

0.准备:
在三台机器下修改/etc/hosts文件,增加下面内容
172.16.1.95 node1 (datanode)
192.168.0.143 hadoop1 (namenode1 datanode)
192.168.0.157 hadoop2 (namenode2 datanode)
1.免密登录
(1)在三台机器上执行ssh-keygen -t rsa
(2)将公钥复制到一个文件下
在master机器上执行
cat ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
在hadoop1和hadoop2机器上执行
ssh-copy-id -i ~/.ssh/id_rsa.pub node1;
在node1机器上执行
[hadoop@FineReportAppServer ~]$ scp .ssh/authorized_keys hadoop1:~/.ssh/
hadoop@hadoop1's password:
authorized_keys 100% 1213 1.2KB/s 00:00
[hadoop@FineReportAppServer ~]$ scp .ssh/authorized_keys hadoop2:~/.ssh/
hadoop@hadoop1's password:
authorized_keys 100% 1213 1.2KB/s 00:00
2.配置jdk
在三台机器上配置jdk,增加java_home变量,加到path里
[hadoop@FineReportAppServer ~]$ cd jdk1.8.0_60/
[hadoop@FineReportAppServer jdk1.8.0_60]$ pwd
/home/hadoop/jdk1.8.0_60
[hadoop@FineReportAppServer jdk1.8.0_60]$ vim ../.bash_profile
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
JAVA_HOME=/home/hadoop/jdk1.8.0_60
ZOOKEEPER_HOME=/home/hadoop/zookeeper-3.4.5-cdh5.10.0
HADOOP_HOME=/home/hadoop/hadoop-2.6.0-cdh5.7.0
PATH=$PATH:$HOME/bin
PATH=$PATH:$JAVA_HOME:$ZOOKEEPER_HOME:$HADOOP_HOME:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export PATH JAVA_HOME ZOOKEEPER HADOOP_HOME
[hadoop@FineReportAppServer ~] source ../.bash_profile
3.zookeeper
(1)解压软件,配置变量
hadoop@FineReportAppServer zookeeper-3.4.5-cdh5.10.0]$ pwd
/home/hadoop/zookeeper-3.4.5-cdh5.10.0
[hadoop@FineReportAppServer zookeeper-3.4.5-cdh5.10.0]$
变量参考2配置jdk的
(2)修改zookeeper配置zookeeper/conf/zoo.cfg
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
[hadoop@FineReportAppServer conf]$ more zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
#添加
dataDir=/home/hadoop/data/zook_data
dataLogDir=/home/hadoop/data/zook_log
# the port at which the clients will connect
clientPort=2181
#添加(内网IP)
server.1=node1:2888:3888
server.2=hadoop1:2888:3888
server.3=hadoop2:2888:3888
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
在/home/hadoop/data/下创建data和datalog两个目录,在data目录下面创建myid文件并添加内容(echo 1 > myid )。在三台服务器中的myid的内容分别是1,2,3(对应server.xx)。
(3)将zookeeper复制到slave1、slave2下
(4)依次在各个服务器上启动
[hadoop@oracletest01 ~]$ /home/hadoop/zookeeper-3.4.5-cdh5.10.0/bin/zkServer.sh start
JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.5-cdh5.10.0/bin/../conf/zoo.cfg
Starting zookeeper ... already running as process 3086.
[hadoop@oracletest01 ~]$ /home/hadoop/zookeeper-3.4.5-cdh5.10.0/bin/zkServer.sh status
JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.5-cdh5.10.0/bin/../conf/zoo.cfg
Mode: leader
[hadoop@oracletest01 ~]$ ssh hadoop2
Last login: Mon Mar 15 15:07:50 2021 from slave1
[hadoop@drprecoverydb01 ~]$ /home/hadoop/zookeeper-3.4.5-cdh5.10.0/bin/zkServer.sh status
JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.5-cdh5.10.0/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
[hadoop@drprecoverydb01 ~]$ /home/hadoop/zookeeper-3.4.5-cdh5.10.0/bin/zkServer.sh status
JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.5-cdh5.10.0/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
[hadoop@drprecoverydb01 ~]$ /home/hadoop/zookeeper-3.4.5-cdh5.10.0/bin/zkServer.sh start
JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.5-cdh5.10.0/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@drprecoverydb01 ~]$ /home/hadoop/zookeeper-3.4.5-cdh5.10.0/bin/zkServer.sh status
JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.5-cdh5.10.0/bin/../conf/zoo.cfg
Mode: follower
[hadoop@drprecoverydb01 ~]$
4.hadoop配置
配置环境变量,参考jdk配置
下列配置文件/home/hadoop/hadoop-2.6.0-cdh5.7.0/etc/hadoop/下面
(1)hadoop-env.sh
将java_home的变量增加进去
export JAVA_HOME=/home/hadoop/jdk1.8.0_60
(2)core-site.xml
<!-- 指定hdfs的nameservice为ns(任取)-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns/</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop_tmp</value>
</property>
<!--流文件的缓冲区单位KB-->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 指定zookeeper集群的地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop1:2181,hadoop2:2181,node1:2181</value>
</property>
(3)hdfs-site.xml
<!--指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!-- ns下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>hadoop1:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>hadoop1:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>hadoop2:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>hadoop2:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop1:8485;hadoop2:8485;node1:8485/ns</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/journal</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<!--dataNode数据的存储位置-->
<name>dfs.datanode.data.dir</name>
<value>file:///home/hadoop/hdfs/data</value>
</property>
<!--设置副本数为2>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
(4)mapred-site.xml
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--map任务内存大小,默认1G-->
<property>
<name>mapreduce.map.memory.mb</name>
<value>230</value>
</property>
<!--reduce任务内存大小,默认1G-->
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>460</value>
</property>
<!--map任务运行的JVM进程内存大小,默认-Xmx200M-->
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx184m</value>
</property>
<!--reduce任务运行的JVM进程内存,默认-Xmx200M-->
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx368m</value>
</property>
<!--MR AppMaster运行需要内存,默认1536M-->
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>460</value>
</property>
<!--MR AppMaster运行的JVM进程内存,默认-Xmx1024m-->
<property>
<name>yarn.app.mapreduce.am.command-opts</name>
<value>-Xmx368m</value>
</property>
(5)yarn-site.xml
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop1:2181,hadoop2:2181,node1:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--RM中分配容器的内存最小值,默认1G-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>230</value>
</property>
<!--RM中分配容器的内存最大值,默认8G-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>700</value>
</property>
<!--可用物理内存大小,默认8G-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>700</value>
</property>
<!--虚拟内存检查是否开始-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
(6)slaves
node1
hadoop1
hadoop2
将修改好的hadoop程序包复制到其他目录下
scp -r node1:~/hadoop-2.6.0-cdh5.7.0 hadoop1:~/
scp -r node1:~/hadoop-2.6.0-cdh5.7.0 hadoop2:~/
(7)启动
a.启动journalnode集群
在hadoop1执行journalnode集群
[hadoop@FineReportAppServer sbin]$ ./hadoop-daemons.sh start journalnode
slave1: starting journalnode, logging to /home/hadoop/hadoop-2.6.0-cdh5.7.0/logs/hadoop-hadoop-journalnode-oracletest01.out
slave2: starting journalnode, logging to /home/hadoop/hadoop-2.6.0-cdh5.7.0/logs/hadoop-hadoop-journalnode-drprecoverydb01.out
master: starting journalnode, logging to /home/hadoop/hadoop-2.6.0-cdh5.7.0/logs/hadoop-hadoop-journalnode-FineReportAppServer.out
b.格式化HDFS
在hadoop1上格式化HDFS
$HADOOP_HOME/bin/hdfs namenode -format
格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,我这在 /home/hadoop/hadoop_tmp
将这个文件拷贝到hadoop2机器下
scp -r /home/hadoop/hadoop_tmp/ hadoop2:/home/hadoop/;
c.格式化zookeer
在hadoop1上格式化ZK
$HADOOP_HOME/bin/hdfs zkfc -formatZK
d.启动hadoop
在hadoop1上启动HDFS
$HADOOP_HOME/sbin/start-dfs.sh
e.启动yarn
在hadoop3上启动Yarn
$HADOOP_HOME/sbin/start-yarn.sh
f.jps
#hadoop1
[hadoop@oracletest01 ~]$ jps
9825 QuorumPeerMain
18213 NameNode
18757 DFSZKFailoverController
18550 JournalNode
19398 Jps
18872 ResourceManager
18986 NodeManager
18331 DataNode
11775 SecondaryNameNode
#hadoop2
[hadoop@drprecoverydb01 ~]$ jps
13408 DFSZKFailoverController
13266 JournalNode
13860 NameNode
10933 QuorumPeerMain
13160 DataNode
13962 Jps
13549 NodeManager
#node1
[hadoop@FineReportAppServer ~]$ jps
20832 Jps
17540 QuorumPeerMain
14676 ResourceManager
20519 NodeManager
20407 JournalNode
20297 DataNode
1786 SecondaryNameNode
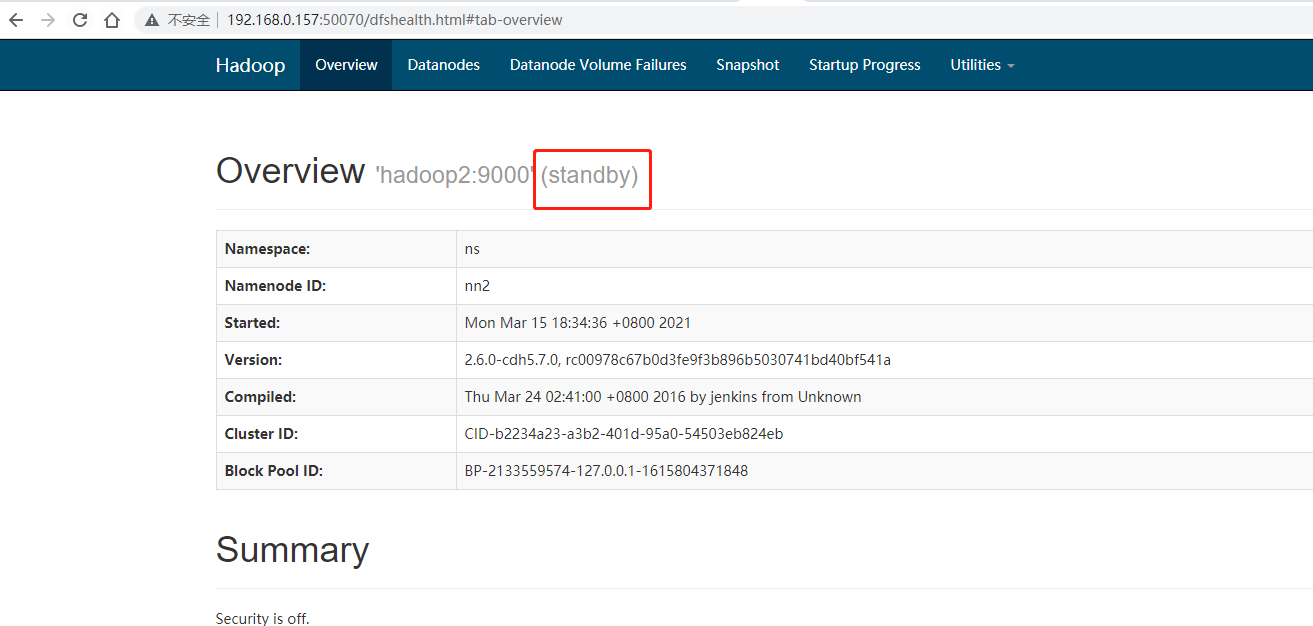
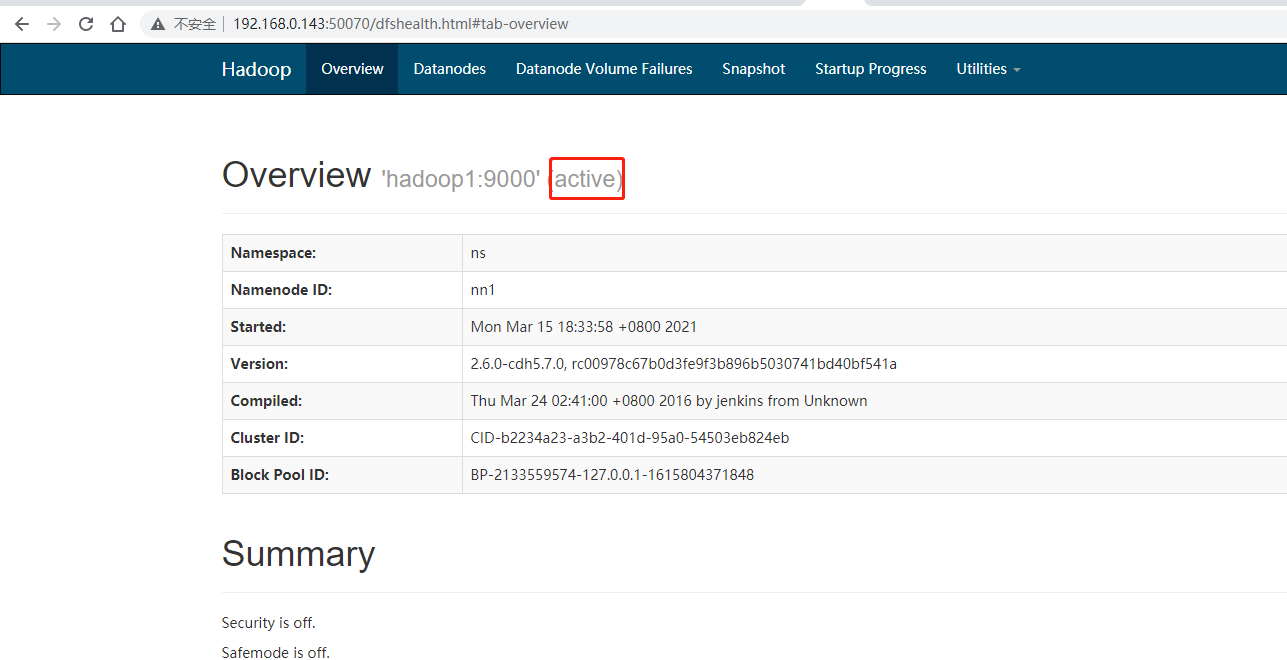
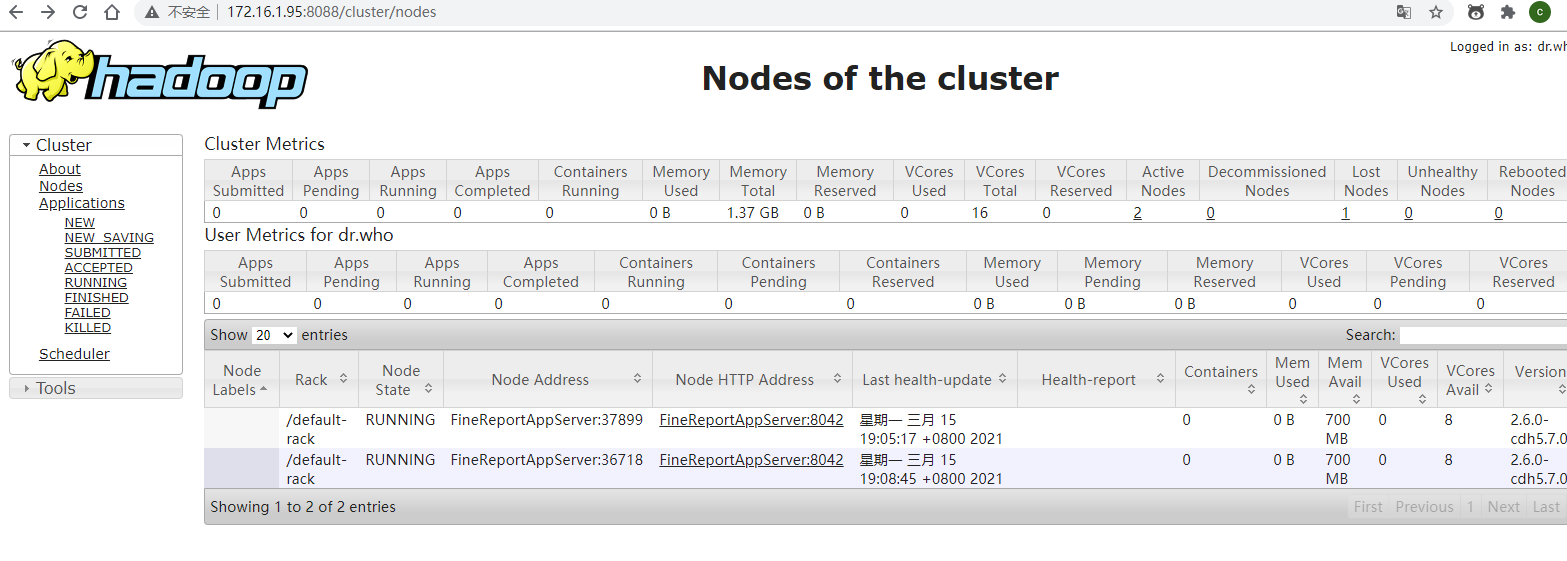
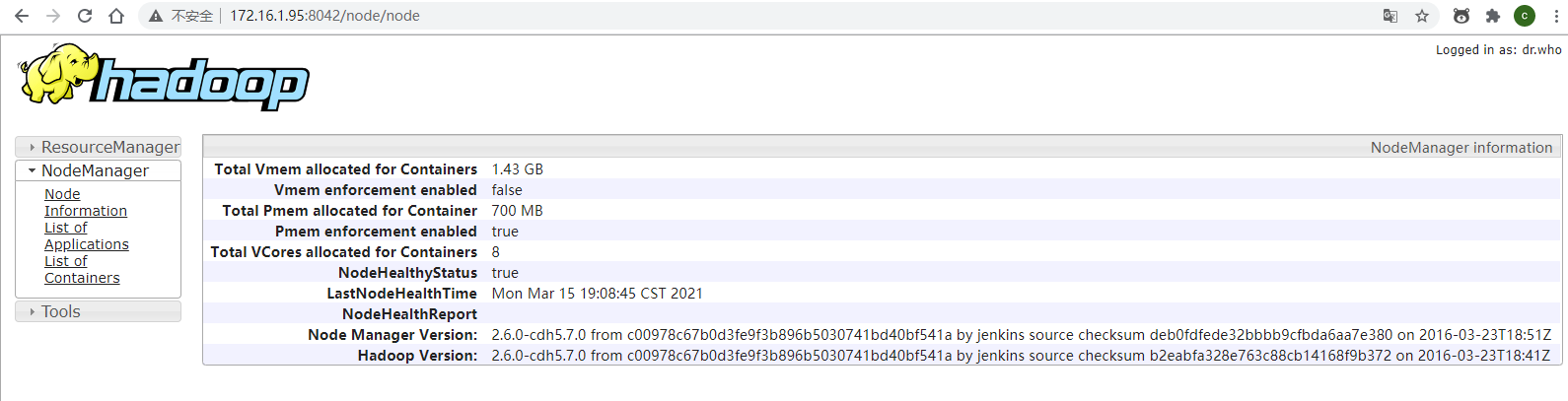
5.hbase配置
(1)配置环境变量
export HBASE_HOME=/home/hadoop/hbase-1.2.0-cdh5.7.0
export PATH=$PATH:$HBASE_HOME/bin
(2)修改conf/hbase-env.sh
export JAVA_HOME=/home/hadoop/jdk1.8.0_60
#使用外部的zk
export HBASE_MANAGES_ZK=false
(3) 修改conf/habse-site.xml
<property>
<!-- 指定hbase在HDFS上存储的路径 三台都是ns的rootdir-->
<name>hbase.rootdir</name>
<value>hdfs://ns/hbase</value>
</property>
<property>
<!-- 指定hbase是分布式的 -->
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<!-- 指定zk的地址,多个用“,”分割 -->
<name>hbase.zookeeper.quorum</name>
<value>node1,hadoop1,hadoop2</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/zookeeper-3.4.5-cdh5.10.0</value>
</property>
(4)在conf下创建backup-masters文件
将hadoop2写入到文件中
将软件包复制到其他两台机器下
(5)在hadoop1启动start-hbase.sh
[hadoop@oracletest01 hbase-1.2.0-cdh5.7.0]$ start-hbase.sh
starting master, logging to /home/hadoop/hbase-1.2.0-cdh5.7.0/bin/../logs/hbase-hadoop-master-oracletest01.out
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
hadoop1: starting regionserver, logging to /home/hadoop/hbase-1.2.0-cdh5.7.0/bin/../logs/hbase-hadoop-regionserver-oracletest01.out
node1: starting regionserver, logging to /home/hadoop/hbase-1.2.0-cdh5.7.0/bin/../logs/hbase-hadoop-regionserver-FineReportAppServer.out
hadoop2: starting regionserver, logging to /home/hadoop/hbase-1.2.0-cdh5.7.0/bin/../logs/hbase-hadoop-regionserver-drprecoverydb01.out
node1: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
node1: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
hadoop1: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
hadoop1: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
访问hadoop1:60010、hadoop2:60010
(6)node1:60030报错:
The RegionServer is initializing
#查看hdfs safe mode
hadoop dfsadmin -safemode get
#退出hdfs safe mode
hadoop dfsadmin -safemode leave
[hadoop@oracletest01 hbase-1.2.0-cdh5.7.0]$ hadoop dfsadmin -safemode leave
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
21/03/16 16:59:21 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Safe mode is OFF in hadoop1/192.168.0.143:9000
Safe mode is OFF in hadoop2/192.168.0.157:9000
[hadoop@oracletest01 hbase-1.2.0-cdh5.7.0]$
6.hive配置
在hadoop1、hadoop2上配置hive 相当于布置了两套hive 避免一套挂掉不能使用
(1)环境变量
JAVA_HOME=/home/hadoop/jdk1.8.0_60
ZOOKEEPER_HOME=/home/hadoop/zookeeper-3.4.5-cdh5.10.0
HADOOP_HOME=/home/hadoop/hadoop-2.6.0-cdh5.7.0
HBASE_HOME=/home/hadoop/hbase-1.2.0-cdh5.7.0
HIVE_HOME=/home/hadoop/hive-1.1.0-cdh5.7.0
PATH=$PATH:$HOME/bin
PATH=$PATH:$JAVA_HOME:$JAVA_HOME/bin:$ZOOKEEPER_HOME:$HADOOP_HOME:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$HBASE_HOME/bin:$HIVE_HOME/bin
export PATH JAVA_HOME ZOOKEEPER_HOME HADOOP_HOME HBASE_HOME HIVE_HOME
source 一下
(2) 创建hive-env.sh
cp $HIVE_HOME/conf/hive-env.sh.template $HIVE_HOME/conf/hive-env.sh
(3) 创建hive-site.xml
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.server2.support.dynamic.service.discovery</name>
<value>true</value>
</property>
<property>
<name>hive.server2.zookeeper.namespace</name>
<value>hiveserver2_zk</value>
</property>
<property>
<name>hive.zookeeper.quorum</name>
<value> hadoop1:2181,hadoop2:2181,node1:2181</value>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>0.0.0.0</value>
</property>
<!-- //两个HiveServer2实例的端口号要一致-->
<property>
<name>hive.server2.thrift.port</name>
<value>10001</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node1:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/home/hadoop/hive/warehouse</value>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>/home/hadoop/hive/tmp</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/home/hadoop/hive/log</value>
</property>
</configuration>
(4)增加mysql jar包到hive目录的lib目录下
[hadoop@drprecoverydb01 lib]$ pwd
/home/hadoop/hive-1.1.0-cdh5.7.0/lib
[hadoop@drprecoverydb01 lib]$ ll -t
total 107940
-rw-rw-r-- 1 hadoop hadoop 1006904 Mar 17 09:35 mysql-connector-java-5.1.49.jar
-rw-r--r-- 1 hadoop hadoop 102069 Mar 16 17:55 accumulo-fate-1.6.0.jar
drwxr-xr-x 6 hadoop hadoop 4096 Mar 16 17:55 php
-rw-r--r-- 1 hadoop hadoop 30359 Mar 16 17:55 apache-curator-2.6.0.pom
-rw-r--r-- 1 hadoop hadoop 32693 Mar 16 17:55 asm-commons-3.1.jar
-rw-r--r-- 1 hadoop hadoop 117910 Mar 16 17:55 hive-hbase-handler-1.1.0-cdh5.7.0.jar
(5)开启 hive 的服务
nohup hive --service metastore &
nohup hive --service hiveserver2 &
(5)测试连接
beeline> !connect jdbc:hive2://hadoop2:10001/hive
scan complete in 3ms
Connecting to jdbc:hive2://hadoop2:10001/hive
Enter username for jdbc:hive2://hadoop2:10001/hive: root
Enter password for jdbc:hive2://hadoop2:10001/hive: ****
Connected to: Apache Hive (version 1.1.0-cdh5.7.0)
Driver: Hive JDBC (version 1.1.0-cdh5.7.0)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://hadoop2:10001/hive> show databases;
INFO : Compiling command(queryId=hadoop_20210317093636_601d18ef-759b-44fd-b19e-88f828df9f47): show databases
INFO : Semantic Analysis Completed
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:database_name, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=hadoop_20210317093636_601d18ef-759b-44fd-b19e-88f828df9f47); Time taken: 1.081 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=hadoop_20210317093636_601d18ef-759b-44fd-b19e-88f828df9f47): show databases
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=hadoop_20210317093636_601d18ef-759b-44fd-b19e-88f828df9f47); Time taken: 0.082 seconds
INFO : OK
+----------------+--+
| database_name |
+----------------+--+
| default |
+----------------+--+
1 row selected (1.762 seconds)
0: jdbc:hive2://hadoop2:10001/hive>
7.spark
hadoop1 (master) hadoop2(slave) node1(slave)
(1)环境变量
JAVA_HOME=/home/hadoop/jdk1.8.0_60
ZOOKEEPER_HOME=/home/hadoop/zookeeper-3.4.5-cdh5.10.0
HADOOP_HOME=/home/hadoop/hadoop-2.6.0-cdh5.7.0
HBASE_HOME=/home/hadoop/hbase-1.2.0-cdh5.7.0
HIVE_HOME=/home/hadoop/hive-1.1.0-cdh5.7.0
SPARK_HOME=/home/hadoop/spark-2.1.0-bin-2.6.0-cdh5.7.0
PATH=$PATH:$HOME/bin
PATH=$PATH:$JAVA_HOME:$ZOOKEEPER:$HADOOP_HOME:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$HBASE_HOME/bin:$HIVE_HOME/bin:$SPARK_HOME/bin
export PATH JAVA_HOME ZOOKEEPER HADOOP_HOME HBASE_HOME HIVE_HOME SPARK_HOME
source 一下
(2) 配置conf/spark-env.sh
export JAVA_HOME=/home/hadoop/jdk1.8.0_60
export HADOOP_HOME=/home/hadoop/hadoop-2.6.0-cdh5.7.0
export SPARK_WORKER_OPTS="-Dspark.worker.cleanup.enabled=true"
export SPARK_WORKER_DIR=/home/hadoop/spark/work
export SPARK_LOG_DIR=/home/hadoop/spark/logs
export SPARK_PID_DIR=/home/hadoop/spark/pid
export SPARK_MASTER_IP=hadoop1
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PORT=8080
export SPARK_WORKER_WEBUI_PORT=8081
export SPARK_WORKER_INSTANCES=1
export SPARK_CONF_DIR=/home/hadoop/spark-2.1.0-bin-2.6.0-cdh5.7.0/conf
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_WORKER_MEMORY=4g
export SPARK_WORKER_CORES=2
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop1:2181,hadoop2:2181,node1:2181 -Dspark.deploy.zookeeper.dir=~/spark"
#-Dspark.deploy.recoverMode=ZOOKEEPER #代表发生故障使用zookeeper服务
#-Dspark.depoly.zookeeper.url=hadoop1,hadoop2,node1 #主机名的名字
#-Dspark.deploy.zookeeper.dir=/spark #spark要在zookeeper上写数据时的保存目录
把软件复制到其他机器上
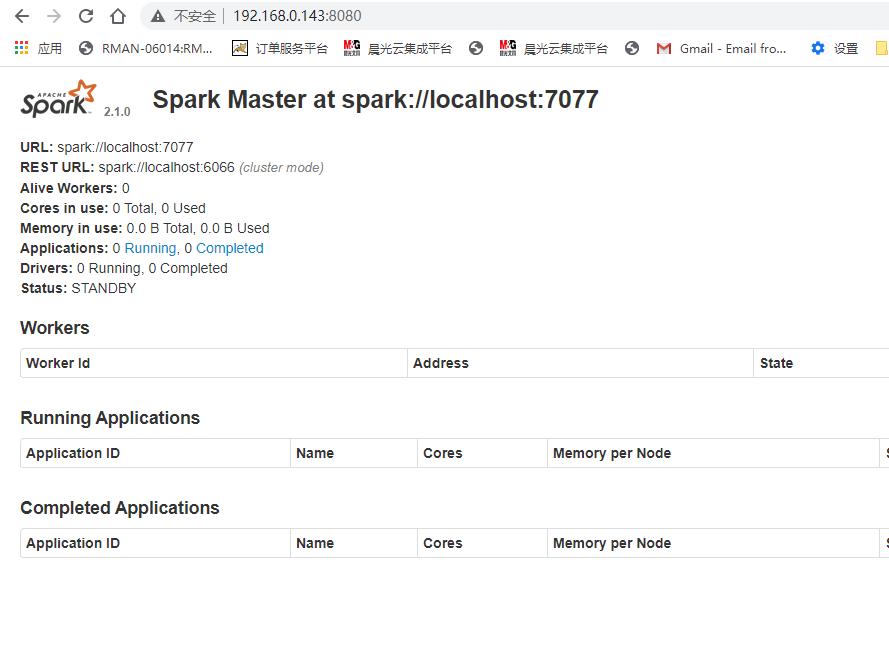
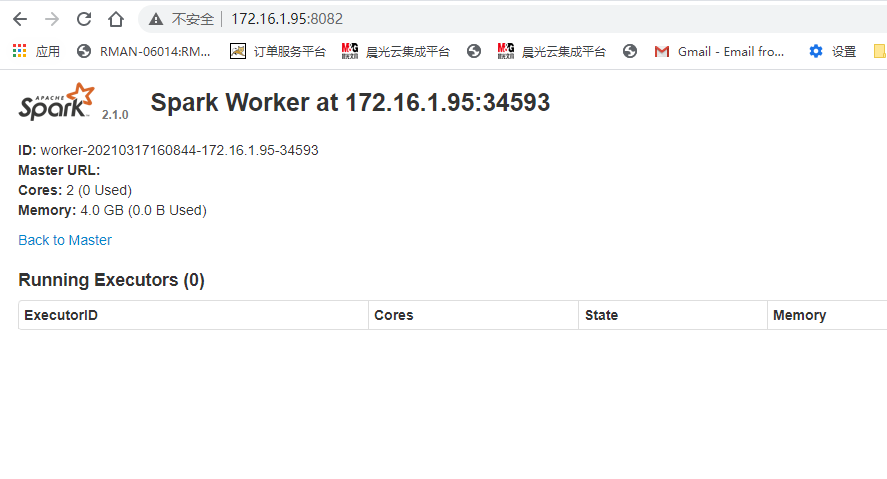
(3)启动sbin/start-all.sh
[hadoop@oracletest01 conf]$ ../sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /home/hadoop/spark/logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-oracletest01.out
hadoop1: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-oracletest01.out
hadoop2: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-drprecoverydb01.out
node1: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-FineReportAppServer.out
jps
[hadoop@oracletest01 conf]$ jps
21601 Master
9825 QuorumPeerMain
16258 SparkSubmit
22244 Jps
13605 SparkSubmit
18213 NameNode
16453 SparkSubmit
18757 DFSZKFailoverController
20520 SparkSubmit
19753 SparkSubmit
18986 NodeManager
21711 Worker
14161 SparkSubmit
20018 SparkSubmit
18550 JournalNode
18872 ResourceManager
20794 RunJar
18331 DataNode
17245 SparkSubmit
11775 SecondaryNameNode
13311 SparkSubmit
[hadoop@oracletest01 conf]$ ssh hadoop2
Last login: Wed Mar 17 09:37:40 2021 from 10.10.109.39
[hadoop@drprecoverydb01 ~]$ jps
13408 DFSZKFailoverController
13266 JournalNode
19572 HRegionServer
13860 NameNode
32052 Jps
10933 QuorumPeerMain
17479 RunJar
19688 HMaster
13160 DataNode
31833 Worker
[hadoop@drprecoverydb01 ~]$ ssh node1
Last login: Tue Mar 16 09:45:55 2021 from 10.10.109.39
[hadoop@FineReportAppServer ~]$ jps
20208 HMaster
20960 Worker
19745 HRegionServer
17540 QuorumPeerMain
14676 ResourceManager
21269 Jps
20519 NodeManager
20407 JournalNode
20297 DataNode
17273 Master
1786 SecondaryNameNode
[hadoop@FineReportAppServer ~]$
8.sqoop
(1)配置环境
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
JAVA_HOME=/home/hadoop/jdk1.8.0_60
ZOOKEEPER_HOME=/home/hadoop/zookeeper-3.4.5-cdh5.10.0
HADOOP_HOME=/home/hadoop/hadoop-2.6.0-cdh5.7.0
HBASE_HOME=/home/hadoop/hbase-1.2.0-cdh5.7.0
SPARK_HOME=/home/hadoop/spark-2.1.0-bin-2.6.0-cdh5.7.0
FLUME_HOME=/home/hadoop/apache-flume-1.6.0-cdh5.10.1-bin
HIVE_HOME=/home/hadoop/hive-1.1.0-cdh5.7.0
SQOOP_HOME=/home/hadoop/sqoop-1.4.6-cdh5.7.0
PATH=$PATH:$HOME/bin
PATH=$PATH:$JAVA_HOME:$ZOOKEEPER_HOME:$HADOOP_HOME:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$HBASE_HOME/bin:$SPARK_HOME/bin:$FLUME_HOME/bin:$HIVE_HOME/bin:$SQOOP_HOME/bin
export PATH JAVA_HOME ZOOKEEPER HADOOP_HOME HBASE_HOME SPARK_HOME FLUME_HOME
(2)修改配置conf/sqoop-env.sh
cp conf/sqoop-env-template.sh conf/sqoop-env.sh
vim conf/sqoop-env.sh
export HADOOP_COMMON_HOME= /home/hadoop/hadoop-2.6.0-cdh5.7.0/
export HADOOP_MAPRED_HOME= /home/hadoop/hadoop-2.6.0-cdh5.7.0/
export HIVE_HOME=/home/hadoop/hive-1.1.0-cdh5.7.0
(3)添加驱动jar包
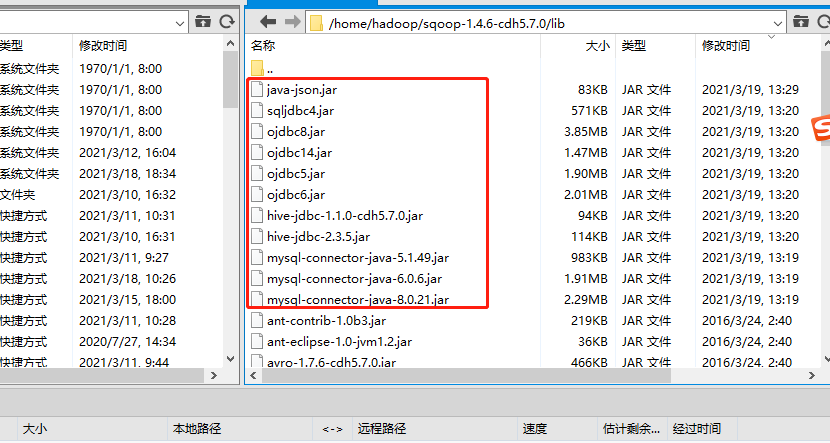
并且将hive的lib下的所有文件复制到sqoop下,以及hive的conf下的hive-site.xml复制到sqoop的conf下
(4)抽取
sqoop import --connect jdbc:oracle:thin:@192.168.0.72:1521:pdm --username xxxx --password xxxx --table PDM.T01_SALES_MAIN_INFO -m 1 --hive-import --hive-database pdm --hive-table T01_SALES_MAIN_INFO
9.flink
(1)配置环境变量
(2)配置conf下的flink-conf.yaml
jobmanager.rpc.port: 6123
jobmanager.heap.size: 1024m
taskmanager.heap.size: 1024m
taskmanager.numberOfTaskSlots: 2
taskmanager.memory.preallocate: false
parallelism.default: 1
high-availability: zookeeper
high-availability.storageDir: hdfs://ns/flink/
high-availability.zookeeper.quorum: hadoop1:2181,hadoop2:2181,node1:2181
high-availability.zookeeper.path.root: /flink
state.checkpoints.dir: hdfs:///flink/checkpoints
state.savepoints.dir: hdfs:///flink/savepoints
rest.port: 8099
(3)配置conf下的master
hadoop1:8099
hadoop2:8099
(4)将安装包发到其他机器下
问题:启动无反应,缺少插件
[hadoop@oracletest01 bin]$ ./start-cluster.sh
Starting HA cluster with 2 masters.
Starting standalonesession daemon on host oracletest01.
Starting standalonesession daemon on host drprecoverydb01.
Starting taskexecutor daemon on host oracletest01.
Starting taskexecutor daemon on host drprecoverydb01.
Starting taskexecutor daemon on host FineReportAppServer.
#查看日志
[hadoop@oracletest01 bin]$ more ../log/flink-hadoop-standalonesession-1-oracletest01.log
2021-03-24 10:16:57,815 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - --------------------------------------------------------------------------------
2021-03-24 10:16:57,818 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - Starting StandaloneSessionClusterEntrypoint (Version: 1.8.0, Rev:4caec0d, Date:03.04.2019 @ 13:25:54 PDT)
2021-03-24 10:16:57,818 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - OS current user: hadoop
2021-03-24 10:16:57,818 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - Current Hadoop/Kerberos user: <no hadoop dependency found>
2021-03-24 10:16:57,818 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - JVM: Java HotSpot(TM) 64-Bit Server VM - Oracle Corporation - 1.8/25.60-b23
2021-03-24 10:16:57,818 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - Maximum heap size: 981 MiBytes
2021-03-24 10:16:57,819 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - JAVA_HOME: /home/hadoop/jdk1.8.0_60
2021-03-24 10:16:57,819 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - No Hadoop Dependency available
2021-03-24 10:16:57,819 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - JVM Options:
2021-03-24 10:16:57,819 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - -Xms1024m
2021-03-24 10:16:57,819 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - -Xmx1024m
2021-03-24 10:16:57,819 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - -Dlog.file=/home/hadoop/flink-1.8.0/log/flink-hadoop-standalonesession-1-oracletest01.log
2021-03-24 10:16:57,820 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - -Dlog4j.configuration=file:/home/hadoop/flink-1.8.0/conf/log4j.properties
2021-03-24 10:16:57,820 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - -Dlogback.configurationFile=file:/home/hadoop/flink-1.8.0/conf/logback.xml
2021-03-24 10:16:57,820 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - Program Arguments:
2021-03-24 10:16:57,820 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - --configDir
2021-03-24 10:16:57,820 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - /home/hadoop/flink-1.8.0/conf
2021-03-24 10:16:57,820 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - --executionMode
2021-03-24 10:16:57,820 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - cluster
2021-03-24 10:16:57,820 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - --host
2021-03-24 10:16:57,820 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - hadoop1
2021-03-24 10:16:57,821 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - --webui-port
2021-03-24 10:16:57,821 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - 8090
2021-03-24 10:16:57,821 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - Classpath: /home/hadoop/flink-1.8.0/lib/log4j-1.2.17.jar:/home/hadoop/flink-1.8.0/lib/slf4j-log4j12-1.7.15.jar:/home/hadoop/flink
-1.8.0/lib/flink-dist_2.11-1.8.0.jar::/home/hadoop/hadoop-2.6.0-cdh5.7.0/etc/hadoop:
2021-03-24 10:16:57,821 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - --------------------------------------------------------------------------------
2021-03-24 10:16:57,823 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - Registered UNIX signal handlers for [TERM, HUP, INT]
2021-03-24 10:16:57,847 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.rpc.port, 6123
2021-03-24 10:16:57,847 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.heap.size, 1024m
2021-03-24 10:16:57,847 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: taskmanager.heap.size, 1024m
2021-03-24 10:16:57,847 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: taskmanager.numberOfTaskSlots, 2
2021-03-24 10:16:57,848 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: taskmanager.memory.preallocate, false
2021-03-24 10:16:57,848 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: parallelism.default, 1
2021-03-24 10:16:57,848 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: high-availability, zookeeper
2021-03-24 10:16:57,848 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: high-availability.storageDir, hdfs://ns/flink/
2021-03-24 10:16:57,849 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: high-availability.zookeeper.quorum, hadoop1:2181,hadoop2:2181,node1:2181
2021-03-24 10:16:57,849 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: high-availability.zookeeper.path.root, /flink
2021-03-24 10:16:57,849 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: state.checkpoints.dir, hdfs:///flink/checkpoints
2021-03-24 10:16:57,849 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: state.savepoints.dir, hdfs:///flink/savepoints
2021-03-24 10:16:57,850 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: rest.port, 8086
2021-03-24 10:16:57,965 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - Starting StandaloneSessionClusterEntrypoint.
2021-03-24 10:16:57,965 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - Install default filesystem.
2021-03-24 10:16:57,973 INFO org.apache.flink.core.fs.FileSystem - Hadoop is not in the classpath/dependencies. The extended set of supported File Systems via Hadoop is not available.
2021-03-24 10:16:57,984 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - Install security context.
2021-03-24 10:16:57,994 INFO org.apache.flink.runtime.security.modules.HadoopModuleFactory - Cannot create Hadoop Security Module because Hadoop cannot be found in the Classpath.
2021-03-24 10:16:58,012 INFO org.apache.flink.runtime.security.SecurityUtils - Cannot install HadoopSecurityContext because Hadoop cannot be found in the Classpath.
2021-03-24 10:16:58,013 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - Initializing cluster services.
2021-03-24 10:16:58,246 INFO org.apache.flink.runtime.rpc.akka.AkkaRpcServiceUtils - Trying to start actor system at hadoop1:0
2021-03-24 10:16:58,759 INFO akka.event.slf4j.Slf4jLogger - Slf4jLogger started
2021-03-24 10:16:58,836 INFO akka.remote.Remoting - Starting remoting
2021-03-24 10:16:59,014 INFO akka.remote.Remoting - Remoting started; listening on addresses :[akka.tcp://flink@hadoop1:28824]
2021-03-24 10:16:59,021 INFO org.apache.flink.runtime.rpc.akka.AkkaRpcServiceUtils - Actor system started at akka.tcp://flink@hadoop1:28824
2021-03-24 10:16:59,038 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint - Shutting StandaloneSessionClusterEntrypoint down with application status FAILED. Diagnostics java.io.IOException: Could not create
FileSystem for highly available storage (high-availability.storageDir)
at org.apache.flink.runtime.blob.BlobUtils.createFileSystemBlobStore(BlobUtils.java:119)
at org.apache.flink.runtime.blob.BlobUtils.createBlobStoreFromConfig(BlobUtils.java:92)
at org.apache.flink.runtime.highavailability.HighAvailabilityServicesUtils.createHighAvailabilityServices(HighAvailabilityServicesUtils.java:121)
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.createHaServices(ClusterEntrypoint.java:316)
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.initializeServices(ClusterEntrypoint.java:273)
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.runCluster(ClusterEntrypoint.java:216)
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.lambda$startCluster$0(ClusterEntrypoint.java:172)
at org.apache.flink.runtime.security.NoOpSecurityContext.runSecured(NoOpSecurityContext.java:30)
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.startCluster(ClusterEntrypoint.java:171)
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.runClusterEntrypoint(ClusterEntrypoint.java:535)
at org.apache.flink.runtime.entrypoint.StandaloneSessionClusterEntrypoint.main(StandaloneSessionClusterEntrypoint.java:65)
Caused by: org.apache.flink.core.fs.UnsupportedFileSystemSchemeException: Could not find a file system implementation for scheme 'hdfs'. The scheme is not directly supported by Flink and no Hadoop file system to support this
scheme could be loaded.
at org.apache.flink.core.fs.FileSystem.getUnguardedFileSystem(FileSystem.java:403)
at org.apache.flink.core.fs.FileSystem.get(FileSystem.java:318)
at org.apache.flink.core.fs.Path.getFileSystem(Path.java:298)
at org.apache.flink.runtime.blob.BlobUtils.createFileSystemBlobStore(BlobUtils.java:116)
... 10 more
Caused by: org.apache.flink.core.fs.UnsupportedFileSystemSchemeException: Hadoop is not in the classpath/dependencies.
at org.apache.flink.core.fs.UnsupportedSchemeFactory.create(UnsupportedSchemeFactory.java:64)
at org.apache.flink.core.fs.FileSystem.getUnguardedFileSystem(FileSystem.java:399)
... 13 more
.
2021-03-24 10:16:59,063 INFO org.apache.flink.runtime.rpc.akka.AkkaRpcService - Stopping Akka RPC service.
2021-03-24 10:16:59,073 INFO akka.remote.RemoteActorRefProvider$RemotingTerminator - Shutting down remote daemon.
2021-03-24 10:16:59,075 INFO akka.remote.RemoteActorRefProvider$RemotingTerminator - Remote daemon shut down; proceeding with flushing remote transports.
2021-03-24 10:16:59,108 INFO akka.remote.RemoteActorRefProvider$RemotingTerminator - Remoting shut down.
2021-03-24 10:16:59,143 INFO org.apache.flink.runtime.rpc.akka.AkkaRpcService - Stopped Akka RPC service.
2021-03-24 10:16:59,144 ERROR org.apache.flink.runtime.entrypoint.ClusterEntrypoint - Could not start cluster entrypoint StandaloneSessionClusterEntrypoint.
org.apache.flink.runtime.entrypoint.ClusterEntrypointException: Failed to initialize the cluster entrypoint StandaloneSessionClusterEntrypoint.
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.startCluster(ClusterEntrypoint.java:190)
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.runClusterEntrypoint(ClusterEntrypoint.java:535)
at org.apache.flink.runtime.entrypoint.StandaloneSessionClusterEntrypoint.main(StandaloneSessionClusterEntrypoint.java:65)
Caused by: java.io.IOException: Could not create FileSystem for highly available storage (high-availability.storageDir)
at org.apache.flink.runtime.blob.BlobUtils.createFileSystemBlobStore(BlobUtils.java:119)
at org.apache.flink.runtime.blob.BlobUtils.createBlobStoreFromConfig(BlobUtils.java:92)
at org.apache.flink.runtime.highavailability.HighAvailabilityServicesUtils.createHighAvailabilityServices(HighAvailabilityServicesUtils.java:121)
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.createHaServices(ClusterEntrypoint.java:316)
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.initializeServices(ClusterEntrypoint.java:273)
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.runCluster(ClusterEntrypoint.java:216)
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.lambda$startCluster$0(ClusterEntrypoint.java:172)
at org.apache.flink.runtime.security.NoOpSecurityContext.runSecured(NoOpSecurityContext.java:30)
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.startCluster(ClusterEntrypoint.java:171)
... 2 more
Caused by: org.apache.flink.core.fs.UnsupportedFileSystemSchemeException: Could not find a file system implementation for scheme 'hdfs'. The scheme is not directly supported by Flink and no Hadoop file system to support this
scheme could be loaded.
at org.apache.flink.core.fs.FileSystem.getUnguardedFileSystem(FileSystem.java:403)
at org.apache.flink.core.fs.FileSystem.get(FileSystem.java:318)
at org.apache.flink.core.fs.Path.getFileSystem(Path.java:298)
at org.apache.flink.runtime.blob.BlobUtils.createFileSystemBlobStore(BlobUtils.java:116)
... 10 more
Caused by: org.apache.flink.core.fs.UnsupportedFileSystemSchemeException: Hadoop is not in the classpath/dependencies.
at org.apache.flink.core.fs.UnsupportedSchemeFactory.create(UnsupportedSchemeFactory.java:64)
at org.apache.flink.core.fs.FileSystem.getUnguardedFileSystem(FileSystem.java:399)
... 13 more
缺少hadoopjar包,下载flink-shaded-hadoop-2-uber-2.6.5-10.0.jar包放到lib下,发到其他机器下
[hadoop@oracletest01 bin]$ scp ../lib/flink-shaded-hadoop-2-uber-2.6.5-10.0.jar hadoop2:~/flink-1.8.0/lib/
flink-shaded-hadoop-2-uber-2.6.5-10.0.jar 100% 35MB 34.6MB/s 00:00
[hadoop@oracletest01 bin]$ scp ../lib/flink-shaded-hadoop-2-uber-2.6.5-10.0.jar node1:~/flink-1.8.0/lib/
flink-shaded-hadoop-2-uber-2.6.5-10.0.jar 100% 35MB 34.6MB/s 00:00
jps下 StandaloneSessionClusterEntrypoint ,TaskManagerRunner
[hadoop@oracletest01 bin]$ jps
8429 JournalNode
8100 NameNode
8670 Jps
14644 HMaster
8738 ResourceManager
8219 DataNode
7958 StandaloneSessionClusterEntrypoint
8852 NodeManager
8571 TaskManagerRunner
8629 DFSZKFailoverController
[hadoop@FineReportAppServer lib]$ jps
6976 JournalNode
25745 Jps
17540 QuorumPeerMain
26133 AzkabanExecutorServer
9686 HRegionServer
28503 RemoteInterpreterServer
6840 DataNode
25658 TaskManagerRunner
26269 AzkabanWebServer
28111 ZeppelinServer
[hadoop@drprecoverydb01 conf]$ jps
11792 StandaloneSessionClusterEntrypoint
31922 JournalNode
31730 NameNode
32068 DFSZKFailoverController
10933 QuorumPeerMain
12277 TaskManagerRunner
31816 DataNode
12413 Jps
2893 HMaster
上面只是standalone模式,standalone cluster的资源隔离做的并不优秀,不适用于生产,需要改为yarn模式
(5)yarn模式
它有两种方式:
a.session模式:所有job共用一个一块资源,如果资源满了,下个作业就无法提交,只能等上个作业执行完资源释放出来后才能提交。除非作业很少执行也快,否则不会用它。
yarn-session.sh -n 3 -jm 1024 -tm 1024
主要参数
-n 指定TaskManager数量
-jm 指定JobManager使用内存
-id:指定yarn的任务ID
-nl:为YARN应用程序指定YARN节点标签
-m 指定JobManager地址
-D 指定动态参数
-d 客户端分离,指定后YarnSession部署到yarn之后,客户端会自行关闭
-j 指定执行jar包
-q:显示可用的YARN资源(内存,内核)
-qu:指定YARN队列
-s:指定TaskManager中slot的数量;
-st:以流模式启动Flink
-tm:每个TaskManager容器的内存(默认值:MB)
-z:命名空间,用于为高可用性模式创建Zookeeper子路径
[hadoop@oracletest01 bin]$ yarn-session.sh -n 3 -jm 1024 -tm 1024 -s 8 -nm FlinkOnYarnSession -d -st
...
...省略日志
...
JobManager Web Interface: http://localhost:8099
2021-03-24 11:32:52,277 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - The Flink YARN client has been started in detached mode. In order to stop Flink on YARN, use the following command or a YARN web interface to stop it:
yarn application -kill application_1616399456334_0008
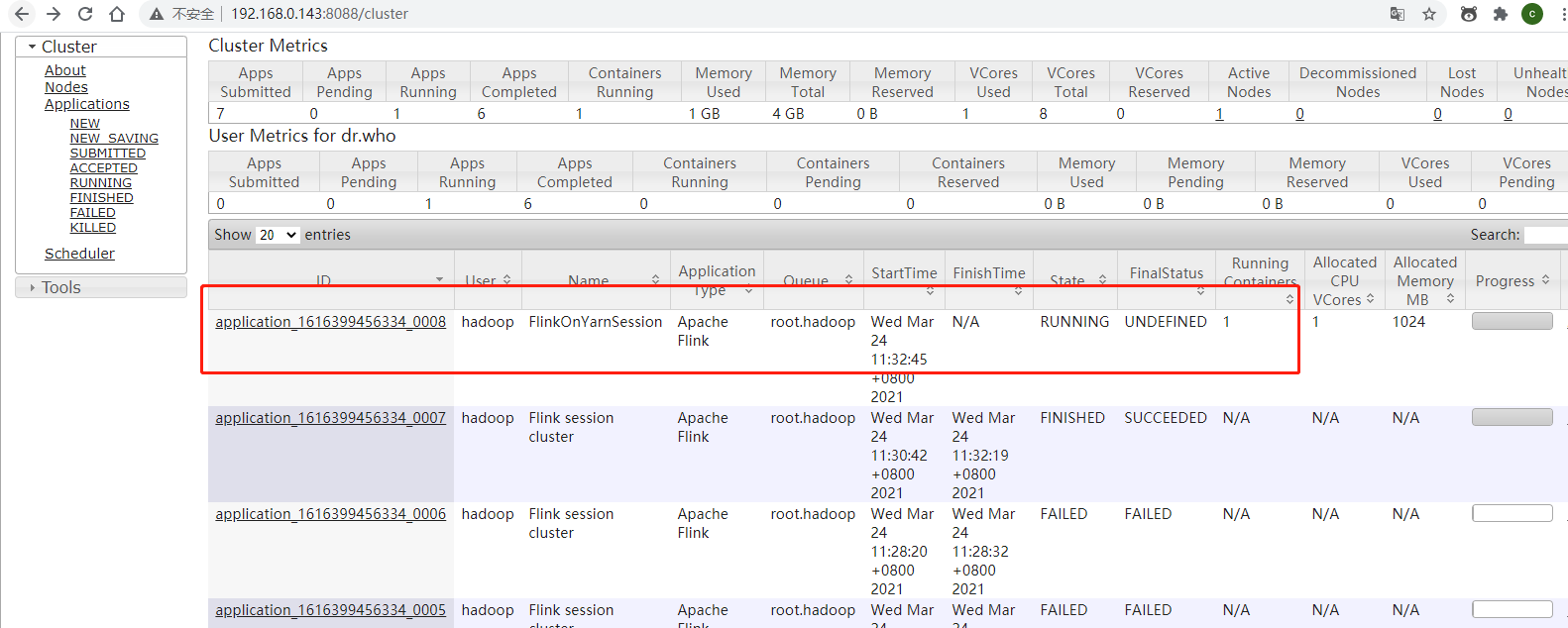
kill:
[hadoop@oracletest01 bin]$ yarn application -kill application_1616399456334_0008
21/03/24 11:35:12 INFO client.RMProxy: Connecting to ResourceManager at hadoop1/192.168.0.143:8032
21/03/24 11:35:12 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Killing application application_1616399456334_0008
21/03/24 11:35:13 INFO impl.YarnClientImpl: Killed application application_1616399456334_0008
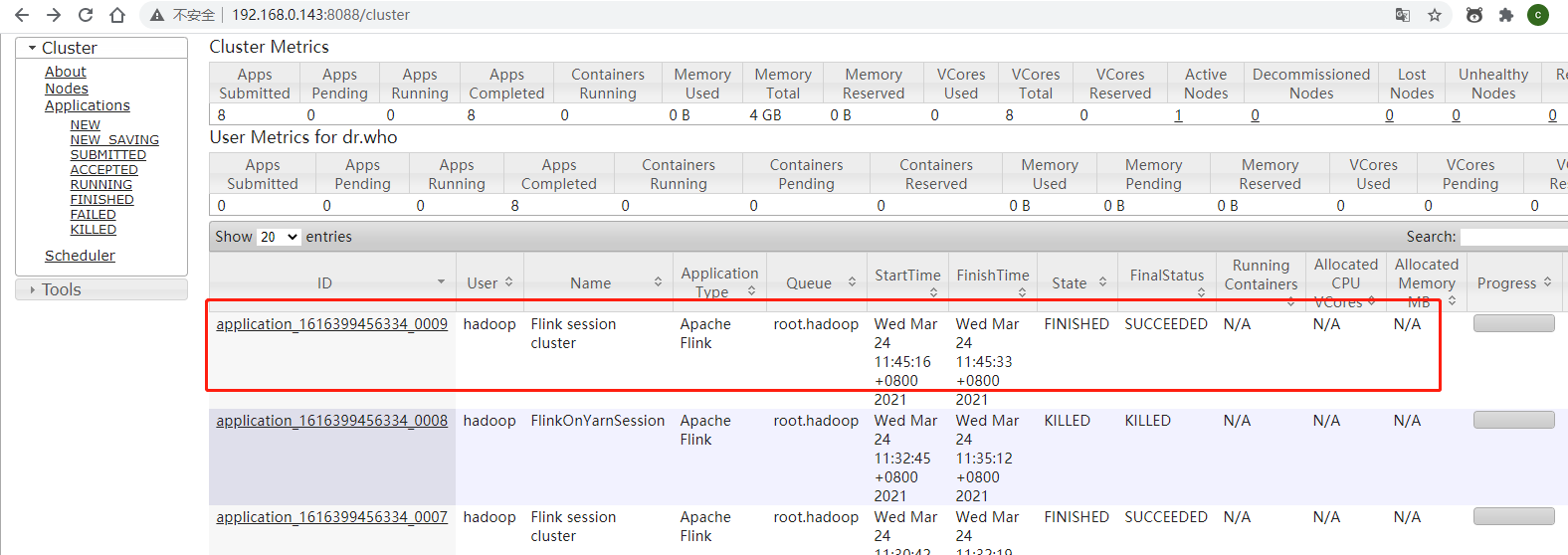
b.per-job模式:每次提交都会创建一个新的flink集群,任务之间互相独立,互不影响,方便管理。任务执行完成之后创建的集群也会消失
[hadoop@oracletest01 bin]$ ./flink run -m yarn-cluster -yn 1 -yjm 1024 -ytm 1024 ../examples/batch/WordCount.jar
...
...省略输出
...
(tis,2)
(to,15)
(traveller,1)
(troubles,1)
(turn,1)
(under,1)
(undiscover,1)
(unworthy,1)
(us,3)
(we,4)
(weary,1)
(what,1)
(when,2)
(whether,1)
(whips,1)
(who,2)
(whose,1)
(will,1)
(wish,1)
(with,3)
(would,2)
(wrong,1)
(you,1)
Program execution finished
Job with JobID 8c491f265d1be7d4d0dc8adda9c4f3a8 has finished.
Job Runtime: 8332 ms
Accumulator Results:
- 35315d281312c3ed64587fef08fd609c (java.util.ArrayList) [170 elements]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号