kafka总结-spring-kafka
spring-kafka
官网:https://spring.io/projects/spring-kafka/
spring-kafka监听多个topic
消费端代码:
|
@KafkaListener(topics = {"jojo_test","test_jojo"}) public void listen(ConsumerRecord<?,?> consumer){ Optional<?> kafkaMessage = Optional.ofNullable(consumer.value()); if (kafkaMessage.isPresent()) { Object message = kafkaMessage.get(); System.out.println("收到了信息:" + message); } } |
把topic写入到配置文件中:
yml配置文件中:
kafkaTopicName: topic1,topic2
|
@KafkaListener(topics = "#{'${kafkaTopicName}'.split(',')}") public void listeninstances(ConsumerRecord<?, ?> record){ logger.info("----------------- record =" + record); Optional<?> kafkaMessage = Optional.ofNullable(record.value()); if (kafkaMessage.isPresent()) { Object message =kafkaMessage.get(); String topic = record.topic(); logger.info("====topic=="+topic+"========message =" + message); rmbKafkaClientService.loadData2Es(topic,message.toString()); logger.info("----------send-to-es-success--------"); } } |
@KafkaListener注解说明
官网说明地址:
https://docs.spring.io/spring-kafka/api/org/springframework/kafka/annotation/KafkaListener.html
使用方式:
|
@KafkaListener(topics = "xxx") public void testListen(List<ConsumerRecord<xxx, xxx>> records) { ... } |
常用属性:
groupId:覆盖group.id配置
idIsGroup:默认是true,代表如果groupId属性没有提供时,使用id作为groupId
id:指定消费者的group.id,如果其他地方也有配置,这里会覆盖掉其他地方配置的
topics:设置监听的topic,
topicPattern:设置topic模式来监听匹配的topic,该容器会订阅所有匹配到的topic,默认是空字符串
topicPattern详细说明:
根据正则来配置监听的topic
topicPattern 已经会定期检查topic列表,所以新增的匹配到的topic也能被监听到,与topics互斥
topicPartitions详细说明:
与topicPattern及topics互斥
|
@KafkaListener(id = "myContainer1",//id是消费者监听容器 topicPartitions = //配置topic和分区:监听两个topic,分别为topic1、topic2,topic1只接收分区0,3的消息 //topic2接收分区0和分区1的消息,但是分区1的消费者初始位置为5 { @TopicPartition(topic = "topic1", partitions = { "0", "3" }), @TopicPartition(topic = "topic2", partitions = "0", partitionOffsets = @PartitionOffset(partition = "1", initialOffset = "4")) }) |
@KafkaListener原理
@KafkaListener工作流程主要有以下几步:
1.解析:解析@KafkaListener注解。
2.注册:将解析后的数据注册到spring-kafka。
3.监听:开始监听topic消息。
4.调用:调用注解标识的方法,将监听到的数据作为参数传入。
2.1解析
@KafkaListener注解由KafkaListenerAnnotationBeanPostProcessor类解析,后者实现了BeanPostProcessor接口,这个接口如下:
public interface BeanPostProcessor {
Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException;
Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException;
}
可以看到,接口内部有2个方法,分别在bean初始化前后被调用。
KafkaListenerAnnotationBeanPostProcessor类会在postProcessAfterInitialization方法内解析@KafkaListener注解。
2.2注册
在解析步骤中,我们可以获取到所有含有@KafkaListener注解的类,之后这些类的相关信息会被注册到 KafkaListenerEndpointRegistry内,包括注解所在的方法、当前的bean等。KafkaListenerEndpointRegistry这个类内部会维护多个Listener Container,每一个@KafkaListener都会对应一个Listener Container,并且每个Container对应一个线程。
2.3监听
注册完成之后,每个Listener Container会开始工作,会新启一个新的线程,用于初始化KafkaConsumer、监听topic消息等。
2.4调用
监听到数据之后,container会组织消息的格式,随后调用“解析得到的@KafkaListener注解标识的方法”,将组织后的消息作为参数传入方法,执行业务逻辑。
监听消息原理:
也是进行while循环进行拉取消息,没有消息时不进行处理,有消息时触发后续逻辑
批量消费
kafka:
consumer:
max-poll-records: 50
代表一次最多拉取消息的数量,默认是500
拉取数据时机
如果数量没有达到要拉取的条数,也会进行拉取
max.poll.interval.ms参数
用于指定consumer两次poll的最大时间间隔,如果超过了该间隔consumer client会主动向coordinator发起LeaveGroup请求,触发rebalance;然后consumer重新发送JoinGroup请求
默认是5分钟
kafka重复消费
如果一次拉取后消费的时间超过了customer配置的max.poll.interval.ms的值,就会触发rebalance,offset无法提交上去,导致消息的重复消费。
springboot中的配置类
https://github.com/spring-projects/spring-boot/blob/v1.5.9.RELEASE/spring-boot-autoconfigure/src/main/java/org/springframework/boot/autoconfigure/kafka/KafkaProperties.java

一个客户端配置多个消费配置
在消费者的注解上进行配置
消费者数量通常不超过partition数量,一个消费者可以消费多个partition上的数据
AckMode模式

MANUAL:批处理结束时提交偏移量
MANUAL_IMMEDIATE:批量执行的时候逐一提交它们
报错与处理
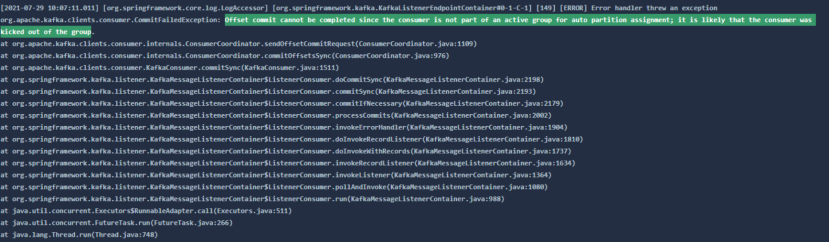
offset提交失败
Offset commit cannot be completed since the consumer is not part of an active group for auto partition assignment; it is likely that the consumer was kicked out of the group

 浙公网安备 33010602011771号
浙公网安备 33010602011771号