redis总结
redis简介
- Redis本质上一个数据库
- 与Memcached类似的NoSQL型数据库,但是他的数据可以持久化的保存在磁盘上,解决了服务重启后数据不丢失的问题
- 他的值可以是string(字符串)、list(列表)、hash(哈希)、set(集合)或者是zset(有序集合)
- 所有的数据类型都具有push/pop、add/remove、执行服务端的并集、交集、两个sets集中的差别等等操作,这些操作都是具有原子性的
- Redis还支持各种不同的排序能力
- 用C语言开发的一个开源的Key/Value的NoSQL数据库
- Redis支持绝大部分主流的开发语言,如:C、Java、C#、PHP、Perl、Python、Lua、Erlang、Ruby等等
- redis默认使用6379端口。
Redis能读的速度是110000次/s,写的速度是81000次/s 。
Redis的所有操作都是原子性的,(之所以是原子性的,是因为Redis是单线程的。)
优点:
(1) 速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)
(2) 支持丰富数据类型,支持string,list,set,sorted set,hash,bitmap,HyperLogLog
(3) 支持持久化,避免服务器重启丢失
(4) 单线程并且提供了原子操作,合理使用可以有效避免线程安全问题
redis数据类型
string
string是最简单的数据类型,一个key对应一个value,string类型是二进制安全的,redis的string可以包含任何数据,如jpg图片或者序列化的对象
hash
hash是一个string类型的field和value的映射表,它的添加、删除操作都是0(1)(平均)。hash特别适合存储对象,相较于把对象的每个字段存成单个string类型,存储在hash类型中占用更少内存,并且方便存取整个对象。
list
lists是链表结构操作中的key可以理解为链表的名称,redis中的list类型其实就是一个每个子元素都是string类型的双向链表,我们可以通过push、pop操作链表的头部或者尾部添加删除元素,这样list即可以作为栈也可以作为队列。
set
它是string类型的无序集合,set通过hash table实现的,不能够有重复的元素,添加,删除和查找的复杂度都是0(1).对集合我们可以取并集,交集,差集。通过这些操作我们可以实现sns中的好友推荐和blog的tag功能。
可以存储2的32次方减1个元素
zset(sorted set)
有序集合,利用这一属性可以在添加或修改元素时指定元素,每次指定后,zset会按照新的值调整顺序,可以理解为有两列的mysql表,一列存value,一列存顺序,操作中的key可以理解为zset的名字。默认按照score进行从小到大排序.不能够有重复的元素
可以存储2的32次方减1个元素
bitmap
位图,位图并不是一个新的数据类型,它其实是使用了字符串类型比如用户签到统计,月活跃用户数统计等等业务场景都适合用位图实现,位图的目的是节省空间,在适当的场景下使用可以很大程度上节省空间,但是使用不当的话反而适得其反。因为bitmap其实就是一个string,因此位图的空间法则和string的空间分配法则一致:当字符串长度小于 1M 时,扩容都是加倍现有的空间,如果超过 1M,扩容时一次只会多扩 1M 的空间。需要注意的是字符串最大长度为 512M。
redis中所有数据都是二进制形式存储的。redis支持一个setbit和getbit操作,它支持在某个key的value上直接对某个二进制位操作,每个二进制位都只有0和1两种状态,正好可以表示用户是否活跃两种状态。
HyperLogLog
Redis 在 2.8.9 版本添加了 HyperLogLog 结构。
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
HyperLogLog 是不精确的去重计数方案,虽然不精确但是也不是非常不精确,标准误差是 0.81%.关于该算法的介绍https://blog.csdn.net/firenet1/article/details/77247649
什么是基数?
比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素个数)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
redis的应用场景
缓存(数据查询、短连接、新闻内容、商品内容等等)。(最多使用)
分布式集群架构中的session分离。分布式会话,session共享
聊天室的在线好友列表。
任务队列。(秒杀、抢购、12306等等)
应用排行榜。使用sorted set能实现排行榜。根据分数排行,可以对分数进行increment
网站访问统计。
数据过期处理(可以精确到毫秒)
取最新n个数据的操作
计数器应用使用incr命令
分布式锁,使用setnx命令封装或使用redisson封装好的
社交网络:点赞、踩、关注/被关注、共同好友等是社交网站的基本功能,可以使用set结构计算交差并集
最新列表
Redis列表结构,LPUSH可以在列表头部插入一个内容ID作为关键字,LTRIM可用来限制列表的数量,这样列表永远为N个ID,无需查询最新的列表,直接根据ID取到对应的内容即可。
可以利用lrange命令,做基于redis的分页功能,性能极佳,用户体验好。
构建消息系统
redis的java客户端
Redisson,Jedis,lettuce等等
Jedis是Redis的Java实现的客户端,其API提供了比较全面的Redis命令的支持;
Redisson实现了分布式和可扩展的Java数据结构,提供很多分布式相关操作服务,例如,分布式锁,分布式集合,可通过Redis支持延迟队列。和Jedis相比,功能较为简单,不支持字符串操作,不支持排序、事务、管道、分区等Redis特性。Redisson的宗旨是促进使用者对Redis的关注分离,从而让使用者能够将精力更集中地放在处理业务逻辑上。
Redisson中的方法则是进行比较高的抽象,每个方法调用可能进行了一个或多个Redis方法调用。
基于Netty实现,采用非阻塞IO,性能高
Lettuce:高级Redis客户端,用于线程安全同步,异步和响应使用,支持集群,Sentinel,管道和编码器。目前springboot默认使用的客户端。
伸缩性:
Jedis:使用阻塞的I/O,且其方法调用都是同步的,程序流需要等到sockets处理完I/O才能执行,不支持异步。Jedis客户端实例不是线程安全的,所以需要通过连接池来使用Jedis。
Jedis仅支持基本的数据类型如:String、Hash、List、Set、Sorted Set。
Redisson:基于Netty框架的事件驱动的通信层,其方法调用是异步的。Redisson的API是线程安全的,所以可以操作单个Redisson连接来完成各种操作。
Redisson不仅提供了一系列的分布式Java常用对象,基本可以与Java的基本数据结构通用,还提供了许多分布式服务,其中包括(BitSet, Set, Multimap, SortedSet, Map, List, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, AtomicLong, CountDownLatch, Publish / Subscribe, Bloom filter, Remote service, Spring cache, Executor service, Live Object service, Scheduler service)。
Lettuce:基于Netty框架的事件驱动的通信层,其方法调用是异步的。Lettuce的API是线程安全的,所以可以操作单个Lettuce连接来完成各种操作。
redis快的原因
Redis是纯内存数据库,一般都是简单的存取操作,线程占用的时间很少,时间的花费主要集中在IO上,所以读取速度快。
Redis使用的是非阻塞IO,使用多路I/O复用模型,通过单线程来处理多个链接请求,减少网络IO的耗时。
Redis采用了单线程的模型,保证了每个操作的原子性,也减少了线程的上下文切换和竞争。
在单线程的情况下,就不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗。
为什么redis 单线程模型也能效率这么高?
- a) 纯内存操作
- b) 核心是基于非阻塞的 IO 多路复用机制
- c) 单线程反而避免了多线程的频繁上下文切换问题
多路I/O复用模型
I/O多路复用,I/O就是指的我们网络I/O,多路指多个TCP连接(或多个Channel),复用指复用一个或少量线程。
使用I/O复用可以用少量的线程处理大量的链接。
I/O多路复用就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。
多路复用I/O的实现
select, poll, epoll 都是I/O多路复用的具体的实现,在现在的Linux内核里有都能够支持
1. select
select 函数监视的文件描述符分3类,分别是writefds、readfds、和exceptfds。调用后select函数会阻塞,直到有描述符就绪(有数据 可读、可写、或者有except),或者超时(timeout指定等待时间,如果立即返回设为null即可),函数返回。
select目前几乎在所有的平台上支持,其良好跨平台支持也是它的一个优点。
select本质上是通过设置或者检查存放fd标志位的数据结构来进行下一步处理。这样所带来的缺点是:
1、select最大的缺陷就是单个进程所打开的FD是有一定限制的,它由FD_SETSIZE设置,默认值是1024。
2、对socket进行扫描时是线性扫描,即采用轮询的方法,效率较低。
3、需要维护一个用来存放大量fd的数据结构,这样会使得用户空间和内核空间在传递该结构时复制开销大。
2. poll
基本原理:poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态,如果设备就绪则在设备等待队列中加入一项并继续遍历,如果遍历完所有fd后没有发现就绪设备,则挂起当前进程,直到设备就绪或者主动超时,被唤醒后它又要再次遍历fd。这个过程经历了多次无谓的遍历。
它没有最大连接数的限制,原因是它是基于链表来存储的,但是同样有一个缺点:
1)大量的fd的数组被整体复制于用户态和内核地址空间之间,而不管这样的复制是不是有意义。
2)poll还有一个特点是“水平触发”,如果报告了fd后,没有被处理,那么下次poll时会再次报告该fd。
注意:从上面看,select和poll都需要在返回后,通过遍历文件描述符来获取已经就绪的socket。事实上,同时连接的大量客户端在一时刻可能只有很少的处于就绪状态,因此随着监视的描述符数量的增长,其效率也会线性下降。
3. epoll
epoll是在2.6内核中提出的,是之前的select和poll的增强版本。相对于select和poll来说,epoll更加灵活,没有描述符限制。epoll使用一个文件描述符管理多个描述符,将用户关系的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需一次。
基本原理:epoll支持水平触发和边缘触发,最大的特点在于边缘触发,它只告诉进程哪些fd刚刚变为就绪态,并且只会通知一次。还有一个特点是,epoll使用“事件”的就绪通知方式,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd,epoll_wait便可以收到通知。
epoll的优点:
1、没有最大并发连接的限制,能打开的FD的上限远大于1024(1G的内存上能监听约10万个端口)。
2、效率提升,不是轮询的方式,不会随着FD数目的增加效率下降。
只有活跃可用的FD才会调用callback函数;即Epoll最大的优点就在于它只管你“活跃”的连接,而跟连接总数无关,因此在实际的网络环境中,Epoll的效率就会远远高于select和poll。
- 内存拷贝,利用mmap()文件映射内存加速与内核空间的消息传递;即epoll使用mmap减少复制开销。
在选择select,poll,epoll时要根据具体的使用场合以及这三种方式的自身特点:
1、表面上看epoll的性能最好,但是在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。
2、select低效是因为每次它都需要轮询。但低效也是相对的,视情况而定,也可通过良好的设计改善。
redis事件模型
Redis并没有使用libevent,libev,libuv等事件IO库,而是通过ae.h、ae.c两个文件,封装了简单的事件处理模型。进一步地,事件处理需要使用到系统的select、epoll等函数
Redis的事件模型实现依托 I/O多路复用技术epoll支撑起来的
利用 I/O 多路复用技术,监听感兴趣的文件 I/O 事件,例如读事件,写事件等,同时也要维护一个以文件描述符为主键,数据为某个预设函数的事件表,这里其实就是一个数组或者链表。当事件触发时,比如某个文件描述符可读,系统会返回文件描述符值,用这个值在事件表中找到相应的数据项(Handler),从而实现回调。同样的,定时事件也是可以实现的,因为系统提供的 I/O 多路复用技术中的函数允许我们设定时间值。
libevent统一了三种事件的处理,IO事件、时间事件和信号事件,并且每个事件可以注册多个回调函数,事件之间具有优先级关系(通过将就绪链表依据优先级设定为多条实现)。而Redis仅仅统一了IO事件和时间事件,且一个事件fd只能注册一个回调函数,并且IO事件之间不具备优先级,按照epoll返回顺序依次执行。因此Redis的封装更加简单明了。
epoll 模型
redis 是cs架构,网络采用epoll 模型,单线程处理每个请求。
Redis的事件模型实现基于linux的epoll
Redis与Memcached是区别
1.Memcached是多线程,而Redis使用单线程.
2.Memcached使用预分配的内存池的方式,Redis使用现场申请内存的方式来存储数据,并且可以配置虚拟内存。
3.Redis可以实现持久化,主从复制,实现故障恢复。Memcache 本身不能支持主从复制(数据同步),只能靠外部工具实现
4.Memcached只是简单的key与value,但是Redis支持数据类型比较多。
5.memcached的key最大250个字符值默认最大为1M;redis的key和value限制均为512MB。
6.使用简单的key-value存储的话,Memcached的内存利用率更高,而如果Redis采用hash结构来做key-value存储,由于其组合式的压缩,其内存利用率会高于Memcached。
7.Memcached本身并不支持分布式,因此只能在客户端通过像一致性哈希这样的分布式算法来实现Memcached的分布式存储。当客户端向Memcached集群发送数据之前,首先会通过内置的分布式算法计算出该条数据的目标节点,然后数据会直接发送到该节点上存储。但客户端查询数据时,同样要计算出查询数据所在的节点,然后直接向该节点发送查询请求以获取数据。
相较于Memcached只能采用客户端实现分布式存储,Redis更偏向于在服务器端构建分布式存储,但没有采用一致性哈希。最新版本的Redis已经支持了分布式存储功能。Redis Cluster是一个实现了分布式且允许单点故障的Redis高级版本,它没有中心节点,具有线性可伸缩的功能。为了保证单点故障下的数据可用性,Redis Cluster引入了Master节点和Slave节点。在Redis Cluster中,每个Master节点都会有对应的两个用于冗余的Slave节点。这样在整个集群中,任意两个节点的宕机都不会导致数据的不可用。当Master节点退出后,集群会自动选择一个Slave节点成为新的Master节
应用场景:
Memcached:动态系统中减轻数据库负载,提升性能;做缓存,适合多读少写,大数据量的情况(如人人网大量查询用户信息、好友信息、文章信息等)。
Redis:适用于对读写效率要求都很高,数据处理业务复杂和对安全性要求较高的系统
redis单线程
选用单线程的原因:
因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了
单线程指的是网络请求模块使用了一个线程(所以不需考虑并发安全性),即一个线程处理所有网络请求,其他模块仍用了多个线程。
每个请求被缓存在一个线程中,一个时间只能有一个线程在处理请求。
Redis采用了线程封闭的方式,把任务封闭在一个线程
由于在单线程模式的情况下已经很快了,就没有必要在使用多线程了!
线程封闭
是把对象封装到一个线程里,只有一个线程能看到这个对象,那么这个对象就算不是线程安全的,也不会出现任何线程安全方面的问题。
它是实现线程安全最简单的方式之一。
线程封闭技术一个常见的应用就是JDBC的Connection对象
|
数据库连接对应jdbc的Connection对象,Connection对象在实现的时候并没有对线程安全做太多的处理,jdbc的规范里也没有要求Connection对象必须是线程安全的。 实际在服务器应用程序中,线程从连接池获取了一个Connection对象,使用完再把Connection对象返回给连接池,由于大多数请求都是由单线程采用同步的方式来处理的,并且在Connection对象返回之前,连接池不会将它分配给其他线程。因此这种连接管理模式处理请求时隐含的将Connection对象封闭在线程里面,这样我们使用的connection对象虽然本身不是线程安全的,但是它通过线程封闭也做到了线程安全。 |
线程封闭的种类:
(1)Ad-hoc 线程封闭:
Ad-hoc线程封闭是指,维护线程封闭性的职责完全由程序实现来承担。Ad-hoc线程封闭是非常脆弱的,因为没有任何一种语言特性,例如可见性修饰符或局部变量,能将对象封闭到目标线程上。事实上,对线程封闭对象(例如,GUI应用程序中的可视化组件或数据模型等)的引用通常保存在公有变量中。
(2)堆栈封闭:
堆栈封闭其实就是方法中定义局部变量。不存在并发问题。多个线程访问一个方法的时候,方法中的局部变量都会被拷贝一份到线程的栈中(Java内存模型),所以局部变量是不会被多个线程所共享的。
(3)ThreadLocal线程封闭:
它是一个特别好的封闭方法,其实ThreadLocal内部维护了一个map,map的key是每个线程的名称,而map的value就是我们要封闭的对象。ThreadLocal提供了get、set、remove方法,每个操作都是基于当前线程的,所以它是线程安全的。
多线程的缺点
多线程处理可能涉及到锁
多线程处理会涉及到线程切换而消耗CPU
单线程的缺点
无法发挥多核CPU性能,不过可以通过在单机开多个Redis实例来完善
redis线程安全
Redis本身是单线程线程安全的内存数据库
Redis采用了线程封闭的方式,把任务封闭在一个线程,自然避免了线程安全问题
不过对于需要依赖多个redis操作的复合操作来说,依然需要锁,而且有可能是分布式锁
redis的线程安全结合你自身的业务也是线程安全,才能做到真正的线程安全,如果你的业务在非线程安全的环境下使用redis照样无法做到真正的线程安全
redis的key
redis本质上一个key-value db,所以我们首先来看看他的key.首先key也是字符串类型,但是key中不能包括边界字符
由于key不是binary safe的字符串,所以像"my key"和"mykey\n"这样包含空格和换行的key是不允许的
顺便说一下在redis内部并不限制使用binary字符,这是redis协议限制的。"\r\n"在协议格式中会作为特殊字符。
redis 1.2以后的协议中部分命令已经开始使用新的协议格式了(比如MSET)。总之目前还是把包含边界字符当成非法的key吧,免得被bug纠缠。
另外关于key的一个格式约定介绍下,object-type:id:field。比如user:1000:password,blog:xxidxx:title
还有key的长度最好不要太长。道理很明显占内存啊,而且查找时候相对短key也更慢。不过也推荐过短的key,
比如u:1000:pwd,这样的。显然没上面的user:1000:password可读性好。
redis部署方案
standaloan(单机模式)
standaloan 是redis单机模式,即所有服务连接一台redis服务,该模式不适用生产。如果发生宕机,内存爆炸,就可能导致所有连接改redis的服务发生缓存失效引起雪崩。
缺点:
1、内存容量有限
2、处理能力有限
3、无法高可用
主从复制
redis2.8版本之前的模式
主从复制有如下特点:
主数据库可以进行读写操作,当读写操作导致数据变化时会自动将数据同步给从数据库
从数据库一般都是只读的,并且接收主数据库同步过来的数据
一个master可以拥有多个slave,但是一个slave只能对应一个master
从服务器也可以有自己的从服务器
复制功能不会阻塞主服务器: 即使有一个或多个从服务器正在进行初次同步, 主服务器也可以继续处理命令请求。
可以通过复制功能来让主服务器免于执行持久化操作,由从服务器去执行持久化操作即可。
复制功能也不会阻塞从服务器: 只要在 redis.conf 文件中进行了相应的设置, 即使从服务器正在进行初次同步, 服务器也可以使用旧版本的数据集来处理命令查询。
- 不过, 在从服务器删除旧版本数据集并载入新版本数据集的那段时间内, 连接请求会被阻塞。
复制功能可以单纯地用于数据冗余(data redundancy), 也可以通过让多个从服务器处理只读命令请求来提升扩展性(scalability)
增量复制子流程:如果全量复制过程中,master-slave网络连接断掉,salve重新连接master时,会触发增量复制;master直接从自己的backlog中获取部分丢失的数据,发送给slave node,默认backlog就是1MB;msater就是根据slave发送的psync中的offset来从backlog中获取数据的
断点续传
从redis 2.8开始,就支持主从复制的断点续传,如果主从复制过程中,网络连接断掉了,那么可以接着上次复制的地方,继续复制下去,而不是从头开始复制一份
master node会在内存中常见一个backlog,master和slave都会保存一个replica offset还有一个master id,offset就是保存在backlog中的。如果master和slave网络连接断掉了,slave会让master从上次的replica offset开始继续复制;如果没有找到对应的offset,那么就会执行一次full resynchronization。
优点:
1、解决数据备份问题
2、做到读写分离,提高服务器性能
缺点:
- 无法高可用,进行故障转移
- 不能解决master写的压力
- 无法实现动态扩容
主从复制工作机制
当slave启动后,主动向master发送SYNC命令。master接收到SYNC命令后在后台保存快照(RDB持久化)和缓存保存快照这段时间的命令,然后将保存的快照文件和缓存的命令发送给slave。slave接收到快照文件和命令后加载快照文件和缓存的执行命令。
复制初始化后,master每次接收到的写命令都会同步发送给slave,保证主从数据一致性。
注:Sync 命令用于同步主从服务器,synchronize的缩写
主从配置
redis默认是主数据,所以master无需配置,我们只需要修改slave的配置即可。
设置需要连接的master的ip端口:
slaveof 192.168.0.107 6379
如果master设置了密码。需要配置:
masterauth
ssentinel(哨兵模式)
redis2.8及之后的模式
redis-Sentinel(哨兵模式)是Redis官方推荐的高可用性(HA)解决方案,当用Redis做Master-slave的高可用方案时,假如master宕机了,Redis本身(包括它的很多客户端)都没有实现自动进行主备切换,而Redis-sentinel本身也是一个独立运行的进程,它能监控多个master-slave集群,发现master宕机后能进行切换
通过一个或多个Sentinel 实例组成的Sentinel 系统可以监视多个主服务器和下属的所有从服务器,当主服务器进入下线状态时,自动将主服务器下的从服务器升级为新的主服务器。
哨兵模式的功能:
监控主从:监控主从数据库是否正常运行
故障转移:master出现故障时,自动将slave转化为master
监控哨兵:多哨兵配置的时候,哨兵之间也会自动监控
注:
多个哨兵可以监控同一个redis
故障转移的概念:即当活动的服务或应用意外终止时,快速启用冗余或备用的服务器、系统、硬件或者网络接替它们工作。
优点:
- 能够自动进行故障转移
- 能够监控各个节点
缺点:
- 主从模式,切换需要时间丢数据
- 没有解决master写的压力
- 无法实现动态扩容
哨兵工作机制:
哨兵进程启动时会读取配置文件的内容,通过sentinel monitor master-name ip port quorum查找到master的ip端口。一个哨兵可以监控多个master数据库,只需要提供多个该配置项即可。
同事配置文件还定义了与监控相关的参数,比如master多长时间无响应即即判定位为下线。
哨兵启动后,会与要监控的master建立俩条连接:
一条连接用来订阅master的_sentinel_:hello频道与获取其他监控该master的哨兵节点信息
另一条连接定期向master发送INFO等命令获取master本身的信息
与master建立连接后,哨兵会执行三个操作,这三个操作的发送频率都可以在配置文件中配置:
定期向master和slave发送INFO命令
定期向master个slave的_sentinel_:hello频道发送自己的信息
定期向master、slave和其他哨兵发送PING命令
这三个操作的意义非常重大,发送INFO命令可以获取当前数据库的相关信息从而实现新节点的自动发现。所以说哨兵只需要配置master数据库信息就可以自动发现其slave信息。获取到slave信息后,哨兵也会与slave建立俩条连接执行监控。通过INFO命令,哨兵可以获取主从数据库的最新信息,并进行相应的操作,比如角色变更等。
接下来哨兵向主从数据库的_sentinel_:hello频道发送信息与同样监控这些数据库的哨兵共享自己的信息,发送内容为哨兵的ip端口、运行id、配置版本、master名字、master的ip端口还有master的配置版本。这些信息有以下用处:
其他哨兵可以通过该信息判断发送者是否是新发现的哨兵,如果是的话会创建一个到该哨兵的连接用于发送PIN命令。
其他哨兵通过该信息可以判断master的版本,如果该版本高于直接记录的版本,将会更新
当实现了自动发现slave和其他哨兵节点后,哨兵就可以通过定期发送PING命令定时监控这些数据库和节点有没有停止服务。发送频率可以配置,但是最长间隔时间为1s,可以通过sentinel down-after-milliseconds mymaster 600设置。
如果被ping的数据库或者节点超时未回复,哨兵任务其主观下线。如果下线的是master,哨兵会向其他哨兵点发送命令询问他们是否也认为该master主观下线,如果达到一定数目(即配置文件中的quorum)投票,哨兵会认为该master已经客观下线,并选举领头的哨兵节点对主从系统发起故障恢复。
如上文所说,哨兵认为master客观下线后,故障恢复的操作需要由选举的领头哨兵执行,选举采用Raft算法:
发现master下线的哨兵节点(我们称他为A)向每个哨兵发送命令,要求对方选自己为领头哨兵
如果目标哨兵节点没有选过其他人,则会同意选举A为领头哨兵
如果有超过一半的哨兵同意选举A为领头,则A当选
如果有多个哨兵节点同时参选领头,此时有可能存在一轮投票无竞选者胜出,此时每个参选的节点等待一个随机时间后再次发起参选请求,进行下一轮投票精选,直至选举出领头哨兵
选出领头哨兵后,领头者开始对进行故障恢复,从出现故障的master的从数据库中挑选一个来当选新的master,选择规则如下:
所有在线的slave中选择优先级最高的,优先级可以通过slave-priority配置
如果有多个最高优先级的slave,则选取复制偏移量最大(即复制越完整)的当选
如果以上条件都一样,选取id最小的slave
挑选出需要继任的slaver后,领头哨兵向该数据库发送命令使其升格为master,然后再向其他slave发送命令接受新的master,最后更新数据。将已经停止的旧的master更新为新的master的从数据库,使其恢复服务后以slave的身份继续运行。
哨兵配置
哨兵配置的配置文件为sentinel.conf,设置主机名称,地址,端口,以及选举票数即恢复时最少需要几个哨兵节点同意。
sentinel monitor mymaster 192.168.0.107 6379 1
只要配置需要监控的master就可以了,哨兵会监控连接该master的slave。
启动哨兵节点:
redis-server sentinel.conf --sentinel &
可以在任何一台服务器上查看指定哨兵节点信息:
bin/redis-cli -h 192.168.0.110 -p 26379 info Sentinel
redis-cluster(集群模式)
redis3.0版本之后
Redis3.0推出cluster分布式集群方案,同样可以实现redis高可用部署,
cluster方案主要解决分片问题,即把整个数据按照规则分成多个子集存储在多个不同节点上,每个节点负责自己整个数据的一部分。
一般集群建议搭建三主三从架构,三主提供服务,三从提供备份功能。每个集群中至少需要三个主数据库才能正常运行
Redis Cluster采用哈希分区规则中的虚拟槽分区。虚拟槽分区巧妙地使用了哈希空间,使用分散度良好的哈希函数把所有的数据映射到一个固定范围内的整数集合,整数定义为槽(slot)。Redis Cluster槽的范围是0 ~ 16383。槽是集群内数据管理和迁移的基本单位。采用大范围的槽的主要目的是为了方便数据的拆分和集群的扩展,每个节点负责一定数量的槽。Redis Cluster采用虚拟槽分区,所有的键根据哈希函数映射到0 ~ 16383,计算公式:slot = CRC16(key)&16384。每一个实节点负责维护一部分槽以及槽所映射的键值数据。
每个key通过CRC16校验后对16384取模来
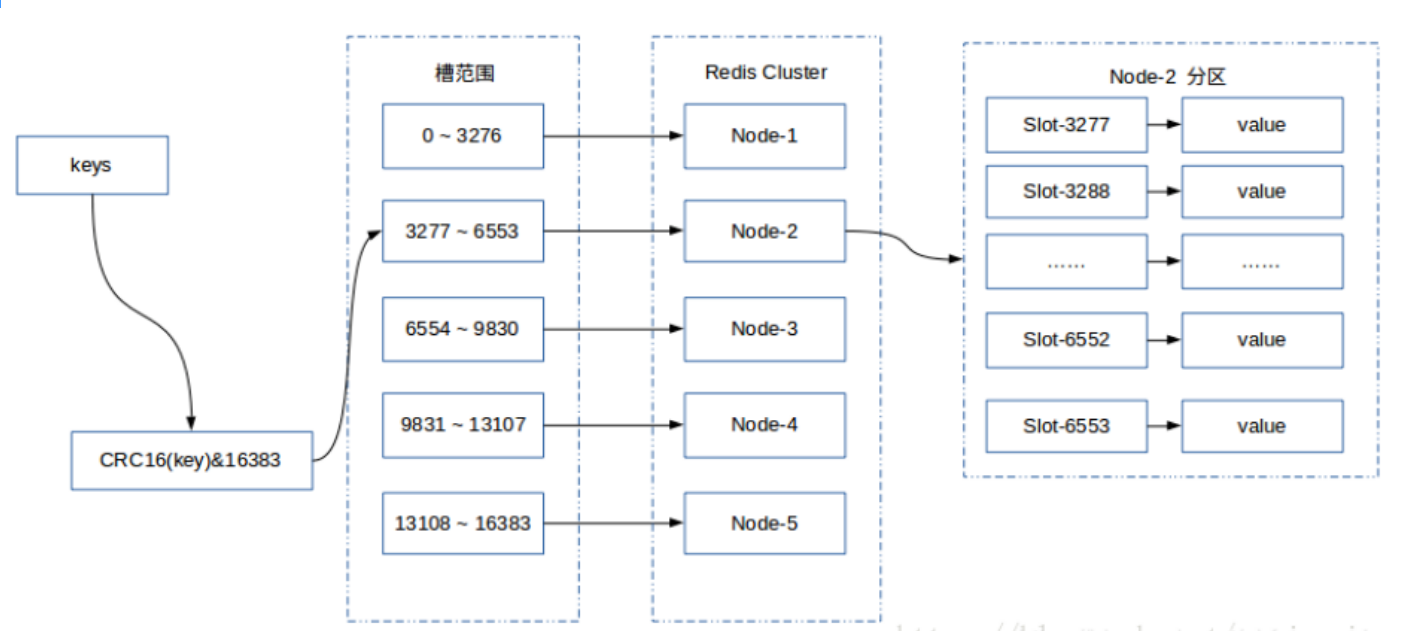
它们之间通过互相的ping-pong判断是否节点可以连接上。如果有一半以上的主节点去ping一个主节点的时候没有回应,集群就认为这个节点宕机了,然后去连接它的备用节点。如果某个节点和所有从节点全部挂掉,我们集群就进入fail状态。还有就是如果有一半以上的主节点宕机,那么我们集群同样进入fail状态。这就是我们的redis的投票机制
fail状态就是不可用状态,当集群不可用时,所有对集群的操作做都不可用,收到((error) CLUSTERDOWN The cluster is down)错误
特点:
每一个节点都存有这个集群所有主节点以及从节点的信息。
优点:
- 可实现动态扩容
- 自动故障转移
- 负载均衡
缺点:
引用场景:
数据量比较大
Redis的安装
redis是C语言开发,建议在linux上运行,本教程使用Centos6.4作为安装环境。
安装redis需要先将官网下载的源码进行编译,编译依赖gcc环境,如果没有gcc环境,需要安装gcc:yum install gcc-c++
redis官网只提供linux系统的安装程序
window的只提供到了2016年,版本是3.2
window的下载网址:https://github.com/MicrosoftArchive/redis/releases
源码下载
从官网下载
http://download.redis.io/releases/redis-3.0.0.tar.gz
将redis-3.0.0.tar.gz拷贝到/usr/local下
- 解压源码
tar -zxvf redis-3.0.0.tar.gz
- 进入解压后的目录进行编译
cd /usr/local/redis-3.0.0
make
- 安装到指定目录,如 /usr/local/redis
cd /usr/local/redis-3.0.0
make PREFIX=/usr/local/redis install
- conf
redis.conf是redis的配置文件,redis.conf在redis源码目录。
注意修改port作为redis进程的端口,port默认6379。
配置redis.conf配置文件:
#是否作为守护进程运行
daemonize yes
#配置pid的存放路径及文件名,默认为当前路径下
pidfile redis.pid #Redis默认监听端口 port 6379
#客户端闲置多少秒后,断开连接
timeout 300
#日志显示级别
loglevel verbose
#指定日志输出的文件名,也可指定到标准输出端口
logfile stdout
#设置数据库的数量,默认连接的数据库是0,可以通过select N来连接不同的数据库
databases 16
#保存数据到disk的策略
#当有一条Keys数据被改变是,900秒刷新到disk一次
save 900 1
#当有10条Keys数据被改变时,300秒刷新到disk一次
save 300 10
#当有1w条keys数据被改变时,60秒刷新到disk一次
save 60 10000
#当dump .rdb数据库的时候是否压缩数据对象
rdbcompression yes
#dump数据库的数据保存的文件名
dbfilename dump.rdb
#Redis的工作目录
dir /home/falcon/redis-2.0.0/
########### Replication #####################
#Redis的复制配置
# slaveof <masterip> <masterport>
# masterauth <master-password>
############## SECURITY ###########
# requirepass foobared
############### LIMITS ##############
#最大客户端连接数
# maxclients 128
#最大内存使用率
# maxmemory <bytes>
########## APPEND ONLY MODE #########
#是否开启日志功能
appendonly no
# 刷新日志到disk的规则
# appendfsync always
appendfsync everysec
# appendfsync no
################ VIRTUAL MEMORY ###########
#是否开启VM功能
vm-enabled no
# vm-enabled yes
vm-swap-file logs/redis.swap
vm-max-memory 0
vm-page-size 32
vm-pages 134217728
vm-max-threads 4
############# ADVANCED CONFIG ###############
glueoutputbuf yes
hash-max-zipmap-entries 64
hash-max-zipmap-value 512
#是否重置Hash表
activerehashing yes
- 拷贝配置文件到安装目录下
进入源码目录,里面有一份配置文件 redis.conf,然后将其拷贝到安装路径下
cd /usr/local/redis
mkdir conf
cp /usr/local/redis-3.0.0/redis.conf /usr/local/redis/bin
- 安装目录bin下的文件列表


redis3.0新增的redis-sentinel是redis集群管理工具可实现高可用。
配置文件目录:

redis启动
前端模式启动
直接运行bin/redis-server将以前端模式启动,/usr/local/redis/bin/redis-server
前端模式启动的缺点是ssh命令窗口关闭则redis-server程序结束,不推荐使用此方法。如下图:
后端模式启动
- 从redis的源码目录中复制conf到redis的安装目录。
- 修改配置文件
- [root@bogon bin]# ./redis-server redis.conf
还可以带几项配置进行启动
# 带配置文件启动 且指定某几个配置 配置名称前加--
redis-server ./redis.conf --daemonize yes --port 1123
它会覆盖配置文件里面的值
window下的启动
redis-server.exe redis.windows.conf
检测Redis是否启动:
netstat -an -t 看对应的端口是否被监听,
ps -ef|grep redis-server 以redis-server为组全格式显示所有进程。看是否有记录
redsi关闭和重启
如果是用apt-get或者yum install安装的redis,可以直接通过下面的命令停止/启动/重启redis
/etc/init.d/redis-server stop
/etc/init.d/redis-server start
/etc/init.d/redis-server restart
如果是通过源码安装的redis,则可以通过redis的客户端程序redis-cli的shutdown命令来重启redis
redis-cli -h 127.0.0.1 -p 6379 shutdown
如果上述方式都没有成功停止redis,则可以使用终极武器 kill -9
redis命令行操作
redis-cli -h host -p port -a password
开启redis服务以后打开客户端:./redis-cli
这时会出现redis 127.0.0.1:6379>
这就说明可以在这里写命令了
查看服务器状态
info
|
# Server redis_version:2.8.19 redis_git_sha1:00000000 redis_git_dirty:0 redis_build_id:3f2362f2daae1822 redis_mode:standalone os:Linux 2.6.32-431.el6.x86_64 x86_64 arch_bits:64 multiplexing_api:epoll gcc_version:4.4.7 process_id:1086 run_id:790d984b5c2aa3eee0665f8a9762dc387c27209e tcp_port:6380 uptime_in_seconds:2859565 uptime_in_days:33 hz:10 lru_clock:11535764 config_file:/etc/redis/6380.conf
# Clients connected_clients:36 client_longest_output_list:0 client_biggest_input_buf:0 blocked_clients:1
# Memory used_memory:2275944 used_memory_human:2.17M used_memory_rss:8032256 used_memory_peak:29431600 used_memory_peak_human:28.07M used_memory_lua:61440 mem_fragmentation_ratio:3.53 mem_allocator:libc
# Persistence loading:0 rdb_changes_since_last_save:0 rdb_bgsave_in_progress:0 rdb_last_save_time:1571813955 rdb_last_bgsave_status:ok rdb_last_bgsave_time_sec:0 rdb_current_bgsave_time_sec:-1 aof_enabled:1 aof_rewrite_in_progress:0 aof_rewrite_scheduled:0 aof_last_rewrite_time_sec:-1 aof_current_rewrite_time_sec:-1 aof_last_bgrewrite_status:ok aof_last_write_status:ok aof_current_size:96452061 aof_base_size:59497619 aof_pending_rewrite:0 aof_buffer_length:0 aof_rewrite_buffer_length:0 aof_pending_bio_fsync:0 aof_delayed_fsync:0
# Stats total_connections_received:57738 total_commands_processed:321457 instantaneous_ops_per_sec:0 total_net_input_bytes:39537004 total_net_output_bytes:12411290 instantaneous_input_kbps:0.00 instantaneous_output_kbps:0.00 rejected_connections:0 sync_full:0 sync_partial_ok:0 sync_partial_err:0 expired_keys:5 evicted_keys:0 keyspace_hits:37090 keyspace_misses:33737 pubsub_channels:1 pubsub_patterns:0 latest_fork_usec:552
# Replication role:master connected_slaves:0 master_repl_offset:0 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0
# CPU used_cpu_sys:2389.70 used_cpu_user:887.23 used_cpu_sys_children:1.01 used_cpu_user_children:1.48
# Keyspace db0:keys=3293,expires=0,avg_ttl=0 |
Server:
|
redis_version |
Redis 服务器版本 |
|
redis_git_sha1 |
Git SHA1 |
|
redis_git_dirty |
Git dirty flag |
|
redis_build_id |
Git dirty flag |
|
redis_mode |
运行模式,单机或者集群 |
|
os |
服务器的宿主操作系统 |
|
arch_bits |
架构(32 或 64 位) |
|
multiplexing_api |
Redis 所使用的事件处理机制 |
|
atomicvar_api |
原子处理api |
|
gcc_version |
编译 Redis 时所使用的 GCC 版本 |
|
process_id |
服务器进程的 PID |
|
run_id |
Redis 服务器的随机标识符(用于 Sentinel 和集群) |
|
tcp_port |
TCP/IP 监听端口 |
|
uptime_in_seconds |
自 Redis 服务器启动以来,经过的秒数 |
|
uptime_in_days |
自 Redis 服务器启动以来,经过的天数 |
|
hz |
edis内部调度(进行关闭timeout的客户端,删除过期key等等)频率,程序规定serverCron每秒运行10次。 |
|
lru_clock |
自增的时钟,用于LRU管理,该时钟100ms(hz=10,因此每1000ms/10=100ms执行一次定时任务)更新一次。 |
|
executable |
执行文件 |
|
config_file |
配置文件路径 |
Clients:
|
connected_clients |
已连接客户端的数量(不包括通过从属服务器连接的客户端) |
|
client_longest_output_list |
当前连接的客户端当中,最长的输出列表 |
|
client_biggest_input_buf |
当前连接的客户端当中,最大输入缓存 |
|
blocked_clients |
正在等待阻塞命令(BLPOP、BRPOP、BRPOPLPUSH)的客户端的数量 |
Memory
|
used_memory |
由 Redis 分配器分配的内存总量,以字节(byte)为单位 |
|
used_memory_human |
以人类可读的格式返回 Redis 分配的内存总量 |
|
used_memory_rss |
从操作系统的角度,返回 Redis 已分配的内存总量(俗称常驻集大小)。这个值和 top 、 ps等命令的输出一致。 |
|
used_memory_rss_human |
以人类可读的格式,从操作系统的角度,返回 Redis 已分配的内存总量(俗称常驻集大小)。这个值和 top 、 ps等命令的输出一致。 |
|
used_memory_peak |
redis的内存消耗峰值(以字节为单位) |
|
used_memory_peak_human |
以人类可读的格式返回redis的内存消耗峰值 |
|
used_memory_peak_perc |
(used_memory/ used_memory_peak) *100% |
|
used_memory_overhead |
Redis为了维护数据集的内部机制所需的内存开销,包括所有客户端输出缓冲区、查询缓冲区、AOF重写缓冲区和主从复制的backlog。 |
|
used_memory_startup |
Redis服务器启动时消耗的内存 |
|
used_memory_dataset |
used_memory—used_memory_overhead |
|
used_memory_dataset_perc |
100%*(used_memory_dataset/(used_memory—used_memory_startup)) |
|
total_system_memory |
整个系统内存 |
|
total_system_memory_human |
以人类可读的格式,显示整个系统内存 |
|
used_memory_lua |
Lua脚本存储占用的内存 |
|
used_memory_lua_human |
以人类可读的格式,显示Lua脚本存储占用的内存 |
|
maxmemory |
Redis实例的最大内存配置 |
|
maxmemory_human |
以人类可读的格式,显示Redis实例的最大内存配置 |
|
maxmemory_policy |
当达到maxmemory时的淘汰策略 |
|
mem_fragmentation_ratio |
used_memory_rss/ used_memory |
|
mem_allocator |
内存分配器 |
|
active_defrag_running |
表示没有活动的defrag任务正在运行,1表示有活动的defrag任务正在运行(defrag:表示内存碎片整理) |
|
lazyfree_pending_objects |
0表示不存在延迟释放(也有资料翻译未惰性删除)的挂起对象 |
Persistence
|
loading |
服务器是否正在载入持久化文件 |
|
rdb_changes_since_last_save |
离最近一次成功生成rdb文件,写入命令的个数,即有多少个写入命令没有持久化 |
|
rdb_bgsave_in_progress |
服务器是否正在创建rdb文件 |
|
rdb_last_save_time |
离最近一次成功创建rdb文件的时间戳。当前时间戳 - rdb_last_save_time=多少秒未成功生成rdb文件 |
|
rdb_last_bgsave_status |
最近一次rdb持久化是否成功 |
|
rdb_last_bgsave_time_sec |
最近一次成功生成rdb文件耗时秒数 |
|
rdb_current_bgsave_time_sec |
如果服务器正在创建rdb文件,那么这个域记录的就是当前的创建操作已经耗费的秒数 |
|
rdb_last_cow_size |
RDB过程中父进程与子进程相比执行了多少修改(包括读缓冲区,写缓冲区,数据修改等)。 |
|
aof_enabled |
是否开启了aof |
|
aof_rewrite_in_progress |
标识aof的rewrite操作是否在进行中 |
|
aof_rewrite_scheduled |
rewrite任务计划,当客户端发送bgrewriteaof指令,如果当前rewrite子进程正在执行,那么将客户端请求的bgrewriteaof变为计划任务,待aof子进程结束后执行rewrite |
|
aof_last_rewrite_time_sec |
最近一次aof rewrite耗费的时长 |
|
aof_current_rewrite_time_sec |
如果rewrite操作正在进行,则记录所使用的时间,单位秒 |
|
aof_last_bgrewrite_status |
上次bgrewriteaof操作的状态 |
|
aof_last_write_status |
上次aof写入状态 |
|
aof_last_cow_size |
AOF过程中父进程与子进程相比执行了多少修改(包括读缓冲区,写缓冲区,数据修改等)。 |
Stats
|
total_connections_received |
新创建连接个数,如果新创建连接过多,过度地创建和销毁连接对性能有影响,说明短连接严重或连接池使用有问题,需调研代码的连接设置 |
|
total_commands_processed |
redis处理的命令数 |
|
instantaneous_ops_per_sec |
redis当前的qps,redis内部较实时的每秒执行的命令数 |
|
total_net_input_bytes |
redis网络入口流量字节数 |
|
total_net_output_bytes |
redis网络出口流量字节数 |
|
instantaneous_input_kbps |
redis网络入口kps |
|
instantaneous_output_kbps |
redis网络出口kps |
|
rejected_connections |
拒绝的连接个数,redis连接个数达到maxclients限制,拒绝新连接的个数 |
|
sync_full |
主从完全同步成功次数 |
|
sync_partial_ok |
主从部分同步成功次数 |
|
sync_partial_err |
主从部分同步失败次数 |
|
expired_keys |
运行以来过期的key的数量 |
|
expired_stale_perc |
过期的比率 |
|
expired_time_cap_reached_count |
过期计数 |
|
evicted_keys |
运行以来剔除(超过了maxmemory后)的key的数量 |
|
keyspace_hits |
命中次数 |
|
keyspace_misses |
没命中次数 |
|
pubsub_channels |
当前使用中的频道数量 |
|
pubsub_patterns |
当前使用的模式的数量 |
|
latest_fork_usec |
最近一次fork操作阻塞redis进程的耗时数,单位微秒 |
|
migrate_cached_sockets |
是否已经缓存了到该地址的连接 |
|
slave_expires_tracked_keys |
从实例到期key数量 |
|
active_defrag_hits |
主动碎片整理命中次数 |
|
active_defrag_misses |
主动碎片整理未命中次数 |
|
active_defrag_key_hits |
主动碎片整理key命中次数 |
|
active_defrag_key_misses |
主动碎片整理key未命中次数 |
Replication
|
role |
实例的角色,是master or slave |
|
connected_slaves |
连接的slave实例个数 |
|
master_replid |
主实例启动随机字符串 |
|
master_replid2 |
主实例启动随机字符串2 |
|
master_repl_offset |
主从同步偏移量,此值如果和上面的offset相同说明主从一致没延迟,与master_replid可被用来标识主实例复制流中的位置。 |
|
second_repl_offset |
主从同步偏移量2,此值如果和上面的offset相同说明主从一致没延迟 |
|
repl_backlog_active |
复制积压缓冲区是否开启 |
|
repl_backlog_size |
复制积压缓冲大小 |
|
repl_backlog_first_byte_offset |
复制缓冲区里偏移量的大小 |
|
repl_backlog_histlen |
此值等于 master_repl_offset - repl_backlog_first_byte_offset,该值不会超过repl_backlog_size的大小 |
CPU
|
used_cpu_sys |
将所有redis主进程在核心态所占用的CPU时求和累计起来 |
|
used_cpu_user |
将所有redis主进程在用户态所占用的CPU时求和累计起来 |
|
used_cpu_sys_children |
将后台进程在核心态所占用的CPU时求和累计起来 |
|
used_cpu_user_children |
将后台进程在用户态所占用的CPU时求和累计起来 |
Commandstats 命令使用统计快照
|
cmdstat_set |
Set 命令统计 |
|
cmdstat_ping |
Ping 命令统计 |
|
cmdstat_del |
Del命令统计 |
|
cmdstat_psync |
Psync命令统计 |
|
cmdstat_keys |
Keys命令统计 |
|
cmdstat_hmset |
Hmset命令统计 |
|
cmdstat_command |
Command命令统计 |
|
cmdstat_info |
Info命令统计 |
|
cmdstat_replconf |
Replconf命令统计 |
|
cmdstat_client |
Client命令统计 |
|
cmdstat_hgetall |
Hgetall命令统计 |
Cluster
|
cluster_enabled |
实例是否启用集群模式 |
Keyspace
|
db0 |
db0的key的数量,以及带有生存期的key的数,平均存活时间 |
Redis命令分为1.键值相关命令2.服务相关命令。
键值相关命令
keys:返回给定条件的所有key
*代表所有
keys my* 将取出所有已my打头的key
增删改查:
randomkey
随机返回一个key
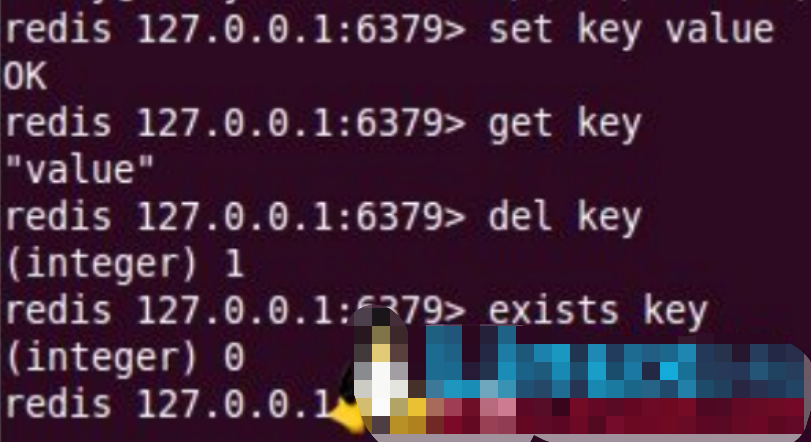
exists mykey
当前的key是否存在
rename mykey mykey2
重命名mykey为mykey2
type
返回值的数据类型
type testlist
list
del mykey
删除当前key
expire
设置过期时间
expire mykey 10
ttl
当 key 不存在时(过期了也是不存在了),返回 -2 。 当 key 存在但没有设置剩余生存时间时,返回 -1 。 否则,以毫秒为单位,返回 key 的剩余生存时间。
注意:在 Redis 2.8 以前,当 key 不存在,或者 key 没有设置剩余生存时间时,命令都返回 -1 。
ttl mykey
persist mykey
移除当前key的过期时间
select 0
选择进入0数据库,进入客户端默认进入0数据库
move mykey 1
将当前数据库中的mykey键值对移动到数据库1中
服务相关命令
客户端连接
src/redis-cli
停止redis服务:
src/redis-cli shutdown
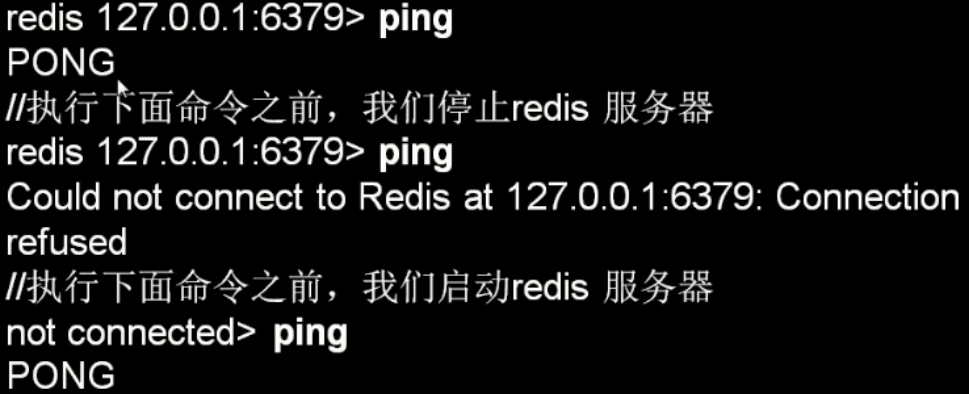
测试连接是否存活
ping
PONG
打印
echo test
"test"
select 15
OK
数据库切换,Redis数据库编号从0~15,我们可以选择任意一个数据库来进行数据的存取。
当选择16及以后会报错。默认选择0数据库
quit
退出连接,或者可以用exit,退出后用……/redis-cli来进入
dbsize
(integer) 12
当前数据库中key的数量
info
服务器基本信息
monitor
实时转储收到的请求
config get
获取服务器的参数配置如:config get dir
flushdb
清空当前数据库
flushall
清除所有数据库
redis.conf配置说明
daemonize no
Redis默认不是以守护进程的方式运行,可以通过该配置项修改,使用yes启用守护进程
pidfile
当Redis 在后台运行的时候,Redis 默认会把pid 文件放在/var/run/redis.pid,你可以配置到其他地址。当运行多个redis 服务时,需要指定不同的pid 文件和端口,pid是记录redis-server进程的pid,pid 亦即 Process ID!
port 6379
指定Redis监听端口,默认端口为6379
bind 127.0.0.1
绑定的主机地址
timeout 300
检测客户端空闲连接的超时时间,一旦idle时间达到了 timeout,客户端将会被关闭,单位为秒。当客户端在这段时间内没有发出任何指令,那么关闭该连接,如果指定为0,表示关闭该功能
loglevel verbose
指定日志记录级别,Redis总共支持四个级别:debug、verbose、notice、warning,默认为verbose,生产环境下一般开启notice
logfile stdout
日志记录方式,默认为标准输出,即打印在命令行终端的窗口上,如果配置Redis为守护进程方式运行,而这里又配置为日志记录方式为标准输出,则日志将会发送给/dev/null
databases 16
设置数据库的个数,可以使用SELECT <dbid>命令来切换数据库。默认使用的数据库是0
tcp-keepalive
检测TCP连接活性的周期,默认值为0,也就是不进行 检测,如果需要设置,建议为60,那么Redis会每隔60秒对它创建的TCP连接进行活性检测,防止大量死连接占用系统资源。
tcp-backlog
TCP三次握手后,会将接受的连接放入队列中,tcpbacklog就是队列的大小,它在Redis中的默认值是511。通常来讲这个参数不 需要调整,但是这个参数会受到操作系统的影响,例如在Linux操作系统 中,如果/proc/sys/net/core/somaxconn小于tcp-backlog,那么在Redis启动时会 看到如下日志,并建议将/proc/sys/net/core/somaxconn设置更大
save
指定在多长时间内,有多少次更新操作,就将数据同步到数据文件,可以多个条件配合
Redis默认配置文件中提供了三个条件:
save 900 1
save 300 10
save 60 10000
分别表示900秒(15分钟)内有1个更改,300秒(5分钟)内有10个更改以及60秒内有10000个更改。
rdbcompression yes
指定存储至本地数据库时是否压缩数据,默认为yes,Redis采用LZF压缩,如果为了节省CPU时间,可以关闭该选项,但会导致数据库文件变的巨大
dbfilename dump.rdb
指定本地数据库文件名,默认值为dump.rdb
dir ./
指定本地数据库存放目录
slaveof
设置当本机为slav服务时,设置master服务的IP地址及端口,在Redis启动时,它会自动从master进行数据同步
masterauth
当master服务设置了密码保护时,slav服务连接master的密码
requirepass foobared
设置Redis连接密码,如果配置了连接密码,客户端在连接Redis时需要通过AUTH 命令提供密码,默认关闭
maxclients 128
设置同一时间最大客户端连接数,默认无限制,Redis可以同时打开的客户端连接数为Redis进程可以打开的最大文件描述符数,如果设置 maxclients 0,表示不作限制。当客户端连接数到达限制时,Redis会关闭新的连接并向客户端返回max number of clients reached错误信息
maxmemory
指定Redis最大内存限制,Redis在启动时会把数据加载到内存中,达到最大内存后,Redis会先尝试清除已到期或即将到期的Key,当此方法处理 后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。Redis新的vm机制,会把Key存放内存,Value会存放在swap区
appendonly no
指定是否在每次更新操作后进行日志记录,Redis在默认情况下是异步的把数据写入磁盘,如果不开启,可能会在断电时导致一段时间内的数据丢失。因为 redis本身同步数据文件是按上面save条件来同步的,所以有的数据会在一段时间内只存在于内存中。默认为no
appendfilename appendonly.aof
指定更新日志文件名,默认为appendonly.aof
appendfsync everysec
指定更新日志条件,共有3个可选值:
no:表示等操作系统进行数据缓存同步到磁盘(快)
always:表示每次更新操作后手动调用fsync()将数据写到磁盘(慢,安全)
everysec:表示每秒同步一次(折衷,默认值)
vm-enabled no
指定是否启用虚拟内存机制,默认值为no,简单的介绍一下,VM机制将数据分页存放,由Redis将访问量较少的页即冷数据swap到磁盘上,访问多的页面由磁盘自动换出到内存中(在后面的文章我会仔细分析Redis的VM机制)
vm-swap-file /tmp/redis.swap
虚拟内存文件路径,默认值为/tmp/redis.swap,不可多个Redis实例共享
vm-max-memory 0
将所有大于vm-max-memory的数据存入虚拟内存,无论vm-max-memory设置多小,所有索引数据都是内存存储的(Redis的索引数据 就是keys),也就是说,当vm-max-memory设置为0的时候,其实是所有value都存在于磁盘。默认值为0
vm-page-size 32
Redis swap文件分成了很多的page,一个对象可以保存在多个page上面,但一个page上不能被多个对象共享,vm-page-size是要根据存储的 数据大小来设定的,作者建议如果存储很多小对象,page大小最好设置为32或者64bytes;如果存储很大大对象,则可以使用更大的page,如果不 确定,就使用默认值
vm-pages 134217728
设置swap文件中的page数量,由于页表(一种表示页面空闲或使用的bitmap)是在放在内存中的,,在磁盘上每8个pages将消耗1byte的内存
vm-max-threads 4
设置访问swap文件的线程数,最好不要超过机器的核数,如果设置为0,那么所有对swap文件的操作都是串行的,可能会造成比较长时间的延迟。默认值为4
glueoutputbuf yes
设置在向客户端应答时,是否把较小的包合并为一个包发送,默认为开启
hash-max-zipmap-entries 64
hash-max-zipmap-value 512
定在超过一定的数量或者最大的元素超过某一临界值时,采用一种特殊的哈希算法
activerehashing yes
指定是否激活重置哈希,默认为开启
include /path/to/local.conf
指定包含其它的配置文件,可以在同一主机上多个Redis实例之间使用同一份配置文件,而同时各个实例又拥有自己的特定配置文件
Redis高级应用
1安全性
设置客户端连接后进行任何其他指定前需要使用的密码。
警告:因为redis速度相当快,所以在一台比较好的服务器下,一个外部的用户可以在一秒钟进行150K次的密码尝试,这意味着你需要指定非常非常强大的密码来防止暴力破解。
需要我们在配置文件中进行修改,如下:
|
# requirepass foobared requirepass beijing |
下面我们做一个实验,说明redis的安全性是如何实现的。
我们设置了连接的口令是beijing
那么们启动一个客户端试一下:
|
[root@localhost redis-2.2.12]# src/redis-cli redis 127.0.0.1:6379> keys * (error) ERR operation not permitted redis 127.0.0.1:6379> |
说明权限太小,我们可以当前的这个窗口中设置口令
|
redis 127.0.0.1:6379> auth beijing OK redis 127.0.0.1:6379> keys * 1) "name" redis 127.0.0.1:6379> |
我们还可以在连接到服务器期间就指定一个口令,如下:
|
[root@localhost redis-2.2.12]# src/redis-cli -a beijing redis 127.0.0.1:6379> keys * 1) "name" redis 127.0.0.1:6379> |
可以看到我们在连接的时候就可以指定一个口令。
2事务处理
Redis通过MULTI、EXEC、WATCH等命令来实现事务(transaction)功能。事务提供了一种将多个命令请求打包,然后一次性、按顺序地执行多个命令的机制,并且在事务执行期间,服务器不会中断事务而去执行其他客户端命令。
一个事务从开始到结束通常经历三个阶段:
(1) 事务开始
(2) 命令入队
(3) 事务执行
MULTI命令可以将执行该命令的客户端从非事务状态切换至事务状态。
EXEC、DISCARD、WATCH、MULTI四个命令以外的其他命令会放在一个事务队列中
事务队列是一个以先进先出(FIFO)的方式保存入队的命令,当一个处于事务状态的客户端向服务器发送EXEC命令时,事务执行
WATCH命令是一个乐观所(optimistic locking),它可以在EXEC命令执行前,监视任意数量的数据库键,并在EXEC命令执行时,检查监视的键是否至少有一个已经被修改过了,如果修改过了,服务器将拒绝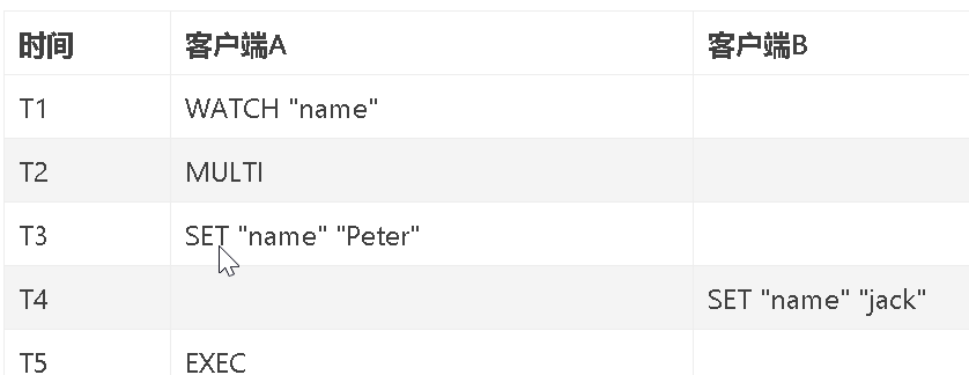
在时间T4,客户端B修改了"name"键的值,当客户端A在T5执行EXEC命令时,服务器会发现WATCH监视的键“name”已经被修改,因此服务器拒绝执行客户端A的事务,并向客户端A返回空
1、简单事务控制
下面可以看一个例子:
redis 127.0.0.1:6379> get age
"33"
redis 127.0.0.1:6379> multi
OK
redis 127.0.0.1:6379> set age 10
QUEUED
redis 127.0.0.1:6379> set age 20
QUEUED
redis 127.0.0.1:6379> exec
1) OK
2) OK
redis 127.0.0.1:6379> get age
"20"
redis 127.0.0.1:6379>
从这个例子我们可以看到2个set age命令发出后并没执行而是被放到了队列中。调用exec后2个命令才被连续的执行,最后返回的是两条命令执行后的结果。
2、如何取消一个事务
我们可以调用discard命令来取消一个事务,让事务回滚。接着上面例子:
redis 127.0.0.1:6379> get age
"20"
redis 127.0.0.1:6379> multi
OK
redis 127.0.0.1:6379> set age 30
QUEUED
redis 127.0.0.1:6379> set age 40
QUEUED
redis 127.0.0.1:6379> discard
OK
redis 127.0.0.1:6379> get age
"20"
redis 127.0.0.1:6379>
可以发现这次2个set age命令都没被执行。discard命令其实就是清空事务的命令队列并退出事务上下文,也就是我们常说的事务回滚。
- redis事务的弊端
Redis不支持事务回滚机制(rollback), 即使事务队列中的某个命令在执行期间出现了错误,整个事务也会继续执行下去,直到将事务队列中的所有命令都执行完毕为止。
只有数值类型的字符串才能够自增
redis 127.0.0.1:6379> get age
"100"
redis 127.0.0.1:6379> multi
OK
redis 127.0.0.1:6379> incr age
QUEUED
redis 127.0.0.1:6379> incr name
QUEUED
redis 127.0.0.1:6379>exec
即当队列中的命令执行不成功,事务不会进行自动回滚。
所以Redis的事务处理有待改进
4、乐观锁复杂事务控制
乐观锁:大多数是基于数据版本(version)的记录机制实现的。何谓数据版本?即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表添加一个 “version”字段来实现读取出数据时,将此版本号一同读出,之后更新时,对此版本号加1。
此时,将提交数据的版本号与数据库表对应记录的当前版本号进行比对,如果提交的数据版本号大于数据库表当前版本号,则予以更新,否则认为是过期数据。
Redis乐观锁实例:
假设有一个age的key,我们开2个session来对age进行赋值操作,我们来看一下结果如何。
|
Session 1 |
Session 2 |
|
(1)第1步 redis 127.0.0.1:6379> get age "10" redis 127.0.0.1:6379> watch age OK redis 127.0.0.1:6379> multi OK redis 127.0.0.1:6379> |
|
|
|
(2)第2步 redis 127.0.0.1:6379> set age 30 OK redis 127.0.0.1:6379> get age "30" redis 127.0.0.1:6379> |
|
(3)第3步 redis 127.0.0.1:6379> set age 20 QUEUED redis 127.0.0.1:6379> exec (nil) redis 127.0.0.1:6379> get age "30" redis 127.0.0.1:6379> |
|
从以上实例可以看到在
第一步,Session 1 还没有来得及对age的值进行修改
第二步,Session 2 已经将age的值设为30
第三步,Session 1 希望将age的值设为20,但结果一执行返回是nil,说明执行失败,之后我们再取一下age的值是30,这是由于Session 1中对age加了乐观锁导致的。
watch命令会监视给定的key,当exec时候如果监视的key从调用watch后发生过变化,则整个事务会失败。也可以调用watch多次监视多个key.这 样就可以对指定的key加乐观锁了。注意watch的key是对整个连接有效的,事务也一样。如果连接断开,监视和事务都会被自动清除。当然了exec,discard,unwatch命令都会清除连接中的所有监视。
3持久化机制
redis是一个支持持久化的内存数据库,也就是说redis需要经常将内存中的数据同步到磁盘来保证持久化。redis支持两种持久化方式,一种是Snapshotting(RDB快照方式)也是默认方式,另一种是Append-only file(缩写aof操作日志方式)的方式。下面分别介绍:
rdb是Redis DataBase缩写
快照是默认的持久化方式。这种方式是就是将内存中数据以快照的方式写入到二进制文件中,默认的文件名为dump.rdb。可以通过配置设置自动做快照持久化的方式。我们可以配置redis在n秒内如果超过m个key被修改就自动做快照,下面是默认的快照保存配置
save 900 1 #900秒内如果超过1个key被修改,则发起快照保存
save 300 10 #300秒内容如超过10个key被修改,则发起快照保存
save 60 10000
下面介绍详细的快照保存过程:
1.redis调用fork,现在有了子进程和父进程。
- 父进程继续处理client请求,子进程负责将内存内容写入到临时文件。由于os的实时复制机制(copy on write)父子进程会共享相同的物理页面,当父进程处理写请求时os会为父进程要修改的页面创建副本,而不是写共享的页面。所以子进程地址空间内的数据是fork时刻整个数据库的一个快照。
3.当子进程将快照写入临时文件完毕后,用临时文件替换原来的快照文件,然后子进程退出。
client 也可以使用save或者bgsave命令通知redis做一次快照持久化。save操作是在主线程中保存快照的,由于redis是用一个主线程来处理所有client的请求,这种方式会阻塞所有client请求。所以不推荐使用。另一点需要注意的是,每次快照持久化都是将内存数据完整写入到磁盘一次,并不是增量的只同步变更数据。如果数据量大的话,而且写操作比较多,必然会引起大量的磁盘io操作,可能会严重影响性能。
下面将演示各种场景的数据库持久化情况
|
redis 127.0.0.1:6379> set name HongWan OK redis 127.0.0.1:6379> get name "HongWan" redis 127.0.0.1:6379> shutdown redis 127.0.0.1:6379> quit |
我们先设置了一个name的键值对,然后正常关闭了数据库实例,数据是否被保存到磁盘了呢?我们来看一下服务器端是否有消息被记录下来了:
|
[6563] 09 Aug 18:58:58 * The server is now ready to accept connections on port 6379 [6563] 09 Aug 18:58:58 - 0 clients connected (0 slaves), 539540 bytes in use [6563] 09 Aug 18:59:02 - Accepted 127.0.0.1:58005 [6563] 09 Aug 18:59:03 - 1 clients connected (0 slaves), 547368 bytes in use [6563] 09 Aug 18:59:08 - 1 clients connected (0 slaves), 547424 bytes in use [6563] 09 Aug 18:59:12 # User requested shutdown... [6563] 09 Aug 18:59:12 * Saving the final RDB snapshot before exiting. [6563] 09 Aug 18:59:12 * DB saved on disk [6563] 09 Aug 18:59:12 # Redis is now ready to exit, bye bye... [root@localhost redis-2.2.12]# |
从日志可以看出,数据库做了一个存盘的操作,将内存的数据写入磁盘了。正常的话,磁盘上会产生一个dump文件,用于保存数据库快照,我们来验证一下:
|
[root@localhost redis-2.2.12]# ll 总计 188 -rw-rw-r-- 1 root root 9602 2011-07-22 00-RELEASENOTES -rw-rw-r-- 1 root root 55 2011-07-22 BUGS -rw-rw-r-- 1 root root 84050 2011-07-22 Changelog drwxrwxr-x 2 root root 4096 2011-07-22 client-libraries -rw-rw-r-- 1 root root 671 2011-07-22 CONTRIBUTING -rw-rw-r-- 1 root root 1487 2011-07-22 COPYING drwxrwxr-x 4 root root 4096 2011-07-22 deps drwxrwxr-x 2 root root 4096 2011-07-22 design-documents drwxrwxr-x 2 root root 12288 2011-07-22 doc -rw-r--r-- 1 root root 26 08-09 18:59 dump.rdb -rw-rw-r-- 1 root root 652 2011-07-22 INSTALL -rw-rw-r-- 1 root root 337 2011-07-22 Makefile -rw-rw-r-- 1 root root 1954 2011-07-22 README -rw-rw-r-- 1 root root 19067 08-09 18:48 redis.conf drwxrwxr-x 2 root root 4096 08-05 19:12 src drwxrwxr-x 7 root root 4096 2011-07-22 tests -rw-rw-r-- 1 root root 158 2011-07-22 TODO drwxrwxr-x 2 root root 4096 2011-07-22 utils [root@localhost redis-2.2.12]#
|
硬盘上已经产生了一个数据库快照了。这时侯我们再将redis启动,看键值还是否真的持久化到硬盘了。
|
redis 127.0.0.1:6379> keys * 1) "name" redis 127.0.0.1:6379> get name "HongWan" redis 127.0.0.1:6379> |
数据被完全持久化到硬盘了。
另外由于快照方式是在一定间隔时间做一次的,所以如果redis意外down掉的话,就会丢失最后一次快照后的所有修改。如果应用要求不能丢失任何修改的话,可以采用aof持久化方式。下面介绍Append-only file:
aof 比快照方式有更好的持久化性,是由于在使用aof持久化方式时,redis会将每一个收到的写命令都通过write函数追加到文件中(默认是appendonly.aof)。当redis重启时会通过重新执行文件中保存的写命令来在内存中重建整个数据库的内容。当然由于os会在内核中缓存 write做的修改,所以可能不是立即写到磁盘上。这样aof方式的持久化也还是有可能会丢失部分修改。不过我们可以通过配置文件告诉redis我们想要通过fsync函数强制os写入到磁盘的时机。有三种方式如下(默认是:每秒fsync一次)
appendonly yes //启用aof持久化方式
# appendfsync always //收到写命令就立即写入磁盘,最慢,但是保证完全的持久化
appendfsync everysec //每秒钟写入磁盘一次,在性能和持久化方面做了很好的折中
# appendfsync no //完全依赖os,性能最好,持久化没保证
接下来我们以实例说明用法:
|
redis 127.0.0.1:6379> set name HongWan OK redis 127.0.0.1:6379> set age 20 OK redis 127.0.0.1:6379> keys * 1) "age" 2) "name" redis 127.0.0.1:6379> shutdown redis 127.0.0.1:6379> |
我们先设置2个键值对,然后我们看一下系统中有没有产生appendonly.aof文件
|
[root@localhost redis-2.2.12]# ll 总计 184 -rw-rw-r-- 1 root root 9602 2011-07-22 00-RELEASENOTES -rw-r--r-- 1 root root 0 08-09 19:37 appendonly.aof -rw-rw-r-- 1 root root 55 2011-07-22 BUGS -rw-rw-r-- 1 root root 84050 2011-07-22 Changelog drwxrwxr-x 2 root root 4096 2011-07-22 client-libraries -rw-rw-r-- 1 root root 671 2011-07-22 CONTRIBUTING -rw-rw-r-- 1 root root 1487 2011-07-22 COPYING drwxrwxr-x 4 root root 4096 2011-07-22 deps drwxrwxr-x 2 root root 4096 2011-07-22 design-documents drwxrwxr-x 2 root root 12288 2011-07-22 doc -rw-rw-r-- 1 root root 652 2011-07-22 INSTALL -rw-rw-r-- 1 root root 337 2011-07-22 Makefile -rw-rw-r-- 1 root root 1954 2011-07-22 README -rw-rw-r-- 1 root root 19071 08-09 19:24 redis.conf drwxrwxr-x 2 root root 4096 08-05 19:12 src drwxrwxr-x 7 root root 4096 2011-07-22 tests -rw-rw-r-- 1 root root 158 2011-07-22 TODO drwxrwxr-x 2 root root 4096 2011-07-22 utils [root@localhost redis-2.2.12]# |
结果证明产生了,接着我们将redis再次启动后来看一下数据是否还在
|
[root@localhost redis-2.2.12]# src/redis-cli redis 127.0.0.1:6379> keys * 1) "age" 2) "name" redis 127.0.0.1:6379> |
数据还存在系统中,说明系统是在启动时执行了一下从磁盘到内存的load数据的过程。
aof 的方式也同时带来了另一个问题。持久化文件会变的越来越大。例如我们调用incr test命令100次,文件中必须保存全部的100条命令,其实有99条都是多余的。因为要恢复数据库的状态其实文件中保存一条set test 100就够了。为了压缩aof的持久化文件。redis提供了bgrewriteaof命令。收到此命令redis将使用与快照类似的方式将内存中的数据以命令的方式保存到临时文件中,最后替换原来的文件。具体过程如下
1、redis调用fork ,现在有父子两个进程
2、子进程根据内存中的数据库快照,往临时文件中写入重建数据库状态的命令
3、父进程继续处理client请求,除了把写命令写入到原来的aof文件中。同时把收到的写命令缓存起来。这样就能保证如果子进程重写失败的话并不会出问题。
4、当子进程把快照内容写入已命令方式写到临时文件中后,子进程发信号通知父进程。然后父进程把缓存的写命令也写入到临时文件。
5、现在父进程可以使用临时文件替换老的aof文件,并重命名,后面收到的写命令也开始往新的aof文件中追加。
需要注意到是重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似。接来我们看一下实际的例子:
我们先调用5次incr age命令:
|
redis 127.0.0.1:6379> incr age (integer) 21 redis 127.0.0.1:6379> incr age (integer) 22 redis 127.0.0.1:6379> incr age (integer) 23 redis 127.0.0.1:6379> incr age (integer) 24 redis 127.0.0.1:6379> incr age (integer) 25 redis 127.0.0.1:6379> |
接下来我们看一下日志文件的大小
|
[root@localhost redis-2.2.12]# ll 总计 188 -rw-rw-r-- 1 root root 9602 2011-07-22 00-RELEASENOTES -rw-r--r-- 1 root root 259 08-09 19:43 appendonly.aof -rw-rw-r-- 1 root root 55 2011-07-22 BUGS -rw-rw-r-- 1 root root 84050 2011-07-22 Changelog |
大小为259个字节,接下来我们调用一下bgrewriteaof命令将内存中的数据重新刷到磁盘的日志文件中
|
redis 127.0.0.1:6379> bgrewriteaof Background append only file rewriting started redis 127.0.0.1:6379> |
再看一下磁盘上的日志文件大小
|
[root@localhost redis-2.2.12]# ll 总计 188 -rw-rw-r-- 1 root root 9602 2011-07-22 00-RELEASENOTES -rw-r--r-- 1 root root 127 08-09 19:45 appendonly.aof -rw-rw-r-- 1 root root 55 2011-07-22 BUGS -rw-rw-r-- 1 root root 84050 2011-07-22 Changelog |
日志文件大小变为127个字节了,说明原来日志中的重复记录已被刷新掉了。
aof的存储结构
内容是redis通讯协议(RESP )格式的命令文本存储。
RESP 是redis客户端和服务端之前使用的一种通讯协议;
比较:
1、aof文件比rdb更新频率高,优先使用aof还原数据。
2、aof比rdb更安全也更大
3、rdb性能比aof好
4、如果两个都配了优先加载AOF
4发布订阅信息
发布订阅(pub/sub)是一种消息通知模式,主要的目的是截除消息发布者和消息订阅者之间的耦合,
功能说明:Redis 的 SUBSCRIBE 命令可以让客户端订阅任意数量的频道, 每当有新信息发送到被订阅的频道时, 信息就会被发送给所有订阅指定频道的客户端。当有新消息通过 PUBLISH 命令发送给频道这个消息就会被发送给订阅它的客户端,使用 UNSUBSCRIBE 命令可以退订指定的频道, 这个命令执行的是订阅的反操作: 它从 pubsub_channels 字典的给定频道(键)中, 删除关于当前客户端的信息, 这样被退订频道的信息就不会再发送给这个客户端。
|
[root@vm4 ~]# redis-cli -a westos 127.0.0.1:6379> SUBSCRIBE tv1 Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "tv1" 3) (integer) 1 1) "message" 2) "tv1" 3) "hy" [root@vm4 ~]# redis-cli -a westos 127.0.0.1:6379> SUBSCRIBE tv1 tv2 Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "tv1" 3) (integer) 1 1) "subscribe" 2) "tv2" 3) (integer) 2 1) "message" 2) "tv1" 3) "hy" 1) "message" 2) "tv2" 3) "hy_new" [root@vm4 ~]# redis-cli -a westos 127.0.0.1:6379> PUBLISH tv1 hy (integer) 2 127.0.0.1:6379> PUBLISH tv2 hy_new (integer) 1
|
标红的是当发布者写入命令后自动弹出来的。
redis发布订阅原理
当客户端调用 SUBSCRIBE channel1 channel2 channel3命令时,redis会把通过一个哈希表配合链表来关联订阅的频道和客户端,哈希表的键就是订阅的频道,链表的内容就是订阅该频道的客户端
当调用PUBLISH channel message 命令, 程序首先根据 channel 定位到哈希表的键, 然后将信息发送给字典值链表中的所有客户端。
5虚拟内存的使用
Redis的虚拟内存与操作系统的虚拟内存不是一回事,但是思路和目的都是相同的。就是暂时把不经常访问的数据从内存交换到磁盘中,从而腾出宝贵的内存空间用于其他需要访问的数据。
redis属于内存数据库,内存总是不够用,redis会暂时把不经常访问的数据从内存交换到磁盘中,从而腾出宝贵的内存空间用于其他需要访问的数据。为了保证key的查找速度只会把value交换到磁盘中
在redis使用的内存没超过设置的vm-max-memory之前是不会交换任何value的。当超过最大内存限制后,redis会选择较老的对象。如果两个对象一样老会优先交换比较大的对象
可以设置vm-max-threads设为0时
主线程定期检查发现内存超出最大上限后,会直接以阻塞的方式,将选中的对象交换到磁盘,并释放其内存,获取交换过的key的值时,会阻塞所有client获取到值后返回,并恢复响应其他请求
vm-max-threads大于0时
当主线程检测到使用内存超过最大上限,会将选中的要交换的对象信息放到一个队列中交由工作线程后台处理,主线程会继续处理client请求。
如果有client请求的key被换出了,主线程先阻塞发出命令的client,然后将加载对象的信息放到一个队列中,让工作线程去加载。加载完毕后工作线程通知主线程。主线程再执行client的命令。这种方式只阻塞请求value被换出key的client
总 的来说blocking vm的方式总的性能会好一些,因为不需要线程同步,创建线程和恢复被阻塞的client等开销。但是也相应的牺牲了响应性。threaded vm的方式主线程不会阻塞在磁盘io上,所以响应性更好。如果我们的应用不太经常发生换入换出,而且也不太在意有点延迟的话则推荐使用blocking vm的方式。
下面是vm相关配置:
vm-enabled yes #开启vm功能
vm-swap-file /tmp/redis.swap #交换出来的value保存的文件路径
vm-max-memory 1000000 #每个页面的大小32字节
vm-pages 134217728 #最多使用多少页面
vm-max-threads 4 #用于执行value对象换入的工作线程数量
重新启动服务
在配置文件中添加really-use-vm yes
再重启
redis集群
简介
Redis Cluster
redis3.0及以后支持集群
redis集群采用P2P模式,是完全去中心化的,不存在中心节点或者代理节点;
redis集群是没有统一的入口的,客户端(client)连接集群的时候连接集群中的任意节点(node)即可,集群内部的节点是相互通信的(PING-PONG机制),每个节点都是一个redis实例;
为了实现集群的高可用,即判断节点是否健康(能否正常使用),redis-cluster有这么一个投票容错机制:如果集群中超过半数的节点投票认为某个节点挂了,那么这个节点就挂了(fail)。这是判断节点是否挂了的方法;
那么如何判断集群是否挂了呢? -> 如果集群中任意一个节点挂了,而且该节点没有从节点(备份节点),那么这个集群就挂了。这是判断集群是否挂了的方法;
那么为什么任意一个节点挂了(没有从节点)这个集群就挂了呢? -> 因为集群内置了16384个slot(哈希槽),并且把所有的物理节点映射到了这16384[0-16383]个slot上,或者说把这些slot均等的分配给了各个节点。当需要在Redis集群存放一个数据(key-value)时,redis会先对这个key进行crc16算法,然后得到一个结果。再把这个结果对16384进行求余,这个余数会对应[0-16383]其中一个槽,进而决定key-value存储到哪个节点中。所以一旦某个节点挂了,该节点对应的slot就无法使用,那么就会导致集群无法正常工作。
综上所述,每个Redis集群理论上最多可以有16384个节点。
集群原理
redis-cluster架构图
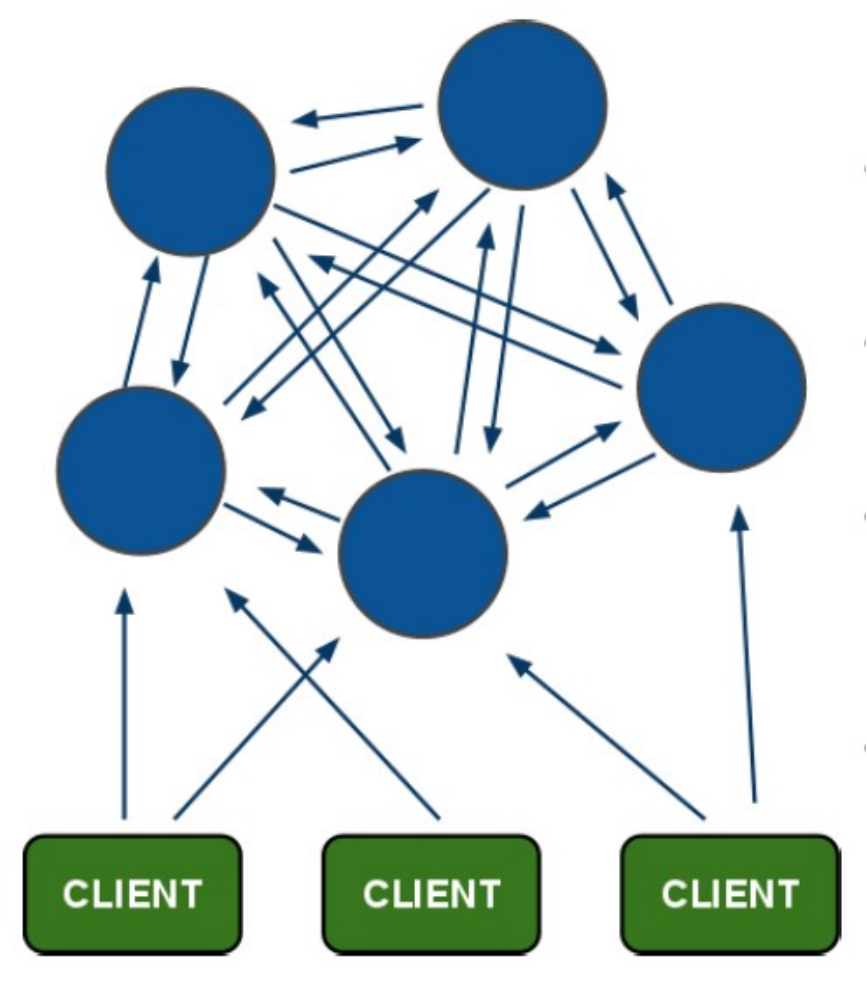
架构细节:
(1)所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽.
(2)节点的fail是通过集群中超过半数的节点检测失效时才生效.
(3)客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
(4)redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 负责维护node<->slot<->value
Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value 时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点
redis-cluster投票:容错
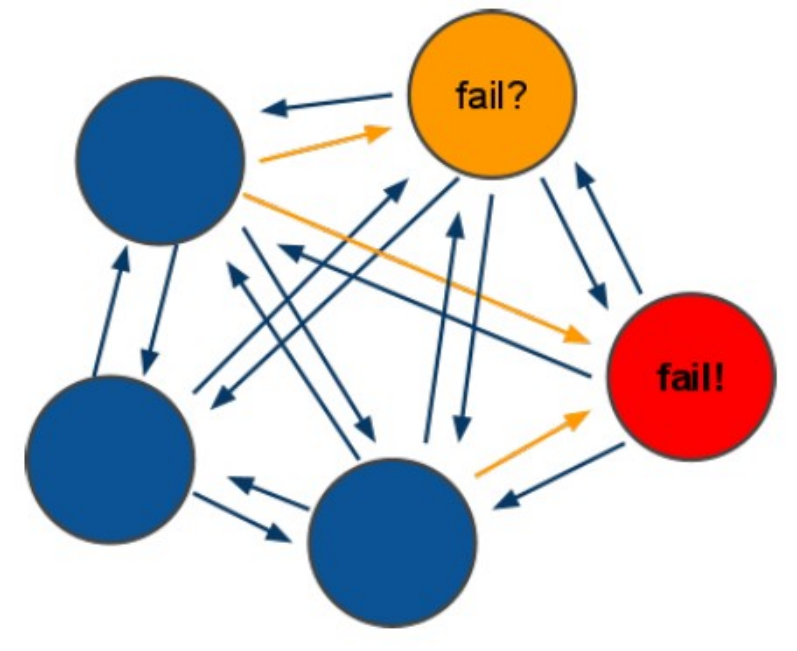
(1)领着投票过程是集群中所有master参与,如果半数以上master节点与master节点通信超过(cluster-node-timeout),认为当前master节点挂掉.
(2):什么时候整个集群不可用(cluster_state:fail)?
a:如果集群任意master挂掉,且当前master没有slave.集群进入fail状态,也可以理解成集群的slot映射[0-16383]不完成时进入fail状态. ps : redis-3.0.0.rc1加入cluster-require-full-coverage参数,默认关闭,打开集群兼容部分失败.
b:如果集群超过半数以上master挂掉,无论是否有slave集群进入fail状态.
ps:当集群不可用时,所有对集群的操作做都不可用,收到((error) CLUSTERDOWN The cluster is down)错误
集群搭建需要的环境
2.1 Redis集群至少需要3个节点,因为投票容错机制要求超过半数节点认为某个节点挂了该节点才是挂了,所以2个节点无法构成集群。
2.2 要保证集群的高可用,需要每个节点都有从节点,也就是备份节点,所以Redis集群至少需要6台服务器。
要搭建集群的话,需要使用一个工具(脚本文件),这个工具在redis解压文件的源代码里。因为这个工具是一个ruby脚本文件,所以这个工具的运行需要ruby的运行环境,就相当于java语言的运行需要在jvm上。
ruby环境
redis集群管理工具redis-trib.rb依赖ruby环境,首先需要安装ruby环境:
安装ruby
yum install ruby
yum install rubygems
安装ruby和redis的接口程序
拷贝redis-3.0.0.gem至/usr/local下
执行:
gem install /usr/local/redis-3.0.0.gem
创建集群:
集群结点规划
这里在同一台服务器用不同的端口表示不同的redis服务器,如下:
主节点:192.168.101.3:7001 192.168.101.3:7002 192.168.101.3:7003
从节点:192.168.101.3:7004 192.168.101.3:7005 192.168.101.3:7006
在/usr/local下创建redis-cluster目录,其下创建7001、7002。。7006目录,如下:
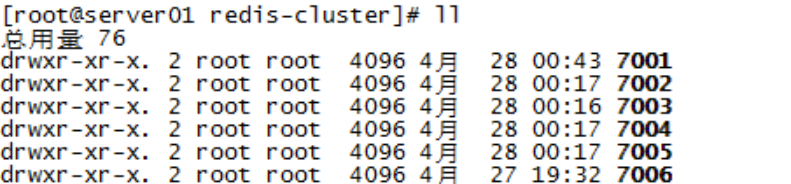
将redis安装目录bin下的文件拷贝到每个700X目录内,同时将redis源码目录src下的redis-trib.rb拷贝到redis-cluster目录下。
修改每个700X目录下的redis.conf配置文件:
port XXXX
#bind 192.168.101.3
cluster-enabled yes
启动每个结点redis服务
分别进入7001、7002、...7006目录,执行:
./redis-server ./redis.conf
查看redis进程:

执行创建集群命令
执行redis-trib.rb,此脚本是ruby脚本,它依赖ruby环境。
./redis-trib.rb create --replicas 1 192.168.101.3:7001 192.168.101.3:7002 192.168.101.3:7003 192.168.101.3:7004 192.168.101.3:7005 192.168.101.3:7006
|
./redis-trib.rb create --replicas 1 192.168.131.102:7001 192.168.131.102:7002 192.168.131.102:7003 192.168.131.102:7004 192.168.131.102:7005 192.168.131.102:7006 |
说明:
redis集群至少需要3个主节点,每个主节点有一个从节点总共6个节点
replicas指定为1表示每个主节点有一个从节点
注意:
如果执行时报如下错误:
[ERR] Node XXXXXX is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0
解决方法是删除生成的配置文件nodes.conf,如果不行则说明现在创建的结点包括了旧集群的结点信息,需要删除redis的持久化文件后再重启redis,比如:appendonly.aof、dump.rdb
创建集群输出如下:
>>> Creating cluster
Connecting to node 192.168.101.3:7001: OK
Connecting to node 192.168.101.3:7002: OK
Connecting to node 192.168.101.3:7003: OK
Connecting to node 192.168.101.3:7004: OK
Connecting to node 192.168.101.3:7005: OK
Connecting to node 192.168.101.3:7006: OK
>>> Performing hash slots allocation on 6 nodes...
Using 3 masters:
192.168.101.3:7001
192.168.101.3:7002
192.168.101.3:7003
Adding replica 192.168.101.3:7004 to 192.168.101.3:7001
Adding replica 192.168.101.3:7005 to 192.168.101.3:7002
Adding replica 192.168.101.3:7006 to 192.168.101.3:7003
M: cad9f7413ec6842c971dbcc2c48b4ca959eb5db4 192.168.101.3:7001
slots:0-5460 (5461 slots) master
M: 4e7c2b02f0c4f4cfe306d6ad13e0cfee90bf5841 192.168.101.3:7002
slots:5461-10922 (5462 slots) master
M: 1a8420896c3ff60b70c716e8480de8e50749ee65 192.168.101.3:7003
slots:10923-16383 (5461 slots) master
S: 69d94b4963fd94f315fba2b9f12fae1278184fe8 192.168.101.3:7004
replicates cad9f7413ec6842c971dbcc2c48b4ca959eb5db4
S: d2421a820cc23e17a01b597866fd0f750b698ac5 192.168.101.3:7005
replicates 4e7c2b02f0c4f4cfe306d6ad13e0cfee90bf5841
S: 444e7bedbdfa40714ee55cd3086b8f0d5511fe54 192.168.101.3:7006
replicates 1a8420896c3ff60b70c716e8480de8e50749ee65
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join...
>>> Performing Cluster Check (using node 192.168.101.3:7001)
M: cad9f7413ec6842c971dbcc2c48b4ca959eb5db4 192.168.101.3:7001
slots:0-5460 (5461 slots) master
M: 4e7c2b02f0c4f4cfe306d6ad13e0cfee90bf5841 192.168.101.3:7002
slots:5461-10922 (5462 slots) master
M: 1a8420896c3ff60b70c716e8480de8e50749ee65 192.168.101.3:7003
slots:10923-16383 (5461 slots) master
M: 69d94b4963fd94f315fba2b9f12fae1278184fe8 192.168.101.3:7004
slots: (0 slots) master
replicates cad9f7413ec6842c971dbcc2c48b4ca959eb5db4
M: d2421a820cc23e17a01b597866fd0f750b698ac5 192.168.101.3:7005
slots: (0 slots) master
replicates 4e7c2b02f0c4f4cfe306d6ad13e0cfee90bf5841
M: 444e7bedbdfa40714ee55cd3086b8f0d5511fe54 192.168.101.3:7006
slots: (0 slots) master
replicates 1a8420896c3ff60b70c716e8480de8e50749ee65
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
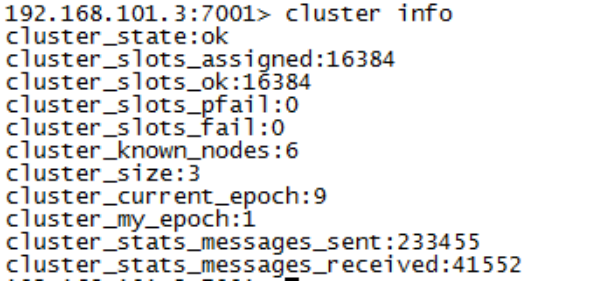
查询集群信息
集群创建成功登陆任意redis结点查询集群中的节点情况。
客户端以集群方式登陆:

说明:
./redis-cli -c -h 192.168.101.3 -p 7001 ,其中-c表示以集群方式连接redis,-h指定ip地址,-p指定端口号
cluster nodes 查询集群结点信息
cluster info 查询集群状态信息
添加主节点
集群创建成功后可以向集群中添加节点,下面是添加一个master主节点
添加7007结点,参考集群结点规划章节添加一个“7007”目录作为新节点。
执行下边命令:
./redis-trib.rb add-node 192.168.101.3:7007 192.168.101.3:7001
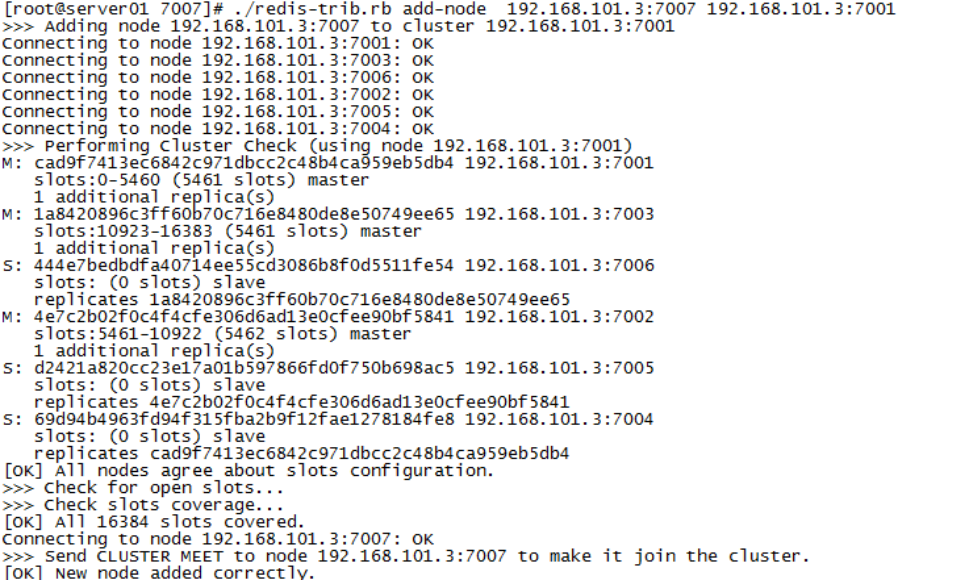
查看集群结点发现7007已添加到集群中:

hash槽重新分配
添加完主节点需要对主节点进行hash槽分配这样该主节才可以存储数据。
redis集群有16384个槽,集群中的每个结点分配自已槽,通过查看集群结点可以看到槽占用情况。

给刚添加的7007结点分配槽:
第一步:连接上集群
./redis-trib.rb reshard 192.168.101.3:7001(连接集群中任意一个可用结点都行)
第二步:输入要分配的槽数量
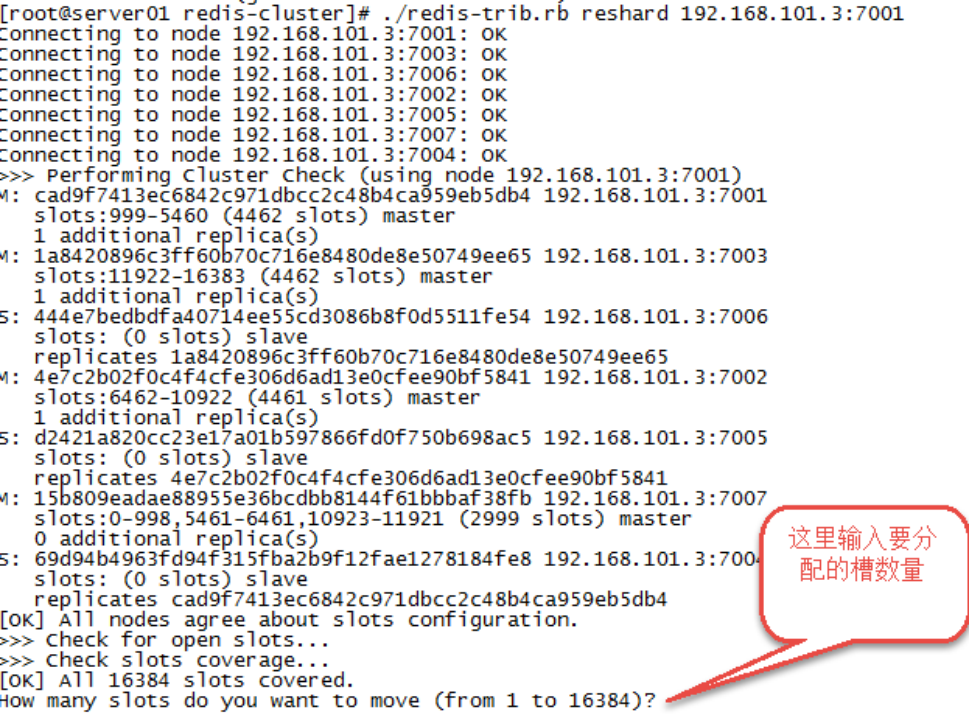
输入 500表示要分配500个槽
第三步:输入接收槽的结点id
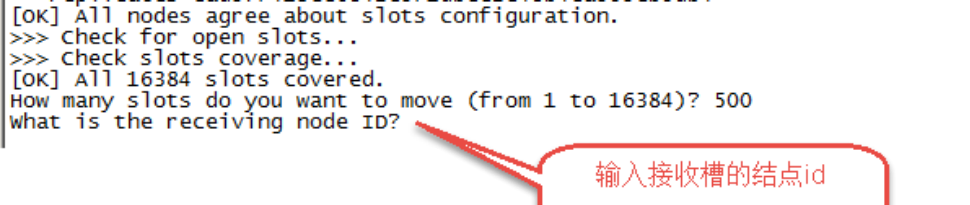
这里准备给7007分配槽,通过cluster nodes查看7007结点id为15b809eadae88955e36bcdbb8144f61bbbaf38fb
输入:15b809eadae88955e36bcdbb8144f61bbbaf38fb
第四步:输入源结点id
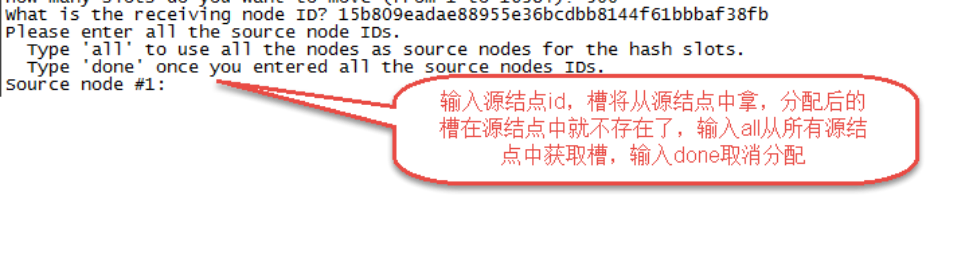
这里输入all
第五步:输入yes开始移动槽到目标结点id

添加从节点
集群创建成功后可以向集群中添加节点,下面是添加一个slave从节点。
添加7008从结点,将7008作为7007的从结点。
./redis-trib.rb add-node --slave --master-id 主节点id 添加节点的ip和端口 集群中已存在节点ip和端口
执行如下命令:
./redis-trib.rb add-node --slave --master-id cad9f7413ec6842c971dbcc2c48b4ca959eb5db4 192.168.101.3:7008 192.168.101.3:7001
cad9f7413ec6842c971dbcc2c48b4ca959eb5db4 是7007结点的id,可通过cluster nodes查看。
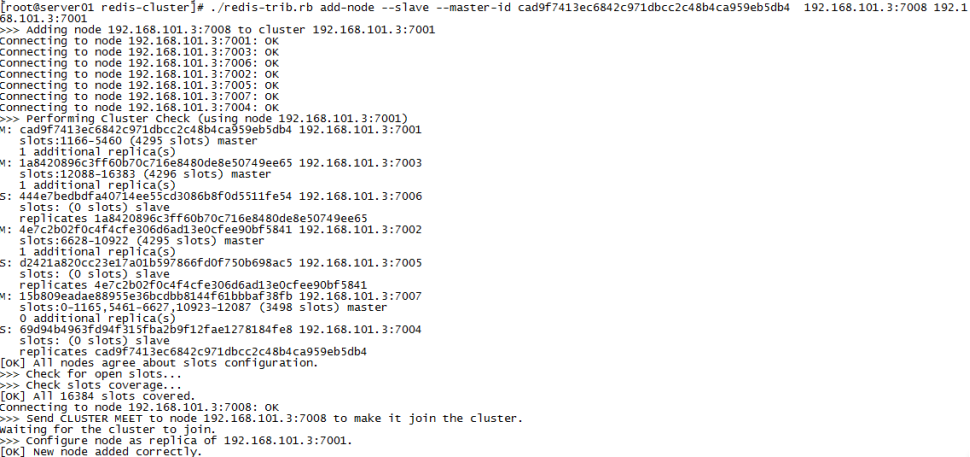
注意:如果原来该结点在集群中的配置信息已经生成cluster-config-file指定的配置文件中(如果cluster-config-file没有指定则默认为nodes.conf),这时可能会报错:
[ERR] Node XXXXXX is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0
解决方法是删除生成的配置文件nodes.conf,删除后再执行./redis-trib.rb add-node指令
查看集群中的结点,刚添加的7008为7007的从节点:

删除结点:
./redis-trib.rb del-node 127.0.0.1:7005 4b45eb75c8b428fbd77ab979b85080146a9bc017
删除已经占有hash槽的结点会失败,报错如下:
[ERR] Node 127.0.0.1:7005 is not empty! Reshard data away and try again.
需要将该结点占用的hash槽分配出去(参考hash槽重新分配章节)。
redis过期机制
定期删除+惰性删除
定期删除:指的是redis默认是每隔100ms就随机抽取一些设置了过期时间的key,检查其是否过期,如果过期就删除。
惰性删除:在你获取某个key的时候,redis会检查一下 ,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除,不会给你返回任何东西。
内存淘汰机制(回收策略)
如果redis的内存占用过多的时候,此时会进行内存淘汰,有如下一些策略:
noeviction:当内存不足以容纳新写入数据时,新写入操作会报错,这个一般没人用吧
allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)
allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key,这个一般没人用吧
volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key(这个一般不太合适)
volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key
volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除
默认的策略为noeviction策略
没有设置key的过期时间
看你redis设置的过期策略,一般
redis构建消息系统
基于List的 LPUSH+BRPOP 的实现
使用rpush和lpush操作入队列,lpop和rpop操作出队列, List支持多个生产者和消费者并发进出消息,每个消费者拿到都是不同的列表元素。但是当队列为空时,lpop和rpop会一直空轮训,消耗资源;所以引入阻塞读blpop和brpop(b代表blocking),阻塞读在队列没有数据的时候进入休眠状态。
线程一直阻塞在那里,Redis客户端的连接就成了闲置连接,闲置过久,服务器一般会主动断开连接,减少闲置资源占用,这个时候blpop和brpop或抛出异常,所以在编写客户端消费者的时候要小心,如果捕获到异常,还有重试。
PUB/SUB,订阅/发布模式
此模式允许生产者只生产一次消息,由中间件负责将消息复制到多个消息队列,每个消息队列由对应的消费组消费
优点:典型的广播模式,一个消息可以发布到多个消费者多信道订阅,消费者可以同时订阅多个信道,从而接收多类消息
缺点:发布时若客户端不在线,则消息丢失,不能寻回,不能保证每个消费者接收的时间是一致的,可见,Pub/Sub 模式不适合做消息存储,消息积压类的业务,而是擅长处理广播,即时通讯,即时反馈的业务
基于Sorted-Set的实现
Sortes Set(有序列表),类似于java的SortedSet和HashMap的结合体,一方面她是一个set,保证内部value的唯一性,另一方面它可以给每个value赋予一个score,代表这个value的排序权重。内部实现是“跳跃表”。有序集合的方案是在自己确定消息顺序ID时比较常用,使用集合成员的Score来作为消息ID,保证顺序,还可以保证消息ID的单调递增。通常可以使用时间戳+序号的方案。确保了消息ID的单调递增,利用SortedSet的依据Score排序的特征,就可以制作一个有序的消息队列了。
优点:就是可以自定义消息ID,在消息ID有意义时,比较重要
缺点:不允许重复消息(因为是集合),同时消息ID如果有错误会导致消息的顺序出错
基于Stream类型的实现
Stream为redis 5.0后新增的数据结构。支持多播的可持久化消息队列,实现借鉴了Kafka设计。Redis Stream的结构,它有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的ID和对应的内容。消息是持久化的,Redis重启后,内容还在。
Stream的消费模型借鉴了kafka的消费分组的概念,它弥补了Redis Pub/Sub不能持久化消息的缺陷。但是它又不同于kafka,kafka的消息可以分partition,而Stream不可以分partition。如果非要分parition的话,得在客户端做,提供不同的Stream名称,对消息进行hash取模来选择往哪个Stream里塞
序列化策略选择
JdkSerializationRedisSerializer序列化
被序列化的对象必须实现Serializable接口。
在存储内容时,除了属性的内容外还存了其它内容在里面,总长度长,且不容易阅读。
对于最下面的代码,存到redis里的内容如下:
redis 127.0.0.1:6379> get users/user1
"\xac\xed\x00\x05sr\x00!com.oreilly.springdata.redis.User\xb1\x1c \n\xcd\xed%\xd8\x02\x00\x02I\x00\x03ageL\x00\buserNamet\x00\x12Ljava/lang/String;xp\x00\x00\x00\x14t\x00\x05user1
Jackson2JsonRedisSerializer序列化
它不仅可以将对象序列化,还可以将对象转换为json字符串并保存到redis中,但需要和jackson配合一起使用。
用Jackson2JsonRedisSerializer序列化的话,被序列化的对象不用实现Serializable接口。
Jackson是利用反射和getter和setter方法进行读取的,如果不想因为getter和setter方法来影响存储,就要使用注解来定义被序列化的对象。
Jackson序列化的结果清晰,容易阅读,而且存储字节少,速度快,推荐。
存到redis里的内容如下:
redis 127.0.0.1:6379> get json/user1
"{"userName":"user1","age":20}"
redis 127.0.0.1:6379> strlen json/user1
(integer) 29
FastJson2JsonRedisSerializer序列化
StringRedisSerializer序列化
一般如果key-value都是string的话,使用StringRedisSerializer就可以了
默认的序列化策略
StringRedisTemplate默认采用的是String的序列化策略(StringRedisSerializer),保存的key和value都是采用此策略序列化保存的。
RedisTemplate默认采用的是JDK的序列化策略(JdkSerializationRedisSerializer),保存的key和value都是采用此策略序列化保存的。
其他总结
如何存储对象
需要将对象转化成json字符串,或序列化成二进制byte数组,然后用的时候再反序列化出来
Redis的key和value都支持二进制安全的字符串
存byte的方式要优于存string
redis支持的key的数量
单个实例支持 2^32
各集合可以存储的元素数量
每个list可以存放个元素,即4294967295 即40多亿个元素
每个set可以存放个元素
每个hash可以存放可以存放个元素
Redis与Lua
Redis中内嵌了对Lua环境的支持,允许开发者使用Lua语言编写脚本传到Redis中执行,Redis客户端可以使用Lua脚本,直接在服务端原子的执行多个Redis命令。
使用脚本的好处:
\1. 减少网络开销,在Lua脚本中可以把多个命令放在同一个脚本中运行
\2. 原子操作,redis会将整个脚本作为一个整体执行,中间不会被其他命令插入。换句话说,编写脚本的过程中无需担心会出现竞态条件
\3. 复用性,客户端发送的脚本会永远存储在redis中,这意味着其他客户端可以复用这一脚本来完成同样的逻辑
Lua是一个高效的轻量级脚本语言(javascript、shell、sql、python、ruby…),用标准C语言编写并以源代码形式开放, 其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能;
在Lua脚本中调用Redis命令,可以使用redis.call函数调用。比如我们调用string类型的命令
redis.call(‘set’,’hello’,’world’)
redis.call 函数的返回值就是redis命令的执行结果。
redis.call函数会将redis的5种类型的返回值转化对应的Lua的数据类型
样redis会自动将脚本返回值的Lua数据类型转化为Redis的返回值类型。
在脚本中可以使用return 语句将值返回给redis客户端,通过return语句来执行,如果没有执行return,默认返回为nil。
监控redis执行的命令
通过redis-cli进入客户端控制台
执行monitor命令进行监控
client list 命令
获取当前连接到redis server端的所有客户端以及相关状态
![]()

flags含义
O: the client is a slave in MONITOR mode
S: the client is a normal slave server
M: the client is a master
x: the client is in a MULTI/EXEC context
b: the client is waiting in a blocking operation
i: the client is waiting for a VM I/O (deprecated)
d: a watched keys has been modified - EXEC will fail
c: connection to be closed after writing entire reply
u: the client is unblocked
U: the client is connected via a Unix domain socket
r: the client is in readonly mode against a cluster node
A: connection to be closed ASAP
N: no specific flag set
查看redis配置命令
ONFIG 命令查看或设置配置项。
CONFIG get * 所有的
CONFIG get XXX
CONFIG set XXX YYY (设置XXX = YYY)
示例
复制代码
#设置配置
config set notify-keyspace-events Egx
#查看配置
config get notify-keyspace-events
#客户端方式
redis-cli config set notify-keyspace-events Egx
#
redis-cli config get notify-keyspace-events
CONFIG SET 命令可以动态地调整 Redis 服务器的配置(configuration)而无须重启,但重启redis后 config set设置的内容将丢失
blpop的问题
在使用 blpop的时候,如果中途因为网络波动或者某些其他原因导致连接池失效,那么就永远接收不到信息了,只需要重新执行 blpop,在执行的瞬间会检查连接的状态,如果连接池有问题,那么它会重新连接。
Redis主动断开空闲连接怎么处理?
使用了阻塞读以后,线程会一直阻塞在那里,如果一直没有数据,这个连接就会成了闲置连接,如果时间过久,Redis会主动断开连接,从而减少闲置资源占用。此时blpop/brpop会抛出异常,所以客户端需要捕捉该异常,并重试。
redis单线程和阻塞
redis是单线程的,那么像BLPOP这种的阻塞命令不会一直占用着线程,其他命令无法执行吗?然而事实上是可以执行的。
对BLPOP命令的处理流程是这样的:
redis先找到对应的key的list,如果list不为空则pop一个数据返回给客户端;
如果list为空,或者list不存在,就将该key添加到一个blockling_keys的字典中,value就是想订阅该key的client链表。此时对应的client的为block状态
当有PUSH 类型的命令进来的时候,先从blocking_keys中查找是否存在对应的key,如果存在就往ready_keys这个链表中添加该key;同时将value插入到对应的list中,并响应客户端。
每次处理完客户端命令后都会遍历ready_keys,并通过blocking_keys找到对应的client,依次将对应list的数据pop出来并响应对应的client;同时检查是否需要再次block。
整个阻塞执行过程相当于是分散开的,每次请求结束后都判断之前的阻塞列表是否满足执行条件,类似我们用轮询来实现长连接的功能。所以看似阻塞的命令对其他命令的执行时不会有影响的,它们依然是单线程的
redis文件事件分配器
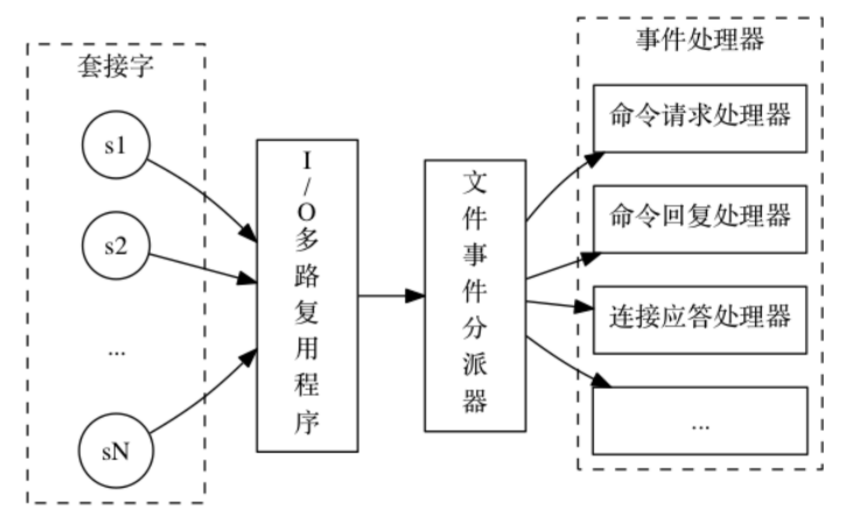
redis的线程模型,是接收客户端命令的线程时 I/O 多路复用的,再通过文件事件分配器单线程执行的。如下图,程序总是会将所有产生事件的套接字都入队到一个队列里面, 然后通过这个队列, 以有序(sequentially)、同步(synchronously)、每次一个套接字的方式向文件事件分派器传送套接字: 当上一个套接字产生的事件被处理完毕之后(该套接字为事件所关联的事件处理器执行完毕), I/O 多路复用程序才会继续向文件事件分派器传送下一个套接字
kill掉应用进程,redis连接会释放吗
这种情况就要考redis自己释放连接了,如果有配置timeout或者keepalive
timeout:client连接空闲多久会被关闭
tcp-keepalive:redis服务端主动向空闲的客户端发起ack请求,以判断连接是否有效,0不会进行Keepalive检测,单位为秒,假如设置为60秒,则server端会每60秒向连接空闲的客户端发起一次ACK请求,以检查客户端是否已经挂掉,对于无响应的客户端则会关闭其连接。所以关闭一个连接最长需要120秒的时间。如果设置为0,则不会进行保活检测。
redisObject
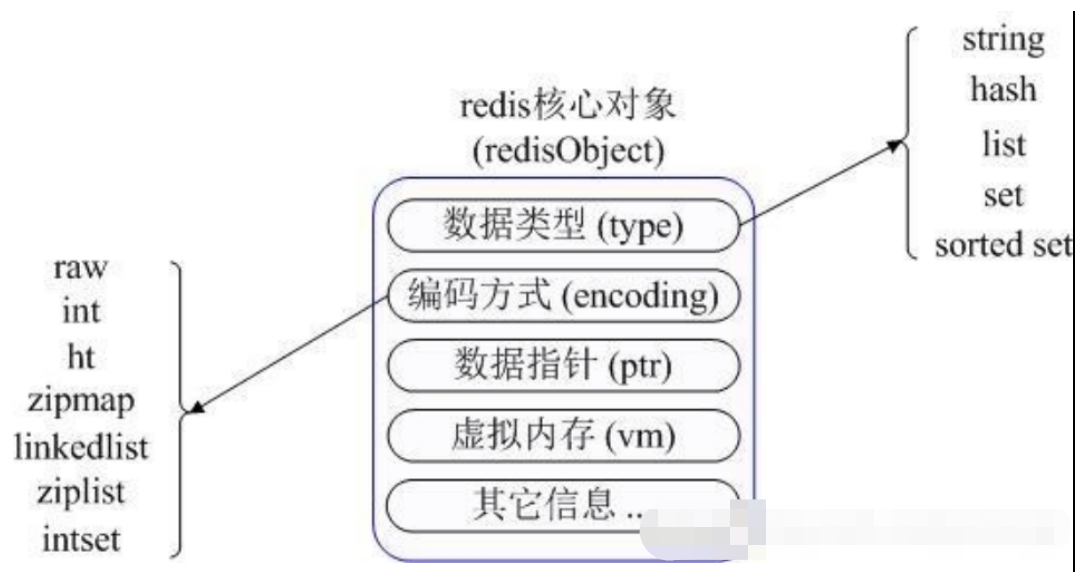
RedisObject包含了:数据结构,编码方式,指针,虚拟内存。
数据类型包括string,hash,list,set,sorted set。编码方式包括raw,int,ht,zipmap,linkedlist,ziplist,intset。
Redis内部使用一个redisObject对象来表示所有的key和value
redis时间复杂度
https://blog.csdn.net/zzm848166546/article/details/80360665

 浙公网安备 33010602011771号
浙公网安备 33010602011771号