3.Spark设计与运行原理,基本操作
1.Spark已打造出结构一体化、功能多样化的大数据生态系统,请用图文阐述Spark生态系统的组成及各组件的功能。
Spark生态系统由:Spark SQL、Spark Streaming、MLlib、GraphX、Apache Spark组成,如图一所示
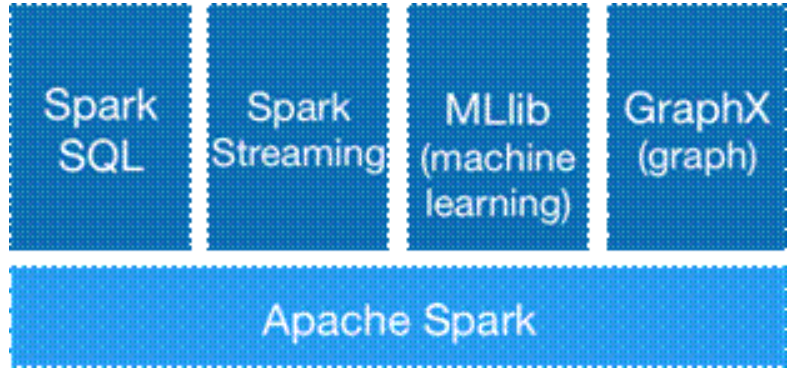
图1 Spark
Spark SQL:
Spark SQL 允许开发人员直接处理RDD,同时也可查询在 Hive 上存在的外部数据。SparkSQL 的一个重要特点是能够统一处理关系表和RDD,使得开发人员可以轻松地使用SQL 命令进行外部查询,同时进行更复杂的数据分析。
特点有:
1.引入了新的RDD 类型SchemaRDD,可以像传统数据库定义表一样来定义SchemaRDD。 SchemaRDD由定义了列数据类型的行对象构成。
2.内嵌了Catalyst 查询优化框架,在把SQL 解析成逻辑执行计划之后,利用Catalyst 包里的一些类和接口,执行了一些简单的执行计划优化,最后变成RDD 的计算。
3.在应用程序中可以混合使用不同来源的数据。
图2 Spark SQL
Spark Streaming:
Spark Streaming 是一个对实时数据流进行高吞吐、高容错的流式处理系统。
特点有:
易用性。Spark Streaming支持Java、Python、Scala等编程语言,可以像编写离线程序一样编写实时计算的程序求照的器。
容错性。Spark Streaming在没有额外代码和配置的情况下,可以恢复丢失的数据。
易整合性。Spark Streaming可以在Spark上运行,并且还允许重复使用相同的代码进行批处理。

图3 Spark Streaming
MLlib:
MLlib是Spark 实现一些常见的机器学习算法和实用程序,包括分类、回归、聚类、协同过滤、降维以及底层优化。该算法可以进行可扩充。
GraphX:
Spark GraphX是一个分布式图处理框架,它是基于Spark平台提供对图计算和图挖掘简洁易用的而丰富的接口,极大的方便了对分布式图处理的需求。
2.请详细阐述Spark的几个主要概念及相互关系:
Master, Worker; RDD,DAG; Application, job,stage,task; driver,executor,Cluster Manager
--------------------------------------------------
DAGScheduler, TaskScheduler.
Master,Worker:
搭建spark集群的时候我们就已经设置好了master节点和worker节点,一个集群有多个master节点和多个worker节点。master节点常驻master守护进程,负责管理worker节点,我们从master节点提交应用。worker节点常驻worker守护进程,与master节点通信,并且管理executor进程。
RDD,DAG:
它是spark中一种基本的数据抽象,有容错机制并可以被并行操作的元素集合,具有只读、分区、容错、高效、无需物化、可以缓存、RDD依赖等特征。RDD算子构建了RDD之间的关系,整个计算过程形成了一个由RDD和关系构成的DAG。
Application,job,stage,task:
Application:通俗讲,用户每次提交的所有的代码为一个application。
Job:一个application可以分为多个job。如何划分job?通俗讲,出发一个final RDD的实际计算为一个job
Stage:一个job可以分为多个stage。根据一个job中的RDD的依赖关系进行划分
Task:task是最小的基本的计算单位。一般是一个块为一个task,大约是128M
driver,executor,Cluster,Manage:
driver可以运行在master上,也可以运行worker上(根据部署模式的不同)。driver首先会向集群管理者(standalone、yarn,mesos)申请spark应用所需的资源,也就是executor,然后集群管理者会根据spark应用所设置的参数在各个worker上分配一定数量的executor,每个executor都占用一定数量的cpu和memory。在申请到应用所需的资源以后,driver就开始调度和执行我们编写的应用代码了。driver进程会将我们编写的spark应用代码拆分成多个stage,每个stage执行一部分代码片段,并为每个stage创建一批tasks,然后将这些tasks分配到各个executor中执行,executor进程宿主在worker节点上,一个worker可以有多个executor。
Cluster Manager:指的是在集群上获取资源的外部服务。目前有三种类型
(1)Standalone:Spark原生的资源管理,由Master负责资源的分配
(2)Apache Mesos:与Hadoop mr兼容性良好的一种资源调度框架
(3)Hadoop Yarn:主要是指Yarn中的ResourceManage
3.在PySparkShell尝试以下代码,观察执行结果,理解sc,RDD,DAG。请画出相应的RDD转换关系图。
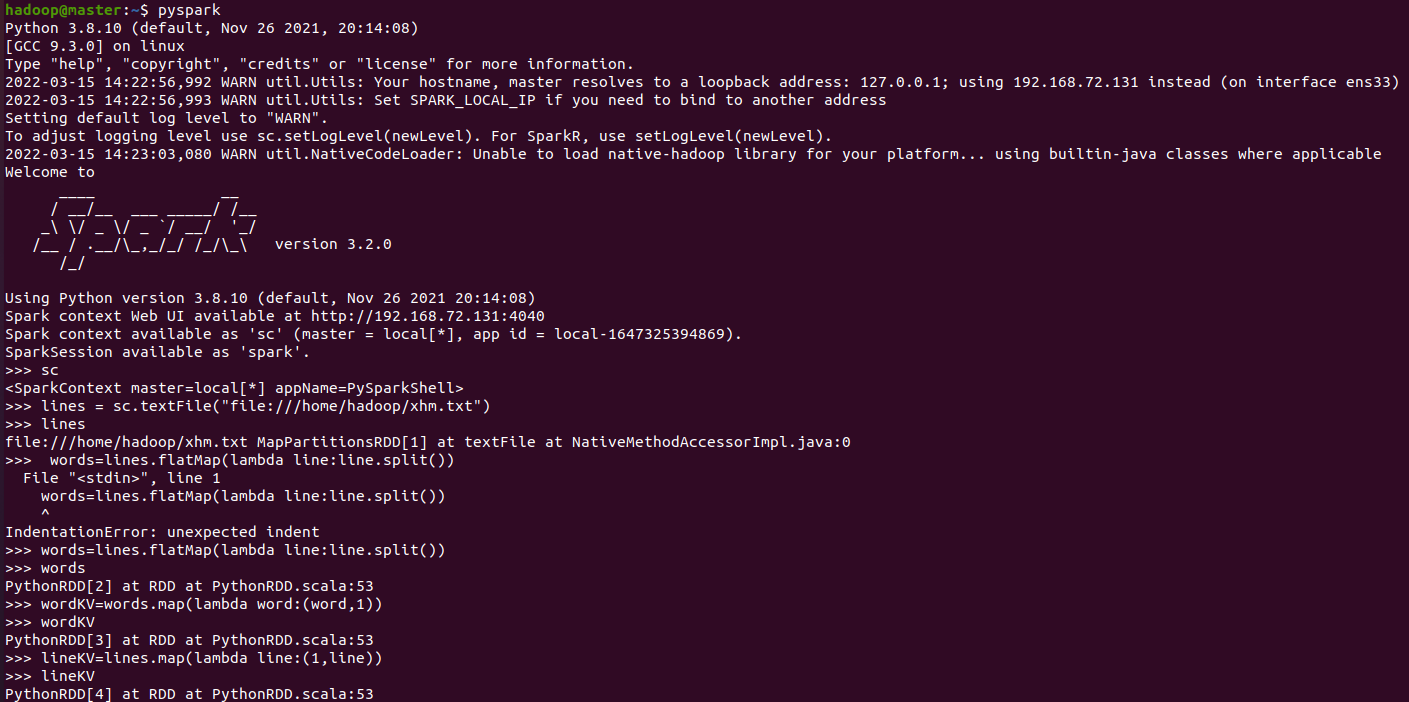 、
、



 浙公网安备 33010602011771号
浙公网安备 33010602011771号