
利用豆瓣爬虫构建推理小说关键字推荐器
原理
图书条目
利用爬虫爬取豆瓣图书信息,书名、作者、出版社、评分等
区分推理小说
利用相关推荐的栏目来爬取,大概率都是推理小说
要是爬出范围就手动调节一下,删除一些url

关键字功能
批量爬取豆瓣短评,利用jieba.analyse提取关键词
https://blog.csdn.net/qq_40082282/article/details/103433612
数据存储和提取
利用openpyxl库操作excel文档


注意事项
访问豆瓣太快会寄,不过访问太多次也会寄
ua伪装试过了fake_useragent,但是爬过一次后就会封ip
最好的办法是ip池
代码
方法
预备爬取的url(区分中文、日文、英文和其他,优先中文)
爬取下来的新url添加到列表末尾
旧url,防止重复爬取
关键词
爬取小说信息,保存到excel
点击查看代码
import json
import os
import time
import requests
from lxml import etree
import langid
import jieba
import jieba.analyse
from fake_useragent import UserAgent
from openpyxl import Workbook,load_workbook
ua = UserAgent(verify_ssl=False)
headers = {
'User-Agent': ua.random,
'cookie':'douban-fav-remind=1; gr_user_id=e832d640-c944-4401-b1a2-2efadf79ddaa; _ga=GA1.1.1276967334.1627091677; _ga_RXNMP372GL=GS1.1.1654269332.4.0.1654269333.59; ll="118172"; bid=wwjHsuJYL6k; __yadk_uid=cEprKpCD1gZ0jxfk1TCNFOPJGzzlAnin; push_doumail_num=0; __utmv=30149280.18994; __gads=ID=173333fa14a865d1-22fa508a93d700da:T=1667015292:RT=1667015292:S=ALNI_MaCmcMf3x03yQfiiGW6gmaIE0MW1g; dbcl2="189943544:g1Hv1KN49uE"; push_noty_num=0; __utmz=30149280.1667573191.139.28.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; ct=y; ck=C2Dq; __utmc=30149280; __gpi=UID=000005a0402014ab:T=1653180716:RT=1667724069:S=ALNI_MbMuOQ-3iaHjVTQc-aYkptamx2ceQ; ap_v=0,6.0; _pk_ref.100001.8cb4=%5B%22%22%2C%22%22%2C1667736951%2C%22https%3A%2F%2Faccounts.douban.com%2F%22%5D; _pk_ses.100001.8cb4=*; __utma=30149280.1276967334.1627091677.1667724062.1667736951.145; gr_session_id_22c937bbd8ebd703f2d8e9445f7dfd03=35b03e36-a3a9-4877-9bac-e07df2271deb; gr_cs1_35b03e36-a3a9-4877-9bac-e07df2271deb=user_id%3A1; gr_session_id_22c937bbd8ebd703f2d8e9445f7dfd03_35b03e36-a3a9-4877-9bac-e07df2271deb=true; __utmt_douban=1; _pk_id.100001.8cb4=bb090c4f79dc080f.1627091669.145.1667737571.1667734816.; __utmt=1; __utmb=30149280.15.10.1667736951'
}
proxy={
# "http":"223.96.90.216:8118",
# "https":"223.96.90.216:8118"
}
session=requests.session()
def get_book(url):
global headers
headers['User-Agent']=ua.random
html= session.get(url,headers=headers,proxies=proxy).text
time.sleep(0.1)
html=etree.HTML(html)
new_names=''.join(html.xpath('//*[@id="db-rec-section"]/div//text()'))
new_names=new_names.replace(' ','').split('\n')
while '' in new_names:
new_names.remove('')
new_urls=html.xpath('//*[@id="db-rec-section"]/div/dl/dt/a/@href')
sort_new(new_names,new_urls)
name=html.xpath('//*[@id="wrapper"]/h1/span/text()')[0]
txt=html.xpath('//*[@id="info"]')[0].xpath('string(.)').strip()
txt=txt.replace(' ','').split('\n')
while "" in txt:
txt.remove("")
book_infos=[name]
info_list=['作者','出版社','出版年','页数','定价','装帧','ISBN']
for info in info_list:
for word in txt:
if info in word:
info_word=word.split(':')[1]
if info_word in ['', ' ']:
info_word=txt[txt.index(word)+1]
if info_word[-1]==']':
info_word+=txt[txt.index(word)+2]
break
else:
info_word=''
book_infos.append(info_word)
try:
score=html.xpath('//*[@id="interest_sectl"]/div[1]/div[2]/strong/text()')[0]
score_num=html.xpath('//*[@id="interest_sectl"]/div[1]/div[2]/div/div[2]/span/a/span/text()')[0]
except:
score='无'
score_num=''
try:
keywords=get_keywords(url)
except:
keywords='无评论'
try:
img=html.xpath('//*[@id="mainpic"]/a/img/@src')[0]
except:
img='无封面'
book_infos+=[score,score_num,keywords,img]
print(book_infos)
make_excel(book_infos)
def sort_new(new_names,new_urls):
global book_list
for name_url in zip(new_names,new_urls):
lineTuple = langid.classify(name_url[0])
if lineTuple[0] == "zh":
book_list_zh.append(name_url[-1])
elif lineTuple[0] == "ja":
book_list_ja.append(name_url[-1])
elif lineTuple[0] == "en":
book_list_en.append(name_url[-1])
else:
book_list_ot.append(name_url[-1])
def get_keywords(url):
comments=''
for i in range(10):
comment_url = f'{url}comments/?start={i*20}&limit=20&status=P&sort=score'
global headers
headers['User-Agent']=ua.random
html= session.get(comment_url,headers=headers,proxies=proxy).text
time.sleep(0.05)
html=etree.HTML(html)
comments+=','.join(html.xpath('//*[@id="comments"]/div[1]/ul/li/div[2]/p/span/text()'))
jieba.load_userdict("Python/实战项目/爬虫推理小说推荐器/word_dict.txt")
return ','.join(jieba.analyse.extract_tags(comments))
def make_excel(book_infos):
path='Python/实战项目/爬虫推理小说推荐器/推理小说信息收集.xlsx'
if not os.path.exists(path):
wb=Workbook()
sheet=wb.active
sheet.append(['书名','作者','出版社','出版年','页数','定价','装帧','ISBN','评分','评分人数','评论关键词','封面'])
wb.save(path)
wb = load_workbook(path)
sheet=wb.active
sheet.append(book_infos)
wb.save(path)
if __name__=='__main__':
with open('Python/实战项目/爬虫推理小说推荐器/old_urls.txt','r') as f:
old_urls=json.load(f)
with open('Python/实战项目/爬虫推理小说推荐器/book_list_zh.txt','r') as f:
book_list_zh=json.load(f)
with open('Python/实战项目/爬虫推理小说推荐器/book_list_ja.txt','r') as f:
book_list_ja=json.load(f)
with open('Python/实战项目/爬虫推理小说推荐器/book_list_en.txt','r') as f:
book_list_en=json.load(f)
with open('Python/实战项目/爬虫推理小说推荐器/book_list_ot.txt','r') as f:
book_list_ot=json.load(f)
book_list=book_list_zh+book_list_ja+book_list_en+book_list_ot
count=0
while book_list:
url=book_list_ja[0]
if url in old_urls:
del book_list_ja[0]
count+=1
continue
print(count)
get_book(url)
old_urls.append(url)
with open('Python/实战项目/爬虫推理小说推荐器/old_urls.txt','w') as f:
json.dump(old_urls,f)
del book_list_zh[0]
if book_list_zh:
with open('Python/实战项目/爬虫推理小说推荐器/book_list_zh.txt','w') as f:
json.dump(book_list_zh,f)
if book_list_ja:
with open('Python/实战项目/爬虫推理小说推荐器/book_list_ja.txt','w') as f:
json.dump(book_list_ja,f)
if book_list_en:
with open('Python/实战项目/爬虫推理小说推荐器/book_list_en.txt','w') as f:
json.dump(book_list_en,f)
if book_list_ot:
with open('Python/实战项目/爬虫推理小说推荐器/book_list_ot.txt','w') as f:
json.dump(book_list_ot,f)
制作ui界面
点击查看代码
import random
import jieba
import zhconv
import tkinter as tk
from tkinter import messagebox
from openpyxl import load_workbook
wb = load_workbook('Python/实战项目/爬虫推理小说推荐器/推理小说信息收集.xlsx')
ws = wb.active
results={}
def find_by_name(key,count):
global results
count+=1
if count>10:
return
for index,cell in enumerate(ws["A"]):
try:
if key in zhconv.convert(cell.value,'zh-hans'):
results[index]=[each[index].value for each in ws.iter_cols()]
except:
pass
if len(results)<=10:
keys=jieba.cut(key)
for key in keys:
find_by_name(key,count)
def find_by_author(key,count):
global results
count+=1
if count>10:
return
for index,cell in enumerate(ws["B"]):
try:
if key in zhconv.convert(cell.value,'zh-hans'):
results[index]=[each[index].value for each in ws.iter_cols()]
except:
pass
if len(results)<=10:
keys=jieba.cut(key)
for key in keys:
find_by_author(key,count)
def find_by_keyword(key,count):
global results
count+=1
if count>10:
return
for index,cell in enumerate(ws["K"]):
try:
if key in zhconv.convert(cell.value,'zh-hans'):
results[index]=[each[index].value for each in ws.iter_cols()]
except:
pass
if len(results)<=10:
keys=jieba.cut(key)
for key in keys:
find_by_keyword(key,count)
def search():
global results
results={}
if int(ch1.get()):
print("书名搜索")
find_by_name(var.get(),0)
if int(ch2.get()):
print("作者搜索")
find_by_author(var.get(),0)
if int(ch3.get()):
print("关键字搜索")
find_by_keyword(var.get(),0)
if not int(ch1.get()) and not int(ch2.get()) and not int(ch3.get()):
find_by_name(var.get(),0)
find_by_author(var.get(),0)
find_by_keyword(var.get(),0)
if not results:
messagebox.showerror(title="未找到",message=f"未找到{var.get()}相关内容")
global book_list
book_list=[]
while len(book_list) <10:
index=random.choice(list(results))
book=results[index]
if book not in book_list:
book_list.append(book)
lab=tk.Label(root,text="***以下是搜索结果***",font=('kaiti',16))
lab.grid(row=2,column=0,columnspan=7)
show(book_list)
def random_choice():
global book_list
book_list=[]
while len(book_list) != 10:
index=random.randint(1,ws.max_row)
book = [each[index].value for each in ws.iter_cols()]
if book not in book_list:
book_list.append(book)
lab=tk.Label(root,text="***猜你喜欢***",font=('kaiti',16))
lab.grid(row=2,column=0,columnspan=7)
show(book_list)
def show(book_list):
lab=tk.Label(root,width=20,text="书名",font=('heiti',12))
lab.grid(row=3,column=0)
lab=tk.Label(root,width=15,text="作者",font=('heiti',12))
lab.grid(row=3,column=1)
lab=tk.Label(root,width=15,text="出版社",font=('heiti',12))
lab.grid(row=3,column=2)
lab=tk.Label(root,width=10,text="出版时间",font=('heiti',12))
lab.grid(row=3,column=3)
lab=tk.Label(root,width=5,text="评分",font=('heiti',12))
lab.grid(row=3,column=4)
lab=tk.Label(root,width=8,text="评分人数",font=('heiti',12))
lab.grid(row=3,column=5)
lab=tk.Label(root,width=10,text="ISBN",font=('heiti',12))
lab.grid(row=3,column=6)
for i,info in enumerate(book_list):
lab=tk.Label(root,width=20,text=info[0],anchor='w',font=('songti',12))
lab.grid(row=4+i,column=0)
lab=tk.Label(root,width=15,text=info[1],anchor='w',font=('songti',12))
lab.grid(row=4+i,column=1)
lab=tk.Label(root,width=15,text=info[2],anchor='w',font=('songti',12))
lab.grid(row=4+i,column=2)
lab=tk.Label(root,width=10,text=info[3],anchor='w',font=('songti',12))
lab.grid(row=4+i,column=3)
lab=tk.Label(root,width=5,text=info[8],font=('songti',12))
lab.grid(row=4+i,column=4)
lab=tk.Label(root,width=8,text=info[9],font=('songti',12))
lab.grid(row=4+i,column=5)
lab=tk.Label(root,width=10,text=info[7],font=('songti',12))
lab.grid(row=4+i,column=6)
# if info[10] is None:
# btn=tk.Button(root,width=10,text="无封面",font=('songti',12))
# else:
# btn=tk.Button(root,width=10,text="看封面",font=('songti',12),command=lambda x=song:play_song(x))
# btn.grid(row=4+i,column=3)
root=tk.Tk()
root.title("推理小说推荐器")
root.iconphoto(True, tk.PhotoImage(file='Python/实战项目/爱心/love.png'))
var=tk.StringVar()
var.set('')
lab=tk.Label(root,width=45,text="*****粗制滥造推理小说推荐器!请随意输入:*****",font=('songti',12))
lab.grid(row=0,column=0,columnspan=4)
ent=tk.Entry(root,width=10,textvariable=var,font=('kaiti',14))
ent.grid(row=0,column=4,columnspan=2)
btn=tk.Button(root,width=10,text="搜索",font=('heiti',10),command=search)
btn.grid(row=0,column=6)
book_list=[]
random_choice()
btn_random=tk.Button(root,width=10,text="随机推荐",font=('heiti',10),command=random_choice)
btn_random.grid(row=1,column=6)
l=tk.Label(root,text="请选择搜索选项:",font=('songti',10))
l.grid(row=1,column=0)
ch1=tk.IntVar()
ch_continue=tk.Checkbutton(root,text="书名",font=('heiti',10),variable=ch1,onvalue=1,offvalue=0)
ch_continue.grid(row=1,column=1)
ch2=tk.IntVar()
ch_continue=tk.Checkbutton(root,text="作者",font=('heiti',10),variable=ch2,onvalue=1,offvalue=0)
ch_continue.grid(row=1,column=2)
ch3=tk.IntVar()
ch_continue=tk.Checkbutton(root,text="关键字",font=('heiti',10),variable=ch3,onvalue=1,offvalue=0)
ch_continue.grid(row=1,column=3)
root.mainloop()
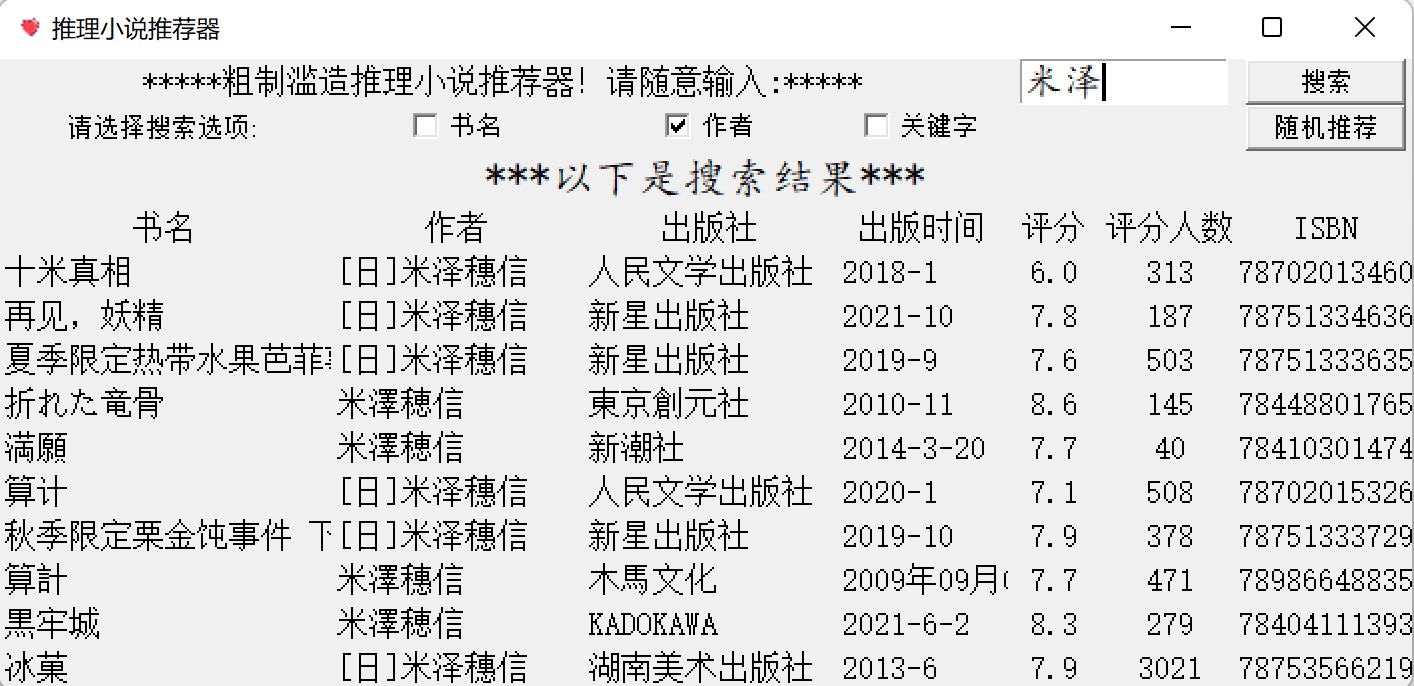
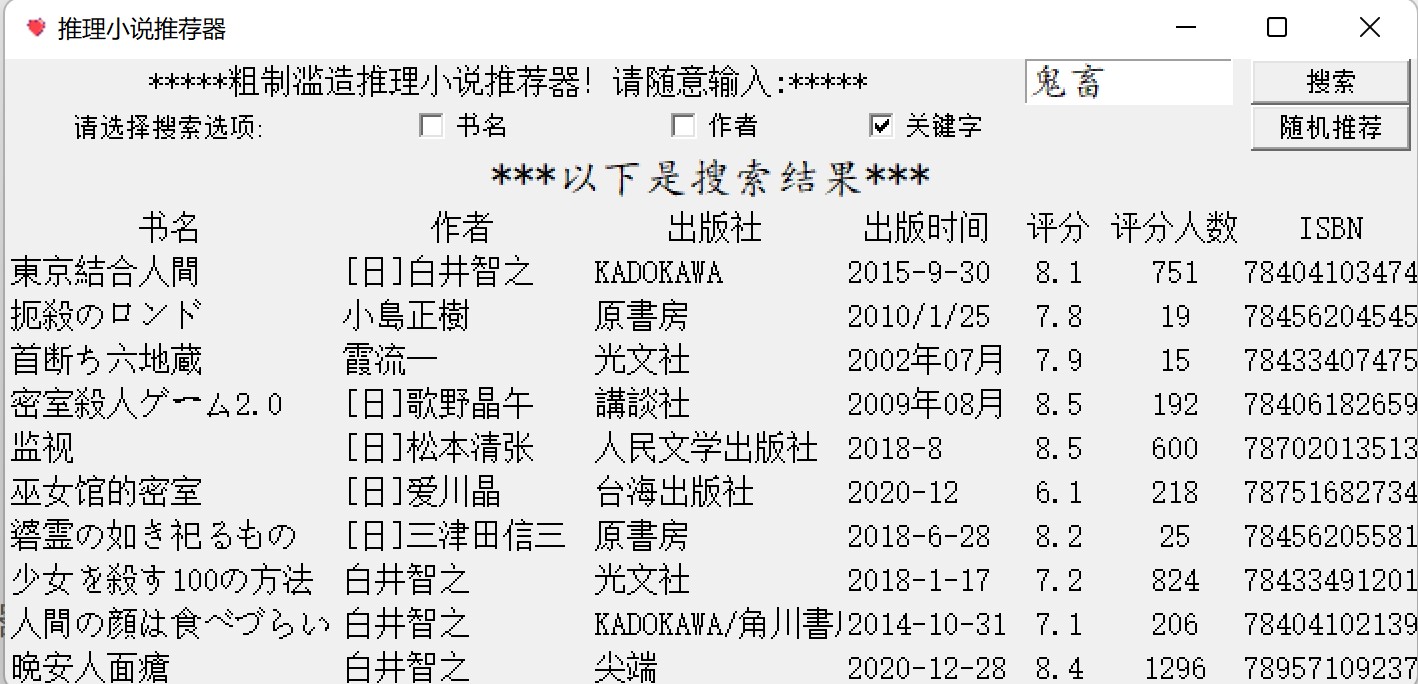
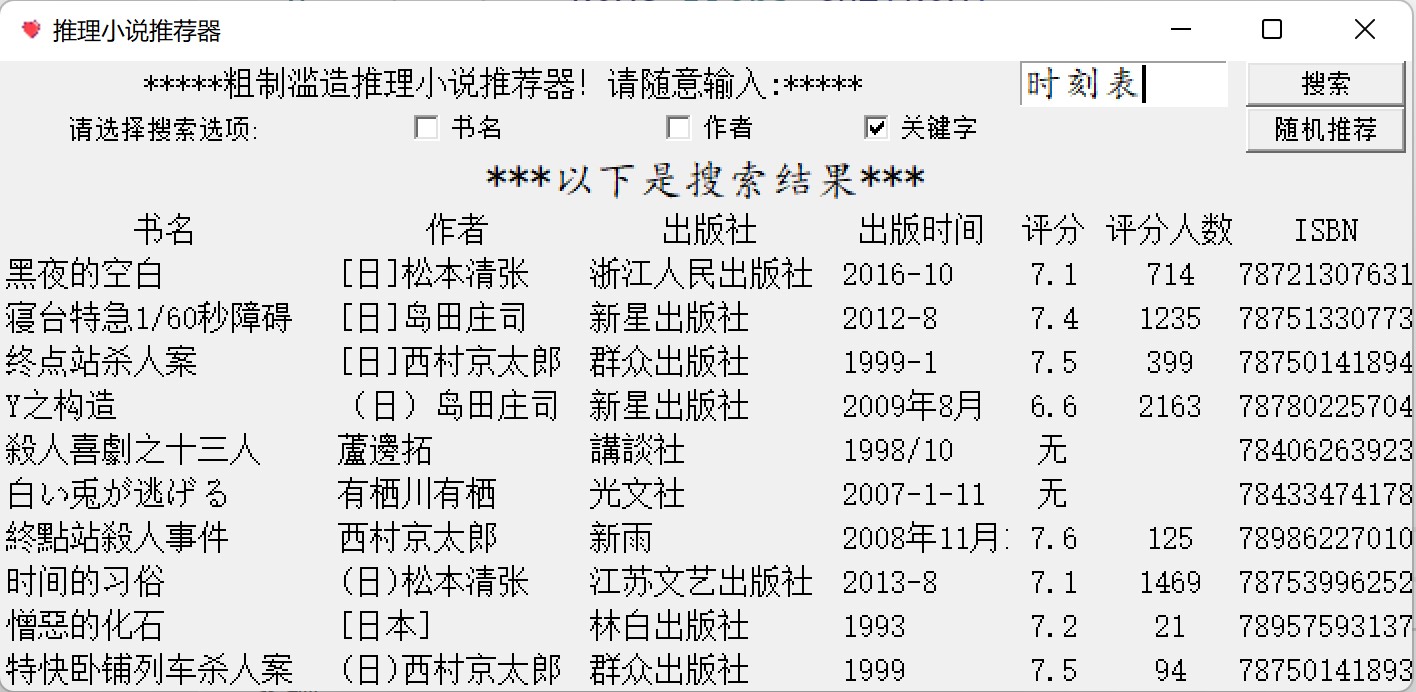
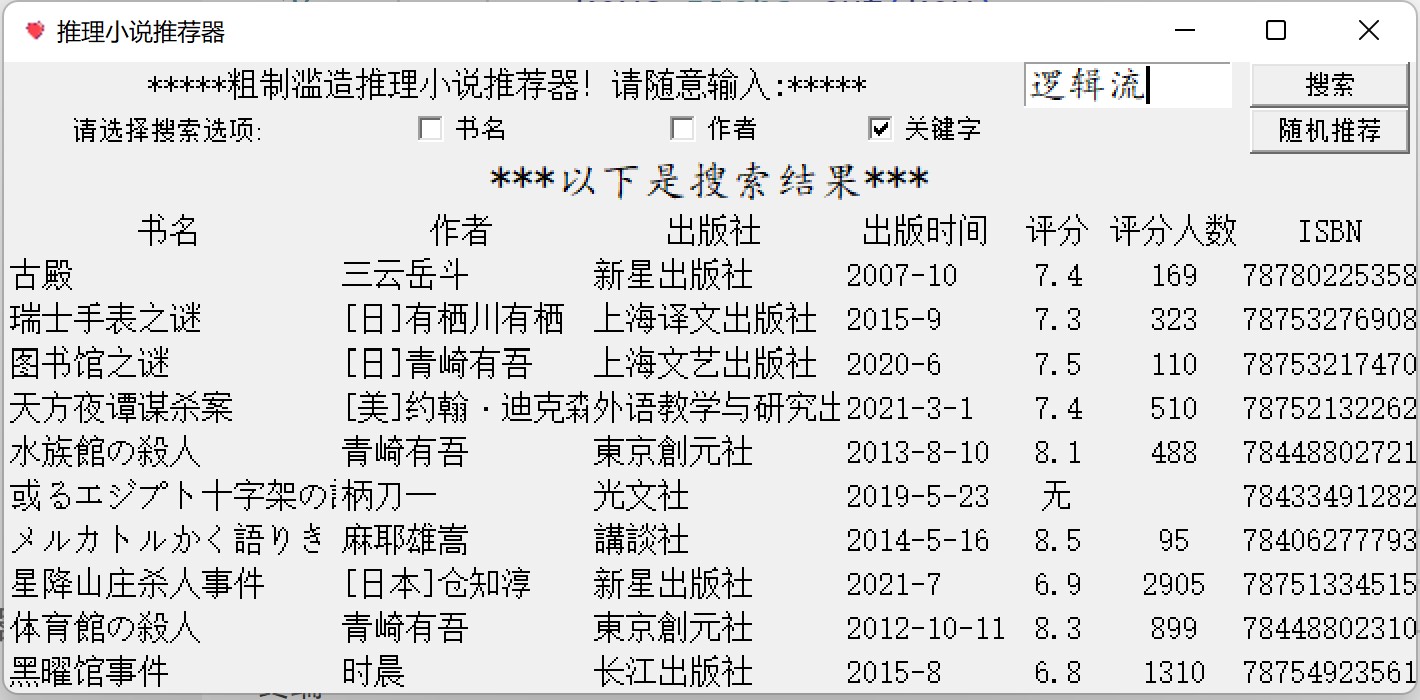
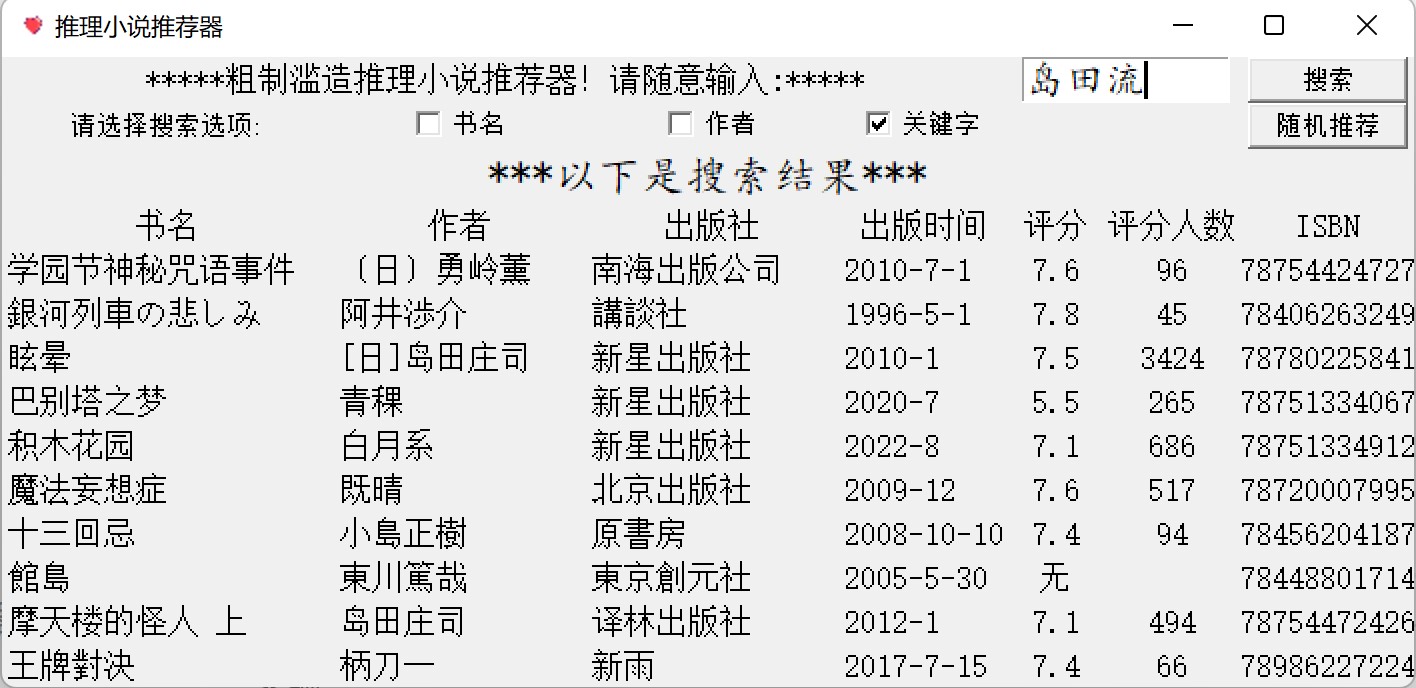
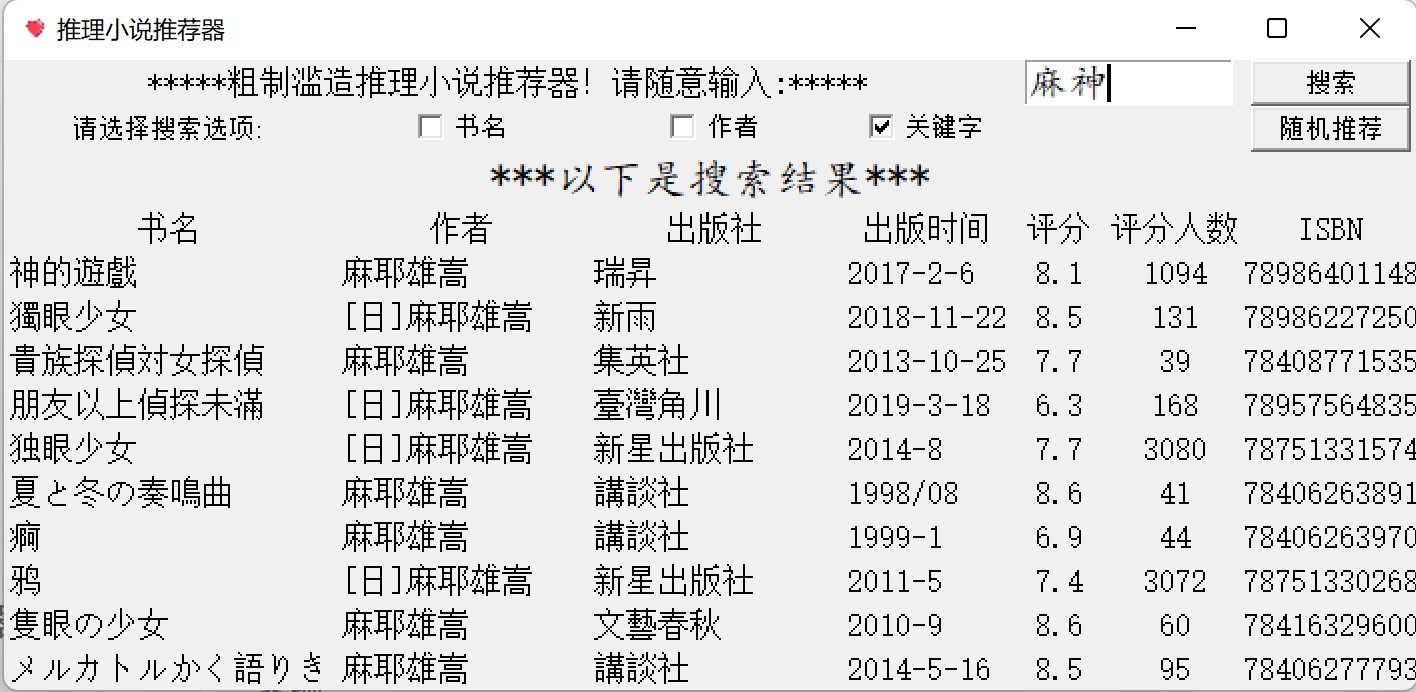
完成效果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号