JVM和垃圾回收面试题
java虚拟机
Jvm概述
概念+作用
jvm就是java虚拟机,是在操作系统之上,抽象出来的计算机
java利用jvm跨平台执行字节码文件(不同平台使用不同的jvm,但字节码文件可以跨平台)
扩展:
虚拟机是基于操作系统和硬件平台并利用软件方法来实现的抽象计算机
jvm运行在操作系统之上,没有直接跟硬件交互
Jvm的作用
加载字节码文件到内存(由类加载器完成)
将程序解释成对应操作系统可以理解的语言进行执行(由执行引擎来完成)
进行自动内存管理,垃圾回收(由垃圾收集器来完成)
为什么要了解jvm
1、内存是由JVM自动管理的,所以一旦出现内存泄漏或溢出的问题,方便排查问题。
2、有助于写出更高质量的代码,写出高性能的代码
了解到jvm的GC,可以进行优化代码,便于对不再使用的对象的回收
主流java虚拟机的类型
HotSpot VM 比如sun的jdk,linux开源的 openjdk
J9 VM IBM的J9 JDK
Zing VM
在许多平台上,IBM J9 VM都只能跟IBM产品一起使用。这不是技术限制,而是许可证限制。
Hotspot JVM是C++实现的
Jvm的组成
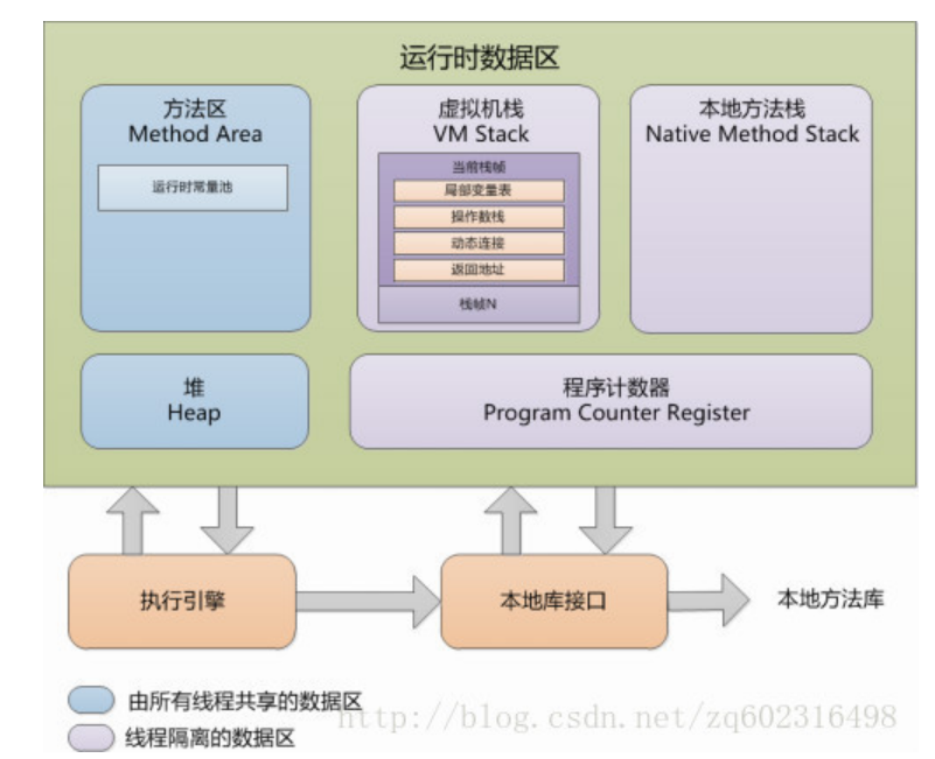
JVM 整体组成可分为以下四个部分:
类加载器(ClassLoader)
运行时数据区(Runtime Data Area)
执行引擎(Execution Engine)
本地库接口(Native Interface)
各个组成部分的用途:
程序在执行之前javac编译器把java代码转换成字节码(class文件),需要某个类时,jvm首先需要使用类加载器(ClassLoader)把文件加载到内存中:运行时数据区(Runtime Data Area) ,而字节码文件是jvm的一套指令集规范,并不能直接交个底层操作系统去执行,因此需要特定的命令解析器:执行引擎(Execution Engine) 将字节码翻译成底层系统指令再交由CPU去执行,而这个过程中需要调用其他语言的接口 本地库接口(Native Interface) 来实现整个程序的功能,这就是这4个主要组成部分的职责与功能。
Javac属于jdk不属于jvm,jdk包括jre和很多工具包括javac,jre是java运行环境,包括jvm和运行类库
类加载器
比较两个类是否“相等”,只有在这两个类是由同一个类加载器加载的前提下才有意义,否则,即使这两个类来源于同一个Class文件,被同一个虚拟机加载,只要加载它们的类加载器不同,那么这两个类必定不相等。对于接口同样适用(接口就是一个特殊的类);
类只需加载一次就行,因此要保证类加载过程线程安全,防止类加载多次。
类加载器加载一个类如果不存在,会抛出ClassNotFoundException异常。
jvm自带的类加载器:(按级别由高到低排序)
启动类加载器(Bootstrap ClassLoader),又被称为根类加载器(负责加载核心包$JAVA_HOME中jre/lib/rt.jar里所有的class,由C++实现,不是ClassLoader子类)没有父加载器
扩展类加载器(Extension ClassLoader),它负责加载JRE的扩展目录,lib/ext或者由java.ext.dirs系统属性指定的扩展包目录中的JAR包的类。由Java语言实现,父类加载器为启动类加载器。
应用程序类加载器(Application ClassLoader)。被称为系统类加载器(System ClassLoader),负责加载环境变量classpath或系统属性java.class.path指定路径下的类库。程序可以通过ClassLoader的静态方法getSystemClassLoader()来获取系统类加载器。如果没有特别指定,则用户自定义的类加载器都以此类加载器作为父加载器。由Java语言实现,父类加载器为扩展类加载器。
类外还有不是jvm自带的类加载器,就是我们自定义的类加载器,父加载器是应用程序类加载器。
类加载机制
JVM的类加载机制主要有如下3种。
全盘负责:所谓全盘负责,就是当一个类加载器负责加载某个Class时,该Class所依赖和引用其他Class也将由该类加载器负责载入,除非显示使用另外一个类加载器来载入。
加载类的顺序:
JVM类加载器在加载类时并不是按照加载器的“级别”或“优先级”来决定加载顺序的,而是遵循双亲委派模型进行类的加载。
双亲委派:当应用需要加载一个类时,首先会检查该类是否已经被加载过(在缓存中),如果已经加载过则直接返回。如果没有加载过,则会委托给父加载器进行加载。如果父加载器也无法加载该类,那么子加载器才会尝试自己加载。
委托关系:用户类加载器->系统类(应用程序类)加载器->扩展类加载器->根类(启动类)加载器
好处:可以避免类的重复加载,当父亲已经加载了该类时,就没有必要子ClassLoader再加载一次。其次是考虑到安全因素,java核心api中定义类型不会被随意替换(如自定义的java.lang.String并不会重新加载新加的这个String类,因为最后委托到根类加载器发现已经加载过了,所以创建的对象也是核心包里面的String类对象)
如何破坏双亲委派模型:
- 自定义一个类加载器,重写loadClass方法,不去调用让父类加载的方法就破坏掉了
- tomcat可以加载自己目录下的class文件,并不会传递给父类的加载器。
tomcat是怎么打破双亲委派模型的:
通过自定义的类加载器(WebAppClassLoader),它不会直接交给应用程序类加载器,在应用程序类加载走之前先自己加载,如果加载不了再交给父类加载器(是一个应用程序类加载器)。
tomcat打破双亲委派模型不会破坏java核心api的类吗:
不会,tomcat自定义类加载器加载类时,对于没有加载过的类,它会把让扩展类加载器尝试加载,扩展类加载器加载不了会交给启动类记载器加载,都加载不了,才会交给tomcat自定义的类加载器去加载,可以可以避免jre的核心类被破坏;如果tomcat自定义类加载器还加载不了会交给自己的父类应用程序类加载器进行加载。
tomcat为什么要打破双亲委派模型:
处理类冲突问题:如果同一个tomcat下有多个应用定义的包名类名相同,如果用双亲委派模型没办法都成功运行,tomcat为每个应用都创建一个自定义类加载器,不同的类加载器加载的类被认为是不同的类,即使名称相同,这样不同应用就都可以加载了。
同一个tomcat多个应用共享的jre核心类会加载多次吗:
不会,tomcat在定义的类加载器(WebAppClassLoader)上加了一个SharedClassLoader,如果 WebAppClassLoader 自己没有加载到某个类,就会委托父加载器SharedClassLoader 去加载这个类
如何隔离 Tomcat 本身的类和 web 应用的类:
Tomcat 又设计了一个类加载器CatalinaClassLoader,专门来加载 Tomcat 自身的类,
再增加一个 CommonClassLoader,作为 CatalinaClassLoader 和 SharedClassLoader 的父加载器。CommonClassLoader 能加载的类都可以被 CatalinaClassLoader 和 SharedClassLoader 使用,而 CatalinaClassLoader 和 SharedClassLoader 能加载的类则与对方相互隔离。WebAppClassLoader 可以使用 SharedClassLoader 加载到的类,但各个 WebAppClassLoader 实例之间相互隔离。
缓存机制。缓存机制将会保证所有加载过的Class都会被缓存,当程序中需要使用某个Class时,类加载器先从缓存区中搜寻该Class,只有当缓存区中不存在该Class对象时,系统才会读取该类对应的二进制数据,并将其转换成Class对象,存入缓冲区中。这就是为什么修改了Class后,必须重新启动JVM,程序所做的修改才会生效的原因。
类的加载过程:
类通常是按需加载,即第一次使用该类时才加载(懒加载)。
对于springboot应用在启动时就会把启动类、配置类、关键框架类、需要放到 spring容器中的非懒加载的类加载了,其他的像没有放到spring容器管理的类、懒加载的类、动态代理的类(目标方法调用时)会在应用使用的时候进行加载。
类加载器在加载类时,是针对单个类进行的,每个类的加载都是独立的。因此,如果一个类加载失败,并不会阻止类加载器加载其他类。
然而,需要注意的是,如果加载失败的类是被其他类所依赖的,那么当尝试使用到那个依赖的类时,可能会因为找不到依赖的类而抛出异常,如果核心类库加载失败,那么整个JVM可能都无法正常启动,自然也无法加载其他类。
类加载的过程包括了加载、验证、准备、解析、初始化五个阶段(验证、准备以及解析三个阶段又被称为链接。)。这些阶段通常都是互相交叉地混合进行的,通常在一个阶段执行的过程中调用或激活另一个阶段。
加载:
类的加载指的是将类的.class文件中的二进制数据读入到内存中(通过字节流的方式读取),将其放在方法区(元空间)内,然后在堆区创建一个 java.lang.Class对象。
链接:
(1)验证阶段。主要的目的是确保被加载的类(.class文件的字节流)满足Java虚拟机规范(如类的字节码文件已经损坏或被篡改)(会抛出相应的异常来指示错误),不会造成安全错误。如果验证失败,那么尽管Class对象已经被创建,但它不会被用来初始化类或者执行其代码。
(2)准备阶段。负责为类的静态成员分配内存,并设置默认初始值。
(3)解析阶段。将类的二进制数据中的符号引用替换为直接引用。
说明:符号引用。即一个字符串,但是这个字符串给出了一些能够唯一性识别一个方法,一个变量,一个类的相关信息。
直接引用。可以理解为一个内存地址,或者一个偏移量。比如类方法,类变量的直接引用是指向方法区的指针;而实例方法,实例变量的直接引用则是从实例的头指针开始算起到这个实例变量位置的偏移量。
举个例子来说,现在调用方法hello(),这个方法的地址是0xaabbccdd,那么hello就是符号引用,0xaabbccdd就是直接引用。
初始化:
初始化,对static修饰的静态变量或语句块进行初始化(如果指定了初始值这里进行赋值)。
如果初始化一个类的时候,其父类尚未初始化,则优先初始化其父类。
如果同时包含多个代码块,则按照自上而下的顺序依次执行。
类的卸载
使用jvm的类加载器加载的类不会被卸载
JVM内存结构/内存模型
按照Java虚拟机规范的规定,JVM自动管理的内存将会包括以下几个运行时数据区域。
程序计数器
程序计数器是线程私有的内存区域,保存着当前线程执行的虚拟机字节码指令的内存地址。
利用程序计数器可以方便线程切换后恢复执行。
(
Java多线程的实现,其实是通过线程间的轮流切换并分配处理器执行时间的方式来实现的,在任何时刻,处理器都只会执行一个线程中的指令。在多线程场景下,为了保证线程切换回来后,还能恢复到原先状态,找到原先执行的指令,所以每个线程都会设立一个程序计数器,并且各个线程之间不会互相影响,程序计数器为"线程私有"的内存区域。
如果当前线程正在执行Java方法,则程序计数器保存的是虚拟机字节码的内存地址,如果正在执行的是Native方法(非Java方法,JVM底层有许多非Java编写的函数实现),计数器则为空。程序计数器是唯一一个在Java规范中没有规定任何OutOfMemory场景的区域。
)
虚拟机栈
虚拟机栈也是线程私有的内存区域,存放的方法执行的局部变量和临时数据
栈特点:后入先出,存取速度比堆要快,仅次于寄存器,中的数据大小与生存期必须是确定的,缺乏灵活性
栈存放的数据:局部变量
栈的作用:作为执行程序的临时存储
虚拟机栈(Java Virtual Machine Stacks)和线程是紧密联系的,每创建一个线程时就会对应创建一个Java栈,所以Java栈也是"线程私有"的内存区域,这个栈中又会对应包含多个栈帧,每调用一个方法时就会往栈中创建并压入一个栈帧,栈帧是用来存储方法数据和部分过程结果的数据结构,每一个方法从调用到最终返回结果的过程,就对应一个栈帧从入栈到出栈的过程。
线程运行过程中,只有一个栈帧是处于活跃状态的,被称为"当前活动帧栈",当前活动帧栈始终是虚拟机栈的栈顶元素。
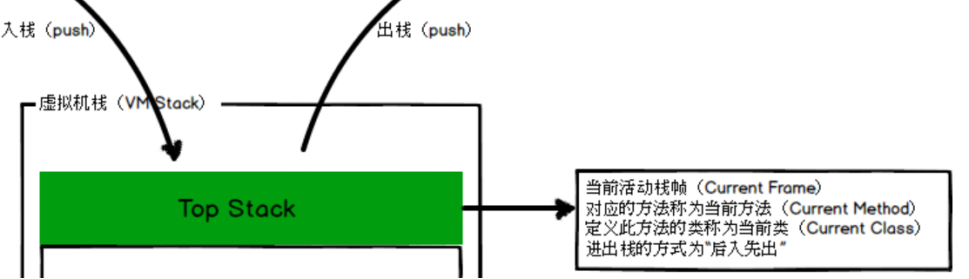
栈帧:每个栈帧对应一个被调用的方法,在编译程序代码的时候,栈帧中需要多大的局部变量表,多深的操作数栈都已经完全确定了
栈帧的组成:局部变量表,操作数栈,动态链接,返回地址
局部变量表(Local Variable Table)是一组变量值存储空间,用于存放方法参数和方法内部定义的局部变量。局部变量表的容量以变量槽(Variable,下称Slot)为最小单位
局部变量表中的变量不可直接使用,如需要使用的话,必须通过相关指令将其加载至操作数栈中作为操作数使用。
操作数栈:以压栈和出栈的方式存储操作数的,例如,在做算术运算的时候是通过操作数栈来进行的,又或者在调用其他方法的时候是通过操作数栈来进行参数传递的
动态链接:每个栈帧都包含一个指向运行时常量池中该栈帧所属方法的引用,持有这个引用是为了支持方法调用过程中的动态连接
方法返回地址:当一个方法开始执行后,只有两种方式可以退出,一种是遇到方法返回的字节码指令;一种是遇见异常,并且 这个异常没有在方法体内得到处理。无论采用何种退出方式,在方法退出之后,都需要返回到方法被调用的位置,程序才能继续执行,方法返回时可能需要在栈帧中保存一些信息,用来帮助恢复它的上层方法的执行状态。
在实际开发中,一般会把动态连接,方法返回地址与其它附加信息全部归为一类,称为栈帧信息。
本地方法栈
本地方法栈(Native Method Stack)和虚拟机栈的作用相似,不过虚拟机栈是为Java方法服务的,而本地方法栈是为Native方法服务的。Navtive 方法是 Java 通过 JNI 直接调用本地 C/C++ 库,可以认为是 Native 方法相当于 C/C++ 暴露给 Java 的一个接口,Java 通过调用这个接口从而调用到 C/C++ 方法。
方法区/元空间
方法区(Method Area)是线程共享的内存区域,是用于存储类结构信息的地方,包括运行时常量池(静态常量池在class文件中不在方法区)、静态变量、构造函数等类型信息,类型信息是由类加载器在类加载时从类文件中提取出来的。
方法区同样存在垃圾收集,因为用户通过自定义加载器加载的一些类同样会成为垃圾,JVM会回收一个未被引用类所占的空间,以使方法区的空间达到最小。
方法区中还存在着常量池,常量池包含着一些常量和符号引用(加载类的连接阶段中的解析过程会将符号引用转换为直接引用)。
注意:
在jdk8前,方法区是堆的一个“逻辑部分”(一片连续的堆空间)。Jdk8之前Hotspot虚拟的方法区实现是永久代(PermGen space)
在jdk1.8中,方法区已经不存在,原方法区中存储的类信息、编译后的代码数据等已经移动到了元空间(MetaSpace)中,元空间并没有处于堆内存上,而是直接占用的本地内存(NativeMemory)。
运行时常量池的存储:
在JDK1.7之前运行时常量池逻辑包含字符串常量池存放在方法区, 此时hotspot虚拟机对方法区的实现为永久代
在JDK1.7 字符串常量池被从方法区拿到了堆中, 这里没有提到运行时常量池,也就是说字符串常量池被单独拿到堆,运行时常量池剩下的东西还在方法区, 也就是hotspot中的永久代
在JDK1.8 hotspot移除了永久代用元空间(Metaspace)取而代之, 这时候字符串常量池还在堆, 运行时常量池还在方法区, 只不过方法区的实现从永久代变成了元空间(Metaspace)
元空间说明
元空间代替永久代的原因
- 永久代的内存在启动的时候是固定好的,类和方法信息等比较难确定大小,不容易调优。
- 随着动态类加载的情况越来越多,这块内存变得不太可控,容易内存溢出。
- 永久代会为 GC 带来不必要的复杂度,并且回收效率偏低。(永久代垃圾在full GC时进行回收)
使用元空间后元空间大小会根据情况进行调整,而且元空间放在虚拟机内存外,有效的控制了内存溢出问题。
元空间的特点
类及相关的元数据的生命周期与类加载器的一致。
每个加载器有专门的存储空间
元空间里的对象的位置是固定的
如果GC发现某个类加载器不再存活了,会把相关的空间整个回收掉
元空间的内存管理:可以通过运行参数指定
元空间的初始大小:默认为20.8M,达到该值就会触发垃圾收集进行类型卸载,同时GC会对该值进行调整:如果释放了大量的空间,就适当降低该值;如果释放了很少的空间,那么在不超过MaxMetaspaceSize时,适当提高该值。
元空间的最大空间:默认是没有限制的。
元空间的内存管理是由元空间虚拟机来管理:
先前的永久代,对于类的元数据我们需要不同的垃圾回收器进行处理,现在只需要执行元空间虚拟机的C++代码即可完成。
注:详细可以搜索元空间内存管理学习
java常量池
java中的常量池分为两种形态:静态常量池和运行时常量池。
静态常量池:(也叫class文件常量池)即*.class文件中的常量池,每一个Class文件中,都维护着一个常量池,当编译生成字节码文件直接就不变了。class文件中的常量池不仅仅包含字符串(数字)字面量,还包含类、方法的信息,占用class文件绝大部分空间。这种常量池主要用于存放两大类常量:字面量(Literal)和符号引用量(Symbolic References),字面量相当于Java语言层面常量的概念,如文本字符串,声明为final的常量值等,符号引用则属于编译原理方面的概念,包括了如下三种类型的常量:
- 类和接口的全限定名
- 字段名称和描述符
- 方法名称和描述符
字面量:
字面量是指由字母,数字等构成的字符串或者数值,它只能作为右值出现,所谓右值是指等号右边的值
描述符:也就是修饰符,如public、protected、private、abstract、static、final、synchronized、volatile等
运行时常量池:则是jvm虚拟机在完成类装载操作后,将静态常量池中的内容加载到运行时常量池,并保存在方法区中,我们常说的常量池,就是指方法区中的运行时常量池。
程序运行时,除非手动向常量池中添加常量(比如调用intern方法),否则jvm不会自动添加常量到常量池。
基本类型排除浮点型的包装类都会有常量池,Float和Double不会创建常量池,因为浮点型有精度,如果把某个范围内的浮点数放到常量池,因为精度不同就会放无数个
数值类型的常量池不可以手动添加常量,程序启动时常量池中的常量就已经确定了,比如整型常量池中的常量范围:-128~127,(Byte,Short,Integer,Long,Character,Boolean)这5种包装类默认创建了数值[-128,127]的相应类型的缓存数据,但是超出此范围仍然会去创建新的对象,并且不会加入到常量池,所以Integer a=5;和Integer b=5;a==b为true;Integer a=128;和Integer b=128;a==b为false;boolean:占1位(bit),1真0假
为什么范围为-128到127,因为这个范围内的数明显比其它范围的数更加常用
静态常量池和运行时常量池关系:
常量池是静态的,存在于.class文件中。运行时常量池是动态的,在类加载的时候,静态常量池的内容被复制到方法区的运行时常量池 ;并非预置入CLass文件中常量池的内容才能进入方法区运行时常量池,运行期间也可能将新的常量放入池中,这种特性被开发人员利用比较多的就是String类的intern()方法。
String的intern()方法会查找在常量池中是否存在一份equal相等的字符串,如果有则返回该字符串的引用,如果没有则添加自己的字符串进入常量池。
常量池的好处:
常量池是为了避免频繁的创建和销毁对象而影响系统性能。如果常量池中有相同内容的对象就不需要在创建了,直接引用常量池中的对象
字符串常量池:
字符串常量池独立于运行时常量池,jdk1.6在方法区,1.7及以后放在堆内存
而运行时常量池jdk1.7及以前在方法区(永久代),jdk1.8及以后也在方法区(元空间)
使字面量定义字符串和使用new关键字定义字符串:
String a=”abc”;String b=new String(“abc”);
采用字面量的方式创建的一个字符串时,JVM首先回去字符串常量池中去查找是否存在"abc"这个对象,如果不存在,则在字符串常量池中创建"abc"对象,然后将该对象的引用地址返回给字符串常量a,若存在,则不创建任何对象,直接将字符串常量池中"abc"对象的引用地址返回,赋值给字符串常量。
采用new的方式创建字符串时,JVM首先在字符串池中查找是否存在"abc"这个字符串对象,若有则不在字符串池中再去创建"abc"对象,而是直接在堆中创建"abc"字符串对象,然后将堆中该对象的引用地址返回给b,若字符串池中没有该对象,则会在字符串池中创建一个该对象,再去堆中创建一个"abc"对象,并将堆中该对象的引用地址返回给b。
堆
特点:是GC的主要区域,同样是线程共享的内存区域。运行时动态分配内存,存取速度较慢
作用:堆(heap)是存储java实例或者对象的地方
堆,一般分为三大部分:新生代、老年代、永久代
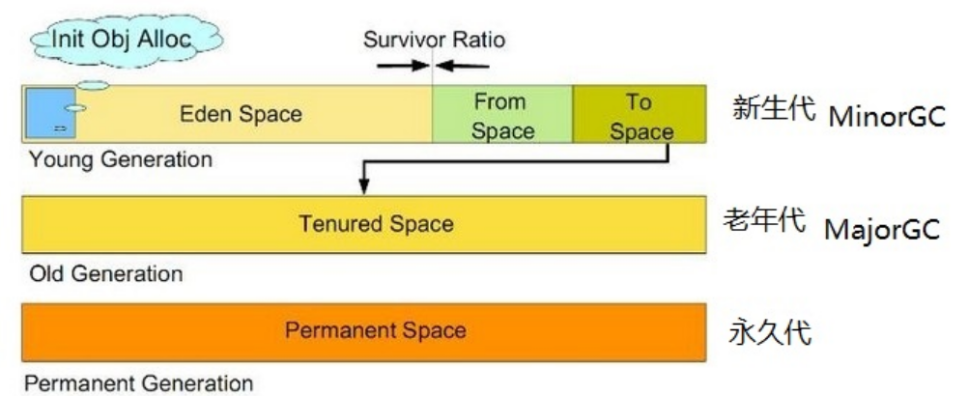
一:新生代:主要是用来存放新生的对象。一般占据堆的1/3空间。由于频繁创建对象,所以新生代会频繁触发MinorGC进行垃圾回收。
新生代又分为 Eden区、ServivorFrom、ServivorTo三个区。
默认比例:8:1:1可以通过-XX:SurvivorRatio参数来修改Eden区与Survivor区的比例。这个比例是jvm的设置,不是垃圾回收器的设置
Eden区:Java新对象的出生地(如果新创建的对象占用内存很大,则直接分配到老年代)。当Eden区内存不够的时候就会触发MinorGC,对新生代区进行一次垃圾回收。
ServivorTo:保留了一次MinorGC过程中的幸存者。
ServivorFrom:上一次GC的幸存者,作为这一次GC的被扫描者。
MinorGC的过程:MinorGC采用复制算法。首先,把Eden和ServivorFrom区域中存活的对象复制到ServicorTo区域(如果有对象的年龄以及达到了老年的标准,则复制到老年代区),同时把这些对象的年龄+1(如果ServicorTo不够位置了就放到老年区);然后,清空Eden和ServicorFrom中的对象;最后,ServicorTo和ServicorFrom互换,原ServicorTo成为下一次GC时的ServicorFrom区。
二:老年代:主要存放应用程序中生命周期长的内存对象。
老年代的对象比较稳定,所以MajorGC不会频繁执行。在进行MajorGC前一般都先进行了一次MinorGC,使得有新生代的对象晋身入老年代,导致空间不够用时才触发。当无法找到足够大的连续空间分配给新创建的较大对象时也会提前触发一次MajorGC进行垃圾回收腾出空间。
MajorGC采用标记—清除算法:首先扫描一次所有老年代,标记出存活的对象,然后回收没有标记的对象。MajorGC的耗时比较长,因为要扫描再回收。MajorGC会产生内存碎片,为了减少内存损耗,我们一般需要进行合并或者标记出来方便下次直接分配。
当老年代也满了装不下的时候,就会抛出OOM(Out of Memory)异常。
三:永久代
指内存的永久保存区域,主要存放Class和Meta(元数据)的信息,Class在被加载的时候被放入永久区域. 它和和存放实例的区域不同,GC不会在主程序运行期对永久区域进行清理。所以这也导致了永久代的区域会随着加载的Class的增多而胀满,最终抛出OOM异常。
在java7及以前,永久代就是方法区的实现,从java8开始永久代被去除,被元空间取代
元数据是指用来描述数据的数据,更通俗一点,就是描述代码间关系,或者代码与其他资源(例如数据库表)之间内在联系的数据。
元空间的本质和永久代类似,都是对JVM规范中方法区的实现。不过元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。因此,默认情况下,元空间的大小仅受本地内存限制。类的元数据放入 native memory, 运行时常量池和静态常量池被存放在元空间中,字符串池和类的静态变量放入java堆中. 这样可以加载多少类的元数据就不再由MaxPermSize控制, 而由系统的实际可用空间来控制.
采用元空间而不用永久代的几点原因:
1、为了解决永久代的OOM问题,元数据存在永久代中,容易出现性能问题和内存溢出。
2、类及方法的信息等比较难确定其大小,因此对于永久代的大小指定比较困难,太小容易出现永久代溢出,太大则容易导致老年代溢出(因为堆空间有限,此消彼长)。
3、永久代会为 GC 带来不必要的复杂度,并且回收效率偏低。
- Oracle 可能会将HotSpot 与 JRockit 合二为一。
堆内存大小可以通过-Xmx和-Xms来控制。
-Xms:设置初始分配大小,默认为物理内存的“1/64”
-Xmx:最大分配内存,默认为物理内存的“1/4”
如果不会调内存的话,可直接将-Xms 和 -Xmx 调成一样大小即可。
为什么分代
因为对象的生命周期不同,就需要有不同频率的垃圾回收,分代可以更合理高效地进行垃圾回收
内存调用过程
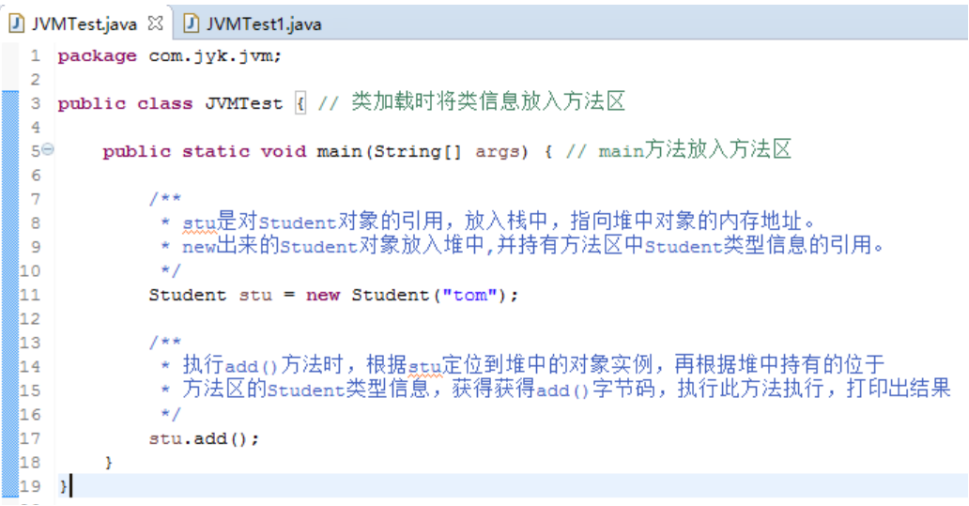
上面main方法中运行的程序过程如下:
(1)用户创建了一个Student对象,运行时JVM首先会去方法区寻找该对象的类型信息,没有则使用类加载器classloader将Student.class字节码文件加载至内存中的方法区,并将Student类的类型信息存放至方法区。
(2)接着JVM在堆中为新的Student实例分配内存空间,这个实例持有着指向方法区的Student类型信息的引用,引用指的是类型信息在方法区中的内存地址。
(3)在此运行的JVM进程中,会首先起一个线程跑该用户程序,而创建线程的同时也创建了一个虚拟机栈,虚拟机栈用来跟踪线程运行中的一系列方法调用的过程,每调用一个方法就会创建并往栈中压入一个栈帧,栈帧用来存储方法的参数,局部变量和运算过程的临时数据。上面程序中的stu是对Student的引用,就存放于栈中,并持有指向堆中Student实例的内存地址。
- JVM根据stu引用持有的堆中对象的内存地址,定位到堆中的Student实例,由于堆中实例持有指向方法区的Student类型信息的引用,从而获得add()方法的字节码信息,接着执行add()方法包含的指令。
总结
所有线程共享的内存数据区:方法区(元空间),堆。
线程私有区域:虚拟机栈,本地方法栈和程序计数器。
存放在栈中的内容:方法执行中的临时变量、方法中定义的局部变量(如果是基本数据类型:变量名+变量值,如果是引用数据类型:引用变量名(对象在堆中存))
存放于堆中的内容:对象的数据,字符串常量池,静态变量
存放于元空间中的内容:类的类型信息(完整类名,修饰符等),静态常量,构造函数,方法信息(方法名,返回类型,参数数量类型,修饰符等结构信息),运行时常量池
jvm调优
jvm调优思路
根据系统情况选择合适的垃圾收集器组合,看追求吞吐量还是系统响应速度
根据系统情况选择合适的jvm内存,合理调整新生代和老年代内存大小,避免频繁的垃圾回收
做好系统内存监控:及时发现问题
公司如何做系统监控
公司基于cat搭建的监控平台,可以监控机器的内存监控,线程监控,报错的代码跟踪,sql的监控,url监控,统计报表等
Jvm的监控工具
- jps_查看JVM进程ID(Java Virtual Machine Process Status Tool)
- jinfo_查看和调整JVM参数
- jstat_统计内存和GC信息(Java Virtual Machine statistics monitoring tool)
- jmap_查看堆内存使用情况和转储堆快照(Java Memory Map)
- jstack_生成线程快照
- 图形化监控工具
jconsole_图形化的分析工具
jvisualvm_强大的图形化分析工具,推荐
jhat:内存分析工具
第三方监控工具
jps
全称:JavaVirtual Machine Process Status Tool
作用:查看当前java进程
命令格式:jps [options ] [ hostid ]
options(对输出格式进行控制):
hostid(指定特定主机)格式:[protocol:][[//]hostname][:port][/servername]
--当未指定hostid时,默认查看本机jvm进程
当未指定options是展示进程号和主类名或包名如:
jps
583 Bootstrap
说明Bootstrap是tomcat启动的main方法所在的类,main()方法是Java应用程序的入口方法,所以Bootstrap类是tomcat程序的入口
-q只输出应用进程号
jps -q
583
-l输出应用程序进程号和主类完整package名称或jar完整名称
jps -l
24744 org.apache.catalina.startup.Bootstrap
-v进程号+主类或jar名+虚拟机启动时显示指定的jvm参数。
jps -v
24744 Bootstrap
-Djava.util.logging.config.file=/usr/local/tomcat_biz-collect-api/conf/logging.properties -Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager -Djava.endorsed.dirs=/usr/local/tomcat_biz-collect-api/endorsed -Dcatalina.base=/usr/local/tomcat_biz-collect-api
-Dcatalina.home=/usr/local/tomcat_biz-collect-api
-Djava.io.tmpdir=/usr/local/tomcat_biz-collect-api/temp
-m:输出main方法的参数
jps -m
24744 Bootstrap start
说明:在Bootstrap的main类可以看到如果接收到start就会启动
多个option一块使用:jps -lvm
jinfo
全名:Java Configuration Info
作用:查看和修改正在运行着的java应用程序的系统参数和命令行参数
语法:jinfo [option] <pid>
option:
no option 输出全部的参数和系统属性
-flag name 输出对应名称的参数
-flag [+|-]name 开启或者关闭对应名称的参数
-flag name=value 设定对应名称的参数
-flags 输出全部的参数
-sysprops 输出系统属性
pid:java应用程序进程id
jinfo 24744
Server compiler detected.
JVM version is 24.45-b08
Java System Properties:
java.runtime.name = Java(TM) SE Runtime Environment
java.vm.version = 24.45-b08
sun.boot.library.path = /usr/java/jdk1.7.0_45/jre/lib/amd64
shared.loader =
java.vendor.url = http://java.oracle.com/
java.vm.vendor = Oracle Corporation
path.separator = :
file.encoding.pkg = sun.io
java.vm.name = Java HotSpot(TM) 64-Bit Server VM
java.util.logging.config.file = /usr/local/tomcat_biz-collect-api/conf/logging.properties
tomcat.util.buf.StringCache.byte.enabled = true
sun.os.patch.level = unknown
sun.java.launcher = SUN_STANDARD
user.country = US
user.dir = /root
java.vm.specification.name = Java Virtual Machine Specification
java.runtime.version = 1.7.0_45-b18
org.apache.catalina.startup.TldConfig.jarsToSkip = tomcat7-websocket.jar
java.awt.graphicsenv = sun.awt.X11GraphicsEnvironment
os.arch = amd64
java.endorsed.dirs = /usr/local/tomcat_biz-collect-api/endorsed
line.separator =
java.io.tmpdir = /usr/local/tomcat_biz-collect-api/temp
java.vm.specification.vendor = Oracle Corporation
java.util.logging.manager = org.apache.juli.ClassLoaderLogManager
java.naming.factory.url.pkgs = org.apache.naming
os.name = Linux
sun.jnu.encoding = UTF-8
java.library.path = /usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib
tomcat.util.scan.DefaultJarScanner.jarsToSkip = bootstrap.jar,commons-daemon.jar,tomcat-juli.jar,annotations-api.jar,el-api.jar,jsp-api.jar,servlet-api.jar,websocket-api.jar,catalina.jar,catalina-ant.jar,catalina-ha.jar,catalina-tribes.jar,jasper.jar,jasper-el.jar,ecj-*.jar,tomcat-api.jar,tomcat-util.jar,tomcat-coyote.jar,tomcat-dbcp.jar,tomcat-jni.jar,tomcat-spdy.jar,tomcat-i18n-en.jar,tomcat-i18n-es.jar,tomcat-i18n-fr.jar,tomcat-i18n-ja.jar,tomcat-juli-adapters.jar,catalina-jmx-remote.jar,catalina-ws.jar,tomcat-jdbc.jar,tools.jar,commons-beanutils*.jar,commons-codec*.jar,commons-collections*.jar,commons-dbcp*.jar,commons-digester*.jar,commons-fileupload*.jar,commons-httpclient*.jar,commons-io*.jar,commons-lang*.jar,commons-logging*.jar,commons-math*.jar,commons-pool*.jar,jstl.jar,taglibs-standard-spec-*.jar,geronimo-spec-jaxrpc*.jar,wsdl4j*.jar,ant.jar,ant-junit*.jar,aspectj*.jar,jmx.jar,h2*.jar,hibernate*.jar,httpclient*.jar,jmx-tools.jar,jta*.jar,log4j.jar,log4j-1*.jar,mail*.jar,slf4j*.jar,xercesImpl.jar,xmlParserAPIs.jar,xml-apis.jar,junit.jar,junit-*.jar,hamcrest*.jar,org.hamcrest*.jar,ant-launcher.jar,cobertura-*.jar,asm-*.jar,dom4j-*.jar,icu4j-*.jar,jaxen-*.jar,jdom-*.jar,jetty-*.jar,oro-*.jar,servlet-api-*.jar,tagsoup-*.jar,xmlParserAPIs-*.jar,xom-*.jar
sun.nio.ch.bugLevel =
java.class.version = 51.0
java.specification.name = Java Platform API Specification
sun.management.compiler = HotSpot 64-Bit Tiered Compilers
os.version = 2.6.32-431.el6.x86_64
user.home = /home/tomcat
org.apache.catalina.startup.ContextConfig.jarsToSkip =
user.timezone = Asia/Shanghai
catalina.useNaming = true
java.awt.printerjob = sun.print.PSPrinterJob
file.encoding = UTF-8
java.specification.version = 1.7
catalina.home = /usr/local/tomcat_biz-collect-api
user.name = tomcat
java.class.path = /usr/local/tomcat_biz-collect-api/bin/bootstrap.jar:/usr/local/tomcat_biz-collect-api/bin/tomcat-juli.jar
java.naming.factory.initial = org.apache.naming.java.javaURLContextFactory
package.definition = sun.,java.,org.apache.catalina.,org.apache.coyote.,org.apache.jasper.,org.apache.naming.,org.apache.tomcat.
java.vm.specification.version = 1.7
sun.arch.data.model = 64
sun.java.command = org.apache.catalina.startup.Bootstrap start
java.home = /usr/java/jdk1.7.0_45/jre
user.language = en
java.specification.vendor = Oracle Corporation
awt.toolkit = sun.awt.X11.XToolkit
java.vm.info = mixed mode
java.version = 1.7.0_45
java.ext.dirs = /usr/java/jdk1.7.0_45/jre/lib/ext:/usr/java/packages/lib/ext
sun.boot.class.path = /usr/java/jdk1.7.0_45/jre/lib/resources.jar:/usr/java/jdk1.7.0_45/jre/lib/rt.jar:/usr/java/jdk1.7.0_45/jre/lib/sunrsasign.jar:/usr/java/jdk1.7.0_45/jre/lib/jsse.jar:/usr/java/jdk1.7.0_45/jre/lib/jce.jar:/usr/java/jdk1.7.0_45/jre/lib/charsets.jar:/usr/java/jdk1.7.0_45/jre/lib/jfr.jar:/usr/java/jdk1.7.0_45/jre/classes
server.loader =
java.vendor = Oracle Corporation
catalina.base = /usr/local/tomcat_biz-collect-api
dubbo.properties.file = conf/dubbo.properties
file.separator = /
java.vendor.url.bug = http://bugreport.sun.com/bugreport/
common.loader = ${catalina.base}/lib,${catalina.base}/lib/*.jar,${catalina.home}/lib,${catalina.home}/lib/*.jar
sun.io.unicode.encoding = UnicodeLittle
sun.cpu.endian = little
package.access = sun.,org.apache.catalina.,org.apache.coyote.,org.apache.jasper.,org.apache.naming.resources.,org.apache.tomcat.
sun.cpu.isalist =
VM Flags:
-Djava.util.logging.config.file=/usr/local/tomcat_biz-collect-api/conf/logging.properties -Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager -Djava.endorsed.dirs=/usr/local/tomcat_biz-collect-api/endorsed -Dcatalina.base=/usr/local/tomcat_biz-collect-api
-Dcatalina.home=/usr/local/tomcat_biz-collect-api
-Djava.io.tmpdir=/usr/local/tomcat_biz-collect-api/temp
结果说明:
Java System Properties:java系统参数
重点内容:
java.runtime.version = 1.7.0_45-b18 --jre版本
java.home = /usr/java/jdk1.7.0_45/jre --jre目录
java.version = 1.7.0_45 --jdk版本
user.name = tomcat --用户名称
VM Flags:jvm参数
只打印启动时指定的,不是启动时指定的可以通过jinfo -flag 参数名 pid来获取
jinfo -flags pid
只打印jvm命令行参数
jinfo -sysprops pid
只打印java系统属性
jinfo -flag PrintGC 24744
-XX:-PrintGC
查看GC日志是否开启,这里是没有开启
如果返回是:
Unable to open socket file: target process not responding or HotSpot VM not loaded
需要切换到与tomcat应用相同的用户就可以
修改参数:
如果命令执行提示下面,就表示该参数不支持动态修改
com.sun.tools.attach.AttachOperationFailedException: flag 'XX:+PrintG' cannot be changed
如果要开启日志或详细日志
jinfo -flag +PrintGC 24744,jinfo -flag +PrintGCDetails 24744
jinfo -flag MaxHeapSize 24744
-XX:MaxHeapSize=1004535808
查看虚拟机最大内存设置,打印的单位是字节Byte,Byte转kb再转mb得到958m
其他常用的: InitialHeapSize:堆内存初始大小
jstat
全称:Java Virtual Machine statistics monitoring tool
作用:对堆内存及垃圾回收进行监控
语法: jstat [option] pid [间隔时间 ] [查询次数]
jstat -help|-options
jstat -<option> [-t] [-h<lines>] <vmid> [<interval> [<count>]]
语法说明:
-t:显示系统时间
-h:指定多少行以后输入一次表头
vmid:Virtual Machine ID也就是进程id
interval:时间间隔,单位是毫秒
count:指定输出多少次记录,缺省则会一直打印
option 可以从下面参数中选择
-class 显示ClassLoad的相关信息;显示加载和卸载class的数量,及所占空间等信息。
-compiler 显示JIT编译的相关信息;
-gc 显示gc次数时间等信息;
-gccapacity 显示各个代的容量以及使用情况;
-gcmetacapacity 显示元空间的大小
-gcnew 显示新生代信息;
-gcnewcapacity 显示新生代大小和使用情况;
-gcold 显示老年代和永久代的信息;
-gcoldcapacity 显示老年代的大小;
-gcutil 显示垃圾收集统计信息;
-gccause 显示垃圾回收的相关信息(通-gcutil),同时显示最后一次或当前正在发生的垃圾回收的诱因;
-printcompilation 输出JIT编译的方法信息;
jstat -gc -t 12328 1000 5
|
Timestamp S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT 3904.7 512.0 512.0 0.0 288.0 32768.0 30803.0 91648.0 89135.1 42112.0 41092.8 4992.0 4802.1 4653 7.900 2 0.179 8.078 3905.7 512.0 512.0 0.0 288.0 32768.0 30805.1 91648.0 89135.1 42112.0 41092.8 4992.0 4802.1 4653 7.900 2 0.179 8.078 3906.7 512.0 512.0 0.0 288.0 32768.0 30805.1 91648.0 89135.1 42112.0 41092.8 4992.0 4802.1 4653 7.900 2 0.179 8.078 3907.7 512.0 512.0 0.0 288.0 32768.0 30807.1 91648.0 89135.1 42112.0 41092.8 4992.0 4802.1 4653 7.900 2 0.179 8.078 3908.7 512.0 512.0 0.0 288.0 32768.0 30807.1 91648.0 89135.1 42112.0 41092.8 4992.0 4802.1 4653 7.900 2 0.179 8.078 |
S0C:年轻代中第一个survivor(幸存区)的容量 (字节)
S1C:年轻代中第二个survivor(幸存区)的容量 (字节)
S0U :年轻代中第一个survivor(幸存区)目前已使用空间 (字节)
S1U :年轻代中第二个survivor(幸存区)目前已使用空间 (字节)
EC :年轻代中Eden(伊甸园)的容量 (字节)
EU :年轻代中Eden(伊甸园)目前已使用空间 (字节)
OC :Old代的容量 (字节)
OU :Old代目前已使用空间 (字节)
MC:metaspace(元空间)的容量 (字节)
MU:metaspace(元空间)目前已使用空间 (字节)
YGC :从应用程序启动到采样时年轻代中gc次数
YGCT :从应用程序启动到采样时年轻代中gc所用时间(s)
FGC :从应用程序启动到采样时old代(全gc)gc次数
FGCT :从应用程序启动到采样时old代(全gc)gc所用时间(s)
GCT:从应用程序启动到采样时gc用的总时间(s)
jstat -gcutil -t 12328 1000 2
|
Timestamp S0 S1 E O M CCS YGC YGCT FGC FGCT GCT 4184.4 56.25 0.00 38.00 41.16 97.44 95.97 4946 8.387 3 0.328 8.715 4185.3 0.00 62.50 72.00 41.16 97.44 95.97 4947 8.389 3 0.328 8.718 |
0 :年轻代中第一个survivor(幸存区)已使用的占当前容量百分比
S1 :年轻代中第二个survivor(幸存区)已使用的占当前容量百分比
E :年轻代中Eden(伊甸园)已使用的占当前容量百分比
O :old代已使用的占当前容量百分比
P :perm代已使用的占当前容量百分比
YGC :从应用程序启动到采样时年轻代中gc次数
YGCT :从应用程序启动到采样时年轻代中gc所用时间(s)
FGC :从应用程序启动到采样时old代(全gc)gc次数
FGCT :从应用程序启动到采样时old代(全gc)gc所用时间(s)
GCT:从应用程序启动到采样时gc用的总时间(s)
jmap
全称:Java Memory Map
作用:
运行java程序的内存分配的详细情况。例如实例个数,大小等
可以获得运行中的jvm的堆的快照,从而可以离线分析堆,以检查内存泄漏,检查一些严重影响性能的大对象的创建,检查系统中什么对象最多,各种对象所占内存的大小等等。
说明:堆Dump是反应Java堆使用情况的内存镜像,其中主要包括系统信息、虚拟机属性、完整的线程Dump、所有类和对象的状态等。 一般,在内存不足、GC异常等情况下,我们就会怀疑有内存泄露。这个时候我们就可以制作堆Dump来查看具体情况。分析原因。
语法:
jmap [ option ] pid
jmap [ option ] executable core
jmap [ option ] [server-id@]remote-hostname-or-IP
executable产生核心dump的Java可执行文件。core: 需要打印配置信息的核心文件。
option说明:
no option: 查看进程的内存映像信息
heap: 显示Java堆详细信息
histo[:live]: 显示堆中对象的统计信息
clstats:打印类加载器信息
finalizerinfo: 显示在F-Queue队列等待Finalizer线程执行finalizer方法的对象
dump:<dump-options>:生成堆转储快照
F: 当-dump没有响应时,使用-dump或者-histo参数. 在这个模式下,live子参数无效.
help:打印帮助信息
J<flag>:指定传递给运行jmap的JVM的参数
使用:
jmap -heap 18230
显示Java堆详细信息
|
Heap Configuration: MinHeapFreeRatio = 0 //JVM堆缩减空间比率,低于则进行内存缩减 MaxHeapFreeRatio = 100 //JVM堆扩大内存空闲比例,高于则进行内存扩张 MaxHeapSize = 994050048 (948.0MB) //堆最大内 NewSize = 20971520 (20.0MB) //新生代初始化内存大小 MaxNewSize = 331350016 (316.0MB) //新生代最大内存大小 OldSize = 41943040 (40.0MB) //老年代内存大小 NewRatio = 2 //新生代和老年代占堆内存比率 SurvivorRatio = 8 //s区和Eden区占新生代内存比率 MetaspaceSize = 21807104 (20.796875MB) //元数据初始化空间大小 CompressedClassSpaceSize = 1073741824 (1024.0MB) //类指针压缩空间大小 MaxMetaspaceSize = 17592186044415 MB //元数据最大内存代销 G1HeapRegionSize = 0 (0.0MB) //G1收集器Region单元大小 Heap Usage: PS Young Generation Eden Space: capacity = 303038464 (289.0MB) //Eden区总容量 used = 22801000 (21.744728088378906MB) //Eden区已使用容量 free = 280237464 (267.2552719116211MB) //Eden区剩余容量 7.524127366221075% used //Eden区使用比例 From Space: //From区(也就是Survivor中的S1区) capacity = 13107200 (12.5MB) //S1区总容量大小 used = 5364536 (5.116020202636719MB) //S1区已使用大小 free = 7742664 (7.383979797363281MB) //S1区剩余大小 40.92816162109375% used //S1使用比例 To Space: //To区 (也就是Survivor中的S2区) capacity = 13631488 (13.0MB) //S2区总容量大小 used = 0 (0.0MB) //S2区已使用大小 free = 13631488 (13.0MB) //S2区剩余大小 0.0% used //S2区使用比率 PS Old Generation capacity = 110624768 (105.5MB) //老年代总容量大小 used = 49431224 (47.14128875732422MB) //老年代已使用大小 free = 61193544 (58.35871124267578MB) //老年代剩余大小 44.68368602589973% used //老年代使用功能比例 |
jmap -histo 18230 | sort -n -r -k 3 | head -10 //统计合计容量前十的类有哪些
第二列为数量,第三列为大小单位为byte字节
B 代表 byte
C 代表 char
D 代表 double
F 代表 float
I 代表 int
J 代表 long
Z 代表 boolean
前边有 [ 代表数组, [I 就相当于 int[]
对象用 [L+ 类名表示
jmap -dump:format=b,file=d:\dump1215.bin 8804
导出快照文件到d:\dump1215.bin,可使用VisualVM来打开文件对里面的内容进行分析。eclipse安装mat插件也可以进行图形化分析
Jstack
全称:
作用:监视JVM线程堆栈情况,可以了解到系统如何崩溃和在程序何处发生问题,有死锁也可以看到日志
语法:
jstack [ option ] pid
jstack [ option ] executable core
jstack [ option ] [server-id@]remote-hostname-or-IP
option说明:
-l长列表. 打印关于锁的附加信息
-F当’jstack [-l] pid’没有相应的时候强制打印栈信息
-m打印java和native c/c++框架的所有栈信息
常用命令:
jstack -l 18230 >jstack.txt
打印线程堆栈到文件
线程状态:
|
waiting on condition //等待条件 deadlock //死锁 waiting on monitor entry //等待获取监视器 Blocked //阻塞 Runnable //运行 Suspended //暂停 TIMED_WAITING //休眠(有超时限制) WAITING //休眠 Parked //停止 |
实例:
使用jstack找出耗cup代码原因
总结:
利用ps配合grep命令找到应用的进程pid
利用top命令找到该进程中最消耗cpu的线程
利用jstack输出这个线程的堆栈信息就定位到问题了
第一步先找出Java进程ID,服务器上的Java应用名称为mrf-center
root@ubuntu:/# ps -ef | grep mrf-center | grep -v grep
root 21711 1 1 14:47 pts/3 00:02:10 java -jar mrf-center.jar
得到进程ID为21711,第二步找出该进程内最耗费CPU的线程,可以使用
1)ps -Lfp pid
2)ps -mp pid -o THREAD, tid, time
3)top -Hp pid
用第三个,输出如下:
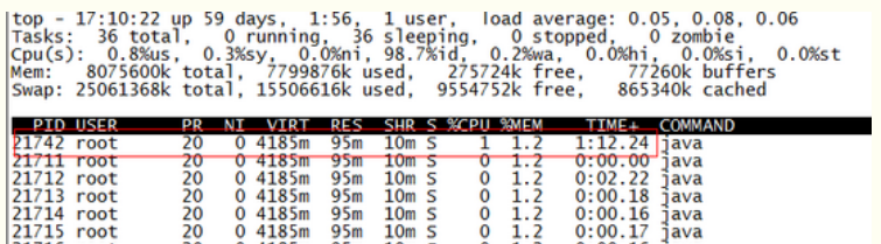
TIME列就是各个Java线程耗费的CPU时间,CPU时间最长的是线程ID为21742的线程,用
printf "%x\n" 21742
得到21742的十六进制值为54ee,下面会用到。
OK,下一步终于轮到jstack上场了,它用来输出进程21711的堆栈信息,然后根据线程ID的十六进制值grep,如下:
root@ubuntu:/# jstack 21711 | grep 54ee
"PollIntervalRetrySchedulerThread" prio=10 tid=0x00007f950043e000 nid=0x54ee in Object.wait()
可以看到CPU消耗在PollIntervalRetrySchedulerThread这个类的Object.wait(),我找了下我的代码,定位到代码
jconsole
全称:Java Monitoring and Management Console
作用:监控本地或远程jvm内存、线程、加载类数量,cup占用率等图形化展示
使用方式:
可以从命令行(直接输入jconsole)或在 GUI shell (jdk\bin\jconsole.exe)中运行。
优点:占用系统资源少
实例:
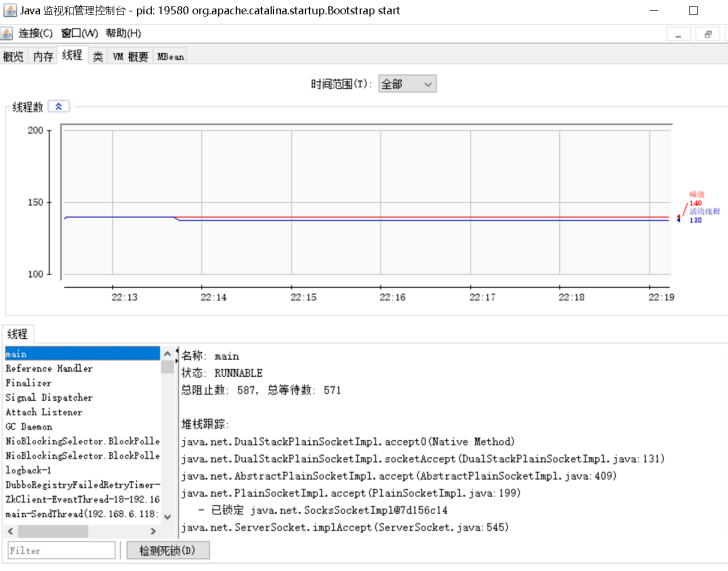
命令行输入jconsole,可以看到,双击tomcat的进程,可以查看监控情况
可以查看使用详情,可以显示每个内存分类总大小和使用大小,可以手动gc
线程可以进行指定线程进行堆栈跟踪,还可以检测死锁
类的就是显示装载和写在的类数量
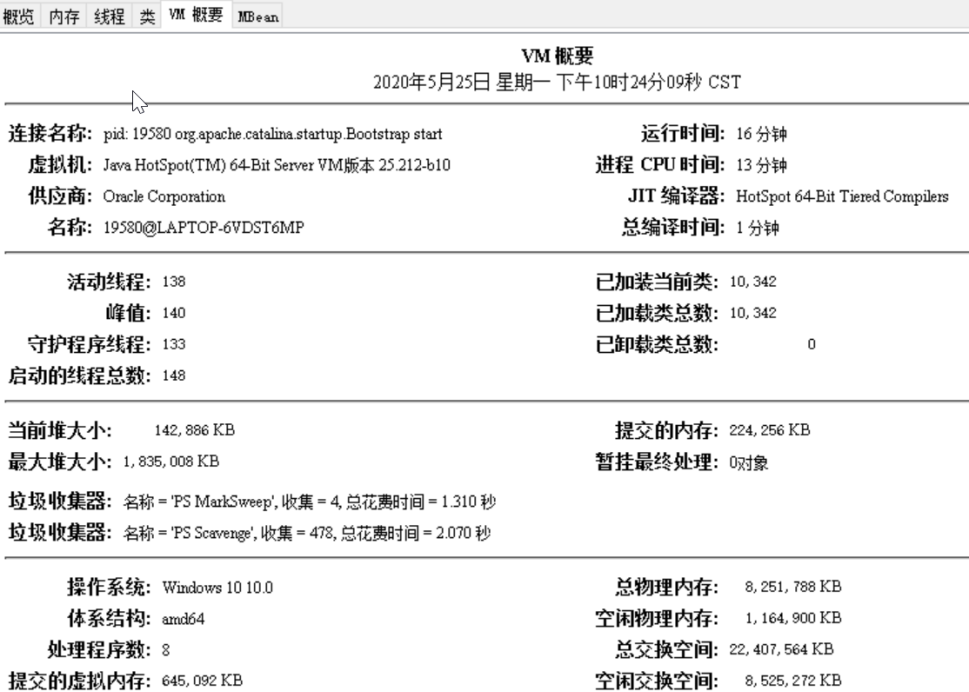
vm概要,展示很多常用信息包括使用的牢记收集器及jvm启动参数
mbean 代表一个被管理的资源实例,MBean就是一个Java Object, MBean可以用来干嘛?就是可以有一套JDK级别的对外的服务接口。比如,你写了一个JVM允许状态辅助查询的Bean,你希望别人下载一个Jconsole就可以看到你写的杰作。那你就可以考虑用MBean规范来实现。
远程连接的话需要要停止正在运行的服务
在远程机的tomcat的catalina.sh中加入配置:
JAVA_OPTS="$JAVA_OPTS -Djava.rmi.server.hostname=192.168.202.121 -Dcom.sun.management.jmxremote"
JAVA_OPTS="$JAVA_OPTS -Dcom.sun.management.jmxremote.port=12345"
JAVA_OPTS="$JAVA_OPTS -Dcom.sun.management.jmxremote.authenticate=true"
JAVA_OPTS="$JAVA_OPTS -Dcom.sun.management.jmxremote.ssl=false"
JAVA_OPTS="$JAVA_OPTS -Dcom.sun.management.jmxremote.pwd.file=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.101-3.b13.el7_2.x86_64/jre/lib/management/jmxremote.password"
2.配置权限文件
[root@localhost bin]# cd /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.101-3.b13.el7_2.x86_64/jre/lib/management/
[root@localhost management]# cp jmxremote.password.template jmxremote.password
[root@localhost management]# vi jmxremote.password
monitorRole QED
controlRole chenqimiao
3.配置权限文件为600
[root@localhost management]# chmod 600 jmxremote.password jmxremote.access
记得开放指定端口的防火墙
VisualVM也需要同样的配置
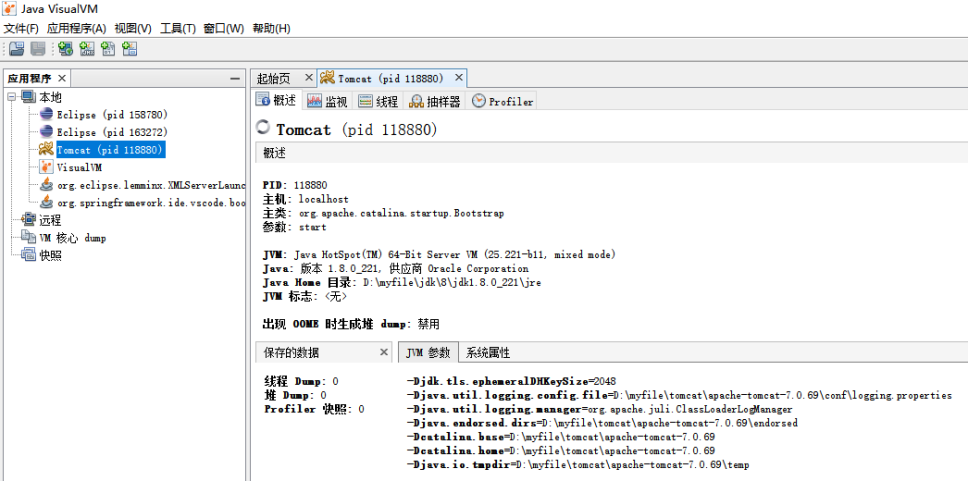
jvisualvm
常用的jvm命令行参数
在一个java应用启动时,我们可以配置其jvm的启动参数,如:
java -jar -Xms4096M -Xmx4096M -Xmn1024M -Xss256K hello.jar [args参数]
-X设置
堆大小设置:
-Xmx3550m:设置JVM最大可用内存为3550M。
-Xms3550m:设置JVM初始内存为3550m。可以与-Xmx相同,避免每次垃圾回收完JVM重新分配内存。
-Xss128k:设置每个线程的堆栈大小。(JDK5.0以后每个线程堆栈大小为1M)
-Xmn1024m:设置年轻代大小为1024m。等效于同时配置下面两个。
-XX:NewSize=1024m:设置年轻代初始值为1024M。
-XX:MaxNewSize=1024m:设置年轻代最大值为1024M。
-XX:PermSize=256m:设置持久代初始值为256M。
-XX:MaxPermSize=256m:设置持久代最大值为256M。
JVM8.0已经没有持久代,若设置则会警告
垃圾回收参数设置
串行收集器
-XX:+UseSerialGC:设置串行收集器。
并行收集器(吞吐量优先)
-XX:+UseParallelGC:设置年轻代为并行收集器。(此时年老代仍然为串行)
-XX:+UseParallelOldGC:配置年老代为并行收集。
-XX:ParallelGCThreads=20:配置并行收集器的线程数。
-XX:MaxGCPauseMillis=100:设置每次年轻代垃圾回收的最长时间(单位毫秒)。如果无法满足此时间,JVM会自动调整年轻代大小,以满足此时间。
-XX:+UseAdaptiveSizePolicy:设置此选项后,并行收集器会自动调整年轻代Eden区大小和Survivor区大小的比例,以达成目标系统规定的最低响应时间或者收集频率等指标。此参数建议在使用并行收集器时,一直打开。
并发收集器(响应时间优先)
-XX:+UseConcMarkSweepGC:即CMS收集,设置年老代为并发收集。
-XX:+UseParNewGC:设置年轻代为并发收集。JDK5.0以上JVM会自行设置,无需再设。
-XX:CMSFullGCsBeforeCompaction=0:每次Full GC后立刻开始压缩和整理内存。
-XX:+UseCMSCompactAtFullCollection:打开内存空间的压缩和整理,在Full GC后执行。
-XX:+CMSIncrementalMode:设置为增量收集模式。一般适用于单CPU情况。
-XX:CMSInitiatingOccupancyFraction=70:表示年老代内存空间使用到70%时就开始执行CMS收集,以确保年老代有足够的空间接纳来自年轻代的对象,避免Full GC的发生。
其它垃圾回收参数
-XX:+ScavengeBeforeFullGC:年轻代GC优于Full GC执行。
-XX:-DisableExplicitGC:不响应 System.gc() 代码。
-XX:+UseThreadPriorities:启用本地线程优先级API。即使 java.lang.Thread.setPriority() 生效,不启用则无效。
-XX:SoftRefLRUPolicyMSPerMB=0:软引用对象在最后一次被访问后能存活0毫秒(JVM默认为1000毫秒)。
-XX:TargetSurvivorRatio=90:允许90%的Survivor区被占用(JVM默认为50%)。提高对于Survivor区的使用率。
辅助信息参数设置
-XX:-CITime:打印消耗在JIT编译的时间。
-XX:ErrorFile=./hs_err_pid.log:保存错误日志或数据到指定文件中。
-XX:HeapDumpPath=./java_pid.hprof:指定Dump堆内存时的路径。
-XX:-HeapDumpOnOutOfMemoryError:当首次遭遇内存溢出时Dump出此时的堆内存。
-XX:OnError=";":出现致命ERROR后运行自定义命令。
-XX:OnOutOfMemoryError=";":当首次遭遇内存溢出时执行自定义命令。
-XX:-PrintClassHistogram:按下 Ctrl+Break 后打印堆内存中类实例的柱状信息,同JDK的 jmap -histo 命令。
-XX:-PrintConcurrentLocks:按下 Ctrl+Break 后打印线程栈中并发锁的相关信息,同JDK的 jstack -l 命令。
-XX:-PrintCompilation:当一个方法被编译时打印相关信息。
-XX:-PrintGC:每次GC时打印相关信息。
-XX:-PrintGCDetails:每次GC时打印详细信息。
-XX:-PrintGCTimeStamps:打印每次GC的时间戳。
-XX:-TraceClassLoading:跟踪类的加载信息。
-XX:-TraceClassLoadingPreorder:跟踪被引用到的所有类的加载信息。
-XX:-TraceClassResolution:跟踪常量池。
-XX:-TraceClassUnloading:跟踪类的卸载信息。
-D设置
定义运行期变量(或系统属性),功能与环境变量相同
在程序中可以通过System.getProperty("参数名获取")如
指定:-Dfuck.abc="1234"
获取:System.getProperty("fuck.abc")
jvm调优思路
使用各种JVM监控工具(如JVisualVM、JConsole、JMC等)来实时查看JVM的性能指标,包括内存使用、CPU占用、线程情况等。
调整堆内存大小:根据应用的内存使用情况和GC日志分析结果,调整堆内存的大小。一般建议将初始堆大小和最大堆大小设置为相等。这样可以垃圾回收后对内存的重新分配带来的性能损耗。java -jar -Xms4096M -Xmx4096M -Xmn1024M -Xss256K hello.jar [args参数]
选择合适的垃圾收集器:根据应用的特性和性能需求来选择合适的垃圾收集器。
调整垃圾收集器参数:在选择了合适的垃圾收集器后,还需要调整其相关参数以优化GC性能。例如,可以调整新生代与老年代的内存大小、调整GC触发的阈值等。
代码优化:除了JVM层面的优化外,还可以对应用代码进行优化。例如,减少对象的创建和销毁、避免不必要的内存分配、优化循环和算法等,都可以减少内存占用和提高性能。
持续监控和调优:性能调优是一个持续的过程。在调优完成后,需要持续监控系统的性能表现,并根据实际情况进行进一步的调整和优化。
jvm调优常用的命令和参数
命令
jps命令查看系统正在运行的java进程获取到进程的PID
jps -v 可以看到JVM启动时,显式指定的参数信息
使用jinfo 命令可以查看指定pid进程的java系统参数(java版本)和jvm参数(堆内存大小,垃圾回收器等)
jinfo -flag name 输出对应名称的参数
jstak 命令可以查看指定进程id的堆栈信息,可以看到线程的状态信息deadlock就是死锁状态
使用jstat命令可以对指定pid的堆内存及垃圾回收进行监控
使用jmp可以获取指定pid的java程序的内存分配的详细情况。例如实例个数,大小等,可以获得运行中的jvm的堆的快照,从而可以离线分析堆,以检查内存泄漏,检查一些严重影响性能的大对象的创建,检查系统中什么对象最多,各种对象所占内存的大小等等。
参数:java应用启动时可以指定对jvm调优的一些参数
-Xmx3550m:设置JVM最大可用堆内存为3550M。
-Xms3550m:设置JVM初始堆内存为3550m。可以与-Xmx相同,避免每次垃圾回收完JVM重新分配内存。
-Xss128k:设置每个线程的堆栈大小。(JDK5.0以后每个线程堆栈大小为1M)
-Xmn1024m:设置年轻代大小为1024m。等效于同时配置下面两个。
-XX:+UseG1GC:设置使用的垃圾回收器
如何对jvm优化
jvm调优工具:
Jconsole,jProfile,VisualVM
Jconsole : jdk自带,功能简单,但是可以在系统有一定负荷的情况下使用。对垃圾回收算法有很详细的跟踪。
JProfiler:商业软件,需要付费。功能强大。
VisualVM:JDK自带,功能强大,与JProfiler类似。推荐。
主要就是监控cup,内存,垃圾回收情况
线程信息监控:系统线程数量。
线程状态监控:各个线程都处在什么样的状态下
根据情况调节服务器jvm
jvm内存优化:有富余物理内存的情况,加大tomcat使用的jvm的内存;(bin目录下Windows系统catalina.bat,Unix系统catalina.sh中JAVA_OPTS中设置)
Tomcat并发优化:调整连接线程数(在Tomcat配置文件server.xml中配置)
Jvm参数说明
堆设置:
xms:ms看做的memory size的缩写
xmx:mx看做memory max
Xss:ss就是stack size的缩写,所以是用来代表线程栈的大小
-Xms256M:初始堆大小256M,默认为物理内存的1/64
-Xmx1024M:最大堆大小1024M,默认为物理内存的1/4
-Xss128k:设置JAVA线程堆栈大小为128k
xms和xmx设置成一样
可以避免jvm运行过程中再向系统申请内存,给系统造成压力
避免堆内存改变引起堆内存划分的重新调整,避免每次垃圾回收完成后JVM重新分配内存。
java垃圾回收机制
垃圾收集是将分配给对象但不再使用的内存回收或释放的过程。如果一个对象没有指向它的引用或者其赋值为null,则此对象适合进行垃圾回收。
为什么要进行垃圾回收
释放没有没必要占用的资源,可以有效的防止内存泄露,合理的使用内存;
什么是内存泄露
指一个不再被程序使用的对象或变量一直占据在内存中。
内存泄漏会报错吗:
没有内存泄漏的报错,但内存泄漏消耗系统内存资源,严重了会导致内存溢出报错
内存泄漏的例子:
- 集合类对象添加的对象在集合类对象没有被垃圾回收前不能被回收
- 变量不合理的作用域。一般而言,一个变量的定义的作用范围大于其使用范围,很有可能会造成内存泄漏。
- 各种连接,如数据库连接、网络连接和IO连接等。当不再使用时,需要调用close方法垃圾回收器才会回收对应的对象。
- 内部类持有外部类,如果一个外部类的实例对象的方法返回了一个内部类的实例对象,这个内部类对象被长期引用了,即使那个外部类实例对象不再被使用,但由于内部类持有外部类的实例对象,这个外部类对象将不会被垃圾回收,这也会造成内存泄露。
防止内存泄露:
- 为了防止内存泄露要把不用的对象及时赋值为null
- 尽量减小对象的作用域
- 防止不再被使用的对象被长生命周期对象持有。
- 对数据库连接,网络连接(socket)和io连接等要及时的关闭,否则是不会自动被GC回收的。其实原因依然是长生命周期对象持有短生命周期对象的引用。
发生内存泄露了怎么办:
用专业的工具分析那个类的对象泄露,看看有哪些其他的类与泄漏的类的对象相关联,看看它们是如何互相关联的,找出原因进行处理
工具如:jmap,jProfiler等
什么是内存溢出
内存溢出是指应用系统中存在无法回收的内存或使用的内存过多,最终使得程序运行要用到的内存大于虚拟机能提供的最大内存。
内存溢出和内存泄露都会导致这些报错:
java.lang.OutOfMemoryError: Java heap space 堆内存满了,新对象没地方了
处理方法就是,分析对象引用情况,找到内存泄露的点进行处理
java.lang.OutOfMemoryError: PermGen space
永久代被占满。无法为新的class分配存储空间而引发的异常。这个异常以前是没有的,但是在Java反射大量使用的今天这个异常比较常见了。主要原因就是大量动态反射生成的类不断被加载,最终导致Perm区被占满。
如何解决:设置 -XX:MaxPermSize=16m,或者换用JDK
java中生成类的地方:
- 动态代理
- 反射(需要规避反射开销)
- 有些模版引擎为了提升渲染速度,也会选择做字节码生成
发生内存溢出如何分析原因
启动时设置发生内存溢出自动生成堆转储快照(.hprof文件),当发生内存溢出时使用分析工具进行分析找出高内存消耗点,如:IBM heapAnalyzer、Memory Analyzer Tools (mat)
、jvisualvm(jdk自带)
说明: 启动参数 -XX:+HeapDumpOnOutOfMemoryError
hprof文件:内存镜像文件,记录了内存堆详细的使用信息。
java中会存在内存泄漏吗,请简单描述。
所谓内存泄露就是指一个不再被程序使用的对象或变量一直占据在内存中。 java中有垃圾回收机制,它可以保证一对象不再被引用的时候,对象将自动被垃圾回收器从内存中清除掉。
由于Java 使用有向图的方式进行垃圾回收管理,可以消除引用循环的问题,例如有两个对象,相互引用,只要它们和根进程不可达的,那么GC也是可以回收它们的。
java中的内存泄露的情况:长生命周期的对象持有短生命周期对象的引用就很可能发生内存泄露
垃圾回收机制的原理
垃圾回收器通常是作为一个守护线程运行,根据垃圾回收算法对内存堆中已经没有被引用或赋值为null的对象进行清除和回收
判断对象是否存活的方法:
引用计数法:
在堆中存储对象时,会在对象的对象头处维护一个计数器,用来存储该对象被引用的个数,如果一个对象增加了一个引用与之相连,则将+1。如果一个引用关系失效则-1。如果一个对象的被引用数量变为0,则说明该对象已经被废弃,可以被回收。
问题:循环引用问题:对象A引用了对象B,对象B又引用对象A,那么A和B即使不再使用也无法被回收。
可达性分析算法:
java中没有采用引用计数法,采用的是可达性分析算法
从堆的根节点开始遍历对象图。这些根节点可能包括程序计数器、虚拟机栈、本地方法栈和方法区中的类静态属性等。在遍历对象图的过程中,垃圾回收器会标记所有可以到达的对象为存活对象。未被标记的对象则被认为是垃圾对象。
GC Roots(根)对象
一般来说,如下情况的对象可以作为GC Roots:
- 虚拟机栈(栈桢中的本地变量表)中的引用的对象
- 本地方法栈中引用的对象
- 方法区中的类引用类型静态变量指向的对象
- 方法区中的常量引用的对象
- Java虚拟机内部的引用,如基本数据类型对应的class对象,一些常驻的异常对象等,还有类加载器。
- 所有被同步锁持有的对象等
Minor GC和MajorGC和Full GC
Minor:轻微的小调的,Major:严重的大调的
Minor GC、Young GC、年轻代垃圾回收都是同一个意思;Minor GC、老年代垃圾回收一个意思;fullGC是整个堆进行垃圾回收(不进行元空间的垃圾回收);
对于Serial Old、PS Old等垃圾回收器来说是没有严格区分老年代的垃圾回收(Major GC)和整堆的垃圾回收(Full GC)的,即Major GC就是对应的一次Full GC。而CMS垃圾回收则不同,其针对老年代的垃圾回收就只回收老年代(Major GC)
新生代垃圾回收触发机制:
- Eden区内存不足
新生代垃圾回收特点:发生频繁,回收速度快
新生代垃圾回收过程:MinorGC采用复制算法。首先,把Eden和ServivorFrom区域中存活的对象复制到ServicorTo区域(如果有对象的年龄以及达到了老年的标准,则赋值到老年代区),同时把这些对象的年龄+1(如果ServicorTo不够位置了就放到老年区);然后,清空Eden和ServicorFrom中的对象;最后,ServicorTo和ServicorFrom互换,原ServicorTo成为下一次GC时的ServicorFrom区。
老年代垃圾回收的触发机制:
- 老年代的空间使用率达到某个阈值,具体阀值设置跟垃圾回收器有关,如70%
MajorGC是当老年代内存不够时触发,通常是Minor GC导致老年代内存不够然后触发
MajorGC采用标记—清除算法:首先扫描一次所有老年代,标记出存活的对象,然后回收没有标记的对象。MajorGC的耗时比较长,因为要扫描再回收。MajorGC会产生内存碎片,为了减少内存损耗,我们一般需要进行合并或者标记出来方便下次直接分配。
Full GC
System.gc()方法的调用(不一定马上触发),老年代内存不足,永久代(如果有的话)内存不足都会触发fullGC
在发生minor gc之前,虚拟机会检测 : 老年代最大可用的连续空间>新生代all对象总空间?
不满足,虚拟机查看HandlePromotionFailure参数
(1)为true,允许担保失败,会继续检测老年代最大可用的连续空间>历次晋升到老年代对象的平均大小。若大于,将尝试进行一次minor gc,若失败,则重新进行一次full gc。
- 为false,则不允许冒险,要进行full gc。
jdk1.7永久代大小超过阀值,也会触发fullGC
jdk1.8会设置一个元空间大小阀值,如果达到该阀值会触发fullGC
Full GC是对所有的堆内存空间进行垃圾回收(包括永久代或元空间)
FULLGC的危害:
垃圾回收时间长,影响系统对外提供服务。
Major GC/Full GC的速度一般比Minor GC慢10倍以上。
如何避免fullGC
system.gc()方法会建议虚拟机进行full GC,虽然是建议但也增加了full GC概率,尽量让虚拟机自己去管理gc,不调用system.gc方法
调优时应尽量做到让对象在Minor GC阶段被回收、让对象在新生代多存活一段时间及不要创建过大的对象及数组
合理设置元空间大小,避免太小引发full gc
新生代垃圾回收
新生代晋升老年代
- 对象的年龄:每经过一次垃圾回收并生存下来年龄就+1;默认年龄到达15会进入老年代。年龄的阀值可以设置-XX:MaxTenuringThreshold
- 大对象:避免大对象在年轻代中频繁复制,大对象会直接进老年代,默认大小为1M。大小阀值可以设置-XX:PretenureSizeThreshold。(不是所有的垃圾回收器都按照这个规则,像G1回收器是大于等于分区大小一半的对象被称为巨型对象,会分配到老年代的额巨型分区中)
- Survivor空间不足:当servivorTo的空间占用超过了整个servivor区一定大小后,下次垃圾回收时会把年龄大的和体积大的对象放入到老年代。可以设置占用比例阀值-XX:TargetSurvivorRatio,默认值是50,也就是达到50%的时候
为什么大对象直接进入老年代
避免在Eden区及两个Survivor区之间发生大量的内存复制。具体大于多少Serial和ParNew两款收集器可以设置,默认是0,表示任何对象都会先在新生代分配内存。
Parallel Scavenge收集器一般不需要设置
方法区的垃圾回收:
方法区可以通过参数配置选择是否开启垃圾回收
方法区回收的内容:废弃常量和无用的类。
常量池中没有被引用的常量就是弃用常量(这个常量没有任何地方使用),垃圾回收时虚拟机认为有必有的话就会回收掉
无用的类:
该类所有的实例都已经被回收,也就是Java堆中不存在该类的任何实例。
加载该类的ClassLoader已经被回收。
该类对应的java.lang.Class
对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
可以通过设置jvm的参数来控制垃圾回收时是否对无用的类进行回收
在大量使用反射、动态代理、CGLib等bytecode框架的场景,以及动态生成JSP和OSGi这类频繁自定义ClassLoader的场景都需要虚拟机具备类卸载的功能,以保证永久代不会溢出。
fullGC时会对方法区垃圾回收不管是以前的永久代还是现在的元空间
方法区的垃圾收集:
jdk7及低版本靠垃圾收集器进行收集,之后靠方法区虚拟机回收
堆内存的垃圾回收:
靠垃圾收集器对不在被使用的对象的空间进行回收
栈内存的回收:
不是靠垃圾回收器回收的
栈内存的每一个栈帧中分配多少内存基本上是在类结构确定下来时就已知的,因此这几个区域的内存分配和回收都具备确定性,在这几个区域内就不需要过多考虑回收的问题,因为方法结束或者线程结束,内存自然就跟随着回收了。
栈式存储分配按照先进后出的原则进行分配,当变量退出其作用域后,Java会自动释放掉为该变量所分配的内存空间,该内存空间可以立即被另作他用。
java中的类卸载机制
使用JVM自带的类加载器(根加载器、扩展类加载器、系统类加载器)加载的类永远不会被卸载,使用自己创建的类加载器才会可能被卸载。
Class对象和类加载器
在类加载器的内部实现中,用一个Java集合来存放所加载类的引用。
另一方面,一个Class对象总是会引用它的类加载器。
通过调用Class对象的getClassLoader()方法,就能获得它的类加载器。
所以Class实例和加载它的加载器之间为双向关联关系。
类、类的class对象、类的实例对象
一个类的实例总是引用代表这个类的Class对象,在Object类中定义类getClass方法,这个方法返回代表对象所属类的Class对象的引用。此外,所有的Java类都有一个静态属性class,他引用代表这个类的Class对象。
垃圾回收工作时对应用的影响
不管采用什么垃圾收集器,垃圾回收过程中都会或多或少的暂停所有的用户线程
垃圾收集的优化方法
- 减少暂停用户线程的时间
- 减少垃圾回收的时间
- 避免内存碎片的产生
垃圾收集的优化思路
查看垃圾回收的日志,了解系统垃圾回收的过程,找到垃圾回收触发的原因,之后进行优化
增加新生代的内存大小,可以把对象留在新生代进行垃圾回收,避免进入老年代增加回收成功
如何查看垃圾回收日志
可以在应用启动时指定jvm运行参数-XX:+PrintGCDetails等GC日志相关额参数,或者使用jinfo也可以开启(可以在jvm运行过程中开启),在jinfo中需要打开-XX:+PrintGC和 -XX:+PrintGCDetails两个选项才能开启GC日志
可以使用-Xloggc:../logs/gc.log 指定日志文件的输出路径,不指定文件路径在tomcat输出控制台也可以看到gc日志
内存碎片
内存碎片是占用着的不连续的内存空间
影响:会导致明明有内存空间,但是由于不连续,申请稍微大一些的对象无法做到;造成内存浪费
永久代的垃圾回收
一般的,方法区上 执行的垃圾收集是很少的,但这也不代表着在方法区上完全没有垃圾收集
在方法区上进行垃圾收集,条件苛刻而且相当困难,效果也不令人满意,所以一般不做太多考虑
永久代的垃圾回收主要包括类型的卸载和废弃常量池的回收。
当没有对象引用一个常量的时候,该常量即可以被回收。
而类型的卸载更加复杂。必须满足一下三点:
- 该类型的所有实例都被回收了
- 该类型的类加载器被回收了
- 该类型对应的lang.Class没有在任何地方被引用,在任何地方都无法通过反射来实例化一个对象
永久代大小达到临界值会触发fullGC
垃圾回收的算法分类
垃圾回收有几种算法:
标记-清除算法(Mark-Sweep)
标记-整理算法(Mark-Compact)
复制算法(Copying)
分代收集算法(Generational Collection),借助前面三种算法实现
新生代:
复制算法
老年代:
标记-清除算法(Mark-Sweep)
标记-整理算法(Mark-Compact)
标记清除算法
该算法有两个阶段。
- 标记阶段:找到所有可访问的对象,做个标记
- 清除阶段:遍历堆,把未被标记的对象回收,并且将原来标记为可到达对象的标识清除,以便进行下一次垃圾回收操作。
- 优点
- 是可以解决循环引用的问题 (原因是标记清除算法是从栈中根对象开始的,该算法走完后,a对象和b对象是没有被标记的,会被直接回收。)
- 必要时才回收(内存不足时)
- 缺点:
- 回收时,应用需要挂起,也就是stop the world。(也就是应用程序的执行会暂停,等待回收执行完毕后,再恢复程序的执行。)
- 标记和清除的效率不高,尤其是要扫描的对象比较多的时候
- 会造成内存碎片
备注:该算法一般应用于老年代,因为老年代的对象生命周期比较长。在老年代中,由于对象存活率较高,使用复制算法会导致大量的复制操作,降低效率。
何时开始垃圾回收:
在使用标记清除算法时,未引用对象并不会被立即回收.取而代之的做法是,垃圾对象将一直累计到内存耗尽为止.当内存耗尽时,程序将会被挂起,垃圾回收开始执行。
标记-整理算法
标记过程仍然与“标记-清除”算法一样,后续不直接对可回收对象进行清理,而是让所有可用的对象都向一端移动。然后直接清理掉边界以外的内存。
优点可以避免产生内存碎片
相比标记--清除,多了整理,所以会消耗更多的时间,一般用于老年代
复制算法
为了解决标记-清除算法产生的那些碎片。
首先将内存分两部分(假设A、B两部分,可以根据实际情况,将内存块大小比例适当调整;),每次呢只使用其中的一部分(这里我们假设为A区),等这部分内存不够用了,这时候就将这里面还能活下来的对象复制到另一部分内存(这里设为B区)中(搜索活动对象也是用的标记方法),然后把A区中的剩下部分全部清理掉。
这样一来每次清理都要对一半的内存进行回收操作,这样内存碎片的问题就解决了,可以说简单,高效。
优点可以避免产生内存碎片,存活对象不多的情况下,性能高
缺点:会造成一部分的内存浪费,如果存活对象的数量比较大,coping的性能会变得很差。
coping算法一般是使用在新生代中,因为新生代中的对象一般都是朝生夕死的,存活对象的数量并不多,这样使用coping算法进行拷贝时效率比较高。
分代收集算法
这种算法并没有什么新的思想,只是根据对象的存活周期的不同将内存划分为几块。一般是把Java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用“标记-清理”或“标记-整理”算法来进行回收。
HotSpot vm垃圾收集器
JDK7/8后,HotSpot虚拟机所有收集器及组合(连线),如下图:
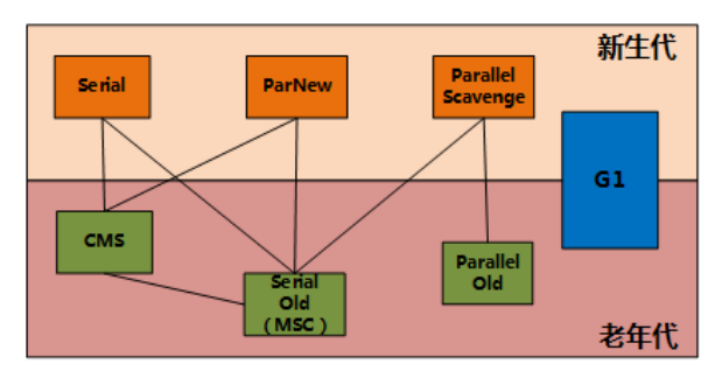
两个收集器间有连线,表明它们可以搭配使用
上面算法都是理论性的东西,Java虚拟机规范没有规定垃圾收集器具体如何实现,因此不同厂商、不同版本虚拟机提供的垃圾收集器可能有所差异。下面列举HotSpot(Sun JDK和Open JDK自带)虚拟机提供的七种垃圾收集器实现:
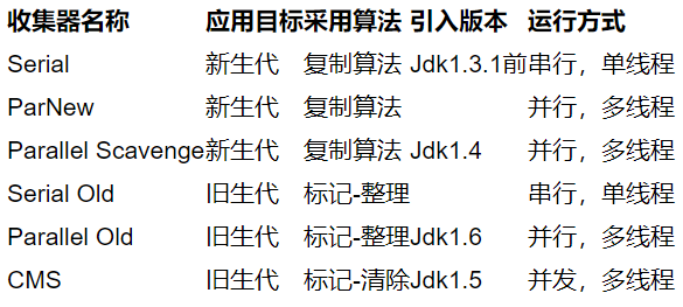
介绍一下垃圾收集器
垃圾收集器负责对分配给对象但不再使用的内存进行回收
新生代收集器:Serial、ParNew、Parallel Scavenge;
老年代收集器:Serial Old、Parallel Old、CMS;
整堆收集器:G1
串行并行并发
串行:Serial、Serial Old
并行:ParNew、Parallel Scavenge、Parallel Old
并发:CMS、G1
低停顿:CMS、G1
并行(Parallel):多条垃圾收集线程并行工作,而用户线程仍处于等待状态。支持并行的都带有par
并发(Concurrent):垃圾收集线程与用户线程一段时间内同时工作(不是并行,而是交替执行)。
串行:是指多个任务时,各个任务按顺序执行,完成一个之后才能进行下一个。
总结:
算法
复制算法:Serial、ParNew、Parallel Scavenge、G1
标记-清除:CMS
标记-整理:Serial Old、Parallel Old、G1
- ParNew收集器是Serial的多线程版本。
- Serial Old收集器是Serial收集器的老年代版本。
- Parallel Scavenge收集器以吞吐量为目标,适合在后台运算而不需要太多交互的任务。
- Parallel Old收集器是Parallel Scavenge的旧生代版本。
- Parallel Scavenge收集器和Parallel Old收集器是名副其实的“吞吐量优先”组合。
- 新生代因为回收留下的对象少,所以采用标记-复制法。
- 旧生代因为回收留下的对象多,所以采用标记-清除/标记-整理算法。
Serial收集器
针对新生代;
采用复制算法;
单线程进行垃圾收集;
进行垃圾收集时,必须暂停所有工作线程,直到完成;
简单高效(与其他收集器的单线程相比);
对于限定单个CPU的环境来说,Serial收集器没有线程交互(切换)开销,可以获得最高的单线程收集效率;
在用户的桌面应用场景中,可用内存一般不大(几十M至一两百M),可以在较短时间内完成垃圾收集(几十MS至一百多MS),只要不频繁发生,这是可以接受的。
ParNew收集器
新生代,复制算法,多线程
ParNew垃圾收集器是Serial收集器的多线程版本。
除了多线程外(多个垃圾收集线程并行工作,收集时用户线程还是会暂停),其余的行为、特点和Serial收集器一样;
在Server模式下,ParNew收集器是一个非常重要的收集器,因为除Serial外,目前只有它能与CMS收集器配合工作;
但在单个CPU环境中,不会比Serail收集器有更好的效果,因为存在线程交互开销。
Parallel Scavenge收集器
Parallel Scavenge垃圾收集器因为与吞吐量关系密切,也称为吞吐量收集器(Throughput Collector)。
(A)、有一些特点与ParNew收集器相似
新生代收集器;
采用复制算法;
多线程收集;
(B)、主要特点是:它的关注点与其他收集器不同
CMS等收集器的关注点是尽可能地缩短垃圾收集时用户线程的停顿时间;
而Parallel Scavenge收集器的目标则是达一个可控制的吞吐量(Throughput);
应用场景
高吞吐量为目标,即减少垃圾收集时间,让用户代码获得更长的运行时间;
当应用程序运行在具有多个CPU上,对暂停时间没有特别高的要求时,即程序主要在后台进行计算,而不需要与用户进行太多交互;
例如,那些执行批量处理、订单处理、工资支付、科学计算的应用程序;
Serial Old收集器
Serial Old是 Serial收集器的老年代版本;
1、特点
针对老年代;
采用"标记-整理"算法(还有压缩,Mark-Sweep-Compact);
单线程收集;
应用场景
主要用于Client模式;
而在Server模式有两大用途:
(A)、在JDK1.5及之前,与Parallel Scavenge收集器搭配使用(JDK1.6有Parallel Old收集器可搭配);
(B)、作为CMS收集器的后备预案,在并发收集发生Concurrent Mode Failure时使用(后面详解);
Parallel Old收集器
parallel Old垃圾收集器是Parallel Scavenge收集器的老年代版本;
JDK1.6中才开始提供;
1、特点
针对老年代;
采用"标记-整理"算法;
多线程收集;
应用场景
JDK1.6及之后用来代替老年代的Serial Old收集器;
特别是在Server模式,多CPU的情况下;
这样在注重吞吐量以及CPU资源敏感的场景,就有了Parallel Scavenge加Parallel Old收集器的"给力"应用组合;
CMS收集器
并发标记清理(Concurrent Mark Sweep,CMS)收集器也称为并发低停顿收集器或低延迟垃圾收集器;
特点
针对老年代;
基于"标记-清除"算法(不进行压缩操作,产生内存碎片);
并发收集、低停顿;
需要更多的内存(看后面的缺点);
垃圾收集线程与用户线程(基本上)同时工作;
应用场景
与用户交互较多的场景;
希望系统停顿时间最短,注重服务的响应速度;
CMS收集器运作过程
比前面几种收集器更复杂,可以分为4个步骤:
(A)、初始标记(CMS initial mark)
仅标记一下GC Roots能直接关联到的对象;速度很快,但需要停止用户线程;
(B)、并发标记(CMS concurrent mark)
进行GC Roots Tracing的过程;
刚才产生的集合中标记出存活对象;
应用程序也在运行;
并不能保证可以标记出所有的存活对象;
(C)、重新标记(CMS remark)
为了修正并发标记期间因用户程序继续运作而导致标记变动的那一部分对象的标记记录;
需要停止用户线程,且停顿时间比初始标记稍长,但远比并发标记短;
采用多线程并行执行来提升效率;
(D)、并发清除(CMS concurrent sweep)
回收所有的垃圾对象;
整个过程中耗时最长的并发标记和并发清除都可以与用户线程一起工作;
所以总体上说,CMS收集器的内存回收过程与用户线程一起并发执行;
CMS收集器缺点
- 内存碎片:由于采用的标记清除算法,所以会存在内存碎片
- 浮动垃圾:CMS清理垃圾过程中,会产生新的垃圾,这就是浮动垃圾,只能放到下次垃圾收集时进行清理了(所以并发清除是要预留一定的内存,不能像其他垃圾收集器老年代几乎满了再收集,预留空间可以设置)
- 占用空间大:由于要预留内存,所以一般都要设置更大的空间
- 回收时间长:因为CMS回收复杂,而且用户线程也会占用CPU,所以回收时间长,这样吞吐量就偏低
- 并发模式失败:CMS清理过程中,预留给浮动垃圾内存空间无法满足程序需要,JVM会临时启用Serail Old收集器,这是一个单线程的垃圾收集器,并引发fullgc
优缺点总结:
特点:标记清除算法,
优点:可以和用户线程并发执行,低停顿
缺点:垃圾回收过程中由于占用cpu用户进程变慢;无法清理并发收集过程中新产生的垃圾对象也就是浮动垃圾,需要下次gc清理;基于标记清理算法会产生内存碎片
内存碎片处理:
为了解决这个问题,CMS提供了一个开关参数,用于在CMS顶不住要进行full gc的时候开启内存碎片的合并整理过程,内存整理的过程是无法并发的,空间碎片没有了,但是停顿的时间变长了。
cms降级为Serail Old:
预留的内存空间无法满足程序需要时,会使用Serail Old来进行清理老年代,它是标记整理算法能够处理掉内存碎片。
G1收集器
G1(Garbage-First)是JDK7-u4才推出商用的收集器;G1是一个整堆垃圾收集器
兼顾吞吐量和停顿时间,是 Oracle JDK 9 以后的默认 GC 选项。
分代时,新生代和老年代1:2
不用指定年轻代大小:在G1中年轻代是在5%-60%的区间中可伸缩的,G1自己会调控到合适的大小所以不要指定。可以指定堆内存大小
应用场景:适用于多处理器和大容量内存环境。
特点
并行与并发
能充分利用多CPU、多核环境下的硬件优势;可以并行来缩短用户线程停顿时间;也可以并发让垃圾收集与用户程序同时进行;年轻代垃圾收集使用多线程并行回收。
整堆收集
能独立管理整个GC堆(新生代和老年代),而不需要与其他收集器搭配;
能够采用不同方式处理不同时期的对象;(在G1算法中,采用了另外一种完全不同的方式组织堆内存,传统的新生代,老年代的数据都是物理内存连续的内存块,G1中的新生代和老年代的内存块只是逻辑上是一段内存,物理上可能不相连,把内存以大小相等的region进行了切分,默认把堆内存按照2048份均分)(region大小1M-32M)
通过分区的方式使得内存块的粒度更小,可以更加细化的管理内存,每次垃圾回收就不需要对整块Eden或Old区进行回收,只需针对小块的分区进行回收即可,减少停顿时间,同时可以有效的避免内存碎片的问题,因为每次垃圾回收都是清空一整块的Region,避免的内存碎片。
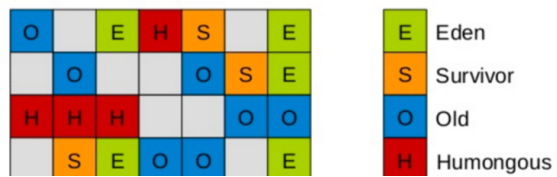
不产生空间碎片
空间整合:基于标记-整理和复制,不会产生内存空间碎片,活跃对象被复制到新的Survivor区或者年老代区域。
低停顿,可预测的停顿:
G1可以设置一个垃圾回收的预期停顿时间,制定一个目标,规定在一个时间内,垃圾回收引起的停顿时间不能超过多久(即垃圾回收时间占用的比例)
巨型对象(Humongous Region):
巨型对象指的是大小大于等于分区大小一半的对象。巨型对象的移动成本很高,而且有可能一个分区不能容纳整个巨型对象。因此,巨型对象会直接在老年代分配,所占用的连续空间称为巨型分区(Humongous Region)。G1针对巨型对象进行了优化,当发现没有引用指向巨型对象时,巨型对象可直接在年轻代收集周期中被回收。巨型对象会独占一个、或多个连续分区,每一个Region中都只有一个巨型对象,其他剩余空间无法被利用,会产生内存碎片。巨型对象永远不会移动,即使在Full GC中。
缺点:
内存占用和执行负载比GMS高
优缺点总结:
特点:针对多CPU,大内存的服务;标记整理和复制算法;整堆垃圾收集;内存等分块
优点:低停顿,可预测的停顿;不产生内存碎片;
缺点:内存占用
应用场景
针对多CPU,大内存的服务;
低停顿、可预测的停顿时间,如:在堆大小约6GB或更大时,可预测的暂停时间可以低于0.5秒;
回收过程:
G1将堆内存划分为多个大小相等的Region,这些Region在逻辑上被映射为Eden、Survivor和老年代。
新生代回收:
当Eden区装满时,会触发新生代的GC。这个GC过程通过复制算法来进行垃圾回收,并且系统会停止用户线程状态。在这个阶段,G1会将Eden区中存活的对象拷贝到Survivor区中的一个空的Region。拷贝完成后,Eden区中的垃圾对象会被回收掉。之后对Survivor区年龄增加并检查年龄,如果年龄达到到老年区的年龄会被移动到老年区,对于Survivor区中的对象,G1会检查它们的年龄。如果对象的年龄达到了预设的阈值这些对象会被移动到老年代。如果Survivor区的空间不足以容纳所有从Eden区复制过来的存活对象,那么部分对象可能会直接被晋升到老年代。
Survivor区空间不足会触发垃圾回收将Survivor区存活的对象复制到其他空的Survivor区,非存活的回收掉。并增加年龄,检查年龄。
老年代回收步骤:
当老年代空间占用的内存达到或超过JVM堆内存大小的45%时(默认值),就会触发混合回收。混合回收会对新生代、老年代整体的进行标记回收。
初始标记:标记一下GC Roots能直接关联到的对象,需要停顿用户线程,但耗时很短
并发标记:是从GC Root开始对堆中对象进行可达性分析,找出存活的对象,这阶段耗时较长,但可与用户程序并发执行
最终标记:修正在并发标记期间因用户程序继续运作而导致标记产生变动的那一部分标记记录,需要停顿用户线程(使用了比CMS更快的算法)
筛选回收:对各个Region的回收价值和成本进行排序,根据用户所期望的GC停顿时间来制定回收计划,和用户线程并发执行回收工作
当老年代空间碎片过多时,G1会触发一个碎片整理过程。这个过程会暂停应用程序的执行,对老年代中的存活对象进行整理,使它们连续排列在内存中。
原理:
G1将整个堆内存划分为多个大小相等的Region,每个Region都可以根据需要扮演新生代或老年代的角色。对于新生代对象,G1采用复制算法;而对于老年代对象,G1采用标记-整理算法。
使用大小相等的region来切分堆内存是为了避免全内存扫描。每个region可以单独进行垃圾回收,通过记录每个region垃圾回收时间以及回收所获得的空间(通过过去回收的经验获得),并维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的region。
每个region不是固定化的属于新生代或老年代,会随着垃圾收集改变
为什么分成大小相等的region:
为了在进行收集时不必在全堆范围内进行,带来了停顿时间可预测的收集模型:用户可以指定垃圾回收引起的用户线程停顿时间。
如何做到可以预期停顿时间:
G1会统计每个Region中有多少垃圾对象,对它进行回收大约要多长时间
根据开发设定的预期系统停顿时间,来选择合适的一组Region进行回收,保证GC时的停顿时间在可控范围内。
为什么要内存大点:
如果内存小的话,因为g1是对部分垃圾对象进行回收,来达到用户制定停顿时间的目的,这样的话内存总是不够用,触发频繁的垃圾回收,再有g1的垃圾回收算法比较复杂,就可能比不上其他垃圾回收器了
G1比较适合内存稍大一点的应用(一般来说至少4G以上),小内存的应用还是用传统的垃圾回收器比如CMS比较合适。
为什么G1回收比其他垃圾收集器早
G1进行垃圾回收的时机更早,默认在堆内存使用率达到45%时就会开始垃圾回收。G1的垃圾回收并非每次都将所有不可达对象完全清除,G1倾向于优先清除活跃度低的内存块,因为这些块中的存活对象少(或者压根没有存活对象),清理速度更快。对于那些活跃度高的内存块,G1会放置不管,直至某个时间点该块的活跃度足够低时再进行回收。
Remembered Set
在G1收集器中,Region之间的对象引用以及其他收集器中的新生代与老年代之间的对象引用,虚拟机都是使用Remembered Set来避免全堆扫描的。
G1中每个Region都有一个与之对应的Remembered Set,记录了region中对象的被引用信息。
并发标记阶段因用户程序继续运作而导致对象变化记录在线程Remembered Set Logs里面,最终标记阶段需要把Remenbered Set Logs的数据合并到Remenbered Set中
CMS和G1对比
CMS的垃圾收集范围是老年代,G1的范围是整个堆
CMS使用标记清除算法进行垃圾收集,G1使用标记整理和复制算法
CMS会产生内存碎片,G1不会产生垃圾碎片
CMS内存中的新生代和老年代都是物理上连续的一块区域,G1是把堆内存分成了等分的小块,物理上不连续
CMS新生代和老年代都是固定区域的内存,G1中每个region可以是新生代也可以是老年代
CMS收集内存是对整个老年代扫描收集,G1可以只收集一部分
CMS不能制定垃圾收集停顿时间,G1可以制定
CMS和G1内存不够用的时候都会降级为serial old GC(full GC)来收集
如何选:
需要更易预测的GC暂停时间选G1
G1内存占用和执行负载比GMS高,如果内存不够大,cpu核数不是很高选CMS
三色标记法
三色标记法是JVM中用来标记对象是否为垃圾的一种方法,CMS、G1都有用到,这类收集器都有一个垃圾回收线程与用户线程并发执行的过程
传统的标记清除算法下,只有两个状态位0、1,比如0:表示未标识,1:表示对象可达,一开始所有对象被标记为0,扫描过程中把存活的对象标记为1,,之后清除所有状态为0的,然后再把状态为1的重置为0。
为什么需要三色标记法:
三色标记法:
白色:尚未访问过(未搜索)
灰色:本对象已访问过,但是本对象 引用到 的其他对象 尚未全部访问完。全部访问后,会转换为黑色(正搜索)
黑色:本对象已访问过,而且本对象 引用到 的其他对象 也全部访问过了(已搜索)
过程:
最开始所有对象都是白色的,假设有 A -> B -> C, A 是 GC Roots 直接关联的对象,首先会把 A 标记成灰色,然后搜索 A 的引用B,搜索到了 B,把 B 变成了灰色,那么 A 就搜索完成了;( C 不是 A 的引用,A的颜色跟C没关系,如果A引用多个对象要把其他都设置为灰色,自己才设置为黑色)。此时把 A 相关的搜索完了,那么 A 就变成了黑色。再搜索B的引用C,搜索到C,C变灰,B变黑,再搜索C,C没引用C变黑
当存在并发时:
漏标问题:
比如原先A-B-C,B标完灰色,A标完黑色之后gc线程停止,用户线程执行,用户线程修改了引用关系改为A-B,A-C,gc线程重新启动后去搜索B发现没有引用了,标为黑;最后A虽然还存活缺还是白色无法被标注
(修改引用如:b.c=null;a.c=instance)
问题解决:
可以看到,发生这种bug的情况需要以下两个条件同时发生
1.黑色指向这个白色
2.灰色不再指向白色
CMS是从条件2入手搞的;G1是从条件1入手搞的
CMS采用的是增量更新
增量更新破坏的是第一个条件,我们在黑色对象增加了对白色对象的引用之后,将它的这个引用,记录下来(记录新增白色对象的黑色对象),在最后标记的时候,再以这个黑色对象为根,对它的引用进行重新扫描.
可以简单理解为,当一个黑色对象增加了对白色对象的引用,那么这个黑色对象就被变灰
这样有一个缺点,就是会重新扫描这个黑色对象的所有引用,比较浪费时间
G1采用的是原始快照
原始快照破坏的是第二个条件,我们在这个灰色对象取消对白色对象的引用之前,将这个引用记录下来(记录被取消引用的白色对象),在最后标记的时候,再以这个引用指向的白色对象为根,对它的引用进行扫描依次标记
可以简单理解为,当一个灰色对象取消了对白色对象的引用,那么这个白色对象被变灰
这样做的缺点就是,这个白色对象有可能并没有黑色对象去引用它,但是它还是被变灰了,就会导致它和它的引用,本来应该被垃圾回收掉,但是此次GC存活了下来,就是所谓的浮动垃圾.其实这样是比较可以忍受的,只是让它多存活了一次GC而已,浪费一点点空间,但是会比增量更新更省时间.
如何记录并发标记阶段的对象引用变化:监听用户修改对象引用关系,变化时记录到Remember Set log然后合并成Remenbered Set,CMS记录的新增关系日志,G1记录的是删除关系日志
并发标记和并行标记
并发说明:垃圾回收线程跑一会停下,让给用户线程,一会在调换过来跑
并行:垃圾回收线程和用户线程可以一同跑
安全点
对于可以和用户线程并发的GC,需要选择合适的时机来停顿用户线程
用户线程什么时候停顿:
并非在所有地方都能停顿下来开始GC,只有在所有线程(这里不包括执行JNI调用的线程)都“跑”到最近的安全点上再停顿下来。在这个执行状态下,Java虚拟机的堆栈不会发生变化。这么一来,垃圾回收器便能够“安全”地执行可达性分析。只要不离开这个安全点,Java虚拟机便能够在垃圾回收的同时,继续运行这段本地代码。
安全点的选定:
基本上是以程序“是否具有让程序长时间执行的特征”为标准进行选定的。“长时间执行”的最明显特征就是指令序列复用,例如方法调用、循环跳转、异常跳转等,所以具有这些功能的指令才会产生Safepoint。
方案:
抢先式中断(Preemptive Suspension)
抢先式中断不需要线程的执行代码主动去配合,在GC发生时,首先把所有线程全部中断,如果发现有线程中断的地方不在安全点上,就恢复线程,让它“跑”到安全点上。现在几乎没有虚拟机采用这种方式来暂停线程从而响应GC事件。
主动式中断(Voluntary Suspension)
主动式中断的思想是当GC需要中断线程的时候,不直接对线程操作,仅仅简单地设置一个标志,各个线程执行时主动去轮询这个标志,发现中断标志为真时就自己中断挂起。
安全区域:
指在一段代码片段中,引用关系不会发生变化。在这个区域中任意地方开始GC都是安全的。
查看jvm使用的垃圾收集器
java -XX:+PrintCommandLineFlags -version
-XX:InitialHeapSize=62763840
-XX:MaxHeapSize=1004221440
-XX:+PrintCommandLineFlags
-XX:+UseCompressedOops
-XX:+UseParallelGC
java version "1.7.0_45"
Java(TM) SE Runtime Environment (build 1.7.0_45-b18)
Java HotSpot(TM) 64-Bit Server VM (build 24.45-b08, mixed mode)
UseParallelGC就代表使用的的parallel scavenge+Serial Old垃圾收集器
该命令作用:让JVM打印出那些已经被用户或者JVM设置过的详细的XX参数的名称和值。
默认的垃圾收集器
jdk7 默认垃圾收集器Parallel Scavenge(新生代)+Parallel Old(老年代)
jdk8 默认垃圾收集器Parallel Scavenge(新生代)+Parallel Old(老年代)
jdk9 默认垃圾收集器G1
jdk11默认使用的垃圾回收器ZGC
jdk17默认使用的垃圾回收器 G1
目前,Java 8、Java 11和Java 17在企业应用中较为流行。
垃圾收集器期望的目标
(1)、停顿时间
停顿时间越短就适合需要与用户交互的程序;
良好的响应速度能提升用户体验;
(2)、吞吐量
CPU用于运行用户代码的时间与CPU总消耗时间的比值;即吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间);高吞吐量即减少垃圾收集时间,让用户代码获得更长的运行时间;
高吞吐量则可以高效率地利用CPU时间,尽快完成运算的任务;
主要适合在后台计算而不需要太多交互的任务;
(3)、覆盖区(Footprint)
在达到前面两个目标的情况下,尽量减少堆的内存空间;
可以获得更好的空间局部性;
如何选择垃圾回收器
单CPU或小内存,单机程序
-XX:+UseSerialGC
多CPU,追求吞吐量,与用户交互不多的场景,如后台计算型应用
-XX:+UseParalellGC或者-XX:+UseParalellOldGC
多CPU,追求低停顿时间,需快速响应如互联网应用,与用户多交互的场景
-XX:+UseParNewGC或者-XX:+UseConcMarkSweepGC
怎么设置垃圾收集器
虚拟机提供了参数,以便用户根据自己的需求设置所需的垃圾收集器:
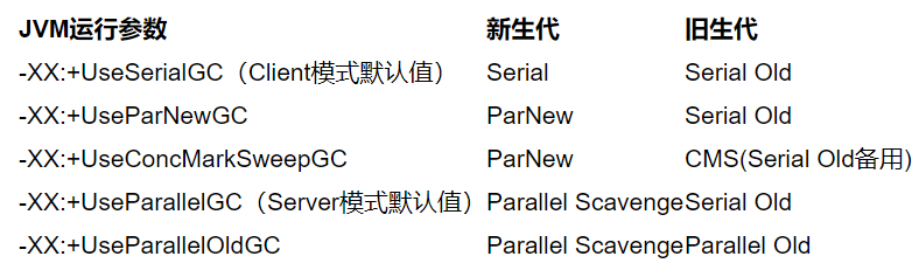
"-XX:+UseConcMarkSweepGC":指定使用CMS后,会默认使用ParNew作为新生代收集器;
Tomcat的catalina.sh文件修改,或启动时指定参数进行修改
JVM client模式和Server模式的区别
命令行:java -version
有这样的信息: Java HotSpot(TM) 64-Bit Server VM (build 25.31-b07, mixed mode)
其中有个Server VM代表了JVM的Server模式了。
JVM Server模式与client模式启动的差别?
最主要的差别在于:-Server模式启动时,速度较慢,但是一旦运行起来后,性能将会有很大的提升.原因是:
当虚拟机运行在-client模式的时候,使用的是一个代号为C1的轻量级编译器, 而-server模式启动的虚拟机采用相对重量级,代号为C2的编译器. C2比C1编译器编译的相对彻底,,服务起来之后,性能更高.
所以通常用于做服务器的时候我们用server模式,如果你的电脑只是运行一下java程序,就客户端模式就可以了。当然这些都是我们做程序优化程序才需要这些东西的,普通人并不关注这些专业的东西了。其实服务器模式即使编译更彻底,然后垃圾回收优化更好,这当然吃的内存要多点相对于客户端模式。
怎么修改JVM的启动模式呢?
64位系统默认在 JAVA_HOME/jre/lib/amd64/jvm.cfg
32在目录JAVA_HOME/jre/lib/i386/jvm.cfg
我的配置是这样的,所以是已服务器模式启动的,当然,你想换成client模式的话,把两个对调一下就可以了。
默认是这样的:表示以server模式启动
#
-server KNOWN
-client IGNORE
换成client就是:
#
-server IGNORE
-client KNOWN
实际项目配置
1、修改 tomcat\bin\Catalina.bat 文件
windows环境下:
在166行左右
rem Execute Java with the applicable properties ”以下每行
%_EXECJAVA% %JAVA_OPTS% %CATALINA_OPTS% %DEBUG_OPTS% -Djava.endorsed.dirs="%JAVA_ENDORSED_DIRS%" -classpath "%CLASSPATH%" -Dcatalina.base="%CATALINA_BASE%" -Dcatalina.home="%CATALINA_HOME%" -Djava.io.tmpdir="%CATALINA_TMPDIR%" %MAINCLASS% %CMD_LINE_ARGS% %ACTION%
在 %DEBUG_OPTS% 后面添加-Xms256m -Xmx512m
linux环境下:
打开在Tomcat的安装目录的bin文件的catalina.sh文件,进入编辑状态.
在注释后面加上如下脚本:
JAVA_OPTS='-Xms512m -Xmx1024m'
JAVA_OPTS="$JAVA_OPTS -server -XX:PermSize=64M -XX:MaxPermSize=256m"
其中 JAVA_OPTS='-Xms512m -Xmx1024m' 是设置Tomcat使用的内存的大小.
-XX:PermSize=64M -XX:MaxPermSize=256m 指定类空间(用于加载类)的内存大小
标准参数设置参考样本1(tomcat可用8G内存案例)
set JAVA_OPTS=%JAVA_OPTS% -server –Xms8192m –Xmx8192m–Xmn1890m -verbose:gc -XX:+UseConcMarkSweepGC -XX:MaxTenuringThreshold=5 -XX:+ExplicitGCInvokesConcurrent -XX:GCTimeRatio=19 -XX:CMSInitiatingOccupancyFraction=70-XX:CMSFullGCsBeforeCompaction=0 –Xnoclassgc -XX:SoftRefLRUPolicyMSPerMB=0
保存后,重新以命令行的方式运行 tomcat ,即可,然后通过最后面介绍的如何观察tomcat现有内存情况的方法进行查看是否已经变更成功。
参考2
cp $TOMCAT_HOME/bin/catalina.sh $TOMCAT_HOME/bin/catalina.sh.bak_20170815
vi $TOMCAT_HOME/bin/catalina.sh
vi catalina.sh
if [ -z "$JSSE_OPTS" ] ; then
JSSE_OPTS="-Djdk.tls.ephemeralDHKeySize=2048"
fi
JVM_OPTS="-server -verbose:gc
-XX:+PrintGCDateStamps
-XX:+PrintGCDetails
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=9
-XX:GCLogFileSize=256m
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:+CMSParallelRemarkEnabled
-XX:CMSInitiatingOccupancyFraction=70
-XX:+CMSClassUnloadingEnabled
-XX:CMSMaxAbortablePrecleanTime=300
-XX:+CMSScavengeBeforeRemark
-XX:GCTimeRatio=19
-XX:SurvivorRatio=3
"
JVM_OPTS="-Xmx16g -Xms4g -Xmn512m $JVM_OPTS -Xloggc:$CATALINA_TMPDIR/jenkins_gc.log"
JAVA_OPTS="$JAVA_OPTS $JVM_OPTS $JSSE_OPTS -Dmail.smtp.starttls.enable=true -Dmail.smtp.auth=true -Dmail.smtp.ssl.trust=mail.service.mtime.com"jvm有两种回收方式,一种是标记完待回收的对象之后一起释放内存,这种方法的缺点是会产生较多难以重复利用的内存碎片。另一种为了避免内存碎片的出现,将内存分为两块,一块使用,一块不使用,标记完所有待回收的对象之后,将还要使用的内存复制到不使用的区域,然后对使用的整体区域进行内存回收,这种方法没有内存碎片问题,但是每次回收的复制工作很耗性能。
通过统计发现,在内存中存活越久的对象就越不容易被回收,越是新分配的内存对象就越可能会被回收。根据这个特性,把内存区域分为新生代和老年代(有的虚拟机会分为很多代),新生代容易被回收,采用复制内存再回收的方法,老年代不容易被回收,采用标记后回收和复制内存相结合的方法。
观察tomcat现有内存情况
1、启动tomcat
2、访问 http://localhost:8080/manager/status ,并输入您在安装tomcat时输入的用户与口令,如 admin ,密码 admin(密码是您在tomcat安装时输入的)
注:添加用户,修改conf/tomcat-users.xml
< ?xml version='1.0' encoding='utf-8'?>
< tomcat-users>
<role rolename="tomcat"/>
<role rolename="role1"/>
<role rolename="manager"/>
<role rolename="admin"/>
<user username="tomcat" password="tomcat" roles="tomcat"/>
<user username="both" password="tomcat" roles="tomcat,role1"/>
<user username="role1" password="tomcat" roles="role1"/>
<user username="admin" password="admin" roles="admin,manager"/>
< /tomcat-users>
3、进入了Server Status页面,可以在JVM表格中看到
Free memory: 241.80 MB Total memory: 254.06 MB Max memory: 508.06 MB
上面的文字即代表了,当前空闲内存、当前总内存、最大可使用内存三个数据。
通知虚拟机进行垃圾回收
可以手动执行System.gc(),通知GC运行,但并不保证GC一定会执行,要看jvm怎么决定。
System.gc()会做什么事情?
这个方法用来提示JVM要进行垃圾回收(full gc)。但是,立即开始还是延迟进行垃圾回收是取决于JVM的。
说一下finalize方法
finalize是Object类的一个方法,在垃圾收集器执行之前调用被回收对象的此方法,可以覆盖此方法提供垃圾收集时的其他资源回收,例如关闭文件等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号