DS博客作业03-树
0.PTA得分截图

1.本周学习总结
串的匹配算法
BF算法
- 思路
这种算法是我们最容易的算法,是一种暴力算法。主串中从第一个开始一个一个和子串中的字符匹配,如果遇到不匹配的,主串再从第二个字符开始和子串中第一个字符开始匹配;直到子串遍历完或者主串遍历完才结束;
while (子串t还未遍历完||主串s还未遍历完)
if(s[i] == t[j])
继续遍历子串和主串的下一字符;
else 发现不匹配
主串s回到和子串t匹配的第二个字符位置;
子串t回到第一个位置;
end if
end while
if 子串遍历完毕
说明找到子串在主串中所在的位置,返回下标;
else
说明子串不在主串中,匹配不成功;
- 代码实现

- 分析
- 时间复杂度O(m*n):最坏的情况是全部都不匹配,且子串中每个字符都遍历了m遍(主串长度为m,子串长度为n);
- 空间复杂度O(1):没有再开辟新的空间;
- 在不匹配时主串需要回溯
i=i-j+1,重新开始匹配,效率较低,如果遇到字符串长度较大的,这种方法并不是最好的。
KMP算法
- 思路:
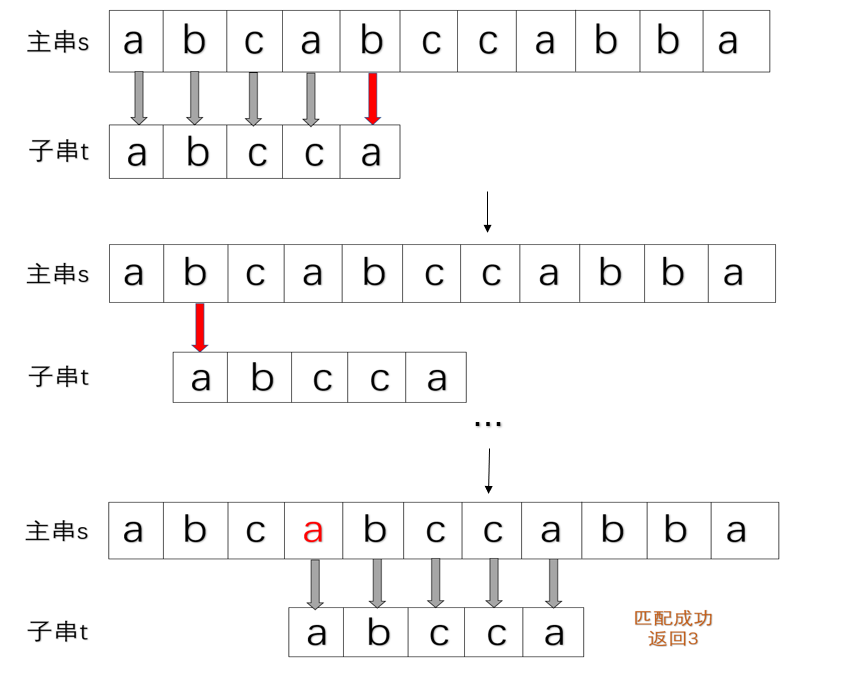
在BF算法中,如果我们遇到不匹配的字符,子串中匹配的位置就要重新回到第一个位置0,主串也回到和子串中第二个匹配的位置继续匹配,接着主串中之前和子串匹配的片段又重新和子串前面片段匹配成功了,如下图情形:
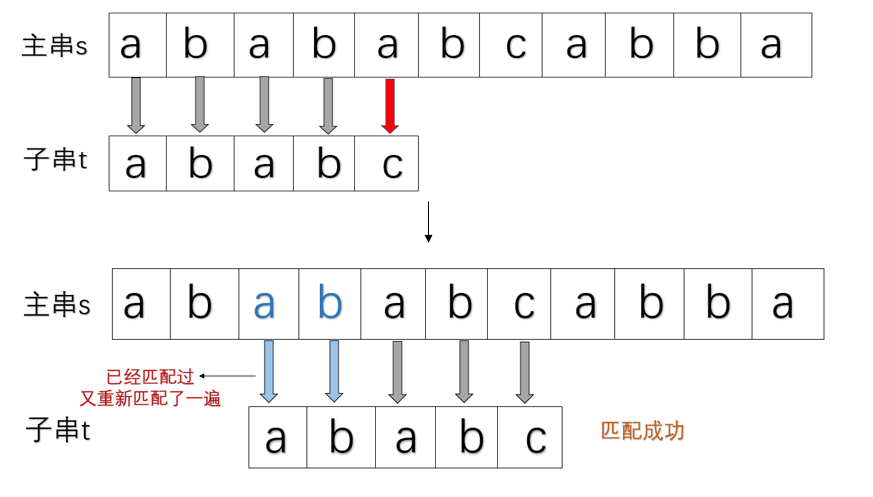
这样重新再匹配就多耗费了一定的时间,于是为了减少时间复杂度,我们希望如果可以跳过已经匹配的片段,主串不用回溯指针,继续往下匹配,如下:
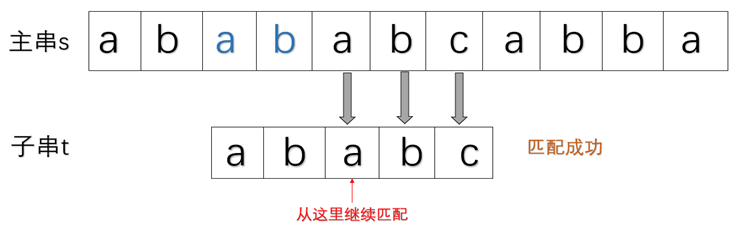
所以我们引进了新的算法KMP,借助next/nextval数组,在遇到失配的字符时,可以减少子串的左移的距离,且主串不用回溯指针。
定义数组next/nextval来保存子串中每个字符失配时要返回的上一位置;
while(i<size()&&j<t.size())
if(子串t重新遍历到起始位置||t[j]==s[i])
子串和主串都继续遍历下一字符;
else //失配情况
子串指针j根据数组next/nextval[j]回到上一匹配位置,但是主串指针i不回溯;
end if
end while
if(j>=t.size())
说明找到子串,返回其位置;
else
说没有找到子串,返回-1表示不匹配;
end if
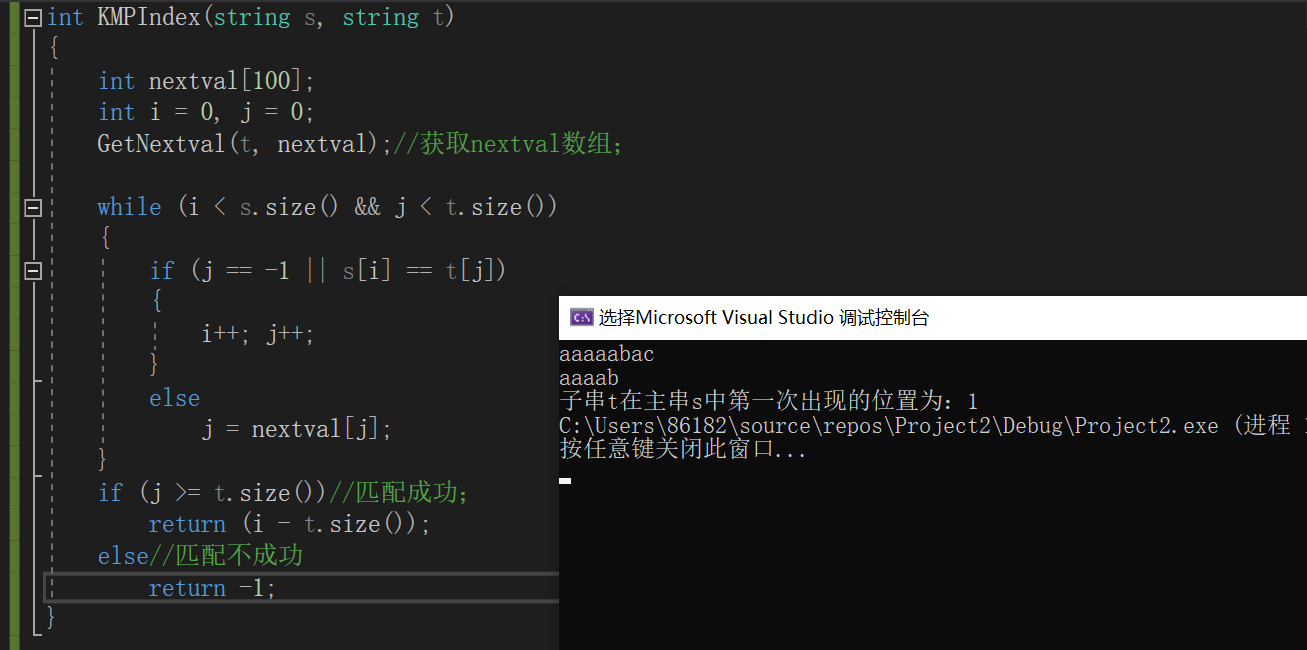
代码实现
-
构造next数组
在遇到不匹配的字符时,为了减少子串左移的距离,开发了next数组用于保存子串中每个字符在失配时,离当前字符位置最近的下一可匹配位置,构造的依据为:子串中处于下标为j的字符前面某段字符串(j-k——j-1)和从位置为0开始的某段字符串(0——k)所能匹配:t[0] t[1] ··· t[k-1] = t[j-k] t[j-k+1] ··· t[j-1]的公共长度k就为next[j]的值;

代码实现
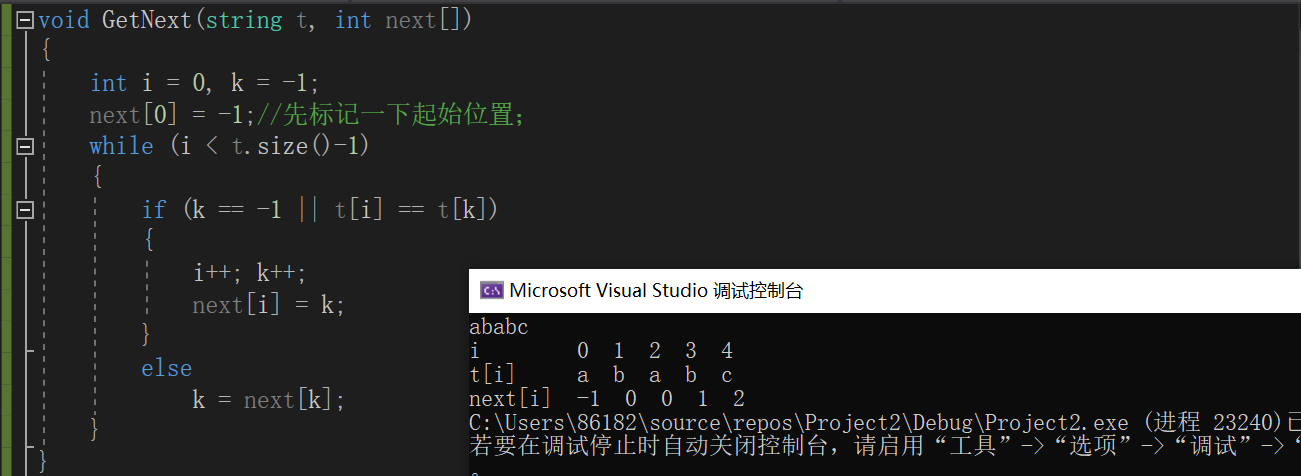
-
构造nextval数组
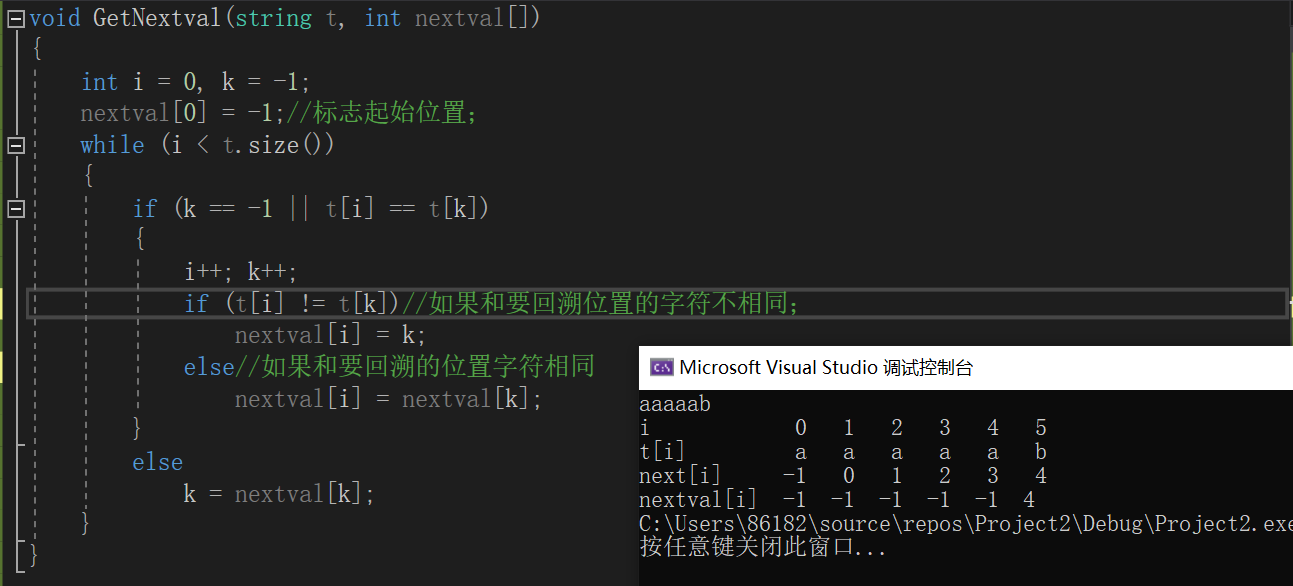
我们在构造next数组的时候又发现了一个问题,如果我们遇到子串开头有多个重复的片段,如t= "aaaaab"时,我们得到的该串的next数组为:
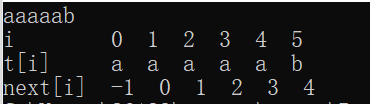
如果在寻找过程中遇到不匹配的,按照next[j]的值回到上一匹配位置后,还是和相同的字符相互比较,还是有些浪费时间。
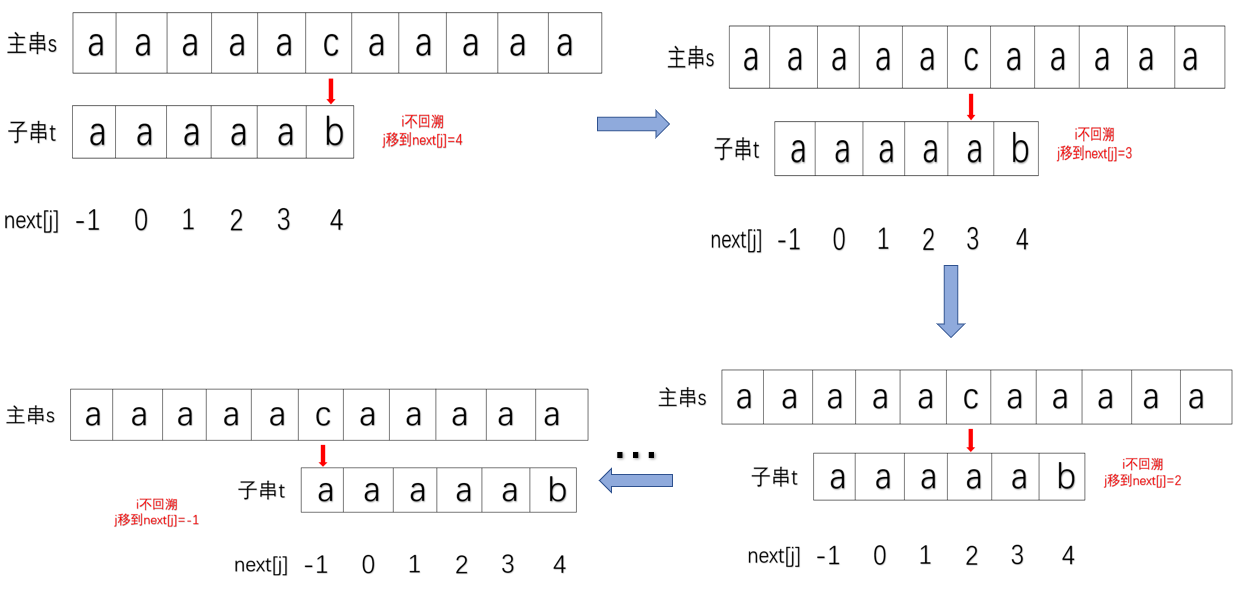
于是我们希望在前面字符如果都相同时,遇到失配情况,直接一步移到不相同字符的位置上去:
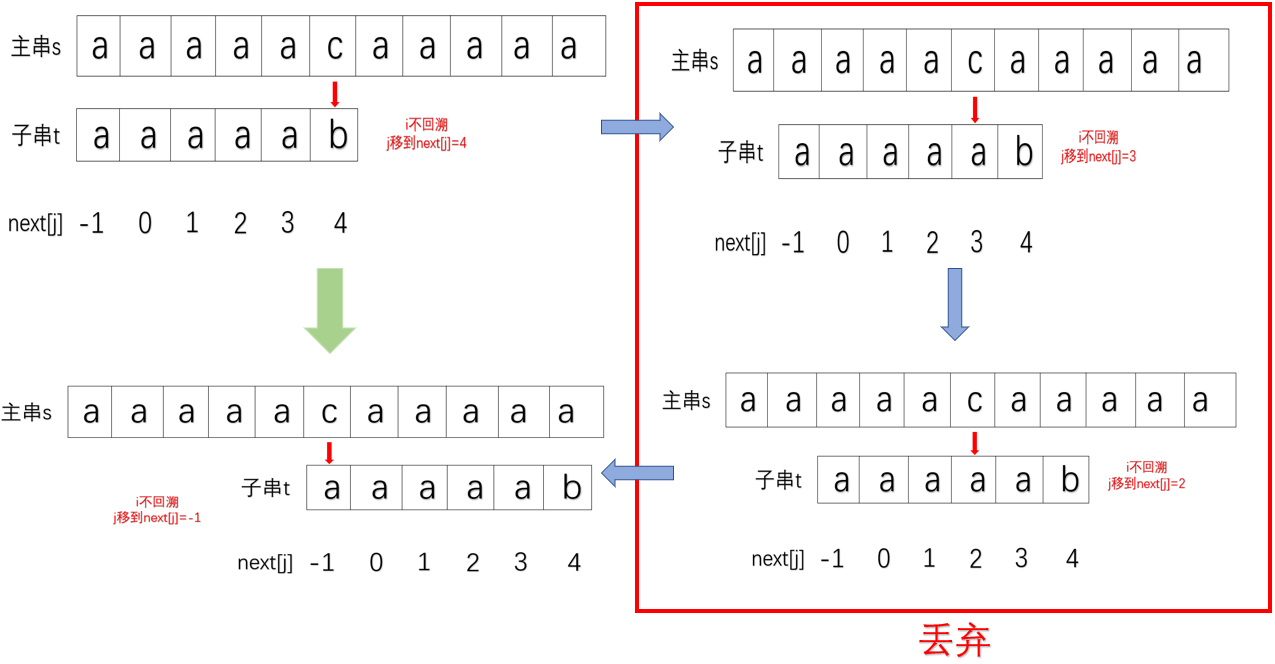
所以对next数组进行改进,得到了nextval数组。
代码实现
string中的查找函数
目标串:string s
需要寻找的字符串:string str
位置: int position;
-
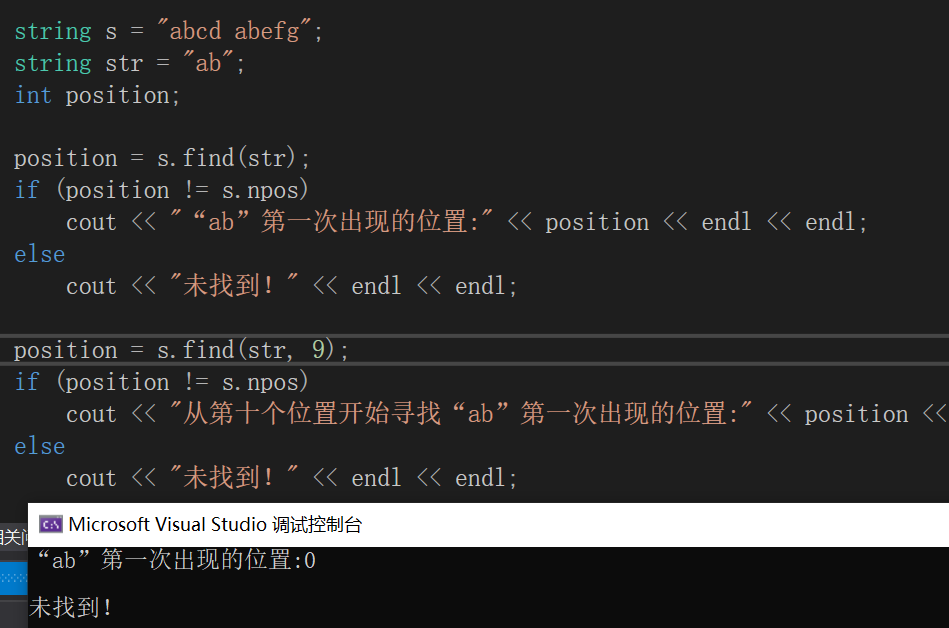
s.find(str,position):find()函数中吸收的两个形参:str是需要在s中寻找的字符串,position表示的是要从目标串s中的哪一个位置开始寻找。position也可不写,默认从第一个位置开始寻找。若没有找到相匹配的内容则函数返回npos。(npos是c++中一个特殊的值)。
-
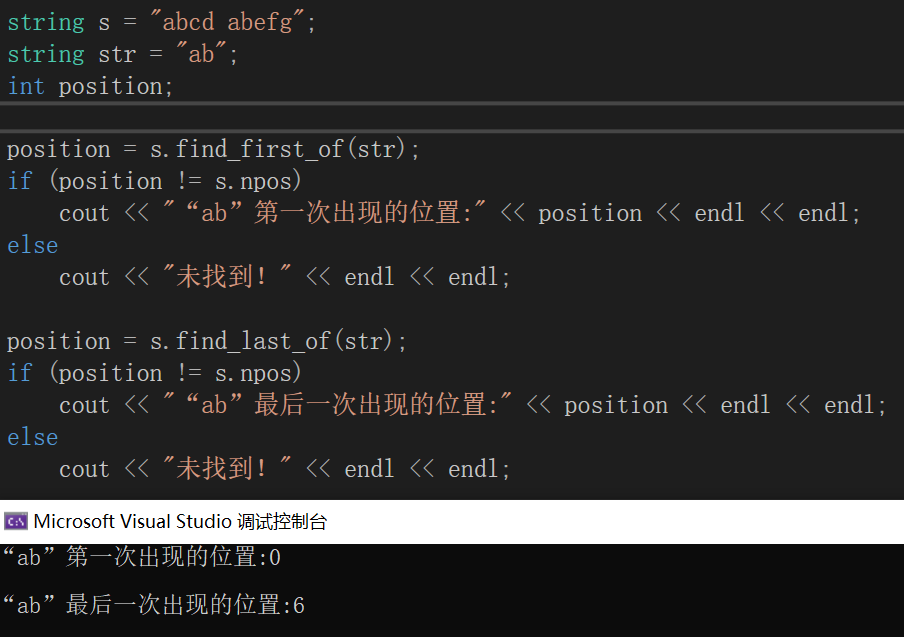
s.find_first_of(str) :在s中查找第一次出现的str,如果找到返回的是str在s中的首地址,如果没有找到则返回npos;
s.find_last_of(str) :在s中查找最后一次出现的str,如果找到返回的是str最后一个字符在s中的位置,如果没有找到则返回npos。
3.s.rfind(str):在s中反向寻找str,如果找到则返回str所在位置,找不到则返回npos;

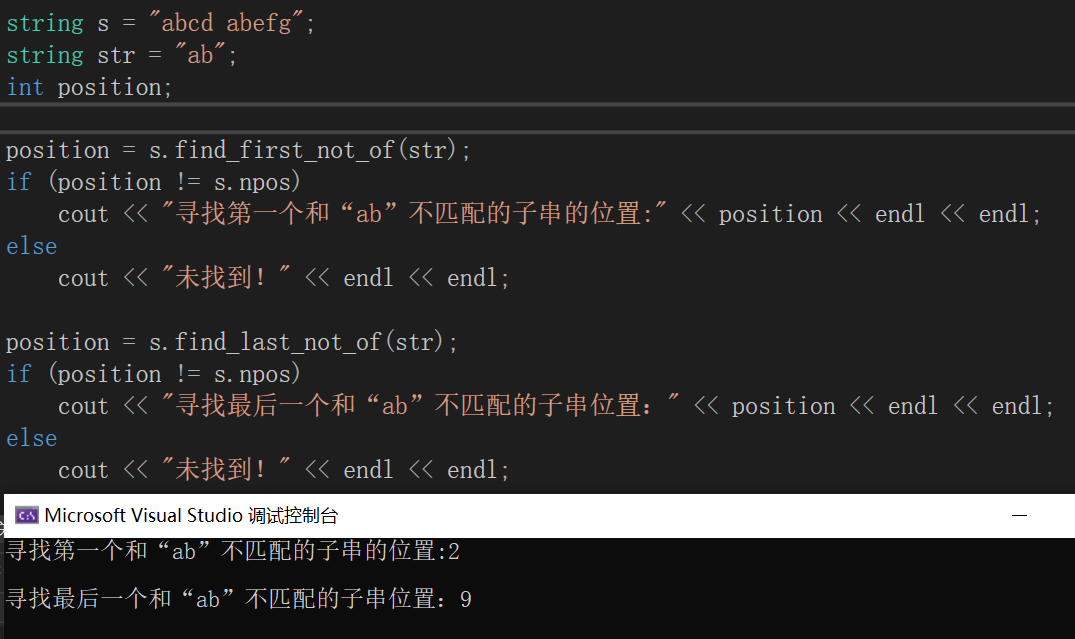
s.find_first_not_of(str):在s中查找第一个和str不匹配的字符位置,如果找到则返回该不匹配字符地址,如果找不到则返回npos;
s.find_last_not_of(str):在s中查找最后一个和str不匹配的字符位置,如果找到则返回该不匹配字符的地址,找不到则返回npos;
5.寻找s中所有str所在的位置:

二叉树
是n(n>=0)个结点的有限集合,它或为空树(n=0),或由一个根结点和之多两棵称为根的左子树和右子树的互不相交的二叉树组成。二叉树中不存在度大于2的结点,并且二叉树的子树有左子树和右子树之分;
二叉树的两种特殊形态
-
满二叉树
一棵二叉树中,所有分支结点都有双分结点,并且叶结点都在二叉树的最下层;满二叉树有2h-1个结点
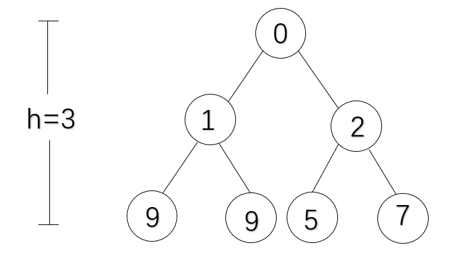
-
完全二叉树
深度为k的,有n个结点的二叉树,当且仅当其每一个结点都与深度为k的满二叉树中编号从1至n的结点一一对应。他没有单独的右分支结点,完全二叉树实际上是对应满二叉树删除最右边若干个结点得到的,其结点个数h范围为:2h-1-1<n<2h-1。完全二叉树中如果有度为1的结点,只可能有一个,且该结点只有左孩子而没有右孩子,且此时完全二叉树的结点为偶数。如果完全二叉树的结点个数为奇数则没有度为1的结点;
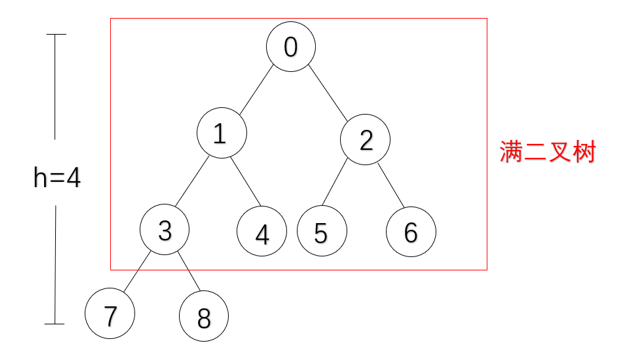
二叉树的性质
- 性质1:非空二叉树上叶结点数等于双分支结点数加1,即n0=n2+1(n0表示度为0的结点个数,n2表示度为2的结点个数)。
- 性质2:在二叉树的第i层上至多有2i-1个结点,满二叉树的时候最多;
- 性质3:高度为h的二叉树至多有2h-1个结点(h>=1);
- 性质4:具有n个结点的完全二叉树深度必为[log2h]+1;
二叉树存储结构
顺序存储结构
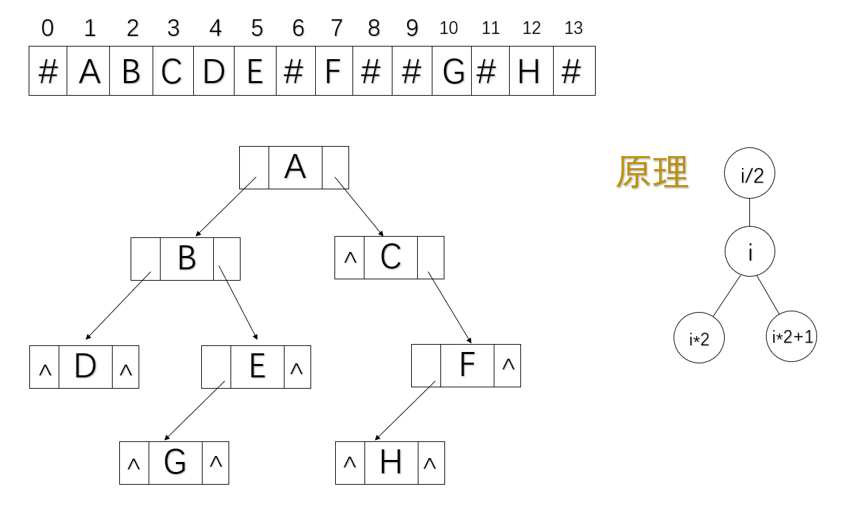
先用空结点把二叉树补成完全二叉树,然后对结点编号,不使用下标为0的元素,编号为i的结点左孩子结点编号为2i,右孩子编号结点为2i+1,其父节点的编号为⌊n/2⌋,
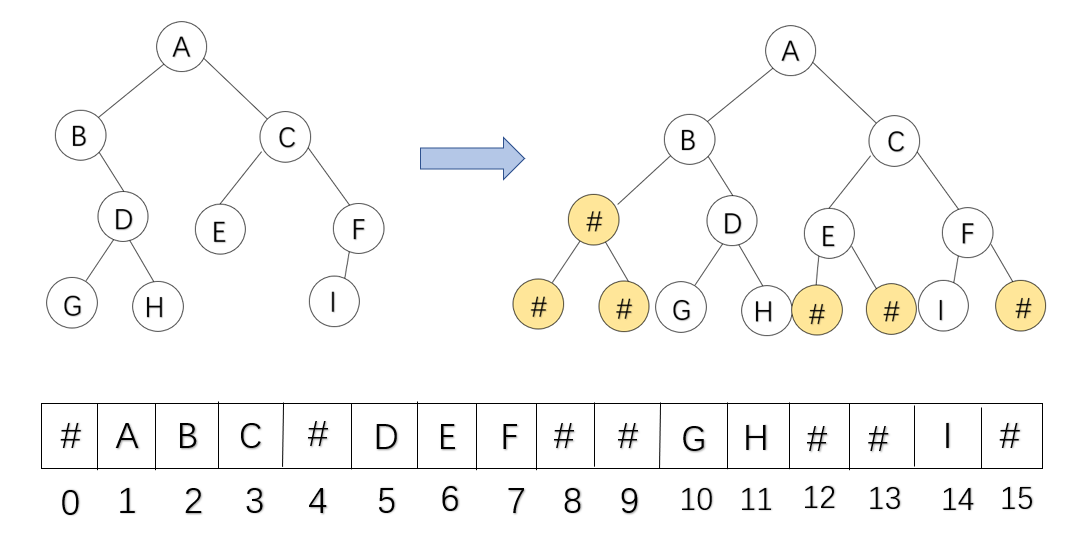
定义
typedef ElemType sqBTree[MaxSize];
优缺点
- 对于完全二叉树俩说,顺序存储结构是非常合适的;
- 在最坏的情况下,一个深度为k且只有k个结点的单支树(树中不存在度为2的结点)却依旧需要2k-1个一维数组,空间利用率太低;
- 数组的通病:插入删除操作不方便;
链式存储结构
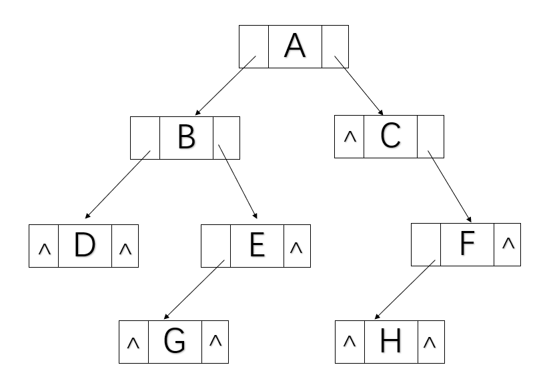
结构体定义
typedef struct TNode * Position;
typedef Position BTree;
struct TNode
{
ElementType data;//结点数据
BTree lchild;//指向左孩子;
BTree rchild;//指向右孩子
};
优缺点
- 空间利用效率高,方便插入和删除;
- 不容易访问结点的双亲;
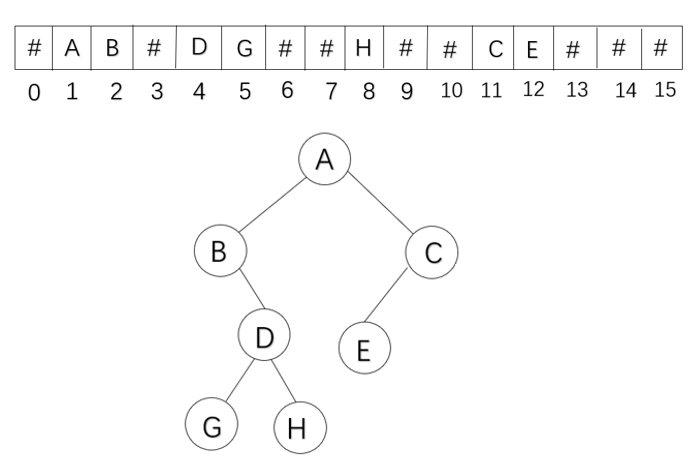
二叉树建法
二叉树的顺序存储结构转换成二叉链
BTree CreatBTree(string str, int i)
{
BTree bt;
bt = new TNode;
if (i > str.size())
return NULL;
if (str[i] == '#')
return NULL;
bt->data = str[i];
bt->lchild = CreatBTree(str, i * 2);
bt->rchild = CreatBTree(str, i * 2 + 1);
return bt;
}
先序遍历递归建树
BTree CreatTree(string str,int &i)//每一次递归都改变i的值,以此达到先建立根结点再建立左子树最后建立右子树的目的;
{
BTree bt;
if(i>len-1)
return NULL;
if(str[i]=='#')
return NULL;
bt = new TNode;
bt->data=str[i];
bt->lchild= CreatTree(str,++i);
bt->rchild= CreatTree(str,++i);
return bt;
}
层次遍历创建二叉树

思路
初始化队伍,创建根结点,将根结点进队;
while(队伍不空)
队伍中出列一个节点T;
去字符str[i];
if(str[i]=='#')
T->lchild=NULL;
else
生成T的左孩子结点,值为str[i],把T->lchild入队;
end if
取str下一个字符;
if(str[i]=='#')
T->rchild=NULL;
else
生成T的右孩子结点,值为str[i],把t->rchild入队;
end if
end while
代码实现

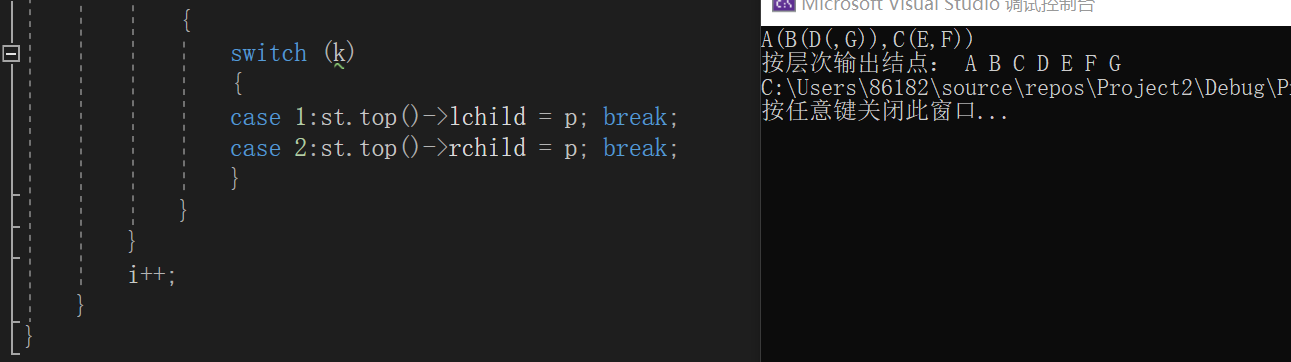
括号法字符串创建二叉树
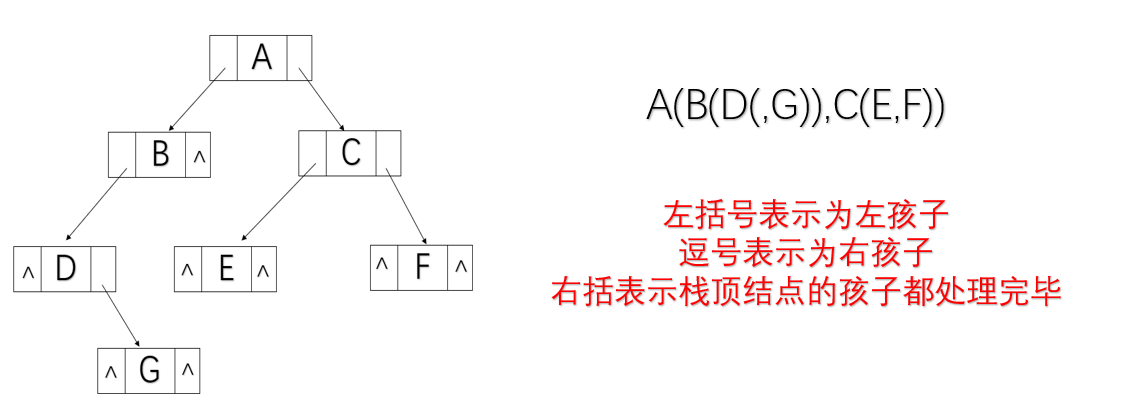
定义一个栈st保存结点;
定义一个变量k用于判断要创建左孩子还是右孩子;
先将根结点初始化为NULL;
while(i小于字符串长度)
switch(字符)
{
case '(':将结点p入栈,且将k置为1,表示即将要处理的是结点p的左孩子;break;
case ')':说明栈顶结点左右孩子都处理完毕,栈顶结点出栈;break;
case ',':将k置为2,表示即将要处理的是栈顶元素的右孩子;break;
default:说明为结点值,创建结点p并赋值,并根据k的值对栈顶结点的左/右孩子进行创建;
}
取下一字符;
end while
代码实现
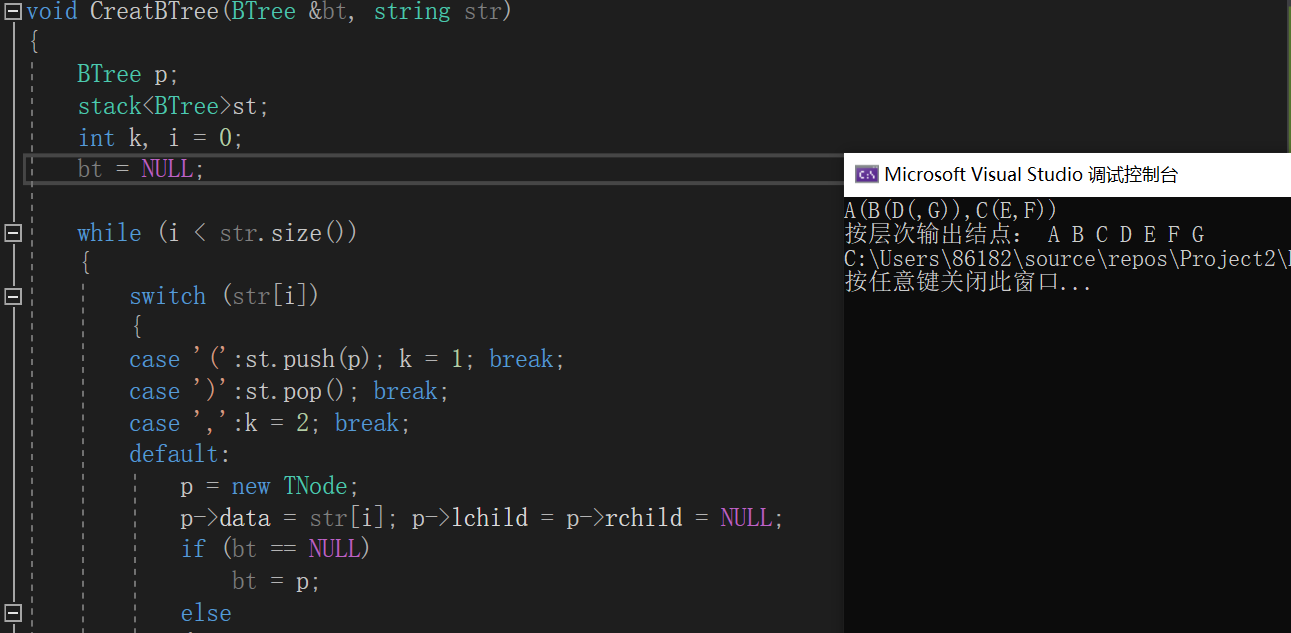
二叉树遍历
二叉树的遍历是指按照一定的次序访问树中所有的结点,并且每个结点仅被访问异常的过程。他是最基本的运算,是二叉树中所有其他运算的基础。
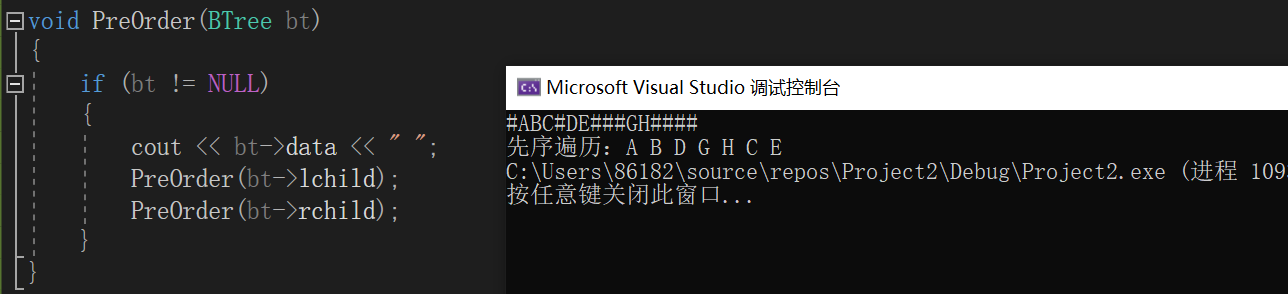
先序遍历:根结点->左子树->右子树

void PreOrder(BTree bt)
{
if(bt!=NULL)
{
cout<<bt->data<<" ";
PreOrder(bt->lchild);
PreOrder(bt->rchild);
}
}
代码实现
中序遍历:左子树->根结点->右子树
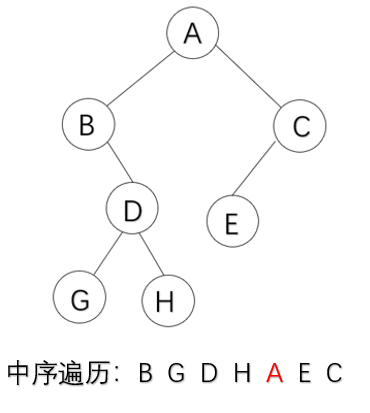
void InOrder(BTree bt)
{
if(bt!=NULL)
{
InOrder(bt->lchild);
cout<<bt->data<<" ";
InOrder(bt->rchild);
}
}
代码实现
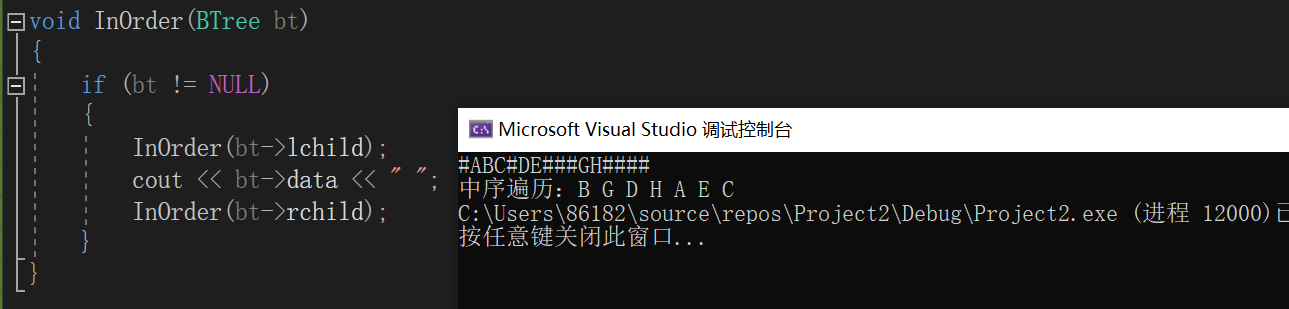
后序遍历:左子树->右子树->根结点
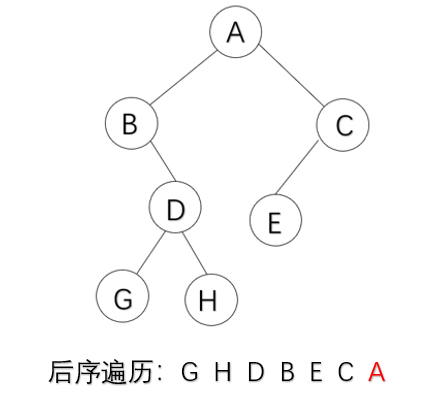
void PostOrder(BTree bt)
{
if (bt != NULL)
{
PostOrder(bt->lchild);
PostOrder(bt->rchild);
cout << bt->data << " ";
}
}
代码实现
二叉树的层次遍历
访问根结点,如果不为空则入队;
while(队列不为空)
队列中出列一个节点,访问它;
如果他的左孩子不为空,则左孩子入队;
如果他的右孩子不为空,则右孩子入队;
end while
代码实现
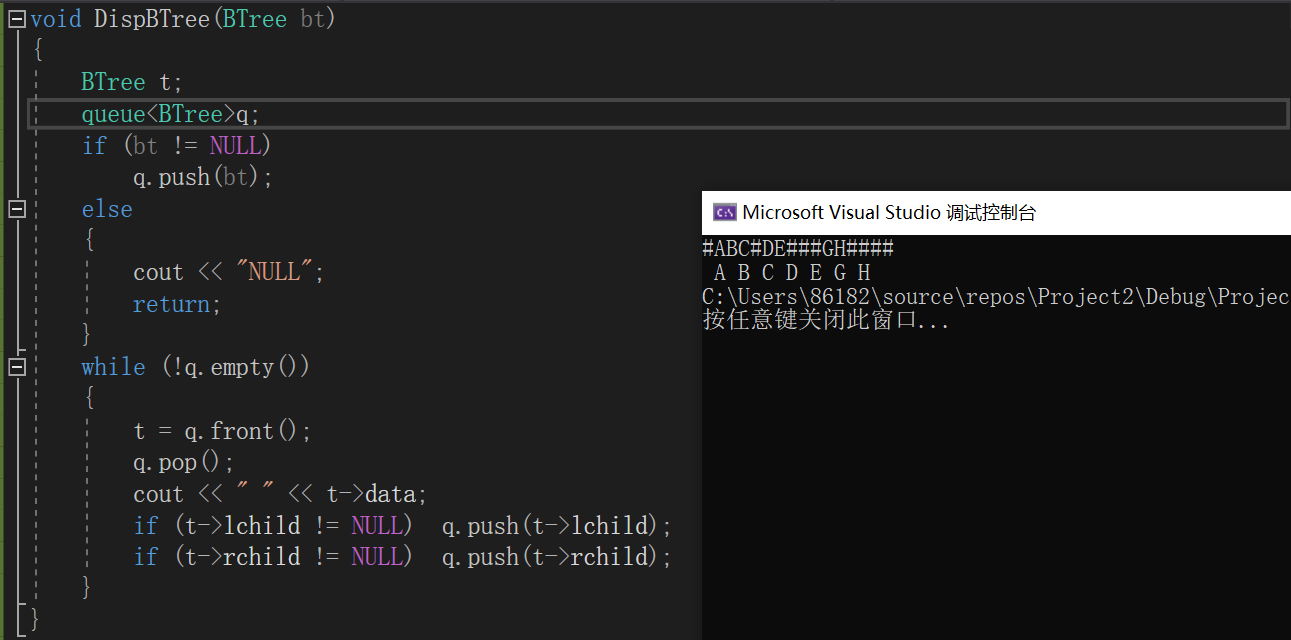
根据中序序列和先序序列创造二叉树
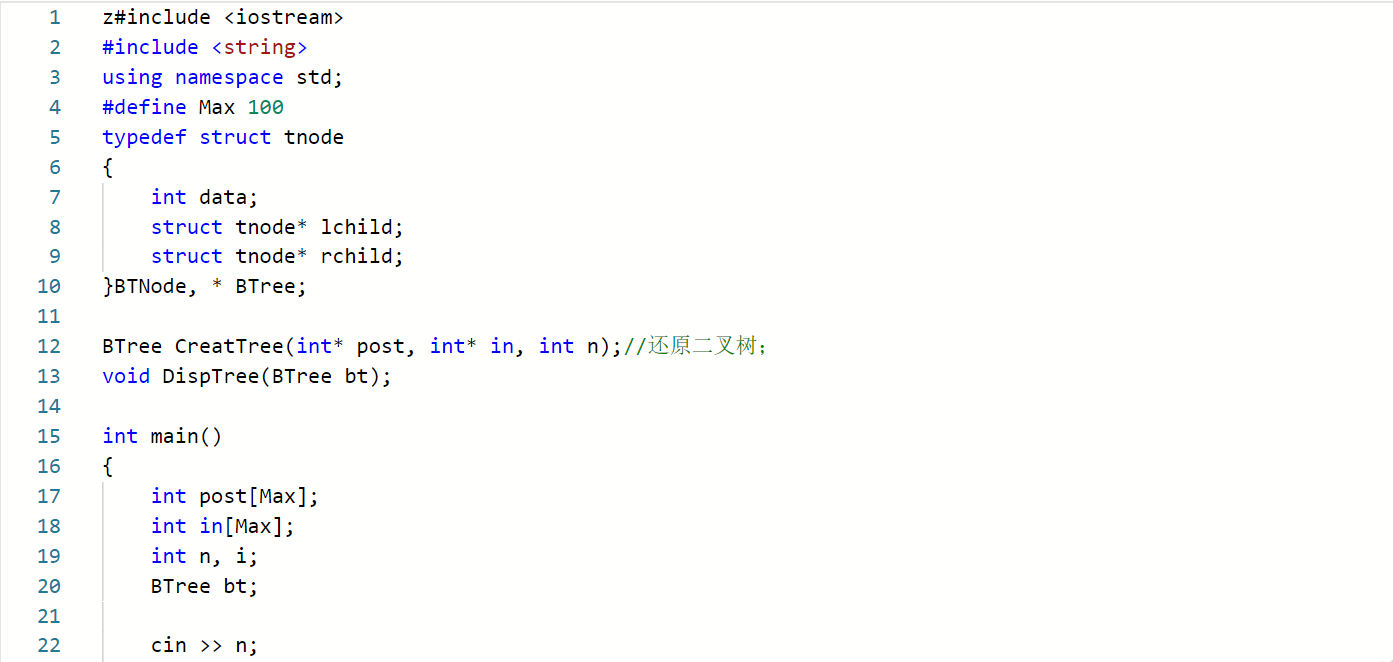
例题:还原二叉树

思路
BTree CreatBT(char *pre,char*in,int n)
{
若n<=0,返回空,递归结束;
创建根结点BT,BT->data=*pre;
查找根结点在中序序列位置k;
创建左子树:BT->lchild=CreatBT(pre+1,in,k);
创建右子树:BT->rchild=CreatBT(pre+k+1,in+k+1;n-k-1);
}
代码实现

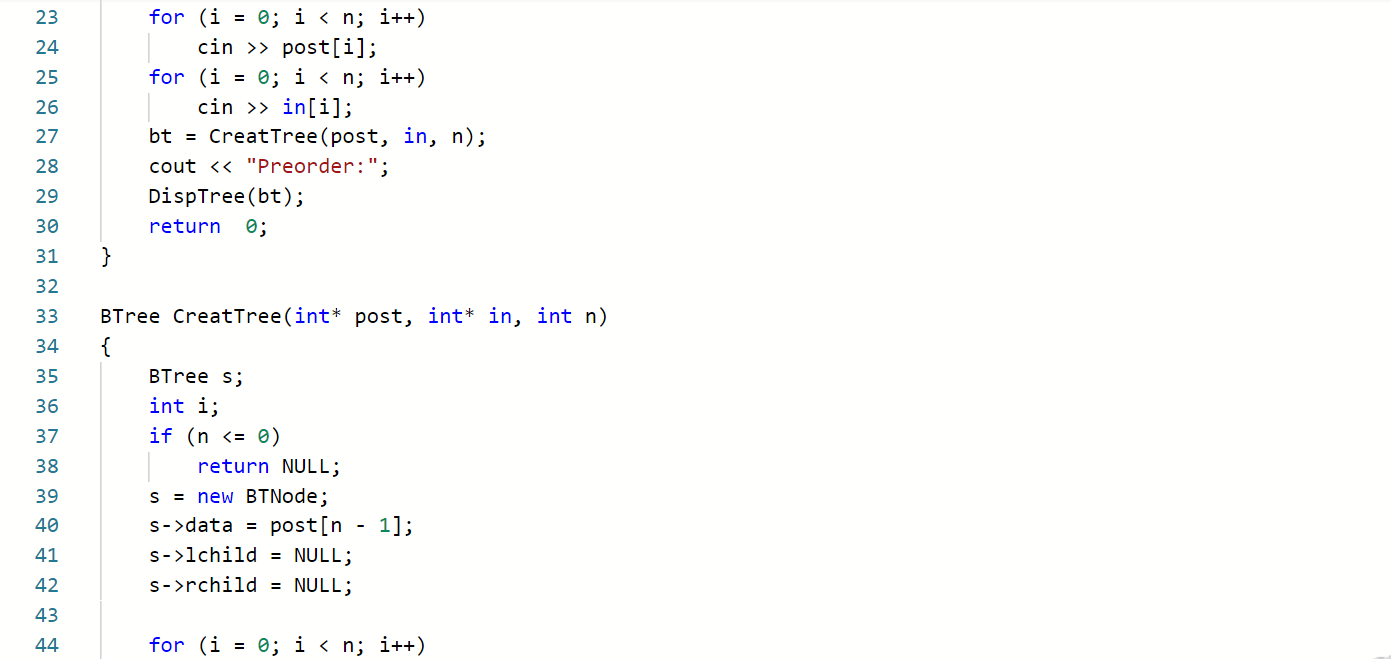
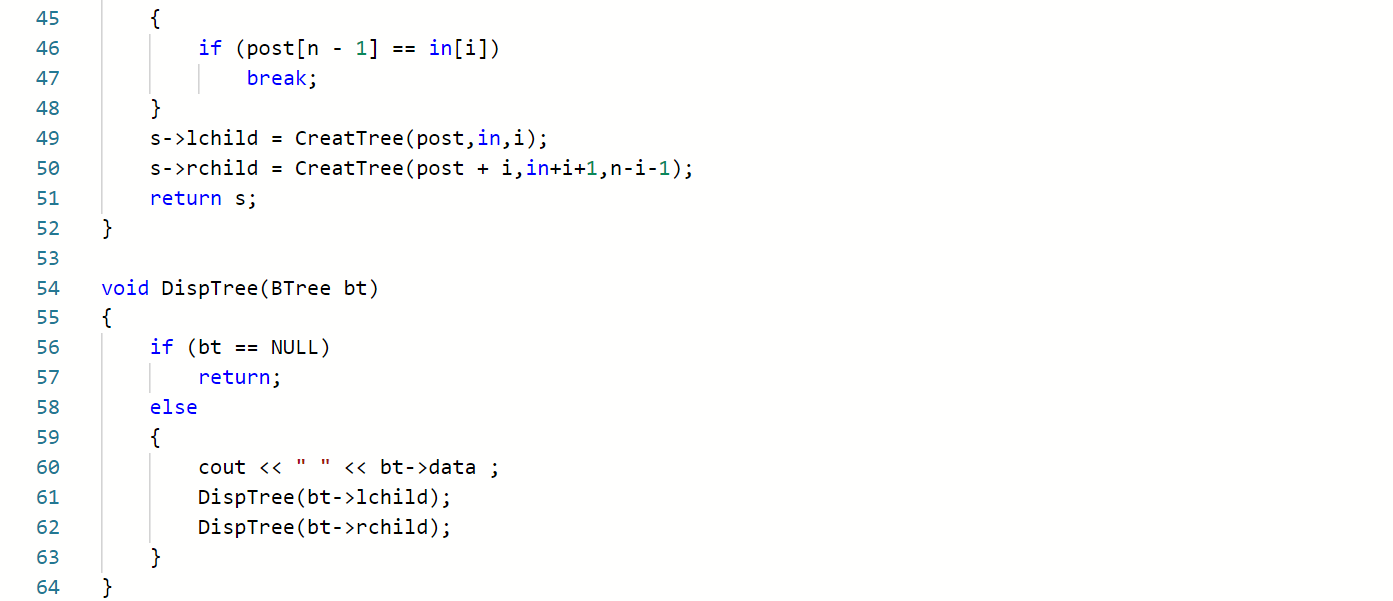
根据中序序列和后序序列创造二叉树
例题:根据后序和中序遍历输出先序遍历
思路
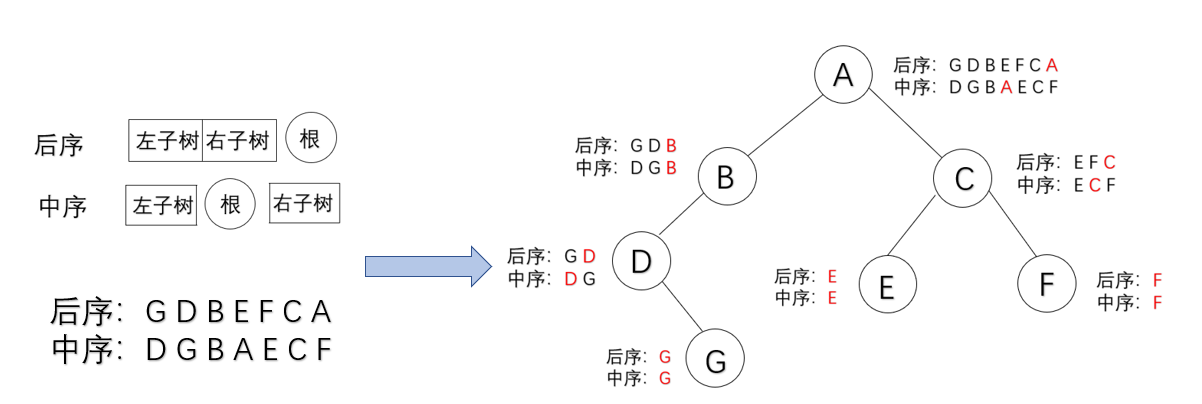
BTree CreatBT(char *post,char*in,int n)
{
若n<=0,返回空,递归结束;
创建根结点BT,BT->data=*pre;
查找根结点在中序序列位置k;
创建左子树:BT->lchild=CreatBT(post,in,k);
创建右子树:BT->rchild=CreatBT(pre+k,in+i+1;n-k-1);
}
代码实现
二叉树应用
1.求结点x所在的层次
思路
先判断当前结点是否为
int GetLevel(BTree bt,char x,int h)
{
定义变量I用于保存x所在的层次,先初始化为0表示找不到;
if(bt==NULL)
说明已经遍历到叶结点都还未找到结点x,返回0;
end if
if(bt->data==x)
找到结点x,return h;
end if
I=GetLever(bt->lchild,x,h+1);//现在左子树中寻找x结点;
if (I==0)
说明没有在左子树中找到结点x;
I=GetLever(bt->rchild,x,h+1);//继续在右子树中寻找结点x;
else
return I;//找到结点x;
end if
}
代码实现

注意
- 一定要判断完左子树是否有结点x之后再去右子树寻找,否则如果在左子树中找到结点x并返回了正确的h,此时却进入到右子树继续寻找结点x,因为结点x唯一,所以右子树中不可能找到结点x,于是返回0,修改了I的值,导致最终结果出错;
- 这里的形参变量h不能设置为引用类型,否则每递归一次h都会加上1,因为这里是先序遍历,检查完左子树时,h会一直递增,返回h将会是递增后的值,这时再去检查右子树,h将不能代表结点所在的层次了。
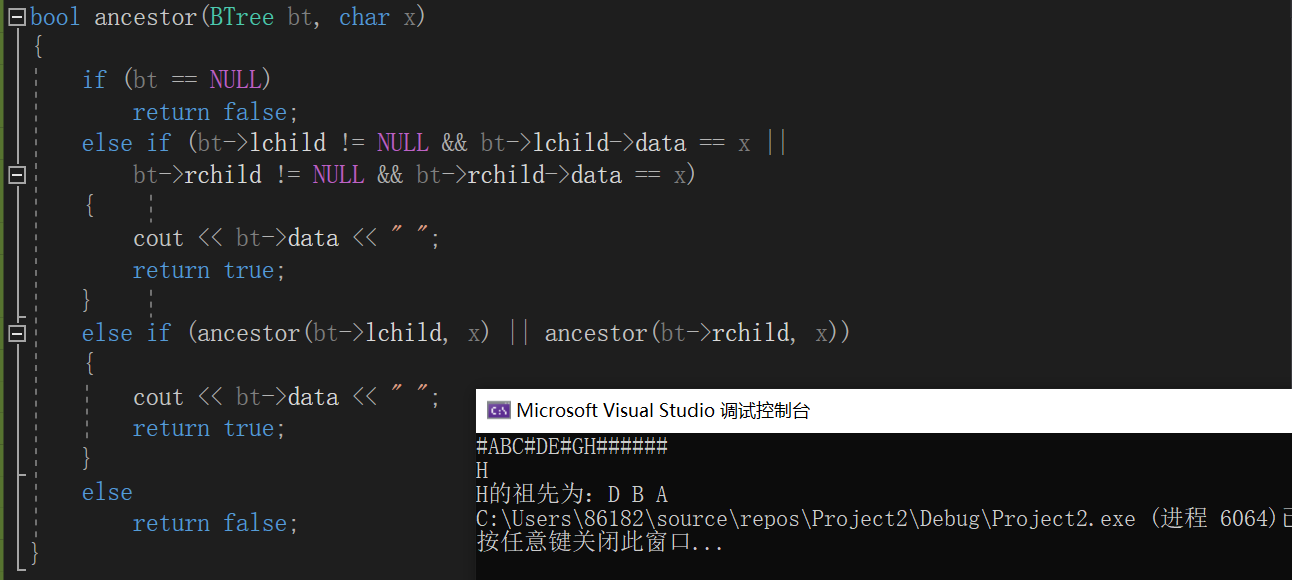
2.输出x结点所有祖先
思路
bool ancestor(BTree bt,char x)
{
if(bt==NULL)
return false;
else if(bt的左孩子为结点x||bt的右孩子为结点x)
输出bt->data; return true;
else if(ancestor(bt->lchild,x)||ancestor(bt->rchild,x))
输出bt->data; return true;
else
return false;
end if
}
代码实现
3.表达式树
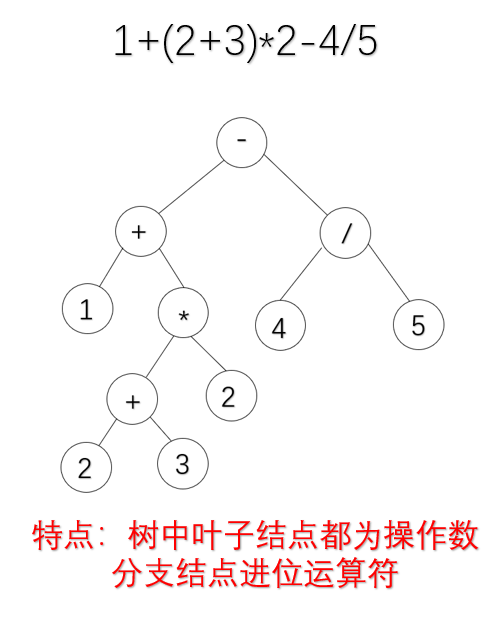
思路
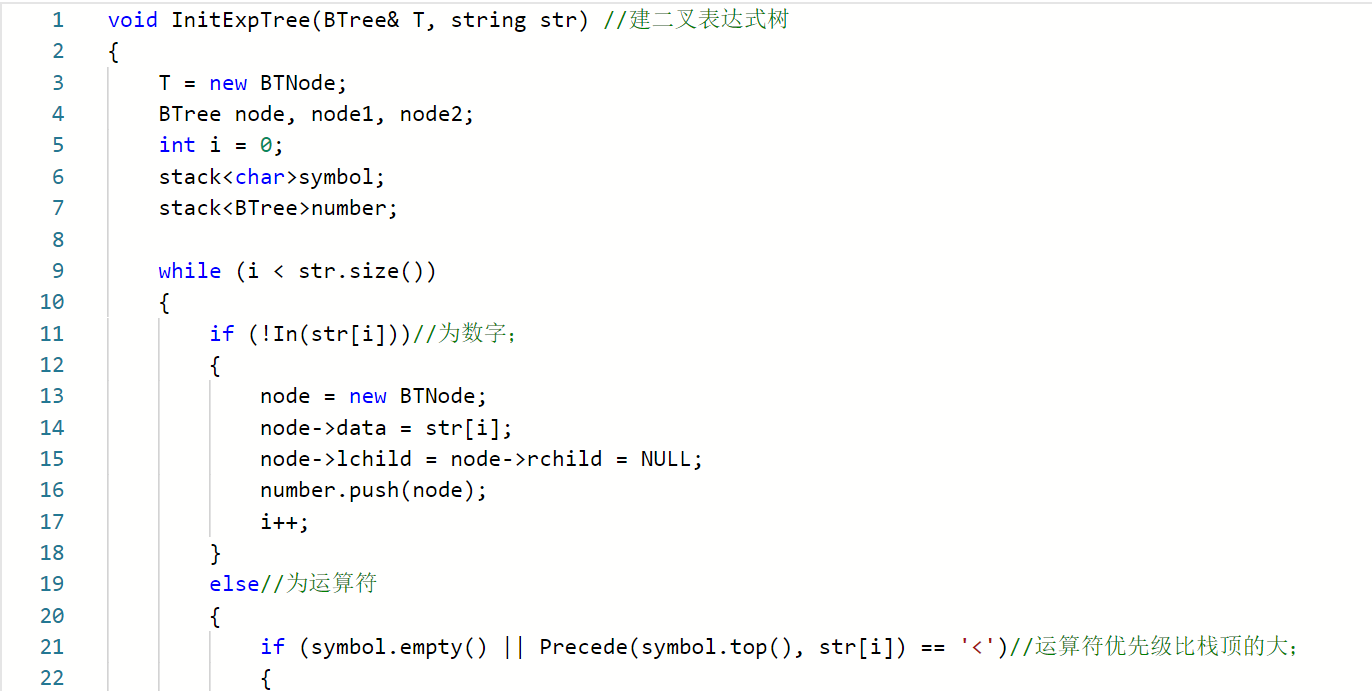
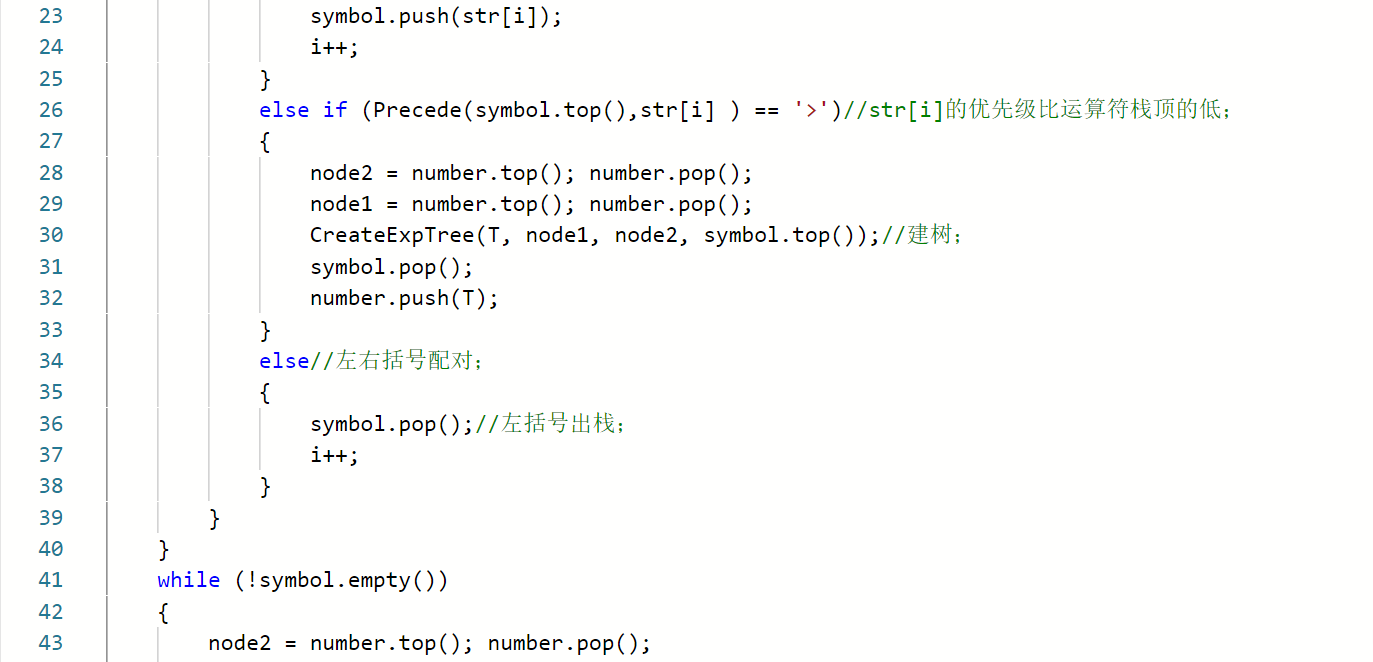
void InitExpTree(BTree& T,string str)//建二叉表达树
{
定义栈symbol来保存运算符;
定义栈number来保存运算数;
函数Precede()用于比较两运算符的优先级;
While(遍历表达式)
if(str[i]为运算数)
构建结点node保存运算数,并进运算数栈;
else//为运算符
若优先级>栈顶运算符,则入运算栈;
若优先级<栈顶运算符,则栈顶运算符出栈,树根栈弹出两个结点进行建树,新生成的树根入树根栈;
若优先级==栈顶运算符,则为左右括号匹配,弹出栈顶的左括号;
end if
end While
While(运算符栈不为空)
栈顶运算符出栈,树根栈弹出两个结点进行建树,新生成的树根入树根栈;
end while
}
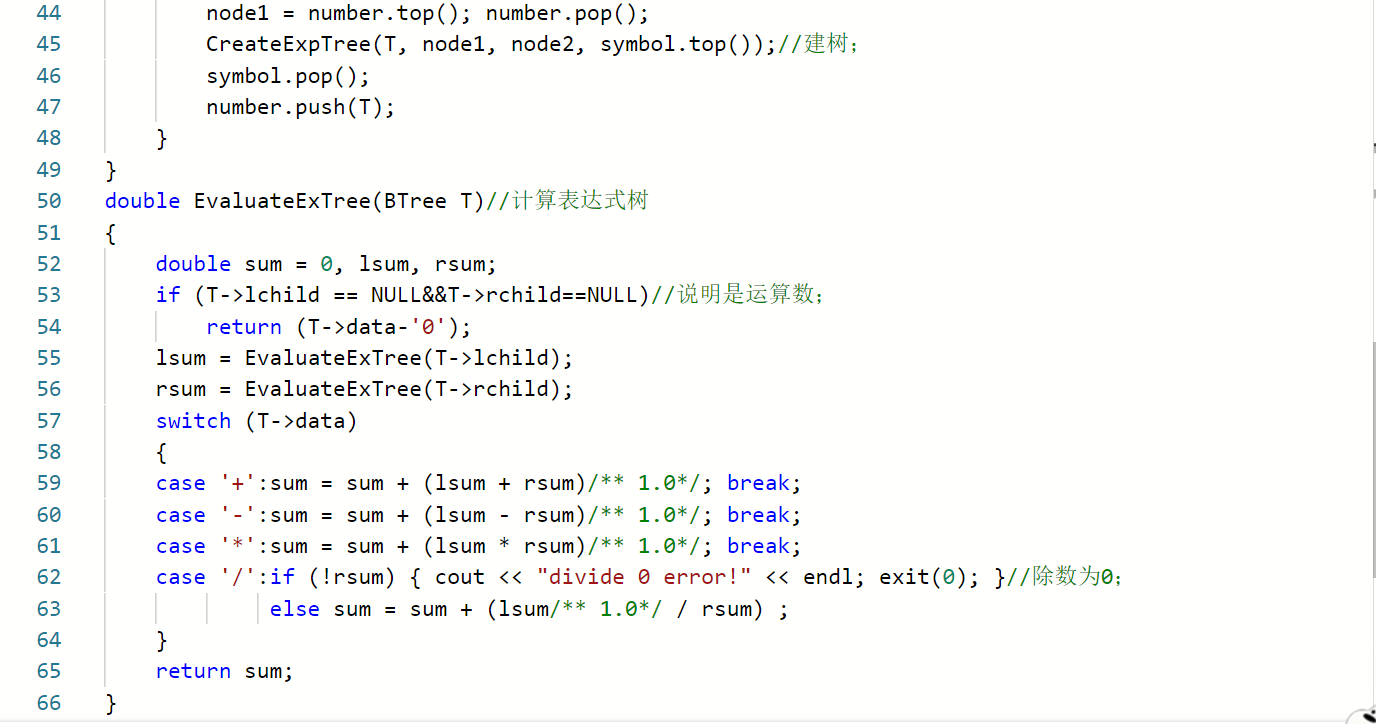
double EvaluateExTree(BTree T)//计算表达式树
{
定义变量sum保存每次运算结果;
if(T->lchild==NULL&&T->rchild==NULL)//遍历到叶结点,找到进行第一次运算的运算数。
return (T->data-'0');//记得返回时要将字符转为数据;
lsum=EvaluateExTree(T->lchild);//lsum保存左值;
rsum=EvaluateExTree(T->rchild);//rsum保存右值;
switch(T->data)
{
lsum和rsum进行相对应的运算,若除数为0时,要exit(0)退出程序;
}
return sum;
}
代码实现
树
树的存储结构
1.双亲存储结构
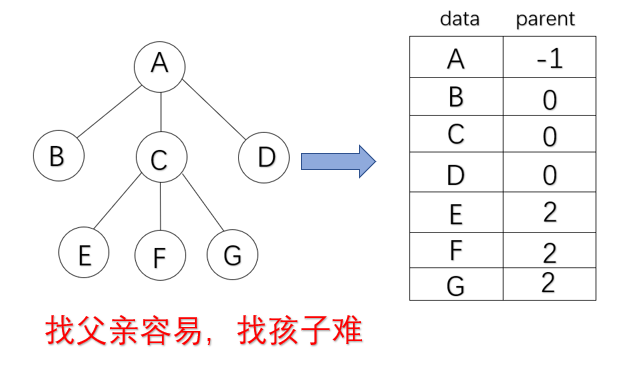
结构体定义
typedef struct
{
ElemType data;//结点的值;
int parent;//双亲位置
}PTree[MaxSize];
2.孩子链式存储结构
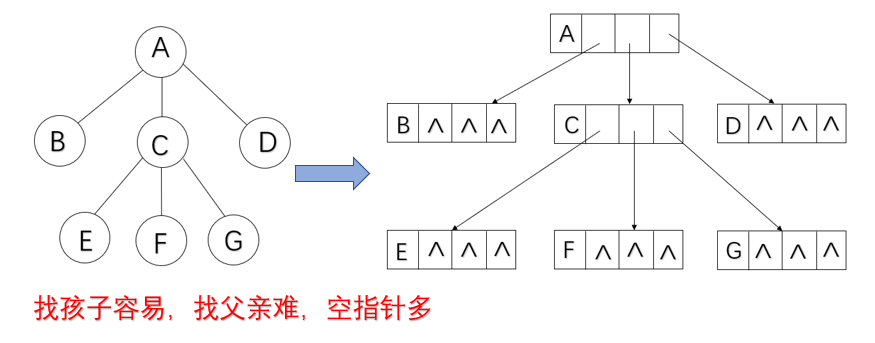
结构体定义
typedef struct node
{
ElemTypde data;//结点的值;
struct node *sons[MaxSons];//保存孩子指针
}TSonNode;
3.孩子兄弟链式存储
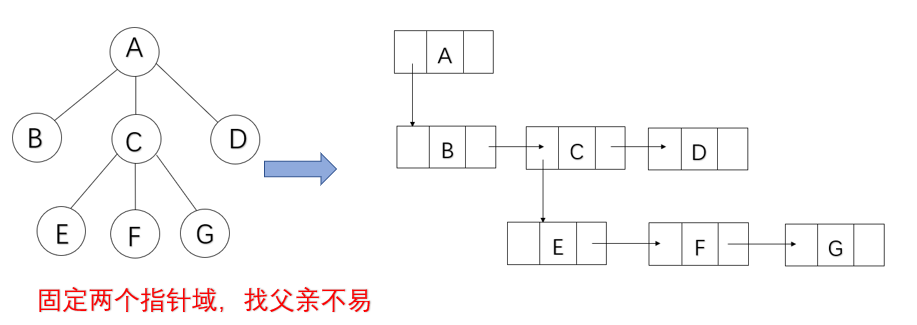
typedef struct tnode
{
ElemType data;
struct tnode *son ;//指向孩子;
struct tnode *brother;//指向兄弟;
}TNode,*Tree;
树的遍历
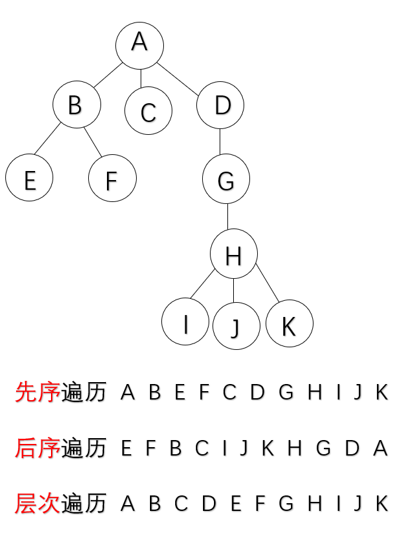
- 先序遍历:若树补为空,则先访问根结点,然后依次先根遍历各棵子树;
- 后序遍历:若树不为空,则先访问后根遍历各子树,然后访问根结点;
- 层次遍历:若树不为空,则自上而下,自左而右访问树中每个结点;
树的应用
目录树
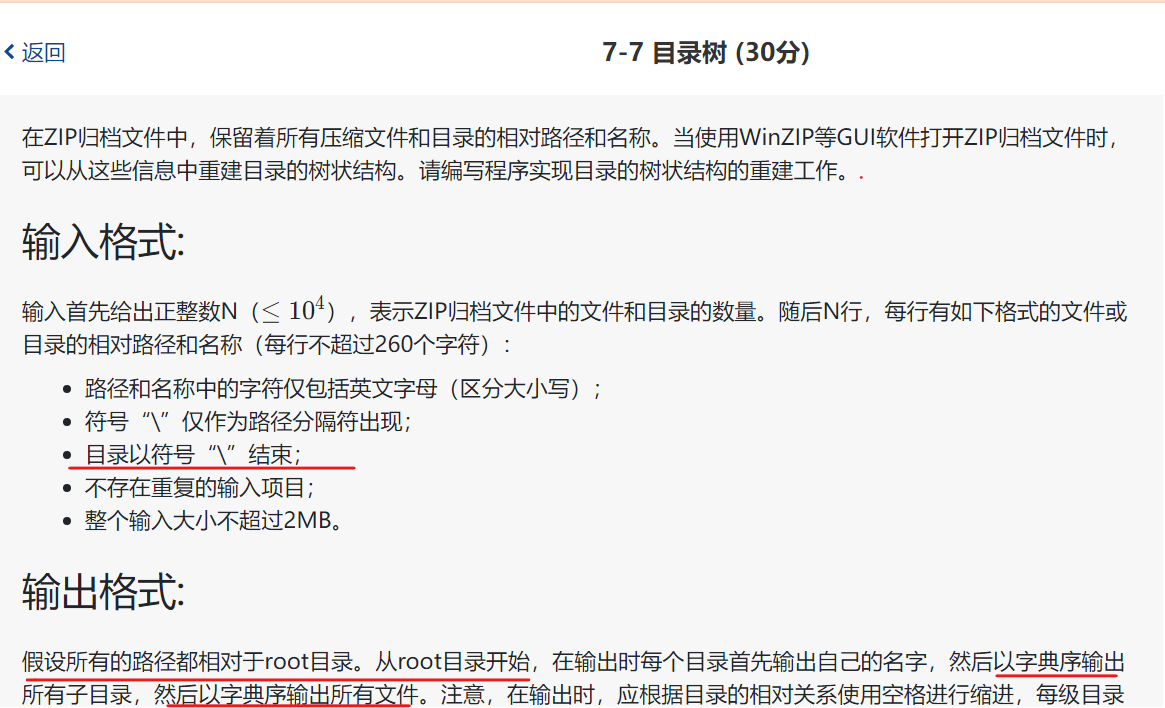
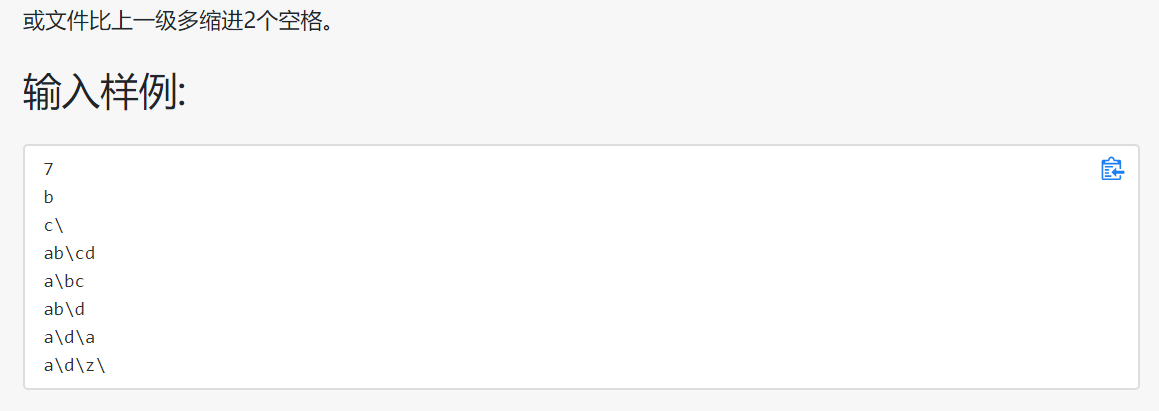
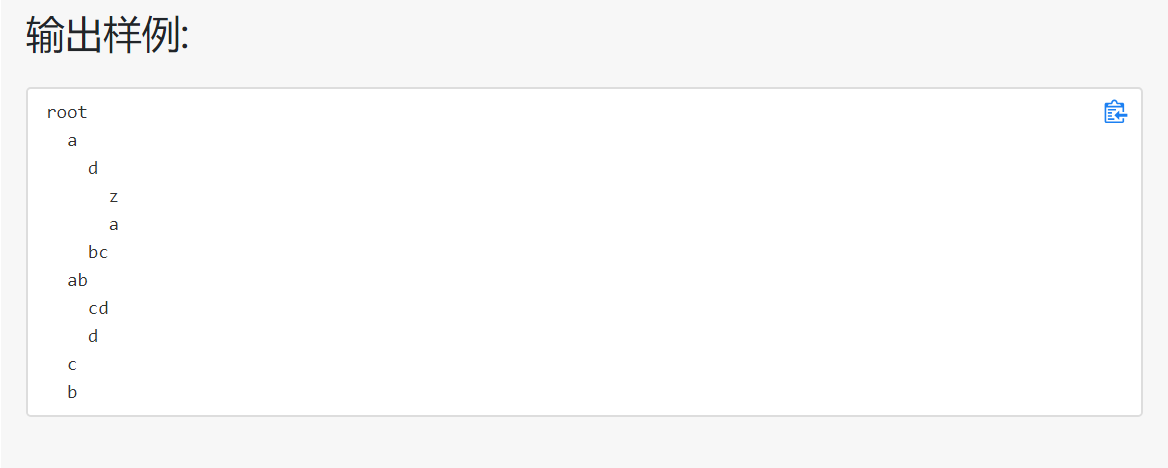
思路
typedef struct tnode
{
string name;//该结点名称
bool isfile;//判断该结点是否为文件;
struct tnode*brother;//左子树存兄弟;
struct tnode*child;//右子树存孩子;
}
void CreatTree(Tree&bt ,string str,int i)
{
定义结构体指针temp,btr;
为temp申请空间并初始化,btr用于指向bt;
if(i>=str.size())
return;//路径遍历完毕;
获取结点temp的名字;
if(str[i]=='\\')
说明结点temp为目录,修改temp->isfile为true;
end if
if(temp为文件)
InitFile(temp,bt);//为文件temp在bt的孩子中找一个可插入位置;
else //temp为目录
InitList(temp,bt);//为目录temp在bt的孩子中找一个可插入位置
CreatTree(temp,str,i);//为temp开辟孩子;
}
void InitList(Tree& temp, Tree& bt)//对目录temp找一个插入位置
{
定义结构体指针btr来遍历二叉树bt;
btr=bt->child;//btr先指向bt的孩子;
/*先对第一个兄弟结点进行判断*/
if(btr==NULL||btr为文件||temp->name<btr->name)//可插入
进行插入,要注意修改bt的孩子指针;
else if(temp->name == btr->name)
直接使temp指向btr;
else //开始从第二个兄弟结点查找插入位置,btr作为一个前驱指针;
while(btr->brother != NULL)
if(btr->brother为文件||btr->brother->name>temp->name)
找到可插入位置,break;
else if(btr->brother->name == temp->name)
直接使temp指向btr->brother;break;
else
btr=btr->brother;//遍历下一兄弟结点;
end if
end while
if(btr->brother为空||btr->brother->name!= temp->name)
进行插入操作:temp->brother=btr->brother;btr->brother=temp;
end if
end if
}
void InitFile(Tree& temp, Tree& bt)//对文件temp找一个可插入位置
{
定义结构体指针btr来遍历二叉树bt;
btr=bt->child;//btr先指向bt的孩子;
if(btr==NULL||btr为文件&&btr->name>=temp->name)//对第一个兄弟结点进行判断
进行插入,注意修改bt的孩子指针;
else //从第二个兄弟结点进行判断,btr作为一个前驱指针;
while(btr->brother != NULL)
if (btr->brother为文件&&btr->brother->name>temp->name)
找到可插入位置,break;
else
btr = btr-> brother;//遍历下一个兄弟结点
end if
end while
对temp进行插入操作:temp->brother=btr->brother;btr->brother=temp;
end if
}
代码实现

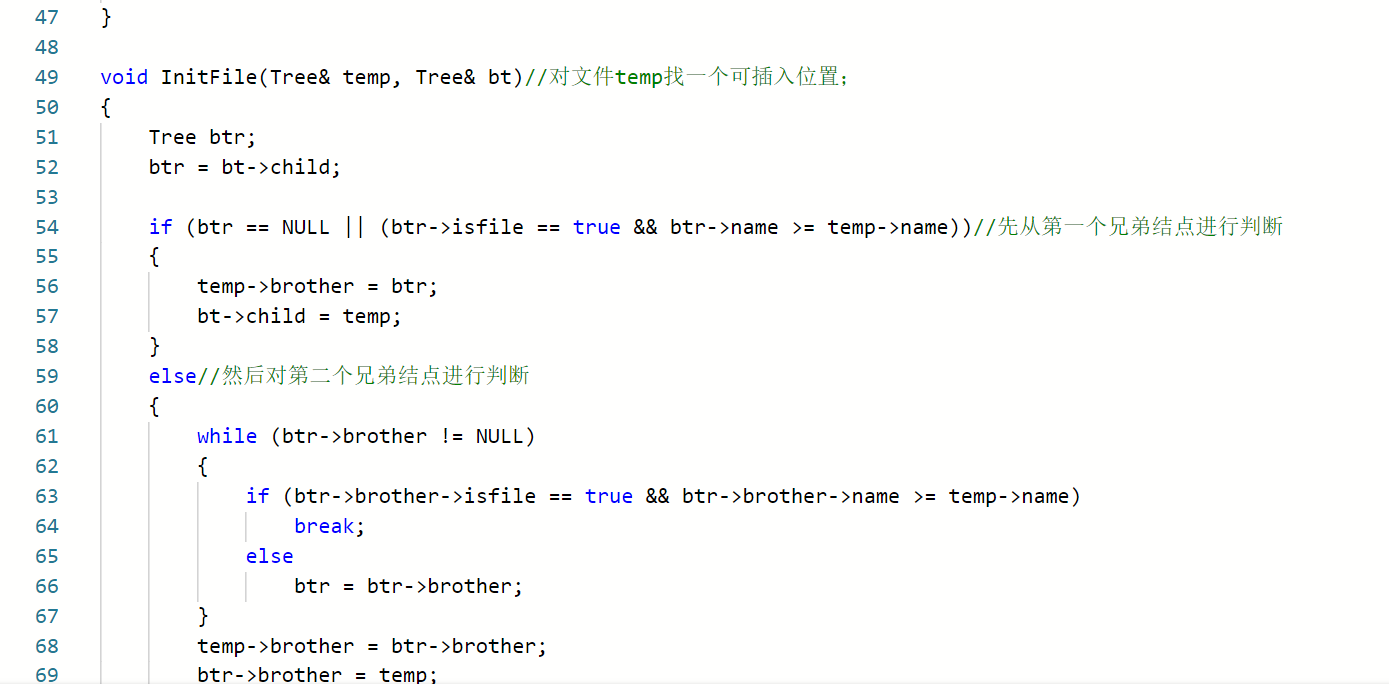

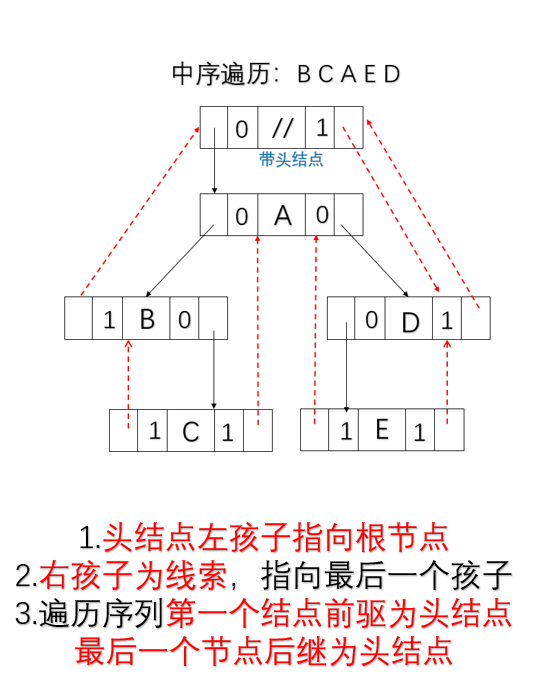
线索二叉树
- 二叉链存储结构时,每个结点有两个指针域,总共有2n个指针域;
- 有效指针域:n-1(根结点没有指针指向)
- 空指针域为:n+1;
- 利用这些空链域指向该线性序列中的“前驱”和“后继”的指针,称为线索;
线索化二叉树
- 若结点有左子树,则lchild指向其左孩子;否则lchild指向其直接前驱(即线索);
- 若结点有右子树,则rchild指向其右孩子,否则rchild指向其直接后继(即线索);
结构体定义
typedef struct node
{
ElemType data;
int ltag,rtag;//用于判断是否有左右孩子;
struct node* lchild;
struct node* rchild;
}
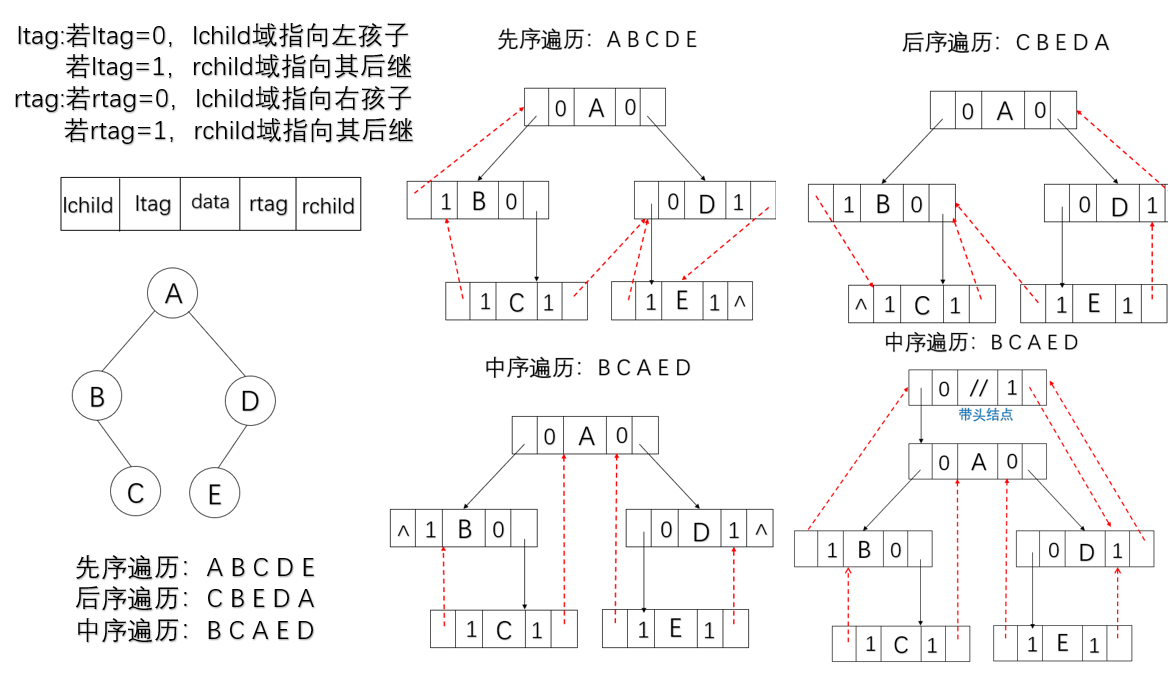
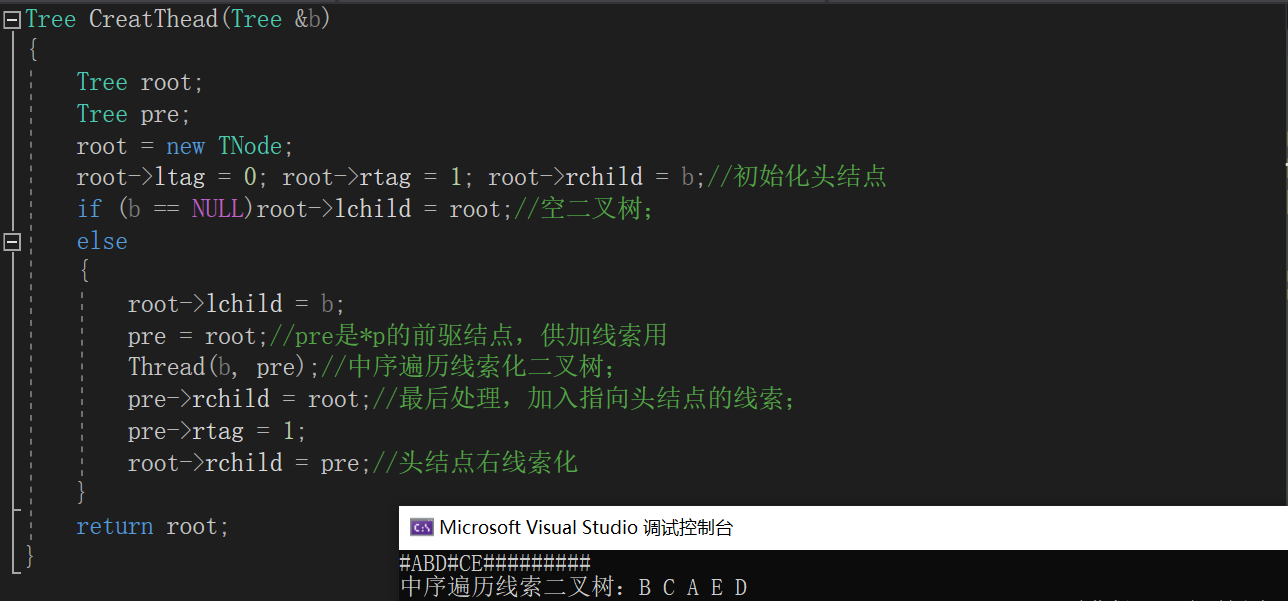
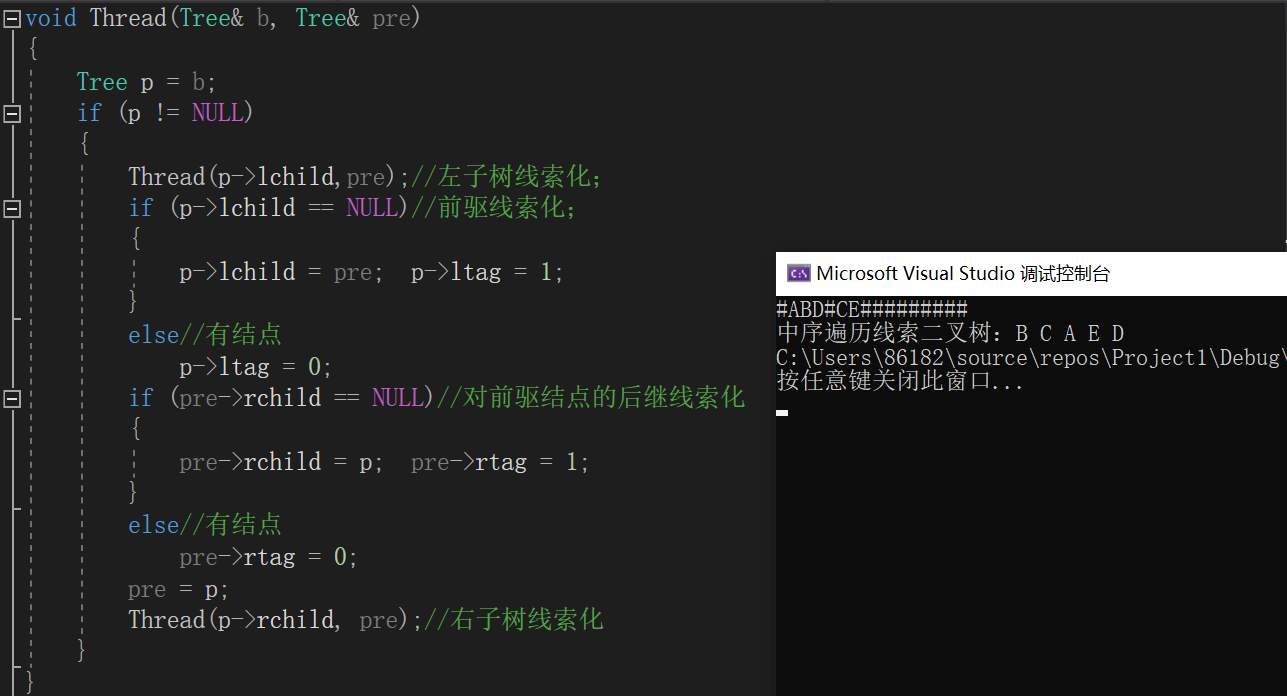
带头结点线索二叉树的创建
代码实现
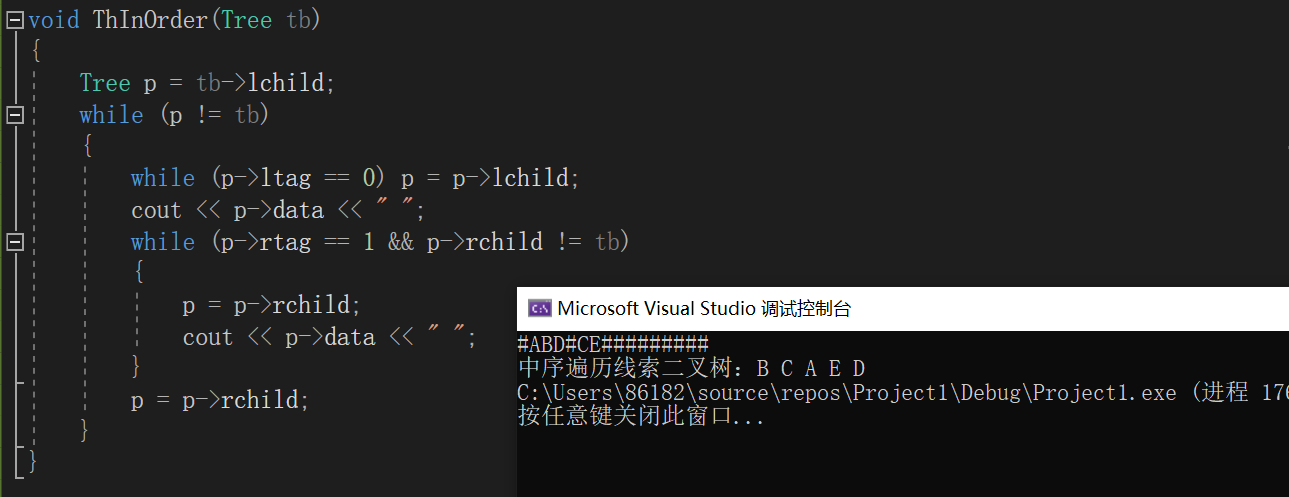
带头结点的中序线索二叉树遍历
思路:
- 1.找中序遍历的第一个结点;
- 2.找中序线索化链表中节点的后继:
- 若无右子树,则为后继线索中所指的结点;
- 否则为其右子树进行中序遍历是访问的第一个结点
代码实现
分析
中序遍历二叉线索数的好处在于遍历二叉树时不需要递归,所有结点只需遍历一次,没有使用栈,空间使用效率提高,时间复杂度为O(n),空间复杂度为O(1)。
哈夫曼树
定义
设二叉树有n个带权值的叶子结点,那么从根结点到各个结点的路径长度与相应节点权值的乘积的和,叫做二叉树的带权路径长度。具有最小带权路径长度(wpl)的二叉树称为哈夫曼树。每个哈弗曼树的结点为2xn0-1,且树中没有单分支结点;
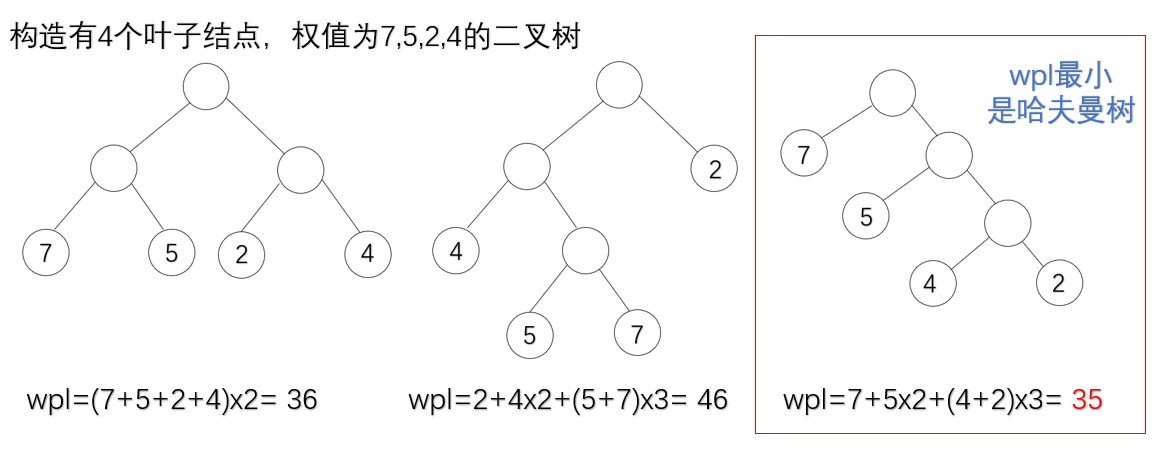
构造哈夫曼树并计算wpl
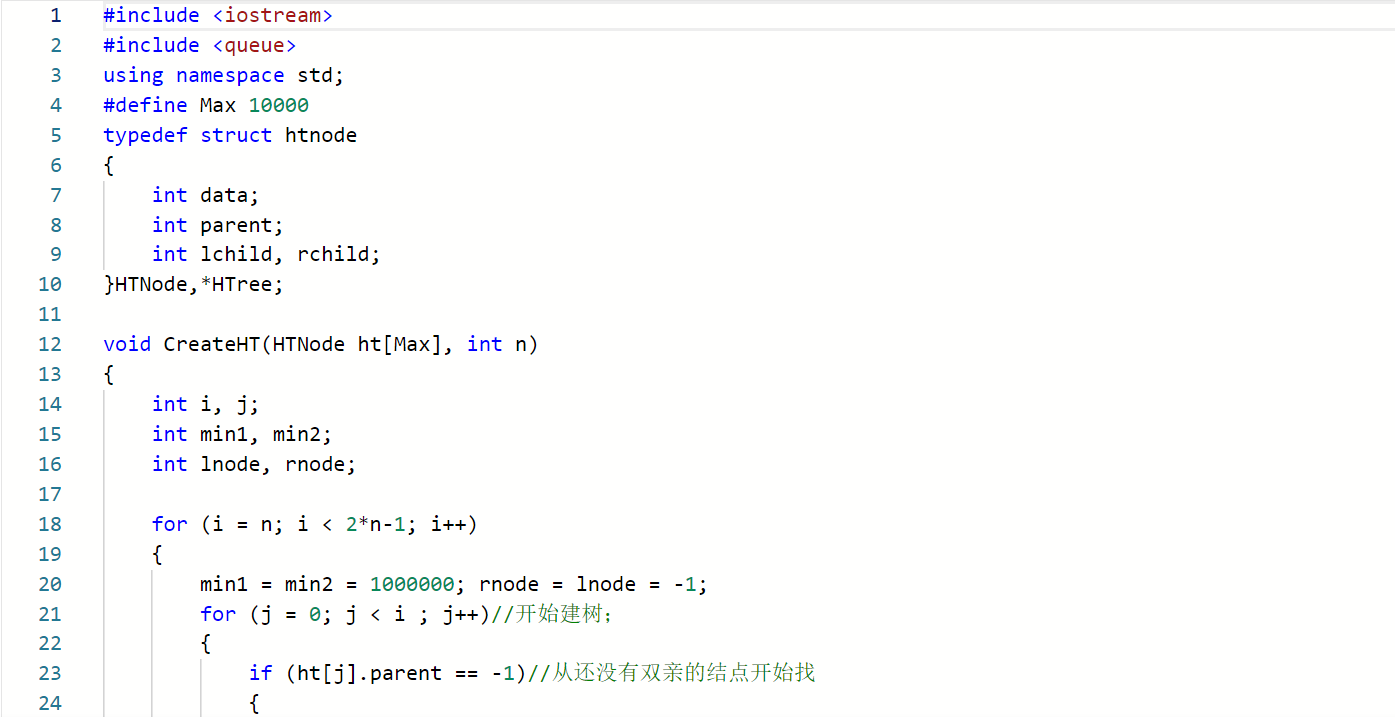
结构体定义
typedef struct //顺序存储结构
{
char data;//节点值;
float weight;//权重;
int parent;//双亲结点;
int lchild,rchild;
}HTNode;
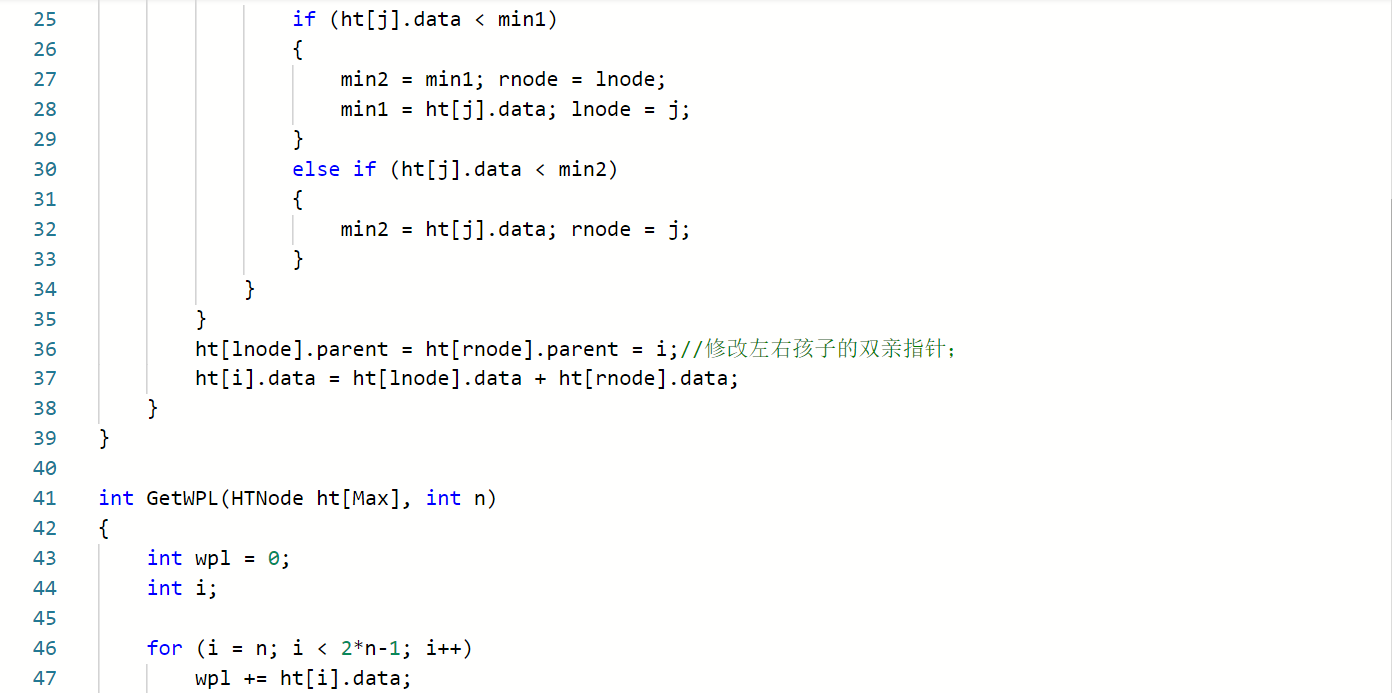
思路
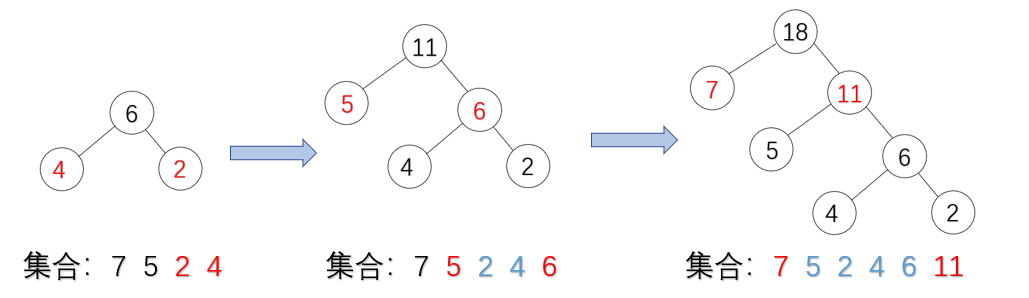
- 初始化哈夫曼树数组ht,包含n个叶子结点,2n-1个总结点
- 所有2n-1个结点的parent,lchild和rchild域置为初值-1;
- 输入n个叶子节点有data和weight域值;
- 构造非叶子节点ht[i],存放在ht[n]~ht[2n-2];
- 从ht[0]~ht[i-1]中找到根结点(parent域为-1的)最小的两个结点,ht[lnode]和ht[rnode];
- ht[lnode]和ht[rnode]的双亲节点置为ht[i],并且ht[i].weight=ht[lnode].weight+ht[rnode].weight;
- 一直到所有2n-1个非叶子结点都处理完毕;
- wpl的计算:wpl=ht[n]+ht[n+1]···+ht[2n-2];
代码实现

哈夫曼编码
在远程通讯中,要将待传字符转换成二进制的字符串,为了统一我们要对每个字符进行编码,不同的字符对应不同的编码,其长度也不相同。为了使总编码的长度最短,提高传递效率,我们应该将使用次数最多的字符的编码设置的尽量短一点,且不能使任一字符的编码为另一个字符编码的前缀,否则一段二进制编码就会有多种不同的解法,得到的信息很可能不是我们所期望的;这里我们可以用哈夫曼树来编码。
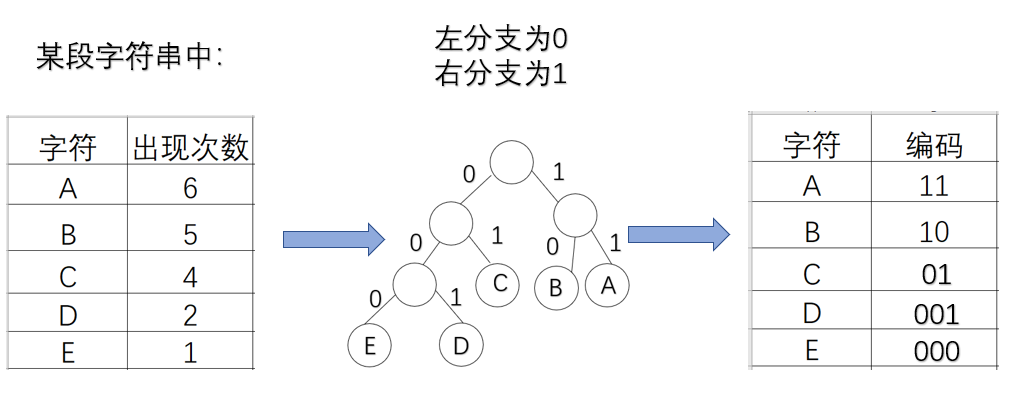
结构体定义
typedef struct
{
char cd[N];//存放当前节点的哈夫曼码
int star;//哈夫曼码在cd中的起始位置;
}HCode;
思路
void CreatHCode(HTNode ht[],HCode hcd[],int n)
{
for i=0 to n
取一叶结点ht[i];
从叶结点开始往树根结点开始编码(从下而上,在数组体现为从第n个位置开始编码)
while(还未遍历到树根结点)
若结点为父节点的右孩子,编码为1;
若结点为父节点的左孩子,编码为0;
结点指针指向父节点,进行下一次判断
end while
记录编码停止的位置
end for
}
代码实现
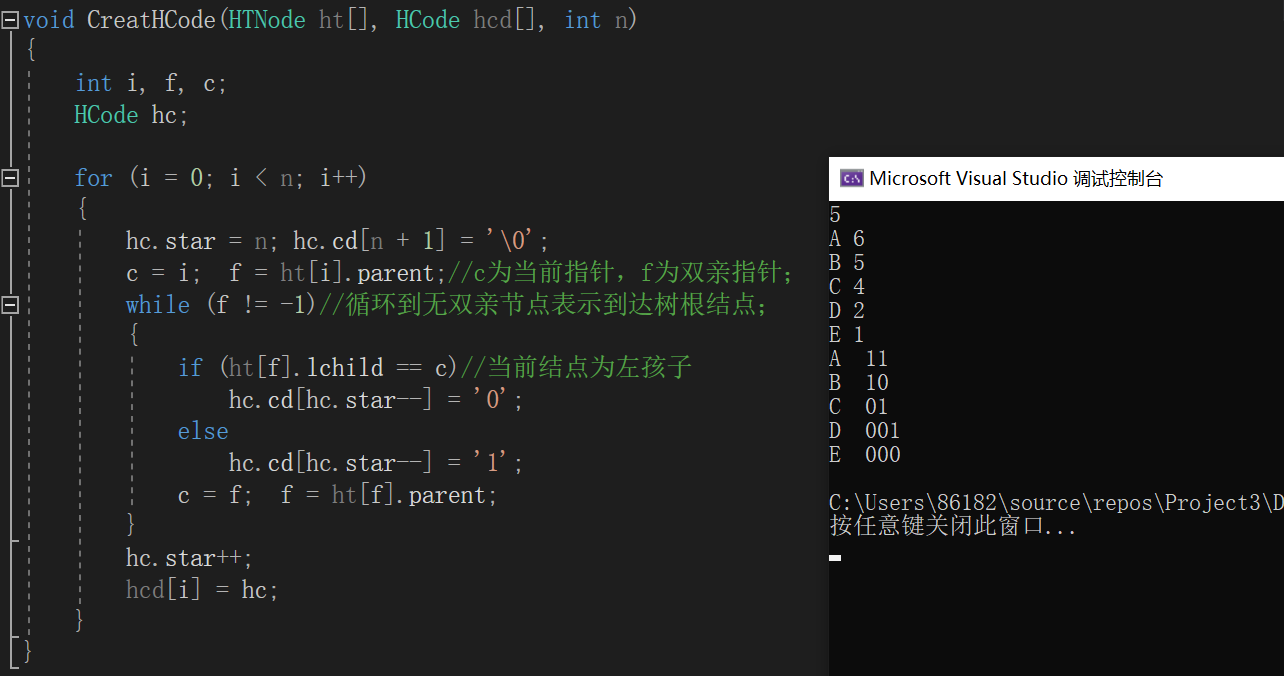
并查集
定义
在并查集中,每个分离集合对应的一棵树,称为分离集合树,整个并查集也就是一棵分离集合森林。
- 集合查找:在一棵高度较低的树中查找根节点的编号,所花时间较少,同一个集合标志就是根是一样的;
- 集合合并:两棵分离集合树A和B,高度分别为ha和hb,若ha>hb,应将b树作为a树的子树。将高度较小的分离集合树作为子树,得到的新的分离集合树c高度为hc=Max{ha,hb};
并查集的操作
结构体定义
typedef struct node
{
int data;//结点值;
int rank;//结点秩,子树高度,合并用;
int parent;//结点对应的双亲下标;
}UFSTree;
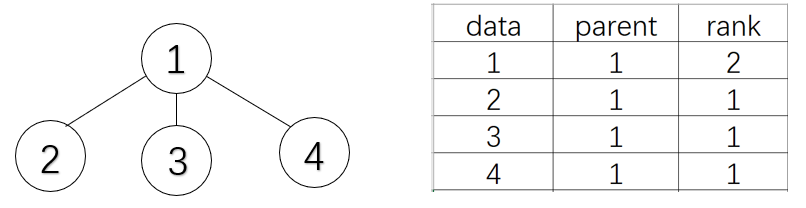
并查集初始化

查找一个元素所属的集合

两个元素各种所属集合的合并

应用
例题:朋友圈
思路
typedef struct node
{
int data;
int rank;
int parent;
}
int main()
{
定义结构体数组t保存每个人的信息;
定义静态数组friends保存每个人所在的朋友圈人数;
定义变量max记录最大的朋友圈人数;
定义变量parent记录每个圈子的组织者;
输入学生人数n和朋友圈个数m;
MAKE_SET(t,n);//初始化t,使每个人的双亲指针指向自己;
for i=0 to m
输入朋友圈的人数;
if(朋友圈人数不为0)//这里将第一位成员先暂定为该朋友圈的组织者
输入该朋友圈的组织者x;
for j=1 to k
输入该朋友圈的成员y;
UNION(t,x,y);//把头目x的朋友圈和成员的朋友圈合并;
end for
end for
for i=1 to n //寻找最大朋友圈人数;
parent=FindParent(t,i);//寻找编号为i的学生所在的朋友圈组织者;
friend[parent]++;//记录该头目朋友圈人数;
if(max<friend[parent])//边记录边寻找最大朋友圈人数
max=friends[parent];
end if
end for
}
代码


1.2学习体会
- 树是我们学习的第一个非线性结构,在生活中我们也可以看到树的运用非常的广泛,家谱,目录文件等等等,你都能在上面看到树的影子。刚开始接触觉得内容非常晦涩难懂,也不是很习惯用一种理性思维去思辨理解,完全就是靠死记。这样效率特别低,在后续的学习中要善于寻找规律和联系,而不是死磕。
- 树这章中许多的操作都和递归有关,递归对我来说是一个很神奇的存在,好懂的时候它真的很好懂,难的时候它也是真的难,有的时候简简单单的代码我都要看好久,递归对我来说是一大短板,我的原则就是能不递归就不递归。但是在阅读代码的时候发现递归的地位还是很重要的,对递归还是需要有更深层次的认识;
- 这次学习总结对我来说是对树的一个重新认识,感觉在学习过程中丢丢捡捡,总结过程中发现了许多细节上的小问题,比如引用符'&',你可不能小看这个小小的符号,真的!!细节决定成败!!在递归函数中,一个引用型形参就相当于一个全局变量。不要觉得在递归回来的时候数据还是原来的
亚子样子,在递归过程中早就已经被修改了,一定要注意! - 对于线索二叉树这部分的内容不是很理解,课外的学习还是不够多,也没有做一些知识积累,导致写博客的时候感觉没有什么课外的知识可以分享,希望之后能够合理调整自己的时间,多接触新的知识。
2.阅读代码
2.1 二叉树中最大路径和
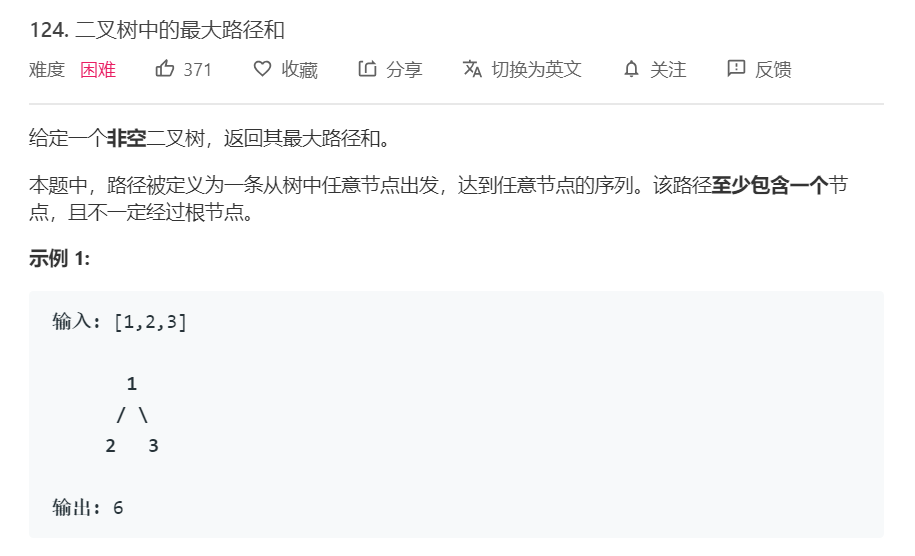

题目介绍:你可以从树中的任一节点走到某另一个结点,在不允许走回头路的情况下求某条路径中所有结点相加得到的结果最大。

代码
int maxPathSum(TreeNode* root, int &val)
{
if (root == nullptr) return 0;
int left = maxPathSum(root->left, val);
int right = maxPathSum(root->right, val);
int lmr = root->val + max(0, left) + max(0, right);
int ret = root->val + max(0, max(left, right));
val = max(val, max(lmr, ret));
return ret;
}
int maxPathSum(TreeNode* root)
{
int val = INT_MIN;
maxPathSum(root, val);
return val;
}
作者:ikaruga
链接:https://leetcode-cn.com/problems/binary-tree-maximum-path-sum/solution/er-cha-shu-zhong-de-zui-da-lu-jing-he-by-ikaruga/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2.1.1 设计思路
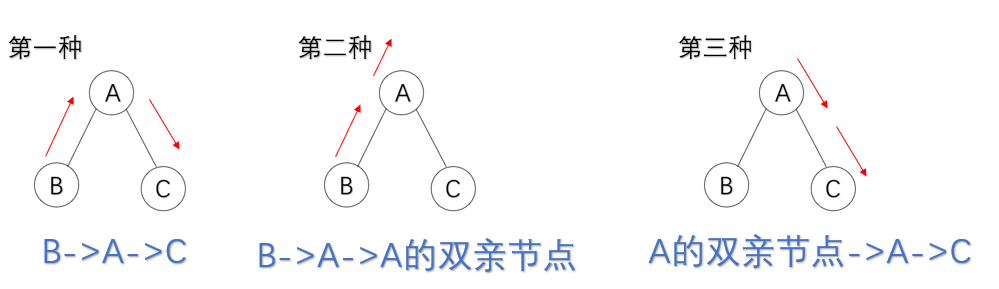
对于需要遍历树的情况我们首先就想到了使用递归的方法,从叶结点开始往根结点,一边遍历一边记录路径和,同时还要注意不能走回头路。对于每一个节点A都有三种不走回头路的路径:
第一种:不联络父节点,遍历完左子树B就遍历右子树C,此时不可将A+B+C的路径和再返回到上一级(A的父节点)的递归函数中,由题意可知"B->A->C->A的父节点"是一条非法路径,这里用lmr来记录该路径和;
第二种和第三种:只遍历左子树或者右子树,对于这两种情况,我们可以选择路径和最大的一种返回到上一级(A的父节点)递归函数中,我们用ret来记录这两种情况中最大的路径和;
在寻找最大路径和时,有些结点可能呢为负值,那么我们在寻找的过程中就要尽量舍弃负值(max(0,x));
在递归函数中我们引用了一个变量val实时记录全局中最大的路径和,我觉得这个是这段代码中最大的亮点!
- 时间复杂度O(n):所有结点都遍历了两边;
- 空间复杂度O(log(n)):我们需要一个大小与树的高度相等的栈开销,对于二叉树空间开销是 O(log(N))。
2.1.2 伪代码
int maxPathSum(TreeNode *root, int& val)
{
if(root==NULL)//当前结点为空
return 0;
end if
left计算左子树最大值,如果左子树最大值为负值便舍弃置为0;
right计算右子树最大值,如果右子树最大值为负值便舍弃置为0;
lmr=root->val+max(0,left)+max(0,right);//计算左子树+当前结点+右子树的路径;
ret =root->val+max(0,max(left,right));//得到左右子树中最大的路径和;
val=max(val,max(lmr,ret));//实时记录当前的最大路径和,这里的max(lmr,ret)可以直接改成lmr,lmr和ret相比一定是lmr较大!
return ret;//返回左子树和右子树中的最优路径;
}
2.1.3 运行结果

注:这里的建树方法用的是层次遍历。
2.1.4分析解题优势及难点。
- 优势:引用形参val可以记录全局最大路径和,即使输入的数据全部为负数,也可以保存最大结点的值。巧妙的利用max(0,x)来舍弃计算过程中出现的负值,为计算新路径和提供了便利。
- 难点:递归函数中对于第一种情况得到的路径和(lmr)不可递归!这点是一定一定要注意的点,也是我们容易忽视的点。且因为这是一个广度搜索,我们需要实时保存当前的最大路径和,一般大家都会想到设置一个全局变量,而这位作者引用形参val进行记录全局最大路径和。还有对于max(0,x)的理解:测试数据中出现负数,如果我们不对负值及时清零,这样就会影响到我们后面计算新的路径和,影响最后得到的最大路径和。
2.2二叉树转换为链表
题目

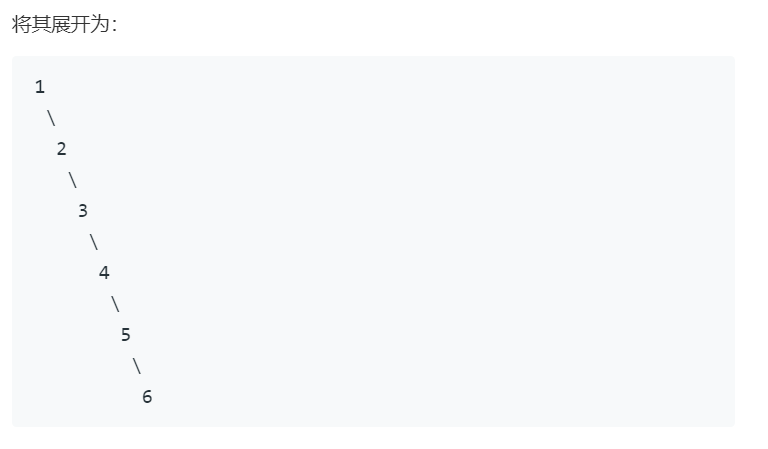
代码
class Solution {
public:
void flatten(TreeNode* &t) {
TreeNode * root=t;
while (root != nullptr) {
if (root->left != nullptr) {
auto most_right = root->left; // 如果左子树不为空, 那么就先找到左子树的最右节点
while (most_right->right != nullptr) most_right = most_right->right; // 找最右节点
most_right->right = root->right; // 然后将跟的右孩子放到最右节点的右子树上
root->right = root->left; // 这时候跟的右孩子可以释放, 因此我令左孩子放到右孩子上
root->left = nullptr; // 将左孩子置为空
}
root = root->right; // 继续下一个节点
}
return;
}
};
作者:hellozhaozheng
链接:https://leetcode-cn.com/problems/flatten-binary-tree-to-linked-list/solution/biao-biao-zhun-zhun-de-hou-xu-bian-li-dai-ma-jian-/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2.2.1 设计思路
从上往下遍历:
第一步:寻找结点root的左子树,如果左子树不为空,寻找左子树的最右结点most_right,把root的右子树接到most_right的右孩子上;
第二步:将root的左子树移到root的右子树上面,然后将root的左子树置为NULL;
第三步:root继续往下遍历;

- 时间复杂度O(n):每个结点最多遍历两次(1.作为根结点;2.作为root中右子树的一个结点)
- 空间复杂度O(1):只开辟了一个空间来存储root和一个临时的存储空间来存储临时变量most_right;
2.2.2 伪代码
定义结构体指针root用于遍历二叉树t;
while (root!=NULL)
if root左子树不为空
auto most_right=root->left;//设置一个临时变量most_right来存储root的左子树;
while (most_right->right!=NULL)
most_right=most_right->right;
end while
将root的右子树移到左子树的最右结点后面;
将root的左子树移到root的右子树上;
将root的左子树置为NULL;
end if
root=root->right;//遍历下一个结点;
end while
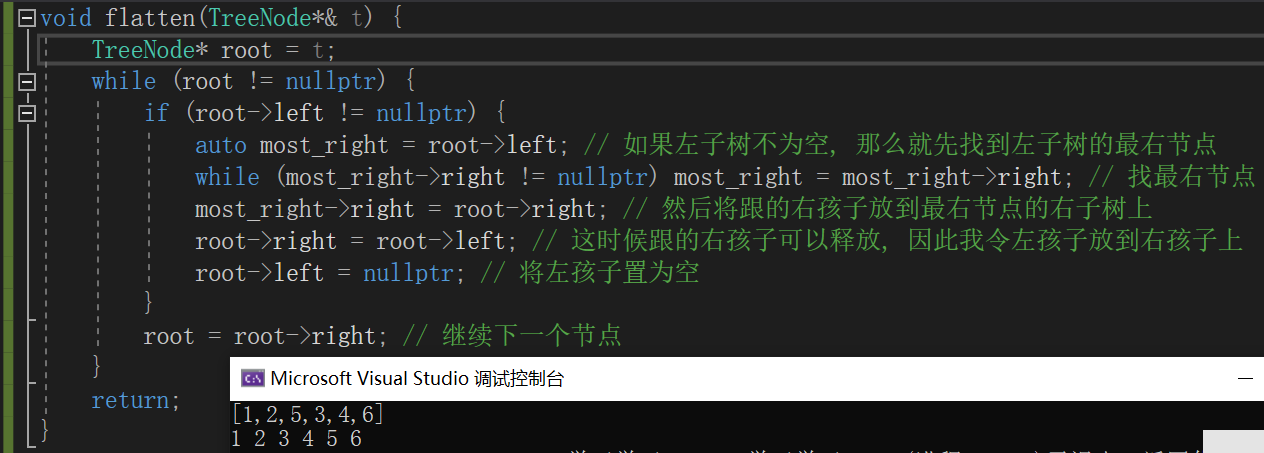
2.2.3 运行结果

2.2.4分析解题优势及难点
- 优势:我自己能想到的方法基本上都是要再开辟一段空间来保存二叉树中的数据,空间复杂度较大。而这种方法的空间复杂度只有O(1),基本上就是在原来的节点上面改变指向,不占用空间,且没有说为了减少对空间的占用而提高了时间复杂度,时间复杂度几乎和所有能实现这道题的方法是一样的。且这段代码思路清晰,比较容易理解和实现。
- 难点:如果是我刚看到这个题目我可能先想到的是先序遍历二叉树,然后重新建一条链出来保存二叉树的数据,想到上面这种方法的应该要对树的结构理解的很深,方法巧妙不容易想到。
2.3寻找x节点的所有祖先


class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if (!root || root == p || root == q) return root;
TreeNode *left = lowestCommonAncestor(root->left, p, q);
TreeNode *right = lowestCommonAncestor(root->right, p, q);
if (left && right) return root;
return left ? left : right;
}
};
作者:guohaoding
链接:https://leetcode-cn.com/problems/lowest-common-ancestor-of-a-binary-tree/solution/236-er-cha-shu-de-zui-jin-gong-gong-zu-xian-jian-j/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2.3.1 设计思路
使用的是递归算法,从左右子树中寻找p和q,p和q所处的位置分为两种情况:
-
第一种:p和q在相同的子树中:q,p中靠近根结点的为最近祖先;
-
第二种:p和q不在相同的子树中:说明一个在左子树,一个在右子树中,当left和right相遇时,当前结点就为最近祖先;
递归结束标志:找到结点q,p;

-
时间复杂度O(n):最坏情况要遍历所有的结点;
-
空间复杂度O(h):h为二叉树的高度;
2.3.2 伪代码
if(root为NULL||root==p||root==q)
return root;
end if
在root的左子树中寻找p和q,将结果赋给left;
在root的右子树中寻找p和q,将结果赋给right;
if(left && right)//说明在当前结点的左子树和右子树中分别找到p和q;
return root;//当前结点为最近祖先,返回当前结点;
end if
return left和right中不为空的结点;
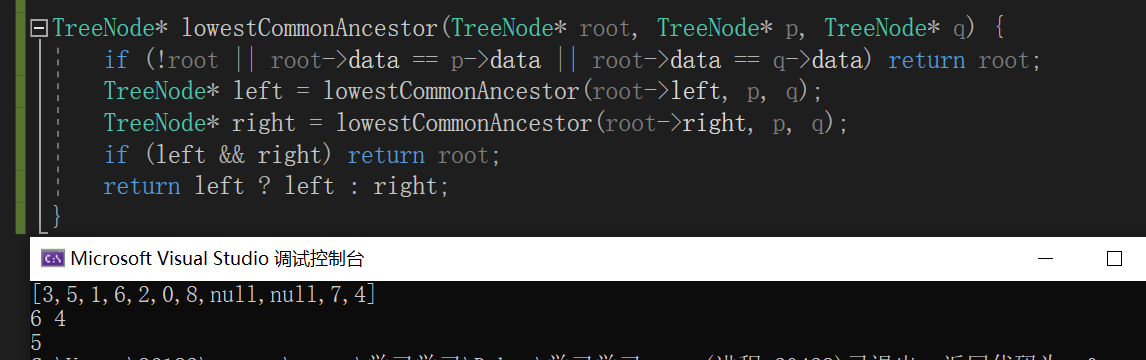
2.3.3 运行结果
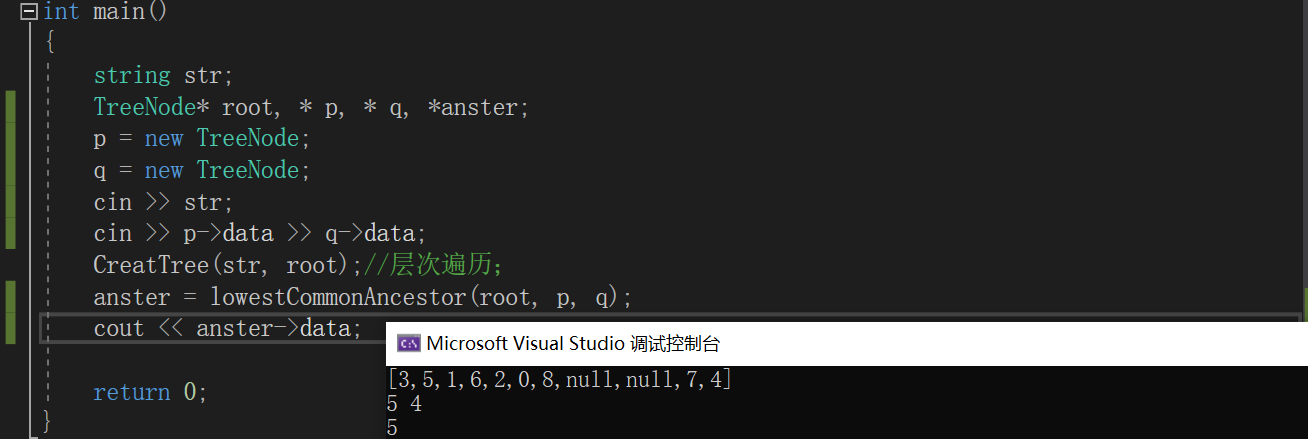
2.3.4分析解题优势及难点
- 优势:这道题目的解法有许多种,这种算法是所有算法中代码量最少且比较容易实现的。其他代码有些运用了回溯法还有并查集,我测试了其他算法,发现在所有算法时间复杂度几乎相等的情况下,递归算法的空间复杂度最小。
- 不足:因为题目明确告诉我们p和q结点是一定存在的,如果p和q其中有一个不存在,那么我们得到的结果应该为null,但是这种算法则得到的结果则会是存在的那个结点的值,这不是我们想要的结果。且如果两个结点在同一子树时,我们会发现,只要找到一个就会直接递归回上一级,没有再继续往下遍历,这样我们就无法确定另一个节点是否存在。所以这种算法值局限于两个结点都存在在二叉树的情况。如果有不存在的情况使用这种算法就会出错,所以如果题目设置二叉树中只存在一个结点时,我们可以在寻找最近祖先前,对两个结点进行一次查找,观察他们是否存在于二叉树中;
2.4恢复二叉搜索树
-
题目


-
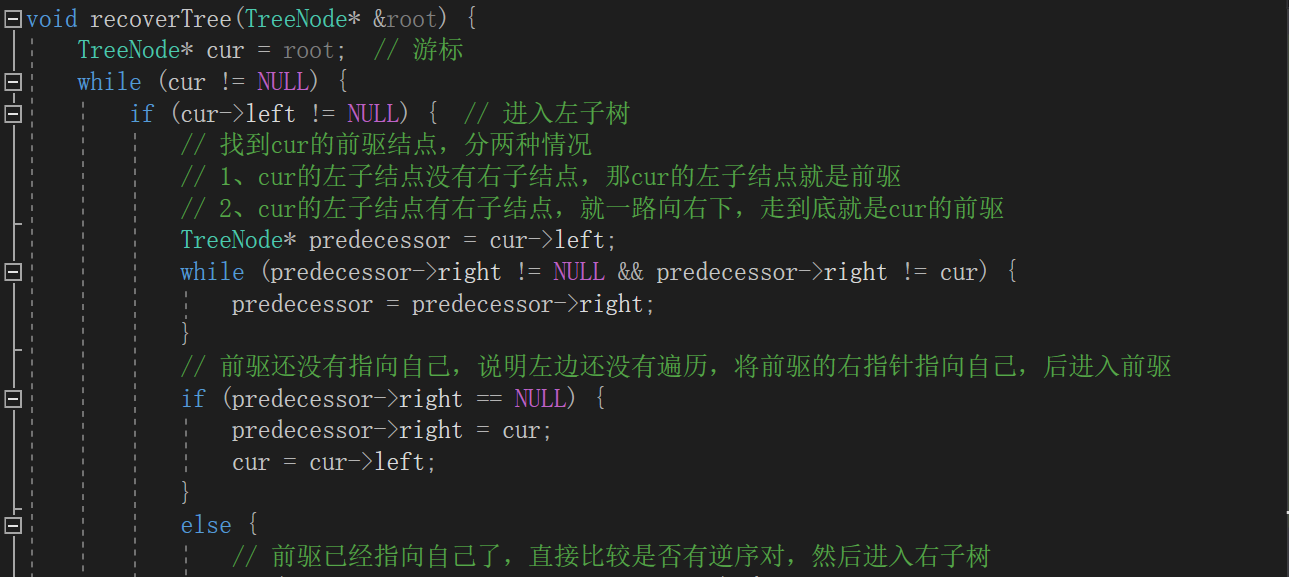
代码
class Solution {
public:
// s1 存小索引那个结点,s2存大索引那个结点,pre存前驱结点
TreeNode *s1 = NULL, *s2 = NULL, *pre = NULL;
void recoverTree(TreeNode* root) {
TreeNode* cur = root; // 游标
while(cur != NULL){
if(cur->left != NULL){ // 进入左子树
// 找到cur的前驱结点,分两种情况
// 1、cur的左子结点没有右子结点,那cur的左子结点就是前驱
// 2、cur的左子结点有右子结点,就一路向右下,走到底就是cur的前驱
TreeNode* predecessor = cur->left;
while(predecessor->right != NULL && predecessor->right != cur){
predecessor = predecessor->right;
}
// 前驱还没有指向自己,说明左边还没有遍历,将前驱的右指针指向自己,后进入前驱
if(predecessor->right == NULL){
predecessor->right = cur;
cur = cur->left;
}else{
// 前驱已经指向自己了,直接比较是否有逆序对,然后进入右子树
if(pre != NULL && cur->val < pre->val){
if(s1 == NULL) s1 = pre;
s2 = cur;
}
pre = cur;
predecessor->right = NULL;
cur = cur->right;
}
}else{ // 左子树为空时,检查是否有逆序对,然后进入右子树
if(pre != NULL && cur->val < pre->val){
if(s1 == NULL) s1 = pre;
s2 = cur;
}
pre = cur;
cur = cur->right;
}
}
// 进行交换
int t = s1->val;
s1->val = s2->val;
s2->val = t;
return;
}
};
作者:aspenstarss
链接:https://leetcode-cn.com/problems/recover-binary-search-tree/solution/zhong-xu-bian-li-shuang-zhi-zhen-zhao-ni-xu-dui-mo/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2.4.1 设计思路
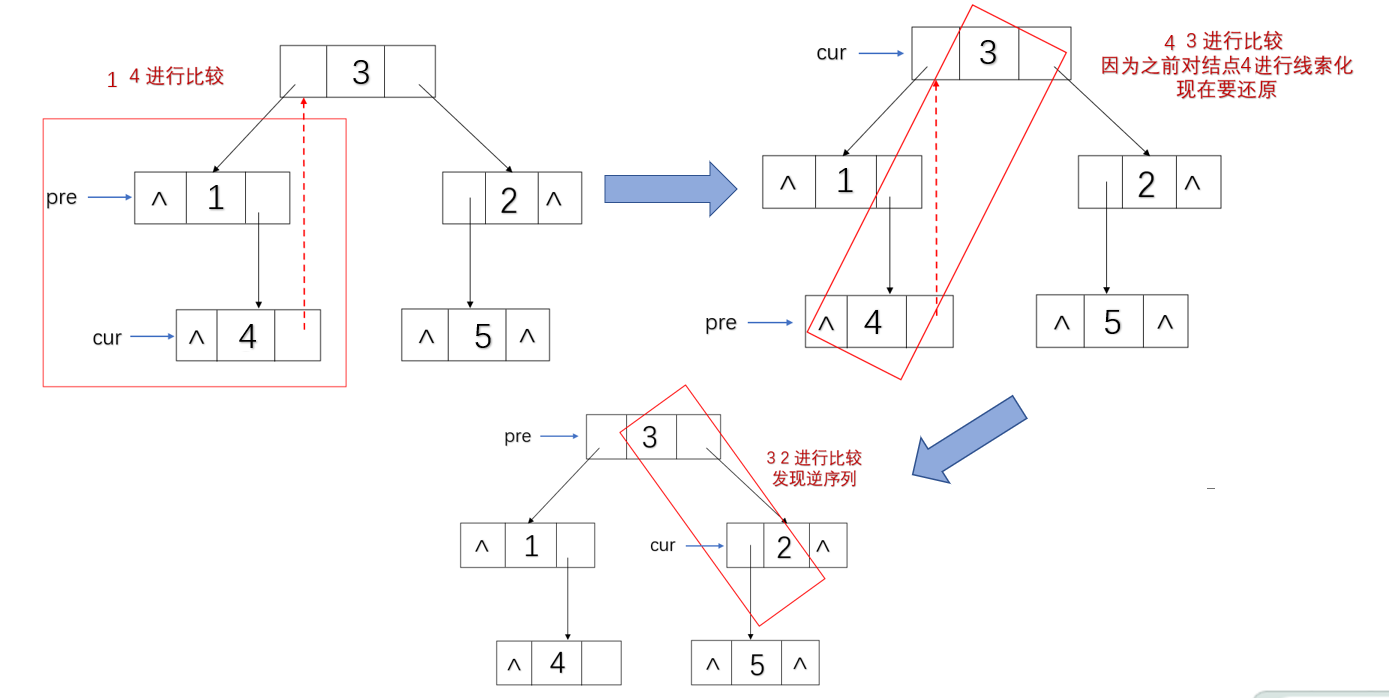
这里运用了morris算法。我们知道二叉搜索树的左子树所有节点值都小于根节点,右子树中所有节点值都大于根节点,按照中序遍历我们就能得到一个升序序列。我们可以通过观察某二叉树的中序序列来判断是哪两个节点交换了位置。因为是在有序序列中,如果交换两个数值的位置,在两两相邻数据进行比较时,会出现1个(相邻两个数据进行调换)或两个(不相邻的两个数据进行调换)逆序对。所以我们可以设置两个指针cur(指向当前结点)和pre(指向前驱结点)来检查序列中的逆序对。
- 第一次出现逆序对:将cur指向的结点和pre指向的结点都保存起来(有可能相邻);
- 第二次出现逆序对:保存cur指向的结点,此时cur指向的结点和第一次出现逆序对pre指向的结点就为交换的两个结点;

morris算法
在二叉搜索树中,如果一个结点有前驱结点,那么前驱结点pre的右指针只有两种情况:是空的 或者 是这个结点本身(即前驱是它的父结点)
所以我们可以把前驱结点的右指针这一特性利用起来,从而降低空间复杂度。
步骤如下:
-
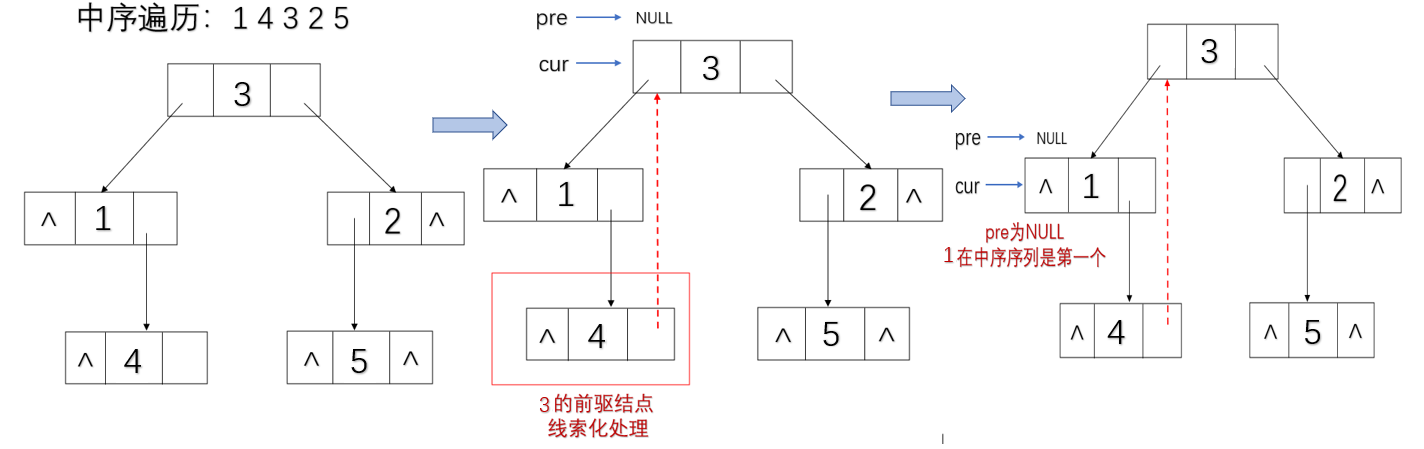
检查当前结点cur的左孩子:
-
如果当前结点cur的左孩子不为空,说明左子树里肯定有它的前驱,那就找到这个前驱
- 如果用于寻找前驱结点predecessor的右孩子是空,说明还没检查过左子树,那么把前驱结点predecessor的右孩子指向当前结点(注意这里是对predecessor指向的结点进行处理,不是对pre)然后把左子树进行线索化。
- 如果当前结点的前驱结点其右孩子指向了cur,说明左子树已被检查过,直接判断pre和cur是否为逆序对,然后把前驱结点pre的右孩子设置为空,恢复原树,cur再进入右孩子进行寻找。
-
如果当前结点cur的左孩子为空,说明要不没有前驱,要不前驱是它的父结点,所以直接进行检查,cur再进入右孩子。
-
时间复杂度O(n):每个结点访问了两次;
-
空间复杂度O(1):没有使用递归算法,只使用了常数个空间;
2.4.2 伪代码
while(当前结点cur不为空)
if(当前结点cur有左子树)
predecessor用于寻找前驱结点
if(前驱结点还没有指向自己)
说明cur的左子树还未线索化;将前驱的右孩子结点指向自己
cur进入左子树进行线索化;
else //说明左子树已经线索化完毕
对pre和cur进行比较,判断是否有逆序对;
if(存在逆序对)
if(是第一次出现逆序)
保存pre结点;
end if
cur不管第一次和第二次都要保存;
end if
将前驱结点的右孩子还原为空,cur进入右子树;
end if
else //cur没有左子树,就不需要再找前驱结点;
if (pre不为空&&有逆序对)
if(是第一次出现逆序)
保存pre;
end if
cur不管第一次和第二次都要保存;
end if
end if
end while
2.4.3 运行结果


2.4.4分析解题优势及难点
- 优势:没有使用递归算法,减少了对空间的利用;巧妙运用线索二叉树的中序遍历中前驱结点右孩子的特性,将二叉树中的每个结点都暂时联系起来;在运算过程中虽然暂时将二叉树转换为线索二叉树,但是最后又还原回原来的二叉树结构;设置predecessor用来寻找前驱结点,保护pre的值不被修改;
- 难点:在我们寻找前驱结点时,要注意使用predecessor去找前驱,而不是直接用pre去寻找。我当初不理解为什么要多设一个变量predecessor去寻找前驱结点,以为直接对pre进行处理就可,但是这样在遍历到中序序列中第一个位置的结点时,pre不为空,但是第一个位置的结点并没有前驱,这样就会出现错误;对于线索二叉树的接触不是很多,算法比较难想到。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号