

07_查询数据_查询性能_查询计划
一、查询性能

代码:
show gp_dynamic_partiton_pruning ;
二、查询分析
1、查询计划

注:获取磁盘页的数量越少,I/O和CPU消耗的越少;
EXPLAIN这个不是最优的查询计划,因为他是评估的,并没有真正执行语句,如果表发生了巨大的变化,然而统计信息没有统计到,就会导致查询计划不正确;
EXPLAIN ANALTZE 获取的是最实际的查询计划;
在实际情况中我们最好是使用EXPLAIN,通过定期的EXPLAIN来收集信息,因为EXPLAIN ANALTZE执行时间长;
2、查询分析-查看EXPLAIN输出
EXPLAIN数据一个计划为节点组成的数;
每个节点表示一个独立的操作;
计划应该从下向上读,每个节点得到的记录向上传递;
成本评估项:

slice:Greenplum在实现分布式执行计划的时候,需要将SQL拆分成多个切片,每个slice是单裤执行的一部分SQL,每一个广播或者重分布会产生一个切片,每一个切片在每一个数据结点上都会对应的发起一个进程来处理该slice负责的数据,上一层负责该slice的进程会读取下级slice广播或重分布的数据,之后进行相应的计算。
cost:数据库自定义的消耗单位,通过统计信息来估计SQL消耗。(查询分析是根据analyze的固执生成的,生成之后按照这个查询计划执行,执行过程中analyze是不会变的。所以如果估值和真是情况差别较大,就会影响查询计划的生成。)
width:返回结果集每一行的长度,这个长度值是根据pg_statistic表中的统计信息来计算的。
注:获取第一条记录的就是开始成本,获取全部记录的是总成本;
width反映的是数据的宽度,如:不同字段的类型,他所占用的长度;
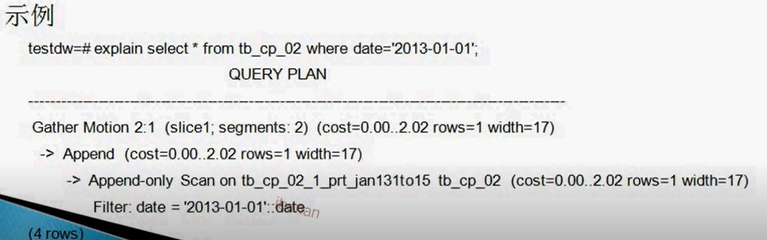
注:由下往上先看Append-only:它使用了分区查询,可以看见它的开始成本
在看Append
最后看Gather Motion:这一步是Segment向master传递,可以看见总成本;
3、查询分析-查看EXPLAIN ANALTZE输出


注: 我们可以对比explain和explain analyze的 cost ,可以了解到是否是真实的;
4、查询计划-如何查看查询计划
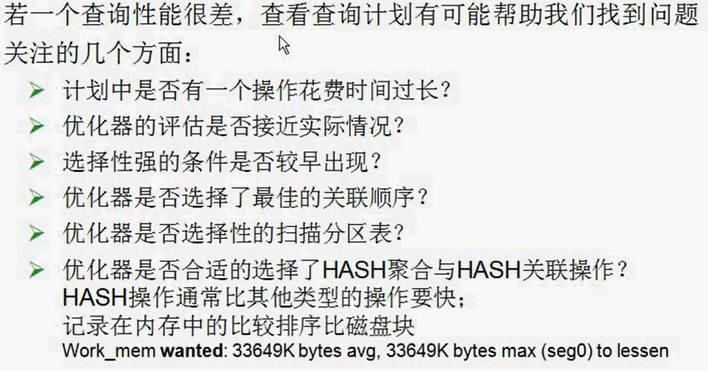
(1)计划中是否有一个操作花费时间超长
查询计划中是否有一个操作花费了大部分的处理时间?例如,如果一个索引扫描比预期的时间超长,也许该索引已经处于过期状态,需要考虑重建索引。还可临时尝试使用enable_之类的参数查看是否可以强制选择不同的计划(可能会更好的效果),这些参数可以设置特定的查询计划操作为开启或关闭状态。
(2)规划器的评估是否接近实际情况
执行EXPLAIN ANALYZE查看规划器评估的记录数与真实运行查询操作返回的记录数是否一致。
(3)选择性强的条件是否较早出现
选择性强的条件应该被较早应用,从而使得在计划树中上传的记录更少。如:表中有100万的数据,选择性强的条件可以只取其中1000行。
(4)规划器是否选择了最佳的关联顺序
如查询使用多表关联,需要确保规划器选择了选择性最好的关联顺序。那些可以消除大量记录的关联应在更早的被执行,从而使得在计划树中上传的记录更少。如果规划器没有选择最佳的关联顺序,可以尝试设置join collapse limit=1并在SQL语句中构造特定的关联顺序,从而可以强制规划器选择指定的关联顺序。如:我们可以将大表和小表先关联或者小表与小表先关联,然后查看他的查询计划,看看哪种关联方式更好。
(5)规划器是否选择性的扫描分区表
父表的扫描返回0条数据,因为父表不含数据。
(6)规划器是否合适的选择了hash聚合与hash关联操作
HASH操作通常比其他类型的关联和聚合要快。记录在内存中的比较排序比磁盘快。要使用HASH操作,必须有足够的工作内存用以放置评估的记录。对于特定查询可以尝试增加工作内存来查看是否能够获得更好的性能。如果可能,为该查询执行EXPLAIN ANALYZE,将可以得到哪些操作缓存到磁盘(由于工作内存不足导致,会导致效率低下),多少的工作内存被使用,以及需要多少内存以保证不缓存到磁盘。例如:
Work_mem used: 23430K bytes avg, 23430K bytes max (seg0)
Work _mem wanted: 33649K bytes avg, 33649K bytes max (seg0) to lessen
workfile l/O affecting 2 workers.
需要注意的是wanted信息只是一个提示,基于写出工作文件的量是不精确的。需要的最小work mem可能会比提示的值或多或少一些。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号