

Python 学习笔记
Python 学习笔记
1、Python脚本
1.1脚本.py
hello.py
#code:utf-8 # 以下空一行
import os # 以下空两行
print(os.getcwd())
print('欢迎大家')
print('来到python世界')`# 最后也要空一行
虽然空行对程序的运行没有影响,但是好的编程习惯还是要有的。
执行脚本指令:
python hello.py
python是指Python编译器
1.2 头注释-#
非必须,但是要了解
# coding:utf-8
1.3导入-import
导入是将Python的一些功能函数放到当前的脚本中使用。
import os
1.4代码中的注释
三种注释
# 这里是注释(#之后有两个空格)
“”“
可以多行注释
”“”
‘’‘
跟双引号一样,多行注释
’‘’
1.5脚本入口main
__name__ =='__main__'
__name__指代本脚本的名字
1.6 变量名
a.由英文字母数字和下划线组成
b.不能由数字开头,可以由下划线开头
c.变量名要有实际意义
1.7Python中的关键字
强关键字(不能使用来作为变量使用)
弱关键字(某些不冲突的情况下可以使用作为变量等使用)
- 强关键字:除了常见的if、else、false、true等与其他语言一样的关键字,还有如下表(部分)
| 关键字 | 含义 |
|---|---|
| def | 定义函数 |
| is | 判断变量是否市某个类的实例 |
| not | 逻辑运算,非 |
| or | 逻辑运算,或 |
| pass | 无意义,站位字符,什么都不做 |
| raise | 主动抛出异常 |
| in | 判断变量是否在序列中 |
| with | 简化Python语句 |
| yield | 从循环或函数依次返回数据 |
| import | 导入语句 |
2、Python数据类型
2.1数据类型
| 数据类型 | |
|---|---|
| 数字类型 numbers | |
| 字符串类型 string | |
| 布尔类型 bool | |
| 空类型 None | |
| 列表类型 list | |
| 元组类型tuple | |
| 字典类型dict |
2.1.1数字类型
- 整型 int
- 浮点型 float
- 内置函数 type : 返回变量的类型
count_100_01 = int(100)
count_100_01 = 100
注:Python2中曾经有long整型,在Python3之后就废弃了
pi_01 = float(3.14)
pi_02 = 3.14
print(type(pi_02))
2.1.2字符串类型
字符串的重要思想:字符串不可改变
重要的内置函数:
- id:返回变量的内存地址 id(变量)
- len:返回字符串的长度 len(字符串)
- in:判断成员内是否含有某个元素
- max:返回数据中最大的成员 max(数据)
- min: 返回数据中最小的成员 min(数据)
重要的知识点:
先看代码
str_01 = '这是str1'
str_02 = '这是str2'
str_03 = str_01
print(id(str_01))
print(id(str_03))
str_04 = 'this is a "string" test'
str_05 = “this is a 'string' test”
- str_03和str_01的内存地址是一样的,所以可以看出,行3的赋值代码并不是重新开了一个内存,而是引用了str_01的内存,指向同一内存,所以如果修改str_01的值,str_03的值也会变。
- 如果字符串中有引号,则在字符串中使用与外侧不同的引号,str_04和str_05的字符串能正常输出。
2.1.3布尔类型和空类型
- 真true
- 假false
- 空类型:不属于任何数据类型
空类型:固定值None
2.1.4列表类型list
列表就是队列,是各种数据类型的集合,也是一种数据结构。在Python中,列表是一个无限制长度的数据结构。
列表定义:
- 使用list()
names_01 = list(['hongyun', '小雪', 'hongyun', 'Howardy'])
- 使用[]
names_02 = ['hongyun', 12, None, 'Howardy']
知识点:
none_list = [None, None, None]
这里的none_list长度为3,而不是0,只有这样none_list = []才是0。
2.1.5元组类型
元组与列表一样,都是一种可以储存多种数据结构的队列,也是有序,且元素可以重复的集合。
定义元组:
- 使用tuple()
name_01 = tuple(('hongyun', '中文'))
- 使用()
name_02 = ('hongyun', '中文')
name_03 = ('hongyun', ) # 如果只有一个元素,需要在后面加一个逗号
注:如果只有一个元素,不在后加逗号,那么这个元组就不是元组了,而是与该元素的类型一致。比如上面name_03的元素为字符串,那么id(name_03)也返回的是字符串,而不是元组。
列表与元组的区别:
- 元组比列表占用资源更小;
- 列表是可变的,元组是不可变的。
none_tuple = (None, None, None) # 空类型元组
tuple_tuple = ((1, 2, 3), (4, 5, 6)) # 元组中的元素也是元组
list_tuple = ([1, 2, 3], [2, 3, 4]) # 列表作为元素
mix_tuple = ('hong', 2, 3.14, None, False) # 多数据类型元组
2.1.6字典类型
字典是由多个键(key)及其对应的值(value)所组成的一种数据类型。
创建字典:
使用dict()创建,{}中存入内容
a = dict()
a = {'name': 'hongyun', 'age': 22}
知识点:
- key支持字符串,数字和元组类型,不支持列表
- value支持所有的Python数据类型
- 字典中的每一个key都是唯一的
Python3.7与之前版本字典的区别:
3.7之前的版本的字典是无序的,之后是有序的。
2.2 运算
2.2.1赋值运算
除了常规的运算之外,还有如下运算:
| 运算符 | 描述 | 使用 |
|---|---|---|
| % | 取模运算符 | c %=a |
| ** | 幂运算符 | c **=a -->c=c **a |
| // | 整除运算符 | c //= a |
字符串与数字的乘法:
字符串无法与字符串相乘,字符串只可以和数字做乘法。
name = 'hy'
print(name*3)
'hyhyhy'
同理,列表和元组可以与数字相乘,但不能跟字典相乘。需要注意的是,列表和元组与数字相乘之后得到的是新的列表和元组。
2.2.2比较运算符
除了常规的比较运算符,还有如下的身份运算符:
| 运算符 | 描述 | 使用 |
|---|---|---|
| is | 判断两个对象存储单元是否相同 | a is b |
| is not | 判断两个对象存储单元是否不同 | a is not b |
3、字符串
3.1 字符串的内部函数
3.1.1 capitalize()
功能:将字符串的首字母大写,其他字母小写
使用方法:newstr = str.capitalize()
注意事项:
- 只对第一个字母有效
- 只对字母有效
3.1.2 lower()和upper()
功能:lower()是将字符串中的大写字母变成小写字母,upper()则是反过来。
与lower()功能相同的函数还有casefold(),casefold()是Python3.3才引入的,能适应更多语种的大小写转化,比如德语字母。
newstr = str.lower()
newstr = str.upper()
3.1.3 swapcase()
功能:将字符串中的小写字母转换成大写字母,大写字母转换成小写字母。
newstr = str.swapcase()
3.1.4 zfill()
功能:为字符串定义长度,如果不满足,缺少的部分使用0填充,0补充在字符串前
使用方法:
new = str.zfill(width) # 参数width:新字符串的宽度
3.1.5 count()
功能:返回当前字符串中某个成员(元素)的个数,如果不存在,则返回0。
用法:int_type = string.count(item) # item:需要查询的元素
3.1.6 starswith()和endswith()
功能:分别判断字符串开始和结尾是否是某成员(元素)
使用:
string.startswith(item) # item:需要查询的元素,返回布尔值
string.endswith(item) # item:需要查询的元素,返回布尔值
3.1.7 find()和index()
功能:两者都是返回想要寻找成员的位置
使用:
string.find(item) # item:想要查询的元素,函数返回一个整型
string.index(item) # item:想要查询的元素,函数返回一个整型或者报错
注意事项:
- 如果find找不到元素,会返回-1;
- 如果index找不到元素,会导致程序报错
3.1.8 strip()
功能:去掉字符串左右两边的指定元素,默认是空格
使用:
newstr = string.strip(item) # item可填可不填,不填默认为空格
注:
传入的元素如果不在开头或则结尾则无效
lstrip 仅去掉字符串开头的指定元素或空格
rstrip 仅去掉字符串结尾的指定元素或空格
3.1.9 replace()
功能:将字符串中的old(旧元素)替换成new(新元素),并指定替换的数量
使用:
newstr = string.replace(old, new, max)
参数:
old:被替换的元素
new:替代old的新元素
max:可选参数,表示替换几个,默认全部全部替换匹配的元素
3.1.10 字符串中返回bool的函数集合
| 函数名 | 功能 |
|---|---|
| isspace | 判断字符串是否是一个由空格组成的字符串 |
| istitle | 判断字符串是否是一个标题类型(即字符串是英文字母,且每个单词首字母大写) |
| isupper | 判断字符串中的字母是否都是大写 |
| islower | 判断字符串中的字母是否都是小写 |
| join | |
| split |
3.2 字符串其他操作
3.2.1 字符的编码格式
编码格式:编码是用预先规定的方法将文字、数字、其他特殊字符等编成数码,或将信息、数据转换成规定的脉冲信号。
常见的标准化编码格式:
- GBK中文编码
- ASCII英文编码
- utf-8 一种国际通用的编码格式
3.2.2 字符串的格式化
格式化:一个固定的字符串中有部分元素是根据变量的值而改变的。
根据类型定义的格式化:
- 字符串格式化使用操作符%来实现
'my name is %s, my age is %s' % ('hongy', 22)
%s 是python的通用格式化类型
- 使用{}代替格式符
str1 = 'my name is {}, my age is {}'
print(str1.format('hongy', 22))
-
python3.6加入新的格式化方法——f-strings
str2 = f 'my name is {name_01}, my age is {age_01}'{}内必须是变量,比如直接写'hongy'是不可行的
| 符号 | 说明 |
|---|---|
| %s | 格式化字符串,通用类型 |
| %d | 格式化整型 |
| %f | 格式化浮点型 |
| %u | 格式化无符号整型 |
| %c | 格式化字符 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号16进制数 |
| %e | 科学计数法格式化浮点数 |
3.2.3 转义字符
| 符号 | 说明 |
|---|---|
| \n | 换行,一般用于末尾,strip对其他有效 |
| \t | 横向制表符 |
| \v | 纵向制表符 |
| \a | 响铃 |
| \b | 退格符,将光标前移,覆盖(删除前一个) |
| \r | 回车 |
| \f | 翻页 |
\' |
转义字符的单引号 |
\" |
转义字符的双引号 |
\\ |
转义斜杠 |
4、Python列表
4.1 列表常用方法
4.1.1 append()
功能:将一个元素添加到当前列表中
使用:list.append(new_item)
注意事项:
- 被添加元素只会被添加到末尾
- append函数是在原有列表的基础上添加,不需要额外添加新的变量
- append只能添加一个元素
4.1.2 insert()
功能:将一个元素添加到当前列表指定的位置。
使用:
list.insert(index, new_item) # index:添加的位置 new_item:添加的新元素
注意事项:
- 如果insert传入的位置在列表中不存在,则将新元素添加到列表的末尾
4.1.3 列表/元组的count()
功能:返回列表/元组的需要查询元素的个数,列表和元组使用完全一样。
使用:
inttype = list.count(item)
inttype =tuple.count(item)
注意事项:
- 如果查询的成员不在,则返回0
4.1.4 remove()与del
功能:删除列表中的某个元素
使用:list.remove(item)
注意事项:
- 如果删除的成员(元素)不存在,则会直接报错
- 如果删除的元素有多个,只会删除第一个
- 不会返回一个新的列表,而是在原来的列表中对元素进行删除
del:直接把变量完全删除
del的使用
drinks = ['雪碧', '可乐', '王老吉']
del drinks
print(drinks) # 运行后报错,name 'drinks' is not defined
4.1.5 reverse()
功能:对当前列表顺序进行翻转
使用:list.reverse()
4.1.6 sort()
功能:对当前列表按一定的规律排序
使用:list.sort(key = None, reverse = False)
参数:key - 参数比较
reverse -- 排序规则,True为降序,False为升序(默认)
注意事项:
- 列表中的元素类型必须形同,否则无法排序(报错)
4.1.7 clear()
功能:将当前列表中的数据清空
使用:list.clear()
4.1.8 copy()以及深浅拷贝
功能:将当前列表复制得到一份新的列表,新列表与旧列表内容相同,但内存空间不一样(即地址不一样)
使用:list.copy()
浅拷贝:有一个列表a,其里面的元素还是列表,当我们拷贝出新列表b后,无论a还是b的内部的列表中的数据发生变化之后,相互之间会受到影响
copy()属于浅拷贝
比如:
a = [[1, 2, 3], [4, 5, 6]]
b = a.copy()
b[0].append(10)
print(b) # [[1, 2, 3, 10], [4, 5, 6]]
print(a) #[[1, 2, 3, 10], [4, 5, 6]]
注:list深层次的数据还是会相互影响的,只在第一层数据之间不影响
深拷贝:不仅是第一层数据进行了copy,对深层次的数据也进行了copy,原始变量和新变量完完全全不共享数据
a = [[1, 2, 3], [4, 5, 6]]
b = copy.deepcopy(a)
b[0].append(10)
print(b) # [[1, 2, 3, 10], [4, 5, 6]]
print(a) #[[1, 2, 3], [4, 5, 6]]
4.1.9 extend()
功能:将其他列表/元组中的元素导入到当前列表中
使用:list.extend(iterable) # 参数iterable代表列表/元组,该函数无返回值
stu = ['小明', '小雪', '小红']
new_stu = ['老高', '小潘']
stu.extend(new_stu)
print(stu) # ['小明', '小雪', '小红', '老高', '小潘']
4.2 索引与切片
索引从最左边开始记录的位置,用数字表示,起始从0开始。超出索引范围,会报错。
索引用来对单个元素进行访问,而切片则是对一定范围内的元素进行访问。
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 0]
print(numbers[3:8]) # [4, 5, 6, 7, 8]
print(numbers[:]) # 完整列表
print(numbers[0,:]) # 完整列表
print(numbers[::-1]) # 反序
print(numbers[0:8:2]) # 指定步长 [1, 3, 5, 7]
print(numbers[0:0]) # 切片生成空列表
切片规则:左含,右不含。所以上面例子1不打印9。
- index():
list.index(item) # 返回item所在的索引值,如果没有该元素则报错
- pop():通过索引删除并获取列表的元素
list.pop(index) # 删除列表index索引位置的元素,并将元素值返回,如果不存在index索引则报错
- del:删除索引位置的元素
del list[index] # 直接删除,没有返回值
注意事项:
- 元组可以和列表一样获取索引与切片
- 元组函数index和列表使用完全一样
- 无法通过索引修改、删除元素
4.2.1 字符串索引
name = 'hongyun'
print(name[0]) # h
print(name[:2]) # ho
注:
- 切片和索引获取的内容方式与列表相同
- 无法通过索引修改与删除内容
- 字符串可不修改
4.2.2 字符串的find与index函数
功能:都是获取元素的位置
使用:
string.index(item) # item查询的元素,返回索引位置
string.find(item) # item查询的元素,返回索引位置
info = 'my name is hongyun'
print(info.index('hongyun')) # 11
print(info.find('hongyun')) # 11
find与index的区别:
- find如果获取不到,返回-1
- index如果获取不到,直接报错
4.3 字典
4.3.1 字典常用方法
[]处理方法
- 字典没有索引
- 通过键key来获取相应的值
- 是 添加 还是 修改,由key是否存在决定
update函数:
用法:dict.update(new_dict) # 无返回值,new_dict是一个新字典
注:若dict中有new_dict中的key,则修改对应的值,如没有,则添加相应的键值。
user = {'username': 'hongyun', 'age': 23}
yuchen = {'username': 'yuchen', 'age': 22, 'high': 175}
user.update(yuchen)
print(user) # {'username': 'yuchen', 'age': 22, 'high': 175}
setdefault函数:
用法:dict.setdefault(key, value)
参数: key-需要获取的key
value-如果key不存在,对应key存入字典的默认值
4.3.2 字典的keys函数
功能:获取当前字典中所有的键key
使用:dict.keys() # 无参数,返回一个key集合的伪列表
伪列表:看似列表,但不具备列表功能
my_dict = {'name': 'hongyun', 'age': 23}
my_dict.keys() #伪列表dict_keys(['name', 'age'])
key_list = list(my_dict.keys()) #列表['name', 'age']
4.3.3 字典的values函数
功能:获取当前字典中所有键值对中的值(value)
使用:dict.values() # 无参数,返回一个value集合的伪列表
4.3.4 字典获取key对应的value
两种方法获取key对应的value:
my_dict = {'name': 'hongyun', 'age': 23}
age = my_dict['age'] # 23 方法一 []
age = my_dict.get('age') # 23 方法二 get
[]与get的区别:
- []如果获取key是不存在的,则直接报错
- get如果获取key是不存在的,则返回默认值
所以在开发中,优先使用get函数。
4.3.5 字典的删除
- clear函数:
dict.clear() # 无参数,无返回值。对dict进行清空,删除所有键值对
- pop函数:
dict.pop(key) # key:希望被删除的键, 函数返回key对应的value
- del:
my_dict = {'name': 'hongyun', 'age': 23}
del my_dict['name'] #删除my_dict字典中的name
del my_dict # 直接删除my_dict字典
4.3.6 copy
使用:
dict.copy() # 无参数,返回一个一样的字典,但是内存地址不同
4.3.7 popitem
功能:删除当前字典里末尾一组键值对并将其返回
使用:dict.popitem() # 无参数
说明:函数删除最后一组键值对,并返回,返回值用元组包裹,索引0是key,索引1是value
注意事项:
如果字典为空,则直接报错
4.4 集合
什么是集合:
- 集合是一个无序的不重复的元素序列
- 常用来对两个列表进行交并差的处理
- 集合和列表一样支持所有数据类型
集合与列表的区别:
| 功能 | 列表 | 集合 |
|---|---|---|
| 顺序 | 有序 | 无序 |
| 内容 | 可重复 | 不可重复 |
| 功能 | 用于数据的使用 | 用于数据的交集并集差集的获取 |
| 索引 | 可索引 | 无索引 |
| 符号 | [] [1, 2, 3] | { } |
集合的创建:使用set函数来创建集合,不能使用{}来创建空集合
a_set = set() # 空集合
b_set = set([1,2,3]) # 传入列表或者元组
c_set = set{1, 2, 3} # 传入元素
d_set = {} #错误的方法,得到的不是空集合,而是空字典
4.4.1 集合的增删改
- add函数
set.add(item) # item:要添加到集合中的元素,无返回值
注意:如果item已经存在set中了,则add无效,因为集合元素是不可重复的
- update函数
功能:加入一个新的集合(或列表、元组、字符串),如新集合内的元素在原集合中存在则无视
使用:
set.update(iterable) # iterable:集合、列表元组或字符串 ,无返回值,直接作用于原集合
- remove函数
set.remove(item) # item:当前集合中的一个元素,无返回值,作用于原集合
- clear函数
功能:清空当前集合的所有元素
使用:
set.clear() # 无参数,无返回值,直接作用于原集合
- del函数
a_set = {1, 2, 3}
del a_set # 直接删除集合a_set,内存中也不再有a_set,所以print(a_set)会报错
集合的重要说明:
- 集合无法通过索引获取元素
- 集合无获取元素的方法
- 集合只是用来处理列表或元组的一种临时类型,不适合存储与传输
4.4.2 集合的差集
difference函数
功能:返回集合的差集,即返回的集合元素在第一个集合中,但不包含在第二个集合(方法参数)中。
使用:
a_set.difference(b_set) #b_set:当前集合需要对比的集合,返回两个集合的差集
4.4.3 集合的交集
intersection函数
功能:返回两个或多个集合中都包含的元素,即交集
使用:
a_set.intersection(b_set...) #b_set...:与当前集合对比的1个或多个集合
返回值:返回原始集合与对比集合的交集
4.4.4 集合的并集
union函数
使用:
a_set.union(b_set...) # b_set...:与当前集合对比的1个或多个集合
返回值:返回原始集合与对比集合的并集
4.4.5 判断两个集合中是否有相同的元素
isdisjoin函数
功能:判断两个集合是否包含相同的元素,如果没有返回True,否则返回False。
使用:
a_set.isdisjoin(b_set) # 如果没有相同元素返回True,否则返回False
4.5 Pyhon不同数据类型之间的转换
4.5.1 字符串与数字之间的转换
| 原始类型 | 目标类型 | 函数 | 举例 |
|---|---|---|---|
| 整型 | 字符串 | str | new_str = str(1234) |
| 浮点型 | 字符串 | str | new_str = str(3.14159) |
| 字符串 | 整型 | int | new_int = int('12') |
| 字符串 | 浮点型 | float | new_float = float('1.234') |
注意事项:
- 字符串 -> 数字 要求字符串中除小数点外必须只包含数字,不包含其他字符
4.5.2 字符串与列表之间的转换
split函数
功能:将字符串以一定规则切割成列表
使用:
string.split(seq = None, maxsplit = -1)
参数: seq -> 切割的规则符号,不填写,默认为空格,如果字符串没有空格,则不分割成列表
注意:seq不能传空字符
maxsplit -> 根据切割符号切割的次数,默认-1无限制
返回值:返回一个列表
info = 'my name is hongyun'
info_list = info.split()
print(info_list) # ['my', 'name', 'is', 'hongyun']
join函数
功能:将列表以一定的规则转换成字符串
使用:
'seq'.join(iterable)
参数:seq -> 生成字符串用来分割列表每个元素的符号
iterable -> 非数字类型的列表或元组或集合
返回值:返回一个字符串
test_list = ['a', 'b', 'c']
new_str = '.'.join(test_list)
print(new_str) # 'a.b.c'
test2_list = [1, 2, 3]
print('|'.join(test2_list)) # 编译器报错,因为list元素如果是数字,不能进行转换
报错:TypeError: sequence item 0: expected str instance, int found
Python内置函数---sorted() 对任意类型进行排序
sort_str = 'abdfigej'
res = sorted(sort_str)
print(''.join(res)) # abdefgij
4.5.3 字符串与bytes通过编解码进行转换
比特类型:
- 二进制的数据流---bytes
- 一种特殊的字符串
- 字符串前+b标记
bt = b'my name is hongyun'
print(type(bt)) # <class 'bytes'>
print(bt.capitalize()) # b'My name is hongyun'
print(bt.replace(b'hongyun', b'Howardy')) # b'my name is Howardy'
print(bt[0]) # 109
print(bt[:2]) # b'my'
print(bt.find(b'n')) # 3
print(dir(bt)) # 打印bytes类型所有的属性和内置函数
# ['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'center', 'count', 'decode', 'endswith', 'expandtabs', 'find', 'fromhex', 'hex', 'index', 'isalnum', 'isalpha', 'isascii', 'isdigit', 'islower', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
chinese_str = b'hello 小雪'
print(chinese_str) # 报错,只能包含ASCII,不能包含中文
# SyntaxError: bytes can only contain ASCII literal characters.
字符串转bytes的函数---encode 编码
使用:
string.encode(encoding = 'utf-8', errors = 'strict')
参数:encoding -> 转换成的编码格式,如ascii,gbk 默认为utf-8
errors -> 出错时的处理方法,默认strict,直接抛出错误,也可以选择ignore忽略错误
返回值:返回一个bytes类型
str_data = 'my name is 荷叶'
byte_data = str_data.encode('utf-8')
print(byte_data) # b'my name is \xe8\x8d\xb7\xe5\x8f\xb6'
bytes转字符串的函数---decode 解码
使用:
string.decode(encoding = 'utf-8', errors = 'strict')
参数:encoding -> 转换成的编码格式,如ascii,gbk 默认为utf-8
errors -> 出错时的处理方法,默认strict,直接抛出错误,也可以选择ignore忽略错误
返回值:返回一个字符串类型
str_data = 'my name is 荷叶'
byte_data = str_data.encode('utf-8')
print(byte_data) # b'my name is \xe8\x8d\xb7\xe5\x8f\xb6'
print(byte_data.decode('utf-8')) # 'my name is 荷叶'
4.5.4 列表、集合、元组的转换
| 原始类型 | 目标类型 | 函数 | 举例 |
|---|---|---|---|
| 列表 | 集合 | set | new_set = set([1, 2, 3, 4]) |
| 列表 | 元组 | tuple | new_tuple = tuple([1, 2, 3]) |
| 元组 | 集合 | set | new_set = set((1, 2, 3)) |
| 元组 | 列表 | list | new_list = list((1, 2, 3)) |
| 集合 | 列表 | list | new_list = list({1, 2, 3}) |
| 集合 | 元组 | tuple | new_tuple = tuple({1, 2, 3}) |
5、Python流程控制
5.1 条件
用法:
if bool_result:
do something
elif bool_result:
do something
else:
do otherthing
5.2 for循环
用法:
for item in iterable:
do something(item)
list_tem = ['lihua', 'wanger', 'lisi', 'zhangsan']
for item in list_tem:
print(item)
字典利用items函数进行for循环
功能:将字典转换成伪列表,每个key,value转成元组
使用:
for key, value in dict.items():
print(key, value)
users = {'name': 'hongyun', 'age': 24}
items = users.items()
print(items) # dict_items([('name', 'hongyun'), ('age', 24)])
for key, value in items:
print(key, value)
'''
name hongyun
age 24
'''
Python的内置函数---range
功能:返回的是一个一定范围内的可迭代对象,元素为整型,他不是列表,无法打印信息,但可循环
使用:
for item in range(start, stop, step = 1):
print(item)
参数:start -> 开始的数字,类似索引的左边
stop -> 结束的数字,类似索引的右边
step -> 跳步,类似索引中的第三个参数
else在for循环中的使用
l = range(5)
for item in l:
print(item)
else:
print('循环结束')
'''
0
1
2
3
4
循环结束
'''
5.3 while循环
用法:
while bool_result:
do something
6、函数
6.1 函数的定义与使用
内置函数
自定义函数
6.1.1 函数的定义
def name(args...):
do something
返回值
6.1.2 函数参数
- 必传参数:
在定义函数的时候,没有默认且必须在函数执行的时候传递进去的参数,且顺序与参数顺序相同。
- 默认参数:
在定义函数的时候,定义的参数含有默认值,通过赋值语句给他的是一个默认值。
def add(a, b = 1) # b是默认参数,默认值为1,a为必传参数
- 可变参数:
没有固定的参数名和数量
def add(*args, **kwargs):
......
add(1, 2, 3, name = 'hongyun', age = 23)
1, 2, 3 对应*args
name = 'hongyun', age = 23 对应**kwargs
*args:将无参数的值合并成元组
**kwargs:将有参数与默认值的赋值语句合并成字典
参数规则:
def funcname(a, b =1, *args, **kwargs):
参数的定义从左到右依次是 必传参数,默认参数,可变元组参数,可变字典参数
4.1.3 函数参数类型定义
注:参数定义在python3.7之后可用
def person(name:str, age:int = 23):
print(name, age)
必传参数:参数名+:+类型函数
默认参数:参数名+:+类型函数+=+默认值
函数不会对参数类型进行验证
4.1.4 变量
局部变量
全局变量
global:
name = 'hongyun'
def test():
global name
name = 'limei' # 函数体内给全局变量重新赋值
global传递的变量只支持数字,字符串,空类型以及bool类型,如果要使用全局变量的字典,元组,列表是不需要使用global的,可直接使用。
4.1.5 递归函数
一个函数不停的将自己反复执行
def test(a):
print(a)
return test(a)
递归函数的说明:
- 防止内存溢出
- 避免滥用递归
4.1.6 匿名函数lambda
匿名函数:
- 定义一个轻量化的函数
- 即用即删除,很适合需要完成一项功能,但此功能只在此处使用
f = lambda : value # 无参数
f()
lambda x, y: x*y # 有参数
f(3,4)
user = [
{'name': 'hongyun'},
{'name': 'dejiang'},
{'name': 'awei'}
]
user.sort(key = lambda x: x['name'])
print(user)
7、面向对象
7.1 初识面向对象
7.1.1 什么是面向对象编程
面向对象编程:
- 利用(面向)对象(属性与方法)去进行编码的过程
- 自定义对象数据类型就是面向对象中的class类的概念
7.1.2 类的定义和使用
class Name(object):
attr = something
def func(self):
do
class Person(object):
name = 'hongyun'
def dump(self):
print(f'{self.name} is dumping')
hy = Person()
print(hy.name)
hy.dump()
7.1.2 类的参数self
self是类函数中的必传参数,且必须放在第一个参数位置
self是一个对象,它代表实例化的变量自身
self可以直接通过点来定义一个类变量 self.name = 'hhio'
self中的变量与含有self参数的函数可以在类中任何一个函数中随意调用
非函数中定义的变量在定义的时候不用self
7.1.3 类的构造函数
构造函数:类中的一种默认函数,用来将类实例化的同时,将参数传入类中
构造函数的创建:
def __init__(self, a , b):
self.a = a
self.b = b
7.1.4 对象的生命周期
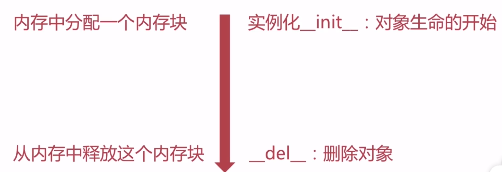
7.1.5 私有函数和私有变量
定义方法:
在变量或函数前添加__(2个下划线),变量或函数名后无需添加
class Person(object):
def __init__(self, name):
self.name = name
self.__age = 23
def dump(self):
print(self.name, self.__age)
def __cry(self):
return 'I am crying, missing my lover'
7.1.6 装饰器
装饰器:也是一种函数;可以使用函数作为参数,也可以返回函数;接收一个函数,内部对其进行处理,然后返回一个新函数,动态地增强函数功能;将c函数在a函数中执行,在a函数中可以选择执行或不执行c函数,也可以对c函数的结果进行二次处理。
定义装饰器:
def out(func_args): # 外围函数
def inter(*args, **kwargs): # 内嵌函数
return func_args(*args, **kwargs)
return inter # 外围函数返回内嵌函数
装饰器的用法:
- 将被调用的函数直接作为参数传入装饰器的外围函数括弧
def a(func):
def b(*args, **kwargs):
return func(*args, **kwargs)
return b
def c(name):
print(name)
a(c('hongyun')) # 调用,打印 hongyun
- 将装饰器与被调用函数绑定在一起
def a(func):
def b(*args, **kwargs):
return func(*args, **kwargs)
return b
@a
def c(name):
print(name)
c('hongyun') # hongyun
7.1.7 类的装饰器
- classmethod:类函数可以不经过实例化而直接被调用
使用方法:
@classmethod
def func(cls, ...):
do something
参数:cls -> 替代普通类函数中的self,cls是class的简写,代表当前操作的类
class Test(object):
@classmethod
def add(cls, a, b):
return a + b
Test.add(1, 2)
- statcmethod:类函数可以不经过实例化而直接被调用,被该装饰器调用的函数不能传递self或cls参数,且无法在该函数内调用其他类函数或类变量
使用方法:
@staticmethod
def func(...):
do something
参数:函数内不能有self或cls参数
class Test(object):
@staticmethod
def add(a, b):
return a + b
Test.add(1, 2)
property:类函数的执行免去括弧,类似于调用属性(变量)
使用方法:
@property
def func(self):
do something
class Test(object):
def __init__(self, name):
self.name = name
@property
def call_name(self):
return 'hello {}'.format(self.name)
test = Test('bilibili')
result = test.call_name # 调用不需要加括弧
print(result) # hello bilibili
但是如果需要修改name的值,怎么办呢
class Test(object):
def __init__(self, name):
self.name = name
@property
def name(self):
return self.__name
@name.setter
def name(self, value):
self.__name = value
test = Test('bilibili')
result = test.name # 调用不需要加括弧
print(result) # bilibili
test.name = 'hongyun'
print(test.name) # hongyun
7.2 继承
7.2.1 类的继承
class Parent(object): # object是内部定义的类,是所有自定义类的父类
def talk(self):
print('talk')
def eat(self):
print('eat')
class Child(Parent):
def drive(self):
print('child can drive vehicle')
- 定义子类时,将父类传入子类参数内
- 子类实例化可以调用自己与父类的函数和变量
7.2.2 super函数
python子类继承父类的方法而使用的关键字,当子类继承父类后,就可以使用父类方法
使用方法:
class Parent(object):
def __init__(self):
print('hello i am parent')
class Child(Parent):
def __init__(self):
print('hello i am child')
super(Child, self).init() # 参数传入子类类名,python3.0可以不用传参数
7.3 多态
7.3.1 类的多态
多态的用法:
- 子类重写父类的函数(方法)
7.3.2 类的多重继承
多重继承:可以 继承多个父类(基类)
多重继承的实现:
class Child(Parent1, Parent2, Parent3, ...)
- 将被继承的类放入子类的参数中,用逗号隔开
- 如果父类中存在相同函数名的函数,那么调用的是从左到右算起的第一个父类中的函数
- 所以括弧中的继承顺序是从左往右依次继承
7.4 类中的高级函数
7.4.1 __str__函数
功能:如果定义了该函数,当print当前实例化对象的时候,会返回该函数的return信息
使用:
def __str__(self):
return str_type
返回值:一般返回对于该类的描述信息
class Test(object):
def __str__(self):
return '这是关于类的描述'
test = Test()
print(test) # 这是关于类的描述
7.4.2 __getattr__函数
功能:当调用的属性或方法不存在时,会返回该方法定义的信息
使用:
def __getattr__(self, key):
print(something...)
参数:key -> 调用任意不存在的属性名
返回值:可以是任意类型也可以不进行返回
class Test(object):
def __getattr__(self, key):
print('这个key:{}不存在!请检查。'.format(key))
test = Test()
test.nonExistFunc() # 这个key:nonExistFunc不存在!请检查。
7.4.3 __setattr__ 函数
功能:拦截当前类中不存在的属性与值
使用:
def __setattr__(self, key, value):
self.__dict__[key] = value
参数:key -> 当前的属性名
value -> 当前的参数对应的值
无返回值
class Test(object):
def __setattr__(self, key, value):
if key not in self.__dict__:
self.__dict__[key] = value
test = Test()
test.name = 'hongyun'
print(test.name) # hongyun
7.4.4 __call__ 函数
功能:本质是将一个类变成一个函数
使用:
def __call__(self, *args, **kwargs):
print('call will start')
参数: 可传任意参数
返回值:与函数情况相同可有可无
class Test(object):
def __call__(self, **kwargs):
print('args is {}'.format(kwargs))
test = Test()
test(name = 'hongyun') # args is {'name': 'hongyun'}
7.5 异常
7.5.1 初识异常
异常:程序的错误,会导致程序崩溃。
异常处理:能监控并捕获异常,将异常部位的程序进行修理使得程序继续正常运行
异常的语法:
try:
<代码块1> # 被try关键字检查并保护的业务代码
except <异常的类型>:
<代码块2> # 代码块1出现错误后执行的代码块
def upper(str_data):
new_str = ''
try:
new_str = str_data.upper()
except:
print('给的参数不是字符串')
return new_str
result= upper(1)
print(result)
通用捕获异常:
在无法确定是哪种异常的情况下使用的异常捕获方法
try:
<代码块>
except Exception as e:
<异常代码块>
def upper(str_data):
new_str = ''
try:
new_str = str_data.upper()
except Exception as e:
print('给的参数不是字符串,而是{type(str_data)},并且{e}')
return new_str
捕获具体异常:
在确定是哪种异常的情况下使用的捕获方法
try:
<代码块>
except <具体异常类型> as e:
<异常代码块>
try:
1/0
print('这里不执行') # 出现异常后,后面的代码不执行
except ZeroDivisionError as e:
print(e) # division by zero
7.5.2 捕获多个异常
方法1:
try:
print('start')
res = 1/0
print('end')
except ZeroDivisionError as e:
print(e)
except Exception as e:
print('this is a public except, bug is : %s' % e)
当except代码块有多个的时候,捕获到第一个异常之后,不会再继续往下捕获。
方法2:
try:
print('try start')
res = 1/0
print('end')
except (ZeroDivisionError, Exception) as e:
print(e)
当except代码后面的异常类型使用元组包裹起来,捕获到哪种就抛出哪种异常。
7.5.3 Python中的异常类型
异常类型集合
| 异常名称 | 说明 |
|---|---|
| Exception | 通用异常类型(所有异常类型的基类) |
| ZeroDivisionError | 不能使用0作为除数 |
| AttributeError | 对象没有这个属性 |
| IOError | 输入输出操作失败 |
| IndexError | 没有当前的索引 |
| KeyError | 没有这个键值(key) |
| NameError | 没有这个变量(未初始化对象) |
| SyntaxError | Python语法错误 |
| SystemError | 解释器的系统错误 |
| ValueError | 传入的参数错误 |
7.5.4 异常中的finally
try:
<代码块1>
except:
<代码块2>
finally:
<代码块3>
- 无论是否发生异常,一定会执行的代码块
- 在函数中,即便在try或except中进行了return也依然会执行finally代码块
- try语法至少要伴随except或finally中的一个
def func1():
try:
print('this is try')
return 'try'
except Exception as e:
print(e)
finally:
print('this is finally')
test = func1()
print(test)
"""
this is try
this is finally
try
"""
def func2():
try:
return 'try'
except Exception as e:
return 'except'
finally:
return 'finally'
test1= func2()
print(test1) # finally
如果try,except和finally都有return,finally的优先级高
7.5.5 自定义异常与抛出异常
自定义抛出异常函数---raise
用法:
raise 异常类型(message)
参数:message -> 错误信息
def testFunc(number):
if number == 100:
raise ValueError('number can not be 100')
return number
res = testFunc(100)
print(res)
'''
File "/home/howardy/Documents/pyCharmProj/except.py", line 27, in testFunc
raise ValueError('number can not be 100')
ValueError: number can not be 100
'''
自定义异常类:
- 继承基类---Exception
- 在构造函数中定义错误信息
class NewError(Exception):
def __init__(self, message):
self.message = message
def testff():
raise NewError('this is a bug')
try:
testff()
except Exception as e:
print(e) # this is a bug
class NumLimitError(Exception):
def __init__(self, message):
self.message = message
class NameLimitError(Exception):
def __init__(self, message):
self.message = message
def funcNum(number):
if number > 100:
raise NumLimitError('数字不能大于100')
return number
def funcName(name):
if name == 'hong':
raise NameLimitError('名字不能是hong')
return name
try:
funcName('hong')
except NameLimitError as e:
print(e)
try:
funcNum(234)
except NumLimitError as e:
print(e)
funcNum(234)
'''
名字不能是hong
数字不能大于100
Traceback (most recent call last):
File "/home/howardy/Documents/pyCharmProj/custom_exception.py", line 29, in <module>
funcNum(234)
File "/home/howardy/Documents/pyCharmProj/custom_exception.py", line 11, in funcNum
raise NumLimitError('数字不能大于100')
__main__.NumLimitError: 数字不能大于100
'''
7.5.6 断言assert
断言的功能:用于判断一个表达式,在表达式条件为false的时候触发异常
用法:
assert expression, message
参数:expresssion -> 表达式,一般是判断相等,或者判断是某种数据类型的bool判断语句
message -> 具体的错误信息
返回值:无返回值
8、包与模块
8.1 Python中的包
8.1.1 什么是Python的包、模块
包:就是文件夹,包中还有包,就是子文件夹
模块:一个个Python文件就是模块
层级关系:包-->模块-->函数
包的身份证:
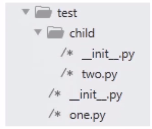
__init__.py是每一个Python包里必须包含的文件
创建一个包:
- 要有一个主题,明确功能,方便使用
- 层次分明,调用清晰
8.1.2 包的导入 import
功能:将Python中的某个包(或者模块),导入到当前的.py文件中
用法:import package
参数:package:被导入包的名字
注意:只会拿到对应包下__init__中的功能或者当前模块下的功能
8.1.3 模块的导入 from ... import ...
功能:通过从某个包找到对应的模块并导入
用法:from package import module
参数:package:来源的包名
module:包中的目标模块
注意:导入灵活多变,也可以是如下导入
from package.module import func
from package1.sub_package.module import func
可以导入之后重命名,比如:
from animal.cat import jump as cat_jump
这样,cat_jump()函数就是导入的函数(重命名后的)
同理也可以导入模块中的类。
8.1.4 强大的第三方包
第三方包:企业或者个人开发好的功能封装成包(模块)发布到网上的
利用pip和easy_install获取第三方包:
Python的第三方包管理工具,pip的使用率最高
Python3.4以上版本在安装Python的时候已经自带了这两种管理工具
旧版本的Python也可以通过https://pip.pypa.io/en/stable/
使用:
pip install 包名
easy_install django # django是
可以在github.com上寻找包,但是它是国外的网站,一般下载版本会比较慢,也可以在国内的网址下载,比如下面的网址:
阿里云:http://mirrors.aliyun.com/pypi/simple/
中科大:https://pypi.mirrors.ustc.edu.cn/simple/
安装指令:
在pycharm terminal输入:pip install -i http://mirrors.aliyun.com/pypi/simple/ ipython
8.1.5 datetime包
datetime包的常用功能:
- 日期与时间的结合
- 获取当前时间
- 获取时间间隔
- 将时间对象装换成时间字符串
- 将字符串转成时间类型
获取当前时间:
导入包与模块:
from datetime import datetime
使用:
datetime.now()
# Out[2]: datetime.datetime(2021, 7, 26, 15, 12, 55, 89076)
# 输出对应 年-月-日-时-分-秒-毫秒
获取时间间隔:
导入:
from datetime import datetime
from datetime import timedelta
使用:
timeobj = timedalta(days = 0, seconds = 0, microsends = 0, milliseconds = 0, minutes = 0, hours = 0, week =0)
使用例子:
from datetime import datetime
from datetime import timedelta
before_one_day = timedelta(days = 1)
yesterday = datetime.now() - before_one_day
yesterday
Out[5]: datetime.datetime(2021, 7, 25, 15, 24, 3, 808918)
时间对象转字符串:
时间转字符串:
date_str = now.strftime(format)
使用举例:
from datetime import datetime
date = datetime.now()
str_date = date.strftime('c')
str_date
# Out[8]: '2021-07-26 15:49:08'
将时间字符串转时间类型:
datetime.strptime(tt, format)
参数:tt -> 符合时间格式的字符串
format -> tt时间字符串匹配规则
使用举例:
from datetime import datetime
str_date = '2021-07-26 15:56:56'
date_obj = datetime.strptime(str_date, '%Y-%m-%d %H:%M:%S')
date_obj
# Out[11]: datetime.datetime(2021, 7, 26, 15, 56, 56)
时间格式字符:
| 字符 | 描述 |
|---|---|
| %Y | 年份,如2021 |
| %m | 月份,1~12 |
| %d | 月中的一天(1~31) |
| %H | 一天中的第几个小时(00~23) |
| %I | 一天中的第几个小时(01~12) |
| %M | 当前的第几个分(00~59) |
| %S | 当前分的第几秒(0~61)闰年多占2秒 |
| %f | 当前的第多少毫秒 |
| %a | 简化的星期,如星期三 Wed |
| %A | 完整的星期,如星期三Wednesday |
| %b | 简化的月份,如二月 Feb |
| %B | 完整的月份,如二月February |
| %c | 本地日期和时间,如Wed Feb 5 10:14:14 2020 |
| %p | 显示上午还是下午,AM/PM |
| %j | 一年中的第几天 |
| %U | 一年中的星期数 |
8.1.6 时间戳
时间戳:1970年1月1日00时00分00秒至今的总毫秒数
- timestamp
- float
生成时间戳的函数time:
import time
time.time()
# Out[13]: 1627294664.0623467
获取本地时间函数localtime:
import time
time.localtime(timestamp) # 参数时间戳timestamp(可不传)
# Out[14]: time.struct_time(tm_year=2021, tm_mon=7, tm_mday=26, tm_hour=18, tm_min=20, tm_sec=50, tm_wday=0, tm_yday=207, tm_isdst=0)
暂停函数sleep:
import time
time.sleep(second) # second:希望程序被暂停的秒数
注意:time包中也有strftime和strptime,使用方法和datetime的一样
datetime中生成时间戳的函数:
from datetime import datetime
now = datetime.now()
datetime.timestamp(now)
# Out[3]: 1627295740.944299
datetime时间戳转时间对象:
from datetime import datetime
datetime.fromtimestamp(timestamp) # timestamp:时间戳
from datetime import datetime
now = datetime.now()
now_timestamp = datetime.timestamp(now)
datetime_obj = datetime.fromtimestamp(now_timestamp)
datetime_obj
# Out[7]: datetime.datetime(2021, 7, 26, 18, 35, 40, 944299)
8.2 python中的os包
import os
| 函数名 | 参数 | 描述 | 举例 | 返回值 |
|---|---|---|---|---|
| getcwd | - | 返回当前的路径 | os.getcwd() | 字符串 |
| listdir | path | 返回指定路径下所有的文件和文件夹 | os.listdir('c://usr') | 返回一个列表 |
| makedirs | path mode | 创建多级文件夹 | os.makedirs('d://imooc/py') | - |
| removedirs | path | 删除多级文件夹 | os.removedirs('d://imooc/py') | - |
| rename | oldname, newname | 给文件或文件夹改名 | os.rename('d://imooc','d://imoc') | - |
| rmdir | path | 只能删除空文件夹 | os.rmdir('d://imooc') | - |
8.2.1 os.path模块常用方法
| 函数名 | 参数 | 描述 | 举例 | 返回值 |
|---|---|---|---|---|
| exists | path | 文件或路径是否存在 | os.exists('d://imoc') | bool |
| isdir | path | 是否是路径 | os.isdir('d://imoc') | bool |
| isabs | path | 是否是绝对路径 | os.path.isabs('test') | bool |
| isfile | path | 是否是文件 | os.path.isfile('usr/proj/a.py') | bool |
| join | path,path* | 路径字符串合并 | os.path.join('d://','test') | 字符串 |
| split | path | 以最后层路径为基准切割 | os.path.split('d://test') | 列表 |
8.2.2 sys中常用的方法
| 函数名 | 参数 | 描述 | 举例 | 返回值 |
|---|---|---|---|---|
| modules | - | py启动时加载的模块 | sys.modules | 列表 |
| path | - | 返回当前py的环境路径 | sys.path | 列表 |
| exit | arg | 退出程序 | sys.exit(0) | - |
| getdefaultencoding | - | 获取系统编码 | sys.getdefaultencoding() | 字符串 |
| platform | - | 获取当前系统平台 | sys.platform() | 字符串 |
| version | - | 获取当前Python版本 | sys.version | 字符串 |
| argv | *args | 程序外部获取参数 | sys.argv | 列表 |
8.3 文件操作
8.3.1 文件的创建与写入
利用内置函数open获取文件对象:
功能:生成文件对象,进行创建、读写操作
使用:
open(path, mode)
# 参数说明:path-> 文件路径
# mode -> 操作模式
# 返回值:返回文件对象
举例:
f = open('usr/date.txt', 'w')
文件操作模式---写入
| 模式 | 描述 |
|---|---|
| w | 创建文件,若文件已存在,则原文件将被新文件覆盖 |
| w+ | 创建文件并读取文件 |
| wb | 二进制形式创建文件,即可写入byte类型内容 |
| wb+ | 二进制形式创建或追加内容 |
| a | 追加内容 |
| a+ | 读写模式的追加 |
| ab+ | 二进制形式读写追加 |
文件对象的操作方法:
| 方法名 | 参数 | 描述 | 举例 |
|---|---|---|---|
| write | Message | 写入信息 | f.write('hello\n') |
| writelines | Message_list | 批量写入 | fwritelines(['hello\n', 'world\n']) |
| close | - | 关闭保存且 | f.close() |
8.3.2 文件的读取操作
文件操作模式---读取
| 模式 | 描述 |
|---|---|
| r | 读取文件 |
| rb | 二进制形式读取文件 |
文件对象的操作方法---读
| 方法名 | 描述 | 举例 |
|---|---|---|
| read | 返回整个文件字符串 | f.read() |
| readlines | 返回文件列表 | f.readlines() |
| readline | 返回文件中的一行 | f.readline() |
| mode | 文件模式 | f.mode() |
| name | 返回文件名称 | f.name() |
| closed | 文件是否关闭 | f.closed() |
注意:操作完成后,必须使用closed方法
8.4 序列化
8.4.1 初识序列化
序列化(Serialization):将对象的状态信息转换为可以存储或传输的形式的过程
可序列化的数据类型:
- number
- str
- list
- tuple
- dict
Python的json模块:
| 方法名 | 参数 | 描述 | 举例 | 返回值 |
|---|---|---|---|---|
| dumps | obj | 对象序列化 | json.dumps([1,2]) | 字符串 |
| loads | str | 反序列化 | json.loads('[1,2,3]') | 原始数据类型 |
Python的pickle模块:
| 方法名 | 参数 | 描述 | 举例 | 返回值 |
|---|---|---|---|---|
| dumps | obj | 对象序列化 | pickle.dumps([1,2]) | 比特 |
| loads | byte | 反序列化 | pickle.loads('[1,2,3]') | 原始数据类型 |
8.4.2 yaml文件
用途:文本文件、服务配置文件
xxx.yaml
name: # key
xiaomu # value
age:
10
xinqing:
- haha # 列表
- heihei
new:
a: b # 字典
c: 1
Python的第三方模块---pyyaml:
pip install pyyaml
import pyyaml
读取yaml的方法:
用法:
f = open(yaml_file, 'r')
data = yaml.load(f.read())
f.closed()
返回值:字典类型
{
'name': 'xiaomu',
'age': 10,
'xinqing': ['haha','heihei'],
'new': {'a':'b', 'c':1}
}
8.5 Python中的加密工具
8.5.1 hashlib模块介绍
- 难破解
- 不可逆
常用加密方法:
| 函数名 | 参数 | 介绍 | 举例 | 返回值 |
|---|---|---|---|---|
| md5 | byte | Md5算法加密 | hashlib.md5(b' hello') | Hash对象 |
| sha1 | byte | Sha1算法加密 | hashlib.sha1(b' hello') | Hash 对象 |
| sha254 | byte | Sha256算法加密 | hashlib.sha256(b' hello') | Hash 对象 |
| sha512 | byte | Sha512算法加密 | hashlib.sha512(b' hello') | Hash 对象 |
生成加密字符串:
hashobj = hashlib.md5(b' hello')
result = hashobj.hexdigest()
print(result)
# 292a5af68d31c10e31ad449bd8f51263
# coding:utf-8
import hashlib
import time
hase_sign = 'muke'
def custom():
a_timestamp = int(time.time())
_token = '%s%s' % (hase_sign, a_timestamp)
hashobj = hashlib.sha1(_token.encode('utf-8'))
a_token = hashobj.hexdigest()
return a_token, a_timestamp
def b_service_check(token, timestamp):
_token = '%s%s' % (hase_sign, timestamp)
b_token = hashlib.sha1(_token.encode('utf-8')).hexdigest()
if token == b_token:
return True
else:
return False
if __name__ == '__main__':
need_help_token, timestamp = custom()
result = b_service_check(need_help_token, timestamp)
if result:
print('a合法,b服务可进行帮助')
else:
print('a不合法,b服务不可进行帮助')
8.5.2 base64模块介绍
- 通用型
- 可解密
base64包常用方法:
| 函数名 | 参数 | 描述 | 举例 | 返回值 |
|---|---|---|---|---|
| encodestring | Byte | base64加密 | base64.encodestring(b' py') | Byte |
| decodingstring | Byte | base64解密 | base64.decodingstring(b'e Glhb211\n') | Byte |
| encodebytes | Byte | base64加密 | base64.encodestring(b' py') | Byte |
| decodingbytes | Byte | base64解密 | base64.decodingstringb'e Glhb211\n') | Byte |
# coding:utf-8
import base64
def encode(data):
if isinstance(data, str):
data = data.encode('utf-8')
elif isinstance(data, bytes):
data = data
else:
raise TypeError('date need bytes or str')
return base64.encodebytes(data).decode('utf-8')
def decode(data):
if not isinstance(data, bytes):
raise TypeError('data need be bytes')
return base64.decodebytes(data).decode('utf-8')
if __name__ == '__main__':
result = encode('hello xiaomu')
print(result)
new_result = decode(result.encode('utf-8'))
print(new_result)
8.6 日志
日志的等级:
debug < info < warning < error < critical
8.6.1 logging模块的使用
logging.basicConfig
| 参数名 | 作用 | 举例 |
|---|---|---|
| level | 日志输出等级 | level = logging.DEBUG |
| format | 日志输出格式 | |
| filename | 存储位置 | filename = 'd://back.log' |
| filemode | 输入模式 | filemode = "w" |
format具体格
| 格式符 | 含义 |
|---|---|
| %(levelname)s | 日志级别名称 |
| %(pathname)s | 执行程序的路径 |
| %(filename)s | 执行程序名 |
| %(lineno)d | 日志的当前行号 |
| %(asctime)s | 打印日志的时间 |
| %(message)s | 日志信息 |
常用日志格式符方案:
format = '%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s'
举例:
# coding:utf-8
import logging
import os
def init_log(path):
if os.path.exists(path):
mode = 'a' # log文件后追加内容
else:
mode = 'w' # 创建文件并添加内容
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s %(filename)s %(lineno)d %(levelname)s %(message)s',
filename=path,
filemode=mode
)
return logging
current_path = os.getcwd()
path = os.path.join(current_path, 'back_log')
log = init_log(path)
log.info('这是第一条执行信息')
log.warning('this is a warning')
8.7 虚拟环境
8.7.1 认识虚拟环境
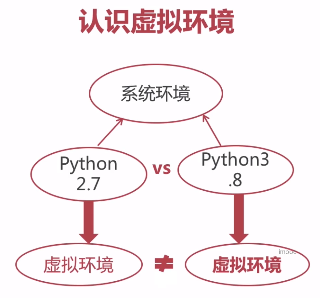
8.7.2 Python中的虚拟环境工具
- virtualenv
- pyenv
pip install virtualenv
8.9 常用函数集合
8.9.1 常用函数
| 函数名 | 参数 | 描述 | 返回值 | 举例 |
|---|---|---|---|---|
| abs | Number | 返回数字绝对值 | 正数字 | abs(-10) |
| all | List | 判断列表内容是否全是true | bool | all(['', '123']) |
| help | object | 打印对象的用法 | 无 | help(list) |
| enumerate | iterable | 迭代时记录索引 | 无 | for index, item in enumerate(list) |
| input | Str | 命令行输入内如 | Str | input('请输出内容:') |
| isinstance | Object, type | 判断对象是否是某种类型 | bool | isinstance('a', str) |
| type | Object | 判断对象的类型 | Str | type(10) |
| vars | instance | 返回实例化的字典信息 | dict | |
| dir | object | 返回对象中所有可用方法和属性 | List | dir('asd') |
| hasattr | Obj, key | 判断对象中是否有某个属性 | bool | hasattr('run', 'sporter') |
| setattr | Obj, key, value | 为实例化对象添加属性与值 | 无 | setattr(instance, 'run', 'go') |
| getattr | Obj, key | 通过对象获取属性 | 类型 | getattr(obj, key) |
| any | iterable | 判断内容是否有true值 | bool | any([1,3, '']) |
8.9.2 python中的random模块
- random.random
随机返回0~1之间的浮点数
- random.uniform
产生一个a, b之间的的随机浮点数
random.uniform(1, 10)
- random.randint
产生a, b之间的随机整数
- random.choice
返回对象中的一个随机元素
random.choice(['1', '2', '3']) '2'
random.choice('abc') c
- random.sample
随机返回对象中指定的元素(列表)
random.sample(['a', 'b', 'c'], 2) ['a', 'c'] #第二个参数表示数量
random.sample('abx', 2) ['b', 'x']
- random.randrange
获取区间内的一个随机数
random.randrange(0, 100, 1) 51 # 参数:起始, 结尾, 步长
random.choice(range(0, 100, 1)) 45
8.10 迭代器
8.10.1 什么是迭代器
迭代器是程序设计的软件设计模式,可在容器对象(列表,元组等)上遍历访问的接口,设计人员无需关心容器对象的内存分配和实现细节。
8.10.2 生成迭代器和使用
生成 迭代器-iter
iter(iterable) # iterable: 可迭代的数据类型
使用迭代器-next
next(iterator) # iterator: 迭代器对象
8.10.3 迭代器常用方法
for循环生成发-yield
def test():
for i in range(12):
yield i
for循环一行生成迭代器
res = (i for i in [1, 2, 3])
8.10.4 高阶函数
- filter
功能:对循环根据过滤条件进行过滤
使用:
filter(func, list) # func: 对每个item进行条件过滤的定义
# 需要过滤的列表
举例:
res = filter(lambda x:x>1, [0,1,2])
print(list(res)) # [2]
- map
功能:对列表中的每个成员是否满足条件返回对应的True或False
使用:
map(func, list) # func: 对list每个item进行条件满足的判断
# list: 需要过滤的列表
举例:
res = map(lambda x: x>1, [0, 1, 2])
print(list(res)) # [False, False, True]
- reduce
功能:对循环前后两个数据进行累加
使用:
reduce(func, list) # func: 对数据累加的函数
# list: 需要处理的列表
举例:
from functools import reduce
res = reduce(lambda x, y: x + y, [1, 2, 3])
print(res) # 6

 浙公网安备 33010602011771号
浙公网安备 33010602011771号