

小白也能弄懂的目标检测之YOLO系列 - 第一期
 大家好,上期分享了电脑端几个免费无广告且实用的录屏软件,这期想给大家来讲解YOLO这个算法,从零基础学起,并最终学会YOLOV3的Pytorch实现,并学会自己制作数据集进行模型训练,然后用自己训练好的模型进行预测。
大家好,上期分享了电脑端几个免费无广告且实用的录屏软件,这期想给大家来讲解YOLO这个算法,从零基础学起,并最终学会YOLOV3的Pytorch实现,并学会自己制作数据集进行模型训练,然后用自己训练好的模型进行预测。
大家好,上期分享了电脑端几个免费无广告且实用的录屏软件,这期想给大家来讲解YOLO这个算法,从零基础学起,并最终学会YOLOV3的Pytorch实现,并学会自己制作数据集进行模型训练,然后用自己训练好的模型进行预测。
话不多说,先上我用VisDrone数据集进行训练的效果图:
在正式制作数据集进行模型训练之前,还是向大家介绍一下YOLO的来源以及其作用效果,我想你们也并不只是想单纯按步骤跑起来这么简单吧,换了一下样子,到时候又不会了,所以重要的是自己能够理解这其中的原理,让我们一起来学习了解一下吧。
前言
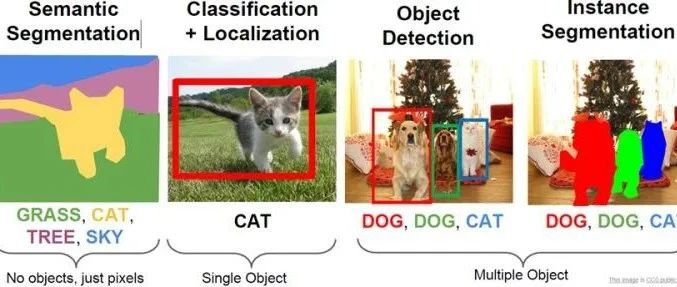
当我们谈起计算机视觉时,首先想到的就是图像分类,没错,图像分类是计算机视觉最基本的任务之一,但是在图像分类的基础上,还有更复杂和有意思的任务,如目标检测,物体定位,图像分割等,见图1所示。其中目标检测是一件比较实际的且具有挑战性的计算机视觉任务,其可以看成图像分类与定位的结合,给定一张图片,目标检测系统要能够识别出图片的目标并给出其位置,由于图片中目标数是不定的,且要给出目标的精确位置,目标检测相比分类任务更复杂。目标检测的一个实际应用场景就是无人驾驶,如果能够在无人车上装载一个有效的目标检测系统,那么无人车将和人一样有了眼睛,可以快速地检测出前面的行人与车辆,从而作出实时决策。
总结:目标检测是识别图片或者视频中所出现所有的目标和其位置,要解决的问题是:目标分类和目标定位。
目前比较流行的目标检测算法可以分为两类:第一类是基于侯选区域Region Proposal的R-CNN系算法(R-CNN,Fast R-CNN, Faster R-CNN),它们是two-stage的,需要先使用启发式方法(selective search)或者CNN网络(RPN)产生候选区域Region Proposal,然后再在Region Proposal上做分类与回归。通俗的意思就是:网络会根据候选区域生成位置和类别。第二类是像Yolo,SSD这类one-stage算法,其仅仅使用一个CNN网络直接预测不同目标的类别与位置,直接从图片生成位置和类别。
从图中的FPS和mAP我们可以看出:第一类方法是准确度高一些,但是速度慢,但是第二类算法是速度快,但是准确性要低一些。这里FPS是用来评估目标检测的速度,即每秒内可以处理的图片数量或者处理一张图片所需时间来评估检测速度,时间越短,速度越快。mAP是物体检测器准确率的度量方法,通俗来说就是目标检测准确度。
提醒:FPS和mAP是目标检测算法的两个重要评估指标。
这里大家可能不太懂具体是什么意思,不要担心,后期在我的卷积系列单元里面会出有关于这些,帮助大家更好的理解。
YOLO进化史
这里主要介绍YOLO算法,首先了解一下YOLO的进化史,其全称是You Only Look Once: Unified, Real-Time Object Detection,You Only Look Once说的是只需要一次CNN运算,Unified指的是这是一个统一的框架,提供end-to-end的预测,而Real-Time体现是Yolo算法速度快。通俗的意思就是神经网络只需要看一次图片,就可以预测图片中所有的物体边框。
从图中我们可以看到,YOLO已经发展到第五代了,而v4和v5是最近提出来的,所以其中包含的技术是非常多的,对于新手来说理解起来肯定又很大的难度,故在此我想和大加分享一下有关于YOLO系列的知识,以便大家能够更好的理解,这里我会从YOLOV1开始进行讲解,我想只有深入理解,才能更好的使用,所以如果你感兴趣的话,就继续追我下面的文章吧。
参考:
https://blog.csdn.net/qq_34510308/article/details/106653190
https://zhuanlan.zhihu.com/p/32525231
https://segmentfault.com/a/1190000022632577
更多有关python、深度学习和计算机编程和电脑知识的精彩内容,可以关注微信公众号:码农的后花园

 浙公网安备 33010602011771号
浙公网安备 33010602011771号