PHP算法
算法复杂度
算法复杂度:执行算法所需的计算工作量。一般来说,计算机算法是问题规模n的函数f(n),算法的时间复杂度也因此记做T(n)=O(f(n));
常见时间复杂度有:常数阶、线性阶、平方阶、立方阶、对数阶、nlog2n阶、指数阶。
效率:O(1) > O(log2n)> o(n)> o(nlog2n) > o(n^2) > o(n^3) > o(2^n) > o(n!) > o(n^n)。
快速排序
快速排序:它的精髓在于切分位置(Partition)的选取,也就是找出一个中轴(pivot),之后进行左右递归进行排序。
在《算法导论》中,快速排序有两种方法Hoare-Partition和Lomuto-Partition。简单的说,抛开中轴数(pivot)选取的不同不说,他们都有两个指针,Hoare的指针一头一尾,各往中间移动;Lomuto两个指针都是从前往后移动。
随机找出一个数(通常就拿数组的第一个数就行),把它插入一个位置,使得它左边的数都比它小,右边的数都比它大,这样就将一个数组分成了两个子数组,然后在按照同样的方法把子数组分成更小的子数组,直到不能分解为止。用比较通俗的话:挖坑填数+分而治之。
平均情况复杂度:时间复杂度为O(nlog2n),空间复杂度为O(log2n)~O(n)。
function find_pivot(&$arr, $low, $high) {
$target = $arr[$low]; // 将目标数存起来
while($low < $high) { // 从数组的两端交替向中间扫描
// 从右向左找小于target的数
while($low < $high && $arr[$high] >= $target) {
$high--;
}
$arr[$low] = $arr[$high]; // 将arr[high]填到arr[low]中
// 从左向右找大于target的数
while($low < $high && $arr[$low] <= $target) {
$low++;
}
$arr[$high] = $arr[$low]; // 将arr[low]填到arr[high]中
}
$arr[$high] = $target; // 此时low=high,将目标数填入这个坑中
return $high;
}
function quick_sort(&$arr, $low, $high){
$pivot = find_pivot($arr, $low, $high); // 将$arr[$low...$high]一分为二,算出枢轴值
if ($low<$pivot-1){
quick_sort($arr, $low, $pivot-1); // 对低子表进行递归排序
}
if ($pivot+1 < $high){
quick_sort($arr, $pivot+1, $high); // 对高子表进行递归排序
}
}
9999个不相同的随机整型测试性能数据:
耗时0.043秒
Now memory_get_usage: 1.5591049194336
User time: 6.433421
System time: 0.00609
冒泡排序
冒泡排序:两两比较,前者大于后者则交换(默认从小到大排列,倒序则相反)
平均情况复杂度:时间复杂度为O(n^2),空间复杂度为O(1)。
function bubble_sort($arr) {
for($i = 0; $i < count($arr)-1; $i++) {
for($j = $i+1; $j < count($arr); $j++) {
if($arr[$i] > $arr[$j]) {
$temp = $arr[$i];
$arr[$i] = $arr[$j];
$arr[$j] = $temp;
}
}
}
return $arr;
}
9999个不相同的随机整型测试性能数据:
耗时6.839秒
Now memory_get_usage: 1.5567626953125
User time: 6.383401
System time: 0.00609
选择排序
原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。然后再从剩余未排序元素中找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。通俗的讲就是找最小的数交换换位置。
平均情况复杂度:时间复杂度为O(n^2),空间复杂度为O(1)。
function selection_sort($arr) {
$count = count($arr);
if($count < 2) return $arr;
for($i = 0; $i < $count-1; $i++) {
//记录第$i个元素后的所有元素最小值下标
$min = $i;
for($j = $i + 1;$j < $count;$j ++){
if($arr[$j] < $arr[$min]){
$min = $j;
}
}
if($min != $i) {
// 交换位置
$temp = $arr[$min];
$arr[$min] = $arr[$i];
$arr[$i] = $temp;
}
}
return $arr;
}
9999个不相同的随机整型测试性能数据:
耗时5.574秒
Now memory_get_usage: 1.5570220947266
User time: 2.668671
System time: 0.007831
二分查找(了解)
二分查找:每次查找都将查找范围缩小一半,直至找到目标数据。
二分查找递归实现(csdn找的):
function binSearch2($arr, $low, $height, $k) {
if($low <= $height) {
$mid = floor(($low + $height) / 2); //获取中间数
if($arr[$mid] == $k) {
return $mid;
}elseif($arr[$mid] < $k) {
return binSearch2($arr, $mid+1, $height, $k);
}elseif($arr[$mid] > $k){
return binSearch2($arr, $low, $mid-1, $k);
}
}
return -1;
}
查找算法 KMP(了解)
csdn一篇lz认为还较为详细的博文
copy的KMP简介
Knuth-Morris-Pratt 字符串查找算法,简称为 “KMP算法”,常用于在一个文本串S内查找一个模式串P 的出现位置,这个算法由Donald Knuth、Vaughan Pratt、James H. Morris三人于1977年联合发表,故取这3人的姓氏命名此算法。
下面先直接给出KMP的算法流程(如果感到一点点不适,没关系,坚持下,稍后会有具体步骤及解释,越往后看越会柳暗花明☺):
假设现在文本串S匹配到 i 位置,模式串P匹配到 j 位置
如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++,继续匹配下一个字符;
如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]。此举意味着失配时,模式串P相对于文本串S向右移动了j - next [j] 位。
换言之,当匹配失败时,模式串向右移动的位数为:失配字符所在位置 - 失配字符对应的next 值(next 数组的求解会在下文的3.3.3节中详细阐述),即移动的实际位数为:j - next[j],且此值大于等于1。
深度、广度优先搜索(了解)
在学校算法课上学过,但是还是没信心能把他描述清楚,这里要求也只是简单了解,还是引用大神的文章了
深度优先遍历图算法步骤:
1.访问顶点v;
2.依次从v的未被访问的邻接点出发,对图进行深度优先遍历;直至图中和v有路径相通的顶点都被访问;
3.若此时图中尚有顶点未被访问,则从一个未被访问的顶点出发,重新进行深度优先遍历,直到图中所有顶点均被访问过为止。
广度优先遍历算法步骤:
1.首先将根节点放入队列中。
2.从队列中取出第一个节点,并检验它是否为目标。如果找到目标,则结束搜寻并回传结果。否则将它所有尚未检验过的直接子节点加入队列中。
3.若队列为空,表示整张图都检查过了——亦即图中没有欲搜寻的目标。结束搜寻并回传“找不到目标”。
4.重复步骤2。
LRU 缓存淘汰算法(了解,Memcached 采用该算法)
LRU (英文:Least Recently Used), 意为最近最少使用,这个算法的精髓在于如果一块数据最近被访问,那么它将来被访问的几率也很高,根据数据的历史访问来淘汰长时间未使用的数据。
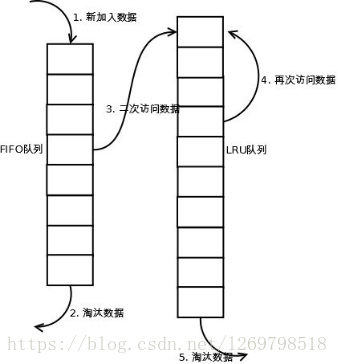
对图理解:
新数据插入到链表头部;
每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
当链表满的时候,将链表尾部的数据丢弃。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号