
SystemVerilog(7):覆盖率
1、覆盖率类型
1.1 概述
- 覆盖率是衡量设计验证完备性的一个通用词语。
- 随着测试逐步覆盖各种合理的组合,仿真过程会慢慢勾画出你的设计情况。
- 覆盖率工具会在仿真过程中收集信息,然后进行后续处理并且得到覆盖率报告。
- 通过这个报告找出覆盖之外的盲区,然后修改现有测试或者创建新的测试来填补这些盲区。
- 这个过程可以一直迭代进行,直到你对覆盖率满意为止。
1.2 覆盖率反馈电路
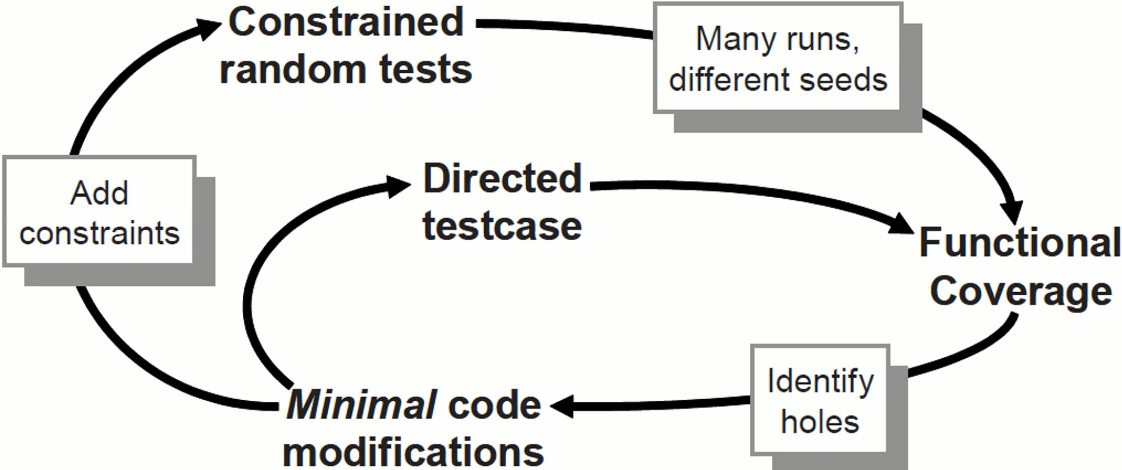
- 可以使用一个反馈回路来分析覆盖率的结果,并决定采取哪种行动来达到100%的覆盖率。
- 首要的选择是使用更多的种子来运行现有的测试程序。
- 当大量种子依然对于覆盖率增长没有帮助时,需要建立新的约束。
- 只有在确实需要的时候才会求助于创建定向测试。
1.3 代码覆盖率
- 不添加任何额外的HDL代码,工具会通过分析源代码和增加隐藏代码来自动完成代码覆盖率的统计。
- 当运行完所有测试,代码覆盖率工具便会创建相应的数据库。
- 仿真器都带有代码覆盖率的工具,覆盖率数据也可被转换为可读格式。
- 行覆盖率:多少行代码已经被执行过。
- 路径覆盖率:在穿过代码和表达式的路径中有哪些已经被执行过。
- 翻转覆盖率:哪些单位比特变量的值为0或1。
- 状态机覆盖率:状态机哪些状态和状态转换已经被访问过。
- 代码覆盖率最终的结果用于衡量你执行了设计中的多少代码。
- 关注点应该放在设计代码的分析上,而不是测试平台。
- 未经测试的设计代码里可能隐藏硬件漏洞,也可能仅仅就是冗余的代码。
- 代码覆盖率衡量的是测试对于硬件设计描述的"实现"究竟测试得有多彻底,而非针对验证计划。
- 代码覆盖率达到了100%,并不意味着验证的工作已经完成,但代码覆盖率100%是验证工作完备性的必要条件。
1.4 断言覆盖率
- 断言是用于一次性地或在一段时间对一个或者多个设计信号在逻辑或者时序上的声明性代码。
- 断言可以跟随设计和测试平台一起仿真,也可以被形式验证工具所证实。
- 你可以使用SV的程序性代码编写等效性检查,但使用SVA (SV断言)来表达会更容易。
- 断言最常用于查找错误,例如两个信号是否应该互斥,或者请求与许可信号之间的时序等。
- 一旦检测到问题,仿真就可以立即停止。
- 有些断言可以用于查找感兴趣的信号值或者设计状态。
- 可以使用 cover property 来测量这些关心的信号值或者状态是否发生。
- 在仿真结束时,仿真工具可以自动生成断言覆盖率数据。
- 断言覆盖率数据以及其它覆盖率数据都会被集成在同一个覆盖率数据库中,verifier可以对其展开分析。
1.5 漏洞率曲线
- 在一个项目实施期间,你应该保持追踪每周有多少个漏洞被发现。
- 一开始,当你创建测试程序时,通过观察可能就会发现很多漏洞。
- 当设计逐渐稳定时,你需要利用自动化的检查方式来协助发现可能的漏洞。
- 在设计临近流片时,漏洞率会下降,甚至有望为零。即便如此,验证工作仍然不能结束。
- 每次漏洞率下降时,就应该寻找各种不同的办法去测试可能的边界情况(corner case) 。
- 漏洞率可能每周都有变化,这跟很多因素都有关。不过漏洞率如果出现意外的变化,可能预示着潜在的问题。
1.6 功能覆盖率
- 验证的目的就是确保设计在实际环境中的行为正确。
- 功能描述文档详细说明了设计应该如何运行,而验证计划则列出了相应的功能应该如何激励、验证和测量。
- 当你收集测量数据希望找出那些功能已经被覆盖时,你其实就是在计算"设计"的覆盖率。
- 功能覆盖率是和功能设计意图紧密相连的,有时也被称为"描述覆盖率”,而代码覆盖率则是衡量设计的实现情况。
- 某个功能在设计中可以被遗漏,代码覆盖率不能发现这个错误,但是功能覆盖率可以。
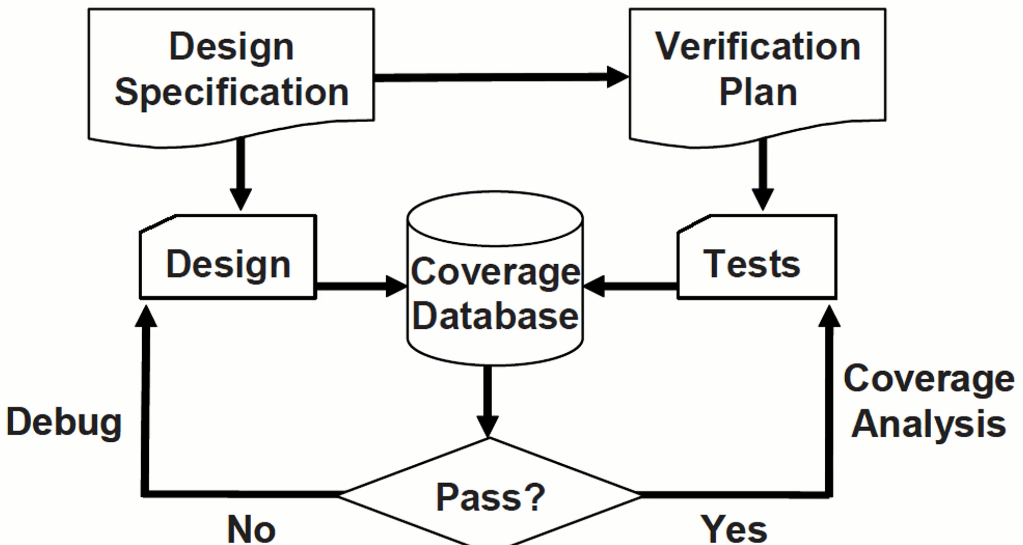
- 每一次仿真都会产生一个带有覆盖率信息的数据库,记录随机游走的轨迹。
- 把这些信息全部合并在一起就可以得到功能覆盖率,从而衡量整体的进展程度。
- 通过分析覆盖率数据可以决定如何修改回归测试集。
- 如果覆盖率在稳步增长,那么添加新种子或者加长测试实际即可。
- 如果覆盖率增速放缓,那么需要添加额外的约束来产生更多"有意思"的激励。
- 如果覆盖率停止增长,然而设计某些测试点没有被覆盖到,那么就需要创建新的测试了。
- 如果覆盖率为100%但依然有新的设计漏洞,那么覆盖率可能没有覆盖到设计中的某些设计功能区域。
2、功能覆盖策略
2.1 收集信息而非数据
- 对于一些设计,你需要关心的是合法的寄存器地址和非法的寄存器地址,可写的寄存器域和非法的寄存器域,而不是具体的寄存器地址数值。
- 一旦关注的地方着眼于感兴趣的状态,而不是具体数值,那么这对于你如何定义功能覆盖率,以及如何收集信息会减轻很大的负担。
- 设计信号如果数量范围太大,应该拆分为多个小范围再加上边界情况。
2.2 只测量需要的内容
- Verifier需要懂得,在使能覆盖率收集时,这一特性会降低很大的仿真性能。
- 由于收集功能覆盖率数据的开销很大,所以应该只测量你会用来分析并且改进测试的那部分数据。
- 同时也需要设定合理的覆盖率采样的事件,一方面提升采样效率,一方面也可以降低收集覆盖率的开销。
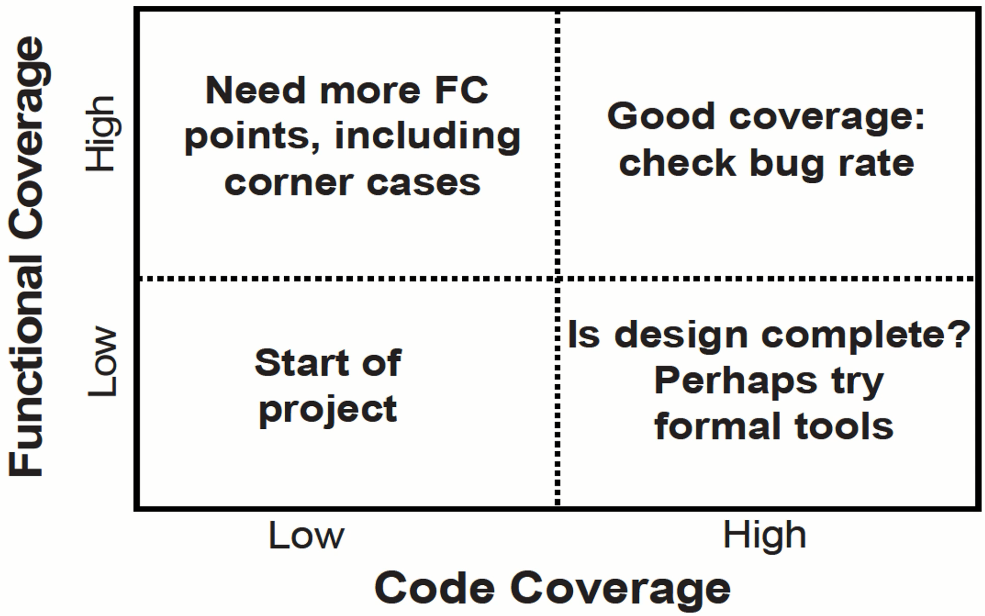
2.3 验证的完备性
- 完备的覆盖率测量结果和漏洞增长曲线,可以帮助确认设计是否被完整地验证过。
- 如果代码覆盖率低但功能覆盖率高,这说明验证计划不完整,测试没有执行设计的所有代码。
- 如果代码覆盖率高但功能覆盖率低,这说明即使测试平台很好地执行了设计的所有代码,但是测试还是没有把设计定位到所有感兴趣的状态上。
- 你的目标是同时驱动高的代码覆盖率和功能覆盖率。
3、覆盖组
3.1 概述
- 覆盖组(covergroup)与类相似,一次定义后便可以多次实例化。
- covergroup可以包含一个或者多个coverpoint,且全都在同一时间采集。
- covergroup可以定义在类中,也可以定义在interface或者module中。
- covergroup可以采样任何可见的变量,例如程序变量、接口信号或者设计端口。
- 一个类里可以包含多个covergroup。
- 当你拥有多个独立的covergroup时,每个covergroup可以根据需要自行使能或者禁止。
- 每个covergroup可以定义单独的触发采样事件,允许从多个源头收集数据。
- covergroup必须被例化才可以用来收集数据。
3.2 covergroup的采样触发
class Transactor;
Transaction tr;
mailbox mbx_in;
covergroup CovPort; //覆盖组
coverpoint tr.port; //采样变量
endgroup
function new(mailbox mbx_in);
covPort = new(); //也可以写成:covPort cg1=new();
this.mbx_in = mbx_in;
endfunction
task main;
forever begin
tr =mbx_in.get;
ifc.cb.port <= tr.port;
ifc.cb.data <= tr.data;
CovPort.sample(); //采样
end
endtask
endclass- covergroup由采样的数据和数据被采样的事件构成。
- 当这两个条件都准备好以后,测试平台便会触发covergroup。
- 这个过程可以通过直接使用 sample( ) 函数完成,也可以在covergroup中采样阻塞表达式或者使用wait或@实现在信号或事件上的阻塞。
- 如果你希望在代码中显式地触发covergroup采样,或者不存在采样时刻的信号或事件,又或者一个covergroup被例化为多个实例需要单独触发,那么可以使用 sample( ) 方法。
- 如果你想借助已有的事件或者信号触发covergroup,可以在covergroup声明中使用阻塞语句。
3.3 使用事件触发
event trans_ready;
covergroup CovPort @(trans_ready);
coverpoint ifc.cb.port;
endgroup与直接调用 sample( ) 相比,使用事件触发的好处在于你能够借助已有的事件。
4、数据采样
4.1 概述
- 当你在coverpoint指定采样一个变量或表达式时,SV会创建很多的"仓(bin)"来记录每个数值被捕捉到的次数。
- 这些bin是衡量功能覆盖率的基本单位。
- covergroup中可以定义多个coverpoint, coverpoint中可以自定义多个cover bin或者SV帮助自动定义多个cover bin。
- 每次covergroup采样,SV都会在一个或者多个cover bin中留下标记,用来记录采样时变量的数值和匹配的cover bin。
- 在仿真之后,可以使用分析工具读取这些数据库来生成覆盖率报告,包含了各部分和总体的覆盖率。
4.2 coverpoint和bin
- 为了计算一个coverpoint上的覆盖率,首先需要确定可能数值的个数,这也被称为域。
- 覆盖率就是采样值的数目除以bin的数目。例如一个3比特变量的域是0:7,正常情况下会自动分配8个bin。如果仿真过程中有7个值被采样到,那么最终该coverpoint的覆盖率是7/8。
- 所有的coverpoint的覆盖率最终构成一个covergroup的覆盖率。
- 所有的covergroup的覆盖率构成了整体的功能覆盖率。
4.3 bin的创建和应用
- SV会默认为某个coverpoint创建bin,用户也可以自己定义bin的采样域。
- 如果采样变量的域范围过大而又没有指定bin,那么系统会默认分配64个bin,将值域范围平均分配给这64个bin。
- 用户可以通过covergroup的选项auto_bin_max来指定自动创建bin的最大数目。
- 实际操作中,自动创建bin的方法不实用,建议用户自行定义bin,或者减小auto_bin_max的数值。
covergroup covPort;
options.auto_bin_max = 8; //所有coverpoint auto_bin数量=8
coverpoint tr.port
{ options.auto_bin_max = 2; }//特定coverpoint auto_bin数量=2
endgroup4.4 命名coverpoint和bin
covergroup CovKind;
coverpoint tr.kind {
bins zero = { 0 }; //1个仓代表kind==0
bins lo = { [1:3],5 };//1个仓代表1:3和5
bins hi[] = { [8:$]}; //8个独立的仓代表8:15
bins misc = default; //1个仓代表剩余的所有值
}//没有分号
endgroup注意coverpoint定义使用{}而不是begin. . .end。大括号的结尾没有带分号,这和end一样。
4.5 条件覆盖率
- 可以使用关键词 iff 给coverpoint添加条件。
- 这种做法常用于在复位期间关闭覆盖以忽略不合理的条件触发。
- 也可以使用 start 和 stop 函数来控制covergroup各个独立实例。
covergroup coverPort;
coverpoint port iff //采样时必须保证已经复位了
(!bus_if.reset);//复位
endgroup
initial begin
CovPort ck=new();
#1ns;
ck.stop();
bus_if.reset = 1;
#100ns
bus_if.reset = 0;
ck .start();
...
end4.6 翻转覆盖率
- coverpoint也可以用来记录变量从A值到B值的跳转情况。
- 还可以确定任何长度的翻转次数。
covergroup coverPort;
coverpoint port { //0跳到1,0跳到2,0跳到3
bins t1 = (0 => 1), (0 => 2), (0 => 3);
endgroup4.7 wildcard覆盖率
- 可以使用关键字 wildcard 来创建多个状态或者翻转。
- 在表达式中,任何x,z或者?都会被当成0或1的通配符。
bit [2:0] port;
covergroup CoverPort;
coverpoint port {
wildcard bins even = { 3'b??0 };
wildcard bins odd = { 3'b??1 };
}
endgroup4.8 忽略的bin
- 在某些coverpoint可能始终无法得到全部的域值。
- 对于那些不计算功能的域值可以使用 ignore_bins 来排除,最终它们并不会计入coverpoint的覆盖率。
bit [2:0]1ow _ports_0_5; //只使用数值0-5
covergroup coverPort;
coverpoint low _ports_o_5 {
ignore_bins hi = { [6,7] }; //忽略数值6-7
}
endgroup4.9 非法的bin
- 有些采样值不仅应该被忽略,而且如果出现还应该报错。
- 这种情况可以在测试平台中监测,也可以使用 illegal_bins 对特定的bin进行标示。
bit [2:0] low_ports_0_5; //只是用数值0-5
covergroup coverPort;
coverpoint low_ports_0_5 {
illegal_bins hi = { [6,7] }; //如果出现6-7便报错
}
endgroup4.10 交叉覆盖率
- coverpoint是记录单个变量或者表达式的观测值。
- 如果像记录在某一时刻,多个变量之间值的组合情况,需要使用交叉(cross)覆盖率。
- cross 语句只允许带coverpoint或者简单的变量名。
class Transaction ;
rand bit [3:0] kind;
rand bit [2:0] port;
endclass
Transaction tr;
covergroup CovPort;
kind: coverpoint tr.kind;
port: coverpoint tr.port;
cross kind, port;
endgroup4.11 排除部分cross bin
- 通过使用 ignore bins、binsof 和 intersect 分别指定coverpoint口值域,这样可以清除很多不关心的cross bin。
covergroup covport;
port: coverpoint tr.port{
bins port[] = { [O:$] };
}
kind: coverpoint tr.kind{
bins zero = { 0 };
bins lo = { [1:3] };
bins hi[] = { [8:$] };
bins misc = default;
}
cross kind, port{
ignore_bins hi = binsof(port)intersect { 7 };
ignore_bins md = binsof(port)intersect { 0 } &&
binsof(kind) intersect { [ 9:11] };
ignore_bins lo = binsof(kind.lo);
}
endgroup4.12 精细的交叉覆盖率指定
- 随着cross覆盖率越来越精细,可能需要花费不少的时间来指定哪些bin应该被使用或者被忽略。
- 更适合的方式是不使用自动分配的cross bin,而自己声明感兴趣的cross bin。
- 假如有两个随机变量a和b,它们带着三种感兴趣的状态,{ a==0, b==0}、{ a==1、b==0}和{b==1}。
class Transaction;
rand bit a, b;
endclass
covergroup CrossBinNames;
a : coverpoint tr.a
{bins a0 = { 0 };
bins a1 = { 1 };
option.weight=0;} //不计算覆盖率
b: coverpoint tr.b
{bins b0 = { 0 };
bins b1 = { 1 };
option.weight=0;} //不计算覆盖率
ab: cross a, b
{bins a0b0 = binsof( a.a0) && binsof ( b.b0 );
bins a1b0 = binsof( a.a1) && binsof ( b.b0 );
bins b1 = binsof( b.b1 );}
endgroupclass Transaction;
rand bit a, b;
endclass
covergroup CrossBinsofintersect;
a : coverpoint tr.a
{ option.weight=0 ; }//Do not count this coverpoint
b: coverpoint tr.b
{ option.weight=0; } //Do not count this coverpoint
ab : cross a, b
{ bins a0b0 = binsof(a) intersect{0} && binsof(b) intersect{0};
bins alb0 = binsof(a) intersect{1} && binsof(b) intersect{0};
bins b1 = binsof(b) intersect{1};
}
endgroup5、覆盖选项
5.1 单个实例的覆盖率
如果对一个covergroup例化多次,那么默认情况下SV会将所有实例的覆盖率合并到一起。如果需要单独列出每个covergroup实例的覆盖率,需要设置覆盖选项。
covergroup coverLength;
coverpoint tr.length;
option.per_instance = 1;
endgroup5.2 注释
如果有多个covergroup实例,可以通过参数来对每一个实例传入单独的注释。这些注释最终会显示在覆盖率数据的总结报告中。
covergroup CoverPort(int lo ,hi, string comment);
option.comment = comment;
option.per_instance = 1;
coverpoint port{
bins range = { [lo: hi] };
}
endgroup
...
coverport cp_lo = new ( 0 ,3, "Low port numbers " );
coverport cp_hi = new ( 4 ,7,"High port numbers " );5.3 覆盖次数
- 默认情况下,数值采样了1次就可以计入有效的 bin。可以通过修改 at_least 来修改每个 bin 的数值最少的采样次数,如果低于 at_least 数值,则不会被计入 bin 中。
- option.at_least 可以在 covergroup 中声明来影响所有的 coverpoint,也可以在 coverpoint 中声明来只影响该 coverpoint 下所有的 bin。
5.4 覆盖率目标
- 一个 covergroup 或者一个 coverpoint 的目标是100%覆盖率。
- 不过你也可以将其设置为低于100%的目标。这个选项只会影响覆盖率报告。
covergroup coverPort;
coverpoint port;
option.goal = 90;
endgroup5.5 covergroup方法
- sample (): 采样。
- get_coverage ( ) / get_inst_coverage ( ):获取覆盖率,返回 0-100 的 real 数值。
- set_inst_name ( string):设置covergroup的名称。
- start ( ) / stop ( ):使能或者关闭覆盖率的收集。
6、数据分析
- 使用 $get_coverage( ) 可以得到总体的覆盖率。
- 也可以使用 covergroup_inst.get_inst__coverage( ) 来获取单个 covergroup 实例的覆盖率。
- 这些函数最实际的用处是在一个测试当中监测覆盖率的变化。
- 如果覆盖率水平在一段时间之后没有提高,那么这个测试就应该停止。
- 重启新的随机种子或者测试可能有望提高覆盖率。
- 如果测试可以基于功能覆盖率采取一些深入的行动,例如重新限定随机的约束,那将是一件非常好的事情,但是这种测试很难编写。
参考资料:
[1] 路科验证V2教程
[2] 绿皮书:《SystemVerilog验证 测试平台编写指南》第2版

 浙公网安备 33010602011771号
浙公网安备 33010602011771号