

java自动化——web自动化复习
之前复习整理:
模块1:https://www.cnblogs.com/xiaobaibailongma/category/1634188.html?page=3
模块2:https://www.cnblogs.com/xiaobaibailongma/category/1643583.html?page=5
=======================================================================
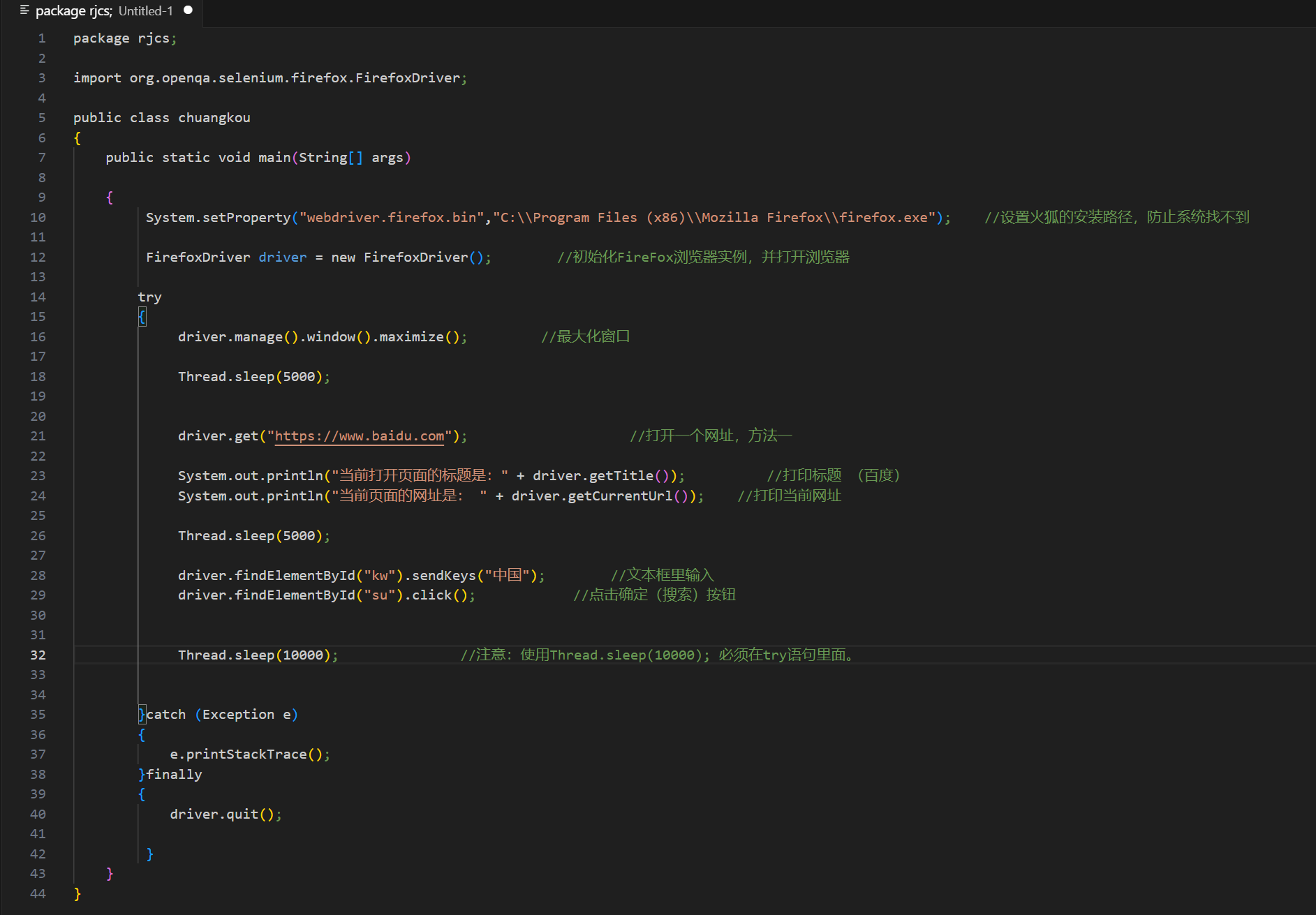
执行结果:
元素是否可见:true
元素是否编辑:true
kw标签名字:input
su标签名字:input
su标签名字:s_ipt
连接文字 地图 的 文本值:地图

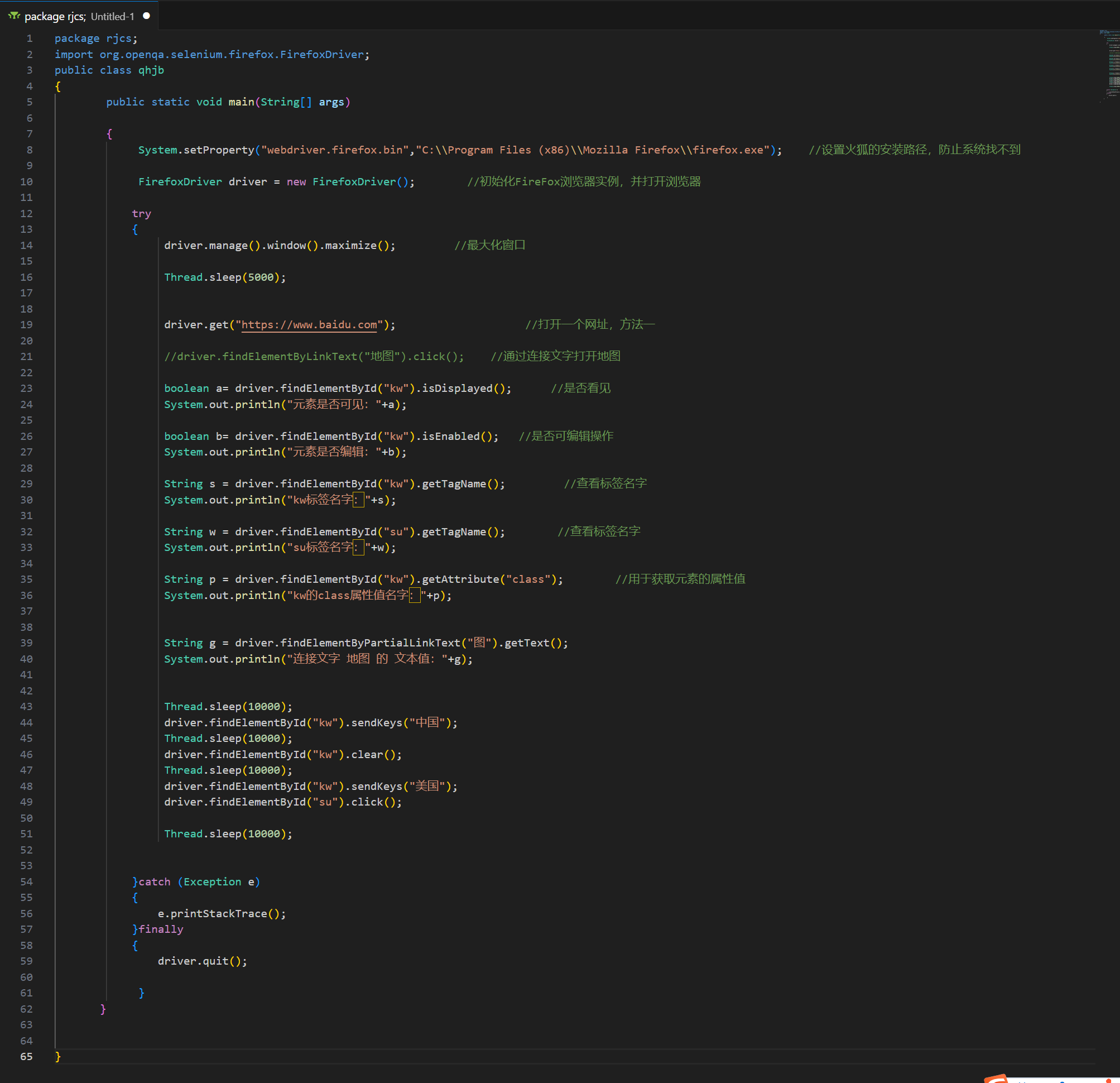
执行结果:
(300, 500)
(300, 600)
(600, 800)
元素是否可见:true
元素是否编辑:true
kw标签名字:input
su标签名字:input
kw的class属性值名字:s_ipt
连接文字 地图 的 文本值:地图
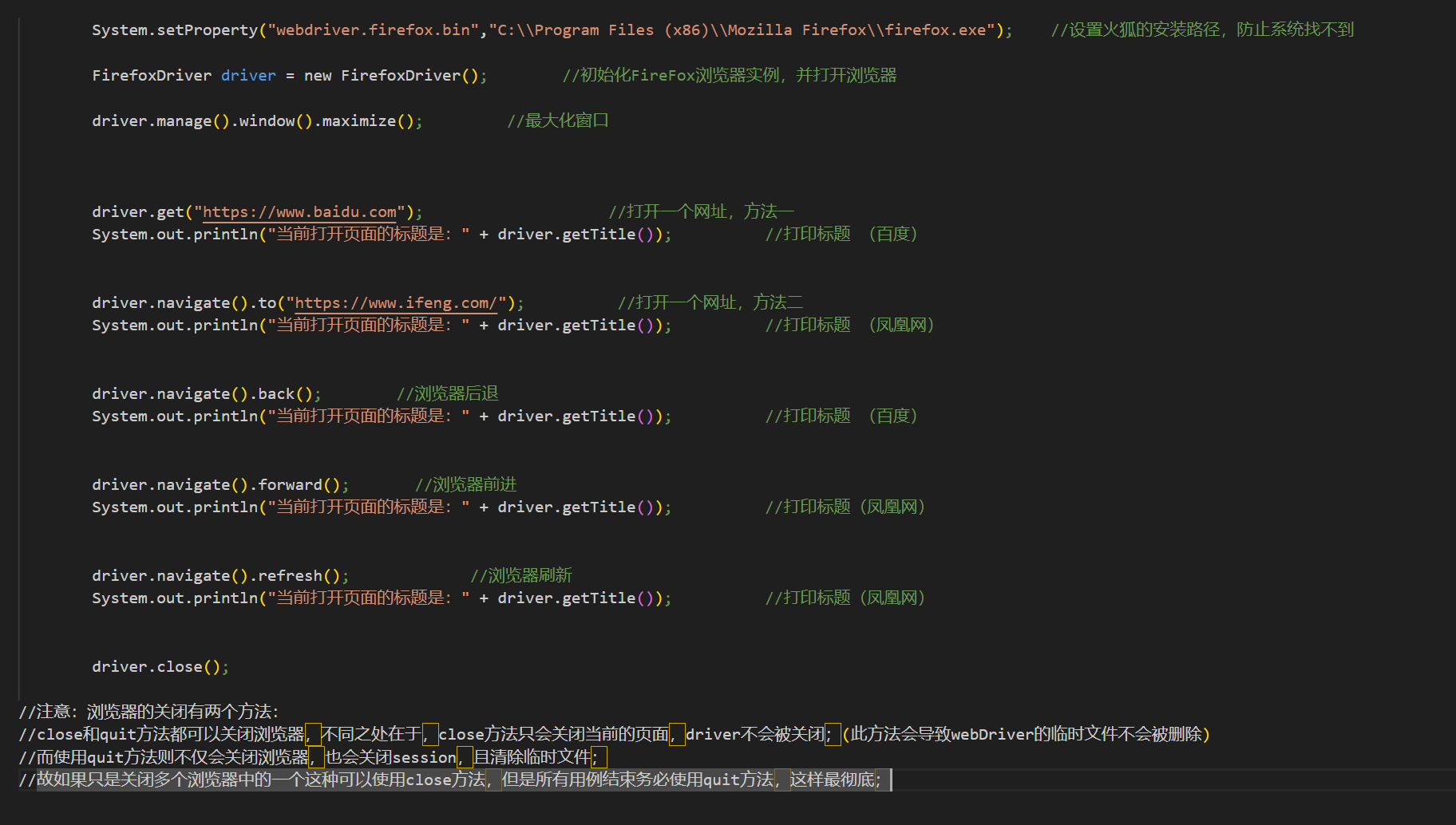
以、元素的基本操作
1、点击
代码为element.click(),此操作用于所有可以点击的操作,注意不能点击的元素用click操作会抛异常;
2、清除
代码为element.clear(),此操作用于input输入框,在输入字符串之前建议先clear下,以避免有数据导致内容输入异常;
3、发送数据
代码为element.sendKeys(keys),此操作用于input输入框;
4、提交数据
代码为element.submit(),此操作常用于form元素块儿的提交按钮,一般和发送数据配合使用,登录框比较常见;
5、获取属性
代码为element.getAttribute(attr_key),用于获取元素的属性值,attr_key为属性的key值;
6、获取css值
代码为element.getCssValue(css_key),用于获取元素的某个css值,css_key为css属性名称;
7、获取位置
代码为element.getLocation(),用于获取元素的位置信息,即该元素左上角在整个浏览器中的坐标;
8、获取大小
代码为element.getSize(),用于获取元素的大小信息,即该元素的长和宽信息,常用于元素截图,和获取位置配合使用,可以获取元素块儿其他三个点的坐标;
9、获取tag_name
代码为element.getTagName();,用于获取元素的tag名称;
10、获取内容
代码为element.getText(),用于获取元素的text的值;
11、查找元素
代码为element.findElement(By),用于根据以该元素为原点获取元素,此处不太常用;
12、是否显示
代码为element.isDisplayed(),返回该元素是否显示,对应元素的这个属性style="display: block;";
13、是否enable
代码为element.isEnable(),常用于单选框等;
14、是否被选择
代码为element.isSelected(),此项用于select元素块儿。
xpath常用定位方式:
(1)、标准写法
标准写法为//标签名[@属性名="属性值"],比如我们要找那个title为搜索热点的元素,则xpath就是这样写//div[@title='搜索热点'](这里属性值用单引号或者双引号都可以,//这个意思是从全局元素始中查找);
(2)、获取父元素
获取父元素,xpath语句中要加个/..即可,so要多级父元素,就多加几个即可,比如我们要获取上图中最上面那个div元素,其xpath可以这样写//div[@title='搜索热点']/../../..;
(3)、获取兄弟元素
获取兄弟元素,这个就可以先定位到其父元素,再下级寻找,比如上图黄色标识那个元素,xpath就可以这样写//div[@title='搜索热点']/../table;
(4)、多属性方式定位
有时候我们用单一属性进行查找还是会有重复的元素,那么怎么办呢,其实属性我们可以加多个,譬如上图中那个a标签元素,其xpath就可以这样写//a[@title='谢霆锋山寨歌迷会'][text()='谢霆锋山寨歌迷会'],注意那个[text()='谢霆锋山寨歌迷会']为text的专有写法;
(5)、获取子元素
子元素获取,子元素的话就比较简单了,可以直接在元素后加[n]就可以了,譬如要获取上图中第二个td标签的元素,则xpath可以写为//a[@title='谢霆锋山寨歌迷会'][text()='谢霆锋山寨歌迷会']/../../../td[2],注意这个td[2]中的2即为其编号,这里编号都是从1开始,如果是第一个td则可以不用加后边那个[1];
其实有个简单方法,即在chrome的开发者工具中,选中要定位的元素,右键选择copy Xpath就可以获取到其xpath,只是有时候这个xpath会很长…所以建议还是自己写比较好;
以上那5中方法是可以灵活配合使用的。
8、通过css选择器查找
与通过xpath查找类似,这个也可以直接在chrome中点击要定位的元素右键选择cssSelector来获取其css选择器,不过和xpath一样有时候会很长…不如自己写的简单(需要注意的是css选择器方式有时候写起来比xpath要简单许多,建议这个好好学习下);
这部分详细教程可以参考这个链接:http://www.w3school.com.cn/cssref/css_selectors.asp
截图以及以时间为文件名:

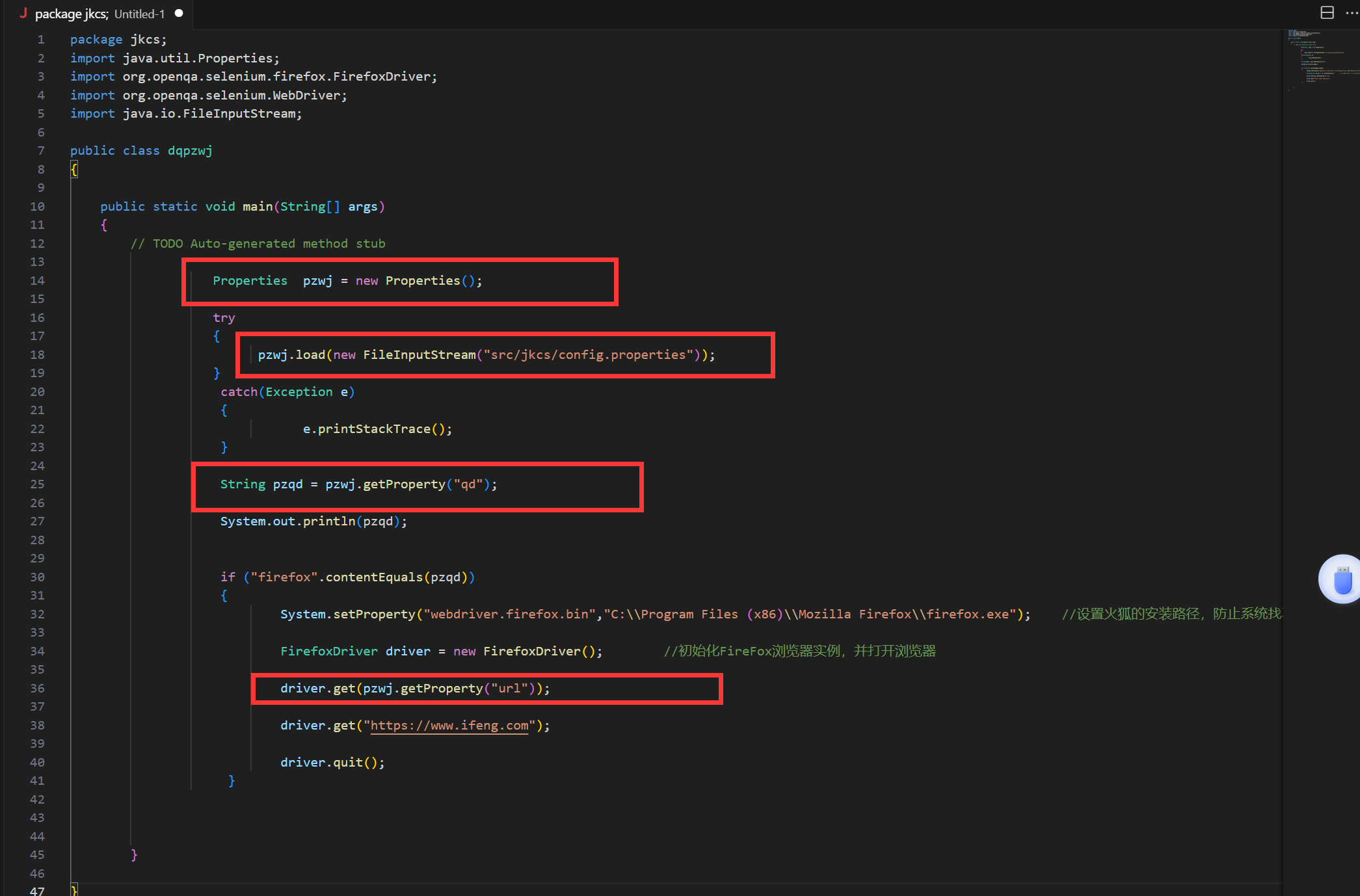
读取配置文件——config.properties
读取excel表格:







 浙公网安备 33010602011771号
浙公网安备 33010602011771号