

缓存设计——缓存和数据库的数据一致性
缓存设计的误区
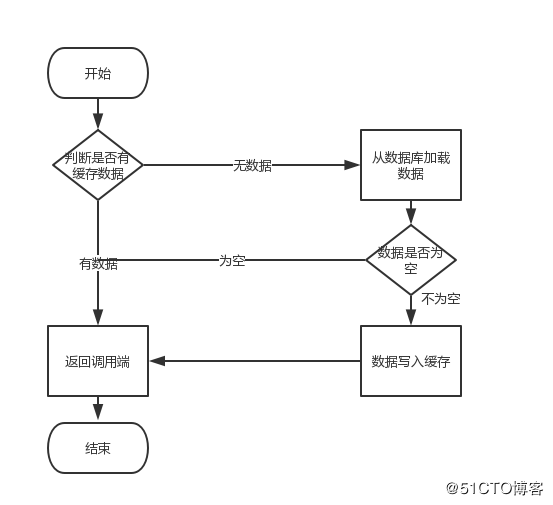
我们通常是这样设计的,应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
那试想一下,如果取出来的null,需不需要放入cache呢?答案当然是需要的。
我们试想一下如果取出为null不放入cache会有什么结果?很显然每次取cache没有走db返回null,很容易让攻击者利用这个漏洞搞垮你的服务器,利用洪水攻击让你的程序夯在这个地方导致你的正常流程抢不到资源。
数据库和缓存双写一致性方案解析
在读取缓存方面,大家没啥疑问,都是按照下图的流程来进行业务操作。
但是在更新缓存方面,有以下几种策略:
- 先更新数据库,再更新缓存
- 先删除缓存,再更新数据库
- 先更新数据库,再删除缓存
一般现在采用的是先更新数据库,再删除缓存。
这有篇写的极好的博客可好好学习:分布式之数据库和缓存双写一致性方案解析
现将主要内容摘录如下:
(1)先更新数据库,再更新缓存
这套方案,大家是普遍反对的。为什么呢?有如下两点原因。
原因一(线程安全角度
同时有请求A和请求B进行更新操作,那么会出现
(1)线程A更新了数据库
(2)线程B更新了数据库
(3)线程B更新了缓存
(4)线程A更新了缓存
这就出现请求A更新缓存应该比请求B更新缓存早才对,但是因为网络等原因,B却比A更早更新了缓存。可能在DB和memcached中具有相同数据项的不同值。这就导致了脏数据,因此不考虑。
原因二(业务场景角度)
有如下两点:
(1)如果你是一个写数据库场景比较多,而读数据场景比较少的业务需求,采用这种方案就会导致,数据压根还没读到,缓存就被频繁的更新,浪费性能。
(2)如果你写入数据库的值,并不是直接写入缓存的,而是要经过一系列复杂的计算再写入缓存。那么,每次写入数据库后,都再次计算写入缓存的值,无疑是浪费性能的。显然,删除缓存更为适合。
(2)先删缓存,再更新数据库
该方案会导致不一致的原因是。同时有一个请求A进行更新操作,另一个请求B进行查询操作。那么会出现如下情形:
(1)请求A进行写操作,删除缓存
(2)请求B查询发现缓存不存在
(3)请求B去数据库查询得到旧值
(4)请求B将旧值写入缓存
(5)请求A将新值写入数据库
(3)先更新数据库,再删缓存
首先,先说一下。老外提出了一个缓存更新套路,名为《Cache-Aside pattern》。其中就指出
失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
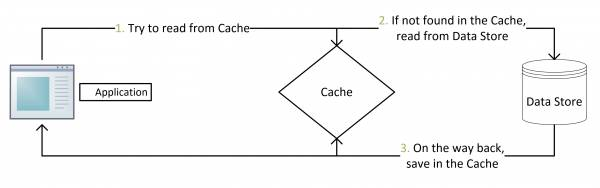
命中:应用程序从cache中取数据,取到后返回
更新:先把数据存到数据库中,成功后,再让缓存失效。
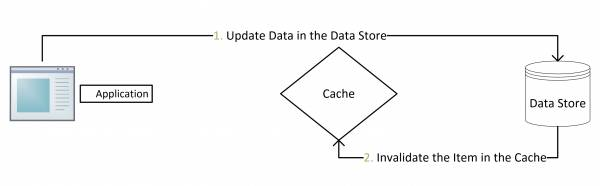
另外,知名社交网站facebook也在论文《Scaling Memcache at Facebook》中提出,他们用的也是先更新数据库,再删缓存的策略。
这种情况不存在并发问题么?
不是的。假设这会有两个请求,一个请求A做查询操作,一个请求B做更新操作,那么会有如下情形产生
(1)缓存刚好失效
(2)请求A查询数据库,得一个旧值
(3)请求B将新值写入数据库
(4)请求B删除缓存
(5)请求A将查到的旧值写入缓存
ok,如果发生上述情况,确实是会发生脏数据。
然而,发生这种情况的概率又有多少呢?
发生上述情况有一个先天性条件,就是步骤(3)的写数据库操作比步骤(2)的读数据库操作耗时更短,才有可能使得步骤(4)先于步骤(5)。可是,大家想想,数据库的读操作的速度远快于写操作的(不然做读写分离干嘛,做读写分离的意义就是因为读操作比较快,耗资源少),因此步骤(3)耗时比步骤(2)更短,这一情形很难出现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号