

MMR 算法优化
一 简介
MMR(Maximal Marginal Relevance,最大边际相关性) 算法多用于推荐场景,目标是减少排序结果的冗余。MMR 算法在物品的相关性和相似性之间做了权衡,在保证相关性的基础上,减少相似性,保证了推荐结果的多样性。
MMR 算法公式如下:

二 问题
该算法采用的贪心策略,复杂度是 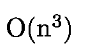 ,耗时过高,导致无法在线上实时运行。
,耗时过高,导致无法在线上实时运行。
我在新闻推荐粗排服务中应用了该算法。在我的应用场景中,又加入了用户浏览历史用一些高爆光未点击新闻的过滤,耗时更高。如果不做性能优化,项目无法发布上线。
三 优化手段
通过对算法的分析,采用了如下优化手段:
1. 降低复杂度
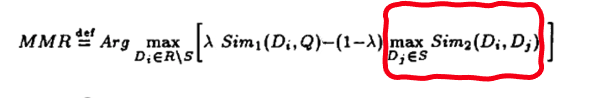
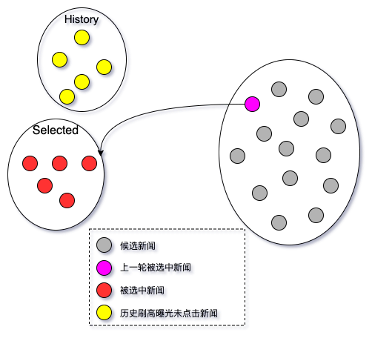
新闻相似度计算部分,可以梳理为三个计算部分:
- 候选新闻和用户历史相似度计算
- 候选新闻和已胜出新闻相似度计算
- 候选新闻和上一轮胜出新闻相似度计算
前两个计算部分可以缓存起来,在代码中只需要计算候选新闻和上一轮胜出新闻的相似度,然后和缓存的数值进行比对,这样时间复杂度降为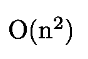
2. 分桶
每条新闻都有自己的分类,例如体育、科技、娱乐等,不同的分类的新闻没有相似度计算的必要。这样根据分类对候选新闻进行分桶,不同的分类之间并行计算,同样可以降低算法的复杂度,降低耗时。
3. 缓存
我的应用场景中,新闻的相似度计算逻辑是这样的:
- 离线模型计算新闻的 embedding,存储在 redis 中
- 召回新闻,从 redis 中读取相应的 embedding
- 新闻相似度就是两个 embedding 的内积得分
考虑到离线计算的 embedding 变更的概率非常小,具体实现时,在服务内部对相似度进行了缓存,避免每次内积计算。
通过以上的优化手段,最终实现了逻辑发布上线。
参考:https://zhuanlan.zhihu.com/p/102285855

 浙公网安备 33010602011771号
浙公网安备 33010602011771号