Django ORM执行sql语句 双下划线 外键字段创建 ORM跨表查询
模型层之ORM执行SQL语句
有时候ORM的操作效率可能偏低 我们是可以自己编写SQL的
如何在django中使用原生SQL?
方式1一
使用pymysql模块
方式二
raw查询关键字主要是对应sql里select查
使用for循环才能打印,raw方法查询到的数据值:
models.User.objects.raw('select * from app01_user;')
使用query方法查看SQL:

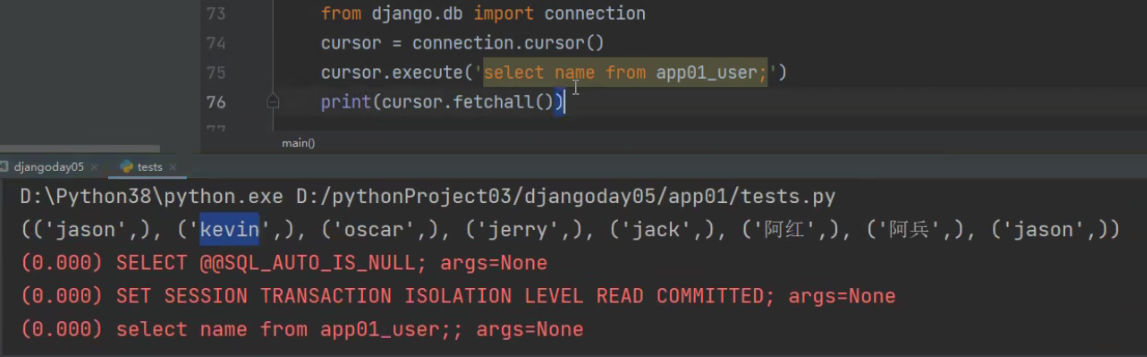
方式三
from django.db import connection
cursor = connection.cursor()
cursor.execute('select name from app01_user;')
print(cursor.fetchall())
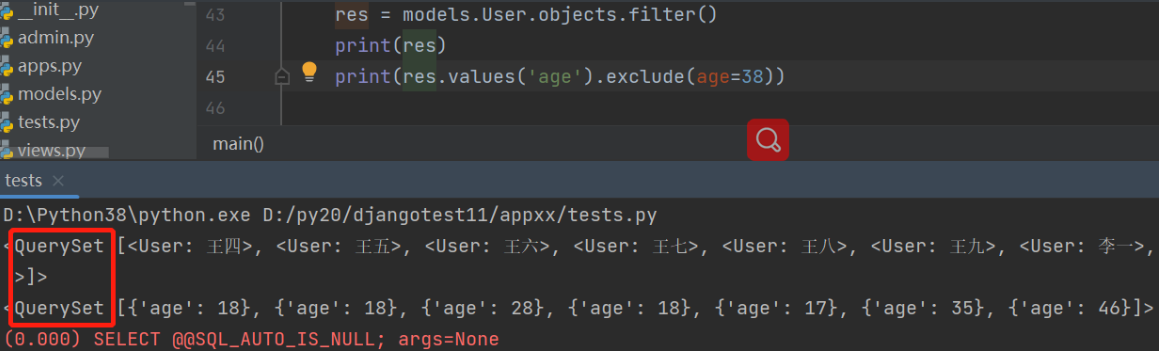
神奇的双下划线查询
只要我们拿到的是queryset对象就可以无限制的点queryset对象的方法
''' queryset.filter().values().filter().values_list().filter()...
'''
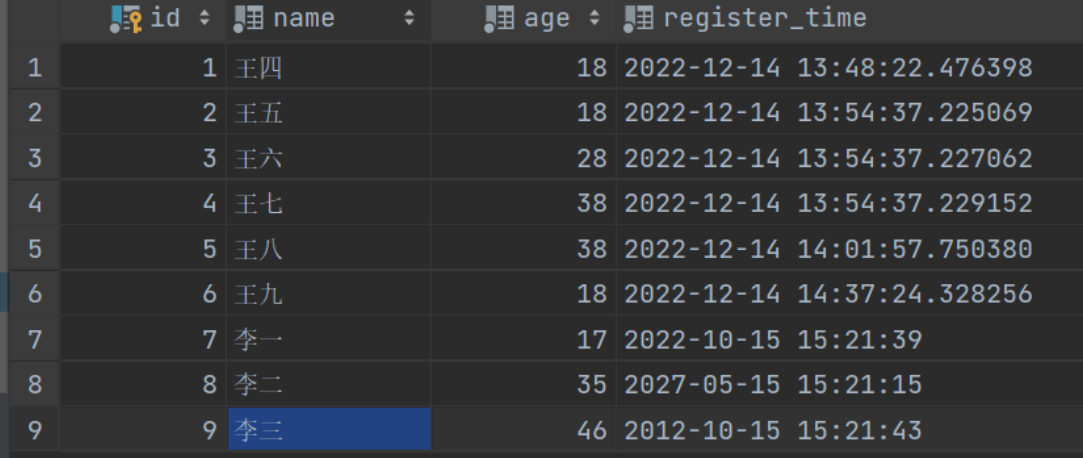
表数据:
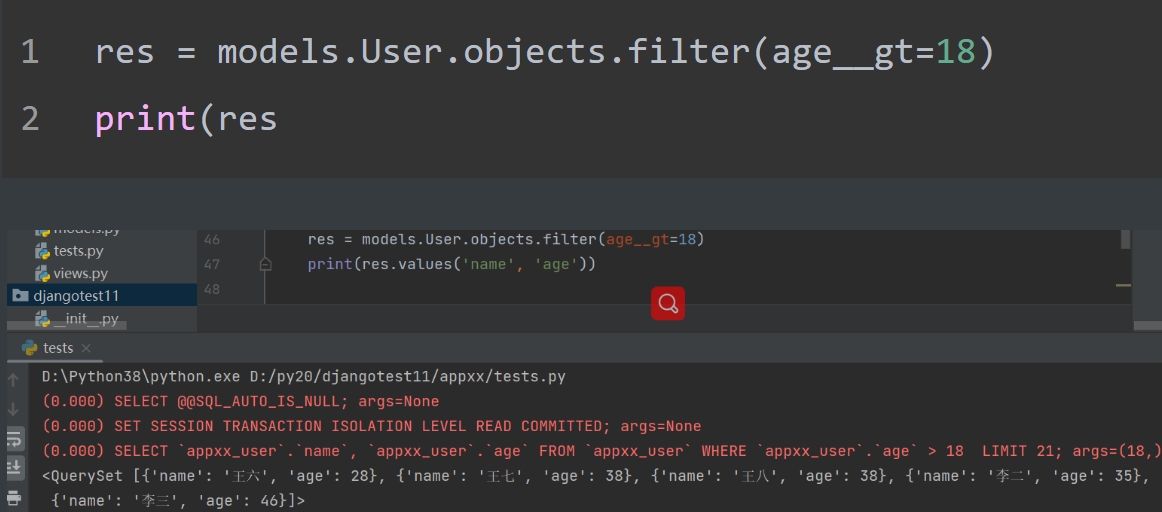
大于 小于
查询年龄大于18的用户数据:
res = models.User.objects.filter(age__gt=18)
print(res
注意:这里的age是user表内的一个字段名
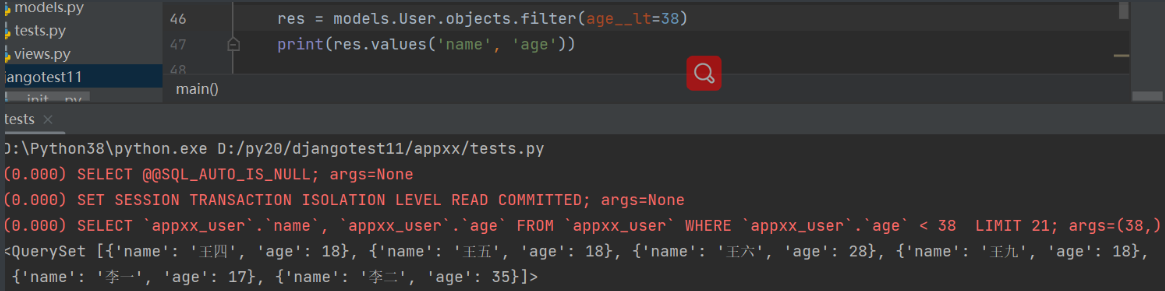
查询小于年龄38的用户数据:
res = models.User.objects.filter(age__lt=38)
print(res)
大于等于 小于等于
res = models.User.objects.filter(age__gte=18)
res = models.User.objects.filter(age__lte=38)
类似于成员运算
查询年龄是18或者28或者38的数据
res = models.User.objects.filter(age__in=(18, 28, 38))
print(res)
查询年龄在18到38范围之内的数据
相当于原生SQL中的between
res = models.User.objects.filter(age__range=(18, 38))
print(res)
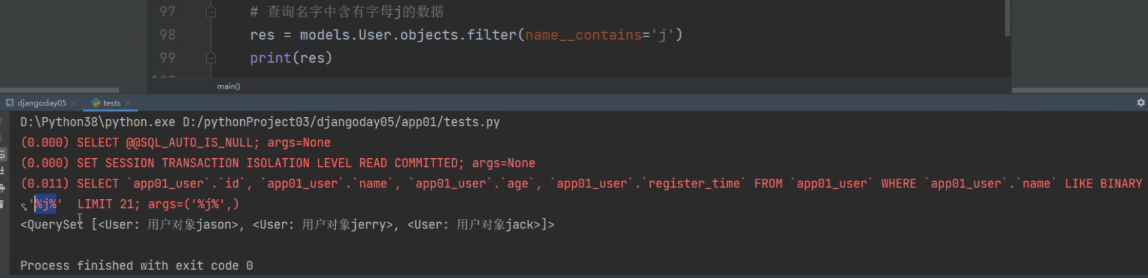
查询名字中含有字母j的数据
相当于原生SQL中的模糊查询(like
但这里是区分大小写的:
区分大小写
res = models.User.objects.filter(name__contains='j') #
print(res)
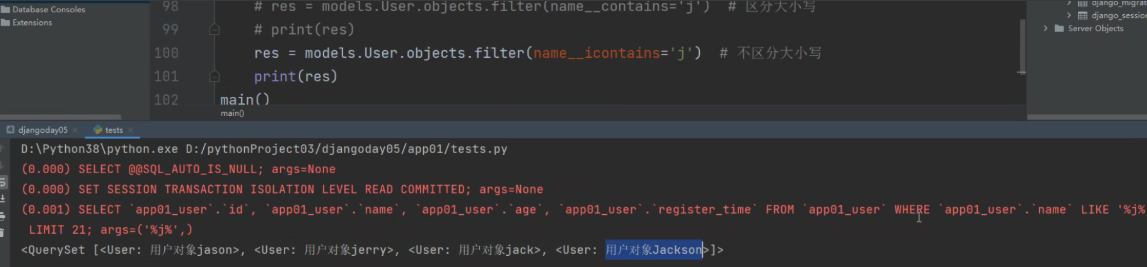
不区分大小写
res = models.User.objects.filter(name__icontains='j')
print(res)
查询注册年份是2022的数据
看我我们的数据表中:
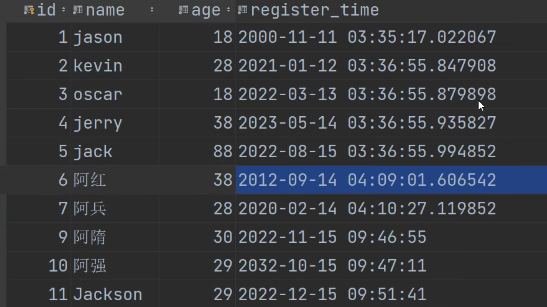
要从中查询出是2022年的数据(只按年份筛选)
res = models.User.objects.filter(register_time__year=2022)
print(res)
注意:register_time是User表的字段名
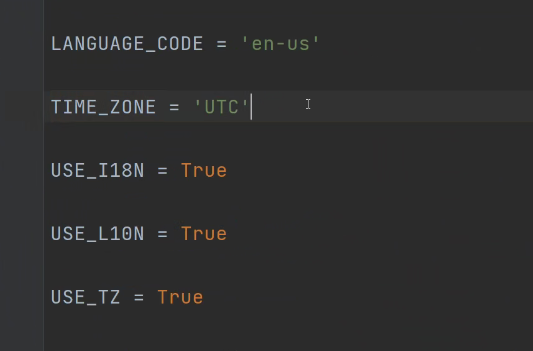
针对Django框架的时区问题 是需要配置文件中修改的 后续在bbs会给讲解

按照时间字段筛选数据的方式有很多
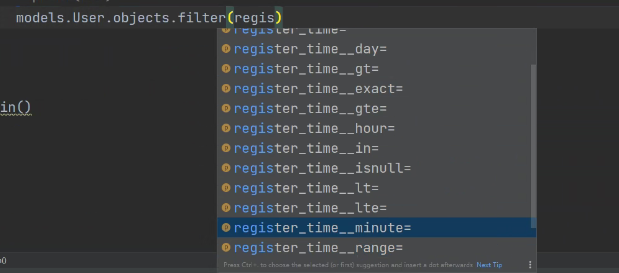
但都得要更改配置文件 后续会讲
要在setting配一下 TIME_ZONE
ORM外键字段的创建
'''
复习MySQL外键关系
一对多
外键字段建在多的一方
多对多
外键字段统一建在第三张关系表
一对一
建在任何一方都可以 但是建议建在查询频率较高的表中
ps:关系的判断可以采用换位思考原则 熟练的之后可以瞬间判断
```
1.创建基础表
(书籍表、出版社表、作者表、作者详情)
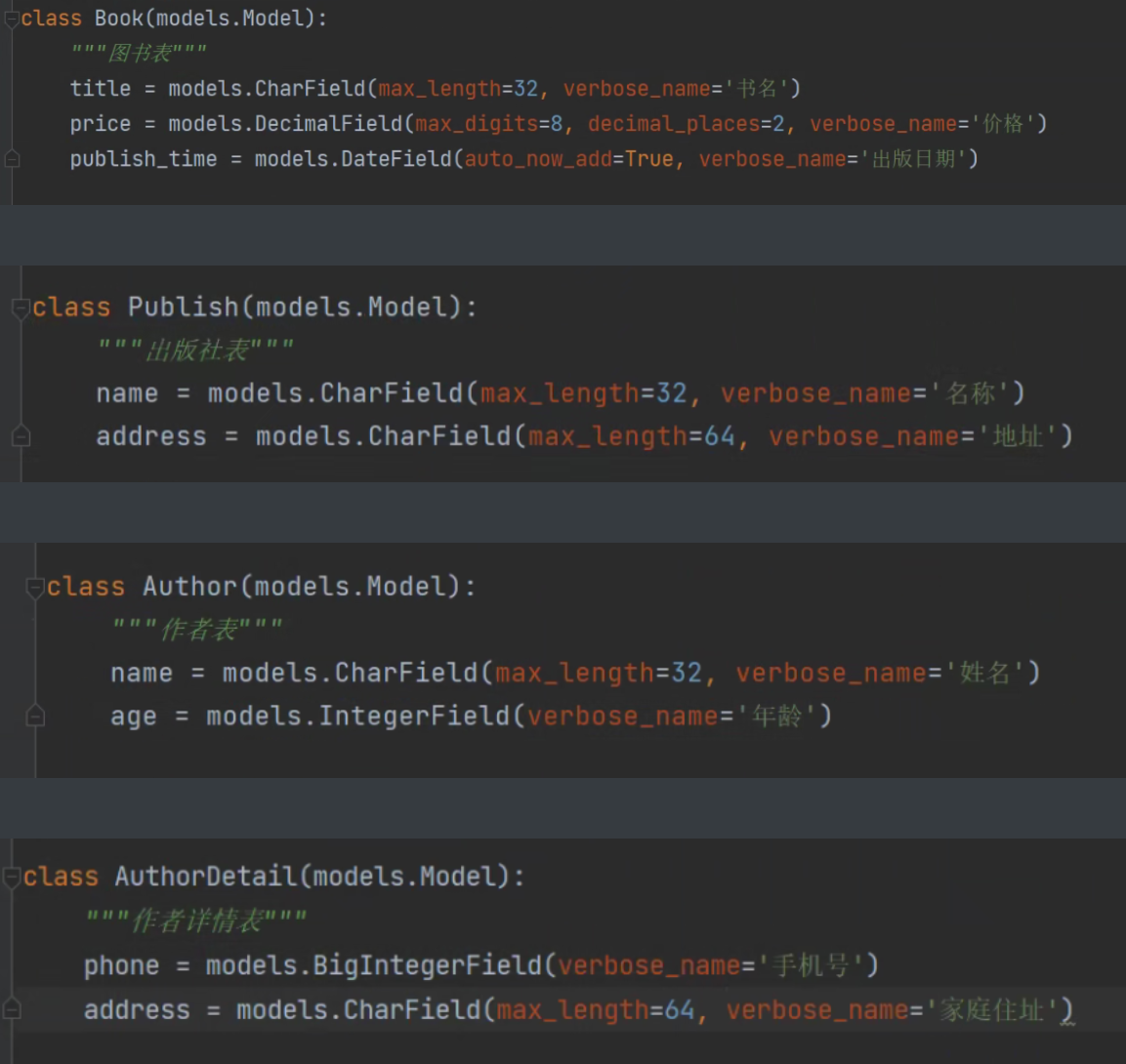
2.确定外键关系
书籍表与出版社表(一对多)
一对多
ORM与MySQL一致 外键字段建在多的一方
书籍与出版社是一对多关系。
一对多 ORM与MySQL一致。
外键字段建在多的一方,也就是建立在书籍表
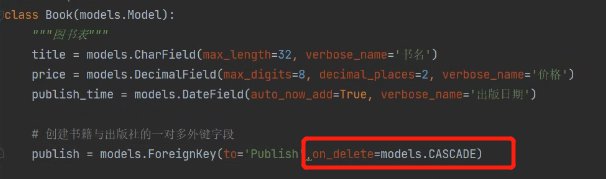
ForeignKey:创建一对多外键。
to:这里的to相当于原生SQL的reference。也就是在book表创建一个publish字段 关联publish表的主键。to后面也可以传一个出版社类,这样ORM也会知道你这个外键字段是要跟这个类绑定,只不过这个列就必须写在to所在类的上面
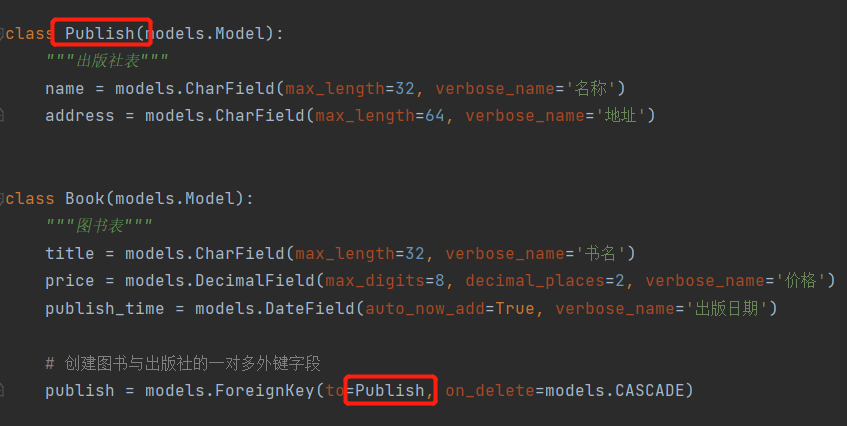
on_delete:这里的表示的是级联删除,级联更新。注意有如下版本区别:
django1.x版本:所有外键字段默认都是级联更新级联删除
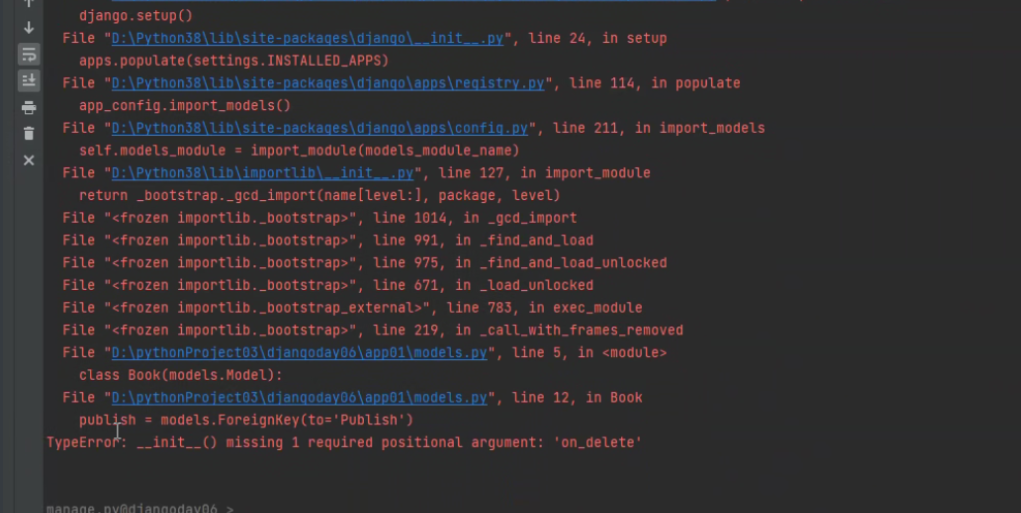
django2.x版本:需要自己声明。也就是添加on_delete=models.CASCADE
如果不申明会报错:
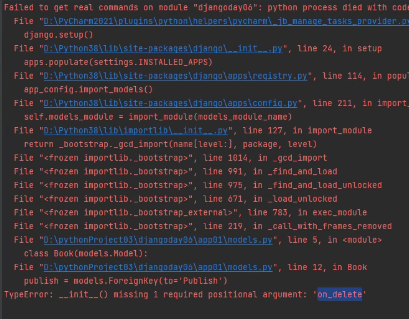
这里还需要注意:
针对外键一对多和一对一同步到表中之后会自动加_id的后缀
publish = models.ForeignKey(to='Publish',on_delete=models.CASCADE)
author_detail = models.OneToOneField(to='AuthorDetail', on_delete=models.CASCADE)
如我们创的外键字段是:
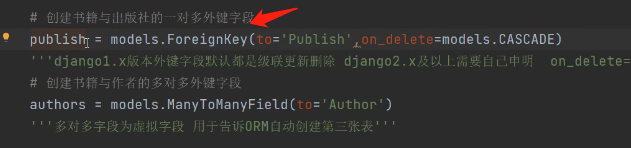
到表中显示的字段都会自己添加后缀_id

多对多
书籍表与作者表是多对多关系。
这里建议把外键建立在查询频率较高的书籍表。
在书籍表创建多对多外键字段,使用ManyToManyField方法
ORM比MySQL有更多变化
1.外键字段可以直接建在某张表中(查询频率较高的)内部会自动帮你创建第三张关系表
2.自己创建第三张关系表并创建外键字段 详情后面会讲
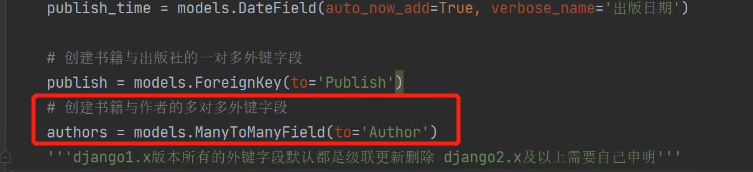
多对多字段为虚拟字段,会告诉Mysql自动创建第三张表,他不会在自己所处的表Book,创建一个新字段author。
除了这种使用虚拟字段创第三张表的方式,还可以自己手动在书籍库创第三张表。且自己手动创也具备一定优势
一对一
ORM与MySQL一致 外键字段建在查询较高的一方
由于作者表访问次数较多,所以我们在作者表创建一对一外键字段,使用OneToOneField
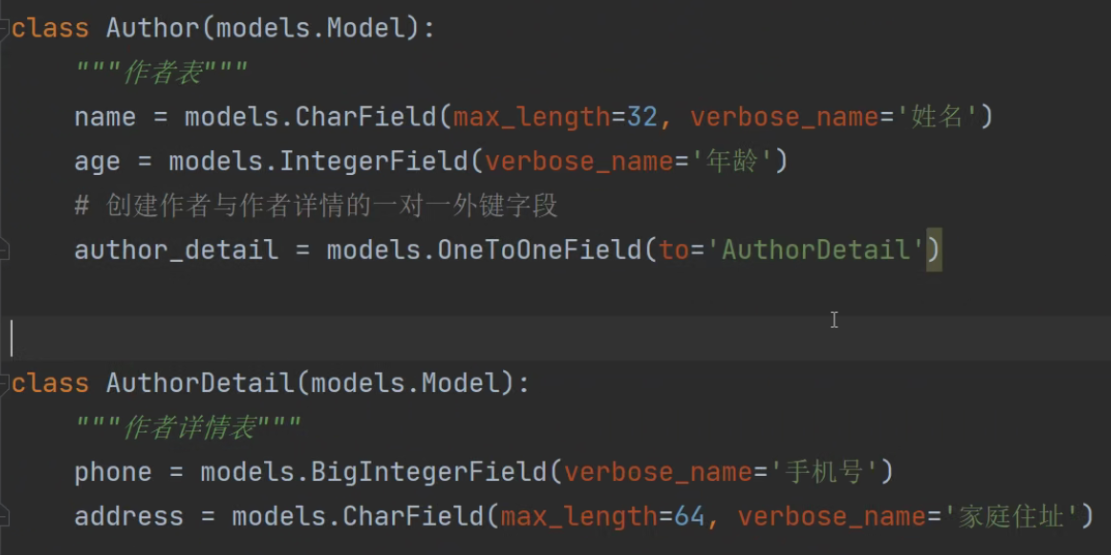
3.表的查看

所以针对一对多和一对一得申明
如果没就报错:
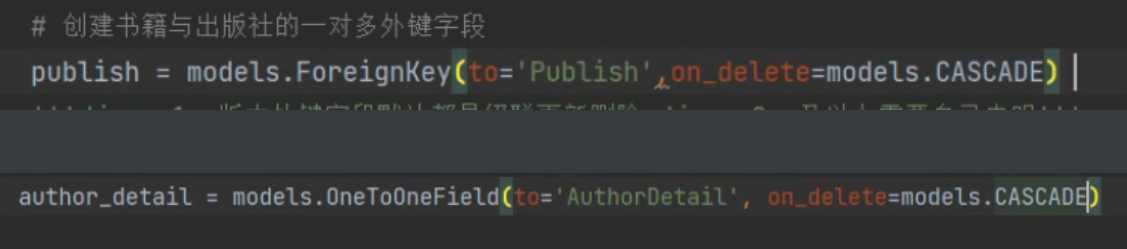
针对一对多和一对一同步到表中之后会自动加_id的后缀
publish = models.ForeignKey(to='Publish',on_delete=models.CASCADE)
author_detail = models.OneToOneField(to='AuthorDetail', on_delete=models.CASCADE)
针对多对多 不会在表中有展示 而是创建第三张表 用于告诉ORM自动创建第三张表
authors = models.ManyToManyField(to='Author')
自动创建了书跟作者的表
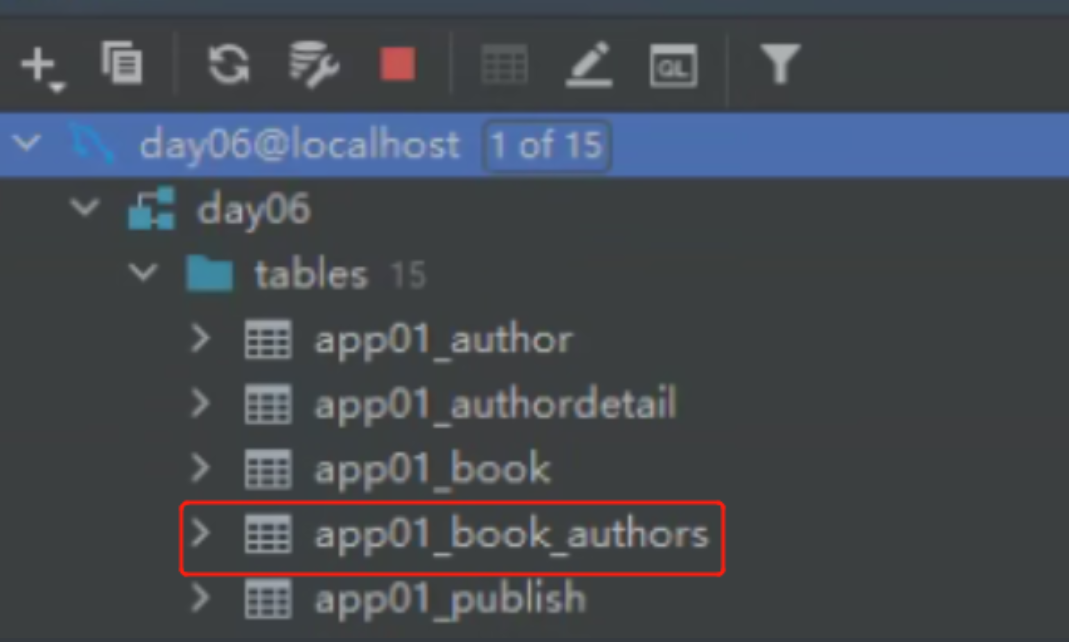
上面的蓝色表示外键字段。可见里面有两个是外键相关联字段
数据的录入
表的录入顺序:先从没有外键字段的表开始填 除了book表不录 其他表都可以录
作者详情表 --- > 作者表
出版社 ---> 图书表
要先给作者详情表添加数据,再给作者表添加数据。
先给出版社表添加数据,再给图书表添加数据
因为当有外键字段 基表相关联的表数据还未创建出来数据是无法录入的
外键字段相关操作
针对一对多
插入数据可以直接填写表中的实际字段
# models.Book.objects.create(title='三国演义', price=888.88, publish_id=1)
# models.Book.objects.create(title='人性的弱点', price=777.55, publish_id=1)
插入数据也可以填写表中的类中字段名
# publish_obj = models.Publish.objects.filter(pk=1).first()
# models.Book.objects.create(title='水浒传', price=555.66, publish=publish_obj)
'''一对一与一对多 也一致'''
既可以传数字也可以传对象
针对多对多关系绑定
多对多关系表models是点不出来的 ORM自动创的
需要获取出含有多对多字段的数据就可以了
# book_obj = models.Book.objects.filter(pk=1).first()
# book_obj.authors.add(1) # 在第三张关系表中给当前书籍绑定作者
# book_obj.authors.add(2, 3)
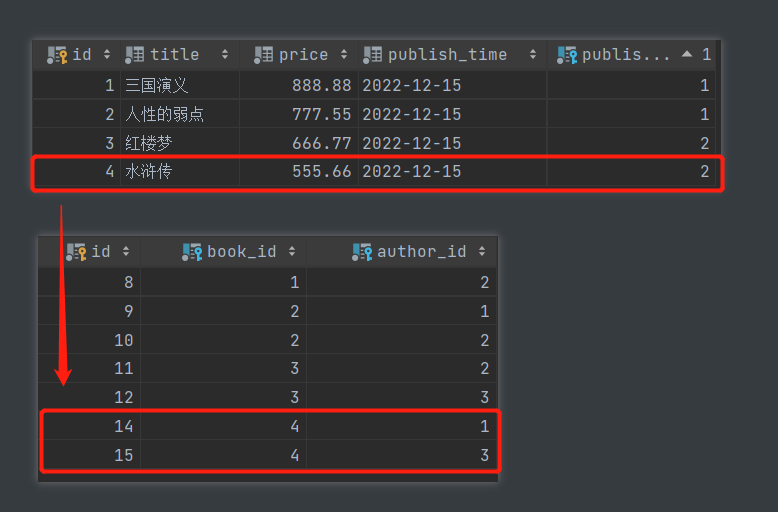
# book_obj = models.Book.objects.filter(pk=4).first()
# author_obj1 = models.Author.objects.filter(pk=1).first()
# author_obj2 = models.Author.objects.filter(pk=2).first()
# book_obj.authors.add(author_obj1)
# book_obj.authors.add(author_obj1, author_obj2)
修改关系
book_obj = models.Book.objects.filter(pk=1).first()
# book_obj.authors.set((1, 3)) # 修改关系
得传元组或列表 能够支持for循环
# book_obj.authors.set([2, ]) # 修改关系
# author_obj1 = models.Author.objects.filter(pk=1).first()
# author_obj2 = models.Author.objects.filter(pk=2).first()
# book_obj.authors.set((author_obj1,))
# book_obj.authors.set((author_obj1, author_obj2))
删除:
# book_obj.authors.remove(2)
# book_obj.authors.remove(1, 3)
# book_obj.authors.remove(author_obj1,)
# book_obj.authors.remove(author_obj1,author_obj2)
清除
book_obj.authors.clear()
add()\remove() 多个位置参数(数字 对象)
set() 可迭代对象(元组 列表) 数字 对象
clear() 情况当前数据对象的关系
ORM跨表查询
"""
复习MySQL跨表查询的思路
子查询
分步操作:将一条SQL语句用括号括起来当做另外一条SQL语句的条件
连表操作
先整合多张表之后基于单表查询即可
inner join 内连接
left join 左连接
right join 右连接
"""
正反向查询的概念(重要)
正向查询
由外键字段所在的表数据查询关联的表数据 正向
ps:正反向的核心就看外键字段在不在当前数据所在的表中
反向查询
没有外键字段的表数据查询关联的表数据 反向
ORM跨表查询的口诀(重要)
正向查询按外键字段
反向查询按表名小写
基于对象的跨表查询
正向查询
1.查询主键为1的书籍对应的出版社名称
# 先根据条件获取数据对象
# book_obj = models.Book.objects.filter(pk=1).first()
# 再判断正反向的概念 由书查出版社 外键字段在书所在的表中 所以是正向查询
# print(book_obj.publish.name)
2.查询主键为4的书籍对应的作者姓名
# 先根据条件获取数据对象
# book_obj = models.Book.objects.filter(pk=4).first()
# 再判断正反向的概念 由书查作者 外键字段在书所在的表中 所以是正向查询
# print(book_obj.authors) # app01.Author.None
# print(book_obj.authors.all())
# print(book_obj.authors.all().values('name'))
3.查询jason的电话号码
author_obj = models.Author.objects.filter(name='jason').first()
print(author_obj.author_detail.phone)
反向查询
4.查询北方出版社出版过的书籍
publish_obj = models.Publish.objects.filter(name='北方出版社').first()
print(publish_obj.book_set) # app01.Book.None
print(publish_obj.book_set.all())
5.查询jason写过的书籍
author_obj = models.Author.objects.filter(name='jason').first()
print(author_obj.book_set) # app01.Book.None
print(author_obj.book_set.all())
6.查询电话号码是110的作者姓名
author_detail_obj = models.AuthorDetail.objects.filter(phone=110).first()
print(author_detail_obj.author)
print(author_detail_obj.author.name)
基于双下划线的跨表查询
正向的查询
# 1.查询主键为1的书籍对应的出版社名称
# res = models.Book.objects.filter(pk=1).values('publish__name','title')
# print(res)
# 2.查询主键为4的书籍对应的作者姓名
# res = models.Book.objects.filter(pk=4).values('title', 'authors__name')
# print(res)
# 3.查询jason的电话号码
# res = models.Author.objects.filter(name='jason').values('author_detail__phone')
# print(res)
反向的查询
查询北方出版社出版过的书籍名称和价格
从出版社出发 前往 书籍表。
由于外键字段在书籍表。所以是反向查询。
口诀:反向查询按表名小写__set。注意这个表名是book,也就是我们的目的地。
由于一个出版社可以发行多本书,所以查询的结果应该是多个。所以这里才要加set。set表示集合,有包含多个的意思
# res = models.Publish.objects.filter(name='北方出版社').values('book__title','book__price','name')
# print(res)
# 5.查询jason写过的书籍名称
# res = models.Author.objects.filter(name='jason').values('book__title', 'name')
# print(res)
# 6.查询电话号码是110的作者姓名
res = models.AuthorDetail.objects.filter(phone=110).values('phone', 'author__name')
print(res)
进阶操作
正向查询
# 1.查询主键为1的书籍对应的出版社名称
# res = models.Publish.objects.filter(book__pk=1).values('name')
# print(res)
# 2.查询主键为4的书籍对应的作者姓名
# res = models.Author.objects.filter(book__pk=4).values('name','book__title')
# print(res)
# 3.查询jason的电话号码
# res = models.AuthorDetail.objects.filter(author__name='jason').values('phone')
# print(res)
反向查询
# 4.查询北方出版社出版过的书籍名称和价格
# res = models.Book.objects.filter(publish__name='北方出版社').values('title','price')
# print(res)
# 5.查询jason写过的书籍名称
# res = models.Book.objects.filter(authors__name='jason').values('title')
# print(res)
# 6.查询电话号码是110的作者姓名
res = models.Author.objects.filter(author_detail__phone=110).values('name')
print(res)
总结:
跨表查询的方式有三种:
方式一 先拿数据对象 用查询条件拿具体数据值 当数据值没有会报错
双下(具体点外键字段还是表名小写看正反向)
方式二 依据条件从查询条件开始着手 那么models后面点条件相对应的表 那么在Values中通过双下划线跳转拿
方式三 依据条件查询从条件屁股后面着手 那么modles后面点对应条件的表 那么filter括号里就通过双下划线跳转到条件已知开始的表中
补充
# 查询主键为4的书籍对应的作者的电话号码
# res = models.Book.objects.filter(pk=4).values('authors__author_detail__phone')
# print(res)
# res = models.AuthorDetail.objects.filter(author__book__pk=4).values('phone')
# print(res)
res = models.Author.objects.filter(book__pk=4).values('author_detail__phone')
print(res)
"""

 浙公网安备 33010602011771号
浙公网安备 33010602011771号