

使用QT creator实现一个五子棋AI包括GUI实现(8K字超详细)
五子棋AI实现
五子棋游戏介绍
五子棋的定义
五子棋是全国智力运动会竞技项目之一,是具有完整信息的、确定性的、轮流行动的、两个游戏者的零和游戏。因此,五子棋是一个博弈问题。
五子棋的玩法
五子棋有两种玩法:
玩法一:双方分别使用黑白两色的棋子,下在棋盘直线与横线的交叉点上,先形成五子连线者获胜。
玩法二:自己形成五子连线就替换对方任意一枚棋子。被替换的棋子可以和对方交换棋子。最后以先出完所有棋子的一方为胜。
本次实验的玩法是第一种。
五子棋的具体规则
-
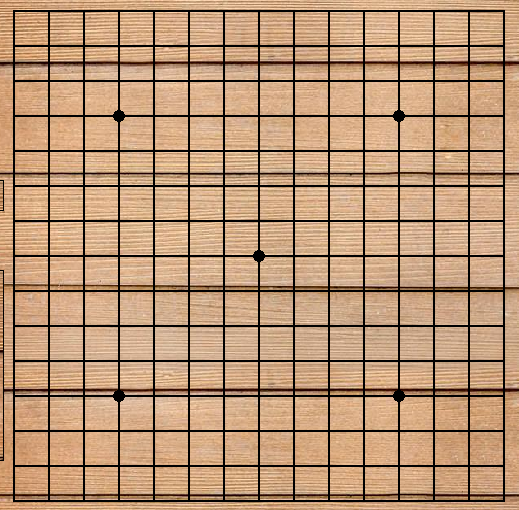
对局双方各执一色棋子,棋盘一共15行15列,225个下棋点。
-
空棋盘开局。
-
黑先、白后,交替下子,每次只能下一子。
-
棋子下在棋盘的空白点上,棋子下定后,不得向其它点移动,不得从棋盘上拿掉或拿起另落别处。
-
黑方的第一枚棋子必须下在天元点上,即中心交叉点
-
轮流下子是双方的权利,但允许任何一方放弃下子权(即:PASS权)。
五子棋博弈算法的具体实现
算法定义:
由于是零和游戏的博弈问题,因此针对此问题的经典算法为min-max算法以及针对其的alpha-beta剪枝优化算法。
min-max算法:
设游戏的两个游戏者为MAX和MIN。MAX先下棋,然后两人轮流出招,对于每一步当前的棋盘局面,使用一个评估函数 \(score(x)\) 来评价MAX距离游戏胜利的远近。MAX越容易获得胜利,\(score(x)\)的值就越大。
算法思想:
对于MAX来说,他的每一步棋都要使得当前棋盘局面的评估函数最大,即\(max(score(board[r][l]))\),\(r\),\(l\) 表示MAX下的棋子的位置。
而相反,对于MIN来说,他的每一步棋都要使得当前棋盘局面的评估函数最小,即\(min(score(board[r][l]))\),\(r\),\(l\) 表示MIN下的棋子的位置。
因此,使用深度有限搜索的方法,即限制问题搜索的深度为\(depth\)(\(depth\)表示MAX和MIN从目前棋盘轮流下子的次数),一旦搜索深度到达\(depth\)就计算预测棋盘的得分,然后往上回溯,搜索树以及搜索过程如图所示:
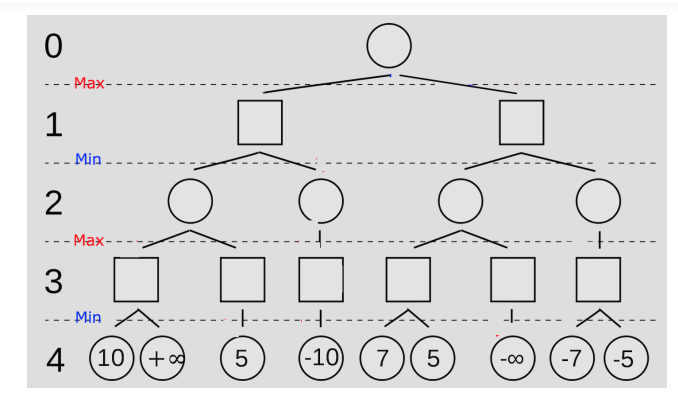
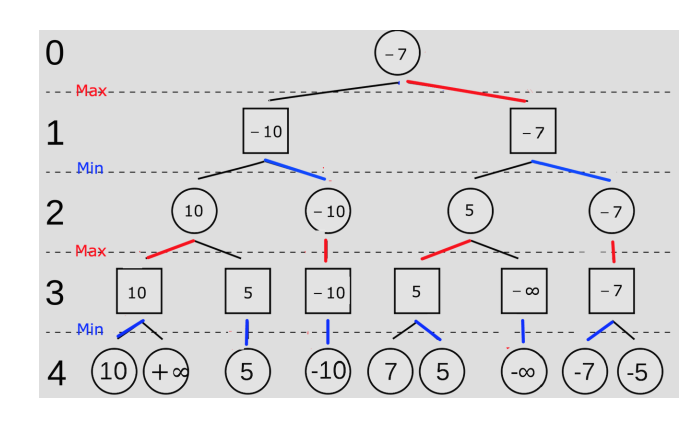
图引自:《人工智能》(一):min-max算法 - 简书 (jianshu.com)
该树的深度为5层,但是\(depth\)为4。
\(depth = 3\)为MIN层,MIN选择所有预测局面中的得分最小的情况作为自己这一步下棋的位置,而\(depth = 2\)的MAX层在\(depth=3\)的MIN层的基础上形成的局面中选择得分最大的位置来作为自己这一步下棋的位置(就是MAX考虑下棋时,遍历225个下棋的点位,选择局面得分最高的点下棋)。以此类推,最后找到能够使\(depth=0\)的MAX下一步得分最高的点。
Min-Max的核心就是假设双方每一步都是相对于评估函数的最优解的情况下来选择下一步该走的位置。
算法伪代码:

cpp代码:
void chess_board::min_max_search(QTextBrowser *detail_info)
{
score_next = max_sear(0,detail_info);
}
int chess_board::max_sear(int deep,QTextBrowser *detail_info)
{
if(deep==depth)
return cal_score(first_me);
int v = -0x3f3f3f3f;
int old_a = 0;
for(int l=0;l<board_col;l++)
for(int r=0;r<board_row;r++)
{
if(board[r][l]=='0')//如果当前位置是空子的话
{
set_temp_chess(r,l,true);
v = max(v,min_sear(deep+1, detail_info));
if(deep==0&&v!=old_a)//如果是在最表层且有更新,则选择这一步
{
char tip_out[1005] = {0};
sprintf(tip_out,"update max:\n l = %d, r = %d \nv = %d\n",l,r,v);
detail_info->textCursor().insertText(tip_out);
next.set_rl(r,l);
old_a = v;
}
clear_temp_chess(r,l);//注意要回溯
}
}
return v;
}
int chess_board::min_sear(int deep,QTextBrowser *detail_info)
{
if(deep==depth)
return cal_score(first_me);
int v = 0x3f3f3f3f;
for(int l=0;l<board_col;l++)
for(int r=0;r<board_row;r++)
{
if(board[r][l]=='0')//如果当前位置是空子的话
{
set_temp_chess(r,l,false);
v = min(v,max_sear(deep+1, detail_info));
clear_temp_chess(r,l);//注意要回溯
}
}
return v;
}
实现细节:
- 由于只有一个棋盘,因此要注意dfs回溯的时候要清除临时下的棋子。
- MAX根节点,也就是最高层,每次更新\(v\)的时候记录下落子的位置,搜索完后对应的位置就是人工智能要落子的位置。
算法缺点:
太慢了。
如果遍历的深度为n,每一层要对225个下棋的点进行遍历,每次遍历又是递归调用。因此每一次下棋就需要对\(225^n\)中棋盘进行分数评估,加上分数评估也需要时间,因此算法复杂度很高,一般\(depth=2\)的时候每一步的等待时间要超过10s。
\(\alpha\)-\(\beta\) 剪枝算法:
为了针对上述MAX-MIN算法复杂度高的问题,\(\alpha\)-\(\beta\) 剪枝算法应运而生。
剪枝思想
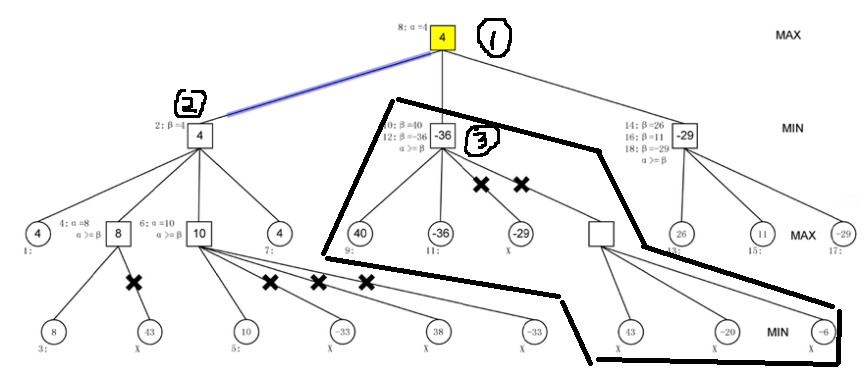
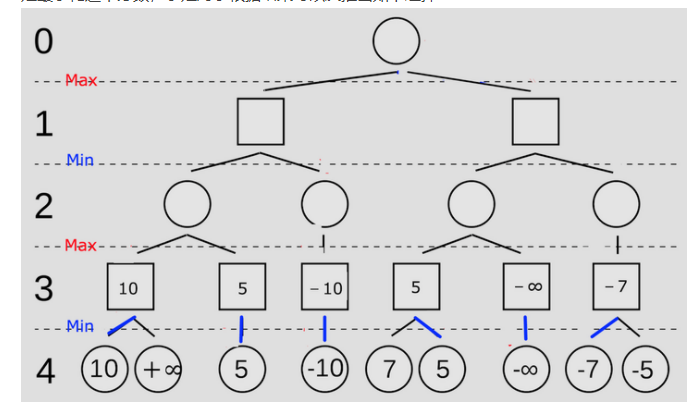
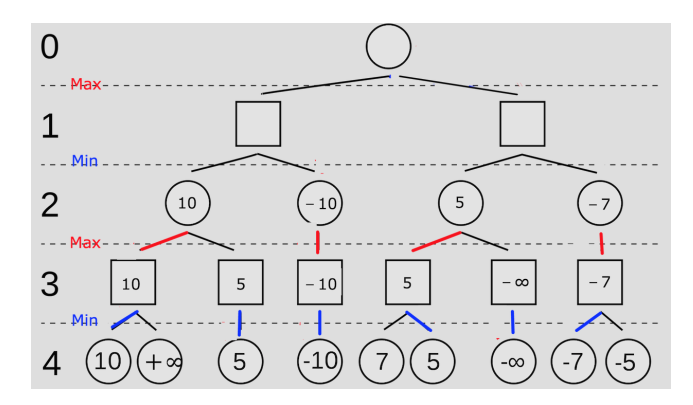
考虑图中画圈的部分:
已知MAX要选择所有MIN已经造成的得分中最高的那一个位置落子;
对于图中的①号节点,其遍历过②号节点以及对应的子树之后目前的得分是4;
其开始遍历自己的第二棵子树,其根节点为③,节点③遍历自己的第一个子树后获得的值为40;
由于节点①取最大值,因此节点③目前的值有保留的必要。
继续搜索第二棵子树,发现第二棵子树的根节点对应的值为-36;
由于节点③对应的是MIN玩家,要选择最小的位置,因此MIN玩家更新自己落子的位置,节点③的值更新为-36;
由于节点③对应的是MIN玩家,其选择的落子位置得分不会比-36大;
而节点①是MAX玩家,其不可能选择落子得分为-36的局面;
因此节点③就没有往后搜索的必要了,因此后面的搜索都可以去掉。完成一个剪枝。
注意,这个搜索过程是在建立树的过程中剪枝的,是先剪枝,再有整个问题的完整搜索树
算法具体实现:
-
每一个节点维护一个\(\alpha\)和\(\beta\)值以及这个节点的估值\(v\),表示该节点的估值应该在\([\alpha,\beta]\)区间内,一旦\(\alpha \ge \beta\),这个节点就不再进行拓展,成为死节点。
-
\(\alpha\)和\(\beta\)的更新有两个来源:
- 如果目前考虑的节点为MAX玩家对应的节点,则它的\(\alpha\)值为目前所有孩子节点的值中的最大值(此时\(v == \alpha\)),如果目前考虑的节点为MIN玩家对应的节点,则它的\(\beta\)值为目前所有孩子节点中值的最小值(此时\(v == \beta\))。
- \(\alpha\)和\(\beta\)的初始值继承自其双亲节点。最初的根节点其\(\alpha = -\infin, \beta=\infin\)。
具体过程如图所示:
这里略过12张图片,具体看下面链接
图片引自:详解Minimax算法与α-β剪枝_文剑木然的专栏-CSDN博客_α-β剪枝
自己用笔画一遍就会了啦
算法伪代码:
分为三个函数,alpha_beta_search函数代表调用的入口,Max_Value函数代表Max的操作,Min_Value函数代表Min的操作。

cpp代码:
int chess_board::max_value(int deep,int alpha,int beta,QTextBrowser *detail_info)
{
if(deep==depth)
return cal_score(first_me);
int v = -0x3f3f3f3f;
int old_a = 0;
for(int l=0;l<board_col;l++)//启发式搜索
for(int r=0;r<board_row;r++)
{
if(board[r][l]=='0')//如果当前位置是空子的话
{
set_temp_chess(r,l,true);
v = max(v,min_value(deep+1,alpha,beta,detail_info));
if(v>=beta)
{
clear_temp_chess(r,l);//注意要回溯
return v;
}
alpha = max(alpha,v);
if(deep==0&&alpha==v&&alpha!=old_a)//如果是在最表层且有更新,则选择这一步
{
char tip_out[1005] = {0};
sprintf(tip_out,"update max:\n l = %d, r = %d \nv = %d\n",l,r,v);
detail_info->textCursor().insertText(tip_out);
next.set_rl(r,l);
old_a = alpha;
}
clear_temp_chess(r,l);//注意要回溯
}
}
return v;
}
int chess_board::min_value(int deep,int alpha,int beta, QTextBrowser *detail_info)
{
if(deep==depth)
return cal_score(first_me);
int v = 0x3f3f3f3f;
int old_a = 0;
vector<node>h_score;
for(int l=0;l<board_col;l++)//启发式搜索
for(int r=0;r<board_row;r++)
{
if(board[r][l]=='0')//如果当前位置是空子的话
{
set_temp_chess(r,l,false);
v = min(v,max_value(deep+1,alpha,beta,detail_info));
if(v<=alpha)
{
clear_temp_chess(r,l);//注意要回溯
return v;
}
beta = min(beta,v);
clear_temp_chess(r,l);//注意要回溯
}
}
return v;
}
void chess_board::alpha_beta_search(QTextBrowser *detail_info)
{
int alpha = -0x3f3f3f3f;
int beta = 0x3f3f3f3f;
score_next = max_value(0,alpha,beta,detail_info);
}
实现细节
注意要回溯,对的,基本上没什么了,注意要回溯。
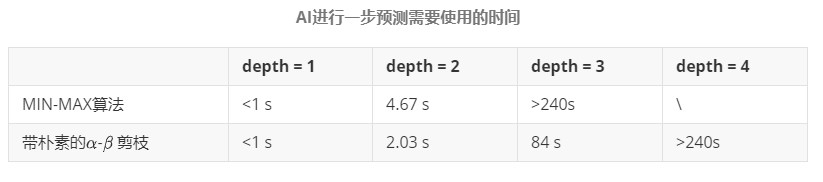
有无\(\alpha\)-\(\beta\) 剪枝对比:
估值函数:
估值函数的定义:
用于估计当前棋盘局面的函数 \(score(x)\), 来评价MAX距离游戏胜利的远近。MAX越容易获得胜利,\(score(x)\)的值就越大。
估值函数实现思路:
多玩几盘五子棋就会发现 (也许也不会发现) ,评估一个局面某一玩家是否容易取得胜利主要是看棋盘横竖边以及斜边中含有的棋型,假设\(A\)棋子表示MAX下的棋子,\(B\)表示MIN下的棋子,\(0\)表示没有棋子。如果某一行列中有"0AAAA0"的话,说明MAX就要获得胜利了,所以棋盘评估的得分就高,如果某一行列中有"0BBBB0"的话,说明MIN要获得胜利了,棋盘评估的得分就低。而且比对的话会发现棋盘中有"0AAAA0"比棋盘中有“00AAA0”MAX更容易获得胜利,因此棋型"0AAAA0"的分值要比“00AAA0”的分值要更高。
所以,经过分析,实现估值函数的思路就是先找出五子棋中出现的所有棋型并为其打分,然后遍历当前棋盘中每一行每一列每一斜边,寻找出所有符合的棋型,如果棋型对MAX有利,则在总分数上加上该棋型所对应的分值,如果棋型对MIN有利,则减去该棋型对应的分值。
经过多次的调整,确定棋型以及得分如下:(这里显示的为MAX的棋型,MIN的话要把所有的A改成B)
// MAX MIN
// 死二 A: BAA000 或 000AAB 150 140
// 死二 B: BA0A00 或 00A0AB 250 240
// 死二 C: BA00A0 或 0A00AB 200 190
// 活二 A: 0AA000 或 000AA0 650 640
// 活二 B: 00A0A0 或 0A0A00 400 390
// 死三 A: BAAA00 或 00AAAB 500 490
// 死三 B: BA0AA0 或 0AA0AB 800 790
// 死三 C: A00AA 600 590
// 死三 D: A0A0A 600 590
// 活三 A: 0A0AA0 2000 1990
// 活三 B: 0AAA00 或 00AAA0 3000 2990
// 死四 A: BAAAA0 或 0AAAAB 2500 2490
// 死四 B: AAA0A 3000 2990
// 死四 C: AA0AA 2600 2590
// 活四 0AAAA0 300000 299990
// 连棋 AAAAA 30000000 299999990
估值函数代码实现:
实现细节:
使用一个15*15的char型数组来存储棋盘,四种数组储存行,列,左下到右上的斜行,左上到右下的斜行一共 \(15+15+21+21=72\)个数组,将整个棋盘划分成72份,每次遍历预测的时候动态更新棋盘和这72个数组,然后每次只要寻找这72个数组中有无匹配的字符串就行了。这个部分的难点就是斜边的42个数组该如何取出来以及如何更新。
各个具体分值定义:
partern chess_type_all_my[25] = {{"BAA000", 150, 140}, {"000AAB", 150, 140}, {"BA0A00", 250, 240}, {"00A0AB", 250, 240}, {"BA00A0", 200, 190}, {"0A00AB", 200, 190}, {"0AA000", 650, 640}, {"000AA0", 650, 640},{"0A0A00", 300, 290}, {"00A0A0", 300, 290}, {"BAAA00", 500, 490}, {"00AAAB", 500, 490}, {"BA0AA0", 800, 790}, {"0AA0AB", 800, 790}, {"A00AA", 600, 590}, {"A0A0A", 600, 590}, {"0A0AA0", 2000, 1990}, {"0AAA00", 3000, 2990}, {"00AAA0", 3000, 2990}, {"BAAAA0", 2500, 2490}, {"0AAAAB", 2500, 2490}, {"AAA0A", 3000, 2990}, {"AA0AA", 2600, 2590}, {"0AAAA0", 300000, 299990}, {"AAAAA", 3000000, 29999990}};
partern chess_type_all_opt[25] = {{"ABB000", 150, 140}, {"000BBA", 150, 140}, {"AB0B00", 250, 240}, {"00B0BA", 250, 240}, {"AB00B0", 200, 190}, {"0B00BA", 200, 190}, {"0BB000", 650, 640}, {"000BB0", 650, 640},{"0B0B00", 300, 290}, {"00B0B0", 300, 290}, {"ABBB00", 500, 490}, {"00BBBA", 500, 490}, {"AB0BB0", 800, 790}, {"0BB0BA", 800, 790}, {"B00BB", 600, 590}, {"B0B0B", 600, 590}, {"0B0BB0", 2000, 1990}, {"0BBB00", 3000, 2990}, {"00BBB0", 3000, 2990}, {"ABBBB0", 2500, 2490}, {"0BBBBA", 2500, 2490}, {"BBB0B", 3000, 2990}, {"BB0BB", 2600, 2590}, {"0BBBB0", 300000, 299990}, {"BBBBB", 3000000, 29999990}};
函数解析:
int find_count(const char* temp,const char*partern)
这个函数用来匹配每一个数组中句型的个数。使用strstr方法,寻找到匹配字符串的位置后count++,然后将寻找的起始字符串向后移,继续寻找,直到strstr返回为NULL
代码如下:
int find_count(const char* temp,const char*partern)
{
int count1 = 0;
int cur = 0;
char *now = NULL;
while((now = strstr(temp+cur,partern))!=NULL)
{
cur = now - temp + strlen(partern);
count1++;
}
return count1;
}
chess_board::chess_board(void)
这个是类的构造函数,用于构造这72个数组,行列的数组还比较好构造,但是斜边的数组就不那么好构造了,因为有的斜边少于5个点可以落子,这种斜边不能考虑,如下图红圈部分,四个角都是:这也就是为什么斜边的数组只有21个而不是27个

因此,需要确定坐标系,叫左下角作为坐标原点,使用\(l+r = b\)中的\(b\)来区分不同的数组(这里很难讲清楚,自己体会)
代码如下:
chess_board::chess_board(void)
{
for(int r=0;r<15;r++)
{
for(int l=0;l<15;l++)
{
board[r][l] = '0';
rows[r][l] = '0';
cols[r][l] = '0';
}
board[r][15] = '\0';
rows[r][15] = '\0';
cols[r][15] = '\0';
}
for(int b=0;b<21;b++)//左下向右上
for(int l=0;l<15;l++)
{
int r = l+b-10;//b = r+10-l
if(l>=0&&l<15&&r>=0&&r<15)
edge_lr[b][l] = '0';
else
edge_lr[b][l] = '\0';
}
for(int b=0;b<21;b++)//右下向左上
for(int l=0;l<15;l++)
{
·····
}
algorithm_opt = 1;
depth = 4;//先遍历两步看看吧
}
int chess_board::cal_score(bool is_att)
终于来到计算分数的函数了,在这个函数中,由于斜边对应的数组每个的起始不同,需要计算(这里有点复杂),就是要根据\(b\)来推出数组的起始位置,这个每个人的实现方法不同对应的算法也不同,自己想。
该函数遍历每一个数组,找出每一个数组中存在的句型,如果这个句型在我方中存在,那就在总分上加上\(句型的分值*句型的数量\),如果这个句型在对方句型库中存在,那就在总分上减去\(句型的分值*句型的数量\),符合零和游戏的特点。
int chess_board::cal_score(bool is_att)
{
int score = 0;
for(int r=0;r<15;r++)//每一行
{
string temp = rows[r];
if(pd_null(temp))//判断是否为空,没有棋子就不要查了
continue;
for(int i = 0;i<type_count;i++)//查找每一种棋型
{
int count1 = find_count(temp.c_str(),chess_type_all_my[i].ptn.c_str());
if(i==8)
count1-= find_count(temp.c_str(),chess_type_all_my[7].ptn.c_str());
if(i==19)
count1-= find_count(temp.c_str(),chess_type_all_my[18].ptn.c_str());
score+=count1*chess_type_all_my[i].my_score;
int count2 = find_count(temp.c_str(),chess_type_all_opt[i].ptn.c_str());
if(i==8)
count2-= find_count(temp.c_str(),chess_type_all_opt[7].ptn.c_str());
if(i==19)
count2-= find_count(temp.c_str(),chess_type_all_opt[18].ptn.c_str());
score-=count2*chess_type_all_my[i].opt_score;
}
}
for(int l =0;l<15;l++)//每一列
{
····
}
for(int b = 0;b<=20;b++)//左下到右上的斜行
{
····
}
for(int b = 0;b<=20;b++)//左上到右下的斜行
{
····
}
return score;
}
遇到的一些坑:
- 写计算句型数量的函数的时候,每次找到一个句型之后没有跳过匹配的句型,只是简单的将寻找的起始位置加1,这样会遇到重复计算的情况,如:"00AAA0"和"0AAA00"就会重复计算,这样会导致明明只有一个三活却读出了两个。
- 写计算分值的时候,因为定义的句型中间"00AAA0"和"0AAA00"有时会重复计算,为了避免这个事情发生。以这个为例,在计算"00AAA0"的时候,会先数一下"0AAA00"是否已经被计算过了,如果计算过了,就会将"00AAA0"的数量减一。
- 一开始将72个数组的更新放在了一个临时的数组当中,每次预测的时候都要复制一遍72个数组,这样降低了遍历的速度,利用深度优先搜索可回溯的特点,动态更新,可以加快搜索的速度。
- 在对每一个棋型的分值进行评估的时候,将自己的五连珠和对手的五连珠的分值设置的太过接近,导致遍历的时候AI不去管对面即将五连珠的棋型,反而专注于自己的五连珠(但是自己始终比对手慢一步),导致防守失败。因此对手五连珠的分值应该设为自己五连珠分值的10倍
alpha-beta剪枝优化
尽管alpha-beta剪枝对速度有所优化,但是在实际问题中,我们还是很少使用朴素的alpha-beta剪枝算法,因为还是太慢了。
朴素的alpha-beta剪枝缺陷:
还是慢。。。
在可接受的范围内只能搜到\(depth=2\)的情况,相当于只预测了一轮(MAX下了一次,然后MIN下了一次,再轮到MAX下的时候就要算分了)。这样的层数下算法肯定还是不够聪明,因此得想办法加快。
alpha-beta剪枝算法加速:
前剪枝:
在五子棋中,落子的点一般都在别的已经落子的棋子旁边,很容易看出,在当前棋盘的局面下,如果落子在红圈所在的地方肯定是没有意义的,因为其对评估函数的结果不会变得更好。
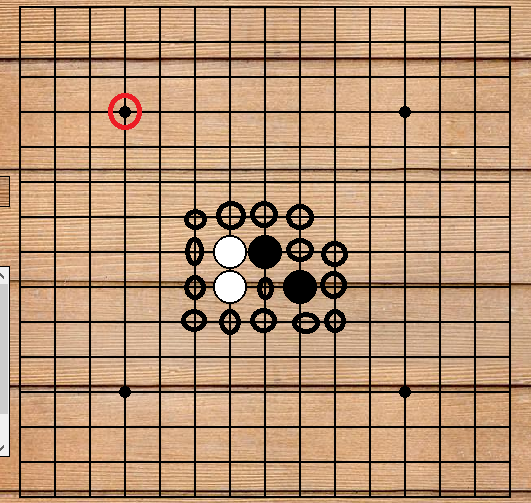
所以,在遍历的时候,我们可以只考虑目前在棋盘上所有棋子的附近的棋子。换句话说,对于某一个位置,如果其四周都没有棋子的话,就不考虑它,将其剪枝。因此,在上图中只用考虑黑圈中的棋子。这样就达到了前剪枝,节省了大量的时间。
启发式搜索:
启发式搜索的定义:
用于生成待搜索位置的函数,在朴素的alpha-beta剪枝中,节点搜索的顺序是按照从下到上,从左往右的顺序进行的。但是深入理解alpha-beta剪枝会发现:节点的值的排列顺序非常的影响alpha-beta剪枝的效率:对于某个节点来说,如果第一个孩子节点就是所有孩子节点的分数的最小值,而该节点又是MIN节点,就可以在第一个节点满足alpha-beta剪枝的条件:\(\alpha>=\beta\),这样就可以大大增加剪枝的效率。
例如:对于下图中黑圈内的区域,如果叶子节点值为4的节点能和叶子节点值为7的节点顺序互换,那么就可以将叶子节点值为7的节点剪掉,增加了剪枝的效率。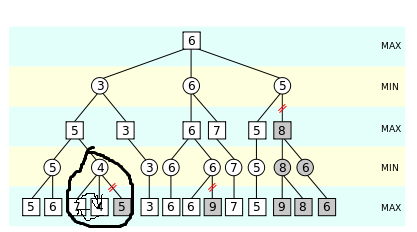
因此,我们需要一个启发式搜索的函数,该函数可以有效的评估哪些落子的点的评估函数值大,哪些落子的点评估函数的值小,这样就可以大大加快剪枝的效率了。
本实验设计的启发式搜索函数:
将该函数命名为\(h(x)\),针对每一个落子的点,遍历经过这个点的行,列,斜线的四个数组,找出相应的对我方有利的棋型然后加分,如果遇到两个以上的三活以及四活,则将\(h(x)\)加一个很大的值,表示优先遍历。
这样的好处是AI可以有效的识别两个三活以及死四以及活四这种必杀棋的情况,并且针对其进行进攻和防守。
实现代码如下:
int partern_count[type_count]={0};//用来存每一个棋子的数量
int sum_score = 0;
int b_lr = r+10-l;
int b_rl = r+l-4;
for(int i = 0;i<type_count;i++)//查找每一种棋型
{
string temp_rl;
string temp_lr;
if(b_rl>=0&&b_rl<=20)//如果不存在,则不考虑
temp_rl = &edge_rl[b_rl][(b_rl-10<0)?0:b_rl-10];
if(b_lr>=0&&b_lr<=20)
temp_lr = &edge_lr[b_lr][(10-b_lr<0)?0:10-b_lr];
int count1 = find_count(rows[r],chess_type_all_my[i].ptn.c_str());//行
int count2 = find_count(cols[l],chess_type_all_my[i].ptn.c_str());//列
int count3 = find_count(temp_rl.c_str(),chess_type_all_my[i].ptn.c_str());//左下到右上
int count4 = find_count(temp_lr.c_str(),chess_type_all_my[i].ptn.c_str());//左上到右下
if(i==8)
{
count1 -= find_count(rows[r],chess_type_all_my[7].ptn.c_str());
count2 -= find_count(cols[l],chess_type_all_my[7].ptn.c_str());//列
count3 -= find_count(temp_rl.c_str(),chess_type_all_my[7].ptn.c_str());//左下到右上
count4 -= find_count(temp_lr.c_str(),chess_type_all_my[7].ptn.c_str());//左上到右下
}
if(i==19)
{
count1 -= find_count(rows[r],chess_type_all_my[18].ptn.c_str());
count2 -= find_count(cols[l],chess_type_all_my[18].ptn.c_str());//列
count3 -= find_count(temp_rl.c_str(),chess_type_all_my[18].ptn.c_str());//左下到右上
count4 -= find_count(temp_lr.c_str(),chess_type_all_my[18].ptn.c_str());//左上到右下
}
sum_score+=(count1+count2+count3+count4)*chess_type_all_my[i].my_score;
int count5 = find_count(rows[r],chess_type_all_opt[i].ptn.c_str());//行
int count6 = find_count(cols[l],chess_type_all_opt[i].ptn.c_str());//列
int count7 = find_count(temp_rl.c_str(),chess_type_all_opt[i].ptn.c_str());//左下到右上
if(deep==0&&r==6&&l==5)
{
cout<<count1<<" "<<count2<<" "<<count3<<" "<<count4<<" "<<endl;
}
int count8 = find_count(temp_lr.c_str(),chess_type_all_opt[i].ptn.c_str());//左上到右下
if(i==8)
{
count5 -= find_count(rows[r],chess_type_all_opt[7].ptn.c_str());//行
count6 -= find_count(cols[l],chess_type_all_opt[7].ptn.c_str());//列
count7 -= find_count(temp_rl.c_str(),chess_type_all_opt[7].ptn.c_str());//左下到右上
count8 -= find_count(temp_lr.c_str(),chess_type_all_opt[7].ptn.c_str());//左上到右下
}
if(i==19)
{
count5 -= find_count(rows[r],chess_type_all_opt[18].ptn.c_str());//行
count6 -= find_count(cols[l],chess_type_all_opt[18].ptn.c_str());//列
count7 -= find_count(temp_rl.c_str(),chess_type_all_opt[18].ptn.c_str());//左下到右上
count8 -= find_count(temp_lr.c_str(),chess_type_all_opt[18].ptn.c_str());//左上到右下
}
sum_score-=(count5+count6+count7+count8)*(chess_type_all_my[i].opt_score);
partern_count[i] = count1+count2+count3+count4;
}
int winner = 0;
for(int i=17;i<=23;i++)//如果存在两个以上的两个活三和活四
winner += partern_count[i];
if(winner>1)
sum_score+=3000000;
h_score.push_back(node{r,l,sum_score});
clear_temp_chess(r,l);//注意要回溯
}
待实现的优化方法:
启发式搜索方法改进
能不能在现在得分的基础上加上当前局面的评估函数得分,以此为依据来对要遍历的落子点进行排序。然后只选择最好的前10个节点进行拓展。
当然这种只选择最好的节点拓展的方法非常依赖于启发式函数的正确性,如果这种启发式搜索函数不好的话,只搜索前10个节点可能会丧失最优解,体现在AI上就是下棋变“蠢”了。
使用迭代加深深度优先搜索加速
迭代加深深度优先搜索就是先搜索depth=1的情况,然后搜索depth=2的情况,以此类推。这种方法看似很慢,其实会加速alpha-beta剪枝。因为浅层搜索得到的最优解很有可能是深层搜索下评估函数得分高的点,因此按照浅层节点的得分进行排序来拓展节点,基本上都是有序的,会大大加快alpha-beta剪枝的速度。
GUI界面的编写
开发平台
Qt Creator 4.14.2 (Community)
使用原因:
QT Creator 是一个将c++编辑器以及GUI界面拖拽组件实现集成在一起的一个软件。可以用于快速开发GUI界面。
关于QT的语法以及编辑器的使用实在太多了,无法列举出来,这里给个网址自己看(找了好久的中文文档):
Qt教程,Qt5编程入门教程(非常详细) (biancheng.net)
界面介绍以及具体实现:
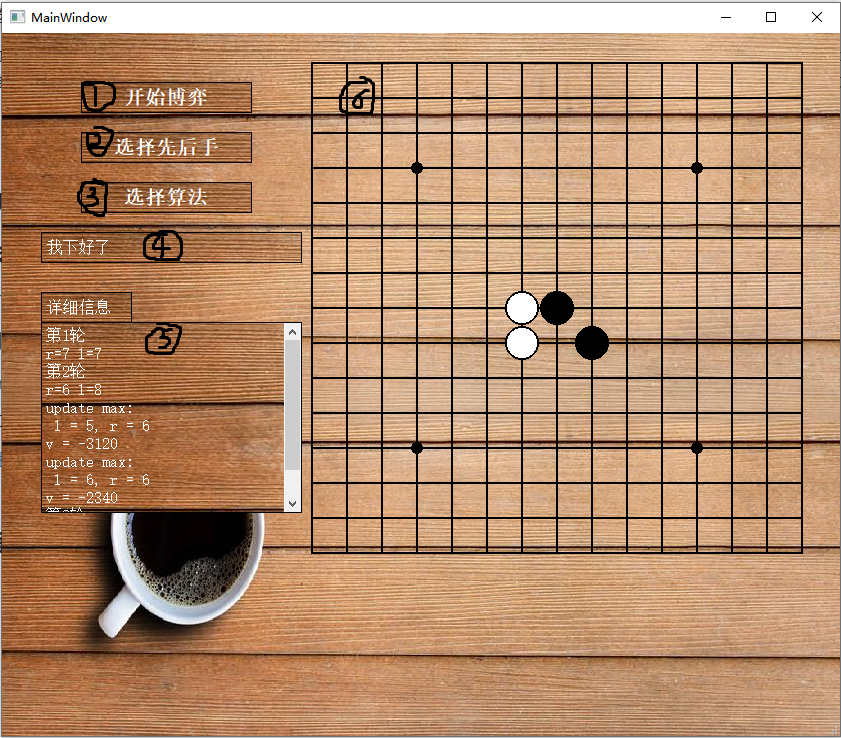
①:QPushButton
点击组件①会让游戏正式开始,如果没有点击②,③设置算法和先后手会默认使用alpha-beta剪枝和先手来进行对局。
使用槽函数和信号,connet方法来连接信号和槽函数。
connect(w.ui->start_bt_2, SIGNAL(clicked()),this , SLOT(on_start_bt_2_clicked()));
②:QPushButton
点击组件②会弹出窗口,其中有两个单选框,两个都是QRadioButton,按确定后会设置先后手
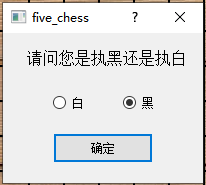
如何展示弹窗?
先定义一个QDialog,点击按钮后,将QDialog resize后,然后定义两个QRadioButton加入到Group当中,最后通过点击button来进行先后手的选择。
void MainWindow::on_start_bt_clicked()
{
who_first.resize(200,150);
tip_who->resize(200,50);
tip_who->setText(" 请问您是执黑还是执白");
tip_who->setStyleSheet("font-size:16px");
firstGroup = new QButtonGroup(&who_first);
firstGroup->addButton(white,0);
firstGroup->addButton(black,1);
black->setText("黑");
white->setText("白");
black->setChecked(1);
white->setGeometry(QRect(50, 60, 30, 20));
black->setGeometry(QRect(120, 60, 30, 20));
who_first.show();
tip_who->show();
white->show();
black->show();
is_ok->setGeometry(QRect(50, 100, 100, 30));
is_ok->setText("确定");
is_ok->show();
connect(is_ok, SIGNAL(clicked()), this, SLOT(on_is_ok_bt_clicked()));
}
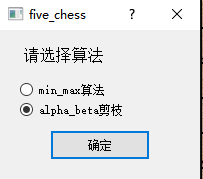
③:QPushButton
点击组件③会弹出窗口,其中有两个单选框,两个都是QRadioButton,按确定后选择算法
弹窗同上。
④:QLabel
对话框,用于显示游戏进行的提示。
使用setText函数来对QLabel的内容

⑤:QTextBrowser
信息框,用于显示搜索的信息。
//为out_tip赋值
w.ui->detail_info->textCursor().insertText(out_tip);

⑥:paintEvent:
棋盘,实时更新数组中的棋子。为了使游戏能顺利进行。
使用paintEvent事件+mousePressEvent事件:
使用paintEvent事件将图片花在背景上,然后画横线和竖线,之后再在特定的五个点画棋盘的标注。
使用mousePressEvent事件检测鼠标是否点击屏幕,触发事件后会返回点击的坐标,根据坐标计算出点击的行列,然后传入棋盘,在指定位置置"A","B"。
使用update()方法可以重新调用paintEvent,实现棋盘的更新。
为了防止搜索过程显示到屏幕上,需要使用一个标志位,no_update,然后每次下棋之前将棋盘情况复制到一个暂存的棋盘当中,no_update=1时一直paint这个暂时的棋盘,然后当no_update=0后paint目前的棋盘。
如何实现多进程
为何需要多线程
因为GUI图形程序一般分为前端显示和后端运算两个部分,如果只使用单个进程的话会导致在后端运算的时候前端界面卡死,因此需要使用多进程来解决这个问题。
实现方法
要开启一个新的进程需要QThread类来实现,但是QThread的run函数是固定好的,因此需要自己定义一个类,这个类继承QThread类,然后重写QThread的run()函数,之后使用start()函数来开启线程,调用run()函数即可。
代码如下
类的定义:
class back_game: public QThread
{
Q_OBJECT
public:
MainWindow w;
private slots:
void on_play_begin_bt_clicked();
void on_start_bt_2_clicked();
void on_start_ag_clicked();
void on_is_ok_bt1_clicked();
protected:
void run(); // 新线程入口
// 省略掉一些内容
};
#endif // MAINWINDOW_H
main函数中的调用:
int main(int argc, char *argv[])
{
QApplication a(argc, argv);
back_game game;
game.w.is_press=0;
game.w.show();
game.start();
// return a.exec();
return a.exec();
}
将所有的游戏流程都放在run()函数当中了。
信号与槽函数如何使用:
使用connect函数来链接信号和槽函数,
connect(sender, SIGNAL(event()), receiver, SLOT(function()));
sender:信号的发送者,如果为按钮,点击后就会发送clicked()信号
receiver: 信号的接受者,如果单纯只是想使用某一个函数而不改变组件的话,可以使用this,this指的是function所在的类。
SIGNAL(event()):发送的信号,不同组件不同
function():槽函数,注意,槽函数一定要定义在private:slot这样声明为私有槽函数的私有成员当中。不然没有用。
遇到点击事件但是没有响应怎么办:
考虑以下五种情况:
1、看看你的类声明中有没有Q_OBJECT,没有加上(并检查是否已经包含#include<QtCore/QObject>头文件)
2、你声明的函数要加声明:
private slots:
3、检查槽函数名拼写是否有误
4、确认对应的signal和slot的参数是否一致
5、如果还不行的话,清理项目,删掉原有的moc_xxx.cpp,重新执行qmake.
如果上述情况还是不行的话,可能是因为多进程,而其中的一个进程占用了cpu内的所有时间,因此需要在当前的死循环内加上一个msleep(1),该线程休息1ms,为信号的接受提供CPU时间。
while(1)
{
·····
msleep(1);
}
总结:
通过本次实验,我受益匪浅,先列举如下:
- 熟悉如何使用min-max以及alpha-beta剪枝来解决一个博弈问题
- 了解了许多能加速alpha-beta剪枝的方法,并且自己实现了两个
- 学会了如何构造评估函数并且实现,如何对评估函数进行调优
- 学会使用了QT create开发平台,了解了如何使用拖拽组件的方法快速制作GUI
- 初步了解了QT多线程的使用方法,解决了进程之间竞争CPU时间的问题
- 发现并解决了为何槽函数无法使用的问题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号