Sphinx的安装和使用
Sphinx是一款基于SQL的高性能全文检索引擎,Sphinx的性能在众多全文检索引擎中也是数一数二的,利用Sphinx,我们可以完成比数据库本身更专业的搜索功能,而且可以有很多针对性的性能优化。
Sphinx的特点
- 快速创建索引:3分钟左右即可创建近100万条记录的索引,并且采用了增量索引的方式,重建索引非常迅速。
- 闪电般的检索速度:尽管是1千万条的大数据量,查询数据的速度也在毫秒级以上,2-4G的文本量中平均查询速度不到0.1秒。
- 为很多脚本语言设计了检索API,如PHP,Python,Perl,Ruby等,因此你可以在大部分编程应用中很方便地调用Sphinx的相关接口。
- 为MySQL设计了一个存储引擎插件,因此如果你在MySQL上使用Sphinx,那简直就方便到家了。
- 支持分布式搜索,可以横向扩展系统性能。
ubuntu下安装
# libsphinxclient安装(PHP模块需要)
sudo apt-get install libmysqlclient-dev libpq-dev unixodbc-dev
sudo apt-get install libmariadb-client-lgpl-dev-compat
sudo apt install sphinxsearch
Sphinx工作流程图
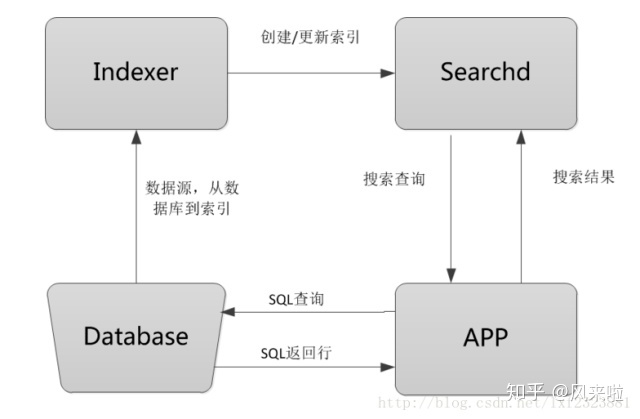
使用sphinx搜索引擎对数据做索引,数据一次性加载进来后保存在内存中,用户在进行搜索的时候只需要在sphinx服务器上检索数据即可。Sphinx的整个工作流程就是Indexer程序到数据库里面提取数据,对数据进行分词,然后根据生成的分词生成单个或多个索引,并将它们传递给searchd程序,然后客户端可以通过API调用进行搜索。
Database:数据源,是sphinx做索引的数据来源。
Indexer:索引程序,从数据源大多数据库中获取数据,并将数据生成全文索引。根据需求定期运行Indexer达到定时更新索引的需求。
sphinx使用配置文件从数据库读出数据之后,就将数据传递给Indexer程序,然后Indexer会逐条读取记录,根据分词算法对每条记录建立索引,分词算法可以是一元分词或mmseg分词。
Searchd:Searchd直接与客户端程序进行对话,并使用Indexer程序构建好的索引来快速地处理搜索查询。
App客户端:接收来自用户输入的搜索字符串,发送查询给searchd程序并显示返回结果。
sphinx的配置
source:数据源,数据是从什么地方来的。
index:索引,当有数据源之后,从数据源处构建索引。索引实际上就是相当于一个字典检索。有了整本字典内容以后,才会有字典检索。
searchd:提供搜索查询服务。它一般是以deamon的形式运行在后台的。
indexer:构建索引的服务。当要重新构建索引的时候,就是调用indexer这个命令。
attr:属性,属性是存在索引中的,它不进行全文索引,但是可以用于过滤和排序。
## sphinx可以定义多个索引与数据源,不同的索引与数据源可以应用到不同表或不同应用的全文检索。
## source 数据源 basic
source basic{
## 说明数据源类型,数据源类型可以是:mysql、mssql、odbc等等
type = mysql
## 下面是sql数据库特有的端口、用户名、密码数据库名等。
sql_host = 127.0.0.1
sql_user = root
sql_pass = root
sql_db = test
sql_port = 3306
## 执行sql前的操作,设置mysql检索编码
sql_query_pre = SET NAMES utf8
}
## source更具体的根据某索引的表数据源基于某数据库源(比如source basic)
source productst : basic{
## 全文索引要显示的内容(尽可能不使用where、group by,将其的内容交给sphinx)
## select字段中必须包含一个唯一主键比如t.id以及要全文检索的字段比如t.title,where中要用到的字段也要select出来(此句不确定),sphinx使用此语句从数据库中拉取数据。
sql_query = \
SELECT t.id,t.uid,t.title,t.description,t.modelno,UNIX_TIMESTAMP(t.tempdate) as tempdate,t.score,CAST(replace(t.min_order, ',', '') AS SIGNED) as min_order,replace(replace(replace(replace(replace(t.payment_type, 'T/T', '1'), 'L/C', '2'), 'D/A', '3'),'D/P','4'),'Western Union','5') as payment_type, \
u.country,u.memtype,u.username,u.is_hubs,u.mempackage, \
g.title as grouptitle,t.groupid, \
c.cid, \
co.flashvideo,co.companyname,crc32(REPLACE(LOWER(co.city),' ','')) as city, \
IF(site.id is null,0,IF(site.status=0,0,IF(site.is_resources=0,1,0))) as endlz, \
ca.sgs,(CASE WHEN u.`memtype`=1 THEN u.`memtype` ELSE ca.audits END) as audits, \
IF(je.`e_id`>0,'1','0') as exhibition_id \
FROM nt_products t \
LEFT JOIN v_sites as site ON t.uid = site.uid and site.lang_id=1 and site.status=1 \
LEFT JOIN nt_members u ON t.uid = u.id \
LEFT JOIN nt_companyprofiles co ON t.uid = co.uid \
LEFT JOIN nt_company_audit ca ON t.uid = ca.uid \
LEFT JOIN nt_product_group g ON t.groupid = g.id \
LEFT JOIN nt_product_cats c ON t.id = c.product_id \
LEFT JOIN nt_product_description d ON t.id = d.product_id \
LEFT JOIN nt_join_exhibition_company_products je ON t.id = je.product_id \
where u.username != '' and t.approved=1 and u.suspended='no' and u.buyer_seller<>1 and co.id is not null and t.id>=$start and t.id<=$end
## 通过某表定死最大最小id不分区查询
sql_query_range = SELECT min_id ,max_id FROM `` WHERE part_id = 1 LIMIT 1
## 当数据源过大时多次查询操作对表进行分区 查询的步长
#sql_query_range = SELECT MIN(id),MAX(id) FROM documents
#sql_range_step = 1000000
## 在where、orderby、groupby中出现的字段要分别定义一个属性(以sql_attr_开头),定义不同类型的字段要用不同的属性名。(此句不确定)
sql_attr_uint = groupid ## 无符号整数类型
sql_attr_uint = endlz
sql_attr_uint = score
sql_attr_uint = uid
sql_attr_uint = cid
sql_attr_uint = country
sql_attr_uint = memtype
sql_attr_uint = mempackage
sql_attr_uint = sgs
sql_attr_uint = audits
sql_attr_string = username
sql_attr_string = grouptitle
sql_attr_uint = city
sql_attr_uint = exhibition_id
sql_attr_uint = min_order
sql_attr_multi = uint payment_type from field payment_type
sql_attr_timestamp = tempdate ## unix时间戳
}
## 索引名称
index search_productst{
type = plain
## 声明索引源
source = productst
## 索引文件存放路径及索引的文件名
path = /srv/sphinxsearch/data/search_productst
docinfo = extern
mlock = 0
morphology = none
## 最小索引词长度,小于这个长度的词不会被索引。
min_word_len = 3
## 字符集编码类型
#charset_type = utf-8 ## 新的sphinx不支持charset_type设置
## 字符表和大小写转换规则
# charset_table = 0..9, A..Z->a..z, _, a..z, U+410..U+42F->U+430..U+44F, U+430..U+44F
## html标记清理,是否从输出全文数据中去除HTML标记。
html_strip = 0
}
## 索引器配置
indexer {
mem_limit = 32M ## 索引过程内存使用限制.可选选项,默认 32M. 这是 indexer 不会超越的强制内存限制.可以以字节,千字节(以 K 为后缀)或兆字节(以 M 为后缀)为单位.参见示例.当过小的值导致 I/O 缓冲低于 8KB 时该限制会自动提高,此 值的最低限度依赖于待索引数据的大小.如果缓冲低于 256KB,会产生警告. 最大可能的限制是 2047M.太低的值会影响索引速度,但 256M 到 1024M 对绝大多数数据 集(如果不是全部)来说应该足够了.这个值设得太高可能导致 SQL 服务器连接超时.在文档收集阶段,有时内存缓冲的一部分会被排序,而与数据库的通信会暂停,于是数据库服务器可能超时.这可以通过提高 SQL 服务器端的超时时间或降低 mem_limit 来解决.
}
searchd
{
listen = 9312 ## 监听端口及对外开放的api端口
listen = 9306:mysql41
log = /var/log/sphinxsearch/searchd.log ## 服务进程日志
query_log = /var/log/sphinxsearch/query.log ## 客户端查询后记录的日志
read_timeout = 5 ## 请求超时
client_timeout = 10
max_children = 60 ## 同时可执行的最大searchd进程数
pid_file = /var/run/sphinxsearch/searchd.pid ## 进程id文件
#max_matches = 10000 ## 查询结果的最大返回数
seamless_rotate = 1 ## 启动无缝轮转
preopen_indexes = 1
unlink_old = 1
# attr_flush_period = 900
# ondisk_dict_default = 1
mva_updates_pool = 1M
max_packet_size = 16M
max_filters = 256
max_filter_values = 4096
max_batch_queries = 32
workers = threads # for RT to work
collation_server = utf8_general_ci
#compat_sphinxql_magics = 0
#并发查询线程数
dist_threads = 7
}
index返回的字段常用的四种形式:
sql_field_string = title #指定字符型字段,可全文搜索,可返回原始文本信息
sql_attr_uint = year #无符号整型属性
sql_attr_string = description #指定字符型属性,只存储不参与搜索
sql_attr_multi = areas #多值字段,值以逗号分开。
创建索引
##创建所有索引
indexer --all
indexer --config /etc/sphinxsearch/sphinx.conf --all
#指定某个数据源生成索引
indexer search_productst
indexer --config /etc/sphinxsearch/sphinx.conf search_productst
##如果此时searchd守护进程已经启动,需要加上--rotate参数:
indexer --config /etc/sphinxsearch/sphinx.conf search_productst --rotate
启动sphinx守护Searchd
searchd --config /etc/sphinxsearch/sphinx.conf
PHP查询sphinx
require('SphinxClient.php');
//创建Sphinx的客户端接口对象
$cl = new SphinxClient();
//设置连接Sphinx主机名与端口 9312对应searchd上面配置的listen
$cl->SetServer('192.168.99.99',9312);
//可选,为每一个全文检索字段设置权重,主要根据你在sql_query中定义的字段的顺序,Sphinx系统以后会调整,可以按字段名称来设定权重
$cl->SetWeights ( array ( 100, 1 ) );
//设定搜索模式,SPH_MATCH_ALL,SPH_MATCH_ANY,SPH_MATCH_BOOLEAN,SPH_MATCH_EXTENDED,SPH_MATCH_PHRASE 下面会介绍各种模式下搜索结果差异(很关键)
$cl->SetMatchMode(SPH_MATCH_ALL);
//设定过滤条件$attribute是属性名,相当于字段名(用SPH_MATCH_EXTENDED时),$value是值,$exclude是布尔型,
//boolean $exclude 匹配该过滤规则的文档是否会被排除在结果之外。当为true时,相当于$attribute!=$value,默认值是false
$cl->SetFilter($attribute, $values, $exclude);
//设定group by
//根据分组方法,匹配的记录集被分流到不同的组,每个组都记录着组的匹配记录数以及根据当前排序方法本组中的最佳匹配记录。
//最后的结果集包含各组的一个最佳匹配记录,和匹配数量以及分组函数值
//结果集分组可以采用任意一个排序语句,包括文档的属性以及sphinx的下面几个内部属性
//@id--匹配文档ID
//@weight, @rank, @relevance--匹配权重
//@group--group by 函数值
//@count--组内记录数量
//$groupsort的默认排序方法是@group desc,就是按分组函数值大小倒序排列
$cl->SetGroupBy($attribute, $func, $groupsort);
//设定匹配排序模式,第一个参数是排序方法名,值有SPH_SORT_RELEVANCE, SPH_SORT_ATTR_DESC,SPH_SORT_ATTR_ASC, SPH_SORT_TIME_SEGMENTS, SPH_SORT_EXTENDED
//$sortby的值如"HITS desc"
$cl->SetSortMode(SPH_SORT_EXTENDED, $sortby);
//set count-distinct attribute for group-by queries,$distinct为字符串
$cl->SetGroupDistinct ( $distinct );
//设置返回结果集偏移量和数目
$cl->SetLimits($start,$limit)
//$q是查询的关键字,$index是索引名称,当等于*时表查询所有索引
$index = 'search_product_tag';
$q = 'Gown';
$res = $cl->Query ( $q, $index );
以上代码输出
string(0) ""
array(10) {
## "error" searchd报告的错误信息
["error"]=>
string(0) ""
## "warning" searchd报告的警告信息
["warning"]=>
string(0) ""
["status"]=>
int(0)
["fields"]=>
array(1) {
[0]=>
string(7) "keyword"
}
["attrs"]=>
array(2) {
["words"]=>
int(7)
["uri"]=>
int(7)
}
## "matches" 存储文档id以及其对应的另一个包含文档权重和属性值得hash表
["matches"]=>
array(4) {
[8]=>
array(2) {
["weight"]=>
string(1) "1"
["attrs"]=>
array(2) {
["words"]=>
string(17) "Beading Ball Gown"
["uri"]=>
string(0) ""
}
}
[9]=>
array(2) {
["weight"]=>
string(1) "1"
["attrs"]=>
array(2) {
["words"]=>
string(15) "Satin Ball Gown"
["uri"]=>
string(0) ""
}
}
[124]=>
array(2) {
["weight"]=>
string(1) "1"
["attrs"]=>
array(2) {
["words"]=>
string(17) "Taffeta Ball Gown"
["uri"]=>
string(0) ""
}
}
[193]=>
array(2) {
["weight"]=>
string(1) "1"
["attrs"]=>
array(2) {
["words"]=>
string(22) "Chapel Train Ball Gown"
["uri"]=>
string(0) ""
}
}
}
## "total" 此查询在服务器检索所得到的匹配文档总数(即服务器端结果集的大小,且与相关设置有关)
["total"]=>
string(1) "4"
## "total_found" 索引中匹配文档的总数
["total_found"]=>
string(1) "4"
["time"]=>
string(5) "0.000"
## "words" 将查询关键词(关键词经过大小写转换,取词干和其他处理)映射到一个包含关于关键字的统计数据。'docs'在多少文档中出现,'hits'一共出现了多少次。
["words"]=>
array(1) {
["gown"]=>
array(2) {
["docs"]=>
string(1) "4"
["hits"]=>
string(1) "4"
}
}
Sphinx匹配模式
| 匹配模式 | 说明 |
|---|---|
| SPH_MATCH_ALL | 匹配所有查询词(默认模式). |
| SPH_MATCH_ANY | 匹配查询词中的任意一个. |
| SPH_MATCH_PHRASE | 将整个查询看作一个词组,要求按顺序完整匹配. |
| SPH_MATCH_BOOLEAN | 将查询看作一个布尔表达式. |
| SPH_MATCH_EXTENDED | 将查询看作一个Sphinx内部查询语言的表达式. |
| SPH_MATCH_FULLSCAN | 使用完全扫描,忽略查询词汇. |
| SPH_MATCH_EXTENDED2 | 类似 SPH_MATCH_EXTENDED ,并支持评分和权重. |
$q = 'Gown';
$res = $cl->Query ( $q, $index );下面字符串表示变量q值可进行操作运算
扩展查询有下面特殊操作符:
操作符OR:hello | world,区配含有hello或world
操作符NOT:hello -world或hello !world,区配包含hello,且不包含world
字段搜索操作符:@title hello @body world,匹配title中有hello及body中有world
字段限位修饰符:@title[5] hello ,匹配title字段前5个词中包含有hello
多字段搜索符:@(title,body) hello,匹配title或body包含有hello
全字段搜索符:@* hello,区配任何一列包含有hello
阀值匹配符:"this is test document number"/3,匹配至少包含有3个词
短语(phrase)搜索符:“hello world”
临近(proximity)搜索符:“hello world”~10,匹配hello与world之间小于10个词
严格有序搜索符:aaa<<bbb<<ccc,匹配aaa,bbb,ccc按顺序出现
字段开始和字段结束修饰符:^hello world$,匹配以hello开始,world为结尾
sphinx增量索引更新
索引建立构成:1、固定不变的主索引。2、增量索引重建。3、索引数据的合并。
在实际操作中,需要为增量索引的建立创建辅助表,这样才可以记住最后建立索引的记录id来做实际的增量部分的索引建立。
1)创建辅助表:CREATE TABLE sph_counter (counter_id int(11) NOT NULL COMMENT '标识不同的数据表',max_doc_id int(11) NOT NULL COMMENT '每个索引表的最大ID,会实时更新',PRIMARY KEY (counter_id)) ENGINE=MyISAM DEFAULT CHARSET=utf8
2)在主索引的数据源中,在sql_query的查询语句中,增加where条件语句(WHERE id<=( SELECT max_doc_id FROM sph_counter WHERE counter_id = 1 ))
3)在增量索引的数据源中,继承主索引数据源,在sql_query的查询语句中,增加where条件语句,获取主索引中没有的数据(WHERE id > ( SELECT max_doc_id FROM sph_counter WHERE counter_id = 1 ))
4)分别配置主索引和增量索引的index定义配置。
生成主索引,可添加crontab,定时重建主索引:
indexer --config /etc/sphinxsearch/sphinx.conf --rotate 主索引
5)生成增量索引并且合并,可添加到crontab任务中每隔一段时间执行一次:
indexer --config /etc/sphinxsearch/sphinx.conf --rotate 增量索引
indexer --config /etc/sphinxsearch/sphinx.conf --merge 主索引 增量索引 --rotate
更改sph_counter表对应的max_doc_id值。
测试
现在一切都已设置好,让我们测试一下搜索功能。使用MySQL接口连接到SphinxQL(在端口9306上)。您的提示将更改为mysql>。
mysql -h0 -P9306
我们来搜索一个句子。
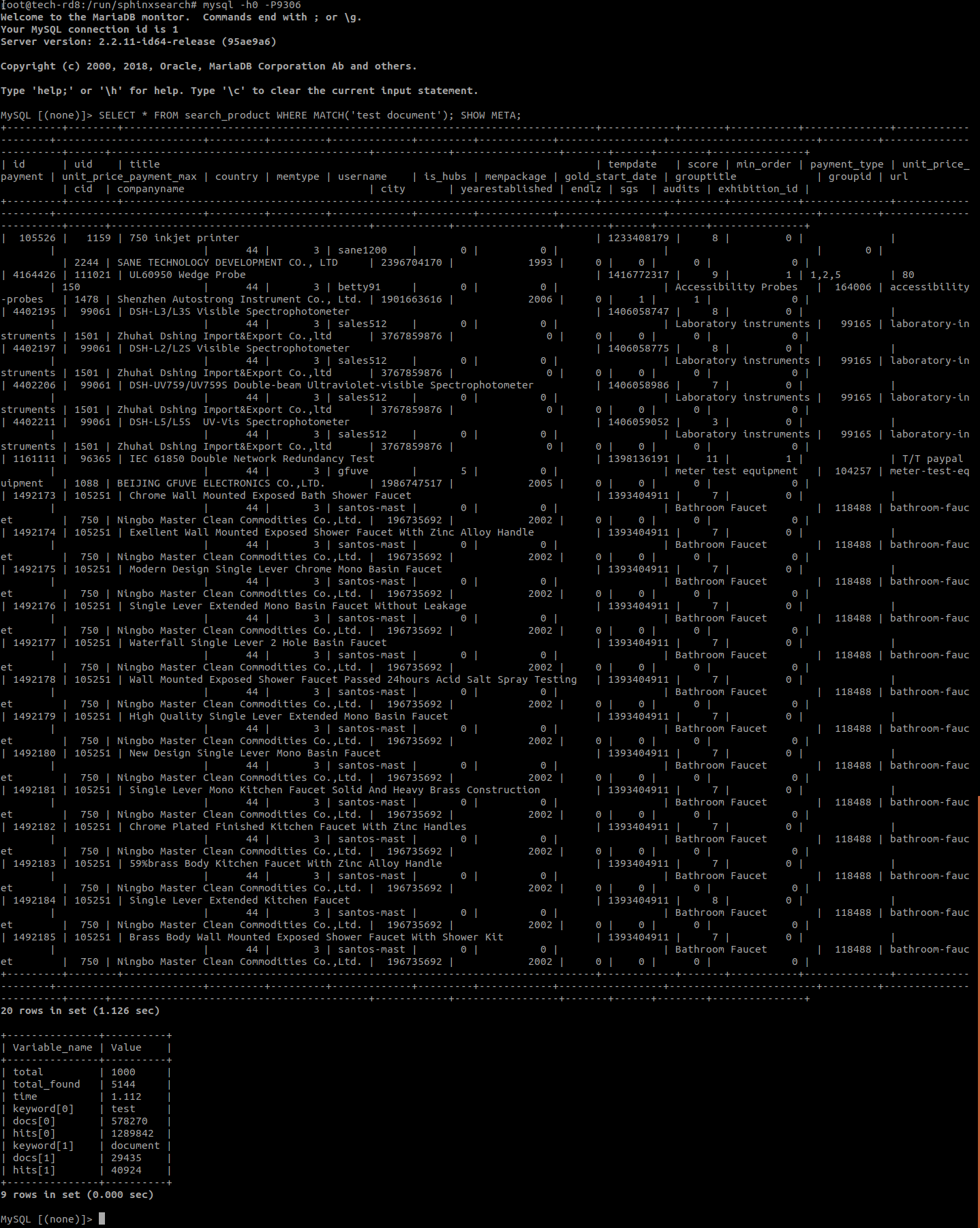
## search_product 索引 'test document'匹配的字符串 SHOW META;命令还显示句子中每个关键字的命中数。
SELECT * FROM search_product WHERE MATCH('test document'); SHOW META;
你应该得到类似下面的东西。
我们来搜索一些关键词。
CALL KEYWORDS ('test dog cat', 'search_productst0', 1);
你应该得到类似下面的东西。
MySQL [(none)]> CALL KEYWORDS ('test dog cat', 'search_productst0', 1);
+------+-----------+------------+-------+-------+
| qpos | tokenized | normalized | docs | hits |
+------+-----------+------------+-------+-------+
| 1 | test | test | 25309 | 47054 |
| 2 | dog | dog | 1217 | 2361 |
| 3 | cat | cat | 3219 | 6412 |
+------+-----------+------------+-------+-------+
3 rows in set (0.013 sec)
在上面的结果中,您可以看到在search_productst0索引中,Sphinx发现:
关键字“test”的25309个文档中的47054个匹配项
1217个文档中的2361个匹配项是关键字“dog”
3219个文档中的6412个匹配项是关键字“cat”
现在你可以离开MySQL shell了。
quit

 浙公网安备 33010602011771号
浙公网安备 33010602011771号