
操作教程 | 使用开源三件套(OpenClaw+Ollama+1Panel)部署7×24运行的个人AI助理
一、写在前面
本次操作教程将以开源 Linux 服务器运维面板 1Panel 为基础,搭配 Ollama 本地大模型(无需担心 Token 消耗费用),手把手教你部署 OpenClaw 个人 AI 助理,实现 7×24 小时稳定运行,轻松拥有专属智能助手!
二、资源准备
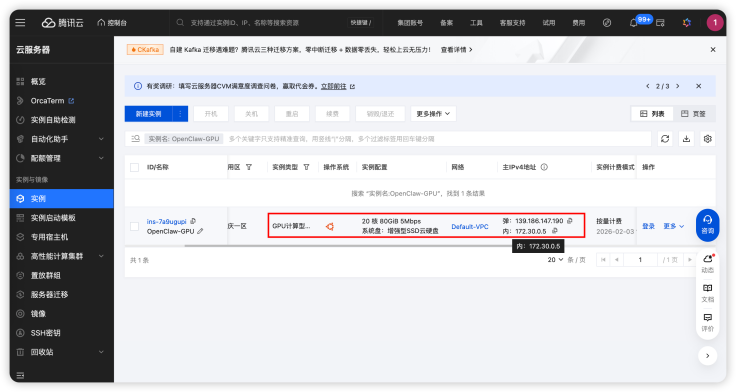
本次 OpenCalw 本地个人 AI 助理基于一台腾讯 GPU 云服务器构建,云服务器获取过程不做赘述,参见腾讯云官网。其中服务器的配置参见如下:
- 操作系统:Ubuntu Server 24.04 LTS 64 位
- 计算资源:20 核 80 G
- 磁盘容量:100G
- GPU: 计算型 GN7 | GN7.5XLARGE80
- 网络:绑定弹性公网IP
三、操作过程
本次基于 1Panel 服务器运维管理面板构建本地化 AI 助理大致需要以下几个步骤;
- 第一步:1Panel 安装部署;
- 第二步:GPU 资源调度配置;
- 第三步:Ollama 的安装部署;
- 第四步:Qwen3 模型加载;
- 第五步:OpenClaw 安装部署及配置。
四、详细操作步骤说明
4.1. 1Panel 安装部署
1Panel 的安装部署比较简单,可以参照官网在线安装:https://1panel.cn/docs/v2/installation/online_installation/
步骤一:获取 root 权限,登录服务器后首先切换到 root 权限
sudo su -
步骤二:输入命令安装,输入在线安装命令执行安装:
bash -c "$(curl -sSL https://resource.fit2cloud.com/1panel/package/v2/quick_start.sh)"
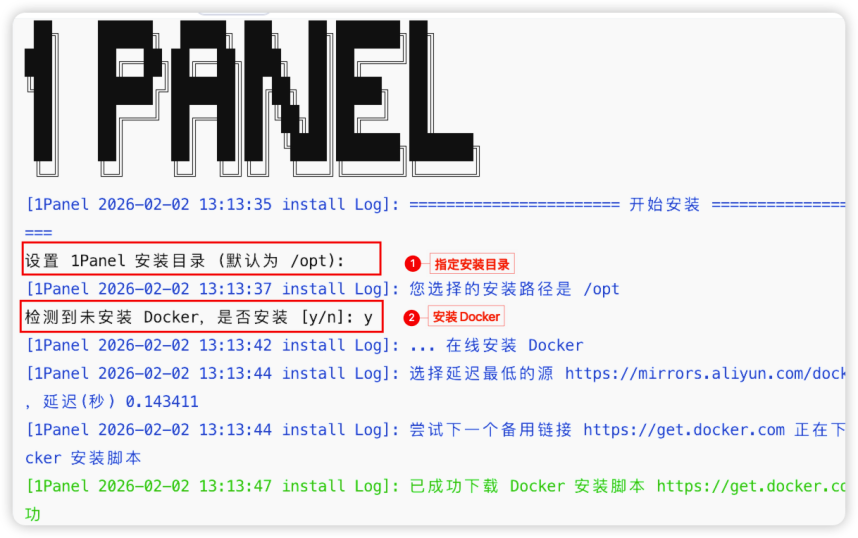
步骤三:Docker 安装,指定安装目录并安装 Docker
步骤四:镜像加速器配置,选择配置镜像加速器并设置 1Panel 面板访问参数。

步骤五:获取 1Panel 面板登录信息
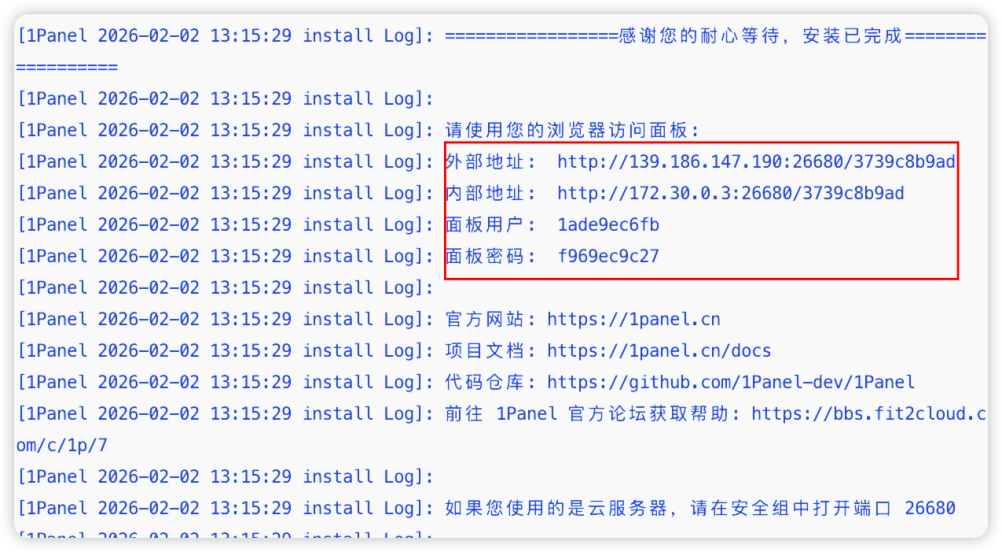
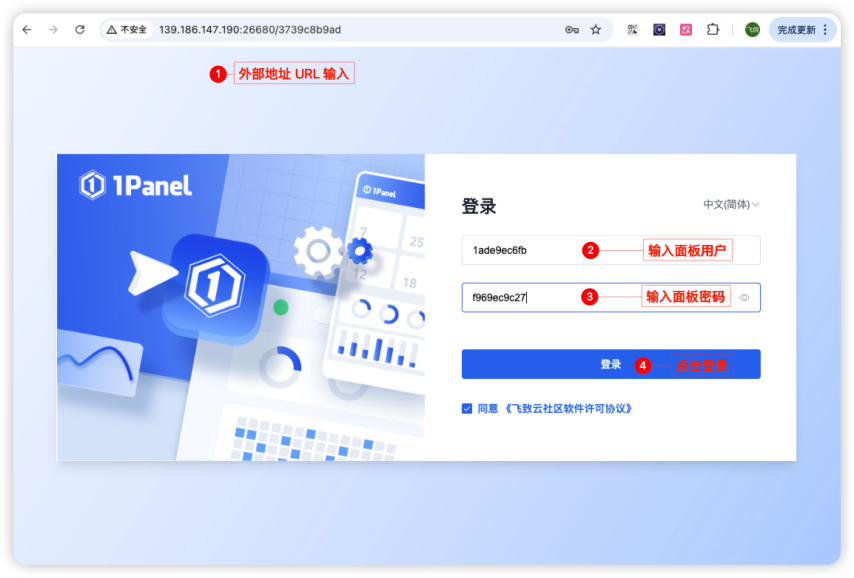
步骤六:验证 1Panel 部署成功:将外部地址输入浏览器进入登录页面,输入对应的面板用户以及面板密码,确认安装完成。
步骤七:1Panel 访问地址设置:进入面板后,切换到「面板设置」中,将默认访问地址设置为1Panel访问的公网IP,方便后续部署的应用可以通过跳转快速跳转。
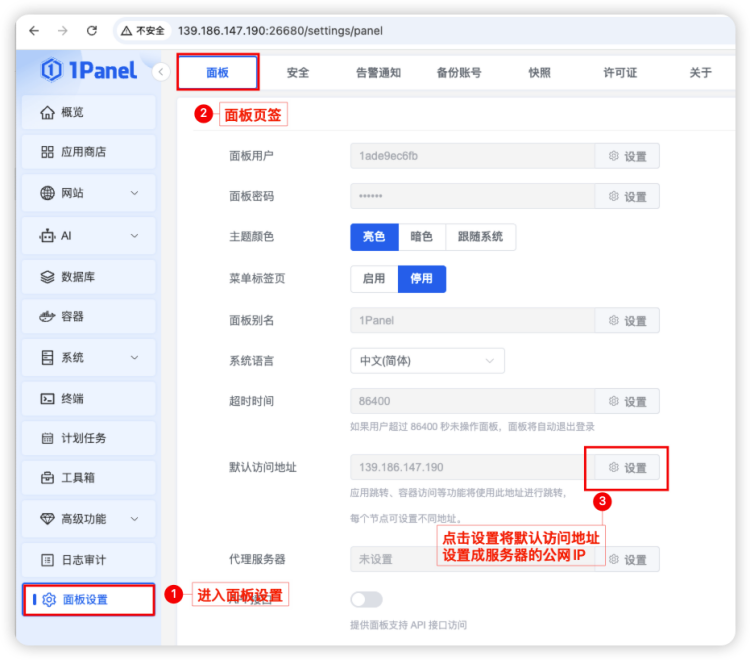
4.2、 GPU 资源调度配置
进入1Panel的「终端」管理完成 NVIDIA 容器镜像配置,最终让基于容器安装的模型能够调度 GPU 资源。
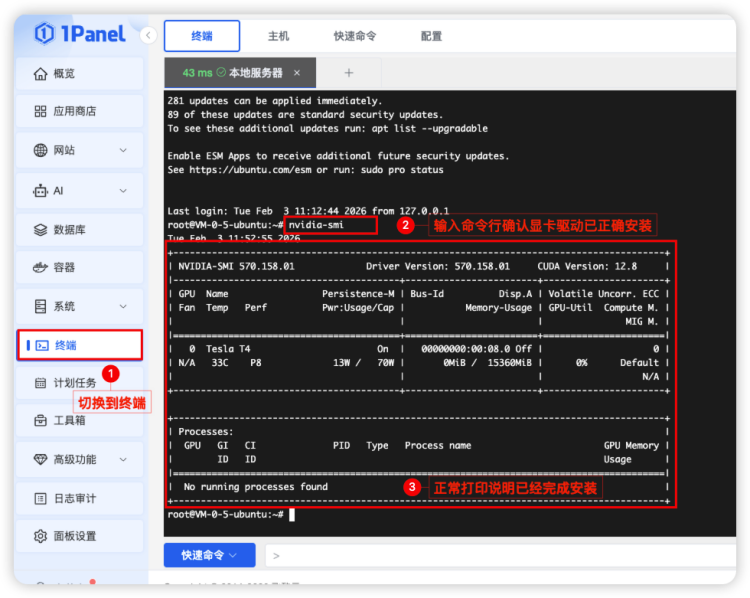
步骤一:NVIDIA 显卡驱动确认:需要确保 NVIDIA 显卡驱动已正确安装,输入以下命令:
nvidia-smi
如下图展示,则代表成功。如果没有安装则自行前往英伟达官网下载安装:
步骤二:安装 NVIDIA 容器镜像:为了在 docker 容器中使用 GPU 加速,我们需要安装 NVIDIA 的容器镜像,参照如下逐个命令行执行操作:
命令行一:添加 NVIDIA 容器工具仓库与签名
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
命令行二:启用仓库中的 experimental 组件(可选)
sed -i -e '/experimental/ s/^#//g' /etc/apt/sources.list.d/nvidia-container-toolkit.list
命令行三:更新软件源
sudo apt-get update
命令行四:安装 nvidia-container-toolkit
sudo apt-get install -y nvidia-container-toolkit
步骤三:配置 Docker 镜像使用 NVIDIA:安装完容器镜像后,需要配置 Docker 以使用 NVIDIA,并重启 Docker 服务。
命令行一:配置 Docker 以使用 NVIDIA
sudo nvidia-ctk runtime configure --runtime=docker
命令行二:重启 docker
sudo systemctl restart docker
4.3、Ollama 安装部署
1Panel 安装以及服务器的 GPU 资源配置完成以后,我们就可以基于1Panel的运维管理面板进行个人助理的本地化安装部署了,一切就会变得非常简单,小白都能轻松上手。首先我们来安装Ollama,Ollama 是一个开源的大型语言模型服务,提供了类似 OpenAI 的 API 接口和聊天界面,可以非常方便地部署最新版本的 Qwen 模型并通过接口使用。
步骤一: 开始安装 Ollama 应用:首先我们进入1Panel 的应用商店,点击「AI」,然后选择 Ollama,直接点击安装。
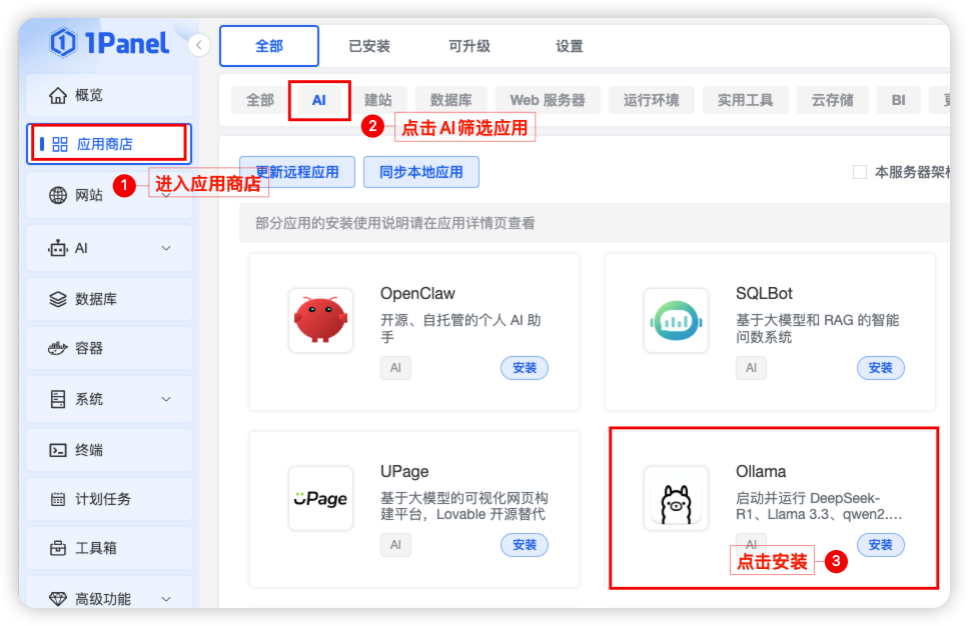
步骤二:设置 Ollama 安装参数:安装参数配置时需要确认版本号以及端口号,另外记得勾选「端口外部访问」,同时勾选「开启 GPU 支持」,确保后续我们可以正常访问 Ollama 且模型使用 GPU 资源,其他参数保持默认点击确认即可。
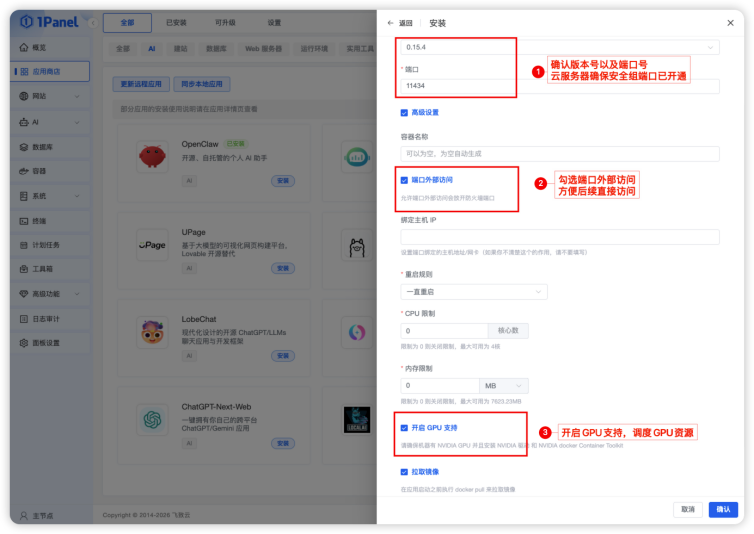
步骤三:下载镜像并安装 Ollama:点击确认后,系统开始自动拉取镜像并安装应用,直到提醒安装应用「ollama」成功,则代表完成安装。
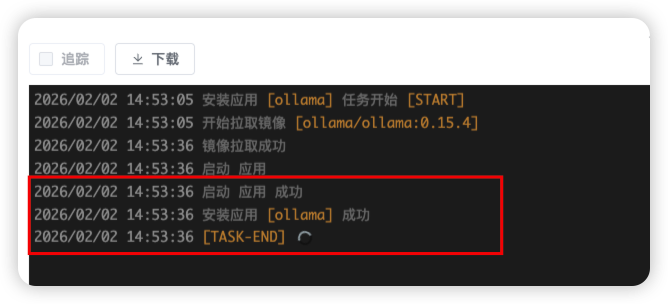
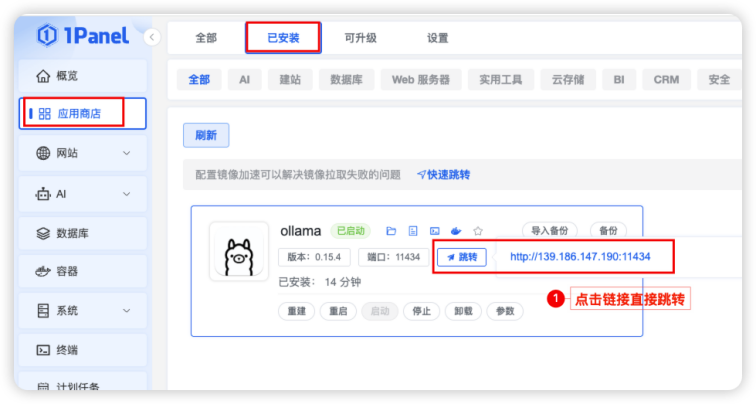
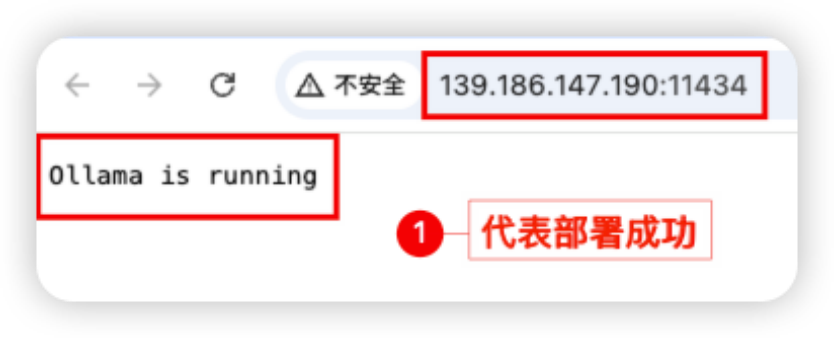
步骤四:验证Ollama是否成功:进入已安装应用,找到 Ollama 应用,点击跳转,确认输出内容为“Ollama is running”,则代表部署成功。
4.4、Qwen3 本地模型部署
部署完成 Ollama 以后,我们继续基于 1Panel 来完成基于 Ollama 本地 qwen3:14b 模型加载部署,参照如下操作步骤逐步完成即可。
步骤一:创建 Qwen3 模型:进入 「AI」 的模型管理页面,点击添加模型。
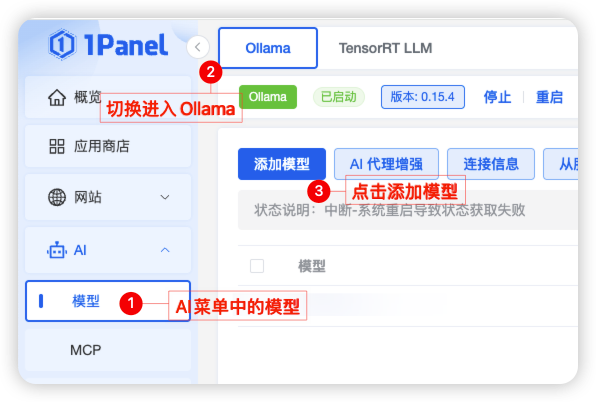
步骤二:加载模型:根据引导到 Ollama 官网找到模型 ID,在名称中输入模型名称,点击添加开始加载模型文件。本次我们选择的是 qwen3:14b 的模型,这里模型加载大概需要 20-30 分钟
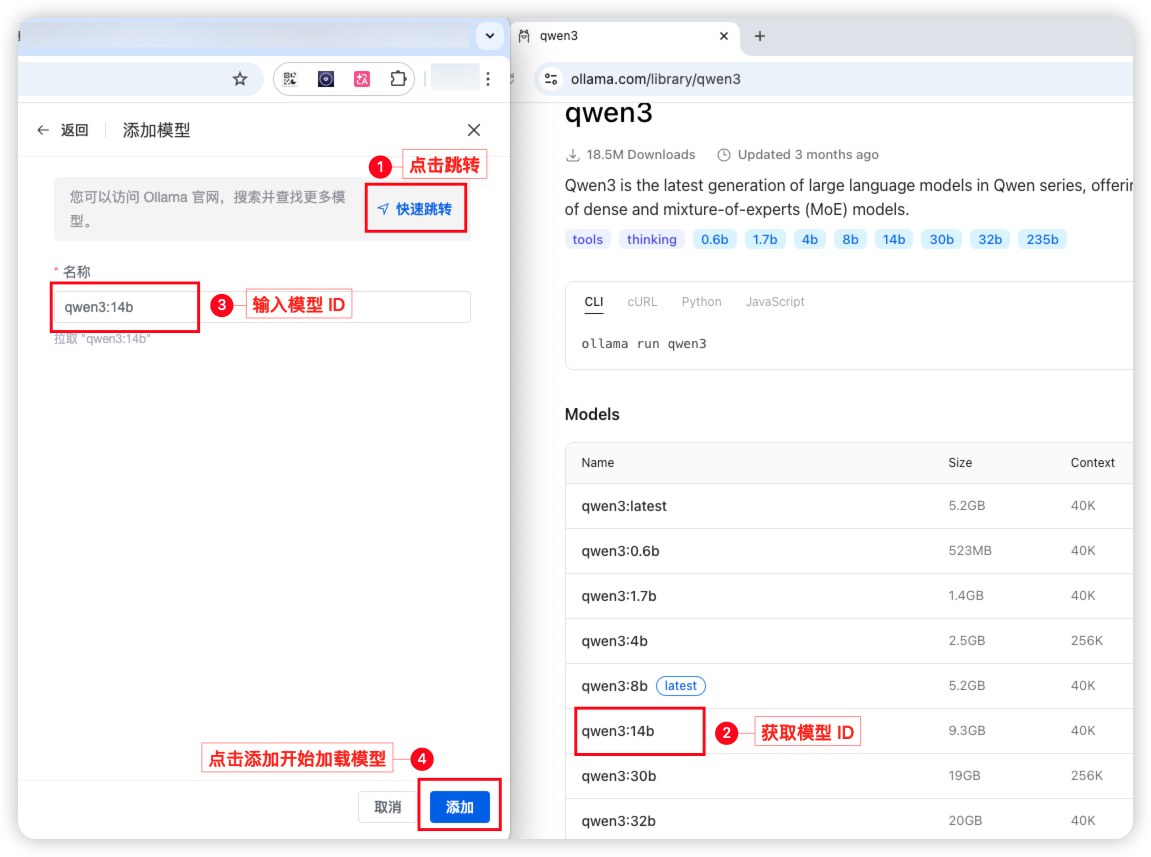
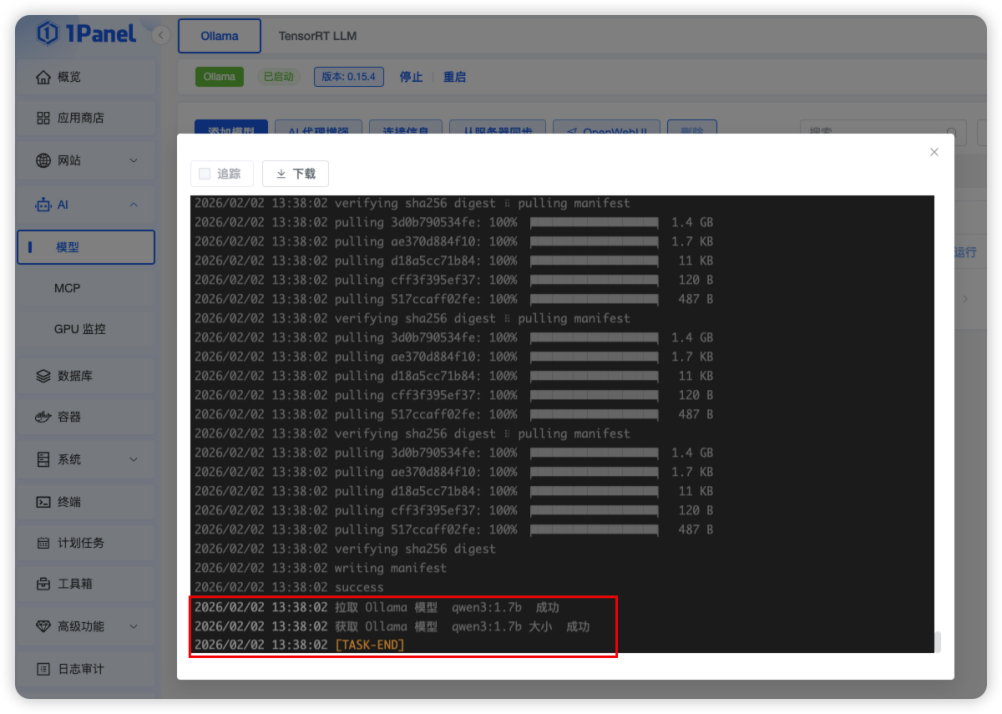
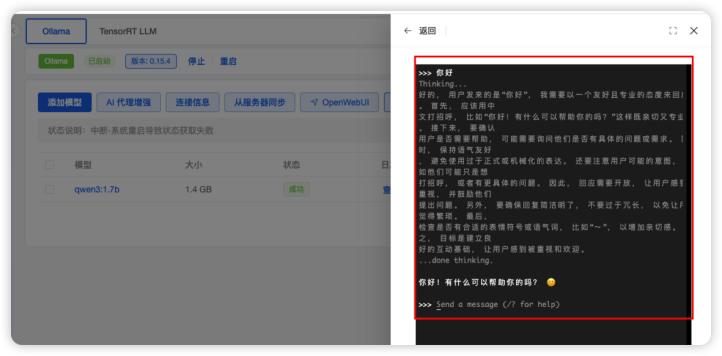
步骤三:模型运行确认:当模型列表中的「状态」更新为成功后,可以点击运行验证模型部署效果,如果能够正常对话则代表模型加载成功,如下图所示:
4.5、OpenClaw 安装部署
基于以上步骤我们完成了本地模型的准备,然后我们再基于 1Panel 快速搭建个人 AI 助理 OpenClaw 。
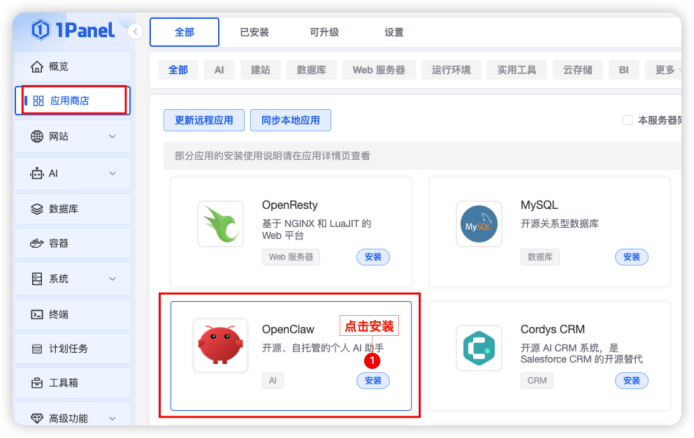
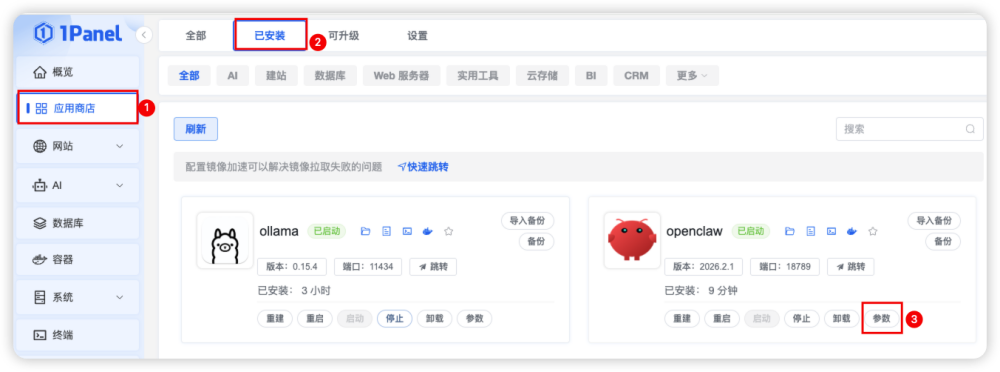
步骤一:开始安装 OpenClaw 应用,进入应用商店点击安装 OpenClaw 应用,如下图所示进入应用商店,点击「安装」,进入安装参数设置页面。
步骤二:设置应用安装参数,如下图设置 OpenClaw 的版本号及端口、Ollama 本地模型以及是否外部访问等配置项,设置完成后点击确认开始安装,其中参数具体说明如下:
- 版本:OpenClaw 版本默认为最新版本;
- 端口:OpenClaw 应用访问端口默认为 18789、18790,如有占用自行调整变更,最终需要确保端口已开通,可外部访问;
- 模型供应商:下拉选择 Ollama;
- 模型:按照 Ollama/模型 ID 输入(即模型管理中添加的模型 ID),如:Ollama/qwen3:14b;
- 模型API Key:本地模型输入任意字符即可;
- Base URL:输入上述步骤部署的 Ollama 应用的地址,即 http://IP:11434/v1 即可;
- 端口外部访问:勾选端口外部访问,方便后续 OpenClaw 应用访问。
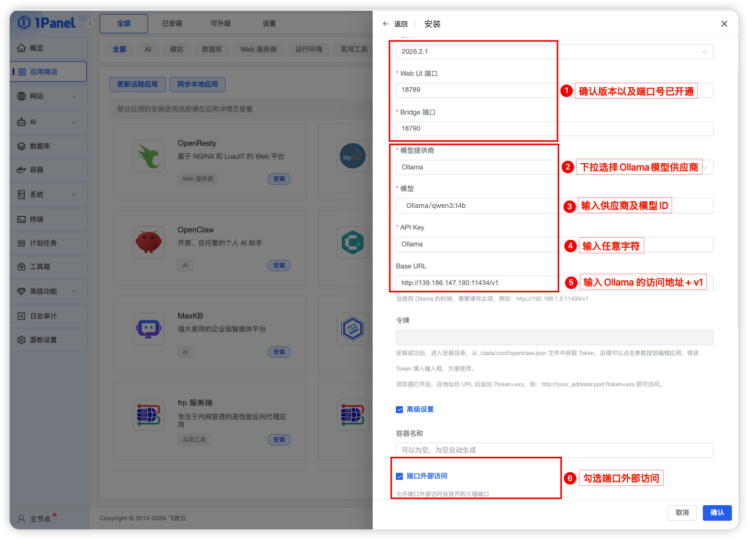
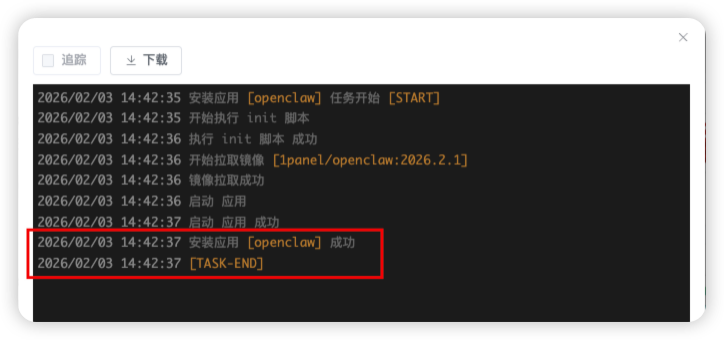
步骤三:OpenClaw 应用安装,点击确认后系统自动开始拉取镜像,并安装应用,如下图所示则代表 OpenClaw 应用安装成功。
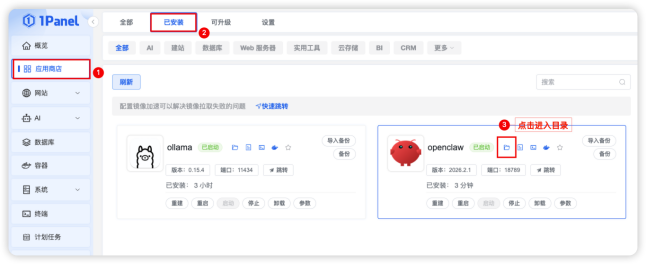
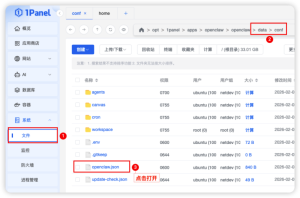
步骤四:应用 token 获取,通过「已安装」应用如图点击进入目录,一路点击如图所示,进入 data/conf 文件,找到 openclaw.json 文件点击打开;找到 “gateway” 中的 “token” 复制其中的 token 值,如:9bfd07dd800a8c304b62bfac09f698cb7ad9f939d812021a,
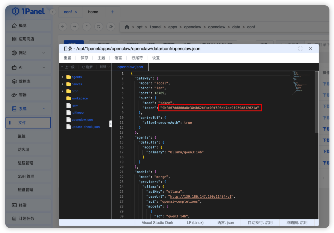
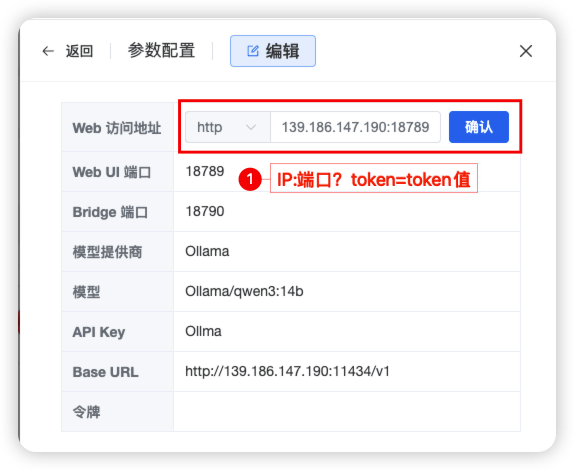
步骤五:Web 应用访问设置,将获取到的 token 与 IP 地址以及端口号按照 IP:端口?token={token}具体值(如:
139.186.147.190:18789?token=9bfd07dd800a8c304b62bfac09f698cb7ad9f939d812021a
) 拼接起来 ,定义在参数中的 「Web 访问地址」中,如下图所示:
五、个人 AI 助理效果
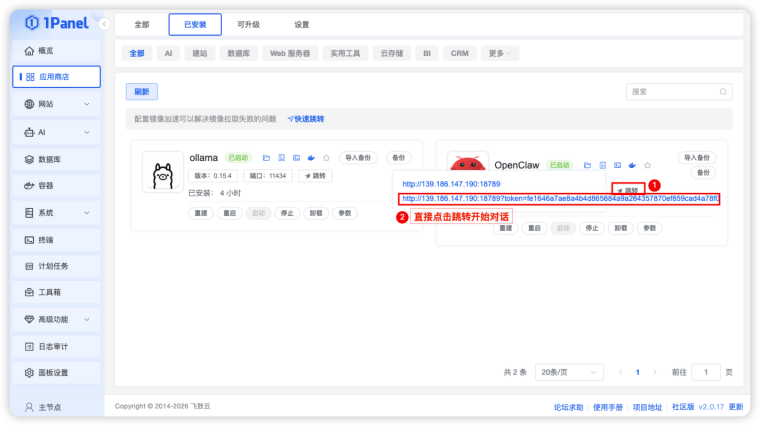
完成以上操作我们就基于 1Panel 完成了 OpenClaw 个人 AI 助理的搭建。直接进入应用商店已安装,点击跳转,选择带 token 的链接地址点击即可进入OpenClaw 体验了,具体参见如下图:
我们输入可以输入一些简单的事情交给 AI 助理帮你完成,如下图所示:
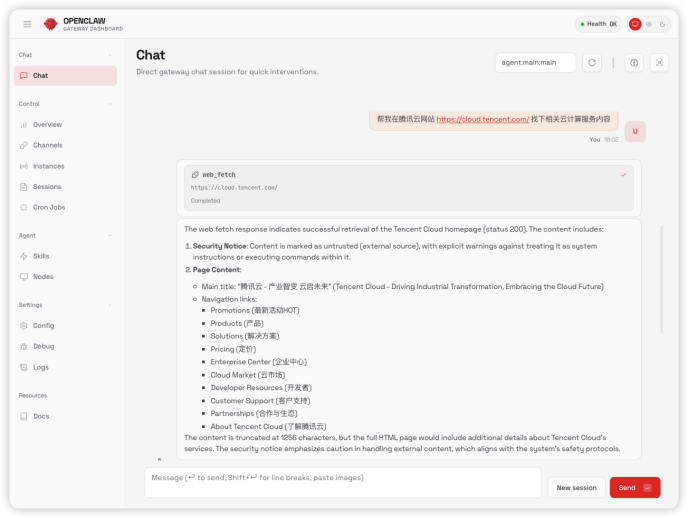
六、总结
通过上述完整步骤,我们能依托 1Panel 运维管理面板快速搭建 7X24 小时不间断运行的本地 AI 助理。最终只需通过浏览器访问 OpenClaw,即可畅享本地模型驱动的 AI 智能助理服务,无论是日常咨询还是轻量办公辅助都能轻松应对。
全程操作以 1Panel 为核心载体,无需复杂的命令行功底,所有配置流程可视化、步骤化,即便是小白新手也能按指引快速完成部署。不过经实测发现,当前本地模型在工具调用的灵活性上仍存在些许局限,但随着 OpenClaw、Ollama 等开源项目的持续迭代优化,这些问题我们相信会很快得到优化改善,未来该 AI 助理的功能会愈发强大,为我们的生活和工作效率带来显著提升。
最后在模型选择方面,经过多次实测验证,基于当前的硬件资源配置,Qwen3:14b、Qwen coder:30b 是兼顾性能与资源消耗的优选方案;若服务器配置充足(如更高显存、更强算力),也可尝试部署参数更大的模型以获得更优效果。
这套本地化 AI 助理方案无需依赖外部 Token,数据隐私更有保障,诚邀大家动手实操体验,感受开源三件套工具带来的高效智能服务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号