2020级北航OO第一单元作业总结
一、作业内容及基本思路
1.1 递归下降法
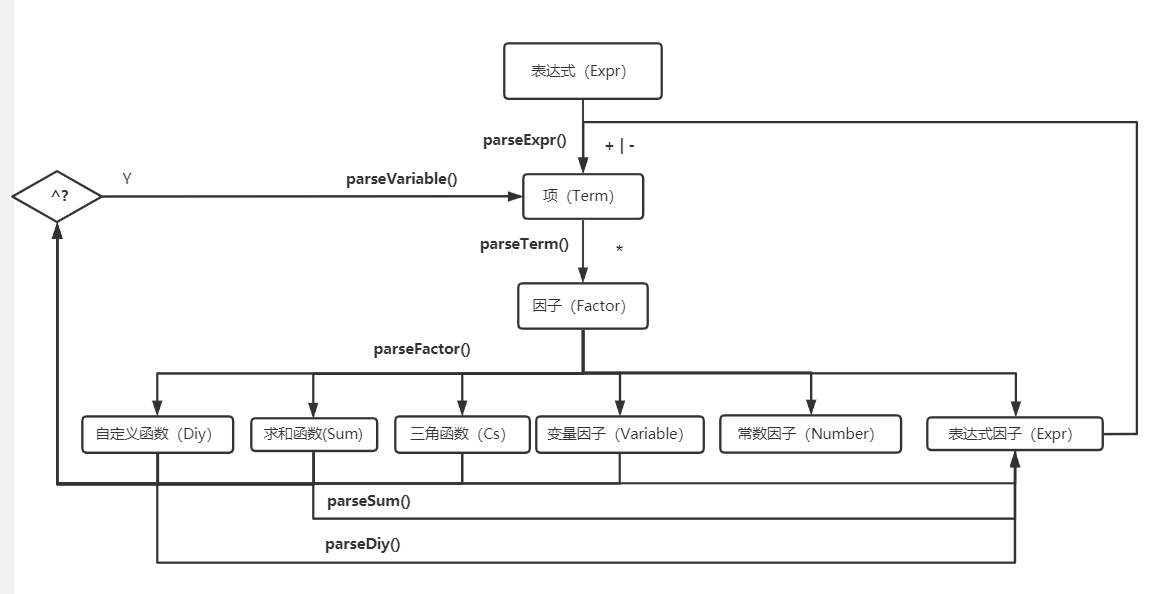
简言之,之所以能递归,在于各个类之间的组成关系。表达式->项->因子就是一种组成关系。表达式由项相加减组成,项由因子相乘组成,因子由...组成... ...递归下降的思路关键是从左向右扫描,碰到连接关系,解析对应的下层class。即在一个表达式中碰到加减号,解析项;在一个项中碰到乘号,解析因子;在一个因子中碰到表达式,解析表达式... ...直到解析得只剩最基本的因子为止。
“碰到xxx”这个行为就由一个叫做Lexer的类来完成。其中包含的lexer.next()方法用来从左向右扫描;lexer.peek()方法用来返回当前lexer碰到的东西。
"解析xxx"这个行为就由一个叫做Parser的类来完成。其中包含了parseExpr()、parseTerm()、parseFactor()等用于解析特定类。
1.2 作业内容
1.2.1 第一次作业
内容:包含对变量因子、常数因子、表达式因子组成的因子通过乘法组成项,再通过加减组成的表达式的括号展开。
思路:先用递归下降的方法解析出每个基本因子,再用HashMap<Integer,BigInteger>中的key存储指数、value存储系数。则加减、乘除操作都可以转换为hashmap对指数和系数的计算。最后按照对应的指数和系数输出HashMap即可。
1.2.2 第二次作业
内容:新增了三角函数、求和函数和自定义函数的表达式的括号展开。
思路:新建三角函数类(Cs)、求和函数类(Sum)、自定义函数类(Diy)。用HashMap<CsList,HashMap<Integer,BigInteger>>中的key存储三角函数,value存储第一次作业中的仅含x、常数组成的表达式因子。其中,CsList类中包含一个成员变量Hashset<Cs>,用来存储诸如sin(...)powcos(...)pow形式的三角函数。并重写Cs类和Cslist类的equals和hashcode,以实现同类项合并。
1.2.3 第三次作业
内容:新增了嵌套的三角函数、自定义函数调用的表达式的括号展开。
思路:将三角函数内的类型从String改成Factor。将输出函数printMap改为遇到三角函数嵌套输出即可。
二、基于度量对程序结构的分析
2.1 第一次作业
2.1.1 类的度量

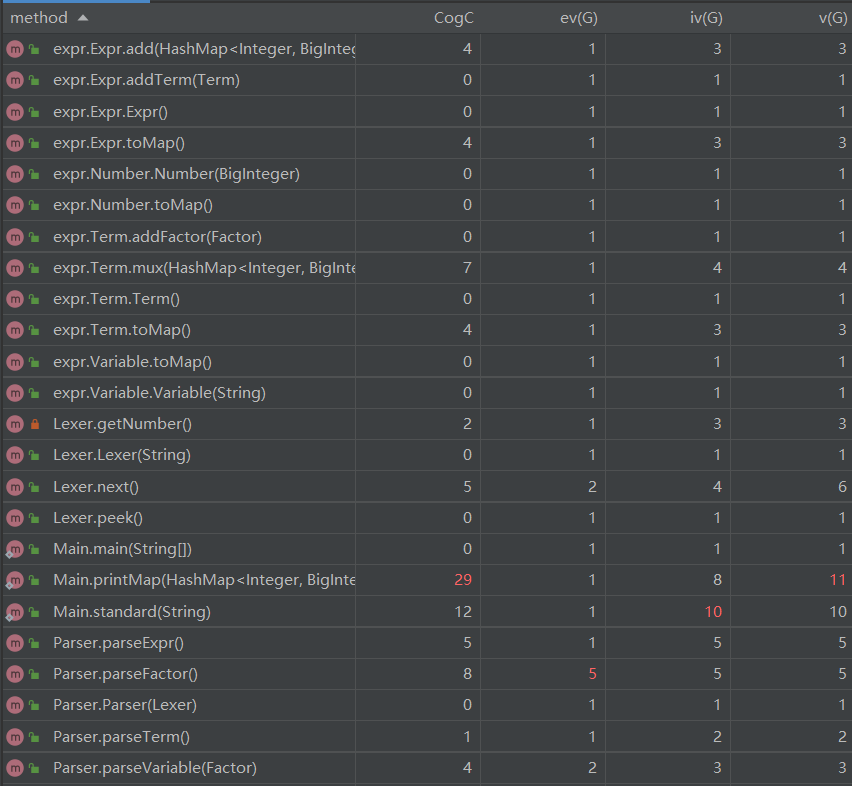
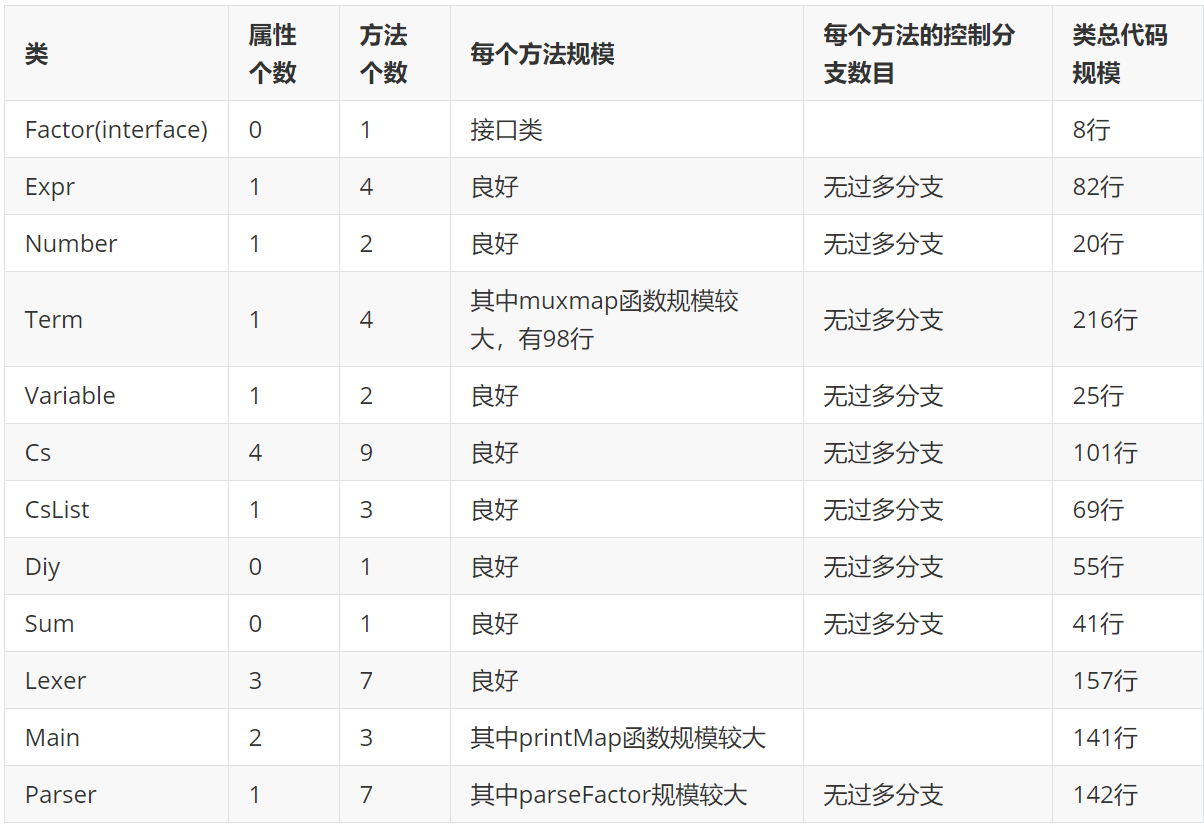
在第一次作业中我主要分了7个类和一个接口。
2.1.2 类的耦合与内聚度量
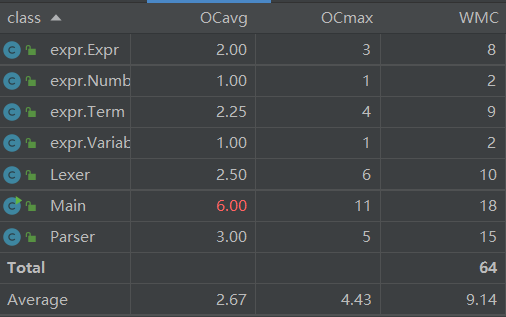
总体来看,除了主类之外的其他类复杂度都较低。主类之所以复杂度高,耦合性差是因为我对输入字符串的标准化处理较为繁琐(比如将空格删去,负号换成-1*,将连续的正负号替换成一个正号或负号,将**替换成^等等...)。事实证明一些必要的替换能使后面的处理更加高效,但是例如将负号替换成 -1* 在之后的作业中会徒增麻烦,所以应该避免这些会改变表达式结构的替换,而是在解析过程中(Parser类)处理。除此之外,我还在主类中写了printMap的输出函数,所以相比起来代码复杂度较高。
2.1.3 UML类图及其优缺点
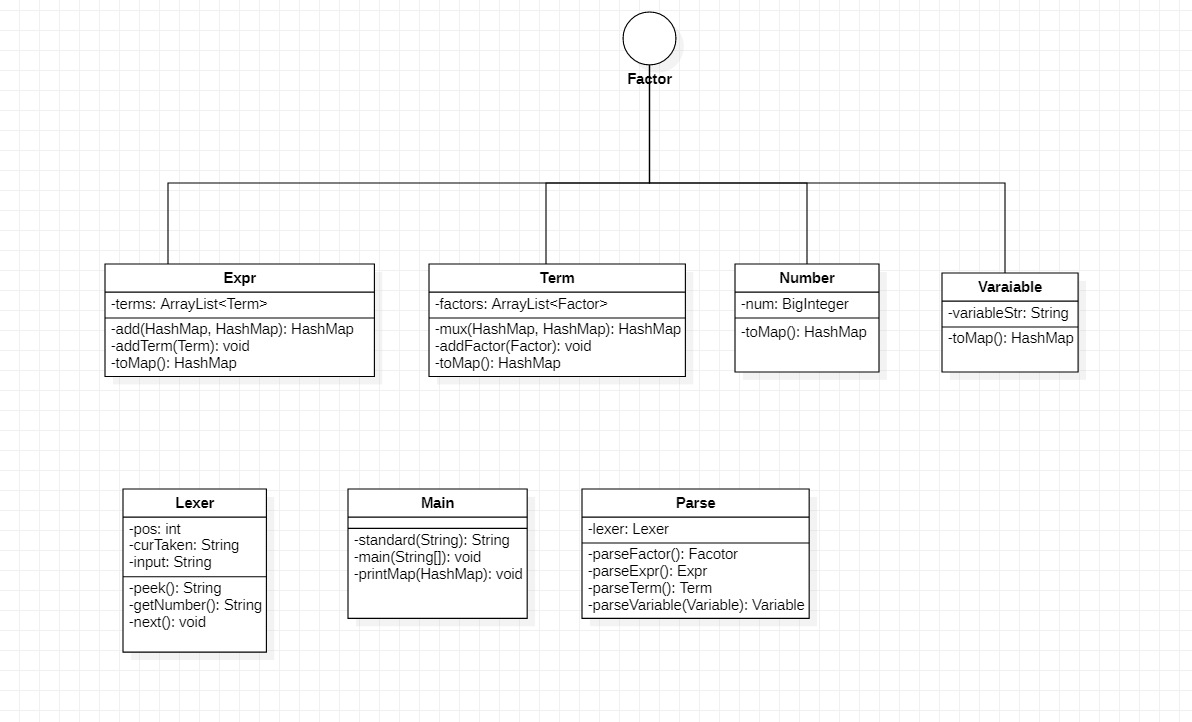
对于Factor、Expr、Term、Number、Variable这些数据类:
Factor是一个接口,Expr、Term、Number、Variable均能实现Factor的toMap()动作。
toMap()函数在Expr里的行为:将成员变量terms中的每个term的HashMap通过add()函数相加,得到一张新的HashMap;
toMap()函数在Term里的行为:将成员变量factors中的每个factor的HashMap通过mux()函数相乘,得到一张新的HashMap;
toMap()函数在Number里的行为:直接返回一张指数为0,系数为num的HashMap;
toMap()函数在Variable里的行为:直接返回一张指数为1,系数为1的HashMap;
对于Lexer、Parser这些解析类:
Lexer类相当于一个字符扫描器,从左向右扫描,并截取相应的字符。其中lexer.next()函数用于向右走一步,lexer.peek()用于返回当前扫描到的字符(可能是一个操作符[()+-*^],也可能是变量因子[x],也可能是一个数[0-9+])。
Parser类相当于一个解析器,与Lexer类配合解析。当lexer.peek()等于加号或减号时-> parseTerm();当lexer.peek()等于乘号时->parseFactor();当lexer.peek()等于"("时-> parseExpr();当lexer.peek()等于变量因子或常量因子这两种基本因子时,解析完成。
具体实现方式如下图所示:
其中对幂函数的处理是当在解析完factor之后,如果之后为 ^ ,则用parseVariable()将幂次个factor add进Term中,相当于幂次个factor相乘。【parseVaribale()函数的意思是幂函数解析,但是解析幂函数的英文应该叫做parsePowerful。或许此处命名的不严谨给读者造成了困扰。】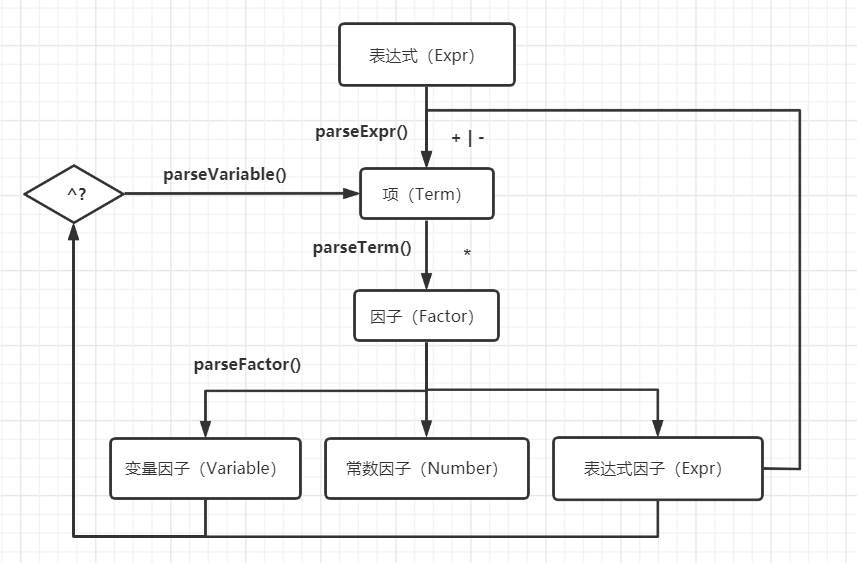
UML图优缺点:
UML图的优点在于能够清晰地知道各个类之间的继承、实现关系,但是缺点在于各个类之间的包含关系不是很清楚。
2.2 第二次作业
2.2.1 类的度量

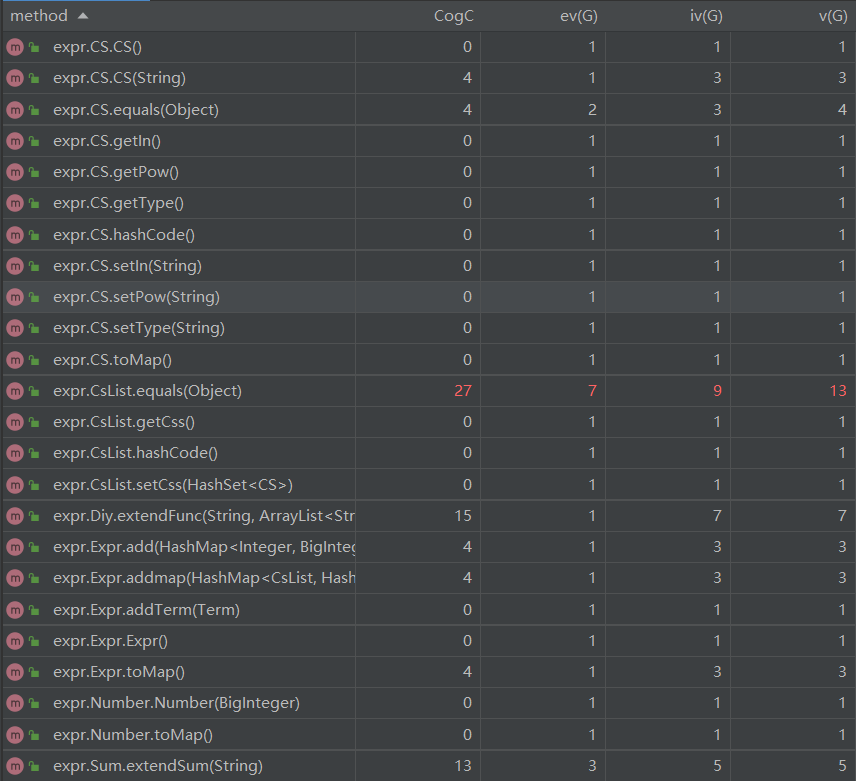
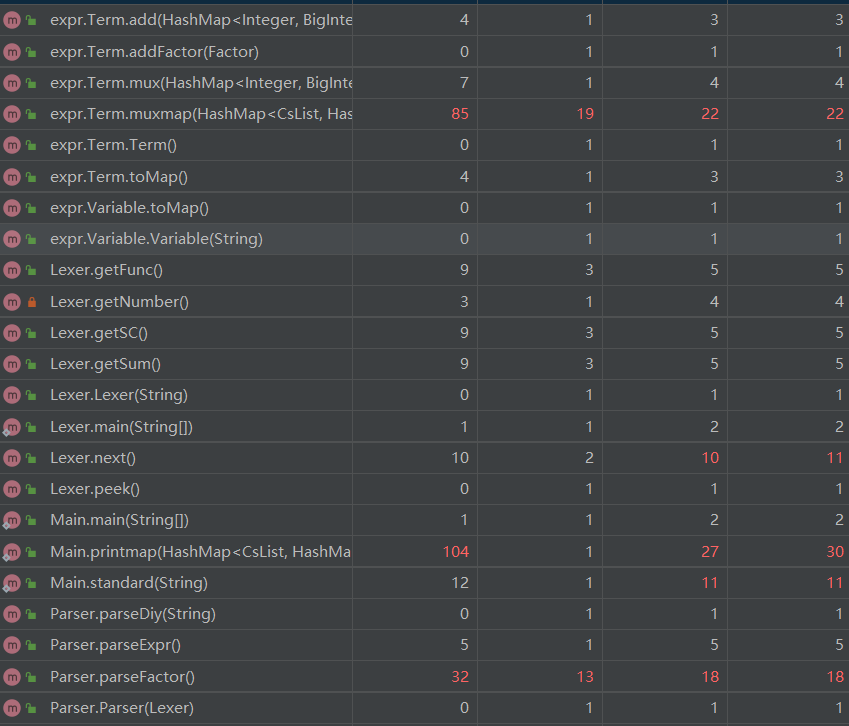
相比于第一次作业新增了Cs三角函数基本因子类、CsList类、Diy自定义函数类、Sum求和函数类。
2.2.2 类的耦合与内聚度量
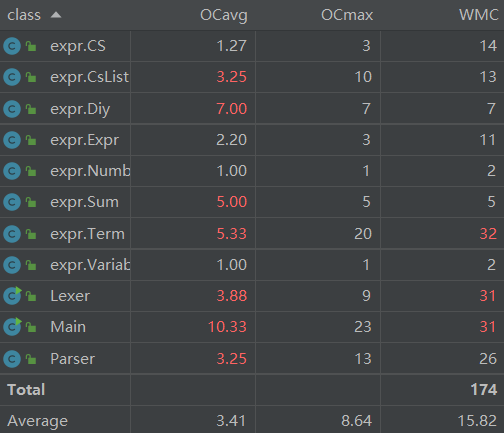
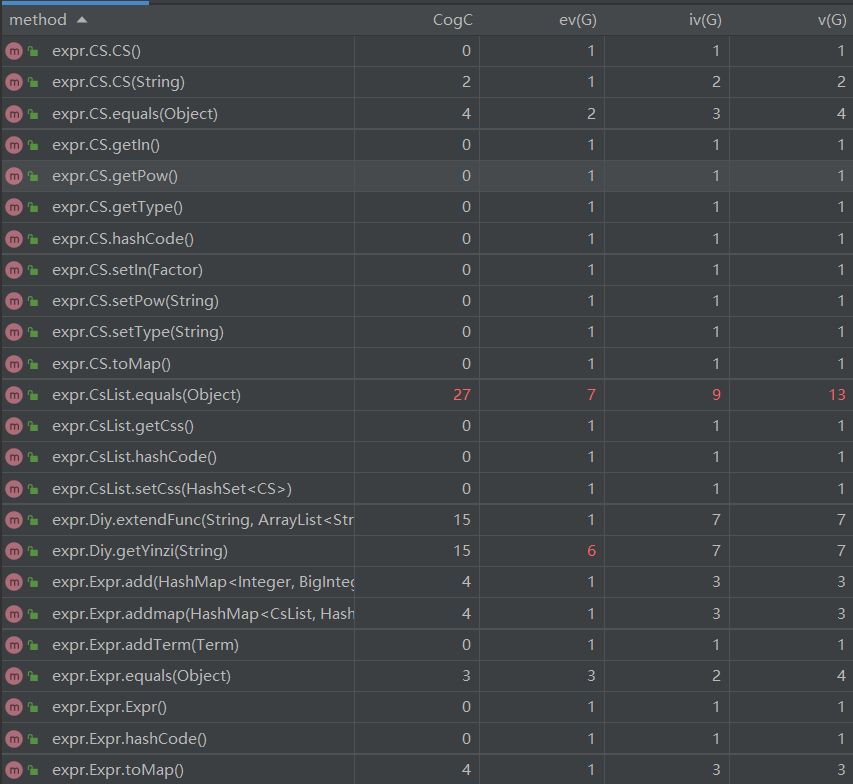
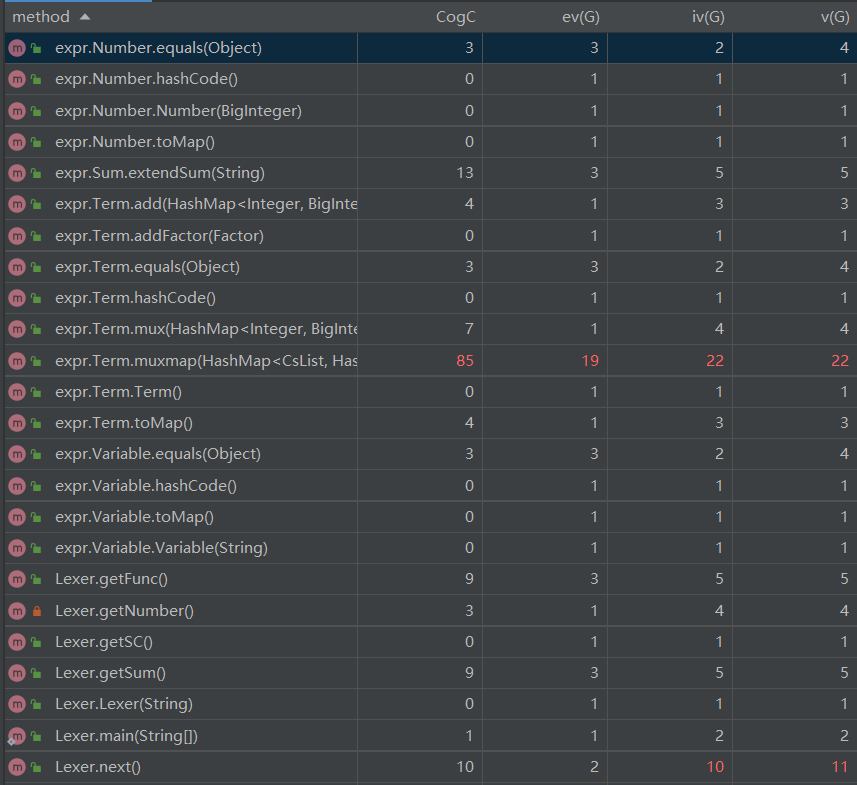
自定义函数类和求和函数类相对比较复杂是因为在这次作业我用的是正则表达式匹配字符串并替换的方法。事实证明正则表达式不是必须的,而且极容易出错。所以在之后又优化成了与Lexer里的getNumber()类似的getFactor()等函数截取字符串。对于Term这个类的复杂度之所以很高,是因为其中的mux(HashMap,HashMap)函数的实现我写得较为复杂。
2.2.3 UML类图及其优缺点
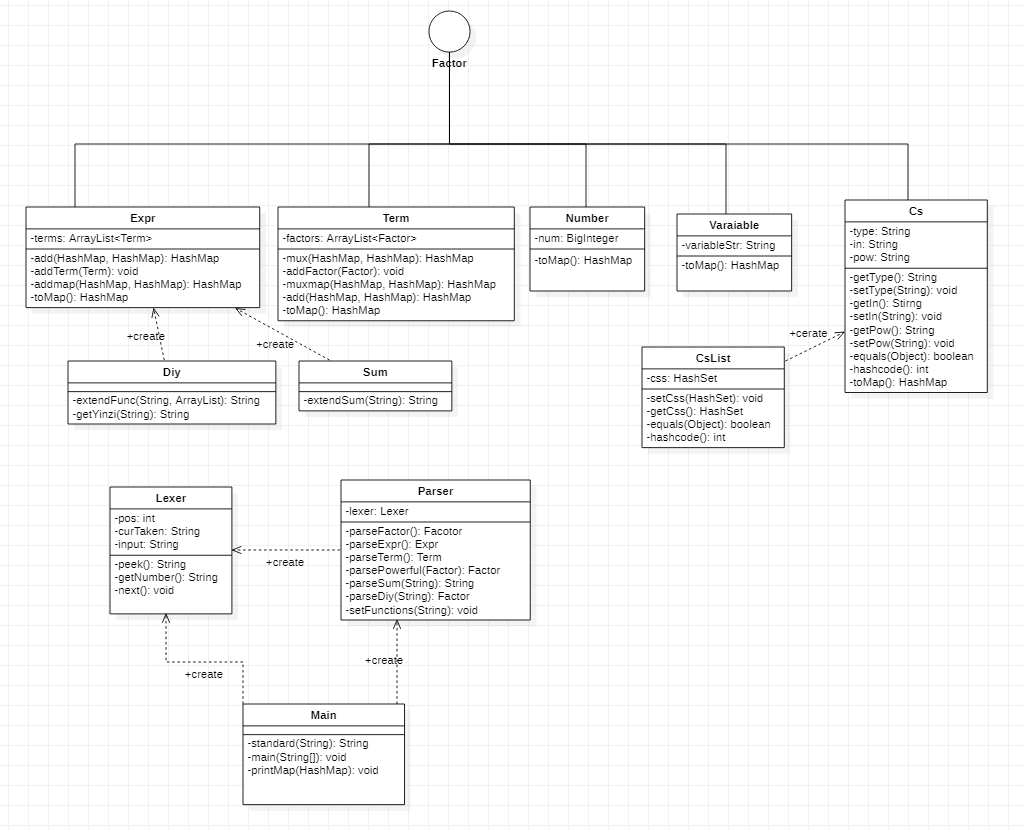
- 新增的Diy类和Sum类:之所以没有实现Factor接口,是因为我的想法是Diy和Sum只是一个实现输入函数调用式,根据函数定义式,返回表达式的一个字符串替换工具。所以没必要实现Factor接口中的toMap()方法。
- 新增的Cs三角函数类:里面设置了三个属性,分别是类型type(描述是sin还是cos),指数pow,内容in。这个类用于描述sin(in)pow或者cos(in)pow这种最基本的三角函数。所以这个类与Number类、Variable类类似,同是基本因子。其toMap()的行为是:直接返回一个key为只有一个基本三角函数因子的CsList,value为一个指数为0、系数为1的HashMap<Integer,BigInteger> 的HashMap<CsList,HashMap<Integer,BigInteger>>。
其具体实现方式如下图所示:
UML图优缺点:
各个类之间的关系没有表述很清楚,比如create关系等等。层次化结构也不是特别清楚。特别是Diy和Sum两个类,类的本质只是一个实现字符串替换的工具。
2.3 第三次作业
2.3.1 类的度量
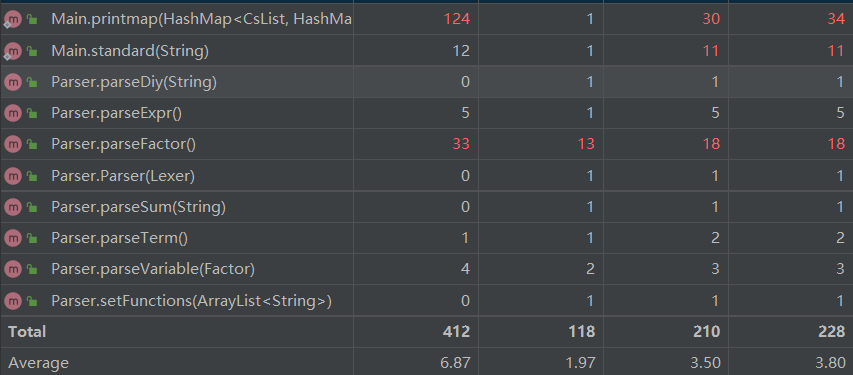
相比于第二次的作业,第三次作业没有新增的类。修改的地方也较少。
2.3.2 类的耦合与内聚度量
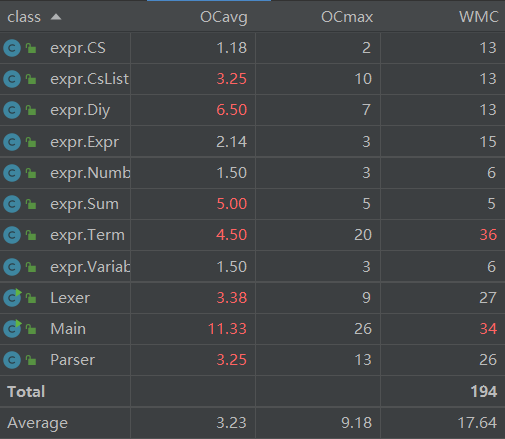
2.3.3 UML类图及其优缺点
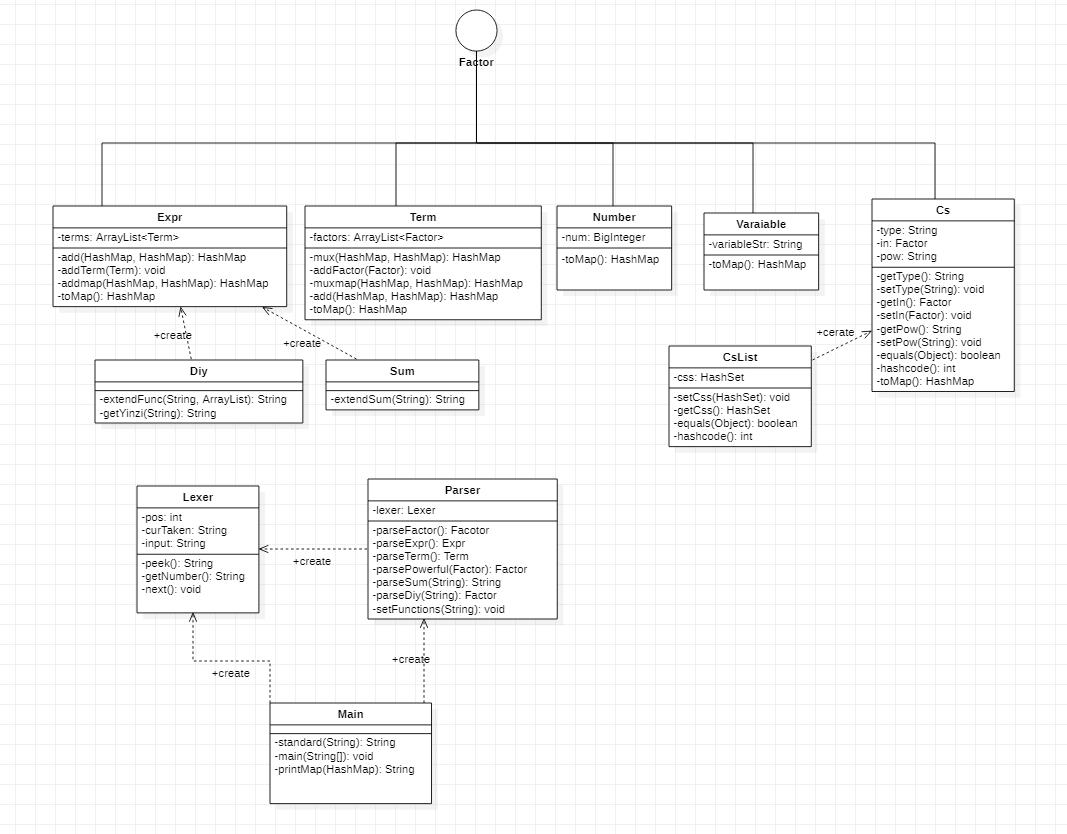
相比于第二次的改动在于:
- Cs类中的in类型从String变成了Factor,因为三角函数可以嵌套。
- 其次在Diy类舍弃了第二周的正则表达式捕获替换的方法,而是采用了类似字符分割器一样的函数getYinzi()来取出调用函数中的每个因子(对括号的处理采用压栈与入栈即可)。
- 最后在Main中的printfMap函数将其返回值从void改成String,将原本输出字符串为三角函数的地方改成printMap(csoutput.toMap()),即再次调用printMap函数嵌套输出。如下图所示:
![]()
![]()


UML图优缺点:
缺点是各个类之间的create关系不明确。
三、Bug分析
Bug方面:
第一次作业强测、互测没有被hack出bug。
第二次作业强测寄了。原因是在输出的时候我一直是先输出三角函数类,没有考虑到cos(x)*-x这种形式是不合法的...还有一个点是在合并同类项的时候只考虑了指数相等时合并,导致在HashSet中若已有一个sin(x)**2和sin(x)**4,后又来了一个sin(x)**2,合并成sin(x)**4存入HashSeth后,HashSet中的sin(x)**4的系数仍然为1,因为HashSet不允许重复元素!!Bug修复阶段我加了个while循环,一直判断HashSet中是否有可合并元素,直到全合并了再退出循环。
第三次作业强侧没有出bug,互测被找了两个bug,都出在Sum的实现中。其一为当我用字符串替换i时,没有考虑到当i为负数的情况,导致i为负数时i**2被替换成-1**2,与结果不符。所以Bug修复阶段我在替换时加了一对括号->(-1)**2。其二为sum中的系数我没考虑到BigInteger范围。Bug修复阶段我将其转换为BigInteger就好了。
性能方面:
性能方面我没有做很多优化,只是合并了同类项。对系数、指数做了一些判断。甚至都没有将sin(0)替换成0,将cos(0)替换成1。sin(x)**2+cos(x)**2也没有考虑。之后的作业希望在保证正确率的前提下试着多做一些性能优化。
四、Hack策略
前两次均没有hack成功他人,也没有被hack。第三次互测大家都卷起来了貌似,也可能bug比较普遍,被hack了7次,hack他人2次。其实我的hack积极性不是很高,偶尔会交一交自己debug时产生的bug。互测时的bug主要出在有没有越界、是否加括号等细节问题上。
五、架构设计体验
通过前三周的作业,我对面向对象架构的了解初具雏形。从面向过程转换为面向对象确实会有一定的不适应,在最开始甚至不清楚为什么要分这么多类。在通过训练代码的启发下,才对层次化架构与递归下降法有了一定的了解。在第一次作业的良好架构下,第二次、第三次的作业实现起来也会相对轻松一些。总之,第一单元作业让我体会到了一个良好的架构的重要性。一旦明确了总体架构,码代码时就不太会有中途做不下去的困境。
六、总结与展望
第一单元的作业在经历多次试错、debug之后终于完成了。十分感谢第一次作业时助教发的training代码提供的良好架构与思路以及课程组老师的辛勤付出。希望之后的作业与学习过程中能够相对顺利一些~
注:内容如有错误请纠正,谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号