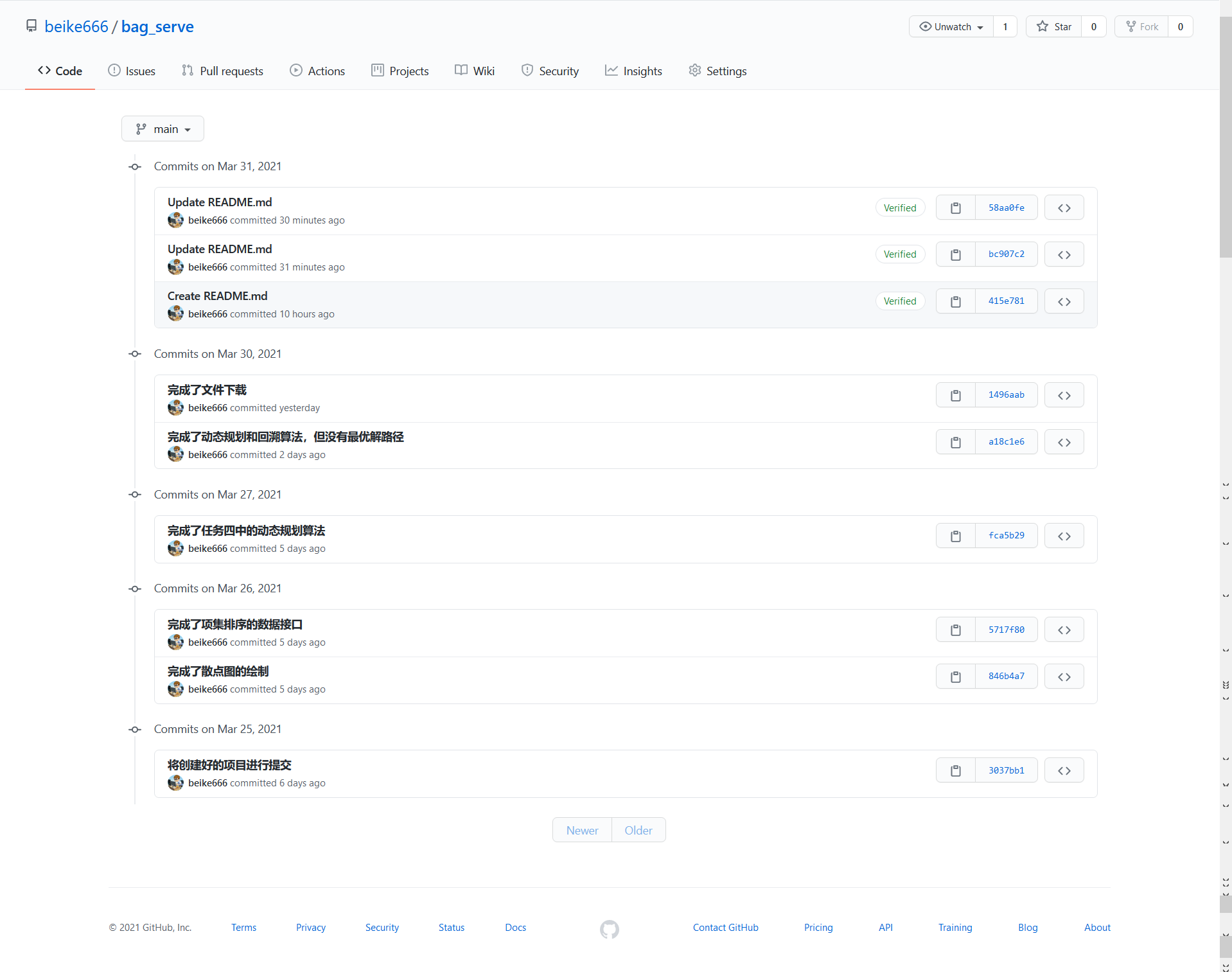
一、bag_serve仓库(后台数据接口)
- 推送项目展示
- 提交及推送记录
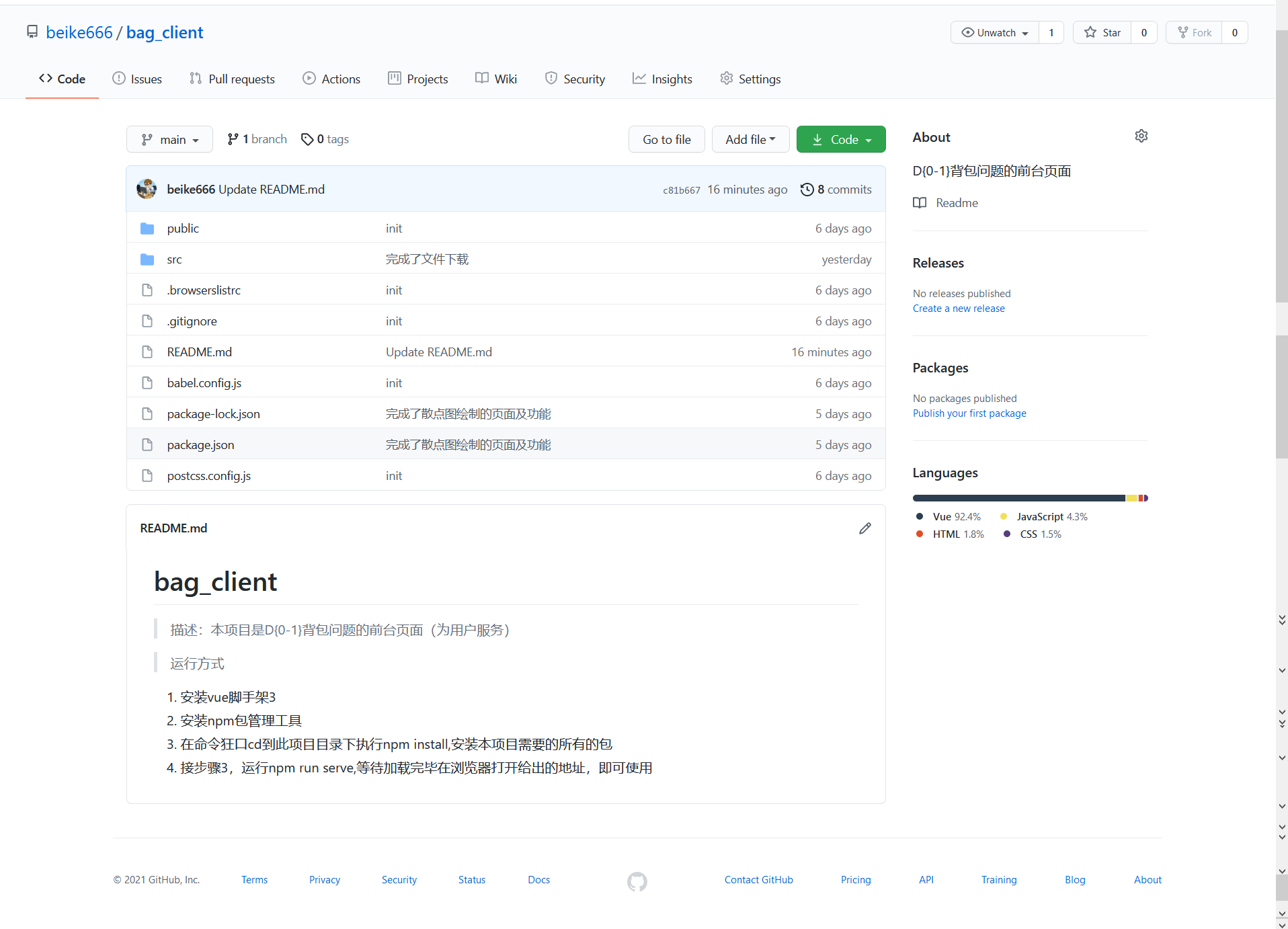
二、bag_client仓库(前台页面)
- 推送项目展示
- 提交及推送记录

 浙公网安备 33010602011771号
浙公网安备 33010602011771号