寒假生活(StandAlone HA 运行原理)
Spark Standalone集群是Master-Slaves架构的集群模式,和大部分的Master-Slaves结构集群一样,存在着Master 单点故障(SPOF)的问题。
如何解决这个单点故障的问题,Spark提供了两种方案:
1.基于文件系统的单点恢复(Single-Node Recovery with Local File System)--只能用于开发或测试环境。
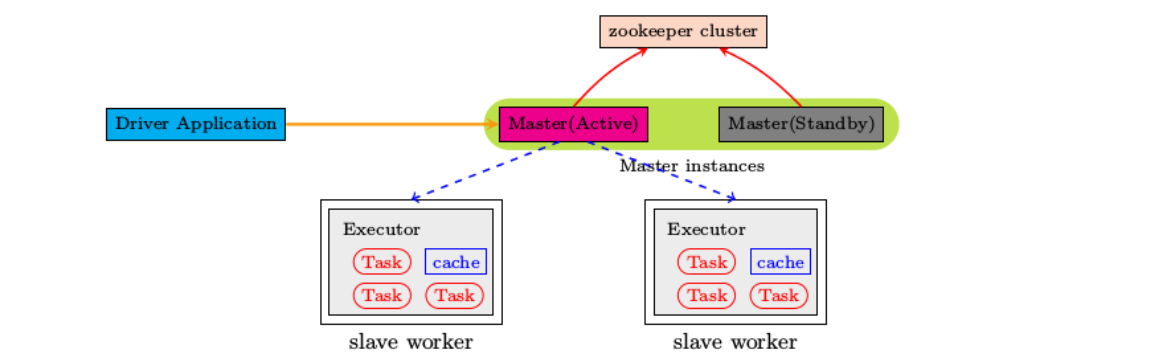
2.基于zookeeper的Standby Masters(Standby Masters with ZooKeeper)--可以用于生产环境。 ZooKeeper提供了一个Leader Election机制,利用这个机制可以保证虽然集群存在多个Master,但是只有一个是Active 的,其他的都是Standby。当Active的Master出现故障时,另外的一个Standby Master会被选举出来。由于集群的信息 ,包括Worker, Driver和Application的信息都已经持久化到文件系统,因此在切换的过程中只会影响新Job的提交,对 于正在进行的Job没有任何的影响。加入ZooKeeper的集群整体架构如下图所示。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号