

实验5文件应用编程
1.实验任务1
task1_1.py
1 with open('data1_1.txt','r',encoding='utf-8')as f: 2 data=f.readlines() 3 4 n=0 5 for line in data: 6 if line.strip('\n')=='': 7 continue 8 n+=1 9 print(f'共{n}行')

task1_2.py
1 with open('data1_1.txt','r',encoding='utf-8')as f: 2 n=0 3 for line in f: 4 if line.strip('\n')=='': 5 continue 6 n+=1 7 print(f'共{n}行')

task1_3.py
1 with open('data1_2.txt','r',encoding='utf-8')as f: 2 n=0 3 for line in f: 4 if line.strip()=='': 5 continue 6 n+=1 7 print(f'共{n}行')

task1_4.py
1 with open('data1_2.txt','r',encoding='utf-8')as f: 2 n=0 3 for line in f: 4 if line.isspace(): 5 continue 6 n+=1 7 print(f'共{n}行')

2.实验任务2
1 with open('data2.txt','r',encoding='utf-8')as f: 2 data=f.read().split('\n') 3 unique_line=[] 4 for line in data: 5 if data.count(line)==1: 6 unique_line.append(line) 7 print(f'共{len(unique_line)}独特行') 8 for i in unique_line: 9 print(i)

3.实验任务3
1 with open('data3.txt', 'r', encoding = 'utf-8') as f: 2 data = f.read().split('\n') 3 data0=data.copy() 4 for s in range(len(data0)): 5 data0[s]=data0[s]+'\t' 6 print(data0) 7 for i in range(1,len(data)): 8 data[i]=eval(data[i]) 9 if data[i]-int(data[i])>=0.5: 10 data[i]=int(data[i])+1 11 else: 12 data[i]=int(data[i]) 13 data[0]='四舍五入后数据' 14 for j in range(len(data)): 15 data[j]=str(data[j])+'\n' 16 print(data) 17 data2=[] 18 for x,y in zip(data0,data): 19 z=x+y 20 data2.append(z) 21 print(data2) 22 with open('data3.txt', 'w', encoding = 'utf-8') as f: 23 f.write(''.join(data2))
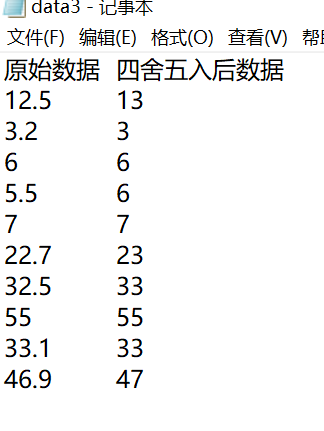
4.实验4
1 with open('data4.txt','r',encoding='utf-8')as f: 2 with open('data4_processed.txt','w',encoding='utf-8')as f1: 3 data=f.readlines() 4 data1=[i.strip('\n').split('\t') for i in data] 5 x=data1.pop(0) 6 data2=[sorted(data1,key=lambda x: (x[2], -int(x[3])))] 7 print('\t\t'.join(x)) 8 f1.write('\t\t'.join(x)+'\n') 9 for i in data2: 10 for j in i: 11 print('\t'.join(j)) 12 f1.write('\t'.join(j)+'\n')
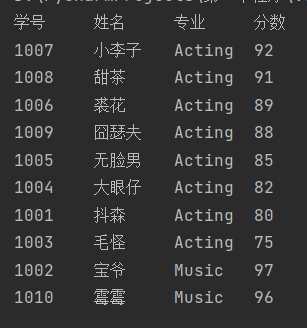
5.实验5
1 data=[] 2 word1=0 3 word2=0 4 word3=0 5 with open('data5.txt', 'r',encoding = 'utf-8') as f: 6 for i in f: 7 data.append(i) 8 for i in range(len(data)): 9 word1+=len(data[i].split(' ')) 10 word2+=len(data[i]) 11 word3+=data[i].count(' ') 12 print('行数:',len(data)) 13 print('单词数:',word1) 14 print('字符数:',word2) 15 print('空格数',word3) 16 for i in range(len(data)): 17 data[i]=str(i+1)+' '+data[i] 18 with open('data5.txt', 'w',encoding = 'utf-8') as f: 19 f.writelines(data)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号