
简单爬虫项目实战(一)
概述
最近自己想搞一个小的项目,这个项目我们就先从爬虫开始,爬取直播吧的NBA滚动新闻,再存入数据库。先写个简单点的,后期再不断的优化下。
准备
直播吧对于喜欢看球的朋友肯定不陌生,https://www.zhibo8.cc/,打开我们看到如下界面,
我们选择NBA新闻tab,然后选择滚动新闻,
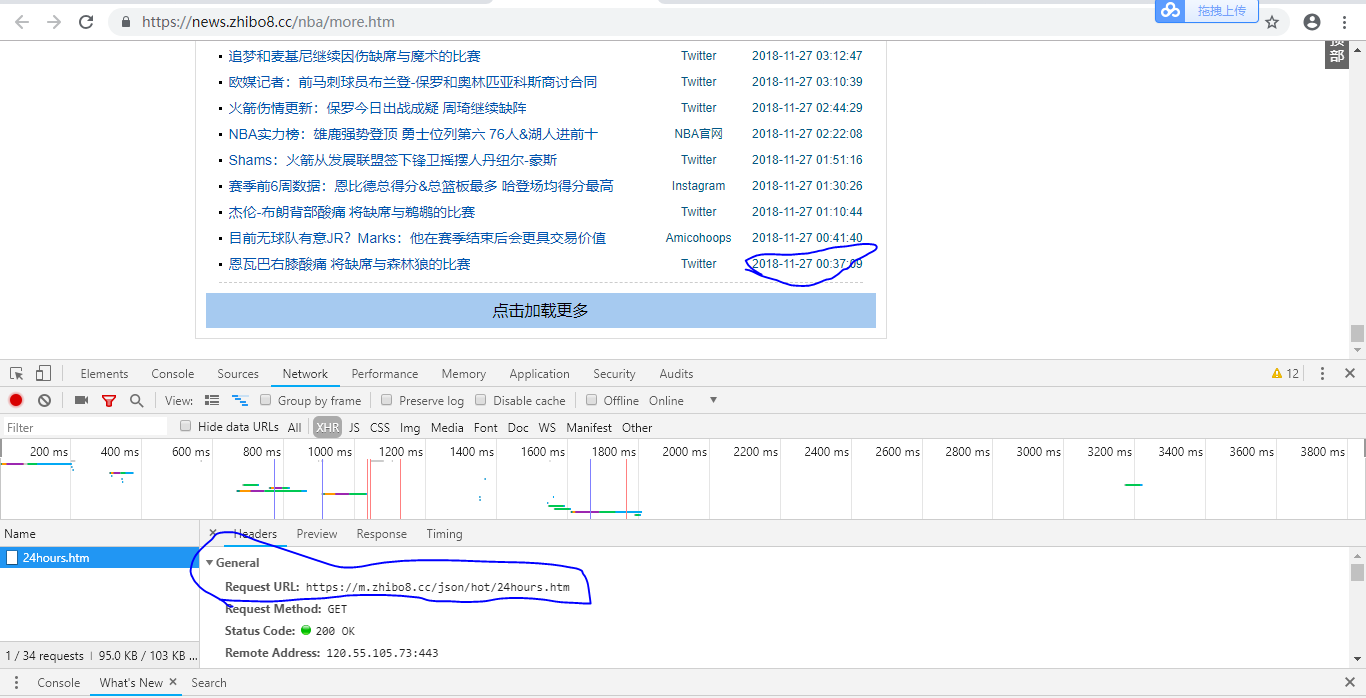
我们按下F12,分析下这个请求
我们试着来直接请求下这个地址
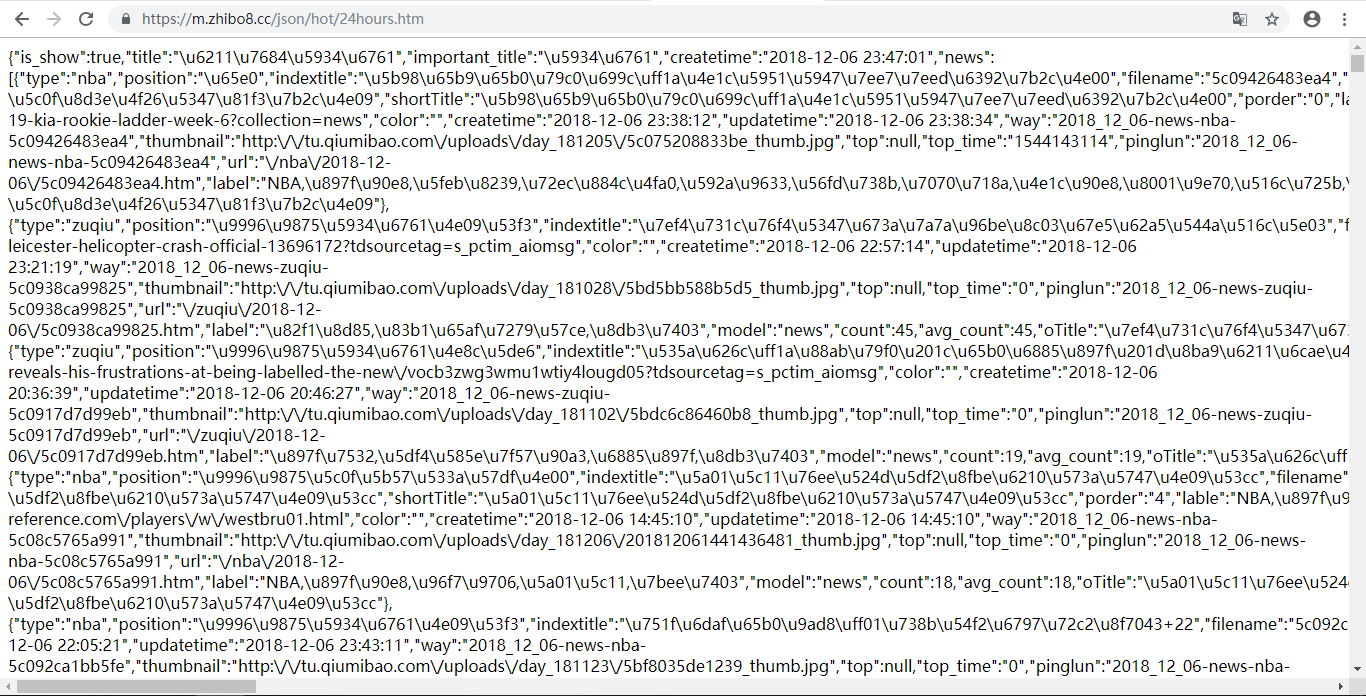
哈哈,太好了,这个就是页面上的内容啊,我们就要解析这个数据,就能得到所有数据,是不是很简单呢
代码
conn = pymysql.connect("localhost", "root", "123456", "news") # 获取连接
cursor = conn.cursor() # 获取游标 默认元组类型
cursor = conn.cursor(pymysql.cursors.DictCursor)
insert_news_sql = 'insert into news(title, url, hash, publish_time, news_type, from_name) values(%s, %s, %s, %s, %s, %s)'
response = requests.get("https://m.zhibo8.cc/json/hot/24hours.htm")
news_list = json.loads(response.text).get('news')
news_data = ()
for news in news_list:
title = news.get('title')
news_type = news.get('type')
publish_time = news.get('createtime')
url = news.get('from_url')
from_name = news.get('from_name')
hash_str = hash(title)
news_data = (title, url, hash_str, publish_time, news_type, from_name)
cursor.execute(insert_news_sql, news_data) # 执行语句
conn.commit() # 提交
cursor.close() # 关闭游标
conn.close() # 关闭连接
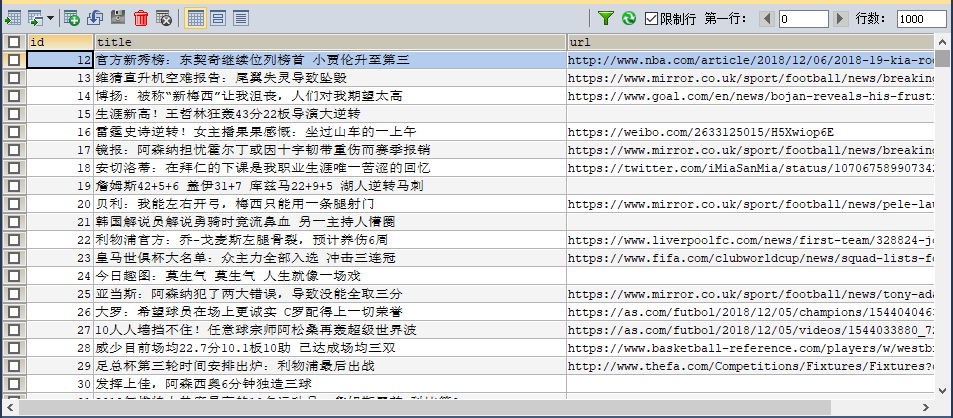
=================================================================
Easier said than done.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号