

Python实验报告(第4章)
实验4:Python序列的应用
一、实验目的和要求
学会应用列表、元组、字典等序列;
二、实验环境
软件版本:Python 3.10 64_bit
三、实验过程
1、实例1:输出每日一贴
(1)在IDLE中创建一个名称为tips.py的文件,然后在该文件中导入日期时间类,然后定义一个列表(保存7条励志文字作为每日一贴的内容),再获取当前的星期,最后将当前的星期作为列表的索引,输出元素内容。代码如下:
1 import datetime # 导入日期时间类
2 # 定义一个列表
3 mot = ["今天星期一:\n坚持下去不是我很坚强,而是因为我别无选择。",
4 "今天星期二:\n含泪播种的人一定能笑着收获。",
5 "今天星期三:\n做对的事情比把事情做对重要。",
6 "今天星期四:\n命运给予我们的不是失望之酒,而是机会之杯。",
7 "今天星期五:\n不要等到明天,明天太遥远,今天就行动。",
8 "今天星期六:\n求知若饥,虚心若愚。",
9 "今天星期日:\n成功将属于那些从不说“不可能”的人。"]
10 day = datetime.datetime.now().weekday() # 获取当前星期
11 print(mot[day]) # 输出每日一贴
(2)运行结果如图所示:

2、实例2:分两列显示2017~2018赛季NBA西部联盟前八名的球队
(1)在IDLE中创建一个名称为printteam.py的文件,并且在该文件中先输出标题,然后定义一个列表(保存球队名称),再应用for循环和enumerate()函数遍历列表,在循环体中通过if…else语句判断是否为偶数,如果为偶数则不换行输入,否则换行输入。代码如下:
1 print("2017~2018赛季NBA西部联盟前八名\n")
2 team = ["火箭","勇士","开拓者","雷霆","爵士","鹈鹕","马刺","森林狼"]
3 for index,item in enumerate(team):
4 if index % 2 == 0: # 判断是否为偶数,为偶数时不换行
5 print(item + "\t\t",end = "")
6 else:
7 print(item + "\n")
(2)运行结果如图所示:

3、实例3:向NBA名人堂列表中追加2018年新进入的球星
(1)在IDLE中创建一个名称为nba.py的文件,然后在该文件中定义一个保存NBA名人堂原有球星名字的列表,然后创建一个保存2018年新进入球星名字的列表,再调用列表对象的extend()方法追加元素,最后输出追加元素后的列表。代码如下:
1 oldlist = ["迈克尔 • 乔丹",
2 "卡里姆 • 阿布杜尔 • 贾巴尔",
3 "哈基姆 • 奥拉朱旺",
4 "查尔斯 • 巴克利",
5 "姚明"] # NBA名人堂原有人员
6 newlist = ["贾森 • 基德",
7 "史蒂夫 • 纳什",
8 "格兰特 • 希尔"] # 新增人员列表
9 oldlist.extend(newlist) # 追加新球星
10 print(oldlist) # 显示新的名人堂人员列表
(2)运行结果如图所示:

4、实例4:使用二维列表输出不同版式的古诗
(1)在IDLE中创建一个名称为printverse.py的文件,然后在该文件中首先定义4个字符串,内容为柳宗元的《江雪》中的诗句,并定义一个二维列表,然后应用嵌套的for循环将古诗以横版方式输出,再将二维列表进行逆序排列,最后应用嵌套的for循环将古诗以竖版的方式输出。代码如下:
1 str1 = "千山鸟飞绝"
2 str2 = "万径人踪灭"
3 str3 = "孤舟蓑笠翁"
4 str4 = "独钓寒江雪"
5 verse = [list(str1), list(str2),
6 list(str3), list(str4)] # 定义一个二维列表
7 print("\n-- 横板 --\n")
8 for i in range(4): # 循环古诗的每一行
9 for j in range(5): # 循环每一行的每个字(列)
10 if j == 4: # 如果是一行中的最后一个字
11 print(verse[i][j]) # 换行输出
12 else:
13 print(verse[i][j], end = "") # 不换行输出
14
15 verse.reverse() # 对列表进行逆序排列
16 print("\n-- 竖版 --\n")
17 for i in range(5): # 循环每一行的每个字(列)
18 for j in range(4): # 循环新逆序排列后的第一行
19 if j == 3: # 如果是最后一行
20 print(verse[j][i]) # 换行输出
21 else:
22 print(verse[j][i], end = "") # 不换行输出
(2)运行结果如图所示:

5、实例5:使用元组保存咖啡馆里提供的咖啡名称
(1)在IDLE中创建一个名为cafe_coffeename.py的文件,然后在该文件中定义一个包含6个元素的元组,内容为伊米咖啡馆里的咖啡名称,并输出元组。代码如下:
1 coffeename = ("蓝山","卡布奇诺","曼特宁",
2 "摩卡","麝香猫","哥伦比亚") # 定义元组
3 print(coffeename) # 输出元组
(2)运行结果如图所示:
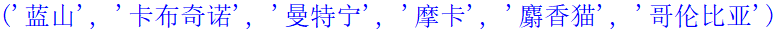
6、实例6:使用for循环列出咖啡馆里的咖啡名称
(1)在IDLE中创建一个名为cafe_coffeename.py的文件,然后在该文件中,定义一个包含6个元素的元组,内容为伊米咖啡馆里的咖啡名称,然后应用for循环语句输出每个元组元素的值,即咖啡名称,并且在后面加上“咖啡”二字。代码如下:
1 coffeename = ("蓝山","卡布奇诺",
2 "曼特宁","摩卡",
3 "麝香猫","哥伦比亚") # 定义元组
4 print("您好,欢迎光临~伊米咖啡馆~\n\n我店有:\n")
5 for name in coffeename: # 遍历元组
6 print(name + "咖啡",end = " ")
(2)运行结果如图所示:

7、实例7:分两列显示2017~2018赛季NBA西部联盟前八名球队
(1)本实例将在实例2的基础上进行修改,将列表修改为元组,其他内容不变,修改后的代码如下:
1 print("2017~2018赛季NBA西部联盟前八名\n")
2 team = ("火箭","勇士","开拓者","雷霆","爵士","鹈鹕","马刺","森林狼")
3 for index,item in enumerate(team):
4 if index % 2 == 0: # 判断是否为偶数,为偶数时不换行
5 print(item + "\t\t", end = "")
6 else:
7 print(item + "\n") # 换行输出
(2)运行结果如图所示:

8、实例8:将麝香猫咖啡替换成拿铁
(1)在IDLE中创建一个名为cafe_coffeename.py的文件,然后在该文件中定义一个包含6个元素的元组,内容为伊米咖啡馆里的咖啡名称,然后修改其中的第5个元素的内容为“拿铁”。代码如下:
1 coffeename = ("蓝山","卡布奇诺",
2 "曼特宁","摩卡",
3 "麝香猫","哥伦比亚") # 定义元组
4 coffeename[4] = "拿铁" # 将“麝香猫”替换为“拿铁”
5 print(coffeename)
运行结果如图所示:

(2)出现以上结果的原因是:元组是不可变序列,不能对它的单个元素进行修改。但是元组也不是完全不能修改。我们可以对元组进行重新赋值。例如,下面的代码是允许的:
1 coffeename = ("蓝山","卡布奇诺","曼特宁","摩卡","麝香猫","哥伦比亚") # 定义元组
2 coffeename = ("蓝山","卡布奇诺","曼特宁","摩卡","拿铁","哥伦比亚") # 对元组进行重新赋值
3 print("新元组",coffeename)
运行结果如图所示:
![]()
9、实例9:创建一个保存女神星座的字典
(1)在IDLE中创建一个名称为sign_create.py的文件,然后在该文件中,定义两个包括4个元素的列表,再应用dict()函数和zip()函数将前两个列表转换为对应的字典,并且输出该字典。代码如下:
1 name = ["绮梦","冷伊一","香凝","黛蓝"] # 作为键的列表
2 sign = ["水瓶座","射手座","双鱼座","双子座"] # 作为值的列表
3 dictionary = dict(zip(name,sign)) # 转换为字典
4 print(dictionary) # 输出转换后字典
(2)运行结果如图所示:
![]()
10、实例10:根据星座测试性格特点
(1)再IDLE中创建一个名称为sign_get.py的文件,然后在该文件中创建两个字典,一个保存名字和星座,另一个保存星座和性格特点,最后从这两个字典中取出相应的信息组合出想要的结果,并输出。代码如下:
1 name = ["绮梦","冷伊一","香凝","黛兰"] # 作为键的列表
2 sign_person = ["水瓶座","射手座","双鱼座","双子座"] # 作为值的列表
3 person_dict = dict(zip(name,sign_person)) # 转换为个人字典
4 sign_all = ["白羊座","金牛座","双子座","巨蟹座","狮子座","处女座","天秤座","天蝎座","射手座","摩羯座","水瓶座","双鱼座"]
5 nature = ["有一种让人看见就觉得开心的感觉, 阳光、乐观、 坚强, 性格直来直去,就是有点小脾气。",
6 "很保守, 喜欢稳定, 一旦有什么变动就会觉得心里不踏实, 性格比较慢热,是个理财高手。",
7 "喜欢追求新鲜感,有点小聪明, 耐心不够, 因你的可爱性格会让很多人喜欢和你做朋友。",
8 "情绪容易敏感, 缺乏安全感, 做事情有坚持到底的毅力,为人重情重义,对朋友和家人特别忠实。",
9 "有着远大的理想, 总想靠自己的努力成为人上人,总是期待被仰慕被崇拜的感觉。",
10 "坚持追求自己的完美主义者。",
11 "追求平等、和谐, 交际能力强, 因此朋友较多。 最大的缺点就是面对选择总是犹豫不决。",
12 "精力旺盛, 占有欲强,对于生活很有目标, 不达目的哲不罢休,复仇心重。",
13 "崇尚自由,勇敢、 果断、 独立,身上有一股勇往直前的劲儿, 只要想做,就能做。",
14 "是最有耐心的, 做事最小心。 做事脚踏实地, 比较固执,不达目的不罢休,而且非常勤奋。",
15 "人很聪明,最大的特点是创新, 追求独一无二的生活,个人主义色彩很浓重的星座。",
16 "集所有星座的优缺点于一身。最大的优点是有一颗善良的心, 愿意帮助别人。"]
17 sign_dict = dict(zip(sign_all,nature)) # 转换为星座字典
18 print("【香凝】的星座是",person_dict.get("香凝")) # 输出星座
19 print("\n 她的性格特点是:\n\n",sign_dict.get(person_dict.get("香凝"))) # 输出性格特点
(2)运行结果如图所示:

11、实例11:应用字典推导式实现根据名字和星座创建一个字典
(1)在IDLE中创建一个名称为sign_create.py的文件,然后在该文件中,定义两个包括4个元素的列表,再应用字典推导式将前两个列表转换为对应的字典,并且输出该字典。代码如下:
1 name = ["绮梦","冷伊一","香凝","黛兰"] # 作为键的列表
2 sign = ["水瓶","射手","双鱼","双子"] # 作为值的列表
3 dictionary = {i:j+"座" for i,j in zip(name,sign)} # 使用列表推导式生成字典
4 print(dictionary) # 输出转换后字典
(2)运行结果如图所示:![]()
12、实例12:创建保存学生选课信息的几何
(1)在IDLE中创建一个名称为section_create.py的文件,然后在该文件中,定义两个包括4个元素的集合,再输出这两个集合。代码如下:
1 python = {"绮梦","冷伊一","香凝","梓轩"} # 保存选择Python语言的学生姓名
2 c = {"冷伊一","零语","梓轩","圣博"} # 保存选择C语言的学生姓名
3 print("选择Python语言的学生有:",python,"\n") # 输出选择Python语言的学生姓名
4 print("选择C语言的学生有:",c) # 输出选择C语言的学生姓名
(2)运行结果如图所示:

13、实例13:学生更改选学课程
(1) 在IDLE中创建一个名称为section_addpy的文件,然后在该文件中,定义一个包括4个元素的集合,并且利用add()函数向该集合中添加一个元素,再定义一个包括4个元素的集合,并且利用remove()方法从该集合中删除指定的元素,最后输出这两个集合。代码如下:
1 python = set(["绮梦","冷伊一","香凝","梓轩"]) # 保存选择Python语言的学生姓名
2 python.add("零语") # 添加一个元素
3 c = set(["冷伊一","零语","梓轩","圣博"]) # 保存选择C语言的学生姓名
4 c.remove("零语") # 删除指定元素
5 print("选择Python语言的学生有:",python,"\n") # 输出选择Python语言的学生姓名
6 print("选择C语言的学生有:",c) # 输出选择C语言的学生姓名
(2)运行结果如图所示:

14、实例14:对选课集合进行交集、并集和差集运算
(1)在IDLE中创建一个名称为section_operate.py的文件,然后在该文件中定义两个包括4个元素的集合,再根据需要对两个集合进行交集、并集和差集的运算,并输出这两个集合。代码如下:
1 python = set(["绮梦","冷伊一","香凝","梓轩"]) # 保存选择Python语言的学生姓名
2 c = set(["冷伊一","零语","梓轩","圣博"]) # 保存选择C语言的学生姓名
3 print("选择Python语言的学生有:",python) # 输出选择Python语言的学生姓名
4 print("选择C语言的学生有:",c) # 输出选择C语言的学生姓名
5 print("交集运算:",python & c) # 输出既选择了Pyhon语言又选择了C语言的学生姓名
6 print("并集运算",python | c) # 输出参与选课的全部学生姓名
7 print("差集运算",python - c) # 输出只选择了Python语言但没有选择C语言的学生姓名
(2)运算结果如图所示:

15、实战一:输出“王者荣耀”的游戏角色
(1)“王者荣耀”游戏中有许多英雄,这些英雄可以分为法师、战士、坦克、刺客、射手和辅助。本实战将利用Python中的列表存储不同类别的英雄,并且遍历输出这些英雄。代码如下:
1 rint("“王者荣耀”游戏角色:")
2 print("====坦克====")
3 tank = ["苏烈","刘邦","钟馗","张飞","牛魔","程咬金","白起","刘婵","庄周","项羽","廉颇","巨灵神","安禄山","猪八戒"] # 直接创建“坦克”列表
4 # 遍历并输出“坦克”列表的每个元素
5 for i,j in enumerate(tank):
6 if i+1 == len(tank):
7 print(j)
8 else:
9 print(j, " ", end = "")
10 print("====战士====")
11 warrior = ["狂铁","裴擒虎","铠","孙悟空","哪吒","杨戬","橘右京","亚瑟","雅典娜","夏侯淳","关羽","吕布","韩信","老夫子""达摩","典书","曹操","钟无艳","墨子","赵云","刑天","龙且"] # 直接创建“战士”列表
12 # 遍历并输出“战士”列表的每个元素
13 for i,j in enumerate(warrior):
14 if i+1 == len(warrior):
15 print(j)
16 else:
17 print(j, " ", end = "")
18 print("====刺客====")
19 assassin = ["百里玄策","庞统","花木兰","阿轲(荆轲)","不知火舞","李白","娜可露露","兰陵王","露娜","韩信","宫本武藏","盖聂","红拂"] # 直接创建“刺客”列表
20 # 遍历并输出“刺客”列表的每个元素
21 for i,j in enumerate(assassin):
22 if i+1 == len(assassin):
23 print(j)
24 else:
25 print(j, " ", end = "")
26 print("====法师====")
27 master = ["杨玉环","奕星","女娲","周瑜","鬼谷子","芈月","干将莫邪","东皇太一","大乔","诸葛亮","貂蝉","张良","安琪拉","不知火舞","不知火舞","姜子牙","武则天","王昭君","甄姬","扁鹊","高渐离","嬴政","妲己"] # 直接创建“法师”列表
28 # 遍历并输出“法师”列表的每个元素
29 for i,j in enumerate(master):
30 if i+1 == len(master):
31 print(j)
32 else:
33 print(j, " ", end = "")
34 print("====射手====")
35 shooter = ["公孙离","百里守约","后羿","刘备","黄忠","马可波罗","成吉思汗","虞姬","李元芳","艾琳","狄仁杰","鲁班七号","孙尚香"] # 直接创建“射手”列表
36 # 遍历并输出“射手”列表的每个元素
37 for i,j in enumerate(shooter):
38 if i+1 == len(shooter):
39 print(j)
40 else:
41 print(j, " ", end = "")
42 print("====辅助====")
43 support = ["明世隐","梦奇","孙膑","太乙真人","蔡文姬"] # 直接创建“辅助”列表
44 # 遍历并输出“辅助”列表的每个元素
45 for i,j in enumerate(support):
46 if i+1 == len(support):
47 print(j)
48 else:
49 print(j, " ", end = "")
(2)运行结果如图所示:

16、实战二:模拟火车订票系统
(1)模拟火车订票系统,代码如下:
1 yi = ["车次","出发站-到达站","出发时间","到达时间"," 历时"]
2 checi = ["T40","T298","Z158","Z62"] # 作为键的列表
3 # 作为值的列表
4 station = ["长春-北京","长春-北京","长春-北京","长春-北京"]
5 time1 = ["00:12","00:06","12:48","21:58"]
6 time2 = ["12:20","10:50","21:06","08:18"]
7 time3 = ["12:08","10:44","08:18","8:20"]
8 # 遍历并输出标题列表
9 for i in yi:
10 print(i,end = "\t")
11 print("\n",end = "")
12 # 输出数据
13 print(checi[0],"\t",station[0],"\t",time1[0],"\t\t",time2[0],"\t\t",time3[0])
14 print(checi[1],"\t",station[1],"\t",time1[1],"\t\t",time2[1],"\t\t",time3[1])
15 print(checi[2],"\t",station[2],"\t",time1[2],"\t\t",time2[2],"\t\t",time3[2])
16 print(checi[3],"\t",station[3],"\t",time1[3],"\t\t",time2[3],"\t\t",time3[3])
17 # 转换为字典
18 line1 = dict(zip(checi,station))
19 line2 = dict(zip(checi,time1))
20 line3 = dict(zip(checi,time2))
21 line4 = dict(zip(checi,time3))
22 buycheci = input("请输入购买车次:")
23 human = input("请输入乘车人(用逗号分隔):")
24 gostation = line1[buycheci]
25 gotime1 = line2[buycheci]
26 print("你已购买" + buycheci + "次列车" + "从" + gostation + gotime1 + "开,请" + human + "尽快换取纸质车票。【铁路客服】")
(2)运行结果如图所示:

17、实例三:电视剧的收视率排行榜
(1)应用列表和元组将以下电视剧按收视率由高到低进行排序:
《Give up, hold on to me》收视率:1.4%
《The private dishes of the husbands》收视率:1.343%
《My father-in-law will do martiaiarts》收视率:0.92%
《North Canton still believe in love》收视率:0.862%
《Impossible task》收视率:0.553%
《Sparrow》收视率:0.411%
《East of dream Avenue》收视率:0.164%
《The prodigal son of the new frontier town》收视率:0.259%
《Distant distance》收视率:0.394%
《Music legend》收视率:0.562%
代码如下:
1 TV = [("《Give up, hold on to me》收视率:","1.4%"),
2 ("《The private dishes of the husbands》收视率:","1.343%"),
3 ("《My father-in-law will do martiaiarts》收视率:","0.92%"),
4 ("《North Canton still believe in love》收视率:","0.862%"),
5 ("《Impossible task》收视率:","0.553%"),
6 ("《Sparrow》收视率:","0.411%"),
7 ("《East of dream Avenue》收视率:","0.164%"),
8 ("《The prodigal son of the new frontier town》收视率:","0.259%"),
9 ("《Distant distance》收视率:","0.394%"),
10 ("《Music legend》收视率:","0.562%")] # 原电视剧列表
11 TV.sort(key=lambda x:x[1], reverse=True) # 对元素的第二个字段进行降序
12 print('电视剧的收视率排行榜:')
13 for i in TV:
14 for j in range(len(i)):
15 if j == 1: # 若为元素的第二字段,则输出后换行
16 print(i[j])
17 else: # 否则不换行输出
18 print(i[j], end = "")
(2)运行结果如图所示:

18、实战四:定制自己的手机套餐
(1)假设我们可以根据需求定制自己的手机套餐,可选项为话费、流量和短信。假设有如下设置:
话费:0分钟、50分钟、100分钟、300分钟、不限量
流量:0M、500M、1G、5G不限量
短信:0条、50条、100条
最后将用户选择的内容搭配为一个套餐输出。代码如下:
1 call = ["0分钟","50分钟","100分钟","300分钟","不限量"]
2 liu = ["0M","500M","1G","5G","不限量"]
3 message = ["0条","50条","100条"]
4 print("定制自己的手机套餐:")
5 #A.通话时长的选择
6 print("A.请设置通话时长:")
7 for i,j in enumerate(call):
8 print(str(i+1) + "." + j)
9 A = int(input("输入选择的通话时长编号:"))
10 #B.流量的选择
11 print("B.请设置流量包:")
12 for i,j in enumerate(liu):
13 print(str(i+1) + "." + j)
14 B = int(input("输入选择的流量包编号:"))
15 #C.短信的选择
16 print("C.请设置短信条数:")
17 for i,j in enumerate(message):
18 print(str(i+1) + "." + j)
19 C = int(input("输入选择的短信条数编号:"))
20 #输出套餐结果
21 print("您的手机套餐定制成功:"
22 + "免费通话时长为" + call[A-1] + "/月,"
23 + "流量为" + liu[B-1] + "/月,"
24 + "短信条数" + message[C-1] + "/月")
(2)运行结果如图所示:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号