
FPGA实现图像的二值形态学滤波:腐蚀和膨胀
形态学,即数学形态学(Mathematical Morphology),是图像处理中应用最为广泛的技术之一,主要用于从图像中提取对表达和描绘区域形状有意义的图像分量,使后续的识别工作能够抓住目标对象最为本质(最具区分能力 - most discriminative)的形状特征,如边界和连通区域等。同时像细化、像素化和修剪毛刺等技术也常应用于图像的预处理和后处理中,成为图像增强技术的有力补充。
一、理论分析
1、腐蚀
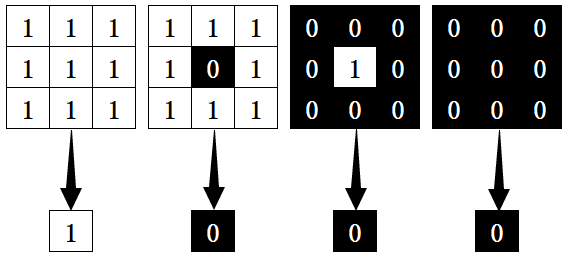
2、膨胀
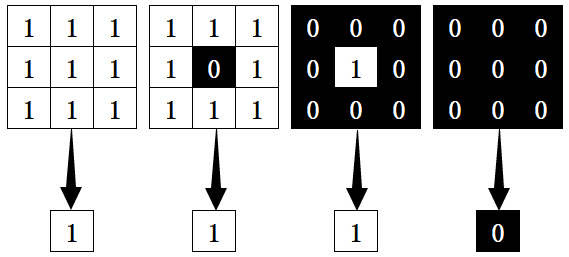
二、MATLAB实现
clc; clear all; close all; RGB = imread('test.png'); %读图 [ROW,COL, DIM] = size(RGB); %得到图像行列数 %------------------------------< Erode >----------------------------------- Erode_img = zeros(ROW,COL); for r = 2:ROW-1 for c = 2:COL-1 and1 = bitand(RGB(r-1, c-1), bitand(RGB(r-1, c), RGB(r-1, c+1))); and2 = bitand(RGB( r, c-1), bitand(RGB( r, c), RGB( r, c+1))); and3 = bitand(RGB(r+1, c-1), bitand(RGB(r+1, c), RGB(r+1, c+1))); Erode_img(r, c) = bitand(and1, bitand(and2, and3)); end end %------------------------------< Dilate >---------------------------------- Dilate_img = zeros(ROW,COL); for r = 2:ROW-1 for c = 2:COL-1 or1 = bitor(RGB(r-1, c-1), bitor(RGB(r-1, c), RGB(r-1, c+1))); or2 = bitor(RGB( r, c-1), bitor(RGB( r, c), RGB( r, c+1))); or3 = bitor(RGB(r+1, c-1), bitor(RGB(r+1, c), RGB(r+1, c+1))); Dilate_img(r, c) = bitor(or1, bitor(or2, or3)); end end %------------------------------< show >------------------------------------ figure; imshow(RGB); title('原图'); subplot(2,1,1); imshow(Erode_img); title('腐蚀'); subplot(2,1,2); imshow(Dilate_img);title('膨胀');
这次图片选择的就是一张二值图片,原图如下所示:

点击运行,得到如下结果:
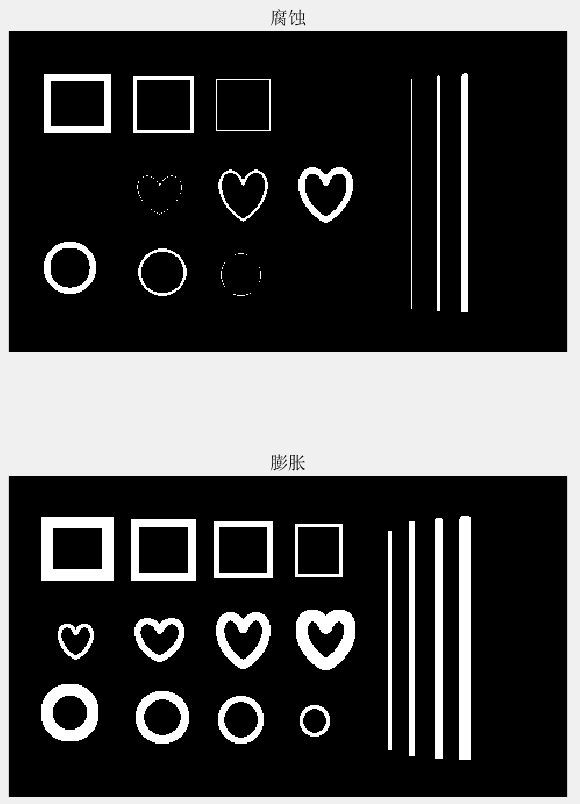
可以看到,腐蚀后,最细的白色线条消失了,其他图案也都变得更细了,而膨胀后所有白色线条都变粗了。
三、FPGA实现
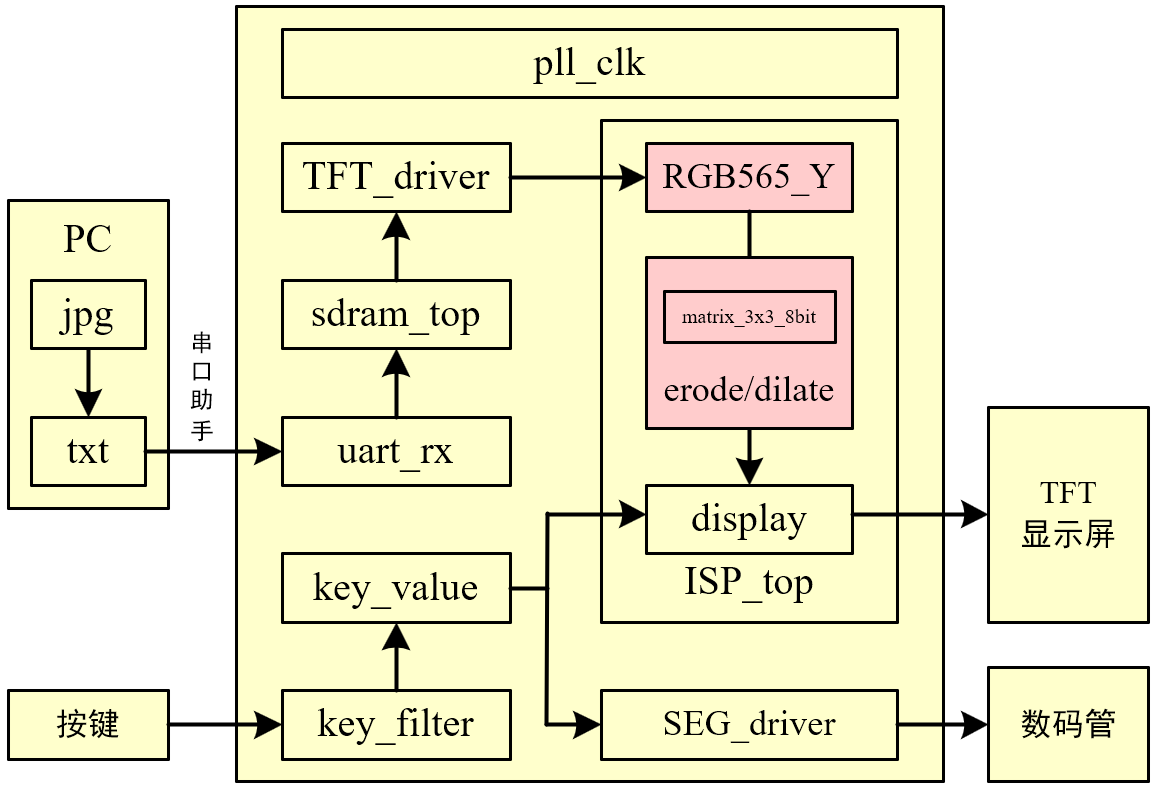
1、腐蚀
(1)形成3x3矩阵
这个在前面的博客花了3篇来解释,就不多说了,我把3x3矩阵的代码用一个专门的 .v 文件写好,这里直接调用即可。输入是 16bi 的二值数据,输出是矩阵数据。耗费 1 个时钟周期。
//**************************************************************************
// *** 名称 : matrix_3x3_8bit.v
// *** 作者 : xianyu_FPGA
// *** 博客 : https://www.cnblogs.com/xianyufpga/
// *** 日期 : 2020年3月
// *** 描述 : 3x3矩阵,边界采用像素复制,最大支持1024x1024,耗费1clk
//**************************************************************************
module matrix_3x3_8bit
//========================< 参数 >==========================================
#(
parameter H_DISP = 12'd480 , //图像宽度
parameter V_DISP = 12'd272 //图像高度
)
//========================< 端口 >==========================================
(
input wire clk ,
input wire rst_n ,
//input ---------------------------------------------
input wire din_vld ,
input wire [ 7:0] din ,
//output --------------------------------------------
output reg [ 7:0] matrix_11 ,
output reg [ 7:0] matrix_12 ,
output reg [ 7:0] matrix_13 ,
output reg [ 7:0] matrix_21 ,
output reg [ 7:0] matrix_22 ,
output reg [ 7:0] matrix_23 ,
output reg [ 7:0] matrix_31 ,
output reg [ 7:0] matrix_32 ,
output reg [ 7:0] matrix_33
);
//========================< 信号 >==========================================
reg [11:0] cnt_col ;
wire add_cnt_col ;
wire end_cnt_col ;
reg [11:0] cnt_row ;
wire add_cnt_row ;
wire end_cnt_row ;
wire wr_en_1 ;
wire wr_en_2 ;
wire rd_en_1 ;
wire rd_en_2 ;
wire [ 7:0] q_1 ;
wire [ 7:0] q_2 ;
wire [ 7:0] row_1 ;
wire [ 7:0] row_2 ;
wire [ 7:0] row_3 ;
//==========================================================================
//== FIFO例化,show模式,深度为大于两行数据个数
//==========================================================================
fifo_show_2048x8 u1
(
.clock (clk ),
.data (din ),
.wrreq (wr_en_1 ),
.rdreq (rd_en_1 ),
.q (q_1 )
);
fifo_show_2048x8 u2
(
.clock (clk ),
.data (din ),
.wrreq (wr_en_2 ),
.rdreq (rd_en_2 ),
.q (q_2 )
);
//==========================================================================
//== 行列划分
//==========================================================================
always @(posedge clk or negedge rst_n) begin
if(!rst_n)
cnt_col <= 12'd0;
else if(add_cnt_col) begin
if(end_cnt_col)
cnt_col <= 12'd0;
else
cnt_col <= cnt_col + 12'd1;
end
end
assign add_cnt_col = din_vld;
assign end_cnt_col = add_cnt_col && cnt_col== H_DISP-12'd1;
always @(posedge clk or negedge rst_n) begin
if(!rst_n)
cnt_row <= 12'd0;
else if(add_cnt_row) begin
if(end_cnt_row)
cnt_row <= 12'd0;
else
cnt_row <= cnt_row + 12'd1;
end
end
assign add_cnt_row = end_cnt_col;
assign end_cnt_row = add_cnt_row && cnt_row== V_DISP-12'd1;
//==========================================================================
//== fifo 读写信号
//==========================================================================
assign wr_en_1 = (cnt_row < V_DISP - 12'd1) ? din_vld : 1'd0; //不写最后1行
assign rd_en_1 = (cnt_row > 12'd0 ) ? din_vld : 1'd0; //从第1行开始读
assign wr_en_2 = (cnt_row < V_DISP - 12'd2) ? din_vld : 1'd0; //不写最后2行
assign rd_en_2 = (cnt_row > 12'd1 ) ? din_vld : 1'd0; //从第2行开始读
//==========================================================================
//== 形成 3x3 矩阵,边界采用像素复制
//==========================================================================
//矩阵数据选取
//---------------------------------------------------
assign row_1 = q_2;
assign row_2 = q_1;
assign row_3 = din;
//打拍形成矩阵,1clk
//---------------------------------------------------
always @(posedge clk or negedge rst_n) begin
if(!rst_n) begin
{matrix_11, matrix_12, matrix_13} <= {8'd0, 8'd0, 8'd0};
{matrix_21, matrix_22, matrix_23} <= {8'd0, 8'd0, 8'd0};
{matrix_31, matrix_32, matrix_33} <= {8'd0, 8'd0, 8'd0};
end
//------------------------------------------------------------------------- 第1排矩阵
else if(cnt_row == 12'd0) begin
if(cnt_col == 12'd0) begin //第1个矩阵
{matrix_11, matrix_12, matrix_13} <= {row_3, row_3, row_3};
{matrix_21, matrix_22, matrix_23} <= {row_3, row_3, row_3};
{matrix_31, matrix_32, matrix_33} <= {row_3, row_3, row_3};
end
else begin //剩余矩阵
{matrix_11, matrix_12, matrix_13} <= {matrix_12, matrix_13, row_3};
{matrix_21, matrix_22, matrix_23} <= {matrix_22, matrix_23, row_3};
{matrix_31, matrix_32, matrix_33} <= {matrix_32, matrix_33, row_3};
end
end
//------------------------------------------------------------------------- 第2排矩阵
else if(cnt_row == 12'd1) begin
if(cnt_col == 12'd0) begin //第1个矩阵
{matrix_11, matrix_12, matrix_13} <= {row_2, row_2, row_2};
{matrix_21, matrix_22, matrix_23} <= {row_2, row_2, row_2};
{matrix_31, matrix_32, matrix_33} <= {row_3, row_3, row_3};
end
else begin //剩余矩阵
{matrix_11, matrix_12, matrix_13} <= {matrix_12, matrix_13, row_2};
{matrix_21, matrix_22, matrix_23} <= {matrix_22, matrix_23, row_2};
{matrix_31, matrix_32, matrix_33} <= {matrix_32, matrix_33, row_3};
end
end
//------------------------------------------------------------------------- 剩余矩阵
else begin
if(cnt_col == 12'd0) begin //第1个矩阵
{matrix_11, matrix_12, matrix_13} <= {row_1, row_1, row_1};
{matrix_21, matrix_22, matrix_23} <= {row_2, row_2, row_2};
{matrix_31, matrix_32, matrix_33} <= {row_3, row_3, row_3};
end
else begin //剩余矩阵
{matrix_11, matrix_12, matrix_13} <= {matrix_12, matrix_13, row_1};
{matrix_21, matrix_22, matrix_23} <= {matrix_22, matrix_23, row_2};
{matrix_31, matrix_32, matrix_33} <= {matrix_32, matrix_33, row_3};
end
end
end
endmodule(2)腐蚀
采用流水线方式,一级一级的运算,最后得到结果,耗费 2 个时钟周期。
//**************************************************************************
// *** 名称 : erode.v
// *** 作者 : 咸鱼FPGA
// *** 博客 : https://www.cnblogs.com/xianyufpga/
// *** 日期 : 2020年3月
// *** 描述 : erode腐蚀处理,输入必须为二值图像
//**************************************************************************
module erode
//========================< 参数 >==========================================
#(
parameter H_DISP = 12'd480 , //图像宽度
parameter V_DISP = 12'd272 //图像高度
)
//========================< 端口 >==========================================
(
input wire clk , //时钟
input wire rst_n , //复位
//input ---------------------------------------------
input wire bina_de , //bina分量行同步
input wire bina_hsync , //bina分量场同步
input wire bina_vsync , //bina分量数据
input wire [ 7:0] bina_data , //bina分量数据使能
//output --------------------------------------------
output wire erode_de , //erode行同步
output wire erode_hsync , //erode场同步
output wire erode_vsync , //erode数据
output wire [ 7:0] erode_data //erode数据使能
);
//========================< 信号 >==========================================
//matrix_3x3 ----------------------------------------
wire [ 7:0] matrix_11 ;
wire [ 7:0] matrix_12 ;
wire [ 7:0] matrix_13 ;
wire [ 7:0] matrix_21 ;
wire [ 7:0] matrix_22 ;
wire [ 7:0] matrix_23 ;
wire [ 7:0] matrix_31 ;
wire [ 7:0] matrix_32 ;
wire [ 7:0] matrix_33 ;
//erode ---------------------------------------------
reg erode_1 ;
reg erode_2 ;
reg erode_3 ;
reg erode ;
//同步 ----------------------------------------------
reg [ 2:0] bina_de_r ;
reg [ 2:0] bina_hsync_r ;
reg [ 2:0] bina_vsync_r ;
//==========================================================================
//== matrix_3x3_8bit,生成3x3矩阵,输入和使能需对齐,耗费1clk
//==========================================================================
//--------------------------------------------------- 矩阵顺序
// {matrix_11, matrix_12, matrix_13}
// {matrix_21, matrix_22, matrix_23}
// {matrix_31, matrix_32, matrix_33}
//--------------------------------------------------- 模块例化
matrix_3x3_8bit
#(
.H_DISP (H_DISP ), //图像宽度
.V_DISP (V_DISP ) //图像高度
)
u_matrix_3x3_8bit
(
.clk (clk ),
.rst_n (rst_n ),
.din_vld (bina_de ),
.din (bina_data ),
.matrix_11 (matrix_11 ),
.matrix_12 (matrix_12 ),
.matrix_13 (matrix_13 ),
.matrix_21 (matrix_21 ),
.matrix_22 (matrix_22 ),
.matrix_23 (matrix_23 ),
.matrix_31 (matrix_31 ),
.matrix_32 (matrix_32 ),
.matrix_33 (matrix_33 )
);
//==========================================================================
//== 腐蚀,耗费2clk
//==========================================================================
//clk1,三行各自相与
//---------------------------------------------------
always @ (posedge clk or negedge rst_n)begin
if(!rst_n)begin
erode_1 <= 'd0;
erode_2 <= 'd0;
erode_3 <= 'd0;
end
else begin
erode_1 <= matrix_11 && matrix_12 && matrix_13;
erode_2 <= matrix_21 && matrix_22 && matrix_23;
erode_3 <= matrix_31 && matrix_32 && matrix_33;
end
end
//clk2,全部相与
//---------------------------------------------------
always @(posedge clk or negedge rst_n)begin
if(!rst_n)begin
erode <= 'd0;
end
else begin
erode <= erode_1 && erode_2 && erode_3;
end
end
//==========================================================================
//== 腐蚀后的数据
//==========================================================================
assign erode_data = erode ? 8'hff : 8'h00;
//==========================================================================
//== 信号同步
//==========================================================================
always @(posedge clk or negedge rst_n) begin
if(!rst_n) begin
bina_de_r <= 3'b0;
bina_hsync_r <= 3'b0;
bina_vsync_r <= 3'b0;
end
else begin
bina_de_r <= {bina_de_r[1:0], bina_de};
bina_hsync_r <= {bina_hsync_r[1:0], bina_hsync};
bina_vsync_r <= {bina_vsync_r[1:0], bina_vsync};
end
end
assign erode_de = bina_de_r[2];
assign erode_hsync = bina_hsync_r[2];
assign erode_vsync = bina_vsync_r[2];
endmodule
2、膨胀
(1)形成3x3矩阵
这个在前面的博客花了3篇来解释,就不多说了,我把3x3矩阵的代码用一个专门的 .v 文件写好,这里直接调用即可。输入是 16bi 的二值数据,输出是矩阵数据。耗费 1 个时钟周期。
//**************************************************************************
// *** 名称 : matrix_3x3_8bit.v
// *** 作者 : xianyu_FPGA
// *** 博客 : https://www.cnblogs.com/xianyufpga/
// *** 日期 : 2020年3月
// *** 描述 : 3x3矩阵,边界采用像素复制,最大支持1024x1024,耗费1clk
//**************************************************************************
module matrix_3x3_8bit
//========================< 参数 >==========================================
#(
parameter H_DISP = 12'd480 , //图像宽度
parameter V_DISP = 12'd272 //图像高度
)
//========================< 端口 >==========================================
(
input wire clk ,
input wire rst_n ,
//input ---------------------------------------------
input wire din_vld ,
input wire [ 7:0] din ,
//output --------------------------------------------
output reg [ 7:0] matrix_11 ,
output reg [ 7:0] matrix_12 ,
output reg [ 7:0] matrix_13 ,
output reg [ 7:0] matrix_21 ,
output reg [ 7:0] matrix_22 ,
output reg [ 7:0] matrix_23 ,
output reg [ 7:0] matrix_31 ,
output reg [ 7:0] matrix_32 ,
output reg [ 7:0] matrix_33
);
//========================< 信号 >==========================================
reg [11:0] cnt_col ;
wire add_cnt_col ;
wire end_cnt_col ;
reg [11:0] cnt_row ;
wire add_cnt_row ;
wire end_cnt_row ;
wire wr_en_1 ;
wire wr_en_2 ;
wire rd_en_1 ;
wire rd_en_2 ;
wire [ 7:0] q_1 ;
wire [ 7:0] q_2 ;
wire [ 7:0] row_1 ;
wire [ 7:0] row_2 ;
wire [ 7:0] row_3 ;
//==========================================================================
//== FIFO例化,show模式,深度为大于两行数据个数
//==========================================================================
fifo_show_2048x8 u1
(
.clock (clk ),
.data (din ),
.wrreq (wr_en_1 ),
.rdreq (rd_en_1 ),
.q (q_1 )
);
fifo_show_2048x8 u2
(
.clock (clk ),
.data (din ),
.wrreq (wr_en_2 ),
.rdreq (rd_en_2 ),
.q (q_2 )
);
//==========================================================================
//== 行列划分
//==========================================================================
always @(posedge clk or negedge rst_n) begin
if(!rst_n)
cnt_col <= 12'd0;
else if(add_cnt_col) begin
if(end_cnt_col)
cnt_col <= 12'd0;
else
cnt_col <= cnt_col + 12'd1;
end
end
assign add_cnt_col = din_vld;
assign end_cnt_col = add_cnt_col && cnt_col== H_DISP-12'd1;
always @(posedge clk or negedge rst_n) begin
if(!rst_n)
cnt_row <= 12'd0;
else if(add_cnt_row) begin
if(end_cnt_row)
cnt_row <= 12'd0;
else
cnt_row <= cnt_row + 12'd1;
end
end
assign add_cnt_row = end_cnt_col;
assign end_cnt_row = add_cnt_row && cnt_row== V_DISP-12'd1;
//==========================================================================
//== fifo 读写信号
//==========================================================================
assign wr_en_1 = (cnt_row < V_DISP - 12'd1) ? din_vld : 1'd0; //不写最后1行
assign rd_en_1 = (cnt_row > 12'd0 ) ? din_vld : 1'd0; //从第1行开始读
assign wr_en_2 = (cnt_row < V_DISP - 12'd2) ? din_vld : 1'd0; //不写最后2行
assign rd_en_2 = (cnt_row > 12'd1 ) ? din_vld : 1'd0; //从第2行开始读
//==========================================================================
//== 形成 3x3 矩阵,边界采用像素复制
//==========================================================================
//矩阵数据选取
//---------------------------------------------------
assign row_1 = q_2;
assign row_2 = q_1;
assign row_3 = din;
//打拍形成矩阵,1clk
//---------------------------------------------------
always @(posedge clk or negedge rst_n) begin
if(!rst_n) begin
{matrix_11, matrix_12, matrix_13} <= {8'd0, 8'd0, 8'd0};
{matrix_21, matrix_22, matrix_23} <= {8'd0, 8'd0, 8'd0};
{matrix_31, matrix_32, matrix_33} <= {8'd0, 8'd0, 8'd0};
end
//------------------------------------------------------------------------- 第1排矩阵
else if(cnt_row == 12'd0) begin
if(cnt_col == 12'd0) begin //第1个矩阵
{matrix_11, matrix_12, matrix_13} <= {row_3, row_3, row_3};
{matrix_21, matrix_22, matrix_23} <= {row_3, row_3, row_3};
{matrix_31, matrix_32, matrix_33} <= {row_3, row_3, row_3};
end
else begin //剩余矩阵
{matrix_11, matrix_12, matrix_13} <= {matrix_12, matrix_13, row_3};
{matrix_21, matrix_22, matrix_23} <= {matrix_22, matrix_23, row_3};
{matrix_31, matrix_32, matrix_33} <= {matrix_32, matrix_33, row_3};
end
end
//------------------------------------------------------------------------- 第2排矩阵
else if(cnt_row == 12'd1) begin
if(cnt_col == 12'd0) begin //第1个矩阵
{matrix_11, matrix_12, matrix_13} <= {row_2, row_2, row_2};
{matrix_21, matrix_22, matrix_23} <= {row_2, row_2, row_2};
{matrix_31, matrix_32, matrix_33} <= {row_3, row_3, row_3};
end
else begin //剩余矩阵
{matrix_11, matrix_12, matrix_13} <= {matrix_12, matrix_13, row_2};
{matrix_21, matrix_22, matrix_23} <= {matrix_22, matrix_23, row_2};
{matrix_31, matrix_32, matrix_33} <= {matrix_32, matrix_33, row_3};
end
end
//------------------------------------------------------------------------- 剩余矩阵
else begin
if(cnt_col == 12'd0) begin //第1个矩阵
{matrix_11, matrix_12, matrix_13} <= {row_1, row_1, row_1};
{matrix_21, matrix_22, matrix_23} <= {row_2, row_2, row_2};
{matrix_31, matrix_32, matrix_33} <= {row_3, row_3, row_3};
end
else begin //剩余矩阵
{matrix_11, matrix_12, matrix_13} <= {matrix_12, matrix_13, row_1};
{matrix_21, matrix_22, matrix_23} <= {matrix_22, matrix_23, row_2};
{matrix_31, matrix_32, matrix_33} <= {matrix_32, matrix_33, row_3};
end
end
end
endmodule(2)膨胀
采用流水线方式,一级一级的运算,最后得到结果,耗费 2 个时钟周期。
//**************************************************************************
// *** 名称 : dilate.v
// *** 作者 : 咸鱼FPGA
// *** 博客 : https://www.cnblogs.com/xianyufpga/
// *** 日期 : 2020年3月
// *** 描述 : dilate膨胀处理,输入必须为二值图像
//**************************************************************************
module dilate
//========================< 参数 >==========================================
#(
parameter H_DISP = 12'd480 , //图像宽度
parameter V_DISP = 12'd272 //图像高度
)
//========================< 端口 >==========================================
(
input wire clk , //时钟
input wire rst_n , //复位
//input ---------------------------------------------
input wire bina_de , //bina分量行同步
input wire bina_hsync , //bina分量场同步
input wire bina_vsync , //bina分量数据
input wire [ 7:0] bina_data , //bina分量数据使能
//output --------------------------------------------
output wire dilate_de , //dilate行同步
output wire dilate_hsync , //dilate场同步
output wire dilate_vsync , //dilate数据
output wire [ 7:0] dilate_data //dilate数据使能
);
//========================< 信号 >==========================================
//matrix_3x3 ----------------------------------------
wire [ 7:0] matrix_11 ;
wire [ 7:0] matrix_12 ;
wire [ 7:0] matrix_13 ;
wire [ 7:0] matrix_21 ;
wire [ 7:0] matrix_22 ;
wire [ 7:0] matrix_23 ;
wire [ 7:0] matrix_31 ;
wire [ 7:0] matrix_32 ;
wire [ 7:0] matrix_33 ;
//dilate --------------------------------------------
reg dilate_1 ;
reg dilate_2 ;
reg dilate_3 ;
reg dilate ;
//同步 ----------------------------------------------
reg [ 2:0] bina_de_r ;
reg [ 2:0] bina_hsync_r ;
reg [ 2:0] bina_vsync_r ;
//==========================================================================
//== matrix_3x3_8bit,生成3x3矩阵,输入和使能需对齐,耗费1clk
//==========================================================================
//--------------------------------------------------- 矩阵顺序
// {matrix_11, matrix_12, matrix_13}
// {matrix_21, matrix_22, matrix_23}
// {matrix_31, matrix_32, matrix_33}
//--------------------------------------------------- 模块例化
matrix_3x3_8bit
#(
.H_DISP (H_DISP ), //图像宽度
.V_DISP (V_DISP ) //图像高度
)
u_matrix_3x3_8bit
(
.clk (clk ),
.rst_n (rst_n ),
.din_vld (bina_de ),
.din (bina_data ),
.matrix_11 (matrix_11 ),
.matrix_12 (matrix_12 ),
.matrix_13 (matrix_13 ),
.matrix_21 (matrix_21 ),
.matrix_22 (matrix_22 ),
.matrix_23 (matrix_23 ),
.matrix_31 (matrix_31 ),
.matrix_32 (matrix_32 ),
.matrix_33 (matrix_33 )
);
//==========================================================================
//== 膨胀,耗费2clk
//==========================================================================
//clk1,三行各自相或
//---------------------------------------------------
always @ (posedge clk or negedge rst_n)begin
if(!rst_n)begin
dilate_1 <= 'd0;
dilate_2 <= 'd0;
dilate_3 <= 'd0;
end
else begin
dilate_1 <= matrix_11 || matrix_12 || matrix_13;
dilate_2 <= matrix_21 || matrix_22 || matrix_23;
dilate_3 <= matrix_31 || matrix_32 || matrix_33;
end
end
//clk2,全部相或
//---------------------------------------------------
always @(posedge clk or negedge rst_n)begin
if(!rst_n)begin
dilate <= 'd0;
end
else begin
dilate <= dilate_1 || dilate_2 || dilate_3;
end
end
//==========================================================================
//== 膨胀后的数据
//==========================================================================
assign dilate_data = dilate ? 8'hff : 8'h00;
//==========================================================================
//== 信号同步
//==========================================================================
always @(posedge clk or negedge rst_n) begin
if(!rst_n) begin
bina_de_r <= 3'b0;
bina_hsync_r <= 3'b0;
bina_vsync_r <= 3'b0;
end
else begin
bina_de_r <= {bina_de_r[1:0], bina_de};
bina_hsync_r <= {bina_hsync_r[1:0], bina_hsync};
bina_vsync_r <= {bina_vsync_r[1:0], bina_vsync};
end
end
assign dilate_de = bina_de_r[2];
assign dilate_hsync = bina_hsync_r[2];
assign dilate_vsync = bina_vsync_r[2];
endmodule
四、上板验证



[1] OpenS Lee:FPGA开源工作室(公众号)
[2] CrazyBingo:基于VIP_Board Mini的FPGA视频图像算法(HDL-VIP)开发教程-V1.6
[3] NingHechuan:FPGA图像处理教程
[4] 牟新刚、周晓、郑晓亮.基于FPGA的数字图像处理原理及应用[M]. 电子工业出版社,2017.
[5] 张铮, 王艳平, 薛桂香. 数字图像处理与机器视觉[M]. 人民邮电出版社, 2010.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号