微服务熔断
一 概念
熔断的三个功臣:sentinel hystrix resilience4j 。
熔断解决的问题:A调用B B调用C 如果C出现了错误流量过大 或者 出现了异常 引发线程等待 则会拖垮整个调用链。
spring 的调用链一般是这样的:Feign 音标:[feɪn] 》 hystrix 音标:[hɪst'rɪks] 》Ribbon 音标:[ˈrɪbən] 》HTTP Client HTTP再分发为server A,,B,C,D。 (建议大家统一读法不要瞎读导致别人都听不懂)
二 使用
Ⅰ 隔离方式:
1 线程隔离(默认):使用一个线程池储存当前请求,线程池对请求处理,设置请求超时时间,堆积的请求堆积入线程池队列。
这种方式为每个依赖的服务申请线程池,有一定的资源消耗,好吃是可以应对突发流量(流量洪峰来临时,可以将数据储存到线程池队列慢慢处理)
2 信号隔离 :使用原子计数器记录当前多少线程在进行,请求到达后与设定的最大线程数比较,若大于最大线程数则丢弃该类型的新请求,否则计数器+1,请求返回计数器-1.
这种严格控制线程的方式无法应对突发流量(处理的请求过多时,请求直接返回,服务端不能进行处理)
Ⅱ熔断:
如果某个服务调用慢或者大量时,熔断该服务的调用,对于后续请求,不继续调用目标,直接返回,快速释放资源。待目标好转,再恢复调用。
虽然看似简单但调用参数很多:来看看使用方法
1 依赖引入
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-hystrix</artifactId>
</dependency>
2 配置参数
feign: hystrix: #不配置或为false则不生效 enabled: true hystrix: command: default: execution: isolation: thread: #若配置了重试则超时时间= (1 + MaxAutoRetries + MaxAutoRetriesNextServer) * ReadTimeout timeoutInMilliseconds: 60000 threadpool: default: coreSize: 10 maxQueueSize: 50 queueSizeRejectionThreshold: 30 keepAliveTimeMinutes: 3
3 配置fallback
断了的话:
//必须实现被@FeignClient修饰的HelloWorldService接口。注意添加@Component或者@Service注解,在Spring容器中生成一个Bean @Component public class HelloWorldServiceFailure implements HelloWorldService { @Override public String sayHello() { System.out.println("hello world service is not onLine"); return "hello world service is not onLine"; } }
feign:
@FeignClient(value = "demo",fallback = HelloWorldServiceFailure.class)//目标项目名,熔断后处理类 public interface HelloWorldService { //接口全名 和 请求方式 // Feign将方法签名中方法参数对象序列化为请求参数放到HTTP请求中的过程,是由编码器(Encoder)完成的。 // 同理,将HTTP响应数据反序列化为Java对象是由解码器(Decoder)完成的。 // 默认情况下,Feign会将标有@RequestParam注解的参数转换成字符串添加到URL中,将没有注解的参数通过Jackson转换成json放到请求体中。 // 注意,如果在@RequetMapping中的method将请求方式指定为POST,那么所有未标注解的参数将会被忽略
@RequestMapping(value = "/hello/hello", method = RequestMethod.GET)
String sayHello();
}
4 配置的其他方式
有的接口1s就可返回 有的接口1min才能返回 ,一刀切难以管理诸多服务和接口。
在之前的配置中会发现关键字default ,这是对全局配置 ,那么对局部配置呢。
hystrix: command: default: execution: isolation: thread: timeoutInMilliseconds: 60000 threadpool: #全局配置 default: coreSize: 10 maxQueueSize: 50 queueSizeRejectionThreshold: 30 keepAliveTimeMinutes: 3 #对某个服务配置,写service-id base-rpc: coreSize: 10 maxQueueSize: 30 queueSizeRejectionThreshold: 20 keepAliveTimeMinutes: 3 #对某个接口配置 BaseApiClient#searchItemSkuList(PosSkuSearch): coreSize: 10 maxQueueSize: 40 queueSizeRejectionThreshold: 30 keepAliveTimeMinutes: 1
@HystrixCommand注解进行配置 :@HystrixCommand和@CacheResult注解使用
5 配置得动态修改
hystrix 利用 archaius 管理配置 :
archaius是Netflix公司开源项目之一,基于java的配置管理类库,主要用于多配置存储的动态获取。
主要功能是对apache common configuration类库的扩展。在云平台开发中可以将其用作分布式配置管理依赖构件。同时,它有如下一些特性:
动态获取属性 高效和线程安全的配置操作 配置改变时提供回调机制 可以通过jmx操作配置 复合配置
//捞配置 AbstractConfiguration config = ConfigurationManager.getConfigInstance(); //提取关注的部分,比如hystrix.threadpool Iterable<String> iterable = () -> config.getKeys("hystrix.threadpool"); List<Property> result = StreamSupport.stream(iterable.spliterator(), false).map(t -> new Property(t, config.getString(t, ""))) .sorted(Comparator.comparing(Property::getName)).collect(Collectors.toList()); //修改配置 config.setProperty("hystrix.threadpool.base-rpc.coreSize", 20); //移除配置 config.clearProperty(hystrix.threadpool.base-rpc.coreSize");
三 其他参数
在hystrix前后还有feign和ribbon 所以:
1.feign超时
feign: hystrix: enabled: true client: config: default: connectTimeout: 5000 readTimeout: 5000 rpc-pos: connectTimeout: 5000 readTimeout: 8000 xx-rpc: connectTimeout: 5000 readTimeout: 12000 order-rpc: connectTimeout: 5000 readTimeout: 8000
feign 超时时间会影响后面的ribbon 超时和 http client超时设置
2.ribbon超时
#全局配置 ribbon: ReadTimeout: 60000 ConnectTimeout: 10000 #false to only allow get method to retry OkToRetryOnAllOperations: true # Max number of next servers to retry (excluding the first server) MaxAutoRetriesNextServer: 2 # Max number of retries on the same server (excluding the first try) MaxAutoRetries: 0 # Interval to refresh the server list from the source ServerListRefreshInterval: 5000 retryableStatusCodes: 404,500 #服务配置 base-rpc: ribbon: ReadTimeout: 60000 ConnectTimeout: 10000 #false to only allow get method to retry OkToRetryOnAllOperations: true # Max number of next servers to retry (excluding the first server) MaxAutoRetriesNextServer: 2 # Max number of retries on the same server (excluding the first try) MaxAutoRetries: 0 # Interval to refresh the server list from the source ServerListRefreshInterval: 5000 retryableStatusCodes: 404,500
ribbon 会根据 feign 超时设置而改变,Ribbon的这个超时时间,用于指导真正调用接口时,设置真正实现者的超时时间。
3.http client 超时
feign: hystrix: enabled: true okhttp: enabled: true httpclient: enabled: false //连接池最大连接数,默认200 max-connections: 500 //每一个IP最大占用多少连接 默认 50 max-connections-per-route: 50 //默认连接超时时间:2000毫秒 connection-timeout: 8000 //连接池管理定时器执行频率:默认 3000毫秒 connection-timer-repeat: 6000 //连接池中存活时间,默认为5 time-to-live: 5 time-to-live-unit: minutes
超时的时间配置 feign > hystrix > ribbon > http client 是由 AutoConfiguration机制实现的
如:若开启feign.okhttp.enabled=true,则okhttp的超时时间是feign.httpclient.connectionTimeout的值,默认2000毫秒
四 hystrix dashboard 可视化
引入一个jar包
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-hystrix-dashboard</artifactId>
</dependency>
//在服务端启动类上加
@EnableHystrixDashboard
看图就知道可视化点啥了
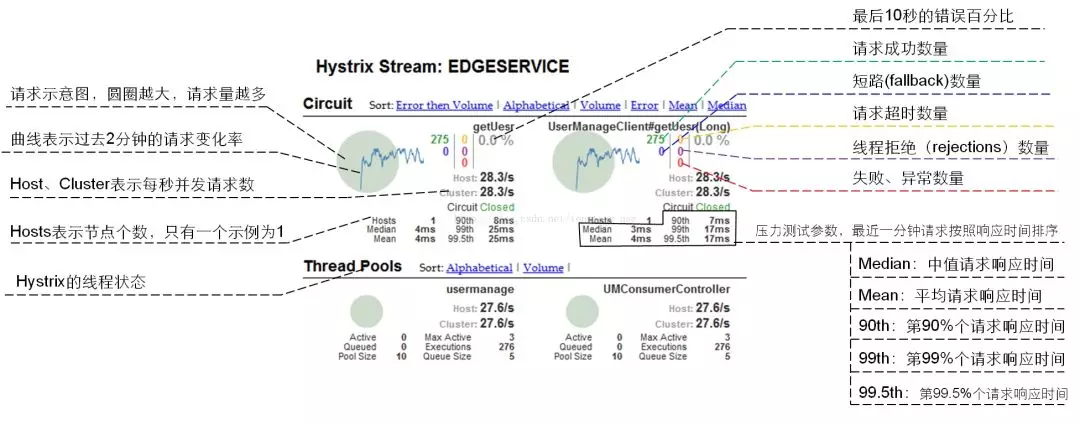
附:配置参数说明
一、Command Properties
以下属性控制HystrixCommand,前缀hystrix.command.default
1、Execution
以下属性控制HystrixCommand.run()如何执行。
比较重要的参数,有:
execution.isolation.strategy
execution.isolation.thread.timeoutInMilliseconds

2、Fallback
以下属性控制HystrixCommand.getFallback()如何执行。这些属性适用于ExecutionIsolationStrategy.THREAD和ExecutionIsolationStrategy.SEMAPHORE。

3、Circuit Breaker
断路器属性控制HystrixCircuitBreaker。
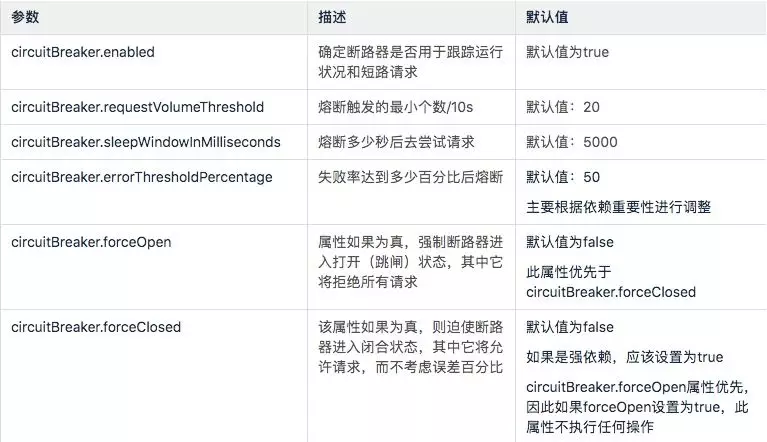
4、Metrics
以下属性与从HystrixCommand和HystrixObservableCommand执行捕获指标有关。

5、Request Context
这些属性涉及HystrixCommand使用的HystrixRequestContext功能
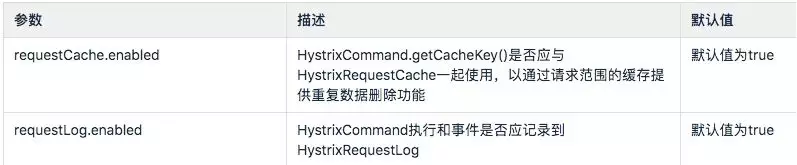
二、Command Properties
下列属性控制HystrixCollapser行为。前缀:hystrix.collapser.default
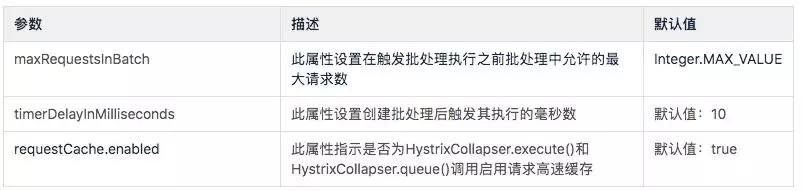
三、ThreadPool Properties
以下属性控制Hystrix命令在其上执行的线程池的行为。
大多数时候,默认值为10的线程会很好(通常可以做得更小)前缀:hystrix.threadpool.default


 浙公网安备 33010602011771号
浙公网安备 33010602011771号