【消息队列】为什么kafka效率这么高?
kafka的IO效率这么高的原因:
(1)kafka是顺序写入数据的(数据都是追加到文件末尾),把普通的那种随机IO变成了顺序IO,这样的话写入数据的速度就比较快
(2)kafka读取数据时是基于sendfile实现Zero Copy
磁盘的特性:快速顺序读写、慢速随机读写。因为磁盘是典型的IO块设备,每次读写都会经历寻址,其中寻址中寻道是比较耗时的。随机读写会导致寻址时间延长,从而影响磁盘的读写速度。
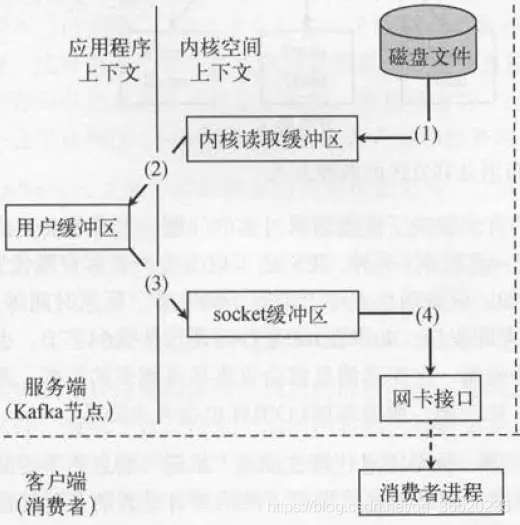
传统的数据读取:
- 基于sendfile调用read函数,文件数据被copy到内核缓冲区
- read函数返回,文件数据从内核缓冲区copy到用户缓冲区
- write函数调用,将文件数据从用户缓冲区copy到内核与socket相关的缓冲区。
- 数据从socket缓冲区copy到相关协议引擎。
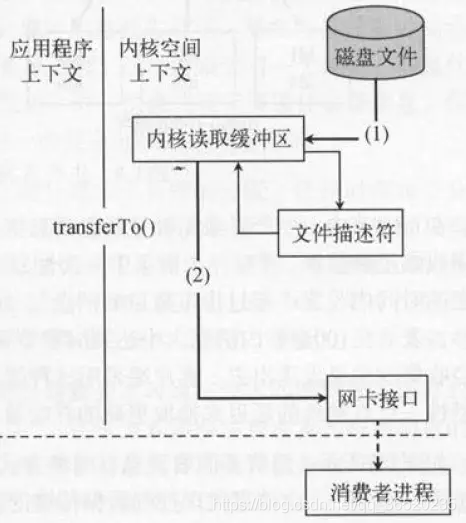
Kafka使用零拷贝的数据读取:
- sendfile系统调用,文件数据被copy至内核缓冲区
- 再从内核缓冲区copy至内核中socket相关的缓冲区
- 最后再将socket相关的缓冲区copy到协议引擎
(3)kafka的数据压缩,Kafka使用了批量压缩,即将多个消息一起压缩而不是单个消息压缩
(4)kafka的生产者在进行生产消息的时候,采用的是批量发送和双线程,其实就是使用了双线程,主线程和Sender线程。
主线程负责将消息置入客户端缓存,Sender线程负责从缓存中发送消息,而这个缓存会聚合多个消息为一个批次。有些消息中间件会把消息直接扔到broker。
|
参考: |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号