

python 基础
python 解释型语言。 常用的称为cpython Python目前有两个版本,Python2和Python3,最新版分别为2.7.13和3.6.2,现阶段大部分公司用的是Python2,Life is shot, you need Python. 人生苦短,我用Python。 4、Python优缺点 简单————Python是一种代表简单主义思想的语言。阅读一个良好的Python程序就感觉像是在读英语一样,尽管这个英语的要求非常严格!Python的这种伪代码本质是它最大的优点之一。它使你能够专注于解决问题而不是去搞明白语言本身。 易学————就如同你即将看到的一样,Python极其容易上手。前面已经提到了,Python有极其简单的语法。 免费、开源————Python是FLOSS(自由/开放源码软件)之一。简单地说,你可以自由地发布这个软件的拷贝、阅读它的源代码、对它做改动、把它的一部分用于新的自由软件中。FLOSS是基于一个团体分享知识的概念。这是为什么Python如此优秀的原因之一——它是由一群希望看到一个更加优秀的Python的人创造并经常改进着的。 高层语言————当你用Python语言编写程序的时候,你无需考虑诸如如何管理你的程序使用的内存一类的底层细节。 可移植性————由于它的开源本质,Python已经被移植在许多平台上(经过改动使它能够工作在不同平台上)。如果你小心地避免使用依赖于系统的特性,那么你的所有Python程序无需修改就可以在下述任何平台上面运行。这些平台包括Linux、Windows、FreeBSD、Macintosh、Solaris、OS/2、Amiga、AROS、AS/400、BeOS、OS/390、z/OS、Palm OS、QNX、VMS、Psion、Acom RISC OS、VxWorks、PlayStation、Sharp Zaurus、Windows CE甚至还有PocketPC、Symbian以及Google基于linux开发的Android平台! 解释性————这一点需要一些解释。一个用编译性语言比如C或C++写的程序可以从源文件(即C或C++语言)转换到一个你的计算机使用的语言(二进制代码,即0和1)。这个过程通过编译器和不同的标记、选项完成。当你运行你的程序的时候,连接/转载器软件把你的程序从硬盘复制到内存中并且运行。而Python语言写的程序不需要编译成二进制代码。你可以直接从源代码运行程序。在计算机内部,Python解释器把源代码转换成称为字节码的中间形式,然后再把它翻译成计算机使用的机器语言并运行。事实上,由于你不再需要担心如何编译程序,如何确保连接转载正确的库等等,所有这一切使得使用Python更加简单。由于你只需要把你的Python程序拷贝到另外一台计算机上,它就可以工作了,这也使得你的Python程序更加易于移植。 面向对象————Python既支持面向过程的编程也支持面向对象的编程。在“面向过程”的语言中,程序是由过程或仅仅是可重用代码的函数构建起来的。在“面向对象”的语言中,程序是由数据和功能组合而成的对象构建起来的。与其他主要的语言如C++和Java相比,Python以一种非常强大又简单的方式实现面向对象编程。 可扩展性————如果你需要你的一段关键代码运行得更快或者希望某些算法不公开,你可以把你的部分程序用C或C++编写,然后在你的Python程序中使用它们。 丰富的库————Python标准库确实很庞大。它可以帮助你处理各种工作,包括正则表达式、文档生成、单元测试、线程、数据库、网页浏览器、CGI、FTP、电子邮件、XML、XML-RPC、HTML、WAV文件、密码系统、GUI(图形用户界面)、Tk和其他与系统有关的操作。记住,只要安装了Python,所有这些功能都是可用的。这被称作Python的“功能齐全”理念。除了标准库以外,还有许多其他高质量的库,如wxPython、Twisted和Python图像库等等。 规范的代码————Python采用强制缩进的方式使得代码具有极佳的可读性。 5、Python应用场景 Web应用开发 Python经常被用于Web开发。比如,通过mod_wsgi模块,Apache可以运行用Python编写的Web程序。Python定义了WSGI标准应用接口来协调Http服务器与基于Python的Web程序之间的通信。一些Web框架,如Django,TurboGears,web2py,Zope等,可以让程序员轻松地开发和管理复杂的Web程序。 操作系统管理、服务器运维的自动化脚本 在很多操作系统里,Python是标准的系统组件。 大多数Linux发行版以及NetBSD、OpenBSD和Mac OS X都集成了Python,可以在终端下直接运行Python。有一些Linux发行版的安装器使用Python语言编写,比如Ubuntu的Ubiquity安装器,Red Hat Linux和Fedora的Anaconda安装器。Gentoo Linux使用Python来编写它的Portage包管理系统。Python标准库包含了多个调用操作系统功能的库。通过pywin32这个第三方软件 包,Python能够访问Windows的COM服务及其它Windows API。使用IronPython,Python程序能够直接调用.Net Framework。一般说来,Python编写的系统管理脚本在可读性、性能、代码重用度、扩展性几方面都优于普通的shell脚本。 科学计算机器学习 NumPy,SciPy,Matplotlib可以让Python程序员编写科学计算程序。 服务器软件(网络软件)——阿里云 Python对于各种网络协议的支持很完善,因此经常被用于编写服务器软件、网络爬虫。第三方库Twisted支持异步网络编程和多数标准的网络协议(包含客户端和服务器),并且提供了多种工具,被广泛用于编写高性能的服务器软件。 Linux下Python的安装 Python2.x 1、 下载Python2.x的包 2、 tar –zxvf python-2.7.15.tar 3、 yum install gcc 4、 ./configure 5、 Make && make install Python3.x 1、 依赖环境:yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel 2、 下载Python3的包 3、 tar –zxvf python-3.6.1.tgz 4、 ./configure 5、 Make && make install 6、 添加环境变量 第二章 python安装下载及基础语法 1、Python的下载 1、python网址:https://www.python.org/ 2、anaconda网址:https://www.anaconda.com/ 注意:Anaconda指的是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。 2、Python的安装 1、Python安装比较简单,只需要双击安装即可,安装比较快(window) 2、anaconda同样是双击安装,但是安装过程的时间比较长,需要很多依赖项(window)
Anaconda 安装 包含许多依赖库。
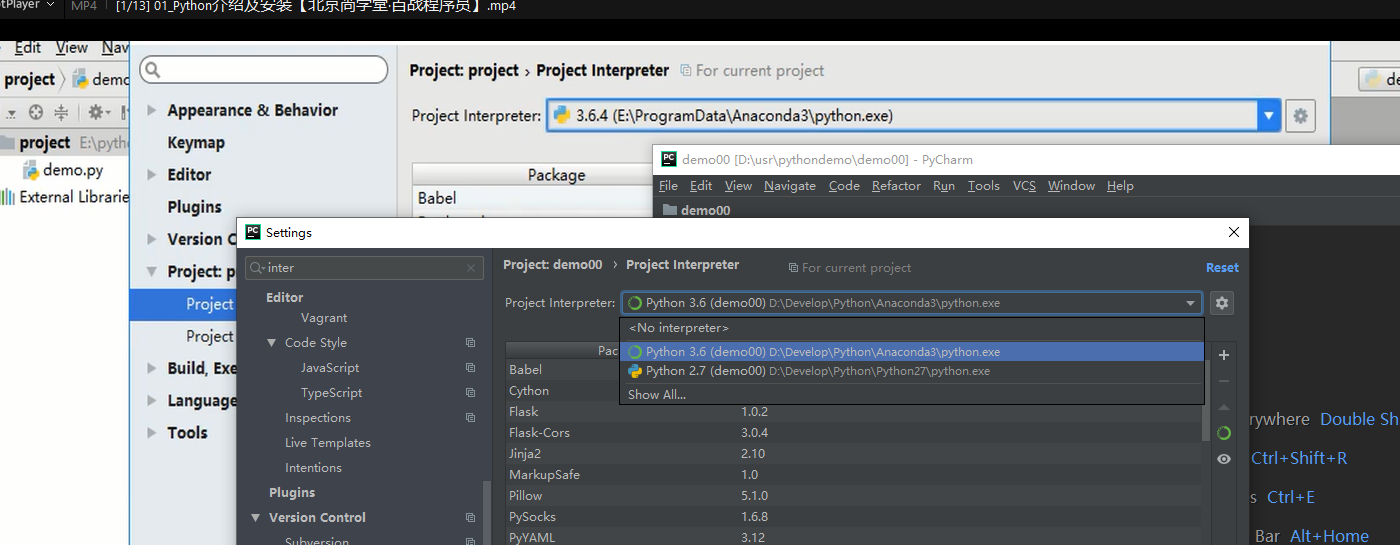
pycharm 推荐开发工具。 python 安装 python-2.7.15.amd64.msi Anaconda3-5.2.0-Windows-x86_64.exe 自带python3 环境变量
HelloWorld3.py
print("hellow python 中文")
HelloWorld2.py
print("hellow python 中文")
D:\usr\pythondemo\demo00>python D:\usr\pythondemo\demo00\com\bjsxt\HelloWorld3.py
hellow python 中文
切换编译器为python2之后,需要加字符集注释
HelloWorld2.py
#coding=utf-8
# _*_ coding:utf-8 _*_
'''
我是注释
'''
print("hellow python 中文")
## cmd 下也可以。
D:\usr\pythondemo\demo00>python D:\usr\pythondemo\demo00\com\bjsxt\HelloWorld2.py
hellow python 中文
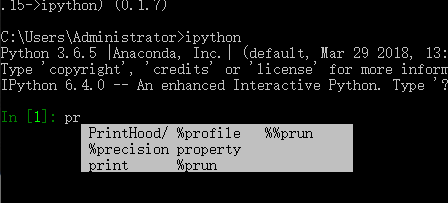
5、交互式窗口 1、python:在cmd中直接输入python(配置环境变量) 2、ipython:找到对应的ipython的执行文件,直接执行 Ipython:支持变量自动补全,自动缩进,支持 bash shell 命令,内置了许多很有用的功能和函数 注意:Python中本身不带有这个ipython的交互,需要自行安装。首先查看计算机中是否包含pip,一般安装完之后有,执行python –m pip install --upgrade pip,先将pip进行更新,然后安装ipython:pip install ipython 6 Python的注释及乱码 1、单行注释:以#开头,#右边的所有东西当做说明,而不是真正要执行的程序,起辅助说明作用 2、多行注释:’’’多行注释’’’可以写多行的功能说明 3、Python乱码问题 由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行: # -*- coding:utf-8 -*- # coding=utf-8
安装ipython 自动补全 C:\Users\Administrator>python -m pip install --upgrade pip C:\Users\Administrator>pip install ipython
C:\Users\Administrator>ipython
Python 3.6.5 |Anaconda, Inc.| (default, Mar 29 2018, 13:32:41) [MSC v.1900 64 bit
In [1]: print("hello")
hello
In [2]: ls
2019/10/02 11:25 <DIR> ..
2019/04/01 14:32 <DIR> .android
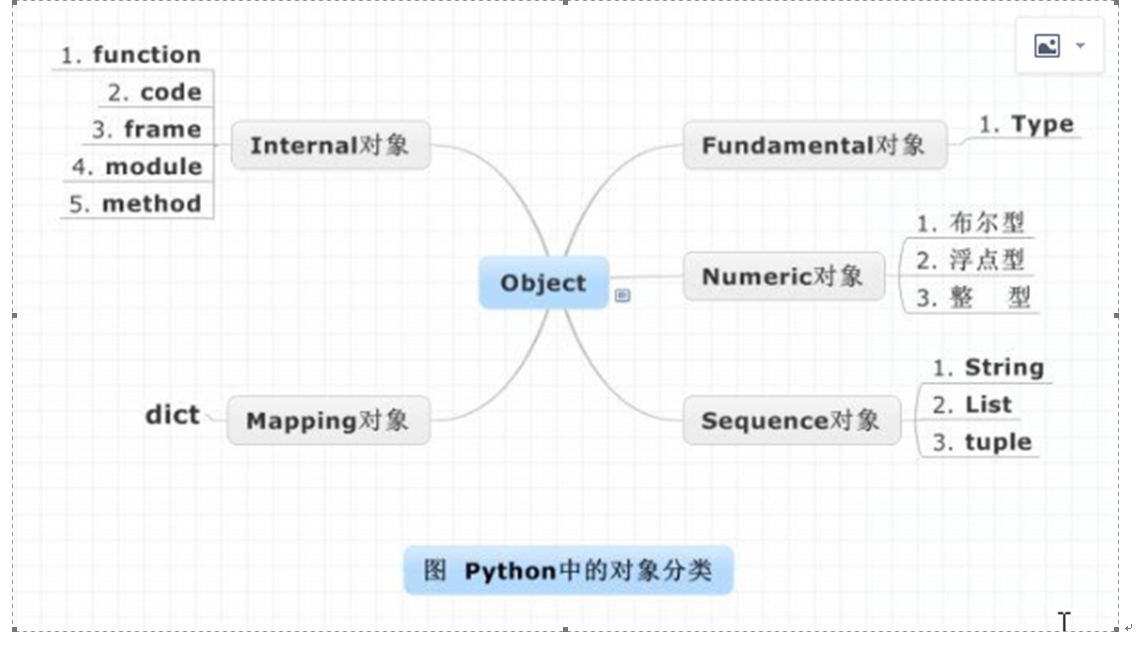
7、变量及类型 1、变量的定义 在程序中,有时我们需要对2个数据进行求和,那么该怎样做呢? 大家类比一下现实生活中,比如去超市买东西,往往咱们需要一个菜篮子,用来进行存储物品,等到所有的物品都购买完成后,在收银台进行结账即可 如果在程序中,需要把2个数据,或者多个数据进行求和的话,那么就需要把这些数据先存储起来,然后把它们累加起来即可 在Python中,存储一个数据,需要一个叫做变量的东西: 例如: num1=100 Num2=87 Result=num1+num2 变量三要素:变量的名称,变量的类型,变量的值 2、变量的类型 为了更充分的利用内存空间以及更有效率的管理内存,变量是有不同的类型,如图所示
python 中没有null 用None
字符串是以单引号或双引号括起来的内容。
标识符与java类似。驼峰命名,也可以用下划线
ipython 查看## 保留的标识符
In [5]: import keyword
In [6]: keyword.kwlist
Out[6]:
['False',
希望输出的内容不换行
>>> a=10
>>> print(a)
10
>>> print(a,end="")
10>>>
输出1+2=3
num1 = 1
num2 = 2
print("%d+%d=%d"%(num1,num2,num1+num2))
输出hello,world
a = 'world'
print("hello,%s"%a)
print("hello,%s"%('world'))
print("hello,%s"%'world')
字符串拼接
print('The quick brown fox', 'jumps over', 'the lazy dog')
%d 整数
%f 浮点数
%s 字符串
%x 十六进制整数
print(True,False)
'''
练习:编写程序
小明的成绩从去年的72分提升到了今年的85分,请计算小明成绩提升的百分点,
并用字符串格式化显示出'xx.x%',只保留小数点后1位:
'''
d = (85-72)/72 * 100
print(d)
print("%.1f%%"%d)
输入 python3
a=input("请输入数字:")
print(a)
python2
D:\Develop\Python\Python27>python
Python 2.7.16 (v2.7.16:413a49145e, Mar 4 2019, 01:37:19) [MSC v.1500 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> a=input("请输入:")
请输入:123
>>> a=input("请输入:")
请输入:abc
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<string>", line 1, in <module>
NameError: name 'abc' is not defined
>>> a=raw_input("请输入")
请输入abc
>>> print(a)
abc
>>> abc='abcdefg'
>>> a=input("请输入")
请输入abc
>>> print(a)
abcdefg
# print(10/3) #3.3333333333333335
# print(10//3) #3 ## 取整
# print(10//3.0) #3.0
# print(2**3) # 8 幂指数
a,b=1,2
print(a,b)
python 中没有a++
用如下:
a = 10
a+=1
>>>
age=input("请输入年龄:")
age = int(age)
if age>20:
print("长大了")
elif age >40:
print("老了")
else:
print("还小呢")
a = 10
if a >10:
pass
else:
pass
# i=1
# sum=0
# while i <=100:
# sum+=i
# i+=1
# print(sum)
## 九九乘法表
n = 1
while n <=9:
c= 1
while c<=n:
print("%d*%d=%d"%(c,n,c*n),end="\t")
c+=1
n+=1
print()
sum = 0
for i in range(1,100):
sum+=i
print(sum)
切片(分片)
切片是指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作。
切片的语法:[起始:结束:步长]
步长:表示下标变化的规律。
注意:选取的区间属于左闭右开型,即从"起始"位开始,到"结束"位的前一位结束(不包含结束位本身)。
# _*_ coding:utf-8 _*_
'''
集合
'''
a="abcdefg"
# print(a[0]) #a
# print(a[-1]) ## g
# ## 切片
# print(a[0:3]) ## abc
# print(a[:3]) ## abc
# print(a[2:]) ## cdefg
# print(a[2:7]) ## cdefg
# print(a[2:6]) ##cdef
# print(a[0:4:2])## ac
# print(a[::-1])## gfedcba
print('...........')
print(a[0:6:-1])##
print(a[1:-1]) ##bcdef
######
a="abcdefg"
a="abcdefg"
# print(a.find(a)) ##0
b = "Hello world hi python"
# print(b.title()) ## Hello World Hi Python
# print(a.rjust(20))# [ abcdefg]
# print("*"*50) ## 打印50个星
# print(a.center(50))
# print("*"*50)
print(a.isalpha())
list删除元素
<4>删除元素("删"del, pop, remove)
类比现实生活中,如果某位同学调班了,那么就应该把这个条走后的学生的姓名删除掉;在开发中经常会用到删除这种功能。
列表元素的常用删除方法有:
del:根据下标进行删除,其实可以删除所有变量
pop:默认删除最后一个元素
remove:根据元素的值进行删除第一个
## python2.7 (仅这一片段)
>>> a={"aaa":12,"bbb":23,"ccc":34}
>>> a.has_key("aaa")
True
s="abcdefg"
# print(s[20]) ## 报错,
print(s[2:20]) ## 不报错
'''
列表
'''
# a=["a","b","c",12,12.34]
# print(a)
# print(a.__len__(),len(a))
# print(a[100]) ## 报错
# print(a[-1])
# print(a[::-1]) ## 反转
# a.append("e")
# a.extend("f")
# b=["aa","bb","cc"]
# a.extend(b)
# a.insert(2,"hello")
# del(a)
# a.pop()
# a.remove(12)
# a.__delitem__(1)
# if "a" in a:
# print("存在")
# else:
# print('不存在')
# print(a.index("a"))
# print(a.index("c",2,6)) ## 从索引2找到6
# a=["a","b","c",12,12.34,"a","b"]
# print(a.count("a"))
# print(a)
# list存放 有序,不唯一的数据,数据类型不必一致
# print(a.sort()) ## TypeError: '< 排序类型必须一致
# c=[1,2,3,5,72,2]
# print(c)
# c.sort()
# print(c)
# c.reverse()
# print(c)
#
# for i,chrs in enumerate(c):
# print("%d-----%d"%(i,chrs))
#
# c[2] = "abcdefg"
# print(c)
'''
元组
'''
# a = ("a","b","c","d")
# a[2]="d" ## TypeError: 'tuple' object does n 元组不能修改数据
# print(id(a))
# b= (1,2,3,4,5)
# print(id(b)) ## 返回引用
# a=b
# print(id(a))
# print(a)
# t=(1)
# print(t) # 1
# t=(1,) ## 注意逗号才表示元组
# print(t) (1,)
'''
可变tuple
'''
# t=("a","b",["A","B"])
# print(t)
# t[2][0] = "X"
# t[2][1]= "Y"
# y=["X","Y"]
# t[2] = y ## TypeError: 'tuple' object 不能对直接子元组元素的引用进行修改
# print(t.index("a",))
# print(t.count("a"))
# print(t)
'''
dict 字典
'''
#dict
person={"aaa":12,"bbb":23,"ccc":34}
# print(person) ## {'aaa': 12, 'bbb': 23, 'ccc': 34}
# print(person['aaa'])
# abc = {"a","b","c"} ## set 可以为没有value的字典
# print(abc)
## 字典遍历
# for key in person.keys():
# print(key)
# for value in person.values():
# print(value)
# for item in person.items():
# print(item)
#
# for k,v in person.items():
# print(k,v)
## 修改元素
# person["aaa"] = 100
# person["ddd"] = 200
# del(person["bbb"])
# person.clear() ## {}
# del(person) ## 从内存中移除 or: name 'person' is not defined
print(person.ha)
print(person)
6、总结:
1、请务必注意,dict内部存放的顺序和key放入的顺序是没有关系的。
2、和list比较,dict有以下几个特点:
1)查找和插入的速度极快,不会随着key的增加而变慢;
2)需要占用大量的内存,内存浪费多。
3)而list相反:查找和插入的时间随着元素的增加而增加;占用空间小,浪费内存很少。
所以,dict是用空间来换取时间的一种方法。
总结:
1、可变类型,值可以改变:
列表 list
字典 dict
set (没有value的字典)
2、不可变类型,值不可以改变:
数值类型 int, long, bool, float
字符串 str
元组 tuple
'''
函数
'''
# def test():
# print("I'm function")
# # 调用;
# test() ## 不到定义重复的文件test __init__.py 不要删除
# def add(a,b):
# print(a+b)
# def add(a,b=2): ## 可以带有默认值
# print(a+b)
# add(1,2)
# add(1)
# add(b=3,a=5)
# a=1
# b=2
# add(a,b)
'''
不定长参数
'''
# def function(a,b,*args,**kwargs):
# print(a,b)
# print(*args)
# for i in kwargs.items():
# print(i)
#
# function(1,2,3,4,5,6,7,8,x=9,y=10)
# a=[1,2]
# a+=a
# print(a) # [1, 2, 1, 2]
'''
可变类型与不可变类型的传参
'''
# def add3(a):
# a+=1
# print(a)
#
# a = 10
# add3(a)
# print(a)## 10
# def add3(a):
# a+=a
# print(a)
# a =[1,2]
# add3(a)
# print(a) # [1, 2, 1, 2]
# a=(1,2)
# add3(a)
# print(a) #(1, 2)
'''
Python中函数参数是引用传递(注意不是值传递)。对于不可变类型,因变量不能修改,
所以运算不会影响到变量自身;而对于可变类型来说,函数体中的运算有可能会更改传入的参数变量。
'''
'''
函数返回值
'''
# def func(a,b):
# c = a+b
# return c
# print(func(2,3)) ## 5
# def func2(a):
# b = 100+a
# c=200+a
# return b,c # 返回值可以是多个
#
# b,c = func2(200)
# print(b,c) ## 300 400
'''
局部变量和全局变量
'''
# a=10
# def func(a):
# a+=10
# print(a)
# func(100)
# a=10
# def func():
# a+=10
# print(a)
# func() ## local variable 'a' referenced before assignment
# a=10
# def func():
# a=10
# print(a)
# func() ## local variable 'a' referenced before assignment
# a=10
# print(id(a))
# def func():
# global a
# a=a+ 10
# print(id(a))
# print(a) # 20
# func() ## local variable 'a' referenced before assignment
# print(a) # 20
# a = 100
# print(id(a))
# def test1():
# a=10
# print(a)
# a=20
# print(a)
#
# def test2():
# global a
# print(a)
# a += 200
# print(a)
# print(id(a))
#
# # test1()
# test2()
# print(id(a))
b = 10
def test():
print(b) ## 引用可以
# b=20 ## 修改值不允许 UnboundLocalError: local variable 'b' referenced before assignment
c=b
print(c)
test()
# _*_ coding:utf-8 _*_
'''
递归函数
'''
'''
斐波那契数列
'''
# def createNum(a):
# arr = []
# def getNum(b):
# if b <2:
# return 1
# else:
# return getNum(b-1) + getNum(b-2)
# for i in range(0,a):
# arr.append(getNum(i))
# print(arr)
#
# createNum(10)
'''
lambda : 小型的匿名函数
'''
# sum = lambda a,b:a+b
# print(sum(1,2))
# def test(a,b,opt):
# print(a)
# print(b)
# print("result:%d"%opt(a,b))
#
# test(1,2,lambda a,b:a+b)
stus = [ {"name":"zhangsan", "age":18}, {"name":"lisi", "age":19}, {"name":"wangwu", "age":17} ]
# stus.sort(key=lambda x:x['name'])
stus.sort(key=lambda x:x['age'])
print(stus)


# _*_ coding:utf-8 _*__
'''
文件操作
'''
f = open("./test.txt","r")
# a = f.read()
# a = f.readlines()
# a = f.readline()
# p = f.tell() ## 位置
# print(a)
# print(p)
# f.close()
# f = open("./test.txt","w")
# f = open("D:\\usr\\pythondemo\\demo00\\com\\bjsxt\\test.txt","w") ## 注意转义
# f = open(r"D:\usr\pythondemo\demo00\com\bjsxt\test.txt","w") ## r 表示字符是本身的含义
# f.write("hello Appollo; python is simple 1")
# f.close()
f = open("./test.txt","rb")
a = f.readline()
print(a)
# f.seek(0,0) ## 又从头开始读取
f.seek(-20,2) ## 需要rb模式
a = f.read()
print(a)
f.close()
import os
# print(os.name) ## Windows 返回 ‘nt'; Linux 返回’posix'
# print(os.getcwd())
# print(os.listdir("d:"))
# os.remove("./test1.txt")
'''
set 补充 # 相当于没有value的字典
'''
a = set([1,2,3,4])
print(a)


1、__new__至少要有一个参数cls,代表要实例化的类,此参数在实例化时由Python解释器自动提供 2、__new__必须要有返回值,返回实例化出来的实例,这点在自己实现__new__时要特别注意,可以return父类__new__出来的实例,或者直接是object的__new__出来的实例 3、__init__有一个参数self,就是这个__new__返回的实例,__init__在__new__的基础上可以完成一些其它初始化的动作,__init__不需要返回值 4、我们可以将类比作制造商,__new__方法就是前期的原材料购买环节,__init__方法就是在有原材料的基础上,加工,初始化商品环节

'''
类和对象
'''
# class Dog:
# class Dog(object):
# def run(self):
# print("running")
#
# dog = Dog()
# print(id(dog))
#
# dog2 = Dog()
# print(id(dog2))
#
# dog.run()
# class Dog:
# def run(self):
# print("running")
#
# dog = Dog()
# dog.name = "hello"
# dog.run()
# print(dog.name)
#
# dog2 = Dog()
# dog2.age =12
# print(dog2.age)
class Dog:
def run(self):
print("running")
## init 不是构造器只是完成对象的初始化
# def __init__(self):
# print("init被调用")
def __init__(self,name,age): ##对象的初始化,完成一些默认的设定
print("init被调用")
self.name = name
self.age = age
def __new__(cls,name,age): ## 这里才是创建对象
print("new被调用")
return object.__new__(cls)
def __del__(self):
print("对象被删除,和回收%s"%self.name)
def __str__(self):
# return object.__str__(self)
# return "hello python"
return "name:%s,age:%s"%(self.name,self.age)
## 先执行创建对象,再初始化
dog = Dog("旺财",7)
# dog.run()
# print(dog.name)
# dog2 = Dog("旺财22",17)
# print(dog2.age)
#
# print(dog)
# print(dog2)
# dog.run()
dog2 = dog
dog3 = dog
print("dog2 被删除")
del dog2
print("dog3 被删除")
del dog3
print("dog 被删除")
del dog
## dog 一直被引用,直到最后才删除。
"魔法"方法

'''
私有属性
'''
class Person(object):
def __init__(self,name,age):
self.__name = name ## 属性前加"__" 为私有属性
self.age = age
def setName(self,name):
if len(name) >3:
self.__name = name
else:
print("名字长度不符合规范")
def getName(self):
return self.__name
def __test(self):
print("test")
def test2(self):
self.__test()
p = Person("张三",12)
# # print(p.__name) ## AttributeError: 'Person' object has no attribute '__name'
# print(p.getName(),p.age)
# p.setName("dd")
# p.__test() ## AttributeError: 'Person' object has no attribute '__test'
p.test2() ## 用共有方法访问私有方法
# class Animal(object):
# def __init__(self,name):
# self.name = name
#
# def eat(self):
# print("吃的很开心")
#
# class Cat(Animal):
# def __init__(self,name,age):
# Animal.__init__(self,name)
# self.age = age
#
# def run(self):
# print("running")
#
#
# cat = Cat("哈哈",12)
# cat.run()
# cat.eat()
# print(cat.name)
# print(cat.age)
'''
单继承
'''
# class Animal(object):
# def __init__(self, name='动物', color='白色'):
# self.__name = name
# self.color = color
# def __test(self):
# print(self.__name)
# print(self.color)
# def test(self):
# print(self.__name)
# print(self.color)
#
#
# class Dog(Animal):
# def dogTest1(self):
# # print(self.__name)
# # 不能访问到父类的私有属性
# print(self.color)
# def dogTest2(self):
# # self.__test()
# # 不能访问父类中的私有方法
# self.test()
#
#
# A = Animal()
# # print(A.__name)
# # 程序出现异常,不能访问私有属性
# print(A.color)
# # A.__test()
# # 程序出现异常,不能访问私有方法
# A.test()
# print("------分割线-----")
# D = Dog(name="小花狗", color="黄色")
# D.dogTest1()
# D.dogTest2()
'''
多继承
'''
class A(object):
def test(self):
print("---------A----------")
class B(object):
def test(self):
print("------B-----")
class C(A,B):
# def test(self):
# A.test(self) ## 犯法重复时,必须指定父类方法
# def test(self): ## 打印A ,
# pass
def test(self): ## 打印A ,
# super(C,self).test()
super().test()
c = C()
c.test()
# print(C.__mro__)
## (<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class 'object'>)
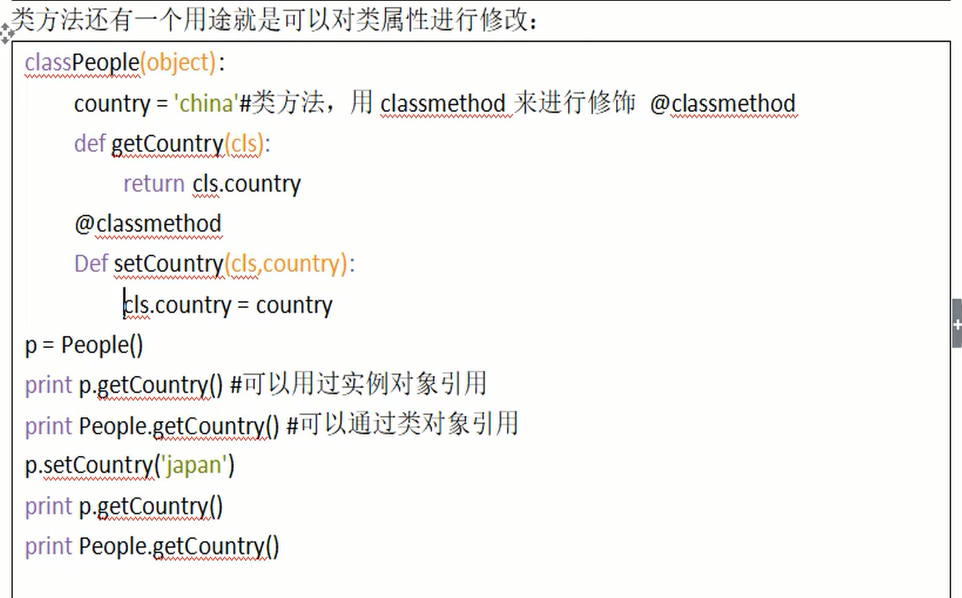
# class Person(object):
# name="zhangsan"
#
# def __init__(self,name,age):
# self.name = name
# self.age = age
#
# p = Person("lisi",12)
# print(p.name) ## lisi
# p.name="wangwu"
# print(p.name) ## wangwu
# print(Person.name) ## zhangsan
# Person.name = "maliu"
# print(Person.name) ## maliu
# print(p.name)
# class Person(object):
# name="zhangsan"
# # def __init__(self,name,age):
# # self.name = name
# # self.age = age
#
# p = Person()
# print(p.name) ## zhangsan
# p.name="wangwu"
# print(p.name) ## wangwu
# Person.name = "maliu"
# print(Person.name) ## maliu
# print(p.name) ## wangwu
'''
类方法和静态方法
'''
class Person(object):
name="zhangsan"
@classmethod
def test(cls):
print("类方法")
def test2(self):
print("test2")
@staticmethod
def test3():
print("test3")
p = Person()
p.test()
p.test2()
Person.test()
# Person.test2(p) ## TypeError: test2() missing 1 required positional argument: 'self'
Person.test3()
《设计模式之禅》 实例比较浅显易懂
'''
设计模式
'''
'''
单例模式
'''
#
# class Singleton:
# __instance = None
# def __new__(cls):
# if not cls.__instance:
# __instance=object.__new__(cls)
# return cls.__instance
#
# a = Singleton()
# b=Singleton()
# print(id(a))
# print(id(b))
'''
简单工厂模式
'''
class Person(object):
def __init__(self,name):
self.name = name
def work(self,type_axe):
print("%s开始工作了"%(self.name))
# axe=StoneAxe()
# axe=SteelAxe()
axe = Factory.create_axe(type_axe)
axe.cut_tree()
class Axe(object):
def cut_tree(self):
print("正在砍树")
class StoneAxe(Axe):
def cut_tree(self):
print("使用石头做的斧子砍树")
class SteelAxe(Axe):
def cut_tree(self):
print("使用钢铁做的斧子砍树")
class Factory(object):
@classmethod
def create_axe(self,type_axe):
if type_axe == "stone":
return StoneAxe()
elif type_axe == "steel":
return SteelAxe()
elif type_axe == "water":
return SteelAxe()
else:
print("传入的参数不对")
p = Person("张三")
p.work("steel")
p.work("stone")
## 切换斧子不太方便,需要工厂模式
## 斧头增加类型了
class WaterAxe(Axe):
def cut_tree(self):
print("使用水做的斧子砍树")
p.work("water")
'''
异常
'''
# f = None
# try:
# # print(num)
# print("test1")
# f = open("./123.txt","r") ## FileNotFoundError:
# print("test2")
# except (FileNotFoundError,NameError) as errormsg: ## errormsg 存储异常信息的基本描述
# print("报错了")
# print(errormsg)
# else:
# print("没有异常")
# finally:
# print("finally")
# if f:
# f.close()
#
# print("test3")
'''
自定义异常
'''
class ShortInputException(Exception):
'''自定义的异常类'''
def __init__(self, length, atleast):
# super().__init__()
self.length = length
self.atleast = atleast
def main():
try:
s = input('请输入 --> ')
if len(s) < 3: # raise引发一个你定义的异常
raise ShortInputException(len(s), 3)
except ShortInputException as result: # x这个变量被绑定到了错误的实例
print('ShortInputException: 输入的长度是 %d,长度至少应是 %d'% (result.length, result.atleast))
else:
print('没有异常发生.')
main()
<5>定位模块 当你导入一个模块,Python解析器对模块位置的搜索顺序是: 1、当前目录 2、如果不在当前目录,Python则搜索在shell变量PYTHONPATH下的每个目录。 3、如果都找不到,Python会察看默认路径。UNIX下,默认路径一般为/usr/local/lib/python/ 4、模块搜索路径存储在system模块的sys.path变量中。变量里包含当前目录,PYTHONPATH和由安装过程决定的默认目录。
<6>安装模块
conda create -n py2 python=2.7
conda install 模块
pip install 模块
pymysql
numpy
__init__.py
'''
可以将from import 的内容写到这里
'''
test.py
def add(a,b):
return a+b
def sub(a,b):
return a-b
'''
模块导包
'''
import os
# from os import * ## 最好需要谁就导谁
from os import path
# print(os.getcwd())
# print(os.path.isfile("./ImportDemo.py"))
# print(path.isfile("./ImportDemo.py"))
import pygame ## 没有,需要安装 ## C:\Users\Administrator>pip install pygame
import pymysql
'''
pip 是python自带的安装方式
pip install 模块
annaconda 也有一种安装方式
conda install 模块
pymysql
numpy
'''
## 导入自己写的包
import test
result = test.add(1,2)
print(result)
result = test.sub(3,2)
print(result)
模块的发布
1.mymodule目录结构体如下:
.
├── setup.py
├── suba
│ ├── aa.py
│ ├── bb.py
│ └── __init__.py
└── subb
├── cc.py
├── dd.py
└── __init__.py
2.编辑setup.py文件
py_modules需指明所需包含的py文件
from distutils.core import setup
setup(name="压缩包的名字", version="1.0", description="描述", author="作者", py_modules=['suba.aa', 'suba.bb', 'subb.cc', 'subb.dd'])
3.构建模块
python setup.py build
4.生成发布压缩包
python setup.py sdist
## 使用pip 暗转模块
C:\Users\Administrator>pip install pygame
C:\Users\Administrator>pip install pymysql
C:\Users\Administrator>pip install numpy

'''
列表推导式
'''
for i in range(1,10):
print(i)
a = [i for i in range(1,10)]
print(a)
a = [i for i in range(1,10) if i%2==0]
print(a)
b = [(i,j) for i in range(1,10) for j in range(1,10)]
print(b) ## 81个
b = [(i,j,k) for i in range(1,10) for j in range(1,10) for k in range(1,10)]
print(b) ##
b = ((i,j) for i in range(1,10)) ## 列表推导式不能这么写,不是叫元组推导式
print(b) ## <generator object <genexpr> at 0x000001C9C2AF3678>
# print(b[1]) ## TypeError: 'generator' object is not subscriptable
d = (1,2,3)
print(d)
'''
连接mysql数据库
pip install pymysql
新建数据库名test,导入如下数据
DROP TABLE IF EXISTS `dept`;
CREATE TABLE `dept` (
`DEPTNO` int(2) NOT NULL,
`DNAME` varchar(14) DEFAULT NULL,
`LOC` varchar(13) DEFAULT NULL,
PRIMARY KEY (`DEPTNO`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `dept` VALUES ('10', 'ACCOUNTING', 'NEW YORK');
INSERT INTO `dept` VALUES ('20', 'RESEARCH', 'DALLAS');
INSERT INTO `dept` VALUES ('30', 'SALES', 'CHICAGO');
INSERT INTO `dept` VALUES ('40', 'OPERATIONS', 'BOSTON');
DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (
`EMPNO` int(4) NOT NULL,
`ENAME` varchar(10),
`JOB` varchar(9),
`MGR` int(4),
`HIREDATE` date,
`SAL` int(7),
`COMM` int(7),
`DEPTNO` int(2),
PRIMARY KEY (`EMPNO`),
KEY `FK_DEPTNO` (`DEPTNO`),
CONSTRAINT `FK_DEPTNO` FOREIGN KEY (`DEPTNO`) REFERENCES `dept` (`DEPTNO`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `emp` VALUES ('7369', 'SMITH', 'CLERK', '7902', '1980-12-17', '800', null, '20');
INSERT INTO `emp` VALUES ('7499', 'ALLEN', 'SALESMAN', '7698', '1981-02-20', '1600', '300', '30');
INSERT INTO `emp` VALUES ('7521', 'WARD', 'SALESMAN', '7698', '1981-02-22', '1250', '500', '30');
INSERT INTO `emp` VALUES ('7566', 'JONES', 'MANAGER', '7839', '1981-04-02', '2975', null, '20');
INSERT INTO `emp` VALUES ('7654', 'MARTIN', 'SALESMAN', '7698', '1981-09-28', '1250', '1400', '30');
INSERT INTO `emp` VALUES ('7698', 'BLAKE', 'MANAGER', '7839', '1981-05-01', '2850', null, '30');
INSERT INTO `emp` VALUES ('7782', 'CLARK', 'MANAGER', '7839', '1981-06-09', '2450', null, '10');
INSERT INTO `emp` VALUES ('7788', 'SCOTT', 'ANALYST', '7566', '1987-04-19', '3000', null, '20');
INSERT INTO `emp` VALUES ('7839', 'KING', 'PRESIDENT', null, '1981-11-17', '5000', null, '10');
INSERT INTO `emp` VALUES ('7844', 'TURNER', 'SALESMAN','7698', '1981-09-08', '1500', '0', '30');
INSERT INTO `emp` VALUES ('7876', 'ADAMS', 'CLERK', '7788', '1987-05-23', '1100', null, '20');
INSERT INTO `emp` VALUES ('7900', 'JAMES', 'CLERK', '7698', '1981-12-03', '950', null, '30');
INSERT INTO `emp` VALUES ('7902', 'FORD', 'ANALYST', '7566', '1981-12-03', '3000', null, '20');
INSERT INTO `emp` VALUES ('7934', 'MILLER', 'CLERK', '7782', '1982-01-23', '1300', null, '10');
'''
import pymysql as pm
conn = pm.connect("node1","root","123456","demo") ## Connection
cursor=conn.cursor()
cursor.execute("select * from emp")
# emp = cursor.fetchone()
# print(emp) ## (7369, 'SMITH', 'CLERK', 7902, datetime.date(1980, 12, 17), 800, None, 20)
# print(type(emp)) ##<class 'tuple'>
all = cursor.fetchall()
print(all) ## ((7369,
conn.close()
#coding:utf-8
import pymysql
class MysqlHelper(object):
config={
"host":"node1",
"user":"root",
"password":"123456",
"db":"demo",
"charset":"utf8"
}
def __init__(self):
self.connection=None
self.cursor=None
# 从数据库表中查询一行数据 select count(*) from emp
def getOne(self,sql,*args):
try:
self.connection = pymysql.connect(**MysqlHelper.config)
self.cursor = self.connection.cursor()
self.cursor.execute(sql,args)
return self.cursor.fetchone()
except Exception as ex:
print(ex,ex)
finally:
self.close()
# 从数据库表中查询多行数据
def getList(self,sql,*args):
try:
self.connection = pymysql.connect(**MysqlHelper.config)
self.cursor = self.connection.cursor()
self.cursor.execute(sql,args)
return self.cursor.fetchall()
except Exception as ex:
print(ex,ex)
finally:
self.close()
# 对数据库进行增,删,改
def executeDML(self,sql,*args):
try:
self.connection = pymysql.connect(**MysqlHelper.config)
self.cursor = self.connection.cursor()
self.cursor.execute(sql,args)# 返回 sql语句执行之后影响的行数
new_id = self.connection.insert_id() # 返回系统刚刚自动生成的id
self.connection.commit();
return new_id
except Exception as ex:
self.connection.rollback()
print(ex,ex)
finally:
self.close()
def close(self):
if self.cursor:
self.cursor.close()
if self.connection:
self.connection.close()
if __name__ == "__main__":
helper = MysqlHelper()
print(helper.executeDML("delete from dept where deptno=%s",80))
# print(helper.executeDML("insert into dept values(%s,%s,%s)","80","admin","beijing"))
1. Numpy是什么?
NumPy(Numerical Python的缩写)是一个开源的Python科学计算库。使用NumPy,就可以很自然地使用数组和矩阵。 NumPy包含很多实用的数学函数,涵盖线性代数运算、傅里叶变换和随机数生成等功能。
这个库的前身是1995年就开始开发的一个用于数组运算的库。经过了长时间的发展,基本上成了绝大部分Python科学计算的基础包,当然也包括所有提供Python接口的深度学习框架。
4. numpy 基础:
NumPy的主要对象是同种元素的多维数组。这是一个所有的元素都是一种类型。在NumPy中维度(dimensions)叫做轴(axes),轴的个数叫做秩(rank)。NumPy的数组类被称作 ndarray(矩阵也叫数组) 。通常被称作数组。常用的ndarray对象属性有:ndarray.ndim(数组轴的个数,轴的个数被称作秩),ndarray.shape(数组的维度。这是一个指示数组在每个维度上大小的整数元组。例如一个n行m列的矩阵,它的shape属性将是(2,3),这个元组的长度显然是秩,即维度或者ndim属性),ndarray.size(数组元素的总个数,等于shape属性中元组元素的乘积),ndarray.dtype(一个用来描述数组中元素类型的对象,可以通过创造或指定dtype使用标准Python类型。另外NumPy提供它自己的数据类型)。
'''
numpy 库
矩阵
机器学习
'''
import numpy as np
# arr = np.array([[1,2,3],[4,5,6]])
# print(arr)
# print(arr.ndim) ## 轴的个数,秩
# print(arr.dtype) ## np.arange(1,10)
# print(arr.shape) ## (2, 3) 行列数量
# print(arr.size) ## 6
## 三维数组
# arr = np.array([[[1,2],[3,4],[5,6]],[[7,8],[9,10],[11,12]]])
# print(arr)
# print(arr.ndim)
# print(arr.dtype)
# print(arr.shape) ## (2, 3, 2)
# print(arr.size)
'''
创建数组的方式2
'''
# arr = np.arange(10).reshape(2,5)
# print(arr)
#
# arr = np.arange(27).reshape(3,3,3) ## 0-26
# print(arr)
# arr = np.arange(35).reshape(3,3,3) ## ValueError: cannot reshape array of size 35 into shape (3,3,3)
# print(arr)
# arr = np.random.random((2,5)) ## 随机小数[0,1) 10个, 2x5矩阵
# arr = np.random.randn(2,3) ## 正太分布
# arr = np.zeros((2,3)) ## 所有元素是0
# arr = np.ones((2,3)) ## 所有元素是1
# arr = np.empty((2,3)) ## 所有元素是0
# print(arr)
# arr=np.arange(10).reshape(2,5)
# print(arr)
# print(np.where(arr>5,arr,0))
# '''
# [[0 0 0 0 0]
# [0 6 7 8 9]]
# '''
# arr=np.random.randint(1,10,20).reshape(4,5)
# print(arr)
# print(arr[0])
# print(arr[0,0])
# print(arr[:,0]) ## 取第一列
# ## 取第一行和第四行
# print(arr[0:4:3])
# print(arr[[0,3]])
## 第一列和第四列
# print(arr[0:,0:5:3])
# print(arr[:,[0,3]])
# ## 第二三行,第二三列
# print(arr[[1,2]])
# print(arr[[1,2],1:3])
# print(arr[[1,2],[1,2]]) ## 合并成坐标了 不行
# for i in range(0,arr.shape[0]):
# print()
# for j in range(0,arr.shape[1]):
# print(arr[i][j],end=" ")
# print(arr.sum())
# print((arr>5).sum()) ## 大于5的个数
# print(arr.sum(0)) ## 逐行相加
# print(arr.sum(1)) ## 逐列相加
# arr=np.random.randint(1,10,20).reshape(4,5)
# arr1=np.random.randint(1,10,20).reshape(4,5)
# print(arr)
# print(arr1)
# print(arr+arr1)
'''
相乘
'''
# arr=np.random.randint(1,10,20).reshape(4,5)
# arr1=np.random.randint(1,10,20).reshape(5,4)
# print(arr)
# # print(arr1)
# # print(np.dot(arr,arr1))
# print(arr.T) ## 转置 旋转
# a = np.arange(10).reshape(2,5)
# print(a.resize(5,2))
# print(a)
b = np.arange(6).reshape(2,3)
print(b)
c = np.ones((2,3))
print(c)
# d = np.hstack((b,c)) # hstack:horizontal stack 左右合并
# print(d)
# e = np.vstack((b,c)) # vstack: vertical stack 上下合并
# print(e)
# f = np.column_stack((b,c))
# print(f)
# g = np.row_stack((b,c))
# print(g)
# h = np.stack((b, c), axis=1) # 按行合并
# print("--h------")
# print(h)
# i = np.stack((b,c), axis=0) # 按列合并
# print("--i------")
# print(i)
# j = np.concatenate ((b, c, c, b), axis=0) #多个合并
# print(j)
print()
print()
print()
i = np.stack((b,c), axis=0) # 按列合并
print(i)
print(i.shape)
#分割
k = np.hsplit(i, 2)
print(k)
l = np.vsplit(i, 2)
print(l)
m = np.split(i, 2, axis=0)
n = np.split(i, 2,axis=1)
print(m)
print(n)
o = np.array_split(np.arange(10),3) #不等量分割
print(o)
'''
机器学习
深度学习
神经网络
'''

 浙公网安备 33010602011771号
浙公网安备 33010602011771号