组件整合之数据库连接池
什么是数据库连接池
数据库连接池是负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个连接。那么其中的运行机制又是怎样的呢?今天主要介绍一下数据库连接池原理和常用的连接池。
为什么需要数据库连接池
数据库连接是一种关键的有限的昂贵的资源,这一点在多用户的网页应用程序中体现得尤为突出。 一个数据库连接对象均对应一个物理数据库连接,每次操作都打开一个物理连接,使用完都关闭连接,这样会造成系统的性能低下。
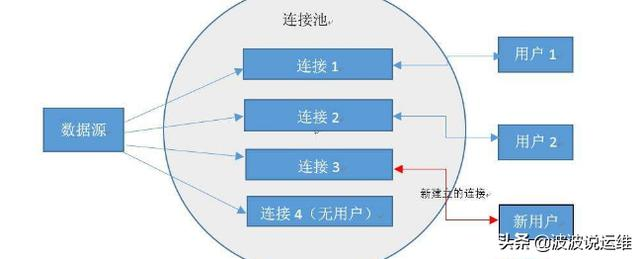
数据库连接池的解决方案是在应用程序启动时建立足够的数据库连接,并讲这些连接组成一个连接池(简单说:在一个“池”里放了好多半成品的数据库连接对象),由应用程序动态地对池中的连接进行申请、使用和释放。对于多于连接池中连接数的并发请求,应该在请求队列中排队等待。并且应用程序可以根据池中连接的使用率,动态增加或减少池中的连接数。
连接池技术尽可能多地重用了消耗内存地资源,大大节省了内存,提高了服务器地服务效率,能够支持更多的客户服务。通过使用连接池,将大大提高程序运行效率,同时,我们可以通过其自身的管理机制来监视数据库连接的数量、使用情况等。
传统的连接机制与数据库连接池运行机制区别
不使用连接池流程
下面以访问MySQL为例,执行一个SQL命令,如果不使用连接池,需要经过哪些流程。
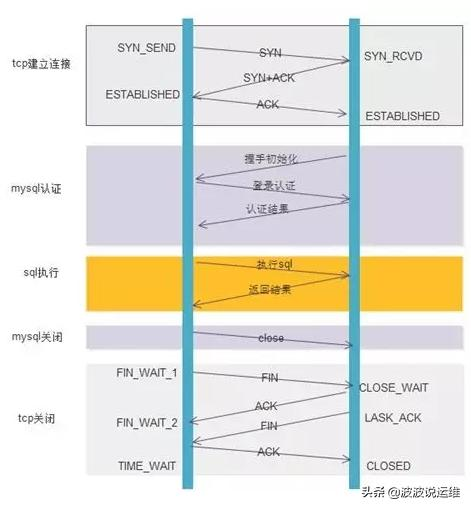
不使用连接池的步骤:
- TCP建立连接的三次握手
- MySQL认证的三次握手
- 真正的SQL执行
- MySQL的关闭
- TCP的四次握手关闭
可以看到,为了执行一条SQL,却多了非常多网络交互。
优点:
- 实现简单
缺点:
- 网络IO较多
- 数据库的负载较高
- 响应时间较长及QPS较低
- 应用频繁的创建连接和关闭连接,导致临时对象较多,GC频繁
- 在关闭连接后,会出现大量TIME_WAIT 的TCP状态(在2个MSL之后关闭)
使用连接池流程

第一次访问的时候,需要建立连接。 但是之后的访问,均会复用之前创建的连接,直接执行SQL语句。
优点:
- 较少了网络开销
- 系统的性能会有一个实质的提升
- 没了麻烦的TIME_WAIT状态
数据库连接池的工作机制
连接池的工作原理主要由三部分组成,分别为:
- 连接池的建立
- 连接池中连接的使用管理
- 连接池的关闭
连接池的建立
一般在系统初始化时,连接池会根据系统配置建立,并在池中创建了几个连接对象,以便使用时能从连接池中获取。连接池中的连接不能随意创建和关闭,这样避免了连接随意建立和关闭造成的系统开销。
Java中提供了很多容器类可以方便的构建连接池,例如Vector、Stack等。
连接池的管理
连接池管理策略是连接池机制的核心,连接池内连接的分配和释放对系统的性能有很大的影响。其管理策略是:
- 当客户请求数据库连接时,首先查看连接池中是否有空闲连接,如果存在空闲连接,则将连接分配给客户使用;如果没有空闲连接,则查看当前所开的连接数是否已经达到最大连接数,如果没达到就重新创建一个连接给请求的客户;如果达到就按设定的最大等待时间进行等待,如果超出最大等待时间,则抛出异常给客户。
- 当客户释放数据库连接时,先判断该连接的引用次数是否超过了规定值,如果超过就从连接池中删除该连接,否则保留为其他客户服务。
该策略保证了数据库连接的有效复用,避免频繁的建立、释放连接所带来的系统资源开销。
连接池的关闭
当应用程序退出时,关闭连接池中所有的连接,释放连接池相关的资源,该过程正好与创建相反。
数据库连接池的注意项
并发问题
为了使连接管理服务具有最大的通用性,必须考虑多线程环境,即并发问题。
这个问题相对比较好解决,因为各个语言自身提供了对并发管理的支持像java,c#等等,使用synchronized(java)lock(C#)关键字即可确保线程是同步的。
事务处理
我们知道,事务具有原子性,此时要求对数据库的操作符合“ALL-OR-NOTHING”原则,即对于一组SQL语句要么全做,要么全不做。
我们知道当2个线程共用一个连接Connection对象,而且各自都有自己的事务要处理时候,对于连接池是一个很头疼的问题,因为即使Connection类提供了相应的事务支持,可是我们仍然不能确定那个数据库操作是对应那个事务的,这是由于我们有2个线程都在进行事务操作而引起的。
为此我们可以使用每一个事务独占一个连接来实现,虽然这种方法有点浪费连接池资源但是可以大大降低事务管理的复杂性。
连接池的分配与释放
连接池的分配与释放,对系统的性能有很大的影响。合理的分配与释放,可以提高连接的复用度,从而降低建立新连接的开销,同时还可以加快用户的访问速度。
对于连接的管理可使用一个List。即把已经创建的连接都放入List中去统一管理。每当用户请求一个连接时,系统检查这个List中有没有可以分配的连接。如果有就把那个最合适的连接分配给他,如果没有就抛出一个异常给用户。
连接池的配置与维护
连接池中到底应该放置多少连接,才能使系统的性能最佳?
系统可采取设置最小连接数(minConnection)和最大连接数(maxConnection)等参数来控制连接池中的连接。比方说,最小连接数是系统启动时连接池所创建的连接数。如果创建过多,则系统启动就慢,但创建后系统的响应速度会很快;如果创建过少,则系统启动的很快,响应起来却慢。这样,可以在开发时,设置较小的最小连接数,开发起来会快,而在系统实际使用时设置较大的,因为这样对访问客户来说速度会快些。最大连接数是连接池中允许连接的最大数目,具体设置多少,要看系统的访问量,可通过软件需求上得到。
如何确保连接池中的最小连接数呢?有动态和静态两种策略。动态即每隔一定时间就对连接池进行检测,如果发现连接数量小于最小连接数,则补充相应数量的新连接,以保证连接池的正常运转。静态是发现空闲连接不够时再去检查。
开源的数据库连接池
dbcp
DBCP(DataBase connection pool)数据库连接池是 apache 上的一个Java连接池项目。
DBCP通过连接池预先同数据库建立一些连接放在内存中(即连接池中),应用程序需要建立数据库连接时直接到从接池中申请一个连接使用,用完后由连接池回收该连接,从而达到连接复用,减少资源消耗的目的。
pom配置
<!--dbcp数据库连接池-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-dbcp2</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.8.0</version>
</dependency>java配置
@Bean
public BasicDataSource dbcpDataSource(){
BasicDataSource dbcpDataSource = new BasicDataSource();
dbcpDataSource.setUrl("jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=false");
dbcpDataSource.setUsername("root");
dbcpDataSource.setPassword("root");
dbcpDataSource.setDriverClassName("com.mysql.jdbc.Driver");
dbcpDataSource.setInitialSize(10);
dbcpDataSource.setMaxIdle(8);
return dbcpDataSource;
}参数说明
| 参数 | 默认值 | 说明 |
| username | \ | 传递给JDBC驱动的用于建立连接的用户名 |
| password | \ | 传递给JDBC驱动的用于建立连接的密码 |
| url | \ | 传递给JDBC驱动的用于建立连接的URL |
| driverClassName | \ | 使用的JDBC驱动的完整有效的Java 类名 |
| connectionProperties | 0 |
当建立新连接时被发送给JDBC驱动的连接参数 格式必须是 [propertyName=property;]* 注意 :参数user/password将被明确传递,所以不需要包括在这里。 |
| defaultAutoCommit | true | 连接池创建的连接的默认的auto-commit状态 |
| defaultReadOnly | 连接池创建的连接的默认的read-only状态 | |
| defaultTransactionIsolation | 连接池创建的连接的默认的TransactionIsolation状态 | |
| initialSize | 0 | 初始化连接:连接池启动时创建的初始化连接数量,1.2版本后支持 |
| maxIdle | 8 | 最大空闲连接:连接池中容许保持空闲状态的最大连接数量,超过的空闲连接将被释放, 如果设置为负数表示不限制 |
| minIdle | 0 | 最小空闲连接:连接池中容许保持空闲状态的最小连接数量,低于这个数量将创建新的连接, 如果设置为0则不创建 |
| maxWait | 无限 | 最大等待时间:当没有可用连接时,连接池等待连接被归还的最大时间(以毫秒计数), 超过时间则抛出异常,如果设置为-1表示无限等待 |
| validationQuery | SQL查询,用来验证从连接池取出的连接,在将连接返回给调用者之前。如果指定, 则查询必须是一个SQL SELECT并且必须返回至少一行记录 |
|
| testOnBorrow | true |
指明是否在从池中取出连接前进行检验,如果检验失败, 注意: 设置为true后如果要生效,validationQuery参数必须设置为非空字符串 |
| testOnReturn | false |
指明是否在归还到池中前进行检验。 注意: 设置为true后如果要生效,validationQuery参数必须设置为非空字符串 |
| testWhileIdle | false |
指明连接是否被空闲连接回收器(如果有)进行检验.如果检测失败, 注意: 设置为true后如果要生效,validationQuery参数必须设置为非空字符串 |
| timeBetweenEvictionRunsMillis | -1 |
在空闲连接回收器线程运行期间休眠的时间值,以毫秒为单位. |
| numTestsPerEvictionRun | 3 |
在每次空闲连接回收器线程(如果有)运行时检查的连接数量 |
| minEvictableIdleTimeMillis | 1000 * 60 * 30 |
连接在池中保持空闲而不被空闲连接回收器线程 |
| poolPreparedStatements | false |
开启池的prepared statement 池功能。 这里可以开启PreparedStatements池. 当开启时, 将为每个连接创建一个statement池 |
| maxOpenPreparedStatements | 不限制 |
statement池能够同时分配的打开的statements的最大数量, |
| accessToUnderlyingConnectionAllowed | false |
控制PoolGuard是否容许获取底层连接 |
| removeAbandoned | false |
标记是否删除泄露的连接,如果他们超过了removeAbandonedTimout的限制。 如果设置为true, 连接被认为是被泄露并且可以被删除,如果空闲时间超过removeAbandonedTimeout 设置为true可以为写法糟糕的没有关闭连接的程序修复数据库连接 |
| removeAbandonedTimeout | 300 | 泄露的连接可以被删除的超时值, 单位秒 |
| logAbandoned | false |
标记当Statement或连接被泄露时是否打印程序的stack traces日志 被泄露的Statements和连接的日志添加在每个连接打开或者生成新的Statement, |
HikariCP
HiKariCP是数据库连接池的一个后起之秀,号称性能最好,可以完美地PK掉其他连接池。
pom配置
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>3.4.5</version>
</dependency>java配置
@Bean
public HikariDataSource hikariDataSource(){
HikariConfig config = new HikariConfig();
config.setJdbcUrl("jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=false");
config.setDriverClassName("com.mysql.jdbc.Driver");
config.setUsername("root");
config.setPassword("root");
config.addDataSourceProperty("cachePrepStmts", "true");
config.addDataSourceProperty("prepStmtCacheSize", "250");
config.addDataSourceProperty("prepStmtCacheSqlLimit", "2048");
return new HikariDataSource(config);
}参数说明
| 参数 | 描述 | 默认值 |
| autoCommit | 自动提交从池中返回的连接 | true |
| connectionTimeout |
等待来自池的连接的最大毫秒数。 说明:如果小于250毫秒,则被重置回30秒 |
30000 |
| idleTimeout |
连接允许在池中闲置的最长时间 。 说明: 如果idleTimeout+1秒>maxLifetime 且 maxLifetime>0, 则会被重置为0(代表永远不会退出);如果idleTimeout!=0且小于10秒,则会被重置为10秒。 |
600000 |
| maxLifetime |
池中连接最长生命周期。 说明:如果不等于0且小于30秒则会被重置回30分钟 |
1800000 |
| connectionTestQuery | 如果您的驱动程序支持JDBC4,我们强烈建议您不要设置此属性 | null |
| minimumIdle |
池中维护的最小空闲连接数 。 说明:minIdle<0或者minIdle>maxPoolSize,则被重置为maxPoolSize |
10 |
| maximumPoolSize |
池中最大连接数,包括闲置和使用中的连接 。 说明: 如果maxPoolSize小于1,则会被重置。 当minIdle<=0被重置为DEFAULT_POOL_SIZE则为10;如果minIdle>0则重置为minIdle的值 。 |
10 |
| metricRegistry | 该属性允许您指定一个 Codahale / Dropwizard MetricRegistry 的实例,供池使用以记录各种指标 | null |
| healthCheckRegistry | 该属性允许您指定池使用的Codahale / Dropwizard HealthCheckRegistry的实例来报告当前健康信息 | null |
| poolName | 连接池的用户定义名称,主要出现在日志记录和JMX管理控制台中以识别池和池配置 | HikariPool-1 |
| initializationFailTimeout | 如果池无法成功初始化连接,则此属性控制池是否将 fail fast | 1 |
| isolateInternalQueries | 是否在其自己的事务中隔离内部池查询,例如连接活动测试 | false |
| allowPoolSuspension | 控制池是否可以通过JMX暂停和恢复 | false |
| readOnly | 从池中获取的连接是否默认处于只读模式 | false |
| registerMbeans | 是否注册JMX管理Bean(MBeans) | false |
| catalog | 为支持 catalog 概念的数据库设置默认 catalog | null |
| connectionInitSql | 该属性设置一个SQL语句,在将每个新连接创建后,将其添加到池中之前执行该语句。 | null |
| driverClassName | HikariCP将尝试通过仅基于jdbcUrl的DriverManager解析驱动程序,但对于一些较旧的驱动程序,还必须指定driverClassName | null |
| transactionIsolation | 控制从池返回的连接的默认事务隔离级别 | null |
| validationTimeout |
连接将被测试活动的最大时间量。 说明:如果小于250毫秒,则会被重置回5秒 |
5000 |
| leakDetectionThreshold |
记录消息之前连接可能离开池的时间量,表示可能的连接泄漏。 说明: 如果大于0且不是单元测试,则进一步判断: (leakDetectionThreshold < SECONDS.toMillis(2) or (leakDetectionThreshold > maxLifetime && maxLifetime > 0), 会被重置为0 . 即如果要生效则必须>0,而且不能小于2秒,而且当maxLifetime > 0时不能大于maxLifetime |
0 |
| dataSource | 这个属性允许你直接设置数据源的实例被池包装,而不是让HikariCP通过反射来构造它 | null |
| schema | 该属性为支持模式概念的数据库设置默认模式 | null |
| threadFactory | 此属性允许您设置将用于创建池使用的所有线程的java.util.concurrent.ThreadFactory的实例。 | null |
| scheduledExecutor | 此属性允许您设置将用于各种内部计划任务的java.util.concurrent.ScheduledExecutorService实例 | null |
Druid
中文文档比较齐全,它的优点在于强大的监控功能,可以清楚的知道连接池和SQL的工作情况,方便扩展。
pom配置
<!-- druid连接池 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.7</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>java配置
@Configuration
public class DataSourceConfig {
@Bean(initMethod = "init", destroyMethod = "close")
public DruidDataSource druidDataSource() throws SQLException {
DruidDataSource druidDataSource = new DruidDataSource();
druidDataSource.setUrl("jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=false");
druidDataSource.setDriverClassName("com.mysql.jdbc.Driver");
druidDataSource.setUsername("root");
druidDataSource.setPassword("root");
druidDataSource.setInitialSize(5);
druidDataSource.setMinIdle(5);
druidDataSource.setMaxActive(50);
druidDataSource.setMaxWait(60000);
druidDataSource.setTimeBetweenEvictionRunsMillis(60000);
druidDataSource.setMinEvictableIdleTimeMillis(300000);
druidDataSource.setTestOnBorrow(true);
druidDataSource.setTestOnReturn(false);
druidDataSource.setTestWhileIdle(false);
druidDataSource.setPoolPreparedStatements(true);
druidDataSource.setMaxPoolPreparedStatementPerConnectionSize(20);
druidDataSource.setFilters("stat,wall,log4j");
druidDataSource.setUseGlobalDataSourceStat(true);
druidDataSource.setValidationQuery("select 1");
return druidDataSource;
}
}参数说明
initialSize:初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时。默认是0.
minIdle:最小连接池数量
maxActive:最大连接池数量,默认是8。
maxWait:获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。
poolPreparedStatements:是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。默认是false。
maxPoolPreparedStatementPerConnectionSize:要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100。默认是-1.
validationQuery:来检测连接是否有效的sql,要求是一个查询语句,常用select 'x'。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会起作用。
validationQueryTimeout:单位:秒,检测连接是否有效的超时时间。底层调用jdbc Statement对象的void setQueryTimeout(int seconds)方法
testOnBorrow:申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。默认true。
testOnReturn:归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。默认false。
testWhileIdle:默认false,建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。
keepAlive:连接池中的minIdle数量以内的连接,空闲时间超过minEvictableIdleTimeMillis,则会执行keepAlive操作。默认false。
timeBetweenEvictionRunsMillis:有两个含义: 1) Destroy线程会检测连接的间隔时间,如果连接空闲时间大于等于minEvictableIdleTimeMillis则关闭物理连接。 2) testWhileIdle的判断依据,详细看testWhileIdle属性的说明。默认1分钟。
minEvictableIdleTimeMillis:连接保持空闲而不被驱逐的最小时间
connectionInitSqls:物理连接初始化的时候执行的sql
filters:属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有: 监控统计用的filter:stat 日志用的filter:log4j 防御sql注入的filter:wall
proxyFilters:类型是List<com.alibaba.druid.filter.Filter>,如果同时配置了filters和proxyFilters,是组合关系,并非替换关系配置Druid的内置监控
(1) 添加druid监控
@WebServlet(name = "statViewServlet", urlPatterns = "/druid/*", asyncSupported = true,
initParams = {
@WebInitParam(name = "allow", value = "127.0.0.1"), //设置ip白名单
@WebInitParam(name = "deny", value = "192.168.0.19"),//设置ip黑名单,如果allow与deny共同存在时,deny优先于allow
@WebInitParam(name = "loginUsername", value = "root"),//设置控制台管理用户
@WebInitParam(name = "loginPassword", value = "123123"),
@WebInitParam(name = "resetEnable", value = "false")//是否可以重置数据
})
public class DruidStatViewServlet extends StatViewServlet {
}(2)添加web监控(对站点的URL进行统计)
@WebFilter(filterName = "statFilter", urlPatterns = "/*", initParams = {
@WebInitParam(name = "exclusions", value = "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*")}) //忽略过滤的形式
public class DruidWebStatFilter extends WebStatFilter {
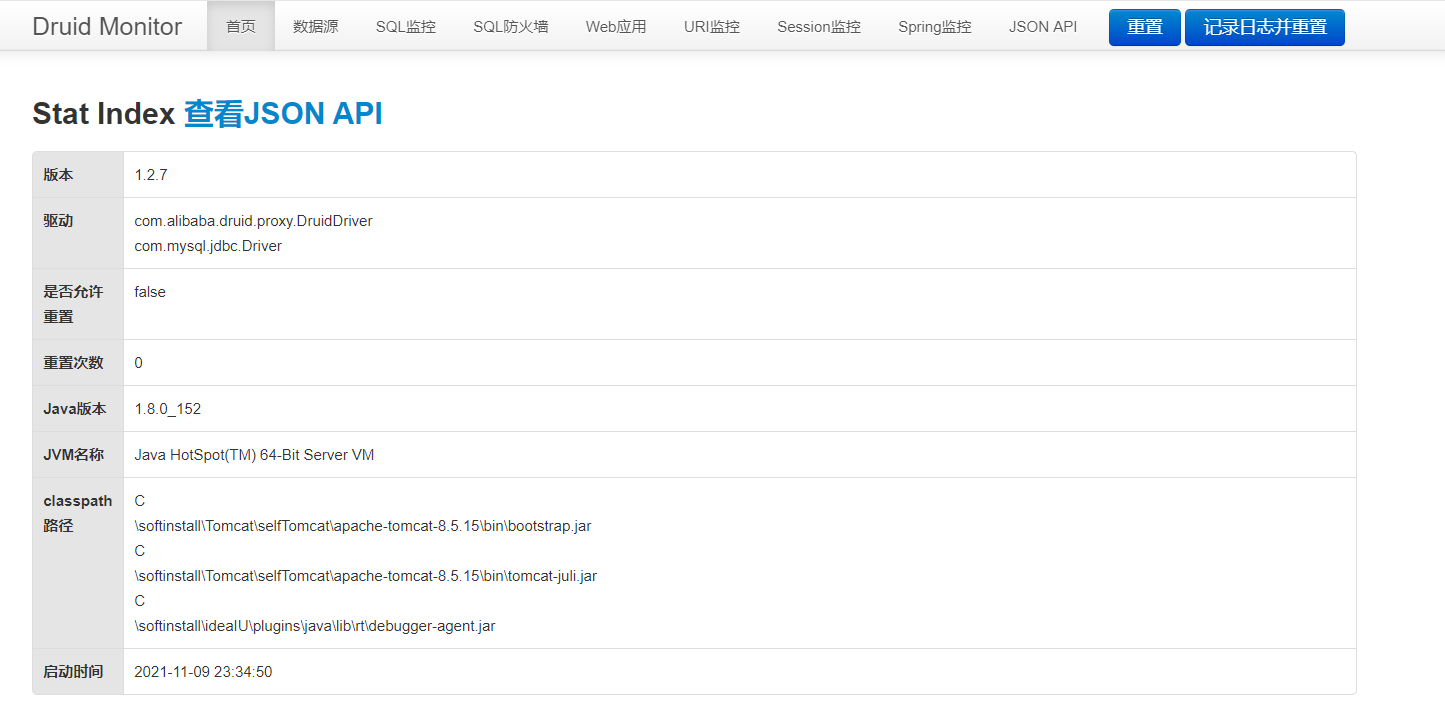
}(3)访问:http://localhost:8888/druid/login.html,密码是在代码中设置的root/123456,页面如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号