自然语言处理BERT模型
自然语言处理BERT模型
自然语言处理通用解决方案:
1、需要熟悉Word2vec,RNN模型,了解词向量和如何建模。
2、重点在Transformer网络架构,BERT训练方法,实际应用。
3、项目是开源的,预训练模型直接可以使用。
4、提供预训练模型,基本任务直接用。
Transformer:
基本组成是机器翻译模型中常见的Seq2Seq网络;
输入输出很直观(输入一句话,输出也为一句话),核心架构就是中间的网络设计。
传统的RNN计算时的问题:
1、不能并行计算,后一时刻依赖于前一时刻的输出。
2、self-attention机制来并行计算,每个词的重要性不一样,基本取代了RNN
传统的word2vec表示词向量的问题:
一个词的词向量训练好就不变了,但是不同语境,同样的词意思不一样,应该用不同的词向量表示。
最好是结合上下文的信息,才能真实的反映词的意思。
Transformer的self-attention机制(重要):
self-attention:让计算机根据输入的信息,自己判断各个词的重要性。每个词编码要结合上下文的所有语境信息。
self-attention计算:
1、输入经过编码后得到向量;
2、想得到当前词语上下文的关系,可以当做是加权;
3、构建是哪个矩阵分别来查询当前词跟其他词的关系,以及特征向量的表达。
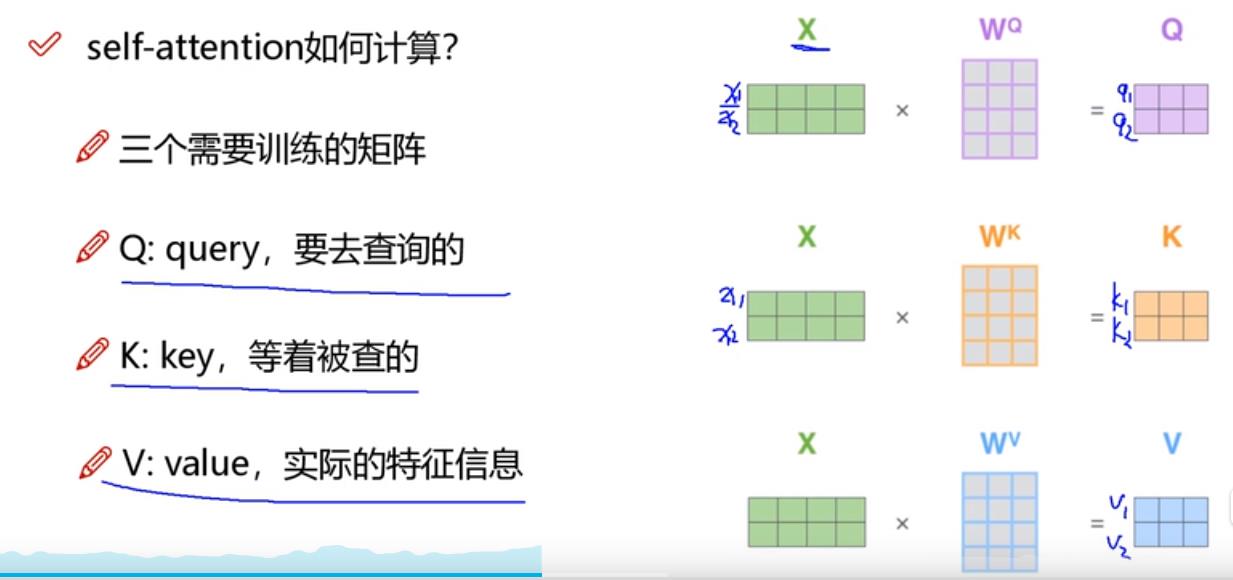
1、q与k的内积表示相关性的大小(得分)。
2、将计算的一系列得分,经过softmax就是最终的上下文结果。
3、将结果与v相乘,得到最终的特征向量。
multi-headde机制:
每个词多组q,k,v,一般8个头(8次自注意力),得到8组特征表达,将所有特征拼接,再通过一个全连接层来降维。
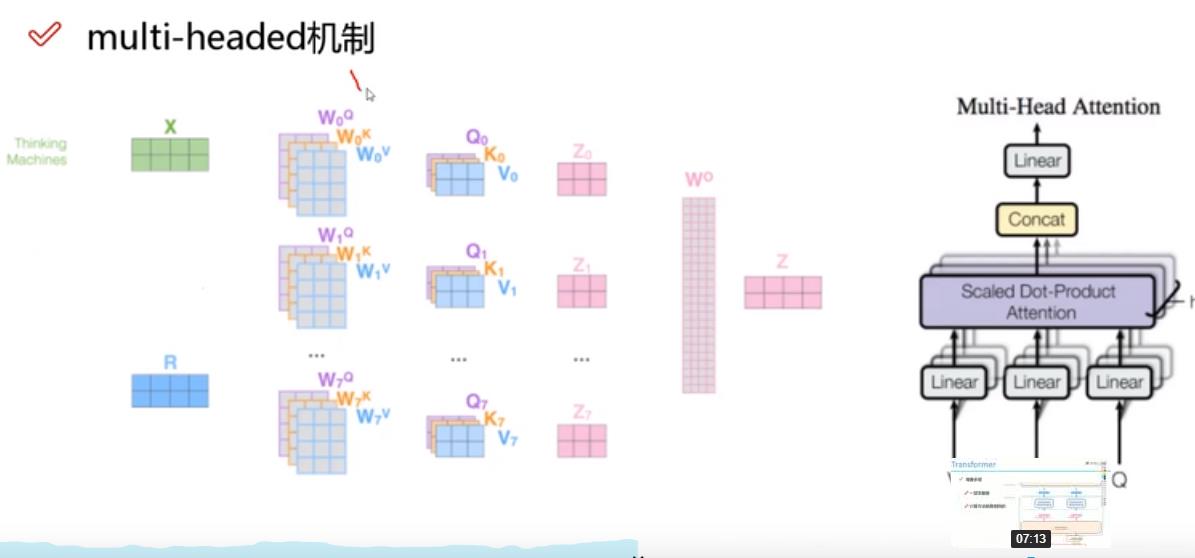
multi-headde机制结果:不同的注意力结果,得到的特征向量表达也不同。
位置信息表达:
给self-attention加入位置信息编码:词嵌入得到词向量,再加上一个周期信号作为位置信息编码,后续开源项目里有,不用自己做。
残差连接和归一化:对每一个数据,使得均值为0,标准差为1.
decoder:
加入了mask机制,每个词编码只能用它之前的词信息。
整体的过程:

BERT(Bidirectional Encoder Representations from Transformers):
BERT就是Transformer的编码器。
BERT提供了预训练模型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号