CTR预估经典模型总结
计算广告领域中数据特点:
1 正负样本不平衡
2 大量id类特征,高维,多领域(一个类别型特征就是一个field,比如上面的Weekday、Gender、City这是三个field),稀疏
在电商领域,CTR预估模型的原始特征数据通常包括多个类别,比如[Weekday=Tuesday,
Gender=Male, City=London, CategoryId=16],这些原始特征通常以独热编码(one-hot encoding)的方式转化为高维稀疏二值向量,多个域(类别)对应的编码向量链接在一起构成最终的特征向量。
![]()
高维、稀疏、多Field是输入给CTR预估模型的特征数据的典型特点。以下介绍的模型都假设特征数据满足上述规律,那些只适用于小规模数据量的模型就不介绍了。
常用模型如下:
1 LR 2 LR+GBDT 3 FM或者FFM 4 混合逻辑回归MLR
5 WDL 6 FNN (Factorization-machine supported Neural Network)
7. PNN(Product-based Neural Networks) 8.DeepFM 9.DIN
本文将从多种视角来观察这些模型,如输入数据的特点、从神经网络的视角,网络结构的组成方式,串并联结构,特征组合的方式等等。
首先从三种基本模型展开
LR ->(LR, MLR, GBDT+LR)
FM -> (FM, FFM)
DNN与FM的结合 (embedding +MLP)
1 串联(改进FM元素乘法) FM改进后加DNN FNN(FM预训练得到嵌入向量) PNN NFM AFM
2 并联(改进DNN,引入resnet) WDL、DeepFM、 DeepCrossNetWork
交叉方式: bit-wise和vector-wise
plain-DNN(MLP)的高阶特征交互建模是元素级的(bit-wise),也就是说同一个域对应的embedding向量中的元素也会相互影响。
FM类方法是以向量级(vector-wise)的方式来构建高阶交叉关系。 经验上,vector-wise的方式构建的特征交叉关系比bit-wise的方式更容易学习。
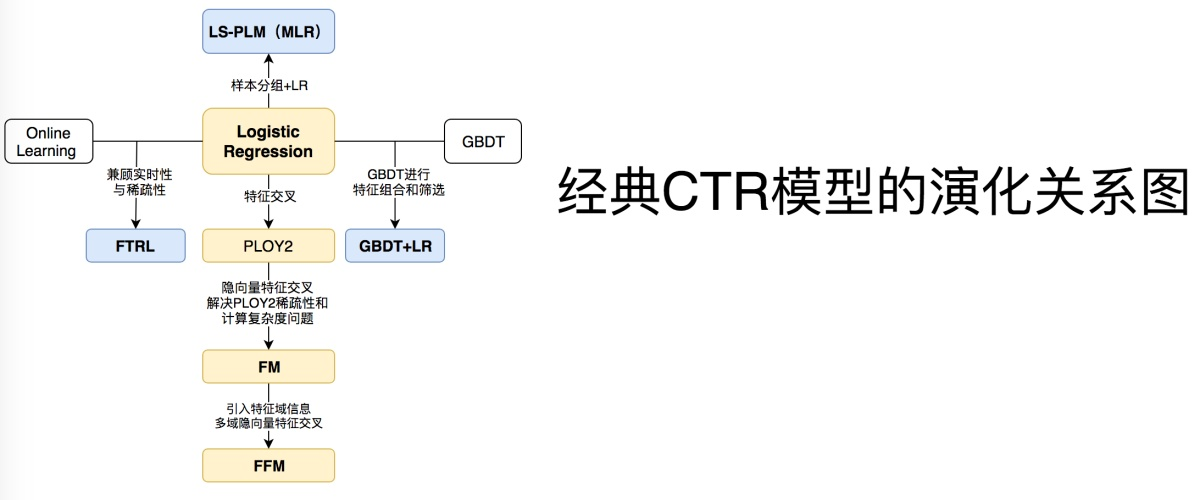
1 LR家族
1 LR:
LR模型是广义线性模型,从其函数形式来看,LR模型可以看做是一个没有隐层的神经网络模型(感知机模型)
LR模型一直是CTR预估问题的benchmark模型,由于其简单、易于并行化实现、可解释性强等优点而被广泛使用。然而由于线性模型本身的局限,不能处理特征和目标之间的非线性关系,因此模型效果严重依赖于算法工程师的特征工程经验。为了让线性模型能够学习到原始特征与拟合目标之间的非线性关系,通常需要对原始特征做一些非线性转换。常用的转换方法包括:连续特征离散化、特征之间的交叉等。
LR的优化算法FTRL:


2 GBDT + LR
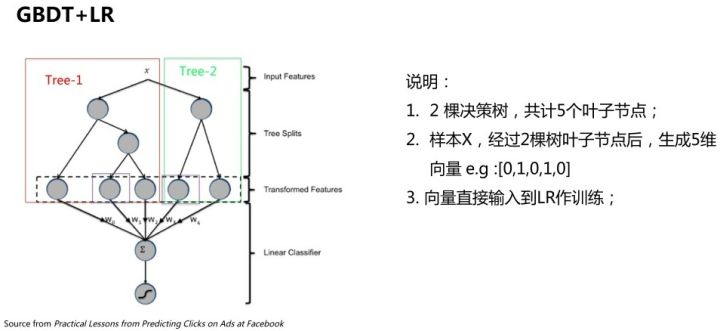
GBDT模型能够学习高阶非线性特征组合,对应树的一条路径(用叶子节点来表示)。通常把一些连续值特征、值空间不大的categorical特征都丢给GBDT模型;空间很大的ID特征(比如商品ID)留在LR模型中训练,既能做高阶特征组合又能利用线性模型易于处理大规模稀疏数据的优势。
3 混合逻辑回归(MLR)
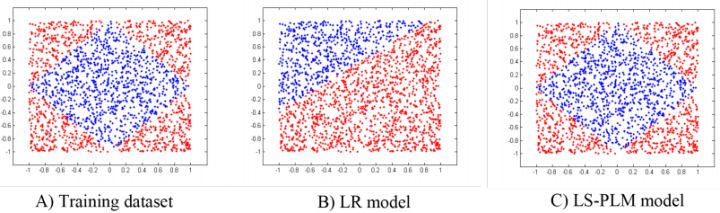
MLR算法是alibaba在2012年提出并使用的广告点击率预估模型,2017年发表出来。MLR模型是对线性LR模型的推广,它利用分片线性方式对数据进行拟合。基本思路是采用分而治之的策略:如果分类空间本身是非线性的,则按照合适的方式把空间分为多个区域,每个区域里面可以用线性的方式进行拟合,最后MLR的输出就变为了多个子区域预测值的加权平均。如下图(C)所示,就是使用4个分片的MLR模型学到的结果。
上式即为MLR的目标函数,其中 为分片数(当
时,MLR退化为LR模型);
是聚类参数,决定分片空间的划分,即某个样本属于某个特定分片的概率;
是分类参数,决定分片空间内的预测;
和
都是待学习的参数。最终模型的预测值为所有分片对应的子模型的预测值的期望。
MLR模型在大规模稀疏数据上探索和实现了非线性拟合能力,在分片数足够多时,有较强的非线性能力;同时模型复杂度可控,有较好泛化能力;同时保留了LR模型的自动特征选择能力。
MLR模型的思路非常简单,难点和挑战在于MLR模型的目标函数是非凸非光滑的,使得传统的梯度下降算法并不适用。相关的细节内容查询论文:Gai et al, “Learning Piece-wise Linear Models from Large Scale Data for Ad Click Prediction” 。
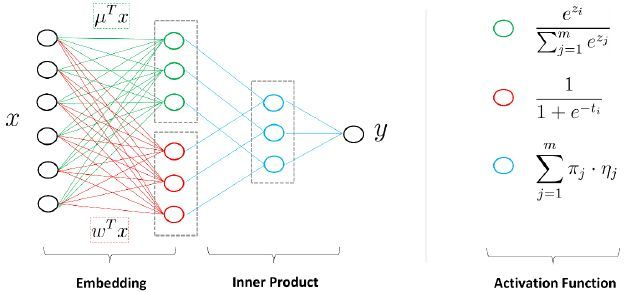
另一方面,MLR模型可以看作带有一个隐层的神经网络。如下图, 是大规模的稀疏输入数据,MLR模型第一步是做了一个Embedding操作,分为两个部分,一种叫聚类Embedding(绿色),另一种是分类Embedding(红色)。两个投影都投到低维的空间,维度为
,是MLR模型中的分片数。完成投影之后,通过很简单的内积(Inner Product)操作便可以进行预测,得到输出
。
2 FM家族
通过神经网络的视角来理解CTR模型:
前面介绍过广告领域的数据都是由one-hot表示的,如果直接连接DNN,会导致输入参数过度,所以通常需要做embedding,避免全连接,分而治之,让Dense Vector进行组合,那么高阶特征的组合就出来了,但是低阶和高阶特征组合隐含地体现在隐藏层中,如果我们希望把低阶特征组合单独建模,然后融合高阶特征组合。即将DNN与FM进行一个合理的融合:二者的融合总的来说有两种形式,一是串行结构,二是并行结构
embedding+MLP:深度学习CTR预估的通用框架
1 embedding表示 2 对embedding向量进行拼接、交叉等等特征组合 3 DNN结构
1 对不同领域的one-hot特征进行嵌入(embedding),使其降维成低维度稠密特征。
2 然后将这些特征向量拼接(concatenate)成一个隐含层。
3 之后再不断堆叠全连接层,也就是多层感知机(Multilayer Perceptron, MLP,有时也叫作前馈神经网络)。
4 最终输出预测的点击率。

如何连接FM与DNN有两种方式: 1 串联 2 并联
串联模型主要有:FNN、Product-based Neural NetWork 、Neual factorization machines 、 Attenation-Based Factorization machines
并联模型主要有: WDL,DeepFM、DeeoCrossNetWork
此外还需要注意一个问题:如何处理多个领域的嵌入特征?
1 拼接 FNN
2 交叉 NFM
3 不同类型的向量乘法: PNN
FM ->(FNN, NFM)
2.1基本结构
FM:嵌入后再进行内积
FM的实际应用:考虑领域信息
FM与GBDT的区别:
1 使用数据不同, FM使用于处理高维稀疏数据,而GBDT在高位稀疏数据上容易产生过拟合。
2 GBDT可以做高阶特征组合,而FM只能做二阶特征组合。
1 GBDT的优势在于处理连续值特征,比如用户历史点击率,用户历史浏览次数等连续值特征。而且由于树的分裂算法,它具有一定的组合特征的能力,
模型的表达能力要比LR强。GBDT对特征的数值线性变化不敏感,它会按照目标函数,自动选择最优的分裂特征和该特征的最优分裂点,而且根据特征的分裂次数,
还可以得到一个特征的重要性排序。所以,使用GBDT减少人工特征工程的工作量和进行特征筛选。
2 GBDT善于处理连续值特征,但是推荐系统的绝大多数场景中,出现的都是大规模离散化特征,如果我们需要使用GBDT的话,则需要将很多特征统计成连续值特征(或者embedding),
这里可能需要耗费比较多的时间。同时,因为GBDT模型特点,它具有很强的记忆行为,不利于挖掘长尾特征,而且GBDT虽然具备一定的组合特征的能力,但是组合的能力十分有限,远不能与dnn相比。
3 树分裂的时候,选择连续值特征,等于选择了一个特征,选择离散化特征,却等于选择了一个特征的某一维,这样子往往会造成离散化特征形同虚设。
基础结构 FM与FFM:
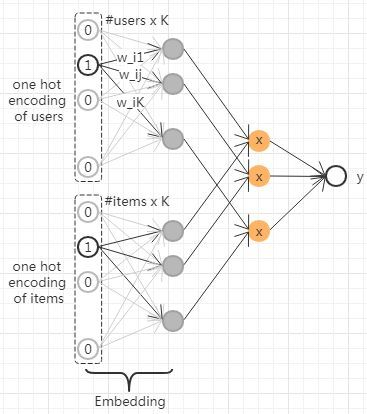
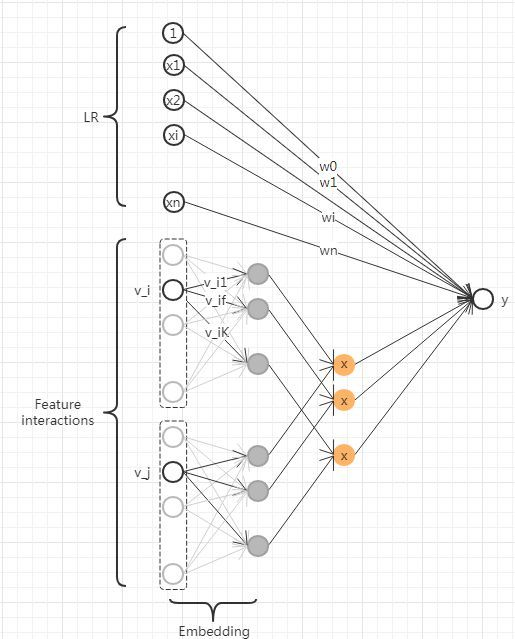
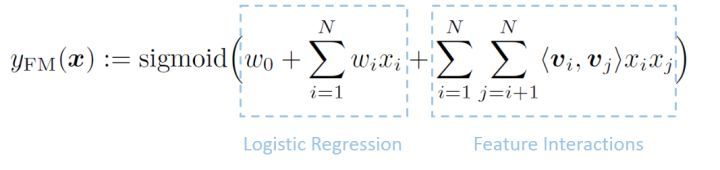
从神经网络的视角来看,MF相当于为user和iem引入了嵌入向量,而FM为所有的离散特征引入了嵌入向量,降低了参数的数量,而FFM结合广告领域数据的多field特点,将不同field的特征交叉与同一filed的特征交叉进行区分,为每一维特征引入了多个隐向量。
2.2 串联模型(FM与DNN串联):
FNN:
FM + MLP 相当于用FM模型得到了每一维特征的嵌入向量,做了一次特征工程,得到特征送入分类器,不是端到端的思路,有贪心训练的思路。

NFM:通过逐元素乘法延迟FM的实现过程

10.AFM: 对简化版NFM进行加权求和
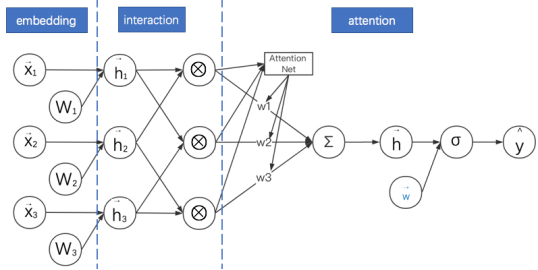
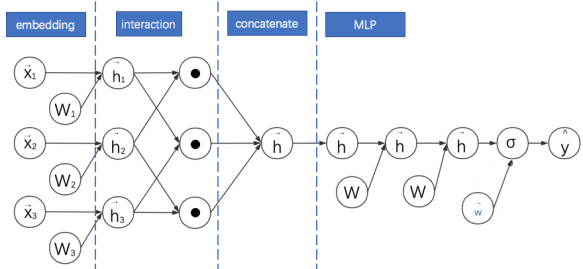
11.PNN:通过改进向量乘法运算延迟FM的实现过程
2.3 并联模型(FM与DNN并联)
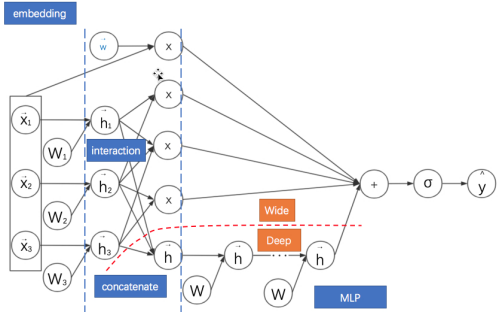
DeepFM: FM与MLP的并联结合
DCN:高阶FM的降维实现

Cross Network的输出就相当于 不断乘以一个数,当然这个数是和
高度相关的。
- CrossNet的输出被限定在一种特殊的形式上
- 特征交叉还是以bit-wise的方式构建的
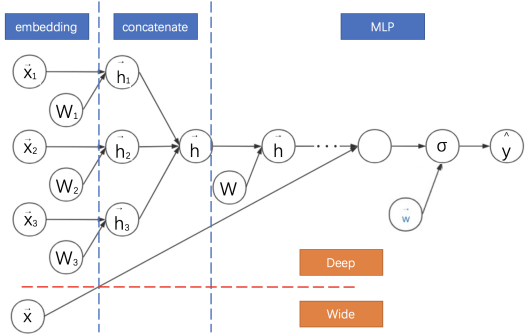
Wide&Deep: DeepFM与DCN的基础框架
xDeepFM:
为了实现自动学习显式的高阶特征交互,同时使得交互发生在向量级上,xDeepFM首先提出了一种新的名为压缩交互网络(Compressed Interaction Network,简称CIN)的模型。
CIN的输入是所有field的embedding向量构成的矩阵 ,该矩阵的第
行对应第
个field的embedding向量,假设共有
个field,每个field的embedding向量的维度为
。CIN网络也是一个多层的网络,它的第
层的输出也是一个矩阵,记为
,该矩阵的行数为
,表示第
层共有
个特征(embedding)向量,其中
。
CIN中第 层的输出
由第
层的输出
和输入
经过一个比较复杂的运算得到,具体地,矩阵
中的第
行的计算公式如下:
其中, 表示哈达玛积,即两个矩阵或向量对应元素相乘得到相同大小的矩阵或向量,示例如:
。
上述计算公式可能不是很好理解,论文作者给出了另一种更加方便理解的视角。在计算 时,定义一个中间变量
,
是一个数据立方体,由D个数据矩阵堆叠而成,其中每个数据矩阵是由
的一个列向量与
的一个列向量的外积运算(Outer product)而得,如图3所示。
的生成过程实际上是由
与
沿着各自embedding向量的方向计算外积的过程。
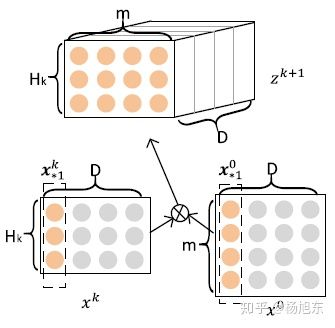
可以被看作是一个宽度为
、高度为
、通道数为
的图像,在这个虚拟的图像上施加一些卷积操作即得到
。
是其中一个卷积核,总共有
个不同的卷积核,因而借用CNN网络中的概念,
可以看作是由
个feature map堆叠而成,如图4所示。
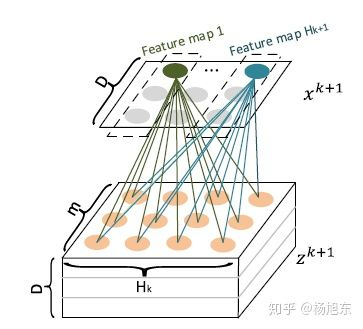
正是通过卷积操作,CIN把第 层由
个向量压缩到了
个向量,起到了防止维数灾难的效果。
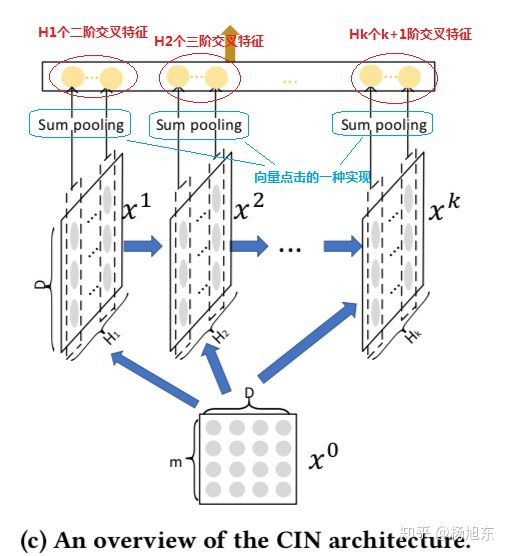
CIN的宏观框架如下图所示,它的特点是,最终学习出的特征交互的阶数是由网络的层数决定的,每一层隐层都通过一个池化操作连接到输出层,从而保证了输出单元可以见到不同阶数的特征交互模式。同时不难看出,CIN的结构与循环神经网络RNN是很类似的,即每一层的状态是由前一层隐层的值与一个额外的输入数据计算所得。不同的是,CIN中不同层的参数是不一样的,而在RNN中是相同的;RNN中每次额外的输入数据是不一样的,而CIN中额外的输入数据是固定的,始终是 。
有了基础结构CIN之后,借鉴Wide&Deep和DeepFM等模型的设计,将CIN与线性回归单元、全连接神经网络单元组合在一起,得到最终的模型并命名为极深因子分解机xDeepFM,其结构如下图所示。同时包含多种不同的结构成分可以提升模型的表达能力。

集成的CIN和DNN两个模块能够帮助模型同时以显式和隐式的方式学习高阶的特征交互,而集成的线性模块和深度神经模块也让模型兼具记忆与泛化的学习能力。值得一提的是,为了提高模型的通用性,xDeepFM中不同的模块共享相同的输入数据。而在具体的应用场景下,不同的模块也可以接入各自不同的输入数据,例如,线性模块中依旧可以接入很多根据先验知识提取的交叉特征来提高记忆能力,而在CIN或者DNN中,为了减少模型的计算复杂度,可以只导入一部分稀疏的特征子集。
3 总结:
从LR出发有四个方向,结合GBDT,结合聚类,结合在线学习,引入FM进行特征交叉,而FM引入了二阶组合关系,同时又可以引入DNN,引入高阶特征交叉,可以从串联与并联的视角来
来观察,串联方式: FNN、NFM、AFM、PNN; 并联方式: WDL deepFM DeepCross,XdeepFM。
特征交叉方式又可以分为两种,
bitewise与vectorWise,bite代表embedding向量中的某一个元素,所以同一领域内的元素也可以进行交叉,但是可解释性不强,例如FNN、PNN、和DeepFM,其缺点是模型学习出来的是隐式的交互特征,其形式是未可知的,
不可控的,同时它们的特征交互是发生在元素级(bit-wise),而不是特征向量之间(vector-wise),这一点违背了因子分解机的初衷。Google在2017年引入了DCN模型,其表现形式是一种很特殊的向量扩张,但是特征交互依旧发生在元素级别上。所以可以从两方面理解特征交互,显示与隐式特征交互,元素级别的交互与向量级别的交互。
同vectorwise相比,vector wise是向量级的交叉,有没有可能引入更高阶的vector-wise的交叉特征,同时又能控制模型的复杂度,避免产生过多的无效交叉特征呢?应对维数挑战艰难呢?必然要引入一定的压缩机制,就是要把高阶的组合特征向量的维数降到一个合理的范围,同时在这个过程中尽量多的保留有效的交叉特征,去除无效的交叉特征。DCN引入cross层,对输入的X0向量做乘数变化,同时也是bitwise的交叉方式。极深因子分解机xDeepFM模型是自动构建交叉特征且能够端到端学习的集大成者,引入CIN网络,将二阶交叉,三阶交叉特征、一直到k+1阶交叉特征,都送入到最终输入中去。集成的CIN和DNN两个模块能够帮助模型同时以显式和隐式的方式学习高阶的特征交互,而集成的线性模块和深度神经模块也让模型兼具记忆与泛化的学习能力。
神经网络最开始都是经过Embedding把原始高纬度稀疏的输入转换为低维度稠密的向量,PNN也不例外。对于FM来说,这就是隐向量,FNN也是利用FM来进行Embedding Vector的初始化的。
处理流程: 通过设计网络结构进行组合特征的挖掘。
基本网络框架: Embedding Layer、Product Layer、Full-connect Layer。
从神经网络的视角看FM
1 embedding + MLP embedding + concatenate + MLP
embedding+MLP的缺点是只学习高阶特征组合,对于低阶或者手动的特征组合不够兼容,而且参数较多,学习较困难。
而dnn类的模型拥有很强的模型表达能力,而且其结构也是“看上去”天然具有特征交叉的能力。利用基于dnn的模型做ctr问题主要有两个优势:
1. 模型表达能力强,能够学习出高阶非线性特征。
2. 容易扩充其他类别的特征,比如在特征拥有图片,文字类特征的时候。
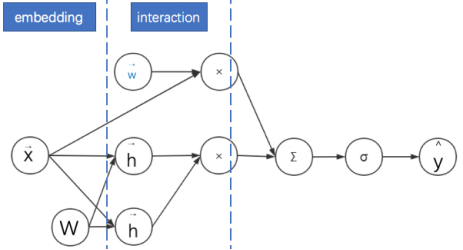
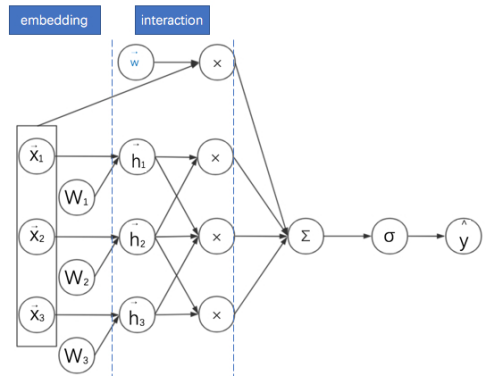
2 FM : embedding + interaction 可以看成一个三层的神经网络。后面的二次项,可以看成神经网络embedding后,然后每两个向量做内积。
3 考虑领域信息的FM: embedding + interaction
串并联网络结构
4 FNN:FM与MLP的串联结合 embedding(FM预训练) + concatenate + MLP
5 DeepFM: FM与MLP的并联结合 embedding + interaction/concatenate + MLP
特征交叉方式 改进元素乘法 和 网络串联结构,改进元素乘法从中也可以看出网络是串联结构。
6 NFM:通过逐元素乘法延迟FM的实现过程 embedding + interation(逐元素乘法) +MLP
7 AFM: 对简化版NFM进行加权求和 embedding + interaction + attenation
8 PNN:通过改进向量乘法运算延迟FM的实现过程 embedding + interation(内积) + concatenate + MLP
PNN的结构为embeddding+product layer + fcs。
而PNN使用product的方式做特征交叉的想法是认为在ctr场景中,特征的交叉更加提现在一种“且”的关系下,而add的操作,是一种“或”的关系,
所以product的形式更加合适,会有更好的效果。
特征交叉方式与 网络并联结构
9 DCN:高阶FM的降维实现 embedding + stack + deep/cross
11 Deep Cross: DCN由其残差网络思想进化 embedding + stack + resnet
12Wide&Deep: DeepFM与DCN的基础框架 embedding + concatenate + MLP
12 DIN 深度兴趣网络
12 ESSM 多任务
embedding + MLP
attenation 求和
FM ResNet 特征组合
4 模型对比:
从神经网络的角度来看
角度一: 网络架构 embedding layer + shallow/stack layer + FC layer
1. 是否保留浅层模型 (存在不保留shallow part的model,比如FNN,PNN。
PNN与FM相比,舍弃了低阶特征,也就是线性的部分,这在一定程度上使得模型不太容易记住一些数据中的规律。WDL(Wide & Deep Learning)模型混合了宽度模型与深度模型,其宽度部分保留了低价特征,偏重记 忆;深度部分引入了bit-wise的特征交叉能力
2. 如何体现特征交叉性,即stack layer的做法是什么。concatenate?Bi-interaction?直接向量加法?。。。等等
cross network的设计思想是利用乘法计算代表特征交叉。而在论文的后面篇章中,它证明了cross network可以拟合任意多项式的表达形式,
所以可以涵盖非常高阶的特征交叉。个人觉得它的亮点在于设计了 x_{0}x_l}^{T} 这种表达特征交叉的计算方式,使得特征交叉通过一个rank-one的数字来表示了,
大大减少了参数量。但值得注意的是DCN只包含了deep part的结构,没有shallow part的结构(lr or fm)。
3. embedding + fc(全连接层)是基本标配。
角度二:网络串并联结构
1 并联 串联 (FM与DNN关系)
2 并联: DeepFM wide and deep DCN
3 串联: PNN NFM AFM
角度三: 各种DNN+FM模型如何简化成FM
1 NFM 当MLP的全连接层都是恒等变换且最后一层参数全为1时,NFM就退化成了FM。
2 AFM 权重都相等时,AFM退化成无全连接层的NFM
3 PNN 当MLP的全连接层都是恒等变换且最后一层参数全为1时,内积形式的PNN就退化成了FM。/PNN把NFM的逐元素乘法换成了外积。
4 DCN 只有两层且第一层与最后一层权重参数相等时的Cross网络与简化版FM等价。
角度四: 特征组和的方式
1 树系列
2 FM系列
3 DNN
不同类型向量乘法

如何做特征工程一直是一个具体问题具体分析的事情,CTR预估模型主要其实是在特征组合上做文章,LR处理一阶,FM处理二阶特征组合,DNN与GBDT处理高阶的特征组合,而DNN与FM的区别在于:DNN做
特征组合时是针对bitwise的,而FM是vector-wise的。通过原始特征隐向量内积构建vector-wise的二阶交叉特征,FM,deepFM,inner-PNN。简单来说,在CTR领域中,特征一般分为两种类别型特征和数值型特征,对于高维稀疏数据,特征组合是一把利器,往往先对类别型特征做一次embedding,那么
此时的输入就会有两种,一种是(batch_size, filed_size, embedding_size)直接输入,作为FM特征交叉的输入,另外一种是将其拉平变成(batch_size, units),作为DNN的输入,其实还可以将FM的输出作为DNN的输入,这也就是NFM的来源,将FM替换成FFM,也就成了NFFM.
此外为何要做特征组合,拿Wide and Deep来说,wide部分侧重记忆,保证泛化能力,deep部分引入了bit-wise的特征交叉,更加具体地描述特征之间的关系。简单来说,粗粒度的特征保证模型的泛化能力,细粒度的特征增强
模型的刻画能力,细粒度的特征对活跃用户比较友好,可以更精确地刻画他的喜好,提供更个性化的商品排序,而粗粒度的特征是为了服务不活跃用户,甚至是新用户,用大数据总结的一般规律来提供商品排序,粗细结合,
整体局部。这也就为我们处理冷启动问题,提供了思路,不同粒度的去考虑问题。
角度五:
FNN的embedding向量需要FM预训练得到,DeepFM中Deep部分与FM部分共用嵌入向量,WDL中Wide部分侧重记忆,deep部分侧重泛化能力,输入特征类型不同,wide部分需要特征交叉。
复现框架: 可以顺着理一下思路,来处理各类CTR预估模型,
数据结构:
feature_dim_dict: 记录类别型特征与数值型特征的属性(名字,维度)
sparse_input_dict: 记录类别型特征征的属性(名字,维度)
dense_input_dict: 记录数值型特征与数值型特征的属性(名字,维度)
inputs_list : 记录输入特征tensor表, 不做embedding
deep_emb_list 记录输入特征嵌入后tensor表,提供给FM层,包括类别型特征与连续型特征,对于数值型特征的嵌入处理,可以增加一个Dense层,将1维变成embedd_size维,也就是嵌入维度都为embedding_size.
linear_emb_list 记录输入特征嵌入后tensor表,提供给LR层,包括类别型特征与连续型特征,也就是嵌入维度都为1
fm_input: 对deep_emb_list的拼接,shape(,field_size, embedding_size )
deep_input : 对fm_input的flatten , shape(,units)
inputs_list 作为model的input
AFM:
fm_input ( list of (batch_size, 1, embedding_size )) -> fm_logit (tensor of (batch_size, 1) ) -> (fm_logit, linear_logit) -> final_logit -> output
DCN:
deep_emb_list (list of (batch_size,1 , embedding_size))-> deep_input(batch, units) -> cross_out(batch_size, units) / deep_out -> stack_out(concatenate) -> final_logit (Dense) -> output(PredictionLayer)
deepFM:
linear_emb_list , dense_input_dict -> linear_logit
fm_input(batch_size, field_size, embedding_size ) -> fm_out (FM, ( batch_size, 1 ) )
fm_input -> deep_input(batch_size, units ) -> deep_out -> deep_logit
out_put = MLP(linear_logit , fm_out, deep_logit)
FNN::
deep_emb_list -> deep_input -> deep_out(MLP) -> deep_logit (Dense) -> final_logit -> output
NFM:
deep_emb_list -> fm_input (batch_size, field_size, embedding_size) -> bi_out( BiInteractionPooling(), (batch_size, 1, embedding_size)) -> deep_out(MLP) -> deep_logit(Dense) -> output(Prediction)
NFFM:
sparse_embedding, dense_embedding, linear_embedding -> embed_list (FFM) -> ffm_out( Flatten() ) -> final_logit -> final_logit
linear_embedding -> linear_logit
final_logit + linear_logit
PNN:
deep_emb_list (batch_size, 1, embedding_size) -> inner_product ( ( batch_size, N*(N-1)/2 , 1) 或者 ( batch_size, N*(N-1)/2 , embedding_size) )
deep_emb_list (batch_size, 1, embedding_size) -> outer_product ( ( batch_size, N*(N-1)/2 )
deep_emb_list -> linear_signal (concatenate)
concatenate( inner_product outter_product, linear_signal) -> deep_out -> deep_out (MLP) -> deep_logit(Dense) -> output
xDeepFM:
fm_input (batch_size, field_size, enbedding_size )-> exFM_out (batch_size, featuremap_num)
fm_input ->deep_input -> deep_out -> deep_logit
linear_logit
concatenate(exFM_out, deep_logit, linear_logit) -> output(PredictionLayer)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号