[论文笔记]RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds

针对目前点云分割存在速度慢、显存需求大的问题,该文提出以一种高效率学习的方法。从论文的结果来看,该文不仅在计算时间和计算资源上大幅缩减,分割效果也是达到甚至超过了SOTA。
采样
大规模点云处理的一个挑战在于如何快速且有效地进行采样,从而加速应用所需的时间和计算资源。针对这个问题,本文的一个贡献在于比对了现有方法的效率,结论是尽管最远点采样是最流行的作法,但是对于LiDAR数据,每一帧上万个点需要处理,随机采样是最适合的,速度快并且performance也不错。但是随机采样可能会丢失重要的点,所以作者提出Local Feature Aggregation。
Local Feature Aggregation
该部分能并行处理点,包含三个units:1) local spatial encoding (LocSE), 2) attentive pooling, and 3) dilated residual block.
Local Spatial Encoding
对于每个采样点,在原所有点云中找其KNN个临近点(欧氏距离);再将该点和临近点以及他们之间的差concatenate并用MLP学习得到相对位置
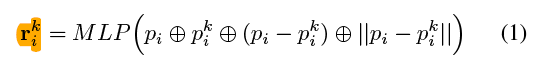
每个采样点得到相对位置后,将其和该点的特征concate,得到该点的一系列最终的增强采样点,组成一个向量。
Attentive Pooling
用attention的方式取代max/mean pooling进行特征融合
Dilated Residual Block
多层叠加

整个网络结构


 浙公网安备 33010602011771号
浙公网安备 33010602011771号